Chapter 4. The Desktop Web
The rest of this book covers support and features for all browsers, both desktop and mobile. In the first three chapters, we talked about mobile browsers and what it takes to build a mobile web app. For the desktop, things are getting better in terms of supporting HTML5 and what this book defines as HTML5e. Comparing Table 4-1 to Table 2-2 in Chapter 2, you can see that support for the five core frameworks is exactly the same, if not better, in desktop browsers. Because of this, we can feel comfortable bringing HTML5 into our production applications today.
Browser | Geolocation | WebSocket | Web Storage | Device Orientation | Web Workers |
Safari 5+ | Yes | Yes | Yes | Unknown | Yes |
Chrome 19+ | Yes | Yes | Yes | Yes | Yes |
IE 10+ | Yes | Yes | Yes | Unknown | Yes |
Opera 12+ | Yes | Yes | Yes | No | Yes |
Firefox 12+ | Yes | Yes | Yes | Yes | Yes |
Of course, you will notice some differences in support. For example, Device Orientation may not make a lot of sense for desktop browsers, but it is supported in Chrome and Firefox browsers.
Warning
Although Geolocation does not fall under HTML5, I am including it under HTML5e because of its value to modern web apps and its wide support in most browsers.
The Browser as a Platform
To some, server-side UI frameworks, which automatically generate JavaScript, CSS, and HTML, are the saviors of enterprise development. To others, those UI frameworks create a massive bottleneck and tie you to stale ideas and structures.
Today, developers are forced to look at web application architecture from a different perspective where the browser and JavaScript are taking just as much spotlight as server-side code (or in some cases, JavaScript is the server-side code).
Client Versus Server HTML Generation
Somewhere between 2008 and 2009, the server-heavy culture of generating HTML and other resources on the backend broke down. This was mostly due to the progressive enhancement of web pages with AJAX and other performance optimizations. This way of thinking forced developers to create better APIs and more efficient ways of delivering data to web applications through JSON and XML.
Generating HTML on the client reduces server load and can deliver a better overall user experience. JSON and XML use less bandwidth than presentation-ready HTML, and there is less string concatenation and HTML escaping to perform. The client browser must download the first payload of JavaScript and markup, but after that, it’s much easier to control how resources are delivered and how the application is enhanced. This also gives you the flexibility of using CDN bandwidth for such popular libraries as jQuery. When using a CDN for resource delivery, you are betting that the user has already downloaded this library through another website using the same CDN. This spares users the bulk and expense of downloading a 33K (gzipped) library like jQuery yet again.
When everything runs on the client, however, performance is reduced. Parsing JSON or XML and generating HTML uses more memory and processing time than just printing some server-rendered HTML.
Whether you are generating HTML on the client or the server, there are pros and cons to each approach.
The client-side approach offers these benefits:
Better user experience
Network bandwidth reduction (decreases cost)
Portability (offline capable)
The most notable client-side con is security. When you create an offline-capable
application that is distributed across many different browsers, WebStorage (localStorage) is the only viable means for storing data on the
client—and it offers no security.
The pluses to using the server-side approach are:
Better security
Reduces processing expense on client (battery life on mobile, and so on)
Expandability (adding more servers can increase load capability)
Server-side rendering has its advantages, and if you are creating a web application that must be connected to the Internet at all times, then you might consider a framework that falls into this realm. When choosing a server-side framework, however, be sure that all markup is easily changeable and editable. You don’t want to be stuck with a prebuilt component that is automatically generated and does not allow you to pass through newer HTML5 attributes and tags.
Overall, the main goal between generating markup on the server or the client should be to avoid ending up with a huge mess. Most of the time, you’ll end up with a hybrid application that does some processing on the server and much more on the client. So you want to be sure that the code is properly distributed and organized. Dealing with two separate code bases that interact with each other takes special care. Using a client side MV* framework (like Backbone or Knockout) forces a clean separation of concerns when querying server APIs for data. (You’ll learn more about this topic later in the chapter.)
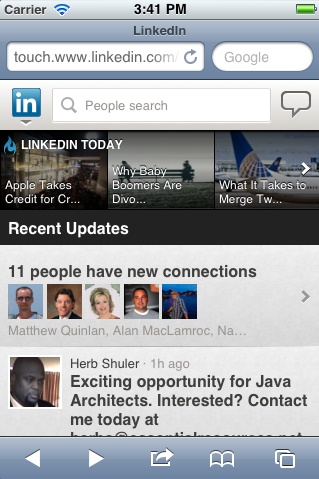
In regard to recent applications that have taken the step toward more client-side processing, LinkedIn launched its new HTML5-based mobile web app in late 2011 (Figure 4-1). The company’s mobile development lead gave the following statement in an interview (http://venturebeat.com/2011/08/16/linkedin-node):
The app is 2 to 10 times faster on the client side than its predecessor, and on the server side, it’s using a fraction of the resources, thanks to a switch from Ruby on Rails to Node.js, a server-side JavaScript development technology that’s barely a year old but already rapidly gaining traction.
With heavily used applications like LinkedIn’s mobile HTML5 web app turning to newer technologies such as Node.js and JavaScript-heavy client-side code, we can see the world of web application development evolving and changing. This world is ever-changing and will continue to change as years go by, but how do we build a performant client-side solution in today’s new world of client- and server-side technologies? Your answer is at hand. This chapter reviews everything it takes to set up the appropriate HTML5 infrastructure for your web app. Certain APIs, such as WebSockets and Web Storage, will be given more emphasis and examples in subsequent chapters. Think of this chapter as a setup script for the rest of the book.
Device and Feature Detection
The first step in delivering new HTML5-based features to your user base is actually
detecting what the browser supports. You need to communicate with the browser to see what it
supports before the page is even rendered. In the past, you were forced to detect and parse
the—sometimes unreliable—browser userAgent (UA) string and then assume you had the correct device. Today, such
frameworks as
Modernizr.js or just simple JavaScript, help you detect
client-side capabilities at a much more finely grained level.
