The preceding sections covered the basic interfaces for writing concurrent code in Haskell. These are enough for simple tasks, but for larger and more complex programs we need to raise the level of abstraction.
The previous chapters developed the Async interface for
performing operations asynchronously and waiting for the results. In
this chapter, we will be revisiting that interface and expanding it
with some more sophisticated functionality. In particular, we will
provide a way to create an Async that is automatically cancelled if
its parent dies and then use this to build more compositional
functionality.
What we are aiming for is the ability to build trees of threads, such that when a thread dies for whatever reason, two things happen: any children it has are automatically terminated, and its parent is informed. Thus the tree is always collapsed from the bottom up, and no threads are ever left running accidentally. Furthermore, all threads are given a chance to clean up when they die, by handling exceptions.
Let’s review the last version of the Async API that we encountered
from Async Revisited:
dataAsyncasync::IOa->IO(Asynca)cancel::Asynca->IO()waitCatchSTM::Asynca->STM(EitherSomeExceptiona)waitCatch::Asynca->IO(EitherSomeExceptiona)waitSTM::Asynca->STMawait::Asynca->IOawaitEither::Asynca->Asyncb->IO(Eitherab)
Now we’ll define a way to create an Async that is automatically
cancelled if the current thread dies. A good motivation for this
arises from the example we had in Error Handling with Async,
geturls4.hs, which contains the following code:
main=doa1<-async(getURL"http://www.wikipedia.org/wiki/Shovel")a2<-async(getURL"http://www.wikipedia.org/wiki/Spade")r1<-waita1r2<-waita2(B.lengthr1,B.lengthr2)
Consider what happens when the first Async, a1, fails with an
exception. The first wait operation throws the same exception,
which gets propagated up to the top of main, resulting in program
termination. But this is untidy: we left a2 running, and if this
had been deep in a program, we would be not only leaking a thread, but
also leaving some I/O running in the background.
What we would like to do is create an Async and install an exception
handler that cancels the Async should an exception be raised. This
is a typical resource acquire/release pattern, and Haskell has a good
abstraction for that: the bracket function. Here is the general pattern:
bracket(asyncio)canceloperation
Here, io is the IO action to perform
asynchronously and operation is the
code to execute while io is running.
Typically, operation will include a
wait to get the result of the Async. For example, we could
rewrite geturls4.hs in this way:
main=dobracket(async(getURL"http://www.wikipedia.org/wiki/Shovel"))cancel$\a1->dobracket(async(getURL"http://www.wikipedia.org/wiki/Shovel"))cancel$\a2->dor1<-waita1r2<-waita2(B.lengthr1,B.lengthr2)
But this is a bit of a mouthful. Let’s package up the bracket
pattern into a function instead:
withAsync::IOa->(Asynca->IOb)->IObwithAsynciooperation=bracket(asyncio)canceloperation
Now our main function becomes:
main=withAsync(getURL"http://www.wikipedia.org/wiki/Shovel")$\a1->withAsync(getURL"http://www.wikipedia.org/wiki/Spade")$\a2->dor1<-waita1r2<-waita2(B.lengthr1,B.lengthr2)
This is an improvement over geturls6.hs. Now the second Async is
cleaned up if the first one fails.
Take another look at the example at the end of the previous section.
The behavior in the event of failure is lopsided: if a1 fails, then the alarm is raised immediately, but if a2 fails, then the program waits for a result from a1 before it notices the failure of a2.
