We should consider ourselves lucky that so much attention has been paid to the discipline of computer performance evaluation by so many talented people over the years. There is a small but very active Special Interest Group of the Association of Computing Machinery called SIGMETRICS (see http://www.sigmetrics.org) devoted to the study of performance evaluation. There are many good university programs where topics in performance evaluation are taught and Ph.D. candidates are trained. For practitioners, there is a large professional association called the Computer Measurement Group (http://www.cmg.org) that sponsors an annual conference in December. The regular SIGMETRICS and CMG publications contain a wealth of invaluable material for the practicing performance analyst.
It is also fortunate that one of the things computers are good for is counting. It is easy to augment both hardware and software to keep track of what they are doing, although keeping the measurement overhead from overwhelming the amount of useful work being done is a constant worry. Over time, most vendors have embraced the idea of building measurement facilities into their products, and at times are even able to position them to competitive advantage because their measurement facilities render them more manageable. A system that provides measurement feedback is always more manageable than one that is a black box.
Users of Windows 2000 are fortunate that Microsoft has gone to the trouble of building in extensive performance monitoring facilities. We explore the use of specific Windows 2000 performance monitoring tools in subsequent chapters. The following discussion introduces the types of events monitored in Windows 2000, how measurements are taken, and what tools exist that access this measurement data. The basic measurement methodology used in Windows 2000 is the subject of more intense scrutiny in Chapter 2.
Measurement facilities are the prerequisite for the development of performance monitors, the primary class of tool. Performance monitoring began as a hardware function, something that continues to thrive in many circumstances, including network line monitors or sniffers, which insert a probe at an appropriate spot on the network. Performance monitoring today is usually associated with extensions to the set of base operating systems software services. Vendors generally accept the notion that the OS should collect measurement data and access additional measurement data collected by hardware.
Windows 2000 is
well instrumented, and you can access a wealth of information on its
operation and performance. Windows 2000 keeps track of many different
events, including interactions that occur between hardware and
systems software. It makes extensive use of event
counters, operating system functions that
maintain a running total of the number of times some event has
occurred. For example, interrupt processing is augmented by a simple
procedure to count the number and types of interrupts or traps being
serviced. It is also possible to obtain a count of virtual memory
page faults that
occur in a similar fashion. Windows 2000 also adds instrumentation to
count the number and types of filesystem requests that are issued.
Event counters that are updated continuously can also be called
accumulators.
The duration of requests to disks and other peripherals can also be measured by recording the start time of the original request and the end time of its completion. In Windows 2000, the operating system data structures used to serialize access to resources like the processor and the disks are instrumented. (Windows 2000 gives lip service to the ideal of object-oriented programming, so these data structures are called objects.) Instrumentation also makes it possible to determine the number of requests waiting in a disk queue, for instance. These are “right now” types of measurements: instantaneous counts of the number of active processes and threads, or numbers that show how full the paging datasets are or how virtual memory is allocated. These instantaneous measurements are more properly considered to be sampled, since typically in Windows 2000 you are accessing individual observations.
When you use Windows 2000’s built-in System Monitor application, accumulators and instantaneous counter fields are all lumped together as counters, but they are actually very different types of data. The distinction is critical because it is based on how the measurement data is collected, which affects how it can be analyzed and interpreted. The kind of field also affects the way collection data must be handled during subsequent summarization. We pursue this topic in Chapter 2.
Once per interval, a performance monitor application like the System Monitor harvests the collection data maintained by Windows 2000, gathering up the current values for these counters. Notice that the overhead associated with performance monitoring when the operating system is already maintaining these event counters is minimal. The only additional work that the application must perform is to gather up the data once per interval, make appropriate calculations, and store or log the results. In Windows 2000, collection agents are linked to performance objects. Windows 2000 operating system services are responsible for collecting base measurements for the principal resources like memory, disks, and the processor. Windows 2000 also provides instrumentation that records resource utilization at a process and thread level. Core subsystems like the network browser and redirector are also instrumented. The performance monitoring facilities are extensible; subsystems like Microsoft Exchange Server and Microsoft SQL Server add their own objects and collection agents. An overview of Windows 2000 performance monitoring is presented in Chapter 2, while subsequent chapters delve into various measurements and their uses.
