We have been discussing concurrency as a means to modularize programs with multiple interactions. For instance, concurrency allows a network server to interact with a multitude of clients simultaneously while letting you separately write and maintain code that deals with only a single client at a time. Sometimes these interactions are batch-like operations that we want to overlap, such as when downloading multiple URLs simultaneously. There the goal was to speed up the program by overlapping the I/O, but it is not true parallelism because we don’t need multiple processors to achieve a speedup; the speedup was obtained by overlapping the time spent waiting for multiple web servers to respond.
But concurrency can also be used to achieve true parallelism. In
this book, we have tried to emphasize the use of the parallel
programming models—Eval, Strategies, the Par monad, and so on—for
parallelism where possible, but there are some problems for which
these pure parallel programming models cannot be used. These are the two main
classes of problem:
- Problems where the work involves doing some I/O
- Algorithms that rely on some nondeterminism internally
Having side effects does not necessarily rule out the use of
parallel programming models because Haskell has the ST monad for
encapsulating side-effecting computations. However, it is typically
difficult to use parallelism within the ST monad, and in that case
probably the only solution is to drop down to concurrency unless your
problem fits into the Repa model (Chapter 5).
In many cases, you can achieve parallelism by forking a few
threads to do the work. The Async API can help by propagating
errors appropriately and cleaning up threads. As with the parallel
programs we saw in Part I, you need to do two things to run
a program on multiple cores:
-
Compile the program with
-threaded. -
Run the program with
+RTS -Ncoreswherecoresis the number of cores to use, e.g.,+RTS -N2to use two cores. Alternatively, use+RTS -Nto use all the cores in your machine.
When multiple cores are available, the GHC runtime system automatically migrates threads between cores so that no cores are left idle. Its load-balancing algorithm isn’t very sophisticated, though, so don’t expect the scheduling policy to be fair, although it does try to ensure that threads do not get starved.
Many of the issues that we saw in Part I also arise when using concurrency to program parallelism; for example, static versus dynamic partitioning, and granularity. Forking a fixed number of threads will gain only a fixed amount of parallelism, so instead you probably want to fork plenty of threads to ensure that the program scales beyond a small number of cores. On the other hand, forking too many threads creates overhead that we want to avoid. The next section tackles these issues in the context of a concrete example.
We start by considering how to parallelize a simple program that
searches the filesystem for files with a particular name. The program
takes a filename to search for and the root directory for the search
as arguments, and prints either Just p if the file was found with
pathname p or Nothing if it was not found.
This problem may be either I/O-bound or compute-bound, depending on whether the filesystem metadata is already cached in memory or not, but luckily the same solution will allow us to parallelize the work in both cases.
The search is implemented in a recursive function find, which takes
the string to search for and the directory to start searching from,
respectively, and returns a Maybe FilePath indicating whether the
file was found (and its path) or not. The algorithm is a recursive
walk over the filesystem, using the functions getDirectoryContents
and doesDirectoryExist from System.Directory:
find::String->FilePath->IO(MaybeFilePath)findsd=dofs<-getDirectoryContentsd--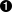
letfs'=sort$filter(`notElem`[".",".."])fs--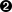
ifany(==s)fs'--
thenreturn(Just(d</>s))elseloopfs'--
whereloop[]=returnNothing--
loop(f:fs)=doletd'=d</>f--
isdir<-doesDirectoryExistd'--
ifisdirthendor<-findsd'--
caserofJust_->returnr--
Nothing->loopfs--
elseloopfs--
-
Read the list of filenames in the directory
d.-
Filter out
"."and".."(the two special entries corresponding to the current and the parent directory, respectively). We alsosortthe list so that the search is deterministic.-
If the filename we are looking for is in the current directory, then return the result:
d </> sis the filename constructed by appending the filenamesto the directoryd.-
If the filename was not found, then loop over the filenames in the directory
d, recursively searching each one that is a subdirectory.-
In the loop, if we reach the end of the list, then we did not find the file. Return
Nothing.-
For a filename
f, construct the full pathd </> f.-
Ask whether this pathname corresponds to a directory.
-
If it does, then make a recursive call to
findto search the subdirectory.-
If the file was found in this subdirectory, then return the name.
-
Otherwise, loop to search the rest of the subdirectories.

If the name was not a directory, then loop again to search the rest.
The main function that wraps find into a program expects two command-line arguments and passes them as the arguments to find:
main::IO()main=do[s,d]<-getArgsr<-findsdr
To search a tree consisting of about 7 GB of source code on
my computer, this program takes 1.14s when all the metadata is
in the cache.[47] The program isn’t as efficient as it could be. The
system find program is about four times faster, mainly because the
Haskell program is using the notoriously inefficient String type
and doing Unicode conversion. If you were optimizing this program for real, it would obviously be important to fix these inefficiencies before trying to parallelize it, but we gloss over that here.
