In the extremely unlikely event that you donât know much about Twitter yet, itâs a real-time, highly social microblogging service that allows you to post short messages of 140 characters or less; these messages are called tweets. Unlike social networks like Facebook and LinkedIn, where a connection is bidirectional, Twitter has an asymmetric network infrastructure of âfriendsâ and âfollowers.â Assuming you have a Twitter account, your friends are the accounts that you are following and your followers are the accounts that are following you. While you can choose to follow all of the users who are following you, this generally doesnât happen because you only want your Home Timeline[6] to include tweets from accounts whose content you find interesting. Twitter is an important phenomenon from the standpoint of its incredibly high number of users, as well as its use as a marketing device and emerging use as a transport layer for third-party messaging services. It offers an extensive collection of APIs, and although you can use a lot of the APIs without registering, itâs much more interesting to build up and mine your own network. Take a moment to review Twitterâs liberal terms of service, API documentation, and API rules, which allow you to do just about anything you could reasonably expect to do with Twitter data before doing any heavy-duty development. The rest of this book assumes that you have a Twitter account and enough friends/followers that you have data to mine.
Note
The official Twitter account for this book is @SocialWebMining .
A minimal wrapper around Twitterâs web API is available through a
package called twitter (http://github.com/sixohsix/twitter) can be installed with
easy_install per the norm:
$ easy_install twitter
Searching for twitter
...truncated output...
Finished processing dependencies for twitterThe package also includes a handy command-line utility and IRC
bot, so after installing the module you should be able to simply type
twitter in a shell to get a usage
screen about how to use the command-line utility. However, weâll focus
on working within the interactive Python interpreter. Weâll work though
some examples, but note that you can always skim the documentation by
running pydoc from the terminal. *nix
users can simply type pydoc twitter.Twitter to view the
documentation on the Twitter class, while Windows users
need to type python -mpydoc twitter.Twitter. If you find
yourself reviewing the documentation for certain modules often, you can
elect to pass the -w option to
pydoc and write out an HTML page that you can save and
bookmark in your browser. Itâs also worth knowing that running
pydoc on a module or class brings up the inline
documentation in the same way that running the help() command in the interpreter would. Try
typing help(twitter.Twitter) in the interpreter to see for
yourself.
Without further ado, letâs find out what people are talking about
by inspecting the trends available to us through Twitterâs trends
API. Letâs fire up the interpreter and initiate a search. Try
following along with Example 1-3, and use
the help() function as needed to try to answer as many of
your own questions as possible before proceeding.
Example 1-3. Retrieving Twitter trends
>>>import twitter>>>twitter_api = twitter.Twitter(domain="api.twitter.com", api_version='1')>>>WORLD_WOE_ID = 1 # The Yahoo! Where On Earth ID for the entire world>>>world_trends = twitter_api.trends._(WORLD_WOE_ID) # get back a callable>>>[ trend['name'] for trend in world_trends()[0]['trends'] ] # iterate through the trends[u'#ZodiacFacts', u'#nowplaying', u'#ItsOverWhen', u'#Christoferdrew', u'Justin Bieber', u'#WhatwouldItBeLike', u'#Sagittarius', u'SNL', u'#SurveySays', u'#iDoit2']
Since youâre probably wondering, the pattern for using the
twitter module is simple and predictable: instantiate the
Twitter class with a base URL and then invoke methods
on the object that correspond to URL
contexts. For example, twitter_api._trends(WORLD_WOE_ID) initiates an HTTP call
to GET http://api.twitter.com/trends/1.json, which
you could type into your web browser to get the same set of results. As
further context for the previous interpreter session, this chapter was
originally drafted on a Saturday night, so itâs not a coincidence that
the trend SNL (Saturday Night Live, a popular comedy show that
airs in the United States) appears in the list. Now might be a good time
to go ahead and bookmark the official Twitter API documentation since
youâll be referring to it quite frequently.
Given that SNL is trending, the next logical step might be to grab some search results about it by using the search API to search for tweets containing that text and then print them out in a readable way as a JSON structure. Example 1-4 illustrates.
Example 1-4. Paging through Twitter search results
>>>twitter_search = twitter.Twitter(domain="search.twitter.com")>>>search_results = []>>>for page in range(1,6):...search_results.append(twitter_search.search(q="SNL", rpp=100, page=page))
The code fetches and stores five consecutive batches (pages) of results for a query (q) of SNL, with 100 results per page (rpp). Itâs again instructive to observe that
the equivalent REST query[7] that we execute in the loop is of the form http://search.twitter.com/search.json?&q=SNL&rpp=100&page=1.