Which detection method is best? The feature-detection approach is new, but growing, while the
approach of parsing the
userAgent string is flawed and should be handled with caution.
Even at the time of this writing, browser vendors are still getting it wrong. The userAgent
string for the latest phone-based Firefox on Android, for example, reports itself as a
tablet not a phone. Mozilla uses the exact same userAgent string
for both phones and tablets, and that string has the word “Android” in both. The key to success is
understanding how you can use each approach most effectively, either by itself or to complement the
other.
Client-Side Feature Detection
JavaScript-based feature detection is often implemented by creating a DOM element to see if it exists or behaves as expected, for example:
detectCanvas()?showGraph():showTable();functiondetectCanvas(){varcanvas=document.createElement("canvas");returncanvas.getContext?true:false;}
This snippet creates a canvas element and checks to see if it supports the getContext property. Checking a property of the created element is a must,
because browsers will allow you to create any element in the DOM, whether it’s supported or
not.
This approach is one of many, and today we have open source, community-backed frameworks that do the heavy lifting for us. Here’s the same code as above, implemented with the Modernizr framework:
Modernizr.canvas?showGraph():showTable();
Feature-detection frameworks may come at a cost, however. Suppose you are running a series of tests on the browser window before the page is rendered. This can get expensive: running the full suite of Modernizr detections, for example, can take more than 30 milliseconds to run per page load. You must consider the costs of computing values before DOM render and then modifying the DOM based on the framework’s findings. When you’re ready to take your app to production, make sure you’re not using the development version of your chosen feature detection library.
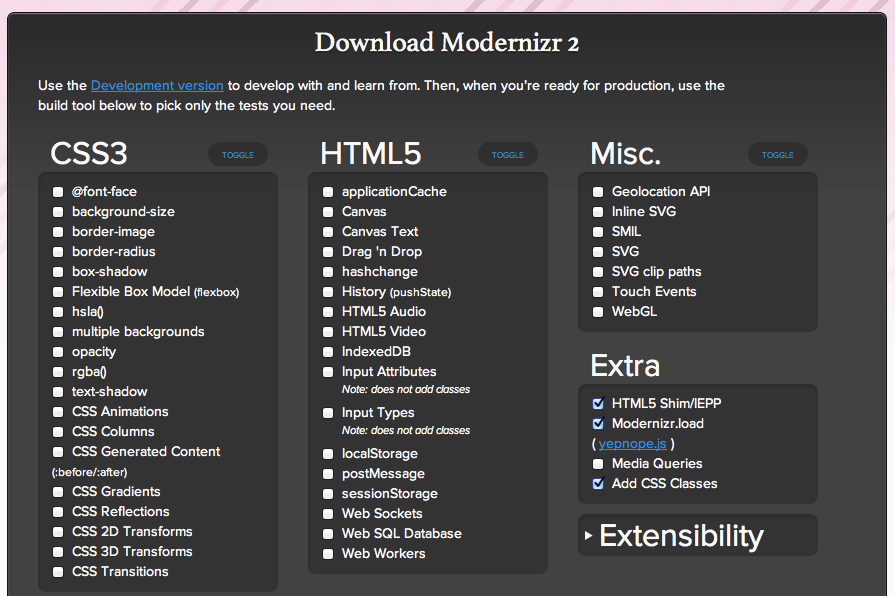
On the plus side, frameworks like Modernizr provide a build tool that enables you to pick and choose the features your app must have (Figure 4-2). You can select exactly which features you want to detect, and thereby reduce the overall detection footprint in a production environment.
Feature-detection performance also depends on the devices and browsers you are targeting. For example, running a feature-detection framework on a first-generation smartphone or old BlackBerry could crash the browser and cause your app to fail completely. Take the time to tweak feature detection to gain top performance on your target browsers.
Sometimes, as well, you may need to go a step further and detect the actual form factor of the device. FormFactor.js can help you with this. It helps you customize your web app for different form factors (a mobile version, a TV version, and the like). For example:
if(formfactor.is("tv")){alert("Look ma, Im on tv!");}if(formfactor.isnt("tv")){alert("The revolution will not be televised");}
Because FormFactor.js is a framework to manage conceptually distinct user interfaces, it doesn’t eliminate the need for feature detection. It does, however, help you to use feature detection in the context of a particular form factor’s interface.
Although the community has gone a bit inactive lately, you can find more examples at https://github.com/PaulKinlan/formfactor.
Client-Side userAgent Detection
There are times when you must detect the userAgent and parse it accordingly. Typically, you can determine
the browser by inspecting JavaScript’s
window.navigator
object or by using the userAgent request header on the
server side. This approach may work for most browsers, but it’s not dependable, as noted
in a recent bug report for the
MobileESP project:
Issue Summary: When using the Firefox browser on an Android mobile phone, the MobileESP code library erroneously reports the device as an Android tablet. An Android tablet is correctly identified as an Android tablet. This issue only affects mobile phones and similar small-screen Android devices like MP3 players (such as the Samsung Galaxy Player).
Root Cause: Mozilla uses the exact same
userAgentstring for both phones and tablets. The string has the word ‘Android’ in both. According to Google guidelines, Mozilla should include the word ‘mobile’ in theuserAgentstring for mobile phones. Unfortunately, Mozilla is not compliant with Google’s guidelines. The omission of the word ‘mobile’ is the reason why phones are erroneously identified as tablets.
So if userAgent detection isn’t always
dependable, when is it a good choice to use?
When you know, ahead of time, which platforms you are supporting and their UA strings report correctly. For example, if you care about only the environment (not its features) your application is running in, such as iOS, you could deliver a custom UI for that environment only.
