Not all characters are available on the keyboard! This hack shows you how to represent such characters in an XML document by using decimal and hexadecimal character references, and how to represent entities by using entity references.
In XML, character and entity references are formed by surrounding a
numerical value or a name with & and
;—for example, ©
is a decimal character reference and © is
an entity reference. This hack shows you how to use both.
According to the third and latest edition of the XML 1.0 specification (http://www.w3.org/TR/REC-xml/), XML processors must accept over 1,000,000 hexadecimal characters (http://www.w3.org/TR/REC-xml/#charsets). It’s possible that you won’t be able to find all those characters on your keyboard! Don’t worry. You can use character references instead.
Tip
You can look up the semantics of individual Unicode characters at http://www.unicode.org/charts/.
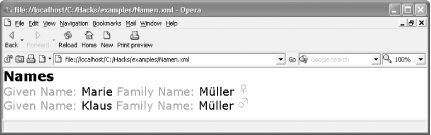
You can reference characters using either decimal or hexadecimal numbers. Which one you use is a matter of style. The document Namen.xml uses both (Example 1-5); it contains some German names enclosed in German language tags.
Example 1-5. Namen.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet href="Namen.css" type="text/css"?> <Namen xml:lang="de"> <Name> <Vorname>Marie</Vorname> <Nachname>Müller</Nachname> <Geschlecht>♀</Geschlecht> </Name> <Name> <Vorname>Klaus</Vorname> <Nachname>Müller</Nachname> <Geschlecht>♂</Geschlecht> </Name> </Namen>
On lines 7 and 8 are the decimal character references
ü and ♀,
respectively. The first one refers to the letter u with an umlaut
(ü) and the second one is a female sign. Lines 12 and 13
use the hexadecimal character references
ü (ü) and
♂ (male sign), respectively. You can
see how these character references are rendered in Opera in Figure 1-6.
Incidentally, the xml:lang attribute on line 4 is
a special language identification attribute in XML 1.0 (http://www.w3.org/TR/REC-xml/#sec-lang-tag).
Its value de is a language identifier as defined
by RFC 3066 (http://www.ietf.org/rfc/rfc3066.txt) and ISO
639 (search http://www.iso.ch).
Other examples of language identifiers are en
(English), fr (French), and es
(Spanish).
XML has five predefined entities,
listed in Table 1-1. These predefined entities can
be used where the equivalent literal character is forbidden. For
example, an attribute value cannot contain a less-than sign
(<), because it looks too much like the
beginning of a tag to an XML parser. No problem: you can use
< instead. Likewise, you cannot use an
ampersand in parsed character data, the text content of an element.
Why? Again, it looks like the beginning of a character or entity
reference to an XML parser. Again, no problem: you can use
&
instead.
Table 1-1. XML predefined entities
|
Entity reference |
Description |
|---|---|
|
|
Less-than sign or open angle bracket ( |
|
|
Greater-than sign or close angle bracket ( |
|
|
Ampersand ( |
|
|
Apostrophe or single quote (') |
|
|
Quote or double quote (“) |
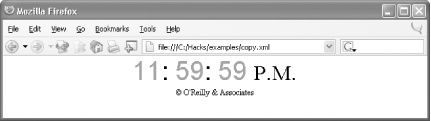
The following document, copy.xml in Example 1-6, uses a predefined entity and also declares and references a new entity.
Example 1-6. copy.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet href="copy.css" type="text/css"?> <!DOCTYPE time [<!ENTITY copy "©">]> <!-- a time instant --> <time timezone="PST"> <hour>11</hour> <minute>59</minute> <second>59</second> <meridiem>p.m.</meridiem> <atomic signal="true"/> <copyright>© O'Reilly & Associates</copyright> </time>
The entity copy is declared in the document type
declaration on line 3. The keyword is ENTITY; it
is followed by the entity name copy; and this is
followed by the value or content of the entity in quotes,
"©“. (This entity comes standard in HTML
and XHTML.) Line 12 of this document references the entity declared
on line 3 (©) and also references the XML
1.0 predefined entity for an ampersand
(&). Open this document in Firefox (it is
styled by the CSS stylesheet copy.css) and it
will appear like Figure 1-7.
Character references provide a convenient means to access a very large number of characters. Entities [Hack #25] are also a convenient means to store information and access it elsewhere, even multiple times if necessary.
Get XML Hacks now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

