Chapter 1. Want to Go Faster? Raise Your Hands if You Want to Go Faster!

â[A]nd in this precious phial is the power to think twice as fast, move twice as quickly, do twice as much work in a given time as you could otherwise do.â
With this book I want to peel back the veils of mystery, misery, and misunderstanding that surround concurrent programming. I want to pass along to you some of the tricks, secrets, and skills that Iâve learned over my last two decades of concurrent and parallel programming experience.
I will demonstrate these tricks, secrets, and skillsâand the art of concurrent programmingâby developing and implementing concurrent algorithms from serial code. I will explain the thought processes I went through for each example in order to give you insight into how concurrent code can be developed. I will be using threads as the model of concurrency in a shared-memory environment for all algorithms devised and implemented. Since this isnât a book on one specific threading library, Iâve used several of the common libraries throughout and included some hints on how implementations might differ, in case your preferred method wasnât used.
Like any programming skill, there is a level of mechanics involved in being ready and able to attempt concurrent or multithreaded programming. You can learn these things (such as syntax, methods for mutual exclusion, and sharing data) through study and practice. There is also a necessary component of logical thinking skills and intuition needed to tackle or avoid even simple concurrent programming problems successfully. Being able to apply that logical thinking and having some intuition, or being able to think about threads executing in parallel with each other, is the art of concurrent and multithreaded programming. You can learn some of this through demonstration by experts, but that only works if the innate ability is already there and you can apply the lessons learned to other situations. Since youâve picked up this volume, Iâm sure that you, my fine reader, already possess such innate skills. This book will help you shape and aim those skills at concurrent and multithreaded programming.
Some Questions You May Have
Before we get started, there are some questions you may have thought up while reading those first few paragraphs or even when you saw this book on the shelves before picking it up. Letâs take a look at some of those questions now.
What Is a Thread Monkey?
A thread monkey is a programmer capable of designing multithreaded, concurrent, and parallel software, as well as grinding out correct and efficient code to implement those designs. Much like a âgrease monkeyâ is someone who can work magic on automobiles, a thread monkey is a wiz at concurrent programming. Thread monkey is a title of prestige, unlike the often derogatory connotations associated with âcode monkey.â
Parallelism and Concurrency: Whatâs the Difference?
The terms âparallelâ and âconcurrentâ have been tossed around with increasing frequency since the release of general-purpose multicore processors. Even prior to that, there has been some confusion about these terms in other areas of computation. What is the difference, or is there a difference, since use of these terms seems to be almost interchangeable?
A system is said to be concurrent if it can support two or more actions in progress at the same time. A system is said to be parallel if it can support two or more actions executing simultaneously. The key concept and difference between these definitions is the phrase âin progress.â
A concurrent application will have two or more threads in progress at some time. This can mean that the application has two threads that are being swapped in and out by the operating system on a single core processor. These threads will be âin progressââeach in the midst of its executionâat the same time. In parallel execution, there must be multiple cores available within the computation platform. In that case, the two or more threads could each be assigned a separate core and would be running simultaneously.
I hope youâve already deduced that âparallelâ is a subset of âconcurrent.â That is, you can write a concurrent application that uses multiple threads or processes, but if you donât have multiple cores for execution, you wonât be able to run your code in parallel. Thus, concurrent programming and concurrency encompass all programming and execution activities that involve multiple streams of execution being implemented in order to solve a single problem.
For about the last 20 years, the term parallel programming has been synonymous with message-passing or distributed-memory programming. With multiple compute nodes in a cluster or connected via some network, each node with one or more processors, you had a parallel platform. There is a specific programming methodology required to write applications that divide up the work and share data. The programming of applications utilizing threads has been thought of as concurrent programming, since threads are part of a shared-memory programming model that fits nicely into a single core system able to access the memory within the platform.
I will be striving to use the terms âparallelâ and âconcurrentâ correctly throughout this book. This means that concurrent programming and design of concurrent algorithms will assume that the resulting code is able to run on a single core or multiple cores without any drastic changes. Even though the implementation model will be threads, I will talk about the parallel execution of concurrent codes, since I assume that we all have multicore processors available on which to execute those multiple threads. Also, Iâll use the term âparallelizationâ as the process of translating applications from serial to concurrent (and the term âconcurrentizationâ doesnât roll off the tongue quite as nicely).