When you use it in combination with feature-detection JavaScript that calls only the minimum functions needed to check the device. For example, you may not care about the discrepancy in the reported string, because it’s unneeded information. You might only care that it reports TV, and everything else is irrelevant. This also allows for “light” feature detection via JavaScript.
When you don’t want all JavaScript-based feature tests to be downloaded to every browser and executed when optimizations based on
userAgent-sniffing are available.
Yahoo! has its own reasons for using userAgent
detection:
At Yahoo we have a database full of around 10,000 mobile devices. Because
userAgentstrings vary even on one device (because of locale, vendor, versioning, etc.), this has resulted in well over a half a million user agents. It’s become pretty crazy to maintain, but is necessary because there’s really no alternative for all these feature phones, which can’t even run JavaScript.
On the other hand, Google and other companies opt for a JavaScript-based (also ported
to node.js) userAgent parser
internally. It’s a wrapper for an approximately 7Kb JSON file, which can be used in other languages.
You can find more information at https://github.com/Tobie/Ua-parser, but here is a
snippet:
varuaParser=require('ua-parser');varua=uaParser.parse(navigator.userAgent);console.log(ua.tostring());// -> "Safari 5.0.1"console.log(ua.toVersionString());// -> "5.0.1"console.log(ua.toFullString());// -> "Safari 5.0.1/Mac OS X"console.log(ua.family);// -> "Safari"console.log(ua.major);// -> 5console.log(ua.minor);// -> 0console.log(ua.patch);// -> 1console.log(ua.os);// -> Mac OS X
Another platform detection library written in JavaScript is
Platform.js. It’s used by jsperf.com for userAgent detection. Platform.js has been tested in at least Adobe AIR 2.6, Chrome 5–15,
Firefox 1.5–8, IE 6–10, Opera 9.25–11.52, Safari 2–5.1.1, Node.js 0.4.8–0.6.1, Narwhal 0.3.2, RingoJS 0.7–0.8, and Rhino 1.7RC3. (For more
information, see https://github.com/Bestiejs/Platform.js.)
The following example shows the results returned from various browsers when using Platform.js:
// on IE10 x86 platformpreviewrunninginIE7compatibilitymodeon// Windows 7 64 bit editionplatform.name;// 'IE'platform.version;// '10.0'platform.layout;// 'Trident'platform.os;// 'Windows Server 2008 R2 / 7 x64'platform.description;// 'IE 10.0 x86 (platform preview; running in IE 7 mode) on WindowsServer2008R2/7x64'// or on an iPadplatform.name; // 'Safari'platform.version; // '5.1'platform.product; // 'iPad'platform.manufacturer; // 'Apple'platform.layout; // 'WebKit'platform.os; // 'iOS5.0'platform.description; // 'Safari5.1onAppleiPad(iOS5.0)'// or parsing a given UA stringvar info = platform.parse('Mozilla/5.0(Macintosh;IntelMacOSX10.7.2;en;rv:2.0)Gecko/20100101Firefox/4.0Opera11.52');info.name; // 'Opera'info.version; // '11.52'info.layout; // 'Presto'info.os; // 'MacOSX10.7.2'info.description; // 'Opera11.52(identifyingasFirefox4.0)onMacOSX10.7.2'
Server-Side userAgent Detection
On the server side,
MobileESP is an open
source framework, which detects the userAgent header.
This gives you the ability to direct the user to the appropriate page and allows other
developers to code to supported device features.
MobileESP is available in six languages:
PHP
Java (server side)
ASP.NET (C#)
JavaScript
Ruby
Classic ASP (VBscript)
In Java, you would use:
userAgentStr=request.getHeader("user-agent");httpAccept=request.getHeader("Accept");uAgentTest=newUAgentInfo(userAgentStr,httpAccept);If(uAgentTest.detectTierIphone()){...//Perform redirect}
In PHP, the code would be:
<?php//Load the Mobile Detection libraryinclude("code/mdetect.php");//In this simple example, we'll store the alternate home page// file names.$iphoneTierHomePage='index-tier-iphone.htm';//Instantiate the object to do our testing with.$uagent_obj=newuagent_info();//In this simple example, we simply re-route depending on// which type of device it is.//Before we can call the function, we have to define it.functionAutoRedirectToProperHomePage(){global$uagent_obj,$iphoneTierHomePage,$genericMobileDeviceHomePage,$desktopHomePage;if($uagent_obj->isTierIphone==$uagent_obj->true)//Perform redirect}
So there you have it, userAgent detection is unreliable and
should be used with caution or for specific cases only. Even in the scenario descripted by the
Android/Firefox bug report, for example, you could still implement userAgent detection and then use feature detection to find the maximum screen size for
Android-based mobile phones using CSS Media Queries. There’s always a workaround, and problems such
as these should not deter you from using the userAgent string.
Compression
Compression of resources is mandatory in today’s mobile-first priority. If you aren’t concerned with the size of your HTML, JavaScript, and CSS files, you should be. HTTP compression is used to achieve a minimal transfer of bytes over a given web-based connection. This reduces response times by reducing the size of the HTTP response. The two commonly used HTTP compression schemes on the Web today are DEFLATE and GZIP (more on these coming up).
When you gain performance on the client side, however, it’s easy to forget about increased overhead on your server resources. If you have complex SQL queries that increase the CPU load to present certain pages, you should analyze the effects of using HTTP compression when these scenarios occur. Compressing a huge page that surpasses 20 to 30K may have a negative effect on your application’s performance. In this case, the expense of compressing the data will be completely dwarfed by the expense of the SQL work on the server side. A few other considerations to take into account before flipping the compression switch on every request are:
Ensure you are compressing only compressible content and not wasting resources trying to compress uncompressible content
Select the correct compression scheme for your visitors
Configure the web server properly so compressed content is sent to capable clients
So, what should be compressed? Along with the obvious resources such as HTML, JavaScript, and CSS, several common text resource types should be served with HTTP compression:
XML.
JSON.
News feeds (both RSS and Atom feeds are XML documents).
