In this chapter, we will look at modeling cameras and how to effectively use such models. In the previous chapter, we covered image to image mappings and transforms. To handle mappings between 3D and images, the projection properties of the camera generating the image needs to be part of the mapping. Here we show how to determine camera properties and how to use image projections for applications like augmented reality. In the next chapter, we will use the camera model to look at applications with multiple views and mappings between them.
The pin-hole camera model (or sometimes projective camera model) is a widely used camera model in computer vision. It is simple and accurate enough for most applications. The name comes from the type of camera, like a camera obscura, that collects light through a small hole to the inside of a dark box or room. In the pin-hole camera model, light passes through a single point, the camera center, C, before it is projected onto an image plane. Figure 4-1 shows an illustration where the image plane is drawn in front of the camera center. The image plane in an actual camera would be upside down behind the camera center, but the model is the same.
The projection properties of a pin-hole camera can be derived from this illustration and the assumption that the image axis is aligned with the x and y axis of a 3D coordinate system. The optical axis of the camera then coincides with the z axis and the projection follows from similar triangles. By adding rotation and translation to put a 3D point in this coordinate system before projecting, the complete projection transform follows. The interested reader can find the details in [13] and [25, 26].
With a pin-hole camera, a 3D point X is projected to an image point x (both expressed in homogeneous coordinates) as
Here, the 3 × 4 matrix P is called the camera matrix (or projection matrix). Note that the 3D point X has four elements in homogeneous coordinates, X = [X, Y, Z, W]. The scalar λ is the inverse depth of the 3D point and is needed if we want all coordinates to be homogeneous with the last value normalized to one.
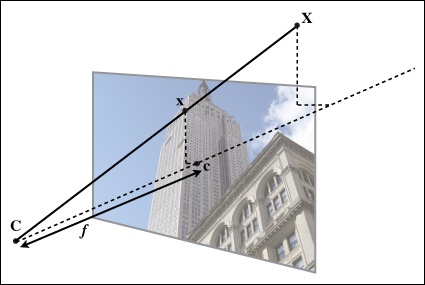
Figure 4-1. The pin-hole camera model. The image point x is at the intersection of the image plane and the line joining the 3D point X and the camera center C. The dashed line is the optical axis of the camera.
The camera matrix can be decomposed as
where R is a rotation matrix describing the orientation of the camera, t a 3D translation vector describing the position of the camera center, and the intrinsic calibration matrix K describing the projection properties of the camera.
The calibration matrix depends only on the camera properties and is in a general form written as
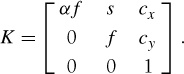
The focal length, f, is the distance between the image plane and the camera center. The skew, s, is only used if the pixel array in the sensor is skewed and can in most cases safely be set to zero. This gives

where we used the alternative notation fx and fy, with fx = αfy.
The aspect ratio, α is used for non-square pixel elements. It is often safe to assume α = 1. With this assumption, the matrix becomes
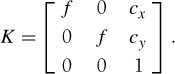
Besides the focal length, the only remaining parameters are the coordinates of the optical center (sometimes called the principal point), the image point c = [cx, cy] where the optical axis intersects the image plane. Since this is usually in the center of the image and image coordinates are measured from the top-left corner, these values are often well approximated with half the width and height of the image. It is worth noting that in this last case the only unknown variable is the focal length f.
Let’s create a camera class to handle all the operations we need for modeling cameras and projections:
from scipy import linalg class Camera(object): """ Class for representing pin-hole cameras. """ def __init__(self,P): """ Initialize P = K[R|t] camera model. """ self.P = P self.K = None # calibration matrix self.R = None # rotation self.t = None # translation self.c = None # camera center def project(self,X): """ Project points in X (4*n array) and normalize coordinates. """ x = dot(self.P,X) for i in range(3): x[i] /= x[2] return x
The example below shows how to project 3D points into an image view. In this example, we will use one of the Oxford multi-view datasets, the “Model House” data set, available at http://www.robots.ox.ac.uk/~vgg/data/data-mview.html. Download the 3D geometry file and copy the house.p3d file to your working directory:
import camera # load points points = loadtxt('house.p3d').T points = vstack((points,ones(points.shape[1]))) # setup camera P = hstack((eye(3),array([[0],[0],[-10]]))) cam = camera.Camera(P) x = cam.project(points) # plot projection figure() plot(x[0],x[1],'k.') show()
First, we make the points into homogeneous coordinates and create a Camera object with a projection matrix before projection the 3D points and plotting them. The result looks like the middle plot in Figure 4-2.