At what rate should the data be collected? Capacity planners who deal with longer- term trends are ordinarily quite content with interval measurements every 15, 30, or 60 minutes. When you are trying to project seasonal or yearly changes, that level of detail is more than sufficient. On the other hand, if you are called upon to perform a post mortem examination to determine the cause of a performance problem that occurred on the network yesterday, more detail is apt to be required. By increasing the rate of data collection, a finer-grained picture of system activity emerges that may make it possible to perform a more detailed problem diagnosis. But this also increases the overhead proportionally—usually the most significant aspect of which is the increased overhead in post-processing, e.g., more disk I/O to the log file, and larger log files that must be stored and moved around the network. Since the accumulators involved are maintained continuously, the duration of the collection interval does not affect the amount of overhead in the measurement facility itself.
In our experience, summary data collected at one-minute intervals is adequate for diagnosing many performance problems. Problems that fall through the cracks at that level of granularity are probably so transitory that it may be very difficult to account for them anyway. Logging data at even more frequent intervals also means a proportionate increase in the size of your collection files. Still, there will be times when you need to know, and the only way to find out is to collect detailed performance or trace data at a fine level of granularity. For example, when you are developing an important piece of code and you want to understand its performance, collecting performance data at very high rates may be the only way to gather enough detail on short-running processes to be useful.
Where formal measurement facilities do not exist, it is sometimes possible to substitute diagnostic traces and other debugging facilities. Debugging facilities typically trap every instance of an event, and, thus, the data collection methodology they use is properly called event-oriented. There is an entry in a diagnostic trace every time an event occurs.
In Windows 2000, there are three event logs that contain information useful in a performance context: one used by the system; one used by applications, and one used for security. Events in the Windows 2000 log are timestamped so you can tell when something happened. When two events are related, you can easily tell how much time has elapsed between them. Sometimes this information is all you have to go on when you are reconstructing what happened. For instance, you can tell when someone logged onto the system, and that an application crashed or a connection was lost. Compared to a user’s recollection of what happened, of course, you can always rely on the accuracy of data recorded in the log.
Windows 2000 also contains a powerful operating system kernel tracing facility called the Windows Management Instrumentation, or WMI. Kernel events that can be traced include Active Directory commands, TCP commands, page faults, and disk I/O requests. WMI is designed to assist in the detailed analysis and diagnosis of performance problems. Because of the volume of trace data that can be generated and the overhead associated with widespread event tracing, this facility needs to be used cautiously. WMI is a new feature in Windows 2000, so there has not been much time to produce killer performance tools that exploit it. But this facility has a great future.
Another powerful tracing tool available in Windows 2000 is the Network Monitor driver. Network Monitors are known generically as “sniffers” after the brand name of the most popular hardware version. The Windows 2000 Network Monitor driver captures communications packets, tracing network activity without specialized hardware probes. While it is designed primarily for diagnosing network problems, the Network Monitor is useful in performance analysis. A fuller discussion of the Network Monitor and the use of Network Monitor traces to diagnose network performance problems is provided in Chapter 11.
Marshaling what are primarily debugging tools to solve performance problems can be difficult because debugging tools have different design criteria. In a debugging environment, the emphasis is on problem determination, not performance monitoring. Moreover, the overhead in running debuggers can be quite significant. In addition, many debuggers are intrusive, i.e., they actually modify the operating environment to obtain the diagnostic information they require. There is nothing more frustrating to a developer than a program that runs to completion successfully in debugging mode, but fails in its normal operating environment. The other problem with using debugging facilities like the event log is the lack of good data reduction tools to create the summarized statistical data used in performance analysis.
Somewhere between general-purpose performance monitors and debugging facilities are application-oriented code profilers designed to help developers understand the way their code operates. A profiler inspects a process as it executes and keeps track of which programming statements and routines are running. The developer then examines the results, using them to zero in on the portions of the program that execute for the longest time. If you are trying to improve the performance of an application, it is usually worthwhile to concentrate on the portion of the program that appears to be running the longest. Profilers can be integrated with compilers so that developers can resolve performance problems at the level of the module or statement. We will take a close look at these tools in Chapter 4.
Performance monitors excel at real-time monitoring. What happens when a performance problem occurs and you are not there to watch it? Unless you are capturing performance statistics to a file, you missed what happened and may not be able to reconstruct it. Even if you are attempting to watch what is going on in the system in real time, there is a limit to how many different variables you can monitor at once. Screen space is one limiting factor, and another is your ability to make rapid mental calculations as whatever phenomenon you are watching whizzes by. Capturing data to a file means you can pursue your post mortem examination under less stringent time constraints.