Why Do I Need to Know This? Whatâs in It for Me?
Iâm tempted to be a tad flippant and tell you that thereâs no way to avoid this topic; multicore processors are here now and here to stay, and if you want to remain a vital and employable programmer, you have no choice but to learn and master this material. Of course, Iâd be waving my hands around manically for emphasis and trying to put you into a frightened state of mind. While all that is true to some degree, a kinder and gentler approach is more likely to gain your trust and get you on board with the concurrent programming revolution.
Whether youâre a faceless corporate drone for a large software conglomerate, writing code for a small in-house programming shop, doing open source development, or just dabbling with writing software as a hobby, you are going to be touched by multicore processors to one degree or another. In the past, to get a burst of increased performance out of your applications, you simply needed to wait for the next generation of processor that had a faster clock speed than the previous model. A colleague of mine once postulated that you could take nine months off to play the drums or surf, come back after the new chips had been released, run some benchmarks, and declare success. In his seminal (and by now, legendary) article, âThe Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Softwareâ (Dr. Dobbâs Journal, March 2005), Herb Sutter explains that this situation is no longer viable. Programmers will need to start writing concurrent code in order to take full advantage of multicore processors and achieve future performance improvements.
What kinds of performance improvements can you expect with concurrent programming on multicore processors? As an upper bound, you could expect applications to run in half the time using two cores, one quarter of the time running on four cores, one eighth of the time running on eight cores, and so on. This sounds much better than the 20â30% decrease in runtime when using a new, faster processor. Unfortunately, it takes some work to get code whipped into shape and capable of taking advantage of multiple cores. Plus, in general, very few codes will be able to achieve these upper bound levels of increased performance. In fact, as the number of cores increases, you may find that the relative performance actually decreases. However, if you can write good concurrent and multithreaded applications, you will be able to achieve respectable performance increases (or be able to explain why you canât). Better yet, if you can develop your concurrent algorithms in such a way that the same relative performance increases seen on two and four cores remains when executing on 8, 16, or more cores, you may be able to devote some time to your drumming and surfing. A major focus of this book will be pointing out when and how to develop such scalable algorithms.
Isnât Concurrent Programming Hard?
Concurrent programming is no walk in the park, thatâs for sure. However, I donât think it is as scary or as difficult as others may have led you to think. If approached in a logical and informed fashion, learning and practicing concurrent programming is no more difficult than learning another programming language.
With a serial program, execution of your code takes a predictable path through the application. Logic errors and other bugs can be tracked down in a methodical and logical way. As you gain more experience and more sophistication in your programming, you learn of other potential problems (e.g., memory leaks, buffer overflows, file I/O errors, floating-point precision, and roundoff), as well as how to identify, track down, and correct such problems. There are software tools that can assist in quickly locating code that is either not performing as intended or causing problems. Understanding the causes of possible bugs, experience, and the use of software tools will greatly enhance your success in diagnosing problems and addressing them.
Concurrent algorithms and multithreaded programming require you to think about multiple execution streams running at the same time and how you coordinate all those streams in order to complete a given computation. In addition, an entirely new set of errors and performance problems that have no equivalent in serial programming will rear their ugly heads. These new problems are the direct result of the nondeterministic and asynchronous behavior exhibited by threads executing concurrently. Because of these two characteristics, when you have a bug in your threaded program, it may or may not manifest itself. The execution order (or interleaving) of multiple threads may be just perfect so that errors do not occur, but if you make some change in the execution platform that alters your correct interleaving of threads, the errors may start popping up. Even if no hardware change is made, consecutive runs of the same application with the same inputs can yield two different results for no more reason than the fact that it is Tuesday.
