Chapter 4. Unit Tests
The hardest unit test to write is the first one. That first test requires a nontrivial amount of boilerplate. It also requires that you answer some initial questions. For example, should you use an existing unit test framework, or roll your own? What about an automated build process? How about collecting, displaying, and tracking unit test code coverage? Developers are already barely motivated to write any unit tests, and having to deal with these legitimate questions only makes the process more painful.
Unfortunately, there is no magic bullet when it comes to unit testing. Developers will need to put in the work to get the rewards. Fortunately, the rewards are substantial. Starting with keeping your paycheck and ending with maintainable working code, unit tests provide a lot of value. As a developer, this is typically the only formal testing that is required; luckily, unit testing does not have to be difficult.
A Framework
Just as you would not write any JavaScript without using a sane framework, you cannot write any unit tests until you decide which testing framework to use. Frameworks provide a lot of the boilerplate you do not need to re-create: test suite/case aggregation, assertions, mock/stub helpers, asynchronous testing implementation, and more. Plenty of good open source testing frameworks are available. I will use YUI Test in this chapter, but of course all good practices are applicable across all frameworks—only the syntax (and maybe some semantics) differs.
The most important part of any testing framework is aggregating the
tests into suites and test cases. Test suites and test cases are spread
across many files, with each test file typically containing tests for a
single module. A best practice is to group all tests for a module into a
single test suite. The suite can contain many test cases, with each case
testing a small aspect of the module. By using setUp and tearDown functions provided at the suite and test case levels, you can easily
handle any pretest setup and post-test teardown, such as resetting the
state of a database.
An equally important part of unit testing is assertions. Assertions are the actual tests applied to expected versus received values. This is where the rubber meets the road: is the value under test what you expect it to be? YUI Test provides a full set of assertion functions whose results are tracked by the framework so that when all the tests are done you can easily see which tests passed and which failed.
Nice-to-have framework functionality, such as asynchronous testing, forced failures, ignorable tests, and mock object support, are also provided by the YUI Test framework, which makes it a nice, full-fledged unit testing toolbox.
A final bonus are the events that YUI Test throws at various times during unit test execution and the various output formats that YUI Test supports for test results; these enable you to integrate unit test runs into an automated build.
One final note: the code being tested does not have to be written using YUI to utilize the YUI Test framework. You can download the YUI Test framework from here.
YUI Test is great for client-side JavaScript, and it can be used for server-side JavaScript unit testing too. However, two popular, behavior-driven development (BDD) testing frameworks are also available for server-side testing: Vows and Jasmine. The idea behind BDD is to use “regular language” constructs to describe what you think your code should be doing, or more specifically, what your functions should be returning. Make no mistake: these are unit test frameworks with 100% more fanciness. Most importantly, they also both support asynchronous tests and can be installed and run easily via the command line. Regardless of whether you buy into the BDD nomenclature, these frameworks provide very nice ways to group, execute, and report client- and server-side JavaScript unit tests.
Let’s Get Clean
You have to write unit tests, so quit messing around and write some. We will start with this code:
function sum(a, b) {
return a + b;
}Unit tests are all about isolating code and writing tests that only
test the chunk of code under test, while factoring out everything else. It
sounds simple enough, and with a function such as sum (as shown in the preceding code) it is
simple indeed:
YUI({ logInclude: { TestRunner: true } }).use('test', 'test-console'
, function(Y) {
var testCase = new Y.Test.Case(
{
name: 'Sum Test'
, testSimple: function () {
Y.Assert.areSame(sum(2, 2), 4
, '2 + 2 does not equal 4?');
}
}
);
// Load it up
Y.Test.Runner.add(testCase);
(new Y.Test.Console({
newestOnTop: false
})).render('#log');
// Run it
Y.Test.Runner.run();
});This is the simplest test case possible, so ensure that you can wrap
your head around it. A new Y.Test.Case
is created, and it is given a name and a set of test functions. Each
function is run in turn with the assumption that one or more Y.Assert functions are called to actually test
something. The test case is loaded into the local Y.Test.Runner and then all tests are
executed.
Given code to test, and code to test that code, we are unfortunately still not quite there, as we need to actually run the tests and view the results. In some server-side-only testing frameworks (e.g., Vows), we would be finished if we were testing server-side-only code. But client-side JavaScript requires an HTML file to tie it all together:
<html>
<head>
<title>Sum Tests</title>
</head>
<body>
<div id='log' class='yui3-skin-sam'></div>
<script src='http://yui.yahooapis.com/3.7.3/build/yui/yui-min.js'>
</script>
<script src='sum.js'></script>
<script src='sumTests.js'></script>
</body>
</html>This HTML ties together YUI3 Test, the code being tested, and the
test code. Loading this HTML into a browser will run all the tests and
output the test results to log
<div>. This represents all the pieces necessary to run
client-side unit tests: the code, the test code, and some HTML glue to tie
it all together. Load it up in a browser and you will see something
similar to Figure 4-1.
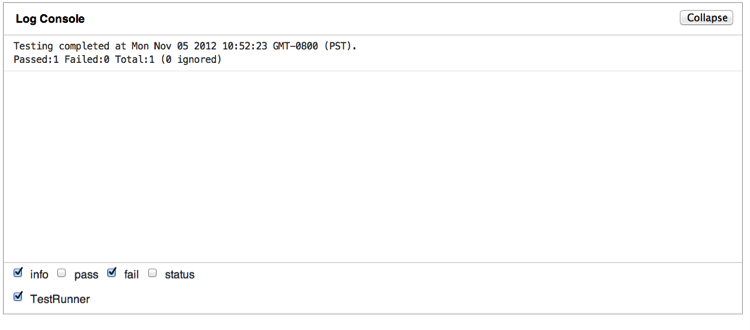
Some pieces are still missing—namely, code coverage and command-line test execution. We will have to revisit those pieces later; first, we must nail down how to write good tests. Fortunately, later we will be able to add those missing pieces for free, so for now let’s concentrate on the tests themselves.
Writing Good Tests
Unfortunately, we are rarely called upon to test functions, such as
sum, that have no side effects and
whose return values are solely a function of their parameters. But even a
function as simple as sum has gotchas.
What happens if you pass in two strings? What if the parameters are a
string and an integer? How about null, undefined, or NaN values? Even the
simplest function requires several cases to really run it through its
paces.
Even worse, the single unit test metric, code coverage, happily reports 100% code coverage from our single unit test. It’s obvious that the single test is not an effective test for the function, but a manager looking at a code coverage report may erroneously conclude that since this function has 100% code coverage it is therefore fully tested and reliable. While unit tests provide value, and code coverage metrics can measure that value to some extent, they obviously do not and cannot tell the whole story.