The Microsoft Windows 2000 System Monitor can log data to a file, which meets the minimum requirements for a performance database. Experienced performance analysts and capacity planners probably have in mind a more extensive facility to capture long-term trends spanning weeks, months, and even years. Commercial software to build and maintain performance databases originated from the need to charge back and finance the purchase of expensive mainframe equipment during the 70s and 80s. Historically, these performance databases were implemented using SAS, a so-called 4GL with strong statistical and charting capabilities. The disadvantage of SAS was that a working knowledge of the language was required to use these packages. As a result, a number of later performance databases were implemented using proprietary databases and reporting facilities. Recently, both types of software packages have been extended to Windows 2000.
Because they support a variety of analytic techniques, performance databases add a whole new dimension to the pursuit of Windows 2000 performance and tuning. With performance databases, the emphasis can shift from real-time firefighting to armchair studies that focus on strategic problems. It is possible to anticipate problems instead of merely reacting to them. In the right hands, performance databases can be extremely valuable tools for workload characterization, management reporting, and forecasting.
In general, the type of statistical analysis of computer performance measurement data that is performed is known as workload characterization. Analysts look for ways of classifying different users and developing a resource profile that describes a typical user in some class. Application developers might be lumped into one class and clerical employees in the accounting office into another based on patterns of computer usage. For instance, users in one class might run different applications than users in another—not too many people in the accounting department execute the C++ compiler. Even when they do use the same applications, they may use them in different ways. Workload characterization leads to the development of a resource profile, which associates an average user in one class with typical computer resource requirements: processing cycles, disk capacity, memory, network traffic, etc. Understanding the characteristics of your workload is a necessary first step in analyzing computer performance for any modeling study or other capacity planning exercise.
The performance data captured to a file is useless unless it is made visible to you and other interested parties through reporting. Some form of management reporting is usually required to provide your organization with a sense of what areas are under control and where problems exist. There are two effective approaches to day-to-day management reporting that parallel recognized management strategies:
Management by Objective
Management by Exception
Save detailed analysis reports for yourself—it is not likely that too many other people are interested in the statistical correlation between memory caching and the response time of particular SQL transactions.
To implement Management by Objective reports, you first have to develop management objectives. If the computer systems being monitored play an integral part in daily work, then your organization undoubtedly has goals for system availability and performance even if no one has expressed them explicitly. These goals or objectives need to be translated into something that can be quantified and measured on the computer. Then reporting can be developed that documents actual availability and performance levels against these objectives.
Management by Exception entails reporting on only those instances where performance objectives are not met. When faced with managing tens, hundreds, or thousands of Windows 2000 computers, the Management by Exception approach helps organizations cope with the potential volume of information they must sift through on a daily basis. Exception reporting alerts key personnel that something serious is afoot at a specific place and time. Much exception reporting attempts to encapsulate “expert” opinions and rules of thumb about which metrics and their values warrant concern. Since experts themselves often disagree, this reliance on received wisdom can be problematic, to say the least. One of our goals in writing this book is to empower you to perform your own “expert” analysis about what is important in your environment.
Exception alerting can also break down when too many exception thresholds are exceeded, with the result that beepers are ringing at the help desk at an annoying frequency. It is important to ensure that alerts truly reflect exceptional conditions that support personnel should be informed of immediately. One approach to managing alerts is statistical. An informational alert based on a 95th percentile observation in a representative baseline measurement can be expected to occur once every 20 measurement observations. If this alert is currently generated 10 times every 20 measurement intervals, then the current system is manifestly different from the baseline interval. One virtue of the statistical approach is that it can be easily calibrated to control the rate at which alarms occur. This approach effectively highlights differences over time, identifying gross changes in measurement observations in the absence of expert opinions about what such changes might mean empirically. The significance of the change is another question entirely, which, of course, may also be problematic.
Graphical reports are certainly the most effective way to communicate the technical issues associated with computer performance. A good reporting tool will allow you to manipulate the raw performance data you collected so that you can present it cogently. Figure 1-10 illustrates a typical management report where the data was massaged extensively prior to presentation. In this example, detailed information on per-process CPU consumption was summarized by hour, and then filtered so that only large consumers of CPU time over the interval are displayed. For the sake of accuracy, processes that were smaller consumers of CPU were grouped into an “Other” category. The stacked bar chart presents detailed and summarized information visually. The results are displayed against a Y axis scale that extends to 400% busy for a multiprocessing system containing 4 CPUs.