HTML Components (HTC). HTC files are a proprietary Internet Explorer feature that package markup, style, and code information used for CSS behaviors. HTC files are often used by polyfills, such as Pie or iepngfix.htc, to fix various problems with IE or to back port modern functionality.
Plain text files can come in many forms, from README and LICENSE files, to Markdown files. All should be compressed.
A text file used to tell search engines what parts of the website to crawl, Robots.txt often forgotten, because it is not usually accessed by humans. Because robots.txt is repeatedly accessed by search engine crawlers and can be quite large, it can consume large amounts of bandwidth without your knowledge.
Anything that isn’t natively compressed should be allowed through HTTP compression. HTTP compression isn’t just for text resources and should be applied to all nonnatively compressed file formats. For example, Favicons (ICO), SVG, and BMP image files are not natively compressed. ICO files are served up as an icon for your site in the URL bar or tab of most browsers, so be sure these filed receive HTTP compression.
GZIP Versus DEFLATE
The top two HTTP compression schemes are by far GZIP and DEFLATE. GZIP was developed
by the GNU project and standardized by RFC 1952. GZIP is the most popular
compression method currently available and generally reduces the response size by about
70%. DEFLATE is a patent-free compression algorithm for lossless data compression. There
are numerous open source implementations of the algorithm.
Apache’s mod_deflate module is one implementation
that many developers are familiar with.
Note
To learn more about the differences between GZIP and DEFLATE compression, see Billy Hoffman’s excellent article at http://zoompf.com/2012/02/lose-the-wait-http-compression.
Approximately 90% of today’s Internet traffic travels through browsers that claim to
support GZIP. All browsers supporting DEFLATE also support GZIP, but all browsers that
support GZIP do not support DEFLATE. Some browsers, such as Android, don’t include DEFLATE
in their Accept-Encoding request header. Because you
are going to have to configure your web server to use GZIP anyway, you might as well avoid
the whole mess with Content-Encoding: deflate.
The Apache module that handles all HTTP compression is mod_deflate. Despite its name, mod_deflate doesn’t support DEFLATE at all. It’s impossible to
get a stock version of Apache 2 to send either raw DEFLATE or zlib-wrapped DEFLATE. Nginx, like Apache, does not support DEFLATE at all and
sends only GZIP-compressed responses. Sending an Accept-Encoding:
deflate request header will result in an uncompressed response.
If you use Apache, the module configuring GZIP depends on your version: Apache 1.3 uses mod_gzip,
while Apache 2.x uses mod_deflate. Again, despite the naming convention, both use GZIP
under the hood.
The following is a simple example of how to match certain file types to include in HTTP compression. You would place it in the .htaccess file in Apache 2.4:
AddOutputFilterByType DEFLATE text/html text/plain text/xml
Here’s a more complex example that deals with browser inconsistencies can be set as follows to compress everything except images:
<Location /> # Insert filter SetOutputFilter DEFLATE # Netscape 4.x has some problems... BrowserMatch ^Mozilla/4 gzip-only-text/html # Netscape 4.06-4.08 have some more problems BrowserMatch ^Mozilla/4\.0[678] no-gzip # MSIE masquerades as Netscape, but it is fine BrowserMatch \bMSIE !no-gzip !gzip-only-text/html # Don't compress images SetEnvIfNoCase Request_URI \.(?:gif|jpe?g|png)$ no-gzip dont-vary # Make sure proxies don't deliver the wrong content Header append Vary User-Agent env=!dont-vary </Location>
The community project HTML5Boilerplate.com contains an excellent example of an optimized .htaccess file. It’s specifically crafted for web performance optimizations. It provides a great starting point for implementing HTTP compression properly. It also serves as a nice guide to compare to an existing web server configuration to verify you are following best practices (https://github.com/h5bp/html5-boilerplate/blob/master/.htaccess).
You can view most other major server configurations for HTTP compression in the github repository for HTML5Boilerplate (https://github.com/h5bp/server-configs), as well as Figure 4-3. Some of the configurations included are:
Node.js
IIS
Nginx
lighttpd
Google App Engine
After you think you have properly configured your web server from a compression and
optimization point of view, you must validate it. Web
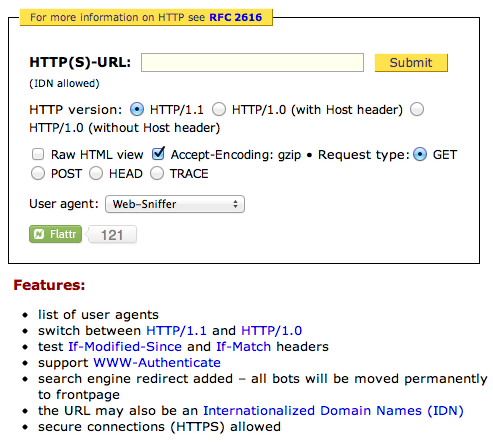
Sniffer is an excellent, free, web-based tool that
enables you make individual HTTP requests and see the responses. As you can see in Figure 4-4,
Web Sniffer gives you some control over the userAgent
and Accept-Encoding headers to ensure that compressed content is
delivered properly.
Minification
The need for JavaScript and CSS compression to keep bandwidth and page load times as small as possible is becoming more important to ensuring faster load times and more enjoyable user experiences. Minification is the process of removing all unnecessary characters from source code, without changing its functionality.
JavaScript and CSS resources may be minified, preserving their behavior while considerably reducing their file size. Some libraries also merge multiple script files into a single file for client download. This fosters a modular approach to development and limits HTTP requests.