So, what makes a good unit test? Code coverage, like it or not, is part of the equation. The other part of
the equation is the edge and nonedge cases of the parameters. Given that
the function’s dependencies are mocked out (and are unit-tested themselves
to be sane), the parameters and external object stubs are the only knobs
you, as a unit tester, have to twist. As an example, let’s use our old
friend the sum function. This function
takes two parameters. Each parameter can be one of six types (number,
string, object, undefined, null, or Boolean)—so the perfect set of unit
tests will test all combinations of these. But what will it test for? What
does it mean, for example, to add null and undefined?
With these questions in mind, perhaps the two most important factors of a good unit test are isolation and scope. As we will see in the following subsections, isolation and scope are closely related.
Isolation
A unit test should load only the bare minimum needed to actually run the test. Any extra code may influence the test or the code being tested, and can cause problems. Typically, unit tests exercise a single method. That method is probably part of a file containing a class or module. That physical unit of code will have to be loaded. Unfortunately, not only does the method under test probably depend on other functions and methods in that file, but it likely has external dependencies (i.e., dependencies in another file) as well.
To avoid loading external dependencies, we can use mocking, stubbing, and test doubles. I will provide details about these strategies later, but for now it’s important to note that they are all used in an attempt to keep the code under test isolated from other pieces of code as much as possible.
Unit testing tests the smallest amount of code possible—a method, and nothing else. For that to be feasible, your test code must strive to isolate that method as much as possible.
Scope
The scope of a unit test—what your test is actually testing—must be small. A fully isolated method allows the scope of the test to be as small as possible. Good unit tests test only one method; they should not rely on other methods being called or used. At the bottom level of a single unit test, a single assertion should rely on only the method being tested and any mocks, stubs, or doubles needed for the method to work.
Unit tests are cheap; you should have a lot of them. Just as a “regular” method should not try to do more than one thing, neither should a unit test. Try to test and load the minimal amount of code necessary to successfully execute a unit test for your application. Unit tests typically focus at the level of a single function or method; however, it is up to you to determine the “unit” size that makes the most sense for your testing.
Defining Your Functions
Before we go into further detail, we need to take a step back. It is impossible to write good unit tests unless you know exactly what you are testing and what the result should be. What defines what the result should be? The tests? Having to read and understand tests (if they even exist) to discern how a function should work is not ideal. The comments define what the result should be. This may not be ideal either, if the comments are not kept up to date. So do you have two places to keep up to date—the tests and the comments? Yes, you do. Utilizing test-driven development (TDD) to write tests before code does not obviate the need for comment blocks above functions.
Comment blocks
Our sum function is
woefully uncommented, so in this vacuum we have
no idea what this function should do. Should it
add strings? Fractions? Null and undefined? Objects? The function must
tell us what it does. So let’s try again using Javadoc syntax:
/*
* This function adds two numbers, otherwise return null
*
* @param a first Number to add
* @param b second Number to add
* @return the numerical sum or null
*/
function sum(a, b) {
return a + b;
}Now we can actually test this function because we know exactly what to test for: numbers. You cannot write a good unit test for an ill-defined function. It is impossible to write a good unit test in a vacuum. The first rule to writing a good unit test is to have a fully defined function specification.
Does this function actually do what it says? That is what unit tests are for—to determine whether a function behaves properly. And the first step in that regard is to define the function’s “proper” behavior. Comments are crucial, and comment bugs are extremely dangerous for both testers and maintainers. Unfortunately, there are no tests to automatically determine whether comments have bugs, but as with code coverage, using a tool such as jsmeter will at least alert you to functions without any comments and to the amount of comments in your code. After code size, the second most telling indicator of bugs in code is missing or incorrect comments, so not only should you have comments, but it is very important that the comments are correct [for more details on this, read this paper].
Ideally, you (or someone else) should be able to write unit tests simply from reading the function comments. These comments will get published from either JSDoc or YUIDoc and Rocco, so make the comments helpful. It is also critical that the function definition is kept up to date. If the parameters or return value change, make sure the comment is also updated.
Writing tests before code, as TDD advocates, may relieve some of the burden of proper commenting. You can utilize the test functions as comments instead of comment blocks, since tests (unlike comments) must stay up to date; otherwise, they will fail. Even if you write tests before any code, a well-commented function header is still beneficial for future maintainers to understand at a glance what your function is up to. Further, having published easily accessible documentation helps in code reuse by allowing other developers to find your code more easily and perhaps use your function instead of writing their own version of that functionality. Other developers need an easily browsable interface to your public methods to help ensure reusability.
Tests
If you write your tests first, they can also be used in the specification for how your functions (or code under test) should function. Since the tests must be maintained to remain in sync with the code under test (otherwise, the tests will fail!), the tests have the final say regarding what the code does, not the comments. In theory, although the comments may fall out of sync, the tests will not, so the tests are to be trusted over the comments. I do not believe you have to fall into this trap: keeping comment blocks up to date should be a normal, standard part of your development practices. The next person to maintain your code will have a much easier time reading your comments while reading your code instead of having to context-switch to another file somewhere else to grok your test code as well.
Positive Testing
Now that we have a well-defined function, let’s test the “correct” case. In
this instance, we will pass in various flavors of two numbers. Here are
the Y.Assert statements:
Y.Assert.areSame(sum(2, 2), 4, "2 + 2 does not equal 4?"); Y.Assert.areSame(sum(0, 2), 2, "0 + 2 does not equal 2?"); Y.Assert.areSame(sum(-2, 2), 0, "-2 + 2 does not equal 0?"); Y.Assert.areSame(sum(.1, .4), .5, ".1 + .4 does not equal .5?");
The preceding code is not earth-shattering; it just tests the basic cases, which is how this function will be called 99% of the time (answering the question, “Does the function do at a very basic level what it claims it does?”). These tests should be the easiest part of your testing, passing in good data and receiving good data back. These should be your first set of tests as these cases are by far the most common. This is where unit tests catch the most bugs; functions that do not fulfill their contract (from the function definition) are obviously broken.
Positive tests should be the first unit tests you write, as they provide a baseline of expected functionality upon which negative and bounds testing can be built. Here, you want to test all the common cases and permutations of how the function is actually supposed to be called and used.
Negative Testing
Negative testing will help locate those hard-to-find bugs typically manifested by the code blowing up somewhere far away from where the bug actually is. Can the code handle values it is not expecting? These tests pass in parameters not expected or wanted by the function under test and ensure that the function under test handles them properly. Here is an example:
Y.Assert.areSame(sum(2),null));
Y.Assert.areSame(sum('1', '2'), null));
Y.Assert.areSame(sum('asd', 'weoi'), null));This test quickly reveals that our sum function is not behaving properly. The key
is that we know what “properly” is for the sum function: it should be returning null for non-numbers. Without the comment
block describing this function’s behavior, we would have no idea whether
this function was misbehaving.
Negative testing will typically not find the same number of bugs as positive testing, but the bugs negative testing does find are usually nastier. These are the hard-to-find bugs when something is not working at a much higher level. They test corner cases, or cases when unexpected things happen. In such situations, what does the function do? Besides meeting its contract, will it behave sanely with unexpected input or state?