To see how moving the camera changes the projection, try the following piece of code that incrementally rotates the camera around a random 3D axis:
# create transformation r = 0.05*random.rand(3) rot = camera.rotation_matrix(r) # rotate camera and project figure() for t in range(20): cam.P = dot(cam.P,rot) x = cam.project(points) plot(x[0],x[1],'k.') show()
Here we used the helper function rotation_matrix(), which creates a rotation matrix for 3D rotations around a vector (add this to camera.py):
def rotation_matrix(a): """ Creates a 3D rotation matrix for rotation around the axis of the vector a. """ R = eye(4) R[:3,:3] = linalg.expm([[0,-a[2],a[1]],[a[2],0,-a[0]],[-a[1],a[0],0]]) return R
Figure 4-2 shows one of the images from the sequence, a projection of the 3D points and the projected 3D point tracks after the points have been rotated around a random vector. Try this example a few times with different random rotations and you will get a feel for how the points rotate from the projections.

If we are given a camera matrix P of the form in equation (Equation 4-2), we need to be able to recover the internal parameters K and the camera position and pose t and R. Partitioning the matrix is called factorization. In this case, we will use a type of matrix factorization called RQ-factorization.
Add the following method to the Camera class:
def factor(self): """ Factorize the camera matrix into K,R,t as P = K[R|t]. """ # factor first 3*3 part K,R = linalg.rq(self.P[:,:3]) # make diagonal of K positive T = diag(sign(diag(K))) if linalg.det(T) < 0: T[1,1] *= -1 self.K = dot(K,T) self.R = dot(T,R) # T is its own inverse self.t = dot(linalg.inv(self.K),self.P[:,3]) return self.K, self.R, self.t
RQ-factorization is not unique, there is a sign ambiguity in the factorization. Since we need the rotation matrix R to have positive determinant (otherwise the coordinate axis can get flipped), we can add a transform T to change the sign when needed.
Try this on a sample camera to see that it works:
import camera K = array([[1000,0,500],[0,1000,300],[0,0,1]]) tmp = camera.rotation_matrix([0,0,1])[:3,:3] Rt = hstack((tmp,array([[50],[40],[30]]))) cam = camera.Camera(dot(K,Rt)) print K,Rt print cam.factor()
You should get the same printout in the console.
Given a camera projection matrix, P, it is useful to be able to compute the camera’s position in space. The camera center, C, is a 3D point with the property PC = 0. For a camera with P = K [R | t], this gives
K[R | t]C = KRC + Kt = 0,
and the camera center can be computed as
C = –RT t.
Note that the camera center is independent of the intrinsic calibration K, as expected.
Add the following method for computing the camera center according to the formula above and/or returning the camera center to the Camera class:
def center(self): """ Compute and return the camera center. """ if self.c is not None: return self.c else: # compute c by factoring self.factor() self.c = -dot(self.R.T,self.t) return self.c
This concludes the basic functions of our Camera class. Now, let’s see how to work with this pin-hole camera model.
Calibrating a camera means determining the internal camera parameters, in our case the matrix K. It is possible to extend this camera model to include radial distortion and other artifacts if your application needs precise measurements. For most applications, however, the simple model in equation (Equation 4-3) is good enough. The standard way to calibrate cameras is to take lots of pictures of a flat checkerboard pattern. For example, the calibration tools in OpenCV use this approach (see [3] for details).
Here we will look at a simple calibration method. Since most of the parameters can be set using basic assumptions (square straight pixels, optical center at the center of the image), the tricky part is getting the focal length right. For this calibration method, you need a flat rectangular calibration object (a book will do), measuring tape or a ruler, and a flat surface. Here’s what to do:
Measure the sides of your rectangular calibration object. Let’s call these dX and dY.