The trivial mapping between the REST API and the twitter
module makes it very simple to write Python code that interacts with
Twitter services. After executing the search, the
search_results list contains five objects, each of which is a batch of 100
results. You can print out the results in a readable way for inspection
by using the json package that comes built-in as of Python
Version 2.6, as shown in Example 1-5.
Example 1-5. Pretty-printing Twitter data as JSON
>>>import json>>>print json.dumps(search_results, sort_keys=True, indent=1)[ { "completed_in": 0.088122000000000006, "max_id": 11966285265, "next_page": "?page=2&max_id=11966285265&rpp=100&q=SNL", "page": 1, "query": "SNL", "refresh_url": "?since_id=11966285265&q=SNL", "results": [ { "created_at": "Sun, 11 Apr 2010 01:34:52 +0000", "from_user": "bieber_luv2", "from_user_id": 106998169, "geo": null, "id": 11966285265, "iso_language_code": "en", "metadata": { "result_type": "recent" }, "profile_image_url": "http://a1.twimg.com/profile_images/809471978/DSC00522...", "source": "<a href="http://twitter.com/">web</a>", "text": " ...truncated... im nt gonna go to sleep happy unless i see @justin...", "to_user_id": null } ... output truncated - 99 more tweets ... ], "results_per_page": 100, "since_id": 0 }, ... output truncated - 4 more pages ... ]
Warning
As of Nov 7, 2011, the from_user_id field in each
search result does correspond to the tweet
authorâs actual Twitter id, which was previously not the case. See
Twitter
API Issue #214 for details on the evolution and resolution
of this issue.
Weâll wait until later in the book to pick apart many of the
details in this query (see Chapter 5); the
important observation at the moment is that the tweets are keyed by
results in the response. We can distill the text of the 500
tweets into a list with the following approach. Example 1-6 illustrates a double list comprehension
thatâs indented to illustrate the intuition behind it being nothing more
than a nested loop.
Example 1-6. A simple list comprehension in Python
>>>tweets = [ r['text'] \...for result in search_results \...for r in result['results'] ]
List comprehensions are used frequently throughout this book.
Although they can look quite confusing if written on a single line,
printing them out as nested loops clarifies the meaning. The result of
tweets in this particular case is equivalent to defining an
empty list called tweets and invoking
tweets.append(r['text']) in the same kind of nested loop as
presented here. See the âData
Structuresâ section in the official Python tutorial for more
details. List comprehensions are particularly powerful because they
usually yield substantial performance gains over nested lists and
provide an intuitive (once youâre familiar with them) yet terse
syntax.
One of the most intuitive measurements that can be applied to unstructured text is a metric called lexical diversity. Put simply, this is an expression of the number of unique tokens in the text divided by the total number of tokens in the text, which are elementary yet important metrics in and of themselves. It could be computed as shown in Example 1-7.
Example 1-7. Calculating lexical diversity for tweets
>>>words = []>>>for t in tweets:...words += [ w for w in t.split() ]... >>>len(words) # total words7238 >>>len(set(words)) # unique words1636 >>>1.0*len(set(words))/len(words) # lexical diversity0.22602928985907708 >>>1.0*sum([ len(t.split()) for t in tweets ])/len(tweets) # avg words per tweet14.476000000000001
Caution
Prior to Python 3.0, the division operator applies the floor function and returns an integer value (unless one of the operands is a floating-point value). Multiply either the numerator or the denominator by 1.0 to avoid truncation errors.
One way to interpret a lexical diversity of around 0.23 would be to say that about one out of every four words in the aggregated tweets is unique. Given that the average number of words in each tweet is around 14, that translates to just over 3 unique words per tweet. Without introducing any additional information, that could be interpreted as meaning that each tweet carries about 20 percent unique information. What would be interesting to know at this point is how ânoisyâ the tweets are with uncommon abbreviations users may have employed to stay within the 140 characters, as well as what the most frequent and infrequent terms used in the tweets are. A distribution of the words and their frequencies would be helpful. Although these are not difficult to compute, weâd be better off installing a tool that offers a built-in frequency distribution and many other tools for text analysis.