Code Coverage
Code coverage is a measure, typically a percentage, of the lines of code executed versus not executed. It is generally used to view how much code is touched by any given test. More tests can be written to “cover” more uncovered lines of code, typically to a certain percentage. We will discuss code coverage in more depth in Chapter 5, but for now, suffice it to say that code coverage is another key to effective unit tests. While code coverage can be misleading when the percentages are high, it is much more applicable (and scary) when the covered percentage is low. A unit test with less than 50% code coverage is a red flag; 60% to 80% code coverage is the sweet spot, and anything over 80% is gravy. The law of diminishing returns can apply to unit testing when trying to get unit tests above 80% coverage. Remember, unit testing is not the only arrow in your QA quiver, but it is one of the few QA metrics that developers are responsible for. In Chapter 5, we will look at how to measure and visualize code coverage.
It is important that code coverage information be generated automatically, without any human intervention. Once people get involved, things deteriorate rapidly. The process for generating code coverage must be seamless.
Real-World Testing
Unfortunately, while it’s an ideal to aim for not all functions are as cut and dried as the sum function. Yet note that even a one-line,
zero-dependency function is not as easy to unit-test properly as you might
think. This again demonstrates the difficulty of unit testing in general
and JavaScript unit testing in particular: if a one-line function has this
many gotchas, what about real-world functions?
Dependencies
We touched on the problem with dependencies earlier in the book. Almost every function has external dependencies that unit testing does not want to test. Unit testers can extract dependencies by utilizing mocks and stubs. Note that I said, “Unit testers can extract” here, because the author of the code under test also has several tools to extract dependencies from code, as detailed in Chapter 2. Once all of those avenues have been exhausted, the burden falls on the unit tests to isolate the code in question for testing.
Use of command query separation highlights the differences between mocks and stubs: mocks are used for commands and stubs are used for queries.
Doubles
Test doubles is a generic term for objects used by tests to stub or mock out dependencies (similar to stunt doubles in movies). Doubles can act as stubs and mocks at the same time, ensuring that external methods and APIs are called, determining how many times they have been called, capturing called parameters, and returning canned responses. A test double that records and captures information about how methods were called is called a spy.
Mock objects
Mock objects are used to verify that your function is correctly calling an external API. Tests involving mock objects verify that the function under test is passing the correct parameters (either by type or by value) to the external object. In the command query world, mocks test commands. In an event hub world, mocks test events being fired.
Take a look at this example:
// actual production code:
function buyNowClicked(event) {
hub.fire('addToShoppingCart', { item: event.target.id });
}
Y.one('#products').delegate('click', buyNowClicked, '.buy-now-button');
/* ... and in your test code: */
testAddToShoppingCart: function() {
var hub = Y.Mock();
Y.Mock.expect(hub,
{
method: "fire"
, args: [ "addToShoppingCart" , Y.Mock.Value.String]
}
);
Y.one('.buy-now-button').simulate('click');
Y.Mock.verify(hub);This code tests the flow of a Buy Now button (an element that
contains the buy-now-button CSS
class). When that button is clicked, the addToShoppingCart event is expected to be
fired with a string parameter. Here, the event hub is mocked out and
the fire method is expected to be
called with a single string parameter (the ID of the Buy Now
button).
Stubs
Stubs are used to return canned values back to the tested function. Stubs do not care how the external object’s method was called; stubs simply return a canned object of your choosing. Typically this object is something the caller expects for a set of test cases for positive testing and an object with unexpected values during another set of tests for negative testing.
Testing with stubs requires you to substitute the real objects with your stubbed-out replacements, whose only joy in life is to return a canned value to keep the method under test moving along.
Take a look at the following code:
function addToShoppingCart(item) {
if (item.inStock()) {
this.cart.push(item);
return item;
} else {
return null;
}
}One way to test this is to stub out the item.inStock method to test both paths
through the code:
testAddOk: function() {
var shoppingCart = new ShoppingCart()
, item = { inStock: function() { return true; } }
, back = shoppingCart.addToShoppingCart(item)
;
Y.Assert.areSame(back, item, "Item not returned");
Y.ArrayAssert.contains(item, shoppingCart.cart, "Item not in shopping cart"); 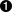 }
, testAddNok: function() {
var shoppingCart = new ShoppingCart()
, item = { inStock: function() { return false; } }
, back = shoppingCart.addToShoppingCart(item)
;
Y.Assert.isNull(back, "Item returned is not null");
Y.ArrayAssert.isEmpty(shoppingCart.cart, "Cart not empty!");
}
}
, testAddNok: function() {
var shoppingCart = new ShoppingCart()
, item = { inStock: function() { return false; } }
, back = shoppingCart.addToShoppingCart(item)
;
Y.Assert.isNull(back, "Item returned is not null");
Y.ArrayAssert.isEmpty(shoppingCart.cart, "Cart not empty!");
}-
YUI Test provides a nice set of convenience assertions for testing arrays (more details are here).
This testing captures both branches of the function by stubbing
out the item object. Of course,
it’s not just parameters that can can be stubbed; typically, all
external dependencies are stubbed or mocked out.
Spies
A test spy wraps the “real” object, overriding some method and letting others pass through. A spy is typically attached to a real object and intercepts some method calls (sometimes even only intercepting method calls with specific parameters) to return a canned response or keep track of the number of times a method has been called. Nonintercepted methods are simply handed off to the real object for normal processing. Spies are great for objects that have some “heavy” operations that you want to mock out and lighter-weight operations that the actual object can easily handle itself.
You are not limited to any of these doubles in your tests! If you need to create a double that has some features of a mock and some of a stub, go for it! Do you want to track how many times an external function was called? Use a spy! Doubles are typically specific to a test or set of tests and are not as reusable as a more limited mock or stub, but in many cases they are necessary for proper testing.
Here is a snippet of test code using a spy for our sum function:
, testWithSpy: function() {
var origSum = sum
, sumSpy = function(a, b) {
Y.Assert.areSame(a, 2, 'first arg is 2!');
Y.Assert.areSame(a, 9, 'second arg is 9!');
return origSum(a, b);
}
;
sum = sumSpy;
Y.Assert.areSame(sum(2, 9), 11
, '2 + 9 does not equal 11?');
sum = origSum; // reset it (or use teardown)
}This spy is local to this test; it simply verifies that the passed arguments were expected. A spy does not need to call the underlying “real” method if it is a heavyweight operation (perhaps a network call), and instead can just return canned data, both expected and unexpected (e.g., simulating a network failure).
The Jasmine test framework has good support for creating doubles and spies. We will get to play with those features a bit later in this chapter.
Asynchronous Testing
JavaScript relies heavily on events. Asynchronous testing involves suspending the testing flow and waiting for an event to fire, then resuming the flow in the event handler, probably with an assert or two thrown in for good measure.