Place the camera and the calibration object on a flat surface so that the camera back and calibration object are parallel and the object is roughly in the center of the camera’s view. You might have to raise the camera or object to get a nice alignment.
Measure the distance from the camera to the calibration object. Let’s call this dZ.
Take a picture and check that the setup is straight, meaning that the sides of the calibration object align with the rows and columns of the image.
Measure the width and height of the object in pixels. Let’s call these dx and dy.
See Figure 4-3 for an example of a setup. Now, using similar triangles (look at Figure 4-1 to convince yourself of that), the following relation gives the focal lengths:

Figure 4-3. A simple camera calibration setup: an image of the setup used (left); the image used for the calibration (right). Measuring the width and height of the calibration object in the image and the physical dimensions of the setup is enough to determine the focal length.
For the particular setup in Figure 4-3, the object was measured to be 130 by 185 mm, so dX = 130 and dY = 185. The distance from camera to object was 460 mm, so dZ = 460. You can use any unit of measurement; only the ratios of the measurements matter. Using ginput() to select four points in the image, the width and height in pixels was 722 and 1040. This means that dx = 722 and dy = 1040. Putting these values in the relationship above gives
fx = 2555, | fy = 2586. |
Now, it is important to note that this is for a particular image resolution. In this case, the image was 2592 × 1936 pixels. Remember that the focal length and the optical center are measured in pixels and scale with the image resolution. If you take other image resolutions (for example a thumbnail image), the values will change. It is convenient to add the constants of your camera to a helper function like this:
def my_calibration(sz): row,col = sz fx = 2555*col/2592 fy = 2586*row/1936 K = diag([fx,fy,1]) K[0,2] = 0.5*col K[1,2] = 0.5*row return K
This function then takes a size tuple and returns the calibration matrix. Here we assume the optical center to be the center of the image. Go ahead and replace the focal lengths with their mean if you like; for most consumer type cameras this is fine. Note that the calibration is for images in landscape orientation. For portrait orientation, you need to interchange the constants. Let’s keep this function and make use of it in the next section.
In Chapter 3, we saw how to estimate homographies between planes. Combining this with a calibrated camera makes it possible to compute the camera’s pose (rotation and translation) if the image contains a planar marker object. This marker object can be almost any flat object.
Let’s illustrate with an example. Consider the two top images in Figure 4-4. The following code will extract SIFT features in both images and robustly estimate a homography using RANSAC:
import homography import camera import sift # compute features sift.process_image('book_frontal.JPG','im0.sift') l0,d0 = sift.read_features_from_file('im0.sift') sift.process_image('book_perspective.JPG','im1.sift') l1,d1 = sift.read_features_from_file('im1.sift') # match features and estimate homography matches = sift.match_twosided(d0,d1) ndx = matches.nonzero()[0] fp = homography.make_homog(l0[ndx,:2].T) ndx2 = [int(matches[i]) for i in ndx] tp = homography.make_homog(l1[ndx2,:2].T) model = homography.RansacModel() H = homography.H_from_ransac(fp,tp,model)

Figure 4-4. Example of computing the projection matrix for a new view using a planar object as marker. Matching image features to an aligned marker gives a homography that can be used to compute the pose of the camera. Template image with a gray square (top left); an image taken from an unknown viewpoint with the same square transformed with the estimated homography (top right); a cube transformed using the estimated camera matrix (bottom).
Now we have a homography that maps points on the marker (in this case the book) in one image to their corresponding locations in the other image. Let’s define our 3D coordinate system so that the marker lies in the X-Y plane (Z = 0) with the origin somewhere on the marker.