To visualize the problem you face, think of all the different ways you can interlace the fingers between two hands. This is like running two threads, where the fingers of a hand are the instructions executed by a thread, concurrently or in parallel. There are 70 different ways to interleave two sets of four fingers. If only 4% (3 of 70) of those interleavings caused an error, how could you track down the cause, especially if, like the Heisenberg Uncertainty Principle, any attempts to identify the error through standard debugging techniques would guarantee one of the error-free interleavings always executed? Luckily, there are software tools specifically designed to track down and identify correctness and performance issues within threaded code.
With the proper knowledge and experience, you will be better equipped to write code that is free of common threading errors. Through the pages of this book, I want to pass on that kind of knowledge. Getting the experience will be up to you.
Arenât Threads Dangerous?
Yes and no. In the years since multicore processors became mainstream, a lot of learned folks have come out with criticisms of the threading model. These people focus on the dangers inherent in using shared memory to communicate between threads and how nonscalable the standard synchronization objects are when pushed beyond a few threads. I wonât lie to you; these criticisms do have merit.
So, why should I write a book about concurrency using threads as the model of implementation if they are so fraught with peril and hazard? Every programming language has its own share of risk, but once you know about these potential problems, you are nine tenths of the way to being able to avoid them. Even if you inadvertently incorporate a threading error in your code, knowing what to look for can be much more helpful than even the best debugger. For example, in FORTRAN 77, there was a default type assigned to variables that were undeclared, based on the first letter of the variable name. If you mistyped a variable name, the compiler blithely accepted this and created a new variable. Knowing that you might have put in the number â1â for the letter âIâ or the letter âOâ for the number â0,â you stood a better chance of locating the typing error in your program.
You might be wondering if there are other, âbetterâ concurrency implementations available or being developed, and if so, why spend time on a book about threading. In the many years that Iâve been doing parallel and concurrent programming, all manner of other parallel programming languages have come and gone. Today, most of them are gone. Iâm pretty sure my publisher didnât want me to write a book on any of those, since there is no guarantee that the information wonât all be obsolete in six months. I am also certain that as I write this, academics are formulating all sorts of better, less error-prone, more programmer-friendly methods of concurrent programming. Many of these will be better than threads and some of them might actually be adopted into mainstream programming languages. Some might even spawn accepted new concurrent programming languages.
However, in the grand scheme of things, threads are here now and will be around for the foreseeable future. The alternatives, if they ever arrive and are able to overcome the inertia of current languages and practices, will be several years down the road. Multicore processors are here right now and you need to be familiar with concurrent programming right now. If you start now, you will be better prepared and practiced with the fundamentals of concurrent applications by the time anything new comes along (which is a better option than lounging around for a couple years, sitting on your hands and waiting for me to put out a new edition of this book using whatever new concurrency method is developed to replace threads).
Four Steps of a Threading Methodology
When developing software, especially large commercial applications, a formal process is used to ensure that everything is done to meet the goals of the proposed software in a timely and efficient way. This process is sometimes called the software lifecycle, and it includes the following six steps:
- Specification
Talk to users of the software to find out what functionality is desired, what the input and output specifications are, and, based on the feedback, formally specify the functionality to be included, a general structure of the application, and the code to implement it.
- Design
Set down more detailed plans of the application and the functional components of the application.
- Implement
Write the code for the application.
- Test
Assure that all the parts of the application work as expected, both separately and within the structure of the entire application, and fix any problems.
- Tune
Make improvements to the code in order to get better performance on target platforms.
- Maintenance
Fix bugs and continue performance improvements, and add new features not in the original design.
The âimplement,â âtest,â and âtuneâ steps may not have hard and fast demarcations between each of them, as programmers will be continually writing, testing, correcting, and tuning code they are working on. There is a cycle of activity around these steps, even when separate QA engineers do the testing. In fact, the cycle may need to go all the way back to the design step if some features cannot be implemented or if some interaction of features, as originally specified, have unforeseen and catastrophic consequences.
The creation of concurrent programs from serial applications also has a similar lifecycle. One example of this is the Threading Methodology developed by Intel application engineers as they worked on multithreaded and parallel applications. The threading methodology has four steps that mirror the steps within the software lifecycle:
- Analysis
Similar to âspecificationâ in the software lifecycle, this step will identify the functionality (code) within the application that contains computations that can run independently.