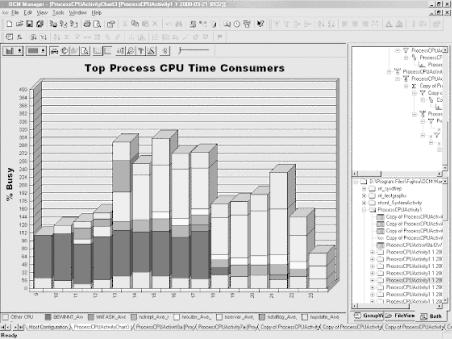
To support Management by Objective, your main tool is service-level reporting. Users care primarily about response time: how long it takes for the computer to generate a response once the user initiates an action, like clicking OK in a dialog box. Response time goals can be translated into service objectives that show the relationship between the user or transaction load and system responsiveness. Referring to the theoretical relationship predicted in queuing theory illustrated back in Figure 1-3, performance tends to degrade at an increasing rate as more and more users are added to the network.
In any organization where one group provides technical support and other systems management functions for others, formal service level agreements can be adopted. These communicate the anticipated relationship between load and responsiveness, and establish reasonableexpectations that as the load increases without a corresponding increase in hardware capacity, performance levels can be expected to decline. In these situations, regular reporting on compliance with service level agreements is obviously very useful. For example, when technical support is outsourced to a third party, reporting on service objectives is absolutely essential to assess contract compliance.
In the absence of formal service level agreements, informal ones based on user expectations usually exist. People can sense when the system they are accustomed to using is slower than normal, and when that happens, they complain. Whether or not formal service level agreements are in place, performance analysts are called upon to investigate the complaints and remedy them. What if the solution is to upgrade or add hardware and there is no money available to buy more equipment? Reporting on the current configuration’s capacity to achieve specific objectives can document the situation so that all parties can see where the problems lie.
As mentioned previously, for all its sophistication, Windows 2000 performance monitoring sorely lacks an orientation towards measuring and monitoring end-to-end transaction response time. Windows 2000 also lacks the ability to track the flow of work from client to server and back at a transaction level. When transaction response time cannot be monitored from end to end, transaction-based service level reporting is not possible. As the platform matures, no doubt this deficiency will be eliminated, but with few exceptions, this is the sorry state of affairs with most Windows 2000 applications today.
It is possible to monitor service levels in Windows 2000 at a somewhat higher level than the transaction with existing measurement facilities. Subsystems like Exchange and SQL Server do report the number of logged-on users, the total number of transactions processed in an interval, and other broad indicators of load. A weaker, but still effective form of service level reporting can be adopted that documents the relationship between the user load measured at this macro level and the ability to achieve service level objectives.
For Management by Exception, exception reporting is what you need. With all the metrics available from a typical Windows 2000 machine, it can be a challenge deciding which to report. Windows 2000 literally can supply data on more than a thousand different performance counters. Instead of reporting on the mundane, exception reporting details only events that are unusual or irregular and need attention.
Deciding which events are mundane and which are problematic is key. Frequently, exceptions are based on reporting intervals where measurements exceeded established threshold values. Chapter 2 summarizes the System Monitor counters and our recommended threshold value for exception reporting. Subsequent chapters provide the rationale behind these recommendations. For example, all intervals where processor utilization exceeds 90% busy can be reported. However, it makes better sense to generate an alarm based on an actual indicator of delay at the processor, not just crossing a utilization threshold. It is more informative to send an alarm when the processor utilization exceeds 90% and the processor queue length exceeds four threads per available processor.
The performance database is also the vehicle for longer-term storage of performance measurement data. Detailed data from log files can be summarized into daily, weekly, monthly, and even yearly files. Keeping data on resource utilization over longer periods of time makes it possible to examine trends and forecast future workload growth. A combination of forecasting techniques can be employed. In the absence of input from other parts of the business, current trends can be extrapolated into the future using simple statistical techniques such as linear regression.
If a correlation can be found between an application’s resource profile and underlying business factors, then historical forecasts can be amplified based on business planning decisions. An example of this business-element-based forecasting approach is an insurance claims system where activity grows in proportion to the number of policies in effect. You then need to develop a resource profile, for example, that shows the computer and network load for each insurance claim, on average. Once the average amount of work generated per customer is known, it is straightforward to relate the need for computer capacity to a business initiative designed to increase the number of customers.