To check our results, we will need some simple 3D object placed on the marker. Here we will use a cube and generate the cube points using the function:
def cube_points(c,wid): """ Creates a list of points for plotting a cube with plot. (the first 5 points are the bottom square, some sides repeated). """ p = [] # bottom p.append([c[0]-wid,c[1]-wid,c[2]-wid]) p.append([c[0]-wid,c[1]+wid,c[2]-wid]) p.append([c[0]+wid,c[1]+wid,c[2]-wid]) p.append([c[0]+wid,c[1]-wid,c[2]-wid]) p.append([c[0]-wid,c[1]-wid,c[2]-wid]) # same as first to close plot # top p.append([c[0]-wid,c[1]-wid,c[2]+wid]) p.append([c[0]-wid,c[1]+wid,c[2]+wid]) p.append([c[0]+wid,c[1]+wid,c[2]+wid]) p.append([c[0]+wid,c[1]-wid,c[2]+wid]) p.append([c[0]-wid,c[1]-wid,c[2]+wid]) # same as first to close plot # vertical sides p.append([c[0]-wid,c[1]-wid,c[2]+wid]) p.append([c[0]-wid,c[1]+wid,c[2]+wid]) p.append([c[0]-wid,c[1]+wid,c[2]-wid]) p.append([c[0]+wid,c[1]+wid,c[2]-wid]) p.append([c[0]+wid,c[1]+wid,c[2]+wid]) p.append([c[0]+wid,c[1]-wid,c[2]+wid]) p.append([c[0]+wid,c[1]-wid,c[2]-wid]) return array(p).T
Some points are reoccurring so that plot() will generate a nice-looking cube.
With a homography and a camera calibration matrix, we can now determine the relative transformation between the two views:
# camera calibration K = my_calibration((747,1000)) # 3D points at plane z=0 with sides of length 0.2 box = cube_points([0,0,0.1],0.1) # project bottom square in first image cam1 = camera.Camera( hstack((K,dot(K,array([[0],[0],[-1]])) )) ) # first points are the bottom square box_cam1 = cam1.project(homography.make_homog(box[:,:5])) # use H to transfer points to the second image box_trans = homography.normalize(dot(H,box_cam1)) # compute second camera matrix from cam1 and H cam2 = camera.Camera(dot(H,cam1.P)) A = dot(linalg.inv(K),cam2.P[:,:3]) A = array([A[:,0],A[:,1],cross(A[:,0],A[:,1])]).T cam2.P[:,:3] = dot(K,A) # project with the second camera box_cam2 = cam2.project(homography.make_homog(box)) # test: projecting point on z=0 should give the same point = array([1,1,0,1]).T print homography.normalize(dot(dot(H,cam1.P),point)) print cam2.project(point)
Here we use a version of the image with resolution 747 × 1000 and first generate the calibration matrix for that image size. Next, points for a cube at the origin are created. The first five points generated by cube_points() correspond to the bottom, which in this case will lie on the plane defined by Z = 0, the plane of the marker. The first image (top left in Figure 4-4) is roughly a straight frontal view of the book and will be used as our template image. Since the scale of the scene coordinates is arbitrary, we create a first camera with matrix
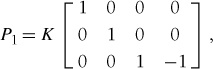
which has coordinate axis aligned with the camera and placed above the marker. The first five 3D points are projected onto the image. With the estimated homography, we can transform these to the second image. Plotting them should show the corners at the same marker locations (see top right in Figure 4-4).
Now, composing P1 with H as a camera matrix for the second image,
P2 = HP1,
will transform points on the marker plane Z = 0 correctly. This means that the first two columns and the fourth column of P2 are correct. Since we know that the first 3 × 3 block should be KR and R is a rotation matrix, we can recover the third column by multiplying P2 with the inverse of the calibration matrix and replacing the third column with the cross product of the first two.
As a sanity check, we can project a point on the marker plane with the new matrix and check that it gives the same projection as the same point transformed with the first camera and the homography. You should get the same printout in your console.