- Design and implementation
This step should be self-explanatory.
- Test for correctness
Identify any errors within the code due to incorrect or incomplete implementation of the threading. If the code modifications required for threading have incorrectly altered the serial logic, there is a chance that new logic errors will be introduced.
- Tune for performance
Once you have achieved a correct threaded solution, attempt to improve the execution time.
A maintenance step is not part of the threading methodology. I assume that once you have an application written, serial or concurrent, that application will be maintained as part of the normal course of business. The four steps of the threading methodology are considered in more detail in the following sections.
Step 1. Analysis: Identify Possible Concurrency
Since the code is already designed and written, the functionality of the application is known. You should also know which outputs are generated for given inputs. Now you need to find the parts of the code that can be threaded; that is, those parts of the application that contain independent computations.
If you know the application well, you should be able to home in on these parts of the code rather quickly. If you are less familiar with all aspects of the application, you can use a profile of the execution to identify hotspots that might yield independent computations. A hotspot is any portion of the code that has a significant amount of activity. With a profiler, time spent in the computation is going to be the most obvious measurable activity. Once you have found points in the program that take the most execution time, you can begin to investigate these for concurrent execution.
Just because an application spends a majority of the execution time in a segment of code, that does not mean that the code is a candidate for concurrency. You must perform some algorithmic analysis to determine if there is sufficient independence in the code segment to justify concurrency. Still, searching through those parts of the application that take the most time will give you the chance to achieve the most âbang for the buckâ (i.e., be the most beneficial to the overall outcome). It will be much better for you (and your career) to spend a month writing, testing, and tuning a concurrent solution that reduces the execution time of some code segment that accounts for 75% of the serial execution time than it would be to take the same number of hours to slave over a segment that may only account for 2%.
Step 2. Design and Implementation: Threading the Algorithm
Once you have identified independent computations, you need to design and implement a concurrent version of the serial code. This step is what this book is all about. I wonât spend any more time here on this topic, since the details and methods will unfold as you go through the pages ahead.
Step 3. Test for Correctness: Detecting and Fixing Threading Errors
Whenever you make code changes to an application, you open the door to the possibility of introducing bugs. Adding code to a serial application in order to generate and control multiple threads is no exception. As I alluded to before, the execution of threaded applications may or may not reveal any problems during testing. You might be able to run the application correctly hundreds of times, but when you try it out on another system, errors might show up on the new system or they might not. Even if you can get a run that demonstrates an error, running the code through a debugger (even one that is thread-aware) may not pinpoint the problem, since the stepwise execution may mask the error when you are actively looking for it. Using a print statementâthat most-used of all debugging toolsâto track values assigned to variables can modify the timing of thread interleavings, and that can also hide the error.
The more common threading errors, such as data races and deadlock, may be avoided completely if you know about the causes of these errors and plan well enough in the Design and Implementation step to avoid them. However, with the use of pointers and other such indirect references within programming languages, these problems can be virtually impossible to foresee. In fact, you may have cases in which the input data will determine if an error might manifest itself. Luckily, there are tools that can assist in tracking down threading errors. Iâve listed some of these in Chapter 11.
Even after you have removed all of the known threading bugs introduced by your modifications, the code may still not give the same answers as the serial version. If the answers are just slightly off, you may be experiencing round-off error, since the order of combining results generated by separate threads may not match the combination order of values that were generated in the serial code.
More egregious errors are likely due to the introduction of some logic error when threading. Perhaps you have a loop where some iteration is executed multiple times or where some loop iterations are not executed at all. You wonât be able to find these kinds of errors with any tool that looks for threading errors, but you may be able to home in on the problem with the use of some sort of debugging tool. One of the minor themes of this book is the typical logic errors that can be introduced around threaded code and how to avoid these errors in the first place. With a good solid design, you should be able to keep the number of threading or logic errors to a minimum, so not much verbiage is spent on finding or correcting errors in code.