Parallelizing this program is not entirely straightforward because doing it naively could waste a lot of work; if we search multiple subdirectories concurrently and we find the file in one subdirectory, then we would like to stop searching the others as soon as possible. Moreover, if an error is encountered at any point, then we need to propagate the exception correctly. We must be careful to keep the deterministic behavior of the sequential version, too. If we encounter an error while searching a subtree, then the error should not prevent the return of a correct result if the sequential program would have done so.
To implement this, we’re going to use the Async API with its
withAsync facility for creating threads and automatically cancelling
them later. This is just what we need for spawning threads to search
subtrees: the search threads should be automatically cancelled as soon
as we have a result for a subtree.
withAsync::IOa->(Asynca->IOb)->IOb
It takes the inner computation as its second argument. So to set off
several searches in parallel, we have to nest multiple calls of
withAsync. This implies a fold of some kind, and furthermore we
need to collect up the Async values so we can wait for the
results. The function we are going to fold is this:
subfind::String->FilePath->([Async(MaybeFilePath)]->IO(MaybeFilePath))->[Async(MaybeFilePath)]->IO(MaybeFilePath)subfindspinnerasyncs=doisdir<-doesDirectoryExistpifnotisdirtheninnerasyncselsewithAsync(findsp)$\a->inner(a:asyncs)
The subfind function takes the string to search for, s, the path
to search, p, the inner IO computation, inner, and the list of
Asyncs, asyncs. If the path corresponds to a directory, we
create a new Async to search it using withAsync, and inside
withAsync we call inner, passing the original list of Asyncs
with the new one prepended. If the pathname is not a directory, then we
simply invoke the inner computation without creating a new Async.
Using this piece, we can now update the find function to create a
new Async for each subdirectory:
find::String->FilePath->IO(MaybeFilePath)findsd=dofs<-getDirectoryContentsdletfs'=sort$filter(`notElem`[".",".."])fsifany(==s)fs'thenreturn(Just(d</>s))elsedoletps=map(d</>)fs'--foldr(subfinds)dowaitps[]--wheredowaitas=loop(reverseas)--loop[]=returnNothingloop(a:as)=do--r<-waitacaserofNothing->loopasJusta->return(Justa)
The differences from the previous find are as follows:
-
Create the list of pathnames by prepending
dto each filename.-
Fold
subfindover the list of pathnames, creating the nested sequence ofwithAsynccalls to create the child threads. The inner computation is the functiondowait, defined next.-
dowaitenters a loop to wait for eachAsyncto finish, but first we must reverse the list. The fold generated the list in reverse order, and to make sure we retain the same behavior as the sequential version, we must check the results in the same order.-
The
loopfunction loops over the list ofAsyncs and callswaitfor each one. If any of theAsyncs returns aJustresult, thenloopimmediately returns it. Returning from here will cause all theAsyncs to be cancelled, as we return up through the nest ofwithAsynccalls. Similarly, if an error occurs inside any of theAsynccomputations, then the exception will propagate from thewaitand cancel all the otherAsyncs.
You might wonder whether creating a thread for every subdirectory is
expensive, both in terms of time and space. Let’s compare findseq
and findpar on the same 7 GB tree of source code, searching for a file that does not exist so that the search is forced to traverse the whole tree:
$ ./findseq nonexistent ~/code +RTS -s
Nothing
2,392,886,680 bytes allocated in the heap
76,466,184 bytes copied during GC
1,179,224 bytes maximum residency (26 sample(s))
37,744 bytes maximum slop
4 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.05s ( 1.06s elapsed)
GC time 0.07s ( 0.07s elapsed)
Total time 1.13s ( 1.13s elapsed)$ ./findpar nonexistent ~/code +RTS -s
Nothing
2,523,910,384 bytes allocated in the heap
601,596,552 bytes copied during GC
34,332,168 bytes maximum residency (21 sample(s))
1,667,048 bytes maximum slop
80 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.28s ( 1.29s elapsed)
GC time 1.16s ( 1.16s elapsed)
Total time 2.44s ( 2.45s elapsed)The parallel version does indeed take about twice as long, and it needs a lot more memory (80 MB compared to 4 MB). But let’s see how well it scales, first with two processors:
$ ./findpar nonexistent ~/code +RTS -s -N2
Nothing
2,524,242,200 bytes allocated in the heap
458,186,848 bytes copied during GC
26,937,968 bytes maximum residency (21 sample(s))
1,242,184 bytes maximum slop
62 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.28s ( 0.65s elapsed)
GC time 0.86s ( 0.43s elapsed)
Total time 2.15s ( 1.08s elapsed)We were lucky. This program scales super-linearly (better than double
performance with two cores), and just about beats the sequential
version when using -N2. The reason for super-linear performance may
be because running in parallel allowed some of the data structures to
be garbage-collected earlier than they were when running sequentially. Note the lower GC time compared with findseq and the lower memory use compared with the single-processor findpar. Running with -N4
shows the good scaling continue:
$ ./findpar nonexistent ~/code +RTS -s -N4
Nothing
2,524,666,176 bytes allocated in the heap
373,621,096 bytes copied during GC
23,306,264 bytes maximum residency (23 sample(s))
1,084,456 bytes maximum slop
55 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.42s ( 0.36s elapsed)
GC time 0.83s ( 0.21s elapsed)
Total time 2.25s ( 0.57s elapsed)Relative to the sequential program, this is a speedup of two on four cores. Not bad, but we ought to be able to do better.