Ideally, we should be able to write this symmetrically so that we
notice the failure of either a1 or a2, whichever one happens
first. This is somewhat like the waitEither operation that we
defined earlier:
waitEither::Asynca->Asyncb->IO(Eitherab)
But here we want to wait for both results and terminate
early if either Async raises an exception. By analogy with
waitEither, let’s call it waitBoth:
waitBoth::Asynca->Asyncb->IO(a,b)
Indeed, we can program waitBoth rather succinctly, thanks to STM’s
orElse combinator:
waitBoth::Asynca->Asyncb->IO(a,b)waitBotha1a2=atomically$dor1<-waitSTMa1`orElse`(dowaitSTMa2;retry)--
r2<-waitSTMa2return(r1,r2)
It is worth considering the different cases to convince yourself that
line ![]() has the right behavior:
has the right behavior:
-
If
a1threw an exception, then the exception is re-thrown here (remember that if anAsyncresults in an exception, it is re-thrown bywaitSTM). -
If
a1returned a result, then we proceed to the next line and wait fora2’s result. If
waitSTM a1retries, then we enter the right side oforElse:-
If
a2threw an exception, then the exception is re-thrown here. -
If
a2returned a result, then we ignore it and callretry, so the whole transaction retries. This case might seem counterintuitive, but the purpose of callingwaitSTM a2here was to check whethera2had thrown an exception. We aren’t interested in its result yet because we know thata1has still not completed. -
If
waitSTM a2retries, then the whole transaction retries.
-
If
Now, using withAsync and waitBoth, we can build a nice symmetric
function that runs two IO actions concurrently but aborts if either
one fails with an exception:
concurrently::IOa->IOb->IO(a,b)concurrentlyioaiob=withAsyncioa$\a->withAsynciob$\b->waitBothab
Finally, we can rewrite geturls7.hs to use concurrently:
main=do(r1,r2)<-concurrently(getURL"http://www.wikipedia.org/wiki/Shovel")(getURL"http://www.wikipedia.org/wiki/Spade")(B.lengthr1,B.lengthr2)
What if we wanted to download a list of URLs at the same time? The
concurrently function takes only two arguments, but we can fold it
over a list, provided that we use a small wrapper to rebuild the list of
results:
main=doxs<-foldrconc(return[])(mapgetURLsites)(mapB.lengthxs)whereconcioaioas=do(a,as)<-concurrentlyioaioasreturn(a:as)
The concurrently function has a companion; if we swap waitBoth for
waitEither, we get a different but equally useful function:
race::IOa->IOb->IO(Eitherab)raceioaiob=withAsyncioa$\a->withAsynciob$\b->waitEitherab
The race function runs two IO actions concurrently, but as
soon as one of them returns a result or throws an exception, the other
is immediately cancelled. Hence the name race: the two IO actions are
racing to produce a result. As we shall see later, race is quite
useful when we need to fork two threads while letting either one terminate
the other by just returning.
These two functions, race and concurrently, are the essence of
constructing trees of threads. Each builds a structure like Figure 11-1.
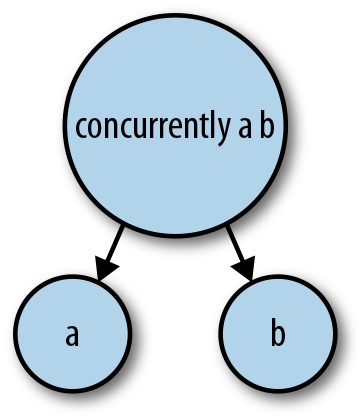
By using multiple race and concurrently calls, we can build up
larger trees of threads. If we use these functions consistently,
we can be sure that the tree of threads constructed will always be
collapsed from the bottom up:
- If a parent throws an exception or receives an asynchronous exception, then the children are automatically cancelled. This happens recursively. If the children have children themselves, then they will also be cancelled, and so on.
- If one child receives an exception, then its sibling is also cancelled.
-
The parent chooses whether to wait for a result from both children
or just one, by using
raceorconcurrently, respectively.
What is particularly nice about this way of building thread trees is
that there is no explicit representation of the tree as a data
structure, which would involve a lot of bookkeeping and would likely
be prone to errors. The thread tree is completely implicit in the
structure of the calls to withAsync and hence concurrently and
race.
A simple demonstration of the power of race is an implementation of the timeout function from Timeouts.
timeout::Int->IOa->IO(Maybea)timeoutnm|n<0=fmapJustm|n==0=returnNothing|otherwise=dor<-race(threadDelayn)mcaserofLeft_->returnNothingRighta->return(Justa)
Most of the code here is administrative: checking for negative and
zero timeout values and converting the Either () a result of race
into a Maybe a. The core of the implementation is simply race
(threadDelay n) m.