Using YUI Test
Using YUI Test, an asynchronous test looks like this:
testAsync: function () {
var test = this, myButton = Y.one('#button');
myButton.on('click', function() {
this.resume(function() {
Y.Assert.isTrue(true, 'You sunk my battleship!');
});
}
myButton.simulate('click');
this.wait(2000);
}This code will simulate a button click and wait two seconds. If the test is not resumed by then, the test will fail; otherwise; the test is resumed and a (hopefully successful) assertion is tested. Clearly, we can do far more interesting things than simulating a click on a button and verifying that a handler was called.
If your code does a lot of Cascading Style Sheets (CSS) manipulation in response to events, asynchronous testing is the way to go. However, for any hardcore UI testing, integration testing using a tool such as Selenium is preferable to unit tests, which can be more brittle and incomplete in these situations. Further, not all DOM events can be simulated; in those cases other types of testing are required.
Regardless, asynchronous testing is necessary when testing event-based code such as the following:
hub.on('log', function(severity, message) {
console.log(severity + ': ' + message);
});Testing this code requires mocking out the global console object (it’s a command, not a
query):
console = Y.Mock();
testLogHandler: function () {
var sev = 'DEBUG', message = 'TEST';
Y.Mock.expect(console, { method: log
, arguments: [ sev, message ] });
hub.fire('log', sev, message);
this.wait(function() {
Y.Mock.verify(console);
}, 1000);
}We can use a “real” event hub, as we are not testing hub
functionality here. This test merely verifies that the mocked-out
object’s log method was called with
the expected arguments, which is what mock objects are for: testing
that the interface is being used correctly.
Running Tests: Client-Side JavaScript
Once you have written a set of test cases and event-aggregated them into a set of test suites, then what? Running tests in your browser by loading up the HTML glue code is amusing and necessary while developing your code, but it does not lend itself at all to automation. There are several strategies that you can use to make your tests part of an automated build process.
PhantomJS
PhantomJS is a headless WebKit browser—that is, a browser that is accessed programmatically. This is an excellent sandbox within which to run unit tests without having a browser up and running somewhere. Note that unit tests typically focus on core functionality abstracted from the UI. Obviously, PhantomJS cannot and does not attempt to handle all the various CSS levels as they are implemented in each browser (although it is very up to date with most standards). Testing fancy CSS or browser-specific CSS requires that browser, and it is unclear whether a unit test is even a valid way to test this type of functionality. That being said, PhantomJS/WebKit can handle a ton of modern features; only the latest cutting-edge CSS 3D transformations, local storage, and WebGL are not supported. Of course, what is supported all depends on the version of WebKit used when building PhantomJS, which is constantly evolving and adding new features.
PhantomJS no longer requires an X server running anywhere, so
setup cannot be easier! Simply download the binary for your operating
system and you are ready to go. You can also compile phantomjs from source, but prepare to wait
awhile, as a good chunk of Qt must be compiled as well. The actual
phantomjs binary is tiny compared to
the giant chunk of required Qt.
Here is our complex JavaScript file to test in sum.js:
YUI().add('sum', function(Y) {
Y.MySum = function(a, b) { return a + b };
});Once you are set up, running your YUI tests through PhantomJS is
easy with one little trick. Here again is our HTML glue for the sum tests, with a single addition:
<html>
<head>
<title>Sum Tests</title>
</head>
<body class="yui3-skin-sam">
<div id="log"></div>
<script src="http://yui.yahooapis.com/3.4.1/build/yui/yui-min.js">
</script>
<script src="sum.js"></script>
<script src="phantomOutput.js"></script>
<script src="sumTests.js"></script>
</body>
</html>And here’s another JavaScript file to be loaded, phantomOutput.js, which defines a small YUI
phantomjs module:
YUI().add('phantomjs', function(Y) {
var TR;
if (typeof(console) !== 'undefined') {
TR = Y.Test.Runner;
TR.subscribe(TR.COMPLETE_EVENT, function(obj) {
console.log(Y.Test.Format.JUnitXML(obj.results));
});
}
});The sole purpose of this module is to output test results, in JUnit XML format, to the console upon test completion (YUI supports other output formats that you can use instead; use whatever your build tool understands—for example, Hudson/Jenkins understands JUnit XML). This dependency must be declared in your test file. Here is sumTests.js:
YUI({
logInclude: { TestRunner: true },
}).use('test', 'sum', 'console', 'phantomjs', function(Y) {
var suite = new Y.Test.Suite('sum');
suite.add(new Y.Test.Case({
name:'simple test',
testIntAdd : function () {
Y.log('testIntAdd');
Y.Assert.areEqual(Y.MySum(2 ,2), 4);
},
testStringAdd : function () {
Y.log('testStringAdd');
Y.Assert.areEqual(Y.MySum('my', 'sum'), 'mysum');
}
}));
Y.Test.Runner.add(suite);
//Initialize the console
var yconsole = new Y.Console({
newestOnTop: false
});
yconsole.render('#log');
Y.Test.Runner.run();
});PhantomJS will pick up the console output and can then persist it
to a file for later processing. Unfortunately, including the phantomjs module in your tests is not ideal.
In Chapter 8 we will make this process more
dynamic.
Here is the PhantomJS script to grab the test output:
var page = new WebPage();
page.onConsoleMessage = function(msg) {
console.log(msg);
phantom.exit(0);
};
page.open(phantom.args[0], function (status) {
// Check for page load success
if (status !== "success") {
console.log("Unable to load file");
phantom.exit(1);
}
});That was quite simple! This PhantomJS script takes the URL to the “glue” HTML test file as the only command-line parameter, loads it up, and, if successful, waits to capture the console output. This script just prints it to the screen, but if you’re running it as part of a larger process you can redirect the standard output from this script to a file, or this PhantomJS script itself can write the output to a file.
PhantomJS has no access to the JavaScript running on the loaded page itself, so we utilize the console to pass the test output from the page being loaded back to PhantomJS-land, where it can be persisted.
Here is how I ran the whole thing against some tests for a sample Toolbar module in the JUTE repository (more on that later) on my Mac:
% phantomjs ~/phantomOutput.js sumTests.htmlHere is the output I received (although not fancily formatted):
<?xml version="1.0" encoding="UTF-8"?>
<testsuites>
<testsuite name="simple test" tests="2" failures="0" time="0.005">
<testcase name="testIsObject" time="0"></testcase>
<testcase name="testMessage" time="0.001"></testcase>
</testsuite>
</testsuites>This is the JUnit XML output for the two unit tests that were executed.