Step 4. Tune for Performance: Removing Performance Bottlenecks
After making sure that you have removed all the threading (and new logic) errors from your code, the final step is to make sure the code is running at its best level of performance. Before threading a serial application, be sure you start with a tuned code. Making serial tuning modifications to threaded code may change the whole dynamic of the threaded portions such that the additional threading material can actually degrade performance. If you have started with serial code that is already tuned, you can focus your search for performance problems on only those parts that have been threaded.
Tuning threaded code typically comes down to identifying situations like contention on synchronization objects, imbalance between the amount of computation assigned to each thread, and excessive overhead due to threading API calls or not enough work available to justify the use of threads. As with threading errors, there are software tools available to assist you in diagnosing and tracking down these and other performance issues.
You must also be aware that the actual threading of the code may be the culprit to a performance bottleneck. By breaking up the serial computations in order to assign them to threads, your carefully tuned serial execution may not be as tuned as it was before. You may introduce performance bugs like false sharing, inefficient memory access patterns, or bus overload. Identification of these types of errors will require whatever technology can find these types of serial performance errors. The avoidance of both threading and serial performance problems (introduced due to threading) is another minor theme of this book. With a good solid design, you should be able to achieve very good parallel performance, so not much verbiage is spent on finding or tuning performance problems in code.
The testing and tuning cycle
When you modify your code to correct an identified performance bug, you may inadvertently add a threading error. This can be especially true if you need to revise the use of synchronization objects. Once youâve made changes for performance tuning, you should go back to the Test for Correctness step and ensure that your changes to fix the performance bugs have not introduced any new threading or logic errors. If you find any problems and modify code to repair them, be sure to again examine the code for any new performance problems that may have been inserted when fixing your correctness issues.
Sometimes it may be worse than that. If you are unable to achieve the expected performance speed from your application, you may need to return to the Design and Implementation step and start all over. Obviously, if you have multiple sites within your application that have been made concurrent, you may need to start at the design step for each code segment once you have finished with the previous code segment. If some threaded code sections can be shown to improve performance, these might be left as is, unless modifications to algorithms or global data structures will affect those previously threaded segments. It can all be a vicious circle and can make you dizzy if you think about it too hard.
What About Concurrency from Scratch?
Up to this point (and for the rest of the book, too), Iâve been assuming that you are starting with a correctly executing serial code to be transformed into a concurrent equivalent. Can you design a concurrent solution without an intermediate step of implementing a serial code? Yes, but I canât recommend it. The biggest reason is that debugging freshly written parallel code has two potential sources of problems: logic errors in the algorithm or implementation, and threading problems in the code. Is that bug youâve found caused by a data race or because the code is not incrementing through a loop enough times?
In the future, once there has been more study of the problem, and as a result, more theory, models, and methods, plus a native concurrent language or two, you will likely be able to write concurrent code from scratch. For now, I recommend that you get a correctly working serial code and then examine how to make it run in parallel. Itâs probably a good idea to note potential concurrency when designing new software, but write and debug in serial first.
Background of Parallel Algorithms
If youâre unfamiliar with parallel algorithms or parallel programming, this section is for youâit serves as a brief guide to some of what has gone before to reach the current state of concurrent programming on multicore processors.
Theoretical Models
All my academic degrees are in computer science. During my academic career, Iâve had to learn about and use many different models of computation. One of the basic processor architecture models used in computer science for studying algorithms is the Random Access Machine (RAM) model. This is a simplified model based on the von Neumann architecture model. It has all the right pieces: CPU, input device(s), output device(s), and randomly accessible memory. See Figure 1-1 for a pictorial view of the components of the RAM and how data flows between components.
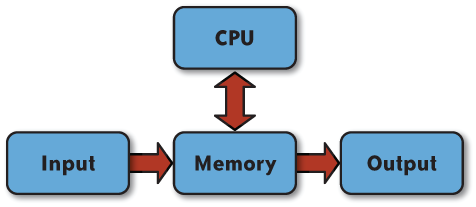
You can add hierarchies to the memory in order to describe levels of cache, you can attach a random access disk as a single device with both input and output, you can control the complexity and architecture of the CPU, or you can make dozens of other changes and modifications to create a model as close to reality as you desire. Whatever bits and pieces and doodads you think to add, the basics of the model remain the same and are useful in designing serial algorithms.