Google has released its Closure Compiler tool, which provides minification as well as the ability to introduce more aggressive renaming. It also can remove dead code and provide function inlining. In addition, certain online tools, such as Microsoft Ajax Minifier, the Yahoo! YUI Compressor, and Pretty Diff, can compress CSS files. Some of your choices are:
- JSMin
JSMin is a conservative compressor, written several years ago by Douglas Crockford. It is a filter that removes comments and unnecessary whitespace from JavaScript files. It typically reduces file size by half, resulting in faster downloads. It also encourages a more expressive programming style, because it eliminates the download cost of clean, literate self-documentation. It’s recommended you use JSLint before minimizing your JavaScript with JSMin.
- Packer
Packer, by Dean Edwards, is also a very popular JavaScript compressor, which can go beyond regular compression and also add advanced on-the-fly decompression with a JavaScript runtime piece. For example, Packer can optionally base64 compress the given source code in a manner that can be decompressed by regular web browsers, as well as shrink variable names that are typically 5 to 10 characters to single letters, which reduces the file size of the script and, therefore, makes it download faster.
- Dojo ShrinkSafe
Dojo ShrinkSafe is a very popular Java-based JavaScript compressor that parses the JavaScript using the Rhino library and crunches local variable names.
- YUI Compressor
The YUI Compressor is a newer compressor written by Julien Lecomte that aims to combine the safety of JSMin with the higher compression levels achieved by Dojo ShrinkSafe. Like Dojo ShrinkSafe, it is written in Java and based on the Rhino library.
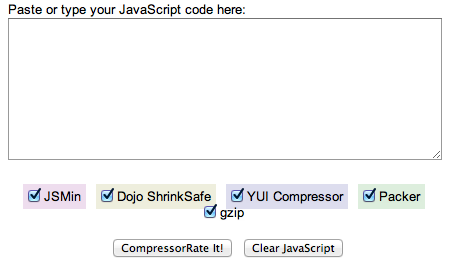
How do you choose a minifier? CompressorRater (http://compressorrater.thruhere.net/) can help. CompressorRater is a tool to rate and evaluate all of the aforementioned minification tools at one time (Figure 4-5).
Bringing it all together
As you’ve seen, there are many tools and options to choose from when minifying and concatenating your code. Fortunately, there has been a recent community effort to bring all of these projects together into one common build tool: it’s called grunt.
More than a simple minifier, grunt (https://github.com/cowboy/grunt) is a task-based command-line build tool for frontend projects. With it, you can concatenate files, validate files with JSHint, and minify with UglifyJS. In addition, grunt enables your project to run headless QUnit tests with a PhantomJS instance.
grunt is available as an npm (node-packaged module), which is the nodejs way of managing installable packages (http://npmjs.org). If you install grunt globally with:
npm install -g grunt
it will be available for use in all of your projects. Once grunt has been installed,
you can type grunt --help at the command line for
more information. Then, your available tasks are:
concatConcatenate files
initGenerate project scaffolding from a predefined template
lintValidate files with JSHint
minMinify files with UglifyJS
qunitRun QUnit unit tests in a headless PhantomJS instance
serverStart a static web server
testRun unit tests with nodeunit)
watchRun predefined tasks whenever watched files change
The following code is an example of a very basic sample grunt.js file that handles project configuration, loading a grunt plug-in, and a default task:
module.exports=function(grunt){// Project configuration.grunt.initConfig({lint:{all:['grunt.js','lib/**/*.js''test/**/*.js']},jshint:{options:{browser:true}}});// Load tasks from "grunt-sample" grunt plugin installed via Npm.grunt.loadNpmTasks('grunt-sample');// Default task.grunt.registerTask('default','lint sample');};
You can easily set up a new grunt project by using the grunt init command. There are a few different templates for various types of projects including
CommonJS, jQuery, and Node.js.
As an example, try running grunt on the slidfast.js library used in the previous chapters. From the root of the project, in the terminal, run:
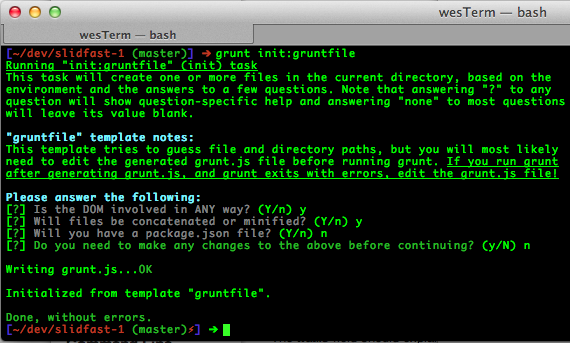
grunt init:gruntfile
This customizable template (Figure 4-6) creates a single grunt.js file based on your answers to a few questions. Grunt also tries to determine source, unit test, and other system paths using it’s own environment detection.
Each time grunt runs, it looks in the current directory for a file named grunt.js. If this file is not found, grunt continues looking in parent directories until that file is found. This file is typically placed in the root of your project repository, and is a valid JavaScript file composed of three parts:
Project configuration
Loading grunt plug-ins or tasks folders
Tasks and helpers
This is what the grunt.js looks like for the slidfast.js JavaScript project (which only includes HTML, CSS, and JavaScript files):
/*global module:false*/module.exports=function(grunt){// Project configuration.grunt.initConfig({meta:{version:'0.1.0',banner:'/*! PROJECT_NAME - v<%= meta.version %> - '+'<%= grunt.template.today("yyyy-mm-dd") %>\n'+'* http://PROJECT_WEBSITE/\n'+'* Copyright (c) <%= grunt.template.today("yyyy") %> '+'YOUR_NAME; Licensed MIT */'},lint:{files:['grunt.js','slidfast.js']},// qunit: {// files: ['example/**/*.html']// },concat:{dist:{src:['<banner:meta.banner>','<file_strip_banner:slidfast.js>'],dest:'dist/slidfast.js'}},min:{dist:{src:['<banner:meta.banner>','<config:concat.dist.dest>'],dest:'dist/slidfast.min.js'}},watch:{files:'<config:lint.files>',tasks:'lint qunit'},jshint:{options:{curly:true,eqeqeq:true,immed:true,latedef:true,newcap:true,noarg:true,sub:true,undef:true,boss:true,eqnull:true,browser:true},globals:{}},uglify:{}});// Default task.grunt.registerTask('default','lint concat min');};
Note
Because no QUnit tests are currently defined for this project, I commented out the default values and removed it from the last line in the file.