Adding snapshots, so you can actually see what happened, is easy. Here is the whole script with snapshot support added. The only difference is that here we “render” the output after any console output:
var page = new WebPage();
page.viewportSize = { width: 1024, height: 768 };
page.onConsoleMessage = function(msg) {
console.log(msg);
setTimeout(function() {
page.render('output.png');
phantom.exit();
}, 500);
};
page.open(phantom.args[0], function (status) {
// Check for page load success
if (status !== "success") {
console.log("Unable to load file");
phantom.exit(1);
}
});First I set the viewport size, and after getting the test results the page is rendered into a PNG file (this needs to be wrapped in a timeout block to give the render step time to finish before exiting). This script will generate snapshots after each test. PhantomJS can also render PDF and JPG files. Figure 4-2 shows our lovely snapshot.
Mighty beautiful! By default, PhantomJS backgrounds are
transparent, but we can clearly see the YUI Test output as it went to
the <div id="log">
element in the HTML.
But wait! What about those awesome log messages YUI is outputting
to the logger? We want to capture those too! We need to revisit the
phantomjs YUI module:
YUI().add('phantomjs', function(Y) {
var yconsole = new Y.Console();
yconsole.on('entry',
function(obj) {
console.log(JSON.stringify(obj.message));
}
);
if (typeof(console) !== 'undefined') {
var TR = Y.Test.Runner;
TR.subscribe(TR.COMPLETE_EVENT, function(obj) {
console.log(JSON.stringify(
{ results: Y.Test.Format.JUnitXML(obj.results) }));
});
}
}, '1.0', { requires: [ 'console' ] });
The biggest addition is the Y.Console object we’ve created solely to
capture YUI Test’s logging messages. Listening for the entry event gives us all the messages in an
object, which we stringify using JSON (note that the JSON object is
included in WebKit; this JavaScript is running the PhantomJS WebKit
browser).
Now two types of messages emitted to the console are passed “back” to our PhantomJS script: logging messages and the final JUnit XML results. Our PhantomJS server-side code must keep track of both types of messages.
Here is the first message:
{
"time":"2012-02-23T02:38:03.222Z",
"message":"Testing began at Wed Feb 22 2012 18:38:03 GMT-0800
(PST).",
"category":"info",
"sourceAndDetail":"TestRunner",
"source":"TestRunner",
"localTime":"18:38:03",
"elapsedTime":24,
"totalTime":24
}It’s not too exciting by itself, but the entire list of messages together is a great resource to dump into a log for each test suite. Details of message properties are available at the YUI website.
Here is the updated onConsoleMessage function from the PhantomJS
script (that function is the only thing that has changed in the
script):
page.onConsoleMessage = function(msg) {
var obj = JSON.parse(msg);
if (obj.results) {
window.setTimeout(function () {
console.log(obj.results);
page.render('output.png');
phantom.exit();
}, 200);
} else {
console.log(msg);
}
};Besides parsing the JSON from the console output, the script now
only exits when it gets the final test results. Of course, you need to
ensure that nothing else (such as your tests or the code you are
testing) is writing to console.log!
You could also get crazier and take a snapshot before/during/after each
test to view the actual test progress (you will know what stage each
test is at due to the log messages).
PhantomJS is an excellent way to run your unit tests during an automated build process. During a build, you can feed this script a list of files/URLs for PhantomJS to execute in the WebKit browser. But you should also run your unit tests in “real” browsers at some point before pushing code out to your production environment. We’ll look at that next.
Selenium
Using Selenium Remote Control (RC) or Selenium2 (WebDriver), you can farm out your unit tests to real browsers: either a browser running on your local machine or one running remotely. Running the Selenium JAR on a machine with Firefox, Safari, Chrome, or IE installed, you can easily launch your unit tests in that browser and then capture the results to be persisted locally. Selenium2/WebDriver is the preferred/current tool provided by Selenium; do not choose Selenium RC if you are just getting started with Selenium.
Here is how it works. Start Selenium somewhere where the browser in which you want to run your tests is installed. To do this you must download the latest version of the Selenium JAR from the SeleniumHQ website. You want the latest version of the Selenium server, which at the time of this writing is version 2.28. Now fire it up:
% java -jar ~/selenium-server-standalone-2.28.0.jarThis will start the Selenium server on the default port of 4444.
You will need to reach this port from whatever machine you run the
Selenium client on, so keep that firewall open. You can change this port
with the -port option.
Now that the Selenium server is up and running, you need to tell it to open a browser and fetch a URL. This means you need a web server running somewhere to serve your test files. It doesn’t need to be anything fancy—remember, these are only unit tests; you are not serving up your entire application. However, it is easiest to have your test code under the same document root as your production code to make serving the tests easier during development. Keep in mind that you probably do not want to actually push your tests into production. Therefore, a nice setup is a test directory under your document root containing a mirror of your production directory structure with the tests for the corresponding modules in the same place in the mirrored hierarchy. When bundling for production, simply do not include the test directory. The structure looks like Figure 4-3.
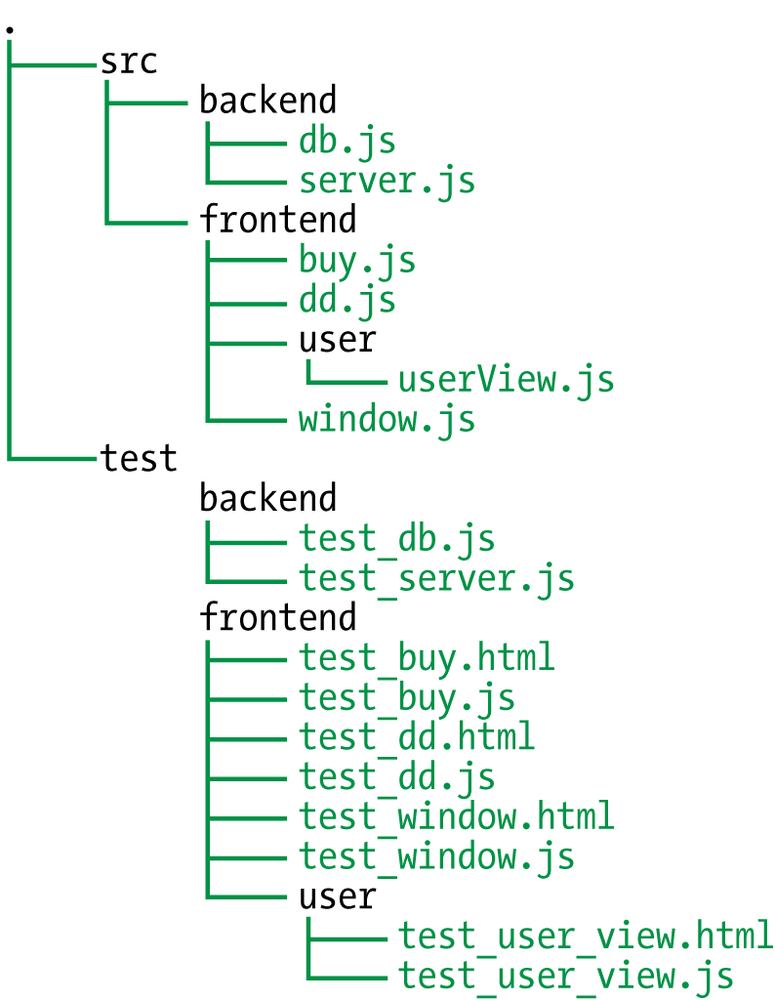
As you can see in Figure 4-3, the test tree mirrors the src tree. Each leaf in the test hierarchy contains (at least) two files: the JavaScript tests and the HTML glue file for those tests. The HTML glue file for test_user_view.html looks like this:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html lang="en">
<head>
<meta http-equiv="Content-Type"
content="text/html; charset=ISO-8859-1">
<title>User View Tests</title>
</head>
<body class="yui3-skin-sam">
<h1>Test User View</h1>
<div id="log" />
<script src="http://yui.yahooapis.com/3.4.0/build/yui/yui-min.js">
</script>
<script src="../../../src/frontend/user/userView.js"></script>
<script src="test_user_view.js"></script>
</body>
</html>This HTML uses relative paths to pull in the file/module to be tested: user_view.js. When the local web server serves, this file all the local files are found and the tests are run.