The findpar program is scaling quite nicely, which indicates that there is plenty of parallelism available. Indeed, a quick glance at a
ThreadScope profile confirms this (Figure 13-1).
So the reason for the lack of speedup relative to the sequential version is the extra overhead in the parallel program. To improve performance, therefore, we need to focus on reducing the overhead.
The obvious target is the creation of an Async, and therefore a thread, for every single subdirectory. This is a classic granularity problem—the granularity is too fine.
One solution to granularity is chunking, where we increase the grain size by making larger chunks of work (we used this technique with the K-Means example in Parallelizing K-Means). However, here the computation is tree-shaped, so we can’t easily chunk. A depth threshold is more appropriate for divide-and-conquer algorithms, as we saw in Example: A Conference Timetable, but here the problem is that the tree shape is dependent on the filesystem structure and is therefore not naturally balanced. The tree could be very unbalanced—most of the work might be concentrated in one deep subdirectory. (The reader is invited to try adding a depth threshold to the program and experiment to see how well it works.)
So here we will try a different approach. Remember that what we are trying to do is limit the number of threads created so we have just the right amount to keep all the cores busy. So let’s program that behavior explicitly: keep a shared counter representing the number of threads we are allowed to create, and if the counter reaches zero we stop creating new ones and switch to the sequential algorithm. When a thread finishes, it increases the counter so that another thread can be created.
A counter used in this way is often called a semaphore. A semaphore contains a number of units of a resource and has two operations: acquire a unit of the resource or release one. Typically, acquiring a unit of the resource would block if there are no units available, but in our case we want something simpler. If there are no units available, then the program will do something different (fall back to the sequential algorithm). There are of course semaphore implementations for Concurrent Haskell available on Hackage, but since we only need a nonblocking semaphore, the implementation is quite straightforward, so we will write our own. Furthermore, we will need to tinker with the semaphore implementation later.
The nonblocking semaphore is called NBSem:
newtypeNBSem=NBSem(MVarInt)newNBSem::Int->IONBSemnewNBSemi=dom<-newMVarireturn(NBSemm)tryAcquireNBSem::NBSem->IOBooltryAcquireNBSem(NBSemm)=modifyMVarm$\i->ifi==0thenreturn(i,False)elselet!z=i-1inreturn(z,True)releaseNBSem::NBSem->IO()releaseNBSem(NBSemm)=modifyMVarm$\i->let!z=i+1inreturn(z,())
We used an MVar to implement the NBSem, with straightforward tryAcquireNBSem and releaseNBSem operations to acquire a unit and
release a unit of the resource, respectively. The implementation uses
things we have seen before, e.g., modifyMVar for operating on the MVar.
We will use the semaphore in subfind, which is where we implement the new decision about whether to create a new Async or not:
subfind::NBSem->String->FilePath->([Async(MaybeFilePath)]->IO(MaybeFilePath))->[Async(MaybeFilePath)]->IO(MaybeFilePath)subfindsemspinnerasyncs=doisdir<-doesDirectoryExistpifnotisdirtheninnerasyncselsedoq<-tryAcquireNBSemsem--ifqthendoletdofind=findsemsp`finally`releaseNBSemsem--withAsyncdofind$\a->inner(a:asyncs)elsedor<-findsemsp--caserofNothing->innerasyncsJust_->returnr
-
When we encounter a subdirectory, first try to acquire a unit of the semaphore.