Visualizing the projected points can be done like this:
im0 = array(Image.open('book_frontal.JPG'))
im1 = array(Image.open('book_perspective.JPG'))
# 2D projection of bottom square
figure()
imshow(im0)
plot(box_cam1[0,:],box_cam1[1,:],linewidth=3)
# 2D projection transferred with H
figure()
imshow(im1)
plot(box_trans[0,:],box_trans[1,:],linewidth=3)
# 3D cube
figure()
imshow(im1)
plot(box_cam2[0,:],box_cam2[1,:],linewidth=3)
show()This should give three figures like the images in Figure 4-4. To be able to reuse these computations for future examples, we can save the camera matrices using Pickle:
import pickle
with open('ar_camera.pkl','w') as f:
pickle.dump(K,f)
pickle.dump(dot(linalg.inv(K),cam2.P),f)Now we have seen how to compute the camera matrix given a planar scene object. We combined feature matching with homographies and camera calibration to produce a simple example of placing a cube in an image. With camera pose estimation, we now have the building blocks in place for creating simple augmented reality applications.
Augmented reality (AR) is a collective term for placing objects and information on top of image data. The classic example is placing a 3D computer graphics model so that it looks like it belongs in the scene, and moves naturally with the camera motion in the case of video. Given an image with a marker plane as in the section above, we can compute the camera’s position and pose and use that to place computer graphics models so that they are rendered correctly. In this last section of our camera chapter we will show how to build a simple AR example. We will use two tools for this, PyGame and PyOpenGL.
PyGame is a popular package for game development that easily handles display windows, input devices, events, and much more. PyGame is open source and available from http://www.pygame.org/. It is actually a Python binding for the SDL game engine. For installation instructions, see Appendix A. For more details on programming with PyGame, see, for example, [21].
PyOpenGL is the Python binding to the OpenGL graphics programming interface. OpenGL comes pre-installed on almost all systems and is a crucial part for graphics performance. OpenGL is cross platform and works the same across operating systems. Take a look at http://www.opengl.org/ for more information on OpenGL. The getting started page (http://www.opengl.org/wiki/Getting_started) has resources for beginners. PyOpenGL is open source and easy to install; see Appendix A for details. More information can be found on the project website, http://pyopengl.sourceforge.net/.
There is no way we can cover any significant portion of OpenGL programming. We will instead just show the important parts, for example how to use camera matrices in OpenGL and setting up a basic 3D model. Some good examples and demos are available in the PyOpenGL-Demo package (http://pypi.python.org/pypi/PyOpenGL-Demo). This is a good place to start if you are new to PyOpenGL.
We want to place a 3D model in a scene using OpenGL. To use PyGame and PyOpenGL for this application, we need to import the following at the top of our scripts:
from OpenGL.GL import * from OpenGL.GLU import * import pygame, pygame.image from pygame.locals import *
As you can see, we need two main parts from OpenGL. The GL part contains all functions stating with “gl”, which, you will see, are most of the ones we need. The GLU part is the OpenGL Utility library and contains some higher-level functionality. We will mainly use it to set up the camera projection. The pygame part sets up the window and event controls, and pygame.image is used for loading image and creating OpenGL textures. The pygame.locals is needed for setting up the display area for OpenGL.
The two main components of setting up an OpenGL scene are the projection and model view matrices. Let’s get started and see how to create these matrices from our pin-hole cameras.
OpenGL uses 4 × 4 matrices to represent transforms (both 3D transforms and projections). This is only slightly different from our use of 3 × 4 camera matrices. However, the camera-scene transformations are separated in two matrices, the GL_PROJECTION matrix and the GL_MODELVIEW matrix. GL_PROJECTION handles the image formation properties and is the equivalent of our internal calibration matrix K. GL_MODELVIEW handles the 3D transformation of the relation between the objects and the camera. This corresponds roughly to the R and t part of our camera matrix. One difference is that the coordinate system is assumed to be centered at the camera so the GL_MODELVIEW matrix actually contains the transformation that places the objects in front of the camera. There are many peculiarities with working in OpenGL; we will comment on them as they are encountered in the examples below.