We now have a URL to feed to Selenium so that the remote browser
controlled by Selenium can fetch and run our test(s). Using the webdriverjs Node.js npm package, we can easily send URLs to a Selenium
server to be executed:
var webdriverjs = require("webdriverjs")
, url = '...';
browser = webdriverjs.remote({
host: 'localhost'
, port: 4444
, desiredCapabilities: { browserName: 'firefox' }
});
browser.init().url(url).end();This code will contact the Selenium server running on port 4444 at
localhost and tell it to fire up
Firefox and load the specified URL. We’re halfway there! All we need to
do now is capture the test output—those useful log messages that YUI
Test emits—capture a snapshot, and persist it all locally.
As in the PhantomJS case, we need to somehow communicate all of
that output (test results, logging messages, and snapshot data) back to
the Selenium driver. Unlike PhantomJS, Selenium cannot read the console
remotely, so we have to perform another trick to manage this
communication. Here is the equivalent to the phantomjs module included by our test
JavaScript for Selenium:
YUI().add('selenium', function(Y) {
var messages = [];
, yconsole = new Y.Console();
yconsole.on('entry', function(obj) { messages.push(obj.message); });
var TR = Y.Test.Runner;
TR.subscribe(TR.COMPLETE_EVENT, function(obj) {
// Data to dump
var data = escape(JSON.stringify(
{
messages: messages
, results: Y.Test.Format.JUnitXML(obj.results)
}
));
// Create a new Node
var item = Y.Node.create('<div id="testresults"></div>');
item.setContent(data);
// Append to document
Y.one('body').append(item);
});
}, '1.0', { requires: [ 'console', 'node' ] });OK, did you spot the trick? Instead of writing the data we want to
capture to console.log, we save all
the messages we get from YUI Test into an array. When the tests are
complete, we create a <div>
with a specific ID and dump the JSON-ified version of all the messages
and results in there. Finally, we append this new element to the current
document. The two most important points about this are that the <div> must be visible and we must
escape the entire contents of the
resultant JSON string, as the JUnit XML output is—surprise,
surprise—XML. We do not want the browser to attempt to parse it;
otherwise, it will get lost since it is not valid HTML.
Now let’s look at the other half to see how it all fits together. Here is the entire client-side Selenium runner:
var webdriverjs = require("webdriverjs")
, url = '...'
, browser = webdriverjs.remote({
host: 'localhost'
, port: 4444
, desiredCapabilities: { browserName: 'firefox' }
})
;
browser.init().url(url).waitFor('#testresults', 10000, function(found) {
var res;
if (found) {
res = browser.getText('#testresults',
function(text) {
// Do something smarter than console.log!
console.log(JSON.parse(unescape(text.value)));
}
);
} else {
console.log('TEST RESULTS NOT FOUND');
}
}).end();Using the same outline from earlier, after we load the URL we
waitFor the element with the ID
testresults to show up in the DOM
(here we will wait for up to 10 seconds; your mileage may vary). When it
shows up, we pull out its text.
The first thing we have to do is to unescape it to get our XML back. Now we can
re-create the hash containing a messages property, which is the array of YUI
Test messages, and a results property
that contains the JUnit XML output for this test run.
Using this runner, you can run your tests in a real Firefox, Chrome, or IE browser from the command line, as long as the Selenium server is running somewhere reachable on the same host as one of those browsers.
To utilize the Chrome browser, you need to add an extra executable
(the Chrome driver) somewhere in your path. You can download the latest
version of the Chrome driver for your operating system from the Chromium open-source project site.
Just add it somewhere in your PATH
and use chrome as the browserName in the desiredCapabilities hash.
Finally, what about snapshots? Selenium conveniently provides snapshot support. So let’s take some pictures! Unlike PhantomJS, our simplistic Selenium runner only knows when the tests end, so we will take the snapshot then.
Here is the full script with snapshot support. Note that Selenium only supports the PNG format. After we get the test results, we grab the snapshot and write it to a local file named snapshot.png:
var webdriverjs = require("webdriverjs")
, url
, browser = webdriverjs.remote({
host: 'localhost'
, port: 4444
, desiredCapabilities: { browserName: 'firefox' }
})
;
browser.init().url(url).waitFor('#testresults', 10000, function(found) {
if (found) {
var res = browser.getText('#testresults'
,function(text) {
// Get log messages and JUnit XML results
console.log(JSON.parse(unescape(text.value)));
// Now take the snapshot
browser.screenshot(
function(screenshot) {
var fs = require('fs')
, filename = 'snapshot.png'
, imageData
;
try {
imageData =
new Buffer(screenshot.value
, 'base64');
fs.writeFileSync(filename, imageData);
} catch(e) {
console.log('Error getting snapshot: '
+ e);
}
}
);
}
);
} else {
console.log('TEST RESULTS NOT FOUND');
}
}).end();Again, during your build, you will use a smarter way to pass all your tests to these drivers rather than having the URL or filename hardcoded into them.
An issue with the use of Selenium concerns speed: starting up a browser session for each test or set of tests can be a very slow process. Something to keep an eye on is the Ghost Driver project. This driver, similar to the Chrome driver, allows Selenium to use PhantomJS as a backend. This, of course, significantly speeds up Selenium backend startup and teardown times. Not all Selenium primitives are supported at the time of this writing, but most if not all of the basic ones are. If the speed of Selenium tests is important to you, help the project along!
Another option for speeding up Selenium tests is to farm out your tests to a lot of runners in parallel using the Selenium grid. We will examine better ways to run tests in an automated and distributed fashion in Chapter 5, where we will discuss code coverage, and in Chapter 6 and Chapter 8, where we will discuss other types of testing and automation, respectively.