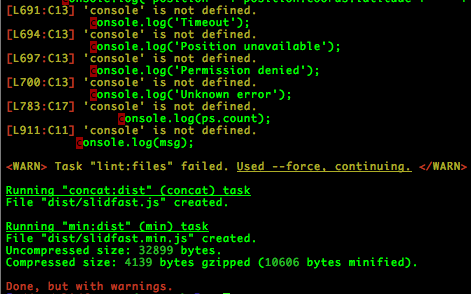
Now, if you run grunt within your project by simply typing grunt at the command line, grunt returns a log like the one in Figure 4-7. As you can see in the example log, grunt lists
where the JavaScript lint fails. In addition, because this example bypassed the lint process by
using grunt -force, grunt was able to continue minifying the
files and display the before and after size of the files.
Two more multipurpose tools useful for minifying are Jawr and Ziproxy.
Jawr is a tunable packaging solution for JavaScript and
CSS that allows for rapid development of resources in separate module files. You can work with a
large set of split JavaScript files in development mode, then Jawr bundles them all together into
one or several files in a configurable way. By using a tag library, Jawr enables you to use the
same, unchanged pages for development and production. Jawr also minifies and compresses the files,
resulting in reduced page load times. You can configure Jawr using a simple .properties descriptor. Besides standard Java web applications, it can also be used with
Facelets and Grails applications.
Ziproxy (http://ziproxy.sourceforge.net) is a forwarding, noncaching, compressing HTTP proxy targeted for traffic optimization. It minifies and optimizes HTML, CSS, and JavaScript resources, plus recompresses pictures. Basically, it squeezes images by converting them to lower quality JPEGs or JPEG 2000 and compresses (via GZIP) HTML and other text-like data. In addition, it provides such features as preemptive hostname resolution, transparent proxying, IP ToS marking (QoS), Ad-Blocker, detailed logging, and more. Ziproxy does not require client software and provides acceleration for any web browser on any OS.
JavaScript MVC Frameworks and the Server
With the myriad of JavaScript MV* (aka MVC) frameworks popping up over the past few years, it’s important to get a high-level view of what frameworks are available today and how they support some form of server-side interaction.
In theory, JavaScript frameworks offer developers an easy path to organizing code.
After a few years of attempting to manually organize AJAX/jQuery callbacks, the
development community recognized the need to create frameworks around frontend code.
Developers realized that complex client-side applications do not scale with spaghetti code
and that keeping up with manually bound, AJAX-returned data using innerHTML() can get quite messy. So the solution was to use
variations of a pattern known as MVC
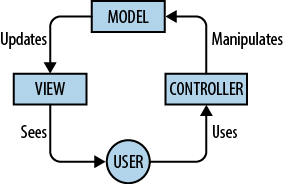
(Model-View-Controller). MVC separates the concerns in an application
down into three parts:
Models
Views
Controllers
Although JavaScript MVC frameworks help us structure our code, they don’t always strictly follow the classic pattern shown in Figure 4-8. Some frameworks will include the responsibility of the controller in the view such as Backbone.js, while others add their own opinionated components into the mix, as they feel this is more effective.
For this reason, I refer to such frameworks as following the MV* pattern; that is, you’re likely to have a view and a model, but more likely to have something else also included. If your goal is to learn the basics of each MV* framework on the market today, TodoMVC (Figure 4-9) provides implementations of a to-do app in more frameworks than anyone has time to learn. Currently there are around 40 JavaScript MV* frameworks in existence. Choosing the right framework for a given project is the start of your journey.
The Top Five Frameworks
Before you can decide which framework is best for your project, you need to know how they perform. The following sections focus on how each of the five leading frameworks handles server-side collections of objects rendered to the DOM. Data interaction is important for two main reasons:
Binding objects to the UI must be declarative, and the view layer should autoupdate as changes to the model occur.
It’s easy to create JavaScript-heavy applications that end up as a tangled mess of jQuery, RESTful endpoints, and callbacks. A structured MVC approach makes code more maintainable and reusable.
For each framework, I’ll evaluate persistence strategies, identify JavaScript frameworks that are server agnostic, and use transports such as HTTP (for RESTful endpoints) and other protocols such as WebSockets. This section assumes you already have a basic idea of what a JavaScript MV* framework is and does. I will not go into details on how well each framework implements the original Smalltalk MVC pattern, rather the discussions focus on how each framework synchronizes data from the server to the client and vice versa.
Note
Choosing the right framework and using it well comes down to knowing what you need. Beyond the five frameworks I review in this section, there are many others you can use in your application. Weigh out the pros and cons of each one, and find the right development model for your targeted application.
Backbone
Backbone.js is today’s framework of choice, and for good reason; an impressive list of brands, such as Foursquare, Posterous, Groupon (Figure 4-10), and many others have built JavaScript applications with Backbone.
Backbone uses Underscore.js heavily and gives developers the options of using jQuery or Zepto for the core DOM framework. It also boasts a healthy community and strong word of mouth (Figure 4-11).
With Backbone, you represent your data as models, which can be created,
validated, destroyed, and saved to the server. Whenever a UI action causes an attribute of a model
to change, the model triggers a change event; all the views that
display the model’s state can be notified of the change so that they are able to respond
accordingly, rerendering themselves with the new information. In a finished Backbone app, you don’t
have to write the glue code that looks into the DOM to find an element with a specific ID and update
the HTML manually. When the model changes, the views simply update themselves.
In the end, Backbone is better suited for larger frameworks and applications. If you are writing a simple application that needs the structure of MVC, you will end up writing a lot of code to present a simple interface.