The Natural Language Toolkit (NLTK) is a popular module weâll use throughout this book: it delivers a vast amount of tools for various kinds of text analytics, including the calculation of common metrics, information extraction, and natural language processing (NLP). Although NLTK isnât necessarily state-of-the-art as compared to ongoing efforts in the commercial space and academia, it nonetheless provides a solid and broad foundationâespecially if this is your first experience trying to process natural language. If your project is sufficiently sophisticated that the quality or efficiency that NLTK provides isnât adequate for your needs, you have approximately three options, depending on the amount of time and money you are willing to put in: scour the open source space for a suitable alternative by running comparative experiments and benchmarks, churn through whitepapers and prototype your own toolkit, or license a commercial product. None of these options is cheap (assuming you believe that time is money) or easy.
NLTK can be installed per the norm with easy_install, but youâll need to restart the
interpreter to take advantage of it. You can use the
cPickle module to save (âpickleâ) your data before exiting
your current working session, as shown in Example 1-8.
Example 1-8. Pickling your data
>>>f = open("myData.pickle", "wb")>>>import cPickle>>>cPickle.dump(words, f)>>>f.close()>>> $easy_install nltkSearching for nltk ...truncated output... Finished processing dependencies for nltk
Warning
If you encounter an âImportError: No module named yamlâ problem
when you try to import nltk, execute an
easy_install pyYaml, which should clear it up.
After installing NLTK, you might want to take a moment to visit its official website, where you can review its documentation. This includes the full text of Steven Bird, Ewan Klein, and Edward Loperâs Natural Language Processing with Python (OâReilly), NLTKâs authoritative reference.
Among the most compelling reasons for mining Twitter data is to try to answer the question of what people are talking about right now. One of the simplest techniques you could apply to answer this question is basic frequency analysis. NLTK simplifies this task by providing an API for frequency analysis, so letâs save ourselves some work and let NLTK take care of those details. Example 1-9 demonstrates the findings from creating a frequency distribution and takes a look at the 50 most frequent and least frequent terms.
Example 1-9. Using NLTK to perform basic frequency analysis
>>>import nltk>>>import cPickle>>>words = cPickle.load(open("myData.pickle"))>>>freq_dist = nltk.FreqDist(words)>>>freq_dist.keys()[:50] # 50 most frequent tokens[u'snl', u'on', u'rt', u'is', u'to', u'i', u'watch', u'justin', u'@justinbieber', u'be', u'the', u'tonight', u'gonna', u'at', u'in', u'bieber', u'and', u'you', u'watching', u'tina', u'for', u'a', u'wait', u'fey', u'of', u'@justinbieber:', u'if', u'with', u'so', u"can't", u'who', u'great', u'it', u'going', u'im', u':)', u'snl...', u'2nite...', u'are', u'cant', u'dress', u'rehearsal', u'see', u'that', u'what', u'but', u'tonight!', u':d', u'2', u'will'] >>>freq_dist.keys()[-50:] # 50 least frequent tokens[u'what?!', u'whens', u'where', u'while', u'white', u'whoever', u'whoooo!!!!', u'whose', u'wiating', u'wii', u'wiig', u'win...', u'wink.', u'wknd.', u'wohh', u'won', u'wonder', u'wondering', u'wootwoot!', u'worked', u'worth', u'xo.', u'xx', u'ya', u'ya<3miranda', u'yay', u'yay!', u'ya\u2665', u'yea', u'yea.', u'yeaa', u'yeah!', u'yeah.', u'yeahhh.', u'yes,', u'yes;)', u'yess', u'yess,', u'you!!!!!', u"you'll", u'you+snl=', u'you,', u'youll', u'youtube??', u'youu<3', u'youuuuu', u'yum', u'yumyum', u'~', u'\xac\xac']
Note
Python 2.7 added a collections.Counter (http://docs.python.org/library/collections.html#collections.Counter)
class that facilitates counting operations. You might find it useful
if youâre in a situation where you canât easily install NLTK, or if
you just want to experiment with the latest and greatest classes
from Pythonâs standard library.
A very quick skim of the results from Example 1-9 shows that a lot more useful information is carried in the frequent tokens than the infrequent tokens. Although some work would need to be done to get a machine to recognize as much, the frequent tokens refer to entities such as people, times, and activities, while the infrequent terms amount to mostly noise from which no meaningful conclusion could be drawn.
The first thing you might have noticed about the most frequent
tokens is that âsnlâ is at the top of the list. Given that it is the
basis of the original search query, this isnât surprising at all.