Another popular technique worth mentioning is baselining. Baselining refers to the practice of collecting a detailed snapshot of computer and network activity and saving it to use later as a basis of comparison. This technique is particularly useful in network monitoring where the amount of detailed information that can be collected is enormous, and the structure of the data does not lend itself readily to summarization. Instead, performance analysts often choose to archive the entire snapshot. Later, when problems arise, a current snapshot is taken and compared to the baseline data in the archive. The comparison may show that line utilization has increased or the pattern of utilization has changed. It is good practice to periodically update the old baseline with current data, perhaps every six months or so.
The final class of performance tools in widespread use is predictive models. Predictive models can be used to answer “what if?” questions to assess the impact of a proposed configuration or workload change. You might be interested in knowing, for example, whether increasing the load on your Internet Information Server will cause the system to bog down, whether adding 50 more users to a particular LAN segment will impact everyone’s performance, and what kind of hardware you should add to your current configuration to maintain service objectives. Modeling tools for Windows 2000 include very detailed simulations of network traffic to very high-level approximations of transaction traffic in a distributed client/server database application.
The first warning about modeling is that these powerful tools are not for novices. Using modeling tools requires a broad foundation and understanding of both the underlying mathematics and statistics being applied, along with a good grounding in the architecture of the computer system being studied. In skilled hands, modeling tools can make accurate predictions to help you avoid performance and capacity-related problems. In the wrong hands, modeling tools can produce answers that are utter nonsense.
Modeling technology is divided into two camps, one that uses simulation techniques and one that uses analytic techniques (i.e., solves a series of mathematical equations). In simulation, a mathematical description of the computer system is created and studied. Transactions enter the system and are timed as they execute. If one transaction can block another from executing, that behavior can be modeled precisely in the system. This type of modeling is sometimes called discrete-event simulation because each transaction or component of a transaction is treated as a discrete element. Monte Carlo techniques refer to the use of random number generators to create workloads that vary statistically. Trace-driven simulations capture current workload traffic and play it back at different rates. At the conclusion of the simulation run, both detailed and summary statistics are output.
The advantage of simulation is that any computer system can be analyzed by someone who knows what they are doing. Commercially available modeling packages contain comprehensive libraries of model building blocks that are ready to use. The disadvantage of simulation is that the models that are constructed can be very complex. One part of the model can interact with another in ways that cannot easily be anticipated, and it is easy to produce behavior that does not match reality. Debugging a detailed simulation model can be very difficult.
Analytic modeling also begins with a mathematical description of the computer system, but there the similarity to simulation ends. Analytic modeling relies on mathematical formulas that can be solved. The trick in analytical modeling is knowing what formulas to use and knowing how to solve them. Fortunately for the rest of us, analytical models and their solutions can be programmed by mathematicians and packaged into solutions that can be applied by skilled analysts.
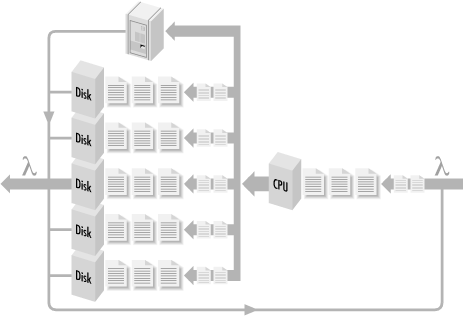
The analytic framework for computer performance modeling was pioneered in the 1960s with applications for both centralized computing and computer networks. For example, one of the leading architects of the ARPAnet networking project back in the 1970s, the forerunner of today’s Internet, was a renowned performance modeler named Dr. Leonard Kleinrock of UCLA. An approach known as the Central Server model was developed during that same period for modeling transaction processing workloads. The Central Server model represents a computer system as a series of interconnected resources, mainly the processor and the disks, as Figure 1-7 illustrated. Transactions enter the system by visiting the CPU, accessing one of the disks, returning to the CPU, etc., until the transaction is processed.
The Central Server model is a convenient abstraction, but of course it does not resemble the way real systems are put together. “Where is memory?” is a common question. The answer is that paging activity to disk as a result of memory contention is usually incorporated into the model indirectly as another disk I/O component. A model is intended only to capture the essence of the computer system, and it is surprisingly effective even when many details are conveniently ignored. The key in modeling, however, is that some details are too important to be ignored and mustbe reflected in the model if it is going to behave properly.