For designing parallel algorithms, a variation of the RAM model called the Parallel Random Access Machine (PRAM, pronounced âpee-ramâ) has been used. At its simplest, the PRAM is multiple CPUs attached to the unlimited memory, which is shared among all the CPUs. The threads that are executing on the CPUs are assumed to be executing in lockstep fashion (i.e., all execute one instruction at the same time before executing the next instruction all at the same time, and so on) and are assumed to have the same access time to memory locations regardless of the number of processors. Details of the connection mechanism between CPUs (processors) and memory are usually ignored, unless there is some specific configuration that may affect algorithm design. The PRAM shown in Figure 1-2 uses a (nonconflicting) shared bus connecting memory and the processors.
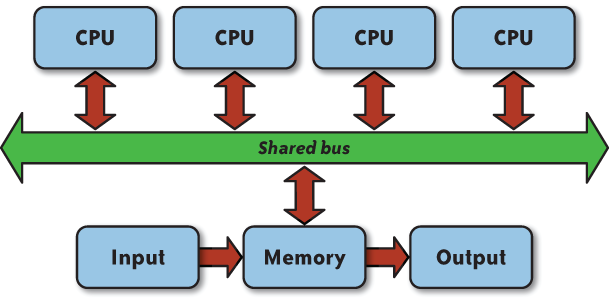
As with the RAM, variations on the basic PRAM model can be made to simulate real-world processor features if those features will affect algorithm design. The one feature that will always affect algorithm design on a PRAM is the shared memory. The model makes no assumptions about software or hardware support of synchronization objects available to a programmer. Thus, the PRAM model stipulates how threads executing on individual processors will be able to access memory for both reading and writing. There are two types of reading restrictions and the same two types of writing restrictions: either concurrent or exclusive. When specifying a PRAM algorithm, you must first define the type of memory access PRAM your algorithm has been designed for. The four types of PRAM are listed in Table 1-1.
Memory access parameters | Description |
Concurrent Read, Concurrent Write (CRCW) | Multiple threads may read from the same memory location at the same time and multiple threads may write to the same memory location at the same time. |
Concurrent Read, Exclusive Write (CREW) | Multiple threads may read from the same memory location at the same time and one thread may write to a given memory location at any time. |
Exclusive Read, Concurrent Write (ERCW) | One thread may read from a given memory location at any time and multiple threads may write to the same memory location at the same time. |
Exclusive Read, Exclusive Write (EREW) | One thread may read from a given memory location at any time and one thread may write to a given memory location at any time. |
On top of these restrictions, it is up to the PRAM algorithm to enforce the exclusive read and exclusive write behavior of the chosen model. In the case of a concurrent write model, the model further specifies what happens when two threads attempt to store values into the same memory location at the same time. Popular variations of this type of PRAM are to have the algorithm ensure that the value being written will be the same value, to simply select a random value from the two or more processors attempting to write, or to store the sum (or some other combining operation) of the multiple values. Since all processors are executing in lockstep fashion, writes to memory are all executed simultaneously, which makes it easy to enforce the designated policy.
Not only must you specify the memory access behavior of the PRAM and design your algorithm to conform to that model, you must also denote the number of processors that your algorithm will use. Since this is a theoretical model, an unlimited number of processors are available. The number is typically based on the size of the input. For example, if you are designing an algorithm to work on N input items, you can specify that the PRAM must have N2 processors and threads, all with access to the shared memory.
With an inexhaustible supply of processors and infinite memory, the PRAM is obviously a theoretical model for parallel algorithm design. Implementing PRAM algorithms on finite resourced platforms may simply be a matter of simulating the computations of N âlogicalâ processors on the cores available to us. When we get to the algorithm design and implementation chapters, some of the designs will take a PRAM algorithm as the basic starting point, and Iâll show you how you might convert it to execute correctly on a multicore processor.