Where it gets more interesting is when you skim the remaining tokens:
there is apparently a lot of chatter about a fellow named Justin
Bieber, as evidenced by the tokens @justinbieber, justin, and bieber. Anyone familiar with
SNL would also know that the occurrences of the
tokens âtinaâ and âfeyâ are no coincidence, given Tina Feyâs
longstanding affiliation with the show. Hopefully, itâs not too
difficult (as a human) to skim the tokens and form the conjecture that
Justin Bieber is a popular guy, and that a lot of folks were very
excited that he was going to be on the show on the Saturday evening
the search query was executed.
At this point, you might be thinking, âSo what? I could skim a few tweets and deduce as much.â While that may be true, would you want to do it 24/7, or pay someone to do it for you around the clock? And what if you were working in a different domain that wasnât as amenable to skimming random samples of short message blurbs? The point is that frequency analysis is a very simple, yet very powerful tool that shouldnât be overlooked just because itâs so obvious. On the contrary, it should be tried out first for precisely the reason that itâs so obvious and simple. Thus, one preliminary takeaway here is that the application of a very simple technique can get you quite a long way toward answering the question, âWhat are people talking about right now?â
As a final observation, the presence of ârtâ is also a very
important clue as to the nature of the conversations going on. The
token RT is a special symbol that is often prepended to a
message to indicate that you are retweeting it on
behalf of someone else. Given the high frequency of this token, itâs
reasonable to infer that there were a large amount of duplicate or
near-duplicate tweets involving the subject matter at hand. In fact,
this observation is the basis of our next analysis.
Tip
The token RT can be prepended to a message to
indicate that it is being relayed, or âretweetedâ in Twitter
parlance. For example, a tweet of âRT
@SocialWebMining Justin Bieber is on SNL 2nite.
w00t?!?â would indicate that the sender is retweeting information
gained via the user
@SocialWebMining . An equivalent form
of the retweet would be âJustin Bieber is on SNL 2nite. w00t?!?
Ummmâ¦(via @SocialWebMining)â.
Because the social web is first and foremost about the linkages between people in the real world, one highly convenient format for storing social web data is a graph. Letâs use NetworkX to build out a graph connecting Twitterers who have retweeted information. Weâll include directionality in the graph to indicate the direction that information is flowing, so itâs more precisely called a digraph . Although the Twitter APIs do offer some capabilities for determining and analyzing statuses that have been retweeted, these APIs are not a great fit for our current use case because weâd have to make a lot of API calls back and forth to the server, which would be a waste of the API calls included in our quota.
Tip
At the time this book was written, Twitter imposes a rate limit of 350 API calls per hour for authenticated requests; anonymous requests are limited to 150 per hour. You can read more about the specifics at http://dev.twitter.com/pages/rate-limiting. In Chapters 4 and 5, weâll discuss techniques for making the most of the rate limiting, as well as some other creative options for collecting data.
Besides, we can use the clues in the tweets themselves to reliably extract retweet information with a simple regular expression. By convention, Twitter usernames begin with an @ symbol and can only include letters, numbers, and underscores. Thus, given the conventions for retweeting, we only have to search for the following patterns:
RTfollowed by a usernameviafollowed by a username
Although Chapter 5
introduces a module specifically designed to parse entities out of
tweets, Example 1-10 demonstrates
that you can use the re module to
compile[8] a pattern and extract the originator of a tweet in a
lightweight fashion, without any special libraries.
Example 1-10. Using regular expressions to find retweets
>>>import re>>>rt_patterns = re.compile(r"(RT|via)((?:\b\W*@\w+)+)", re.IGNORECASE)>>>example_tweets = ["RT @SocialWebMining Justin Bieber is on SNL 2nite. w00t?!?",... "Justin Bieber is on SNL 2nite. w00t?!? (via @SocialWebMining)"]>>>for t in example_tweets:...rt_patterns.findall(t)... [('RT', ' @SocialWebMining')] [('via', ' @SocialWebMining')]
In case itâs not obvious, the call to findall returns a list of tuples in which
each tuple contains either the matching text or an empty string for
each group in the pattern; note that the regex does leave a leading
space on the extracted entities, but thatâs easily fixed with a call
to strip(), as demonstrated in
Example 1-11. Since neither of the example
tweets contains both of the groups enclosed in the parenthetical
expressions, one string is empty in each of the tuples.
