What You Need to Know
A typical Internet search has three components to it. The first is a huge database that contains every word from every page from every website in the world. This database can be searched and matched very quickly against any word(s) that you enter into a search engine. For example, at the time this chapter was written, a query of the term social media bible in Google (see Figure 18.2) returned “Results 1–10 of about 2,320,000 for social media bible. (0.21 seconds).”
FIGURE 18.2 Google “Social Media Bible” Search
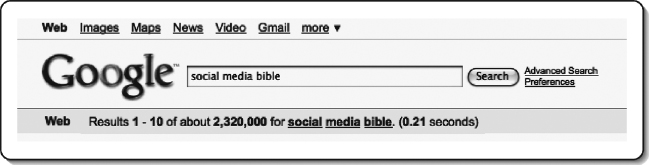
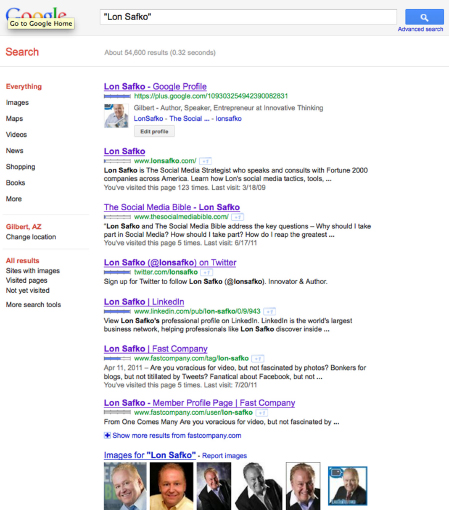
Thus, Google was showing the first 10 results—or matches—of 2.3 million possible matches; and it found all 2.3 million records in just about 0.21 seconds (see Figure 18.3 to see results of my name). Pretty impressive!
FIGURE 18.3 “Lon Safko” Search
The second component of a search engine is its spiders, robots, or just bots. These terms are metaphors for automated computer programs that go out and creep around on the Internet—find a website, and crawl from page to page indexing and cataloging each page’s content. Sound creepy? In reality, the search engine’s computer simply opens a home page, captures the content, and goes onto the next page, and does the same thing. And the reason that that activity usually takes place at night is that Internet traffic ...
Get The Social Media Bible: Tactics, Tools, and Strategies for Business Success, 3rd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