Given that we have a camera calibrated so that the calibration matrix K is known, the following function translates the camera properties to an OpenGL projection matrix:
def set_projection_from_camera(K): """ Set view from a camera calibration matrix. """ glMatrixMode(GL_PROJECTION) glLoadIdentity() fx = K[0,0] fy = K[1,1] fovy = 2*arctan(0.5*height/fy)*180/pi aspect = (width*fy)/(height*fx) # define the near and far clipping planes near = 0.1 far = 100.0 # set perspective gluPerspective(fovy,aspect,near,far) glViewport(0,0,width,height)
We assume the calibration to be of the simpler form in (4.3) with the optical center at the image center. The first function glMatrixMode() sets the working matrix to GL_PROJECTION and subsequent commands will modify this matrix.[11] Then glLoadIdentity() sets the matrix to the identity matrix, basically reseting any prior changes. We then calculate the vertical field of view in degrees with the help of the image height and the camera’s focal length as well as the aspect ratio. An OpenGL projection also has a near and far clipping plane to limit the depth range of what is rendered. We just set the near depth to be small enough to contain the nearest object and the far depth to some large number. We use the GLU utility function gluPerspective() to set the projection matrix and define the whole image to be the view port (essentially what is to be shown). There is also an option to load a full projection matrix with glLoadMatrixf() similar to the model view function below. This is useful when the simple version of the calibration matrix is not good enough.
The model view matrix should encode the relative rotation and translation that brings the object in front of the camera (as if the camera was at the origin). It is a 4 × 4 matrix that typically looks like this:
where R is a rotation matrix with columns equal to the direction of the three coordinate axis and t is a translation vector. When creating a model view matrix, the rotation part will need to hold all rotations (object and coordinate system) by multiplying together the individual components.
The following function shows how to take a 3 × 4 pin-hole camera matrix with the calibration removed (multiply P with K–1) and create a model view:
def set_modelview_from_camera(Rt): """ Set the model view matrix from camera pose. """ glMatrixMode(GL_MODELVIEW) glLoadIdentity() # rotate teapot 90 deg around x-axis so that z-axis is up Rx = array([[1,0,0],[0,0,-1],[0,1,0]]) # set rotation to best approximation R = Rt[:,:3] U,S,V = linalg.svd(R) R = dot(U,V) R[0,:] = -R[0,:] # change sign of x-axis # set translation t = Rt[:,3] # setup 4*4 model view matrix M = eye(4) M[:3,:3] = dot(R,Rx) M[:3,3] = t # transpose and flatten to get column order M = M.T m = M.flatten() # replace model view with the new matrix glLoadMatrixf(m)
First, we switch to work on the GL_MODELVIEW matrix and reset it. Then we create a 90-degree rotation matrix, since the object we want to place needs to be rotated (you will see below). Then we make sure that the rotation part of the camera matrix is indeed a rotation matrix, in case there are errors or noise when we estimated the camera matrix. This is done with SVD and the best rotation matrix approximation is given by R = UVT. The OpenGL coordinate system is a little different, so we flip the x-axis around. Then we set the model view matrix M by multiplying the rotations. The function glLoadMatrixf() sets the model view matrix and takes an array of the 16 values of the matrix taken column-wise. Transposing and then flattening accomplishes this.
The first thing we need to do is to add the image (the one we want to place virtual objects in) as a background. In OpenGL this is done by creating a quadrilateral, a quad, that fills the whole view. The easiest way to do this is to draw the quad with the projection and model view matrices reset so that the coordinates go from – 1 to 1 in each dimension.