Note
Regular expressions are a basic programming concept whose
explanation is outside the scope of this book. The re
module documentation is a good place to start getting up
to speed, and you can always consult Friedlâs classic Mastering Regular Expressions
(OâReilly) if you want to learn more than youâll probably ever
need to know about them.
Given that the tweet data structure as returned by the API provides the username of the person tweeting and the newly found ability to extract the originator of a retweet, itâs a simple matter to load this information into a NetworkX graph. Letâs create a graph in which nodes represent usernames and a directed edge between two nodes signifies that there is a retweet relationship between the nodes. The edge itself will carry a payload of the tweet ID and tweet text itself.
Example 1-11 demonstrates the process of generating such a graph. The basic steps involved are generalizing a routine for extracting usernames in retweets, flattening out the pages of tweets into a flat list for easier processing in a loop, and finally, iterating over the tweets and adding edges to a graph. Although weâll generate an image of the graph later, itâs worthwhile to note that you can gain a lot of insight by analyzing the characteristics of graphs without necessarily visualizing them.
Example 1-11. Building and analyzing a graph describing who retweeted whom
>>>import networkx as nx>>>import re>>>g = nx.DiGraph()>>> >>>all_tweets = [ tweet...for page in search_results...for tweet in page["results"] ]>>> >>>def get_rt_sources(tweet):...rt_patterns = re.compile(r"(RT|via)((?:\b\W*@\w+)+)", re.IGNORECASE)...return [ source.strip()...for tuple in rt_patterns.findall(tweet)...for source in tuple...if source not in ("RT", "via") ]... >>>for tweet in all_tweets:...rt_sources = get_rt_sources(tweet["text"])...if not rt_sources: continue...for rt_source in rt_sources:...g.add_edge(rt_source, tweet["from_user"], {"tweet_id" : tweet["id"]})... >>>g.number_of_nodes()160 >>>g.number_of_edges()125 >>>g.edges(data=True)[0](u'@ericastolte', u'bonitasworld', {'tweet_id': 11965974697L}) >>>len(nx.connected_components(g.to_undirected()))37 >>>sorted(nx.degree(g).values())[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 6, 6, 9, 37]
The built-in operations that NetworkX provides are a useful starting point to make sense of the data, but itâs important to keep in mind that weâre only looking at a very small slice of the overall conversation happening on Twitter about SNLâ500 tweets out of potentially tens of thousands (or more). For example, the number of nodes in the graph tells us that out of 500 tweets, there were 160 users involved in retweet relationships with one another, with 125 edges connecting those nodes. The ratio of 160/125 (approximately 1.28) is an important clue that tells us that the average degree of a node is approximately oneâmeaning that although some nodes are connected to more than one other node, the average is approximately one connection per node.
The call to connected_components shows us that the
graph consists of 37 subgraphs and is not fully connected. The output
of degree might seem a bit cryptic at first, but it
actually confirms insight weâve already gleaned: think of it as a way
to get the gist of how well
connected the nodes in the graph are without having to render an
actual graph. In this case, most of the values are 1, meaning all of
those nodes have a degree of 1 and are connected to only one other
node in the graph. A few values are between 2 and 9, indicating that
those nodes are connected to anywhere between 2 and 9 other nodes. The
extreme outlier is the node with a degree of 37. The gist of the graph
is that itâs mostly composed of disjoint nodes, but there is one very
highly connected node. Figure 1-1
illustrates a distribution of degree as a column chart. The trendline
shows that the distribution closely follows a Power Law and has
a âheavyâ or âlongâ tail. Although the characteristics of
distributions with long tails are by no means treated with rigor in
this book, youâll find that lots of distributions weâll encounter
exhibit this property, and youâre highly encouraged to take the
initiative to dig deeper if you feel the urge. A good starting point
is Zipfâs
law.
