Unless youâve been cryogenically frozen for the past couple of years, youâve no doubt heard of Twitterâa microblogging service that can be used to broadcast short (maximum 140 characters) status updates. Whether you love it, hate it, or are indifferent, itâs undeniable that Twitter has reshaped the way people communicate on the Web. This chapter makes a modest attempt to introduce some rudimentary analytic functions that you can implement by taking advantage of the Twitter APIs to answer a number of interesting questions, such as:
How many friends/followers do I have?
Who am I following that is not following me back?
Who is following me that I am not following back?
Who are the friendliest and least friendly people in my network?
Who are my âmutual friendsâ (people Iâm following that are also following me)?
Given all of my followers and all of their followers, what is my potential influence if I get retweeted?
Warning
Twitterâs API is constantly evolving. It is highly recommended that you follow the Twitter API account, @TwitterAPI, and check any differences between the text and actual behavior you are seeing against the official docs.
This chapter analyzes relationships among Twitterers, while the next chapter hones in on the actual content of tweets. The code weâll develop for this chapter is relatively robust in that it takes into consideration common issues such as the infamous Twitter rate limits,[23] network I/O errors, potentially managing large volumes of data, etc. The final result is a fairly powerful command-line utility that you should be able to adapt easily for your own custom uses (http://github.com/ptwobrussell/Mining-the-Social-Web/blob/master/python_code/TwitterSocialGraphUtility.py).
Note
Having the tools on hand to harvest and mine your own tweets is essential. However, be advised that initiatives to archive historical Twitter data in the U.S. Library of Congress may soon render the inconveniences and headaches associated with harvesting and API rate-limiting non-issues for many forms of analysis. Firms such as Infochimps are also emerging and providing a medium for acquiring various kinds of Twitter data (among other things). A query for Twitter data at Infochimps turns up everything from archives for #worldcup tweets to analyses of how smileys are used.
The year 2010 will be remembered by some as the transition period in which Twitter started to become âall grown up.â Basic HTTP authentication got replaced with OAuth[24] (more on this shortly), documentation improved, and API statuses became transparent, among other things. Twitter search APIs that were introduced with Twitterâs acquisition of Summize collapsed into the âtraditionalâ REST API, while the streaming APIs gained increasing use for production situations. If Twitter were on the wine menu, you might pick up the 2010 bottle and say, âit was a good yearâa very good year.â All that said, thereâs a lot of useful information tucked away online, and this chapter aims not to reproduce any more of it than is absolutely necessary.
Most of the development in this chapter revolves around the social graph APIs for getting the friends and followers of a user, the API for getting extended user information (name, location, last tweet, etc.) for a list of users, and the API for getting tweet data. An entire book of its own (literally) could be written to explore additional possibilities, but once youâve learned the ropes, your imagination will have no problems taking over. Plus, certain exercises always have to be left for the âinterested reader,â right?
The Python client weâll use for Twitter is quite simply named
twitter (the same one weâve already
seen at work in Chapter 1). It provides a minimal
wrapper around Twitterâs RESTful web services. Thereâs very little
documentation about this module because you simply construct requests in
the same manner that the URL is pieced together in Twitterâs online
documentation. For example, a request from the terminal that retrieves Tim
OâReillyâs user info simply involves dispatching a request to the
/users/show resource as a curl command, as
follows:
$ curl 'http://api.twitter.com/1/users/show.json?screen_name=timoreilly'
Note
curl is a handy tool that can be used to transfer
data to/from a server using a variety of protocols, and it is
especially useful for making HTTP requests from a terminal. It comes
standard and is usually in the PATH on most *nix systems,
but Windows users may need to download
and configure it.
There are a couple of subtleties about this request. First, Twitter
has a versioned API, so the appearance of /1 as the URL
context denotes that Version 1 of the API is in use. Next, a user_id could have been passed in instead of a
screen_name had one been available. The
mapping of the curl command to the equivalent Python script
in Example 4-1 should be
obvious.
In case you havenât reviewed Twitterâs online docs yet, itâs
probably worthwhile to explicitly mention that the
/users/show API call does not require authentication, and it
has some specific peculiarities depending on whether a user has
âprotectedâ his tweets in the privacy settings. The
/users/lookup API call is very similar to
/users/show except that it requires authentication and allows
you to pass in a comma-separated list of screen_name or user_id values so that you can perform batch
lookups. To obtain authorization to use Twitterâs API, youâll need to
learn about OAuth, which is the topic of the next section.