-
If we successfully grabbed a unit, then create an
Asyncas before, but now the computation in theAsynchas an additionalfinallyreleaseNBSem, which releases the unit of the semaphore when thisAsynchas completed.-
If we didn’t get a unit of the semaphore, then we do a synchronous call to
findinstead of an asynchronous one. If thisfindreturns an answer, then we can return it; otherwise, we continue to perform theinneraction.
The changes to the find function are straightforward, just pass around the NBSem. In main, we need to create the NBSem, and the
main question is how many units to give it to start with. For now, we
defer that question and make the number of units into a command-line
parameter:
main=do[n,s,d]<-getArgssem<-newNBSem(readn)findsemsd>>=
Let’s see how well this performs. First, set n to zero so we never
create any Asyncs, and this will tell us whether the NBSem has
any impact on performance compared to the plain sequential version:
$ ./findpar2 0 nonexistent ~/code +RTS -N1 -s
Nothing
2,421,849,416 bytes allocated in the heap
84,264,920 bytes copied during GC
1,192,352 bytes maximum residency (34 sample(s))
33,536 bytes maximum slop
4 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.09s ( 1.10s elapsed)
GC time 0.08s ( 0.08s elapsed)
Total time 1.18s ( 1.18s elapsed)This ran in 1.18s, which is close to the 1.14s that the sequential
program took, so the NBSem impacts performance by around 4% (these
numbers are quite stable over several runs).
Now to see how well it scales. Remember that the value we choose for
n is the number of additional threads that the program will use, aside from the main thread. So choosing n == 1 gives us 2 threads,
for example. With n == 1 and +RTS -N2:
$ ./findpar2 1 nonexistent ~/code +RTS -N2 -s
Nothing
2,426,329,800 bytes allocated in the heap
90,600,280 bytes copied during GC
2,399,960 bytes maximum residency (40 sample(s))
80,088 bytes maximum slop
6 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.23s ( 0.65s elapsed)
GC time 0.16s ( 0.08s elapsed)
Total time 1.38s ( 0.73s elapsed)If you experiment a little, you might find that setting n == 2 is
slightly better. We seem to be doing better than findpar, which ran
in 1.08s with -N2.
I then increased the number of cores to -N4, with n == 8, and this
is a typical run on my computer:
$ ./findpar2 8 nonexistent ~/code +RTS -N4 -s
Nothing
2,464,097,424 bytes allocated in the heap
121,144,952 bytes copied during GC
3,770,936 bytes maximum residency (47 sample(s))
94,608 bytes maximum slop
10 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.55s ( 0.47s elapsed)
GC time 0.37s ( 0.09s elapsed)
Total time 1.92s ( 0.56s elapsed)
The results vary a lot but hover around this value. The original
findpar ran in about 0.57s with -N4; so the advantage of
findpar2 at -N2 has evaporated at -N4. Furthermore,
experimenting with values of n doesn’t seem to help much.
Where is the bottleneck? We can take a look at the ThreadScope profile; for example, Figure 13-2 is a typical section:
Things look quite erratic, with threads often blocked. Looking at the
raw events in ThreadScope shows that threads are getting blocked on
MVars, and that is the clue: there is high contention for the
MVar in the NBSem.
So how can we improve the NBSem implementation to behave better when
there is contention? One solution would be to use STM because STM
transactions do not block, they just re-execute repeatedly. In fact
STM does work here, but instead we will introduce a different way to
solve the problem, one that has less overhead than STM. The idea is
to use an ordinary IORef to store the semaphore value and operate
on it using atomicModifyIORef:
atomicModifyIORef::IORefa->(a->(a,b))->IOb
The atomicModifyIORef function modifies the contents of an IORef
by applying a function to it. The function returns a pair of the new
value to be stored in the IORef and a value to be returned by
atomicModifyIORef. You should think of atomicModifyIORef as a
very limited version of STM; it performs a transaction on a single
mutable cell. Because it is much more limited, it has less overhead
than STM.
Using atomicModifyIORef, the NBSem implementation looks like this:
newtypeNBSem=NBSem(IORefInt)newNBSem::Int->IONBSemnewNBSemi=dom<-newIORefireturn(NBSemm)tryWaitNBSem::NBSem->IOBooltryWaitNBSem(NBSemm)=doatomicModifyIORefm$\i->ifi==0then(i,False)elselet!z=i-1in(z,True)signalNBSem::NBSem->IO()signalNBSem(NBSemm)=atomicModifyIORefm$\i->let!z=i+1in(z,())
Note that we are careful to evaluate the new value of i inside
atomicModifyIORef, using a bang-pattern. This is a standard trick
to avoid building up a large expression inside the IORef: 1 + 1 + 1
+ ....