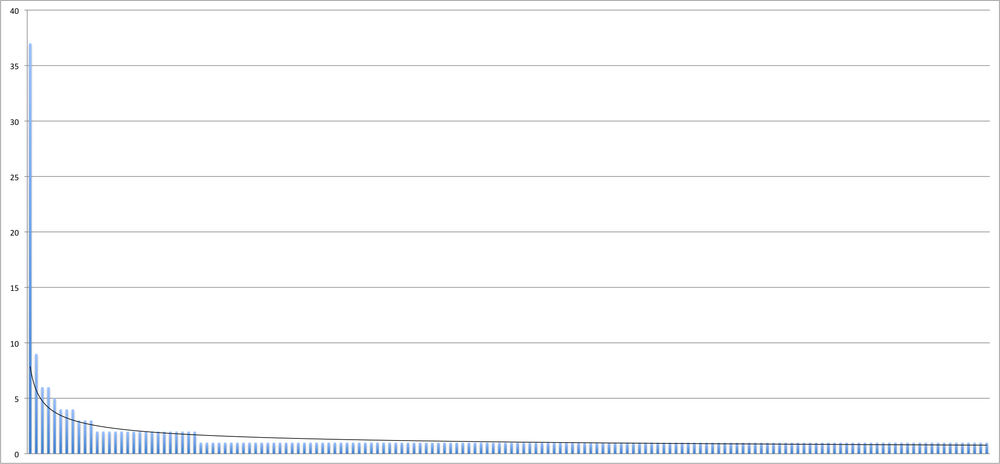
Figure 1-1. A distribution illustrating the degree of each node in the graph, which reveals insight into the graphâs connectedness
Weâll spend a lot more time in this book using automatable heuristics to make sense of the data; this chapter is intended simply as an introduction to rattle your brain and get you thinking about ways that you could exploit data with the low-hanging fruit thatâs available to you. Before we wrap up this chapter, however, letâs visualize the graph just to be sure that our intuition is leading us in the right direction.
Graphviz is a staple in the visualization community. This section
introduces one possible approach for visualizing graphs of tweet data:
exporting them to the DOT language, a
simple text-based format that Graphviz consumes. Graphviz
binaries for all platforms can be downloaded from its official website, and the
installation is straightforward regardless of platform. Once Graphviz is
installed, *nix users should be able to easy_install pygraphviz per the norm to
satisfy the PyGraphviz dependency
NetworkX requires to emit DOT. Windows users will most likely experience
difficulties installing PyGraphviz,[9] but this turns out to be of little consequence since itâs
trivial to tailor a few lines of code to generate the DOT language
output that we need in this section.
Example 1-12 illustrates an approach that works for both platforms.
Example 1-12. Generating DOT language output is easy regardless of platform
OUT = "snl_search_results.dot"
try:
nx.drawing.write_dot(g, OUT)
except ImportError, e:
# Help for Windows users:
# Not a general-purpose method, but representative of
# the same output write_dot would provide for this graph
# if installed and easy to implement
dot = ['"%s" -> "%s" [tweet_id=%s]' % (n1, n2, g[n1][n2]['tweet_id']) \
for n1, n2 in g.edges()]
f = open(OUT, 'w')
f.write('strict digraph {\n%s\n}' % (';\n'.join(dot),))
f.close()The DOT output that is generated is of the form shown in Example 1-13.
Example 1-13. Example DOT language output
strict digraph {
"@ericastolte" -> "bonitasworld" [tweet_id=11965974697];
"@mpcoelho" -> "Lil_Amaral" [tweet_id=11965954427];
"@BieberBelle123" -> "BELIEBE4EVER" [tweet_id=11966261062];
"@BieberBelle123" -> "sabrina9451" [tweet_id=11966197327];
}With DOT language output on hand, the next step is to convert it
into an image. Graphviz itself provides a variety of layout algorithms
to visualize the exported graph; circo, a tool used to render graphs in a
circular-style layout, should work well given that the data suggested
that the graph would exhibit the shape of an ego
graph with a âhub and spokeâ-style topology, with one central
node being highly connected to many nodes having a degree of 1. On a
*nix platform, the following command converts the snl_search_results.dot
file exported from NetworkX into an
snl_search_results.dot.png file that you can open
in an image viewer (the result of the operation is displayed in Figure 1-2):