This function loads an image, converts it to an OpenGL texture, and places that texture on the quad:
def draw_background(imname): """ Draw background image using a quad. """ # load background image (should be .bmp) to OpenGL texture bg_image = pygame.image.load(imname).convert() bg_data = pygame.image.tostring(bg_image,"RGBX",1) glMatrixMode(GL_MODELVIEW) glLoadIdentity() glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT) # bind the texture glEnable(GL_TEXTURE_2D) glBindTexture(GL_TEXTURE_2D,glGenTextures(1)) glTexImage2D(GL_TEXTURE_2D,0,GL_RGBA,width,height,0,GL_RGBA,GL_UNSIGNED_BYTE,bg_data) glTexParameterf(GL_TEXTURE_2D,GL_TEXTURE_MAG_FILTER,GL_NEAREST) glTexParameterf(GL_TEXTURE_2D,GL_TEXTURE_MIN_FILTER,GL_NEAREST) # create quad to fill the whole window glBegin(GL_QUADS) glTexCoord2f(0.0,0.0); glVertex3f(-1.0,-1.0,-1.0) glTexCoord2f(1.0,0.0); glVertex3f( 1.0,-1.0,-1.0) glTexCoord2f(1.0,1.0); glVertex3f( 1.0, 1.0,-1.0) glTexCoord2f(0.0,1.0); glVertex3f(-1.0, 1.0,-1.0) glEnd() # clear the texture glDeleteTextures(1)
This function first uses some PyGame functions to load an image and serialize it to a raw string representation that can be used by PyOpenGL. Then we reset the model view and clear the color and depth buffer. Next, we bind the texture so that we can use it for the quad and specify interpolation. The quad is defined with corners at – 1 and 1 in both dimensions. Note that the coordinates in the texture image go from 0 to 1. Finally, we clear the texture so it doesn’t interfere with what we want to draw later.
Now we are ready to place objects in the scene. We will use the “hello world” computer graphics example, the Utah teapot (http://en.wikipedia.org/wiki/Utah_teapot). This teapot has a rich history and is available as one of the standard shapes in GLUT:
from OpenGL.GLUT import * glutSolidTeapot(size)
This generates a solid teapot model of relative size size.
The following function will set up the color and properties to make a pretty red teapot:
def draw_teapot(size): """ Draw a red teapot at the origin. """ glEnable(GL_LIGHTING) glEnable(GL_LIGHT0) glEnable(GL_DEPTH_TEST) glClear(GL_DEPTH_BUFFER_BIT) # draw red teapot glMaterialfv(GL_FRONT,GL_AMBIENT,[0,0,0,0]) glMaterialfv(GL_FRONT,GL_DIFFUSE,[0.5,0.0,0.0,0.0]) glMaterialfv(GL_FRONT,GL_SPECULAR,[0.7,0.6,0.6,0.0]) glMaterialf(GL_FRONT,GL_SHININESS,0.25*128.0) glutSolidTeapot(size)
The first two lines enable lighting and a light. Lights are numbered as GL_LIGHT0, GL_LIGHT1, etc. We will only use one light in this example. The glEnable() function is used to turn on OpenGL features. These are defined with uppercase constants. Turning off a feature is done with the corresponding function glDisable(). Next, depth testing is turned on so that objects are rendered according to their depth (so that far-away objects are not drawn in front of near objects) and the depth buffer is cleared. Next, the material properties of the object, such as the diffuse and specular colors, are specified. The last line adds a solid Utah teapot with the specified material properties.
The full script for generating an image like the one in Figure 4-5 looks like this (assuming that you also have the functions introduced above in the same file):
from OpenGL.GL import * from OpenGL.GLU import * from OpenGL.GLUT import * import pygame, pygame.image from pygame.locals import * import pickle width,height = 1000,747 def setup(): """ Setup window and pygame environment. """ pygame.init() pygame.display.set_mode((width,height),OPENGL | DOUBLEBUF) pygame.display.set_caption('OpenGL AR demo') # load camera data with open('ar_camera.pkl','r') as f: K = pickle.load(f) Rt = pickle.load(f) setup() draw_background('book_perspective.bmp') set_projection_from_camera(K) set_modelview_from_camera(Rt) draw_teapot(0.02) while True: event = pygame.event.poll() if event.type in (QUIT,KEYDOWN): break pygame.display.flip()

Figure 4-5. Augmented reality. Placing a computer graphics model on a book in a scene using camera parameters computed from feature matches: the Utah teapot rendered in place aligned with the coordinate axis (top); sanity check to see the position of the origin (bottom).
First, this script loads the camera calibration matrix and the rotation and translation part of the camera matrix using Pickle. This assumes that you saved them as described in 4.4 Augmented Reality. The setup() function initializes PyGame, sets the window to the size of the image, and makes the drawing area a double buffer OpenGL window. Next, the background image is loaded and placed to fit the window. The camera and model view matrices are set and finally the teapot is drawn at the correct position.