Pedantically speaking, this implementation of timeout does have a
few differences from the one in Timeouts. First, it doesn’t
have precisely the same semantics in the case where another thread
sends the current thread an exception using throwTo. With the
original timeout, the exception would be delivered to the computation
m, whereas here the exception is delivered to race, which then
terminates m with killThread, and so the exception seen by m
will be ThreadKilled, not the original one that was thrown.
Secondly, the exception thrown to m in the case of a timeout is
ThreadKilled, not a special Timeout exception. This might be
important if the thread wanted to act on the Timeout exception.
Finally, race creates an extra thread, which makes this
implementation of timeout a little less efficient than the one in
Timeouts. You won’t notice the difference unless timeout is
in a critical path in your application, though.
When an Async is created, it has a fixed result type corresponding to the type of the value returned by the IO action. But this might
be inconvenient: suppose we need to wait for several different
Asyncs that have different result types. We would like to emulate
the waitAny function defined in Async Revisited:
waitAny::[Asynca]->IOawaitAnyasyncs=atomically$foldrorElseretry$mapwaitSTMasyncs
But if our Asyncs don’t all have the same result type, then we
can’t put them in a list. We could force them all to have
the same type when they are created, but that might be difficult,
especially if we use an Async created by a library function that is
not under our control.
A better solution to the problem is to make Async an instance of
Functor:
classFunctorfwherefmap::(a->b)->fa->fb
The fmap operation lets us map the result of an
Async into any type we need.
But how can we implement fmap for Async? The type of the result
that the Async will place in the TMVar is fixed when we create the
Async; the definition of Async is the following:
dataAsynca=AsyncThreadId(TMVar(EitherSomeExceptiona))
Instead of storing the TMVar in the Async, we need to store
something more compositional that we can compose with the function
argument to fmap to change the result type. One solution is to replace
the TMVar with an STM computation that returns the same type:
dataAsynca=AsyncThreadId(STM(EitherSomeExceptiona))
The change is very minor. We only need to move the readTMVar call
from waitCatchSTM to async:
async::IOa->IO(Asynca)asyncaction=dovar<-newEmptyTMVarIOt<-forkFinallyaction(atomically.putTMVarvar)return(Asynct(readTMVarvar))
waitCatchSTM::Asynca->STM(EitherSomeExceptiona)waitCatchSTM(Async_stm)=stm
And now we can define fmap by building a new STM computation that is
composed from the old one by applying the function argument of fmap
to the result:
instanceFunctorAsyncwherefmapf(Asynctstm)=Asynctstm'wherestm'=dor<-stmcaserofLefte->return(Lefte)Righta->return(Right(fa))
We visited the Async API several times during the course of the
previous few chapters, each time evolving it to add a new feature or
to fix some undesirable behavior. The addition of the Functor instance
in the previous section represents the last addition I’ll be making to
Async in this book, so it seems like a good point to take a step
back and summarize what has been achieved:
-
We started with a simple API to execute an
IOaction asynchronously (async) and wait for its result (wait). -
We modified the implementation to catch exceptions in the
asynchronous code and propagate them to the
waitcall. This avoids a common error in concurrent programming: forgetting to handle errors in a child thread. -
We reimplemented the
AsyncAPI using STM, which made it possible to have efficient implementations of combinators that symmetrically wait for multipleAsyncs to complete (waitEither,waitBoth). -
We added
withAsync, which avoids the accidental leakage of threads when an exception occurs in the parent thread, thus avoiding another common pitfall in concurrent programming. -
Finally, we combined
withAsyncwithwaitEitherandwaitBothto make the high-level symmetric combinatorsraceandconcurrently. These two operations can be used to build trees of threads that are always collapsed from the bottom up and to propagate errors correctly.
The complete library is available in the async package on Hackage.
Get Parallel and Concurrent Programming in Haskell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