$ circo -Tpng -Osnl_search_results snl_search_results.dot
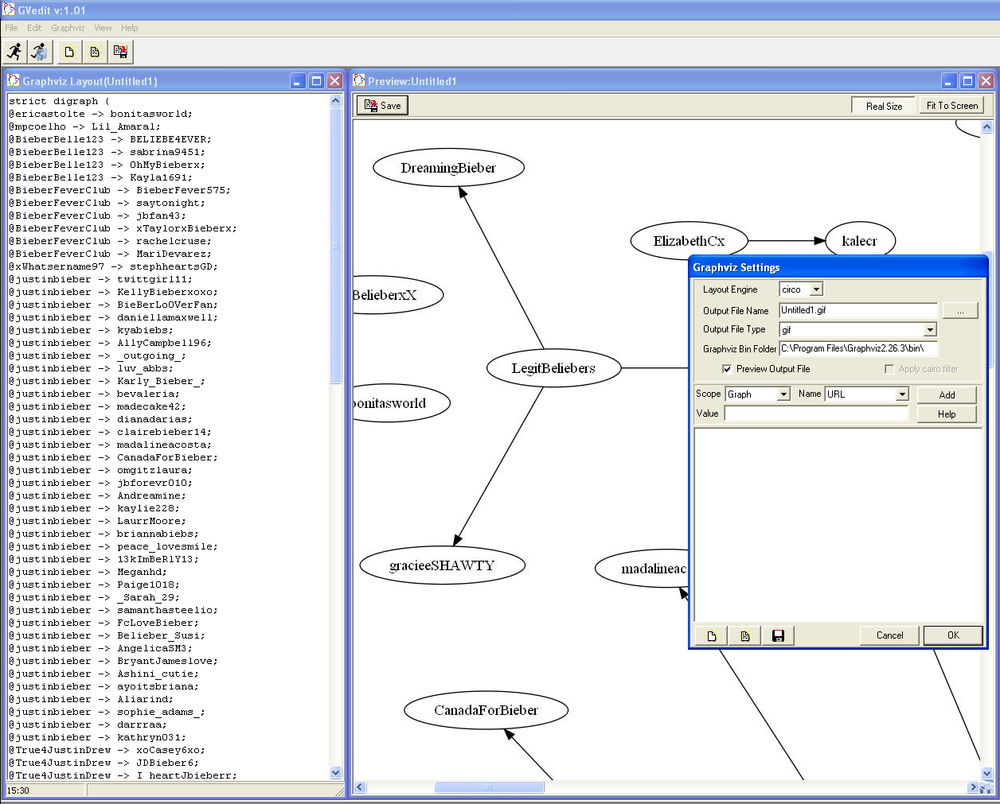
Windows users can use the GVedit application to render the file as
shown in Figure 1-3. You can read more about the various
Graphviz options in the online
documentation. Visual inspection of the entire graphic file confirms that the
characteristics of the graph align with our previous analysis, and we
can visually confirm that the node with the highest degree is @justinbieber, the subject of so much
discussion (and, in case you missed that episode of
SNL, the guest host of the evening). Keep in mind
that if we had harvested a lot more tweets, it is very likely that we
would have seen many more interconnected subgraphs than are evidenced in
the sampling of 500 tweets that we have been analyzing. Further analysis
of the graph is left as a voluntary exercise for the reader, as the
primary objective of this chapter was to get your development
environment squared away and whet your appetite for more interesting
topics.
Graphviz appears elsewhere in this book, and if you consider yourself to be a data scientist (or are aspiring to be one), it is a tool that youâll want to master. That said, weâll also look at many other useful approaches to visualizing graphs. In the chapters to come, weâll cover additional outlets of social web data and techniques for analysis.
A turn-key example script that synthesizes much of the content from this chapter and adds a visualization is how weâll wrap up this chapter. In addition to spitting some useful information out to the console, it accepts a search term as a command line parameter, fetches, parses, and pops up your web browser to visualize the data as an interactive HTML5-based graph. It is available through the official code repository for this book at http://github.com/ptwobrussell/Mining-the-Social-Web/blob/master/python_code/introduction__retweet_visualization.py. You are highly encouraged to try it out. Weâll revisit Protovis, the underlying visualization toolkit for this example, in several chapters later in the book. Figure 1-4 illustrates Protovis output from this script. The boilerplate in the sample script is just the beginningâmuch more can be done!
[7] If youâre not familiar with REST, see the sidebar RESTful Web Services in Chapter 7 for a brief explanation.
[8] In the present context, compiling a regular expression means transforming it into bytecode so that it can be executed by a matching engine written in C.
[9] See NetworkX Ticket
#117, which reveals that this has been a long-standing issue
that somehow has not garnered the support to be overcome even after
many years of frustration. The underlying issue has to do with the
need to compile C code during the easy_install process.
The ability to work around this issue fairly easily by generating
DOT language output may be partly responsible for why it has
remained unresolved for so long.
Get Mining the Social Web now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