The rest of the implementation is the same as findpar2.hs, except that we
added some logic in main to initialize the number of units in the
NBSem automatically:
main=do[s,d]<-getArgsn<-getNumCapabilitiessem<-newNBSem(ifn==1then0elsen*4)findsemsd>>=
The function getNumCapabilities comes from GHC.Conc and returns
the value passed to +RTS -N, which is the number of cores that the
program is using. This value can actually be changed while the
program is running, by calling setNumCapabilities from the same
module.
If the program is running on multiple cores, then we initialize the
semaphore to n * 4, which experimentation suggests to be a
reasonable value.
The results with -N4 look like this:
$ ./findpar3 nonexistent ~/code +RTS -s -N4
Nothing
2,495,362,472 bytes allocated in the heap
138,071,544 bytes copied during GC
4,556,704 bytes maximum residency (50 sample(s))
141,160 bytes maximum slop
12 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.38s ( 0.36s elapsed)
GC time 0.35s ( 0.09s elapsed)
Total time 1.73s ( 0.44s elapsed)This represents a speedup of about 2.6—our best yet, but in the next section we will improve on this a bit more.
In Chapter 4, we encountered the Par monad, a simple API for programming deterministic parallelism as a dataflow graph. There is
another version of the Par monad called ParIO, provided by the module
Control.Monad.Par.IO with two important differences from Par:[48]
Of course, unlike Par, ParIO computations are not guaranteed to be
deterministic. Nevertheless, the full power of the Par framework is
available: very lightweight tasks, multicore scheduling, and the same
dataflow API based on IVars. ParIO is ideal for parallel
programming in the IO monad, albeit with one caveat that we will
discuss shortly.
Let’s look at the filesystem-searching program using ParIO. The
structure will be identical to the Async version; we just need to
change a few lines. First, subfind:
subfind::String->FilePath->([IVar(MaybeFilePath)]->ParIO(MaybeFilePath))->[IVar(MaybeFilePath)]->ParIO(MaybeFilePath)subfindspinnerivars=doisdir<-liftIO$doesDirectoryExistpifnotisdirtheninnerivarselsedov<-new--fork(findsp>>=putv)--inner(v:ivars)--
Note that instead of a list of Asyncs, we now collect a list of
IVars that will hold the results of searching each subdirectory.
-
Create a new
IVarfor this subdirectory.-
forkthe computation to search the subdirectory, putting the result into theIVar.-
Perform the
innercomputation, adding theIVarwe just created to the list.
I’ve omitted the definition of find, which has only one difference
compared with the Async version: we call the Par monad’s get
function to get the result of an IVar, instead of Async’s
wait.
In main, we need to call runParIO to start the parallel computation:
main=do[s,d]<-getArgsrunParIO(findsd)>>=
That’s it. Let’s see how well it performs, at -N4:
$ ./findpar4 nonexistent ~/code +RTS -s -N4
Nothing
2,460,545,952 bytes allocated in the heap
102,831,928 bytes copied during GC
1,721,200 bytes maximum residency (44 sample(s))
78,456 bytes maximum slop
7 MB total memory in use (0 MB lost due to fragmentation)
MUT time 1.26s ( 0.32s elapsed)
GC time 0.27s ( 0.07s elapsed)
Total time 1.53s ( 0.39s elapsed)In fact, this version beats our carefully coded NBSem implementation,
achieving a speedup of 2.92 on 4 cores. Why is that? Well, one
reason is that we didn’t have to consult
some shared state and choose whether to fork or continue
our operation in the current thread, because fork is very cheap in Par and ParIO
(note the low-memory overhead in the results above). Another reason
is that the Par monad has a carefully tuned work-stealing scheduler
implementation that is designed to achieve good parallel
speedup.[49]
However, we cheated slightly here. ParIO has no error
handling: exceptions raised by an IO computation might (or might not)
be silently dropped, depending on which thread the Par monad
scheduler happens to be using to run the computation. It is
possible to fix this; if you enjoy a programming puzzle, why not have a
go at finding a good way yourself—preferably one that requires few
changes to the application code? My attempt can be found in
findpar5.hs.
[47] The performance characteristics of this program depend to some extent on the structure of the filesystem used as a benchmark, so don’t be too surprised if the results are a bit different on your system.
[48] In monad-par-0.3.3 and later.
[49] In fact, the Par monad implementation is built
using nothing more than the concurrency APIs that we have seen so far
in this book.
Get Parallel and Concurrent Programming in Haskell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