Distributed-Memory Programming
Due to shared bus contention issues, shared-memory parallel computers hit an upper limit of approximately 32 processors in the late â80s and early â90s. Distributed-memory configurations came on strong in order to scale the number of processors higher. Parallel algorithms require some sharing of data at some point. However, since each node in a distributed-memory machine is separated from all the other nodes, with no direct sharing mechanism, developers used libraries of functions to pass messages between nodes.
As an example of programming on a distributed-memory machine, consider the case where Process 1 (P1) requires a vector of values from Process 0 (P0). The program running as P0 must include logic to package the vector into a buffer and call the function that will send the contents of that buffer from the memory of the node on which P0 is running across the network connection between the nodes and deposit the buffer contents into the memory of the node running P1. On the P1 side, the program must call the function that receives the data deposited into the nodeâs memory and copy it into a designated buffer in the memory accessible to P1.
At first, each manufacturer of a distributed-memory machine had its own library and set of functions that could do simple point-to-point communication as well as collective communication patterns like broadcasting. Over time, some portable libraries were developed, such as PVM (Parallel Virtual Machine) and MPI (Message-Passing Interface). PVM was able to harness networks of workstations into a virtual parallel machine that cost much less than a specialized parallel platform. MPI was developed as a standard library of defined message-passing functionality supported on both parallel machines and networks of workstations. The Beowulf Project showed how to create clusters of PCs using Linux and MPI into an even more affordable distributed-memory parallel platform.
Parallel Algorithms Literature
Many books have been written about parallel algorithms. A vast majority of these have focused on message-passing as the method of parallelization. Some of the earlier texts detail algorithms where the network configuration (e.g., mesh or hypercube) is an integral part of the algorithm design; later texts tend not to focus so much on developing algorithms for specific network configurations, but rather, think of the execution platform as a cluster of processor nodes. In the algorithms section of this book (Chapters 6 through 10), some of the designs will take a distributed-memory algorithm as the basic starting point, and Iâll show you how you might convert it to execute correctly in a multithreaded implementation on a multicore processor.
Shared-Memory Programming Versus Distributed-Memory Programming
Some of you may be coming from a distributed-memory programming background and want to get into threaded programming for multicore processors. For you, Iâve put together a list that compares and contrasts shared-memory programming with distributed-memory programming. If you donât know anything about distributed-memory programming, this will give you some insight into the differences between the two programming methods. Even if youâve only ever done serial programming to this point, the following details are still going to give you an introduction to some of the features of concurrent programming on shared-memory that you never encounter using a single execution thread.
Common Features
The following features are common to shared-memory parallelism and distributed-memory parallelism.
Redundant work
No matter how concurrent an algorithm is, there are still parts that will have to be carried out serially. When the results of those serial computations must be shared, you can perform the computation in one process and broadcast the results out to the other processes that require the data. Sending this information will add overhead to the execution time. On the other hand, if the data used in the computation is already available to other processes, you can have each process perform the computation and generate results locally without the need to send any messages. In shared-memory parallelism, the data for computation is likely already available by default. Even though doing redundant work in threads keeps processing resources busy and eliminates extraneous synchronization, there is a cost in memory space needed to hold multiple copies of the same value.
Dividing work
Work must be assigned to threads and processes alike. This may be done by assigning a chunk of the data and having each thread/process execute the same computations on the assigned block, or it may be some method of assigning a computation that involves executing a different portion of the code within the application.
Sharing data
There will be times when applications must share data. It may be the value of a counter or a vector of floating-point values or a list of graph vertices. Whatever it happens to be, threads and processes alike will need to have access to it during the course of the computation. Obviously, the methods of sharing data will vary; shared-memory programs simply access a designated location in memory, while distributed-memory programs must actively send and receive the data to be shared.
Static/dynamic allocation of work
Depending on the nature of the serial algorithm, the resulting concurrent version, and the number of threads/processes, you may assign all the work at one time (typically at the outset of the computation) or over time as the code executes. The former method is known as a static allocation since the original assignments do not change once they have been made. The latter is known as dynamic allocation since work is doled out when it is needed. Under dynamic allocation, you may find that the same threads do not execute the same pieces of work from one run to another, while static allocation will always assign the same work to the same threads (if the number of threads is the same) each and every time.