Events in PyGame are handled using infinite loops with regular polling for any changes. These can be keyboard, mouse, or other events. In this case, we check if the application was quit or if a key was pressed and exit the loop. The command pygame.display.flip() draws the objects on the screen.
The result should look like Figure 4-5. As you can see, the orientation is correct (the teapot is aligned with the sides of the cube in Figure 4-4). To check that the placement is correct, you can try to make the teapot really small by passing a smaller value for the size variable. The teapot should be placed close to the [0, 0, 0] corner of the cube in Figure 4-4. An example is shown in Figure 4-5.
Before we end this chapter, we will touch upon one last detail: loading 3D models and displaying them. The PyGame cookbook has a script for loading models in .obj format available at http://www.pygame.org/wiki/OBJFileLoader. You can learn more about the .obj format and the corresponding material file format at http://en.wikipedia.org/wiki/Wavefront_.obj_file.
Let’s see how to use that with a basic example. We will use a freely available toy plane model from http://www.oyonale.com/modeles.php.[12] Download the .obj version and save it as toyplane.obj. You can, of course, replace this model with any model of your choice; the code below will be the same.
Assuming that you downloaded the file as objloader.py, add the following function to the file you used for the teapot example above:
def load_and_draw_model(filename): """ Loads a model from an .obj file using objloader.py. Assumes there is a .mtl material file with the same name. """ glEnable(GL_LIGHTING) glEnable(GL_LIGHT0) glEnable(GL_DEPTH_TEST) glClear(GL_DEPTH_BUFFER_BIT) # set model color glMaterialfv(GL_FRONT,GL_AMBIENT,[0,0,0,0]) glMaterialfv(GL_FRONT,GL_DIFFUSE,[0.5,0.75,1.0,0.0]) glMaterialf(GL_FRONT,GL_SHININESS,0.25*128.0) # load from a file import objloader obj = objloader.OBJ(filename,swapyz=True) glCallList(obj.gl_list)
Same as before, we set the lighting and the color properties of the model. Next, we load a model file into an OBJ object and execute the OpenGL calls from the file.
You can set the texture and material properties in a corresponding .mtl file. The objloader module actually requires a material file. Rather than modifying the loading script, we take the pragmatic approach of just creating a tiny material file. In this case, we’ll just specify the color.
Create a file toyplane.mtl with the following lines:
newmtl lightblue Kd 0.5 0.75 1.0 illum 1
This sets the diffuse color of the object to a light grayish blue. Now, make sure to replace the “usemtl” tag in your .obj file with
usemtl lightblue
Adding textures we leave to the exercises. Replacing the call to draw_teapot() in the example above with
load_and_draw_model('toyplane.obj')should generate a window like the one shown in Figure 4-6.
This is as deep as we will go into augmented reality and OpenGL in this book. With the recipe for calibrating cameras, computing camera pose, translating the cameras into OpenGL format, and rendering models in the scene, the groundwork is laid for you to continue exploring augmented reality. In the next chapter, we will continue with the camera model and compute 3D structure and camera pose without the use of markers.

Modify the example code for the motion in Figure 4-2 to transform the points instead of the camera. You should get the same plot. Experiment with different transformations and plot the results.
Some of the Oxford multi-view datasets have camera matrices given. Compute the camera positions for one of the sets an plot the camera path. Does it match with what you are seeing in the images?
Take some images of a scene with a planar marker or object. Match features to a full-frontal image to compute the pose of each image’s camera location. Plot the camera trajectory and the plane of the marker. Add the feature points if you like.
In our augmented reality example, we assumed the object to be placed at the origin and applied only the camera’s position to the model view matrix. Modify the example to place several objects at different locations by adding the object transformation to the matrix. For example, place a grid of teapots on the marker.
Take a look at the online documentation for .obj model files and see how to use textured models. Find a model (or create your own) and add it to the scene.
Get Programming Computer Vision with Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