Mobile
You can also run your unit tests on your phone or tablet using Selenium, as, yes, there is a driver for that.
iOS
The iOS Selenium driver runs either in the iPhone simulator or on an iPhone device itself. The details are available at the code.google selenium project site. The driver uses a UIWebView application to encase your web application and accept Selenium commands. To run Selenium tests on an actual device you will need a provisioning profile from Apple, which means you must be a member of the iOS Developer Program; an individual membership costs $99 at the time of this writing.
Install at least version 4.2 (4.5 is the newest version available at the time of this writing) and you can check out and build the iPhone driver from this Subversion repository.
After following the instructions you will have built the
WebDriver application, which can then be installed either in the
simulator or on an iDevice. You connect to it just like any other
remote Selenium driver, so the simulator running the WebDriver
application does not need to be on the host where you execute your
tests. Here is how it looks using webdriverjs:
var browser = webdriverjs.remote({
host: 'localhost'
, port: 3001
, desiredCapabilities: { browserName: 'iPhone' } // or 'iPad'
});And now your Selenium tests are running in iOS. Note that the
default port of the iPhone WebDriver is 3001. Alternatively, you can
specify iPhone or iPad to target devices individually.
Unfortunately, there is no headless option, but you can keep an
emulator up and running with the WebDriver application running
within it so that you can be connected and can run tests
anytime.
Android
Details of running a Selenium WebDriver on Android are available on the code.google selenium site. After downloading the Android SDK and setting up the emulator, you have two choices: run the stock Selenium Android driver in Android or run an Android-specific test framework. If you are running these same tests on multiple operating systems you will want to stick with the standard Selenium Android WebDriver. Only if all your tests are specific to Android can you choose to use the Android test framework.
Let’s investigate the Selenium driver further. First, you need to build the driver application bundle (.apk file) and install it on your device or in the simulator.
At this point, connecting is easy:
var browser = webdriverjs.remote({
host: 'localhost'
, port: 8080
, desiredCapabilities: { browserName: 'android' }
});This assumes the emulator is running on your local host. Of course, it does not have to be, and if you are connecting directly to an actual device you will need to be on the same network and know your Android’s IP address. If you have issues, refer to the URL at the beginning of this subsection, which has lots of great information.
An even better option is to run the Android simulator
headlessly so that you can run all your tests remotely from almost
anywhere. If you run the emulator using the -no-window option, you can start the
WebDriver application using this code (all on one line):
$ adb shell am start -a android.intent.action.MAIN -n
org.openqa.selenium.android.app.MainActivityNow you can connect to it locally or remotely to run your tests.
Running Tests: Server-Side JavaScript
The process for server-side JavaScript unit testing is not much different from the process for unit-testing any other server-side code. Your tests and code all reside and run on the same host, making this much simpler than client-side unit testing. I will demonstrate how this works using Jasmine for server-side JavaScript unit testing.
Although you could cook up your own assertions and test framework, you could probably also build your own airplane; do not reinvent the wheel with an inferior version. There are plenty of other test frameworks you can utilize if you do not like Jasmine, so pick one.
Jasmine
% npm install jasmine-node -gJasmine gives us a nice way to run tests from the command line and output test results in a number of interesting ways: namely, for human or automated consumption.
The idea is that you write a bunch of unit tests using Jasmine-provided syntax and semantics and then point the Jasmine command line to the root directory (or any subdirectory) where those tests live. Jasmine will recurse down the directory tree and run all the tests found within.
By default, Jasmine expects your test files to contain the string
spec, as in sum-spec.js—this
convention is a BDD artifact and you can override it with the --matchall option.
Go to the Jasmine
website to see all of what Jasmine can do. For now, we will look
at some short examples, starting with our favorite piece of code: the
sum function! Here is the mySum.js file:
exports.sum = function(a, b) { return a + b };Exciting stuff! Here is some Jasmine code to test integer addition:
var mySum = require('./mySum');
describe("Sum suite", function() {
it("Adds Integers!", function() {
expect(mySum.sum(7, 11)).toEqual(18);
});
});And finally, here is how the test is run:
% jasmine-node .
.
Finished in 0.009 seconds
1 test, 1 assertion, 0 failuresThe test passed! We are definitely on to something. Jasmine
matchers (toEqual in the previous example) are equivalent to YUI Test
assertions. Plus, you can write your own custom matchers. Jasmine’s
describe is equivalent to YUI Test suites and the specs (the it functions) are similar to YUI Test’s test
cases. Jasmine also supports beforeEach and afterEach functions that are executed before and after each spec, similarly to
YUI Test’s setUp and
tearDown functions.
Dependencies
Factoring out dependent objects of the Node.js code under test can
become more demanding as dependencies are pulled in via the require function.
You’ll need to either change your source code for testing (not good),
or mock out the require function
itself (painful). Fortunately, the latter option has already been done
for us in a very nice npm package called Mockery. Mockery intercepts all
calls to require, allowing easy
insertion of mocked versions of your code’s dependencies instead of
the real deal.
Here is our modified sum
function, which now reads a JSON string from a file and adds the
a and b properties found therein:
var fs = require('fs');
exports.sum = function(file) {
var data = JSON.parse(fs.readFileSync(file, 'utf8'));
return data.a + data.b;
};Here is a simple Jasmine test for this:
var mySum = require('./mySumFS');
describe("Sum suite File", function() {
it("Adds Integers!", function() {
expect(mySum.sum("numbers")).toEqual(12);
});
});where the content of the file numbers is:
{"a":5,"b":7}Fair enough—Jasmine runs the test, it passes, and all is good.
But we are simultaneously testing too much—namely the fs dependency is being pulled in and
utilized and unit testing is all about dependency isolation. We do not
want anything brought into the fs
dependency to affect our tests. Granted, this is an extreme case, but
let’s follow through with the logic.
Using Mockery as part of our Jasmine test we can handle the
require call and replace the
fs module with a mocked-out version
of our own. Here is our new Jasmine script:
var mockery = require('mockery');
mockery.enable();
describe("Sum suite File", function() {
beforeEach(function() {
mockery.registerAllowable('./mySumFS', true);
});
afterEach(function() {
mockery.deregisterAllowable('./mySumFS');
});
it("Adds Integers!", function() {
var filename = "numbers"
, fsMock = {
readFileSync: function (path, encoding) {
expect(path).toEqual(filename);
expect(encoding).toEqual('utf8');
return JSON.stringify({ a: 9, b: 3 });
}
}
;
mockery.registerMock('fs', fsMock);
var mySum = require('./mySumFS');
expect(mySum.sum(filename)).toEqual(12);
mockery.deregisterMock('fs');
});
});Here, we have added the mockery object, enabled it, and told Mockery
to ignore the requireing of the
object under test. By default, Mockery will print an error message if
any module being required is not known to it (via
registerAllowable or registerMock); since we do not want to mock
out the object under test, we tell Mockery to load it without
complaining.