Note
Each framework discussion gives a demo hosted in this book’s github repository. For Backbone, you can find the following RESTful demo written in Java at https://github.com/html5e/backbone-jax-cellar.
Backbone server synchronization
If your backend data is exposed through a pure RESTful API, retrieving (GET), creating (POST), updating
(PUT), and deleting (DELETE)
models is incredibly easy using the Backbone.js simple Model API. For
example:
// Modelswindow.Book=Backbone.Model.extend({urlRoot:"/api/books",defaults:{"id":null,"name":"HTML5 Architecture",}});window.BookCollection=Backbone.Collection.extend({model:Book,url:"/api/books"});
In the above code, the urlRoot for window.Book is the RESTful service endpoint to retrieve or persist model data. Note that
this attribute is needed only when retrieving or persisting models that are not part of a
collection. If the Model is part of a collection, the url attribute defined in the collection is enough for Backbone to know how to retrieve,
update, or delete data using your RESTful API.
In window.BookCollection, url provides the endpoint for the RESTFul API. This is all
that’s needed to retrieve, create, update, and delete with Backbone’s simple Model
API.
If your persistence layer is not available through RESTful services, or if you would like to
use a different transport mechanism such as WebSockets, you can override Backbone.sync.
Backbone.sync is the function that Backbone calls every
time it attempts to read or save a model to the server. By default, it uses jQuery or Zepto to make
a RESTful JSON request. You can override it to use a different persistence strategy, such as
WebSockets, XML transport, or localStorage. With the default
implementation, when Backbone.sync sends up a request to save a
model, its attributes will be passed, serialized as JSON, and sent in the HTTP body with content-type application/json. The default sync handler maps CRUD to REST
like so:
create -> POST /collection read -> GET /collection[/id] update -> PUT /collection/id delete -> DELETE /collection/id
Backbone and legacy servers
If you must work with a legacy web server that doesn’t support Backbones’s default
REST/HTTP approach, you may choose to turn on Backbone.emulateHTTP. Setting this option will fake PUT and DELETE requests with
a HTTP POST, setting the X-HTTP-Method-Override header with the true method. If emulateJSON
is also on, the true method will be passed as an
additional _method parameter. For example:
Backbone.emulateHTTP=true;model.save();// POST to "/collection/id", with "_method=PUT" + header.
If you’re working with a web server that can’t handle requests encoded as application/JSON,
setting Backbone.emulateJSON = true; will cause the JSON to be
serialized under a model parameter, and the request to be made with a application/x-www-form-urlencoded mime type, as if from an HTML form.
Ember
Ember.js (formerly Amber.js and SproutCore 2.0) is one of the newest contenders. It is an attempt to extricate the core features from SproutCore 2.0 into a more compact modular framework suited for the Web. It’s also well known for gracefully handling DOM updates and has a respectable following on github (Figure 4-12).
Ember is what happened when SproutCore decided to be less Apple Cocoa and more jQuery. The result is a web framework that retains important high-level concepts, such as observers, bindings, and state charts, while delivering a concise API. SproutCore started its life as the development framework behind an early client-side email application. Then, Apple used it to build MobileMe (and then iCloud), both of which include email clients. Needless to say, Apple has figured out that collections that update from the server are very important.
Unlike Backbone, Ember requires less wiring of things together; for example, point a view at an array, and it will automatically be rerendered as the array is manipulated. Ember’s binding system and tight integration with the Handlebars.js templating language makes this possible.
Note
For a RESTful demo, written in Ruby, to demonstrate Ember’s server synchronization, view this repository: https://github.com/html5e/ember_data_example.
Ember server synchronization
Ember Data is a library for loading models from a persistence layer (such as a JSON API), updating those models, and then saving the changes. It provides many of the facilities you find in such server-side ORMs as ActiveRecord, but it is designed specifically for the unique environment of JavaScript in the browser. Here is a brief example of storing data with Ember:
// our modelApp.Person=Ember.Object.extend();App.people=Ember.ArrayController.create({content:[],save:function(){// assuming you are using jQuery, but could be other AJAX/DOM framework$.post({url:"/people",data:JSON.stringify(this.toArray()),success:function(data){// your data should already be rendered with latest changes// however, you might want to change status from something to "saved" etc.}});}});
The next step in your code would be a call to App.people.save() to persist the data.
Angular
A nice framework developed by Googlers Angular.js, has some very interesting design choices, most namely Dependency Injection (or IOC) for JavaScript. Dependency Injection makes your code easier to test and pushes object creation and wiring as high up in the application as possible, which gives you one central location for the flow of logic.
Angular is well thought out with respect to template scoping and controller design. It supports a rich UI-binding syntax to make operations like filtering and transforming values easy. On github, Angular is a heavily watched project and has a healthy community contributing to it (Figure 4-13).
Note
For a RESTful demo written with Node.js to demonstrate Angular’s server synchronization capabilities, see https://github.com/html5e/angular-phonecat-mongodb-rest.
Angular server synchronization
The Angular model is referenced from properties on Angular scope objects. The data in your model could be JavaScript objects, arrays, or primitives; it doesn’t matter. What matters is that these are all referenced by the scope object. Angular employs scopes to keep your data model and your UI in sync. Whenever something occurs to change the state of the model, Angular immediately reflects that change in the UI and vice versa.
Note
When building web applications, your design needs to consider security threats from JSON vulnerability and XSRF. Both the server and client must cooperate to eliminate these threats. Angular comes preconfigured with strategies that address these issues, but for this to work, backend server cooperation is required.