If the system is capable of processing multiple transactions concurrently, any single transaction is likely to encounter a busy resource where it must first wait in a queue before processing. Multiuser computer systems are inherently more complex to understand because of the potential for resource contention leading to queuing delays. If there are multiple users waiting for a resource, a combination of the scheduling algorithm and the queuing discipline determines which user is selected next for service. To understand the Central Server model it is necessary to know the rate at which transactions arrive at each of the different resources and how long it takes to process each request. The model can then be solved, using either analytical techniques or simulation, to calculate the total round-trip time of a transaction, including the time spent waiting for service in various queues, based on the scheduling algorithm and queuing discipline.
The best-known branch of analytical modeling for computer systems is known as mean value analysis (MVA). Jeff Buzen discovered an exact solution technique for the MVA equations generated by a Central Server model when he was working on his Ph.D. degree at Harvard University during the 1970s. Dr. Buzen later became one of the founders of BGS Systems, where he worked to commercialize the modeling technology he developed. This work led to the BEST/1 family of modeling tools. Now manufactured and distributed by BMC Software, BEST/1 was recently extended to support Windows 2000.
Several years ago, Dr. Buzen published a critique of the measurement data available in Windows NT and described how it should be enhanced to provide a better basis for modeling in the future. Reviewing Dr. Buzen’s critique, it is apparent that Windows 2000 does not yet support modeling studies of the rigor that Buzen envisions, whether simulation or analytic techniques are used. One of Dr. Buzen’s major laments is the lack of transaction-based response time reporting in Windows 2000, a point we touched upon earlier.
Over the years, the basic approaches to modeling computer systems pioneered in the 1960s and 1970s were refined and extended to more complex system configurations. Some of these extensions allow models to incorporate key details of the processor scheduling algorithms being used, represent fine details of the I/O subsystem, and incorporate network traffic. A few of these extensions are described here.
The simplest queuing discipline and one of the most common is FIFO, which stands for First In, First Out. Most computer operating systems implement priority queuing at the processor allowing higher-priority work, such as interrupt processing, to preempt lower-priority tasks. Windows 2000 implements priority queuing with preemptive scheduling at the processor based on priority levels that are adjusted dynamically by the OS. There are a number of ways to approach modeling priority queuing.
Priority schemes are just one of the issues facing detailed disk I/O models. SCSI uses a fixed-priority scheme based on device addresses to decide which of multiple requests will gain access to the shared SCSI bus. SCSI disks that support tagged command queuing implement a shortest-path-first queuing discipline that schedules the next I/O operation based on which queued request can be executed quickest. Other key I/O modeling issues concern the use of disk array technology and RAID, and the ubiquitous use of caching to improve disk performance.
Both local-area networking (LAN) and wide-area networking (WAN) technology introduce further complications. Ethernet uses a simple, non-arbitrated scheme to control access to shared communications media. When two or more stations attempt to transmit across the wire at the same time, a collision occurs that leads to retransmission. Most high-speed IP routers make no provision for queuing. When they become overloaded, they simply drop packets, which forces the TCP software responsible for reliable data communication to retransmit the data.
It is possible to extend the concepts honed in developing the Central Server model to Windows 2000 networks and distributed systems. Figure 1-11 shows a scheme proposed by Dr. Mike Salsberg of Fortel that extends the Central Server model to networks and client/server systems. From the standpoint of the client, there is a new I/O workload that represents remote file I/O. The delays associated with remote file access are then decomposed into network transmission time, remote server processing, and remote server disk I/O activity. Salsberg’s approach captures the bare essentials of distributed processing, which he proposes to solve using conventional simulation techniques.
Modeling studies take one of two basic forms. One route is to study a system that is currently running to predict performance in the future when the workload grows or the hardware characteristics change. A baseline model of the current system is built and validatedagainst the actual system. In validation, the model is prepared and then solved to obtain predicted values, such as the utilization of various resources or the predicted transaction response time. The model outputs are then compared to actual measurements of the system under observation. The model is valid for prediction when the predicted values are approximately equal to the observed values. Obviously, it is not safe to use an invalid model for prediction, but the sources of error in an invalid model can be very difficult to track down.
The second form of modeling studies is for a system under construction. Instead of measurements from an actual running system, there is instead only a set of specifications. These specifications are translated into a resource profile of the proposed system, and then the model is built in the usual way and solved. Obviously, the intermediate step where specifications are transformed into resource profiles of the proposed workload is prone to errors. However, as the system is actually being built, it should be possible to generate successively more accurate models based on collecting actual measurements from running prototype code. Incorporating modeling studies into application development projects is also known as software performance engineering. Practitioners who rely on software performance engineering techniques early and often during application development have a much better chance of success than those who ignore performance concerns until it is too late.
Get Windows 2000 Performance Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

