10.4 JITTER BUFFER
In public switched telephone network (PSTN), voice samples are delivered synchronously with reference clocks. In VoIP, voice samples are compressed and framed as packets. Packets will go through several impediments while traversing from the source to the actual destination.
As shown in Fig. 10.3(a), jitter buffer regulates the flow between incoming packets and the voice decoder. The input to the jitter buffer is at irregular intervals, but jitter buffer output is read at regular codec frame intervals. Jitter buffer removes the jitter in the arrival of the packets by holding them in the buffer for several milliseconds or several voice frame intervals. There is a trade-off between the end-to-end delay caused by the jitter buffer and the packet loss. For a comfortable voice conversation, end-to-end mouth-to-ear delay including jitter buffer should be as low as possible or at least in the range of 150 to 250 ms. The worst-case delay considered is 400 ms [ITU-T-G.1020 (2006)], and beyond this delay, voice calls are treated as not suitable for interactive conversation. As per the E-model estimation given in Chapter 20, maintaining end-to-end delay to less than 177.3 ms helps to maintain better voice quality from delay considerations.
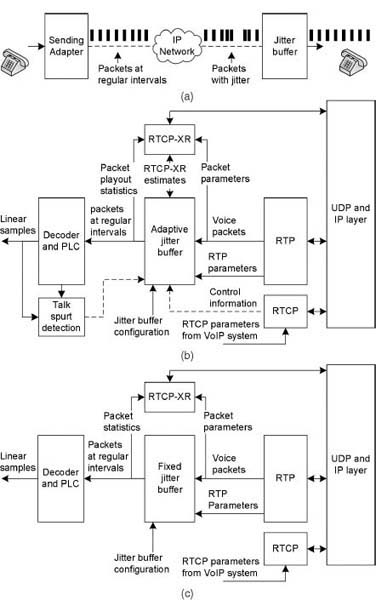
Figure 10.3. Jitter buffer input–output parameters. (a) Jitter buffer packet adjustment. (b) Packet adaptive jitter buffer. (c) Fixed ...
Get VoIP Voice and Fax Signal Processing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