This simple example illustrates how to retrieve and save data with Angular’s default
CRUD methods (.get, .save, .delete, and .query):
// Define CreditCard classvarCreditCard=$resource('/user/:userId/card/:cardId',{userId:123,cardId:'@id'},{charge:{method:'POST',params:{charge:true}}});// We can retrieve a collection from the servervarcards=CreditCard.query();// GET: /user/123/card// server returns: [ {id:456, number:'1234', name:'Smith'} ];varcard=cards[0];// each item is an instance of CreditCardexpect(cardinstanceofCreditCard).toEqual(true);card.name="J. Smith";// non GET methods are mapped onto the instancescard.$save();// POST: /user/123/card/456 {id:456, number:'1234', name:'J. Smith'}// server returns: {id:456, number:'1234', name: 'J. Smith'};
For more details see:
Batman
Created by Shopify, Batman.js is another framework similar to Knockout and Angular. It has a nice UI binding system based on HTML attributes and is the only framework written in coffeescript. Batman.js is also tightly integrated with Node.js and even goes to the extent of having its own (optional) Node.js server. At this time, its following is still relatively small on github in comparison to the others (Figure 4-14).
Note
For a RESTful application that demonstrates Batman’s server synchronization, see the HTML5e Batman repository.
Batman server synchronization
A Batman.js model object may have arbitrary properties set on it, just like any JS object. Only some of those properties are serialized and persisted to its storage backends. Models have the ability to:
Persist to various storage backends
Only serialize a defined subset of their properties as JSON
Use a state machine to expose life cycle events
Validate with synchronous or asynchronous operations
You define persisted attributes on a model with the encode macro:
classArticleextendsBatman.Model@encode'body_html','title','author','summary_html','blog_id','id','user_id'@encode'created_at','updated_at','published_at',Batman.Encoders.railsDate@encode'tags',encode:(tagSet) ->tagSet.toArray().join(', ')decode:(tagString) ->newBatman.Set(tagString.split(', ')...)
Given one or more strings as arguments, @encode will
register these properties as persisted attributes of the model, to be serialized in the model’s
toJSON() output and extracted in its fromJSON(). Properties that aren’t specified with @encode will be ignored for both serialization and deserialization. If an optional coder
object is provided as the last argument, its encode and decode functions will be used by the Model
for serialization and deserialization, respectively.
By default, a model’s primary key (the unchanging property that uniquely indexes its
instances) is its id property. If you want your model to have a
different primary key, specify the name of the key on the primaryKey class property:
classUserextendsBatman.Model@primaryKey:'handle'@encode'handle','email'
To specify a storage adapter for persisting a model, use the @persist macro in its class definition:
classProductextendsBatman.Model@persistBatman.LocalStorage
Now when you call save() or load() on a product, it will use the browser window’s localStorage to retrieve or store the serialized data.
If you have a REST backend you want to connect to, Batman.RestStorage is a simple storage adapter that you can subclass and extend to suit
your needs. By default, it assumes your camelcased-singular product model is accessible at the
underscored-pluralized /products path,
with instances of the resource accessible at /products/:id. You can override these path defaults by assigning either a
string or a function-returning a-string to the url property of
your model class (for the collection path) or to the prototype (for the member path). For
example:
classProductextendsBatman.Model@persistBatman.RestStorage@url ="/admin/products"url:->"/admin/products/#{@id}"
Knockout
Knockout.js is built around three core features:
Observables and dependency tracking
Declarative bindings
Templating
Knockout is designed to allow the use of arbitrary JavaScript objects as viewModels. As long as some of your viewModel’s properties are observables, you can use Knockout to
bind them to your UI, and the UI will be updated automatically whenever the observable
properties change. Figure 4-15 shows Knockout
to have a good following of users and commit logs are active.
Note
For a full demo on how to use Knockout’s server synchronization, view this tutorial.
Knockout server synchronization
Observables are declared on model properties. They allow automatic updates to the UI when the model changes:
varviewModel={serverTime:ko.observable(),numUsers:ko.observable()}
Because the server doesn’t have any concept of observables, it will just supply a plain JavaScript object (usually serialized as JSON).
You could manually bind this viewModel to some
HTML elements as follows:
The time on the server is:<spandata-bind='text: serverTime'></span>and<spandata-bind='text: numUsers'></span>user(s) are connected.
Because the viewModel properties are observable,
Knockout will automatically update the HTML elements whenever those properties
change.
Next, you want to fetch the latest data from the server. For demo purposes, you
might issue an AJAX request every five seconds (perhaps using jQuery’s $.getJSON or $.ajax
functions):
vardata=getDataUsingAjax();// Gets the data from the server
The server might return JSON data similar to the following:
{serverTime:'2010-01-07',numUsers:3}
Finally, to update your viewModel using this
data, you would write:
// Every time data is receivedfromtheserver:viewModel.serverTime(data.serverTime);viewModel.numUsers(data.numUsers);
You would have to do this for every variable you want to display on your page. If
your data structures become more complex and contain children or arrays, this becomes very
cumbersome to handle manually. However, Knockout provides facilities to easily populate a
viewModel with an incoming JSON payload.
Alternately, you could use the Knockout.js
mapping plug-in.
This plug-in allows you to create a mapping from the regular JavaScript object (or JSON
structure) to an observable viewModel. The mapping
plug-in gives you a straightforward way to map that plain JavaScript object into a
viewModel with the appropriate observables. This is an
alternative to manually writing your own JavaScript code that constructs a viewModel based on some data you’ve fetched from the
server.
To create a viewModel via the mapping plug-in,
replace the creation of viewModel in the code above
with the ko.mapping.fromJS function:
varviewModel=ko.mapping.fromJS(data);
This automatically creates observable properties for each of the properties on data.
Then, every time you receive new data from the server, you can update all the properties
on viewModel in one step by calling the ko.mapping.fromJS function again:
// Every time data is receivedfromtheserver:ko.mapping.fromJS(data,viewModel);
All properties of an object are converted into an observable. If an update would change the value, it will update the observable.
Arrays are converted into observable arrays. If an update would change the number of items, it will perform the appropriate add or remove actions. It will also try to keep the order the same as the original JavaScript array.
Get HTML5 and JavaScript Web Apps now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