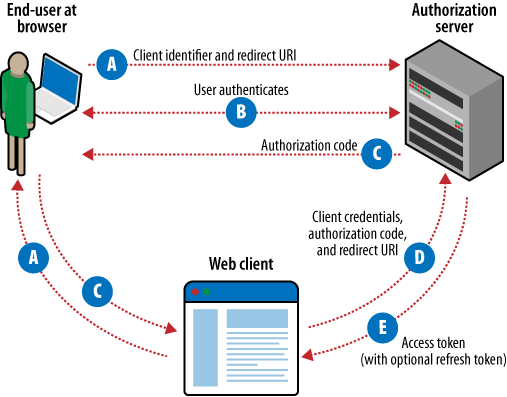
OAuth stands for âopen authorization.â In an effort to be as forward-looking as possible, this section provides a very cursory overview of OAuth 2.0, an emerging authorization scheme that Facebook has already implemented from a clean slate (see Chapter 9) and that Twitter plans to support âsoonâ. It will eventually become the new industry standard. As this book was written, Twitter and many other web services support OAuth 1.0a, as defined by RFC 5849. However, the landscape is expected to shift, with OAuth 2.0 streamlining work for developers and promoting better user experiences. While the terminology and details of this section are specific to OAuth 2.0, the basic workflow involved in OAuth 1.0a is very similar. Both schemes are âthree-leggedâ in that they involve an exchange of information (often called a âdanceâ) among a client application that needs access to a protected resource, a resource owner such as a social network, and an end user who needs to authorize the client application to access the protected resource (without giving it a username/password combination).
Note
It is purely coincidence that Twitterâs current (and only) API Version is 1.0 and that Twitter currently supports OAuth 1.0a. It is likely that Version 1 of Twitterâs API will eventually also support OAuth 2.0 when it is ready.
So, in a nutshell, OAuth provides a way for you to authorize an application to access data you have stored away in another application without having to share your username and password. The IETF OAuth 2.0 Protocol spec isnât nearly as scary as it might sound, and you should take a little time to peruse it because OAuth is popping up everywhereâespecially in the social network landscape. Hereâs the gist of the major steps involved:
You (the end user) want to authorize an application of some sort (the client) to access some of your data (a scope) thatâs managed by a web service (the resource owner).
Youâre smart and you know better than to give the app your credentials directly.
Instead of asking for your password, the client redirects you to the resource owner, and you authorize a scope for the client directly with the resource owner.
The client identifies itself with a unique client identifier and a way to contact it once authorization has taken place by the end user.
Assuming the end user authorizes the client, the client is notified and given an authorization code confirming that the end user has authorized it to access a scope.
But thereâs a small problem if we stop here: given that the client has identified itself with an identifier that is necessarily not a secret, a malicious client could have fraudulently identified itself and masqueraded as being created by a trusted publisher, effectively deceiving the end user to authorize it.
The client presents the authorization code it just received along with its client identifier and corresponding client secret to the resource owner and gets back an access token. The combination of client identifier, client secret, and authorization code ensures that the resource owner can positively identify the client and its authorization.
The access token may optionally be short-lived and need to be refreshed by the client.
The client uses the access token to make requests on behalf of the end user until the access token is revoked or expires.
Section 1.4.1 of the spec provides more details and the basis for Figure 4-1.
Again, OAuth 2.0 is a relatively new beast, and as of late 2010, various details are still being hammered out before the spec is officially published as an RFC. Your best bet for really understanding it is to sweat through reading the spec, sketching out some flows, asking yourself questions, role playing as the malicious user, etc. To get a feel for some of the politics associated with OAuth, review the Ars Technica article by Ryan Paul, âTwitter: A Case Study on How to Do OAuth Wrongâ. Also check out Eran Hammer-Lahavâs (the first author on the OAuth 2.0 Protocol working draft) response, along with the fairly detailed rebuttal by Ben Adida, a cryptography expert.
Note
As a late-breaking convenience for situations that involve what Twitter calls a âsingle-user use caseâ, Twitter also offers a streamlined fast track for getting the credentials you need to make requests without having to implement the entire OAuth flow. Read more about it at http://dev.twitter.com/pages/oauth_single_token. This chapter and the following chapter, however, are written with the assumption that youâll want to implement the standard OAuth flow.
[23] At the time of this writing, Twitter limits OAuth requests to 350 per hour and anonymous requests to 150 per hour. Twitter believes that these limits should be sufficient for most every client application, and that if theyâre not, youâre probably building your app wrong.
[24] As of December 2010, Twitter implements OAuth 1.0a, but you should expect to see support for OAuth 2.0 sometime in 2011.
Get Mining the Social Web now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