Because we’re creating new mocks for the fs module for each test (as we will see
shortly, instead of reusing the same one for each test), we have to
pass the true second parameter to
registerAllowable so that the
deregisterAllowable method will
clean up properly.
Finally, there is the test itself. It now tests that the
fs.readFileSync method was called
correctly and returns canned data back to the sum function. The code under test is
blissfully unaware that any of this is happening as it plows
forward.
Here is a test for string addition:
it("Adds Strings!", function() {
var filename = "strings"
, fsMock = {
readFileSync: function (path, encoding) {
expect(path).toEqual(filename);
expect(encoding).toEqual('utf8');
return JSON.stringify({ a: 'testable'
, b: 'JavaScript' });
}
}
;
mockery.registerMock('fs', fsMock);
var mySum = require('./mySumFS');
expect(mySum.sum(filename)).toEqual('testableJavaScript');
mockery.deregisterMock('fs');
});Again, here we’re registering a new mock for the fs object that will return a canned object
for string concatenation after checking the parameters to readFileSync.
Alternatively, if we wanted to actually read the JSON objects
off the disk, before we enabled
Mockery we could have required the
real fs object and delegated the
calls from the mocked-out readFileSync method to that object—this
would be a test spy. However, keeping the test data within the tests
themselves is useful, especially for small tests like these.
If your mocked objects are large or you would like to keep a library of them, you can also tell Mockery to substitute your mocked object for the original using this code:
mockery.registerSubstitute('fs', 'fs-mock');As shown in the Mockery documentation, now every require('fs') call will actually require('fs-mock').
Mockery is an excellent tool. Just remember that after you
enable it all
require calls will be routed
through Mockery!
Spies
Spies in Jasmine are most useful for code injection. They are essentially a stub and a mock, all rolled into one zany object.
So, we have decided that our sum function that reads JSON from a file and
our sum function that reads
operands from the parameter list can be combined like so:
exports.sum = function(func, data) {
var data = JSON.parse(func.apply(this, data));
return data.a + data.b;
};
exports.getByFile = function(file) {
var fs = require('fs');
return fs.readFileSync(file, 'utf8');
};
exports.getByParam = function(a, b) {
return JSON.stringify({a: a, b: b});
};We have generalized the data input and now only have the
sum operation in one place. This
not only lets us add new operations (subtract, multiply, etc.), but
also separates operations for getting the data from operations
performed on the data.
Our Jasmine spec file for this (without the Mockery stuff for clarity) looks like this:
mySum = require('./mySumFunc');
describe("Sum suite Functions", function() {
it("Adds By Param!", function() {
var sum = mySum.sum(mySum.getByParam, [6,6]);
expect(sum).toEqual(12);
});
it("Adds By File!", function() {
var sum = mySum.sum(mySum.getByFile, ["strings"]);
expect(sum).toEqual("testableJavaScript");
});
});And of course, the strings file contains the following:
{"a":"testable","b":"JavaScript"}But something is not quite right. We are not doing a good job of
isolating the mySum functions for
testing. Of course, we need individual tests for the various mySum inputters: getByParam and getByFile. But to test the actual sum function, we need those functions. So we
would like to mock and stub out those functions when testing the
sum function so that it is tested
in isolation.
This scenario is a good time to break out Jasmine spies. Using spies, we can test those two helper functions to ensure that they are called with the correct parameters, and allow the test code to either return canned values or let the call pass through to the underlying function.
Here is a modified version of the test function with getByParam using a spy:
it("Adds By Param!", function() {
var params = [ 8, 4 ]
, expected = 12
;
spyOn(mySum, 'getByParam').andCallThrough();
expect(mySum.sum(mySum.getByParam, params)).toEqual(expected);
expect(mySum.getByParam).toHaveBeenCalled();
expect(mySum.getByParam.mostRecentCall.args).toEqual(params);
});After setting up the spy on mySum.getByParam and directing it to call
through to the actual implementation, we can verify that the helper
function has been called and that the correct arguments were
used.
Replacing the andCallThrough
line with:
spyOn(mySum, 'getByParam').andReturn('{"a":8,"b":4}');lets our test code return canned data and skips the call to
getByParam completely. You can also
supply an alternate function to be called whose return value will be
passed back to the caller if you must calculate a canned return
value—very handy!
Jasmine has more tricks up its sleeve, including easy test
disabling, mocking setTimer and
setInterval for easier testing, and
asynchronous test support, so go to its home page and check it all
out. Also, Jasmine is not just for server-side JavaScript testing! It
can run within a browser for client-side JavaScript unit testing as
well; however, extracting test output while running Jasmine in a
browser is not as easy as using YUI Test for automated builds. Jasmine
does support custom test reporters that can export results, unlike YUI
Test, which supports that out of the box.
Output
By default, Jasmine will dump test results to the screen, which is
great for developing tests but not so great for automated runs. By
using –junitreport, however, you
can instruct Jasmine to dump test results in the widely supported
JUnit XML output format. By default, all test results are dumped into
a reports directory and are named
with the test suite name (the first parameter to the describe method). For example:
% ls reports TEST-Sumsuite.xml TEST-SumsuiteFile.xml % cat reports/TEST-SumsuiteFile.xml <?xml version="1.0" encoding="UTF-8" ?> <testsuites> <testsuite name="Sum suite File" errors="0" tests="2" failures="0" time="0.001" timestamp="2012-07-25T15:31:48"> <testcase classname="Sum suite File" name="Adds By Param!" time="0.001"> </testcase> <testcase classname="Sum suite File" name="Adds By File!" time="0"> </testcase> </testsuite> </testsuites>
The output is now ready to be imported into something that
understands that format, as we shall see in Chapter 8. Note that the number of tests reported by
Jasmine is the number of it
functions, not the number of times you call expect.
Recap
Unit-testing your JavaScript is not burdensome. With all the great tools available for both writing and running unit tests, there is a lot of flexibility for getting the job done. We investigated two such tools, YUI Test and Jasmine. Both provide full-featured environments for JavaScript unit testing, and at the time of this writing both are active projects, with the developers regularly adding new features and fixing bugs.
The process begins by defining your functions precisely so that you know what to test for. Any comments sprinkled throughout the code greatly enhance testability. Loose coupling of objects makes mocking and stubbing them out much simpler.
After picking a full-featured unit test framework, writing and running the tests should be relatively painless. Different frameworks provide different features, so make sure that whatever you choose is easily added to an automated build process and supports the different modes of testing you require (probably asynchronous testing, and mocking, and stubbing of dependencies).
Running your tests locally or remotely, headlessly or not, is easy using PhantomJS or Selenium. PhantomJS provides a full-featured headless WebKit browser, while Selenium provides a very basic headless browser plus access to almost any “real” browser, including iOS and Android for mobile devices.
Generating code coverage reports to measure the scope and effectiveness of your tests and running the tests automatically in a build environment will be covered in upcoming chapters, so stay tuned!
Get Testable JavaScript now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