Typically, if the work can be broken up into a number of parts that is equal to the number of threads/processes, and the execution time is roughly the same for each of those parts, a static allocation is best. Static allocation of work is always the simplest code to implement and to maintain. Dynamic allocation is useful for cases when there are many more pieces of work than threads and the amount of execution time for each piece is different or even unknown at the outset of computation. There will be some overhead associated with a dynamic allocation scheme, but the benefits will be a more load-balanced execution.
Features Unique to Shared Memory
These next few items are where distributed-memory and shared-memory programming differ. If youâre familiar with distributed-memory parallelism, you should be able to see the differences. For those readers not familiar with distributed-memory parallelism, these points and ideas are still going to be important to understand.
Local declarations and thread-local storage
Since everything is shared in shared memory, there are times it will be useful to have a private or local variable that is accessed by only one thread. Once threads have been spawned, any declarations within the path of code execution (e.g., declarations within function calls) will be automatically allocated as local to the thread executing the declarative code. Processes executing on a node within a distributed-memory machine will have all local memory within the node.
A thread-local storage (TLS) API is available in Windows threads and POSIX threads. Though the syntax is different in the different threaded libraries, the API allocates some memory per executing thread and allows the thread to store and retrieve a value that is accessible to only that thread. The difference between TLS and local declarations is that the TLS values will persist from one function call to another. This is much like static variables, except that in TLS, each thread gets an individually addressable copy.
Memory effects
Since threads are sharing the memory available to the cores on which they are executing, there can be performance issues due to that sharing. Iâve already mentioned storage conflicts and data races. Processor architecture will determine if threads share or have access to separate caches. Sharing caches between two cores can effectively cut in half the size of the cache available to a thread, while separate caches can make sharing of common data less efficient. On the good side, sharing caches with commonly accessed, read-only data can be very effective, since only a single copy is needed.
False sharing is a situation where threads are not accessing the same variables, but they are sharing a cache line that contains different variables. Due to cache coherency protocols, when one thread updates a variable in the cache line and another thread wants to access something else in the same line, that line is first written back to memory. When two or more threads are repeatedly updating the same cache line, especially from separate caches, that cache line can bounce back and forth through memory for each update.
Communication in memory
Distributed-memory programs share data by sending and receiving messages between processes. In order to share data within shared memory, one thread simply writes a value into a memory location and the other thread reads the value out of that memory location. Of course, to ensure that the data is transferred correctly, the writing thread must deposit the value to be shared into memory before the reading thread examines the location. Thus, the threads must synchronize the order of writing and reading between the threads. The send-receive exchange is an implicit synchronization between distributed processes.
Mutual exclusion
In order to communicate in memory, threads must sometimes protect access to shared memory locations. The means for doing this is to allow only one thread at a time to have access to shared variables. This is known as mutual exclusion. Several different synchronization mechanisms are available (usually dependent on the threading method you are using) to provide mutual exclusion.
Both reading and writing of data must be protected. Multiple threads reading the same data wonât cause any problems. When you have multiple threads writing to the same location, the order of the updates to the memory location will determine the value that is ultimately stored there and the value that will be read out of the location by another thread (recall the airline reservation system that put two passengers in the same seat). When you have one thread reading and one thread writing to the same memory location, the value that is being read can be one of two values (the old value or the new value). It is likely that only one of those will be the expected value, since the original serial code expects only one value to be possible. If the correct execution of your threaded algorithm depends upon getting a specific value from a variable that is being updated by multiple threads, you must have logic that guarantees the right value is written at the correct time; this will involve mutual exclusion and other synchronization.
Producer/consumer
One algorithmic method you can use to distribute data or tasks to the processes in distributed-memory programs is boss/worker. Worker processes send a message to the boss process requesting a new task; upon receipt of the request, the boss sends back a message/task/data to the worker process. You can write a boss/worker task distribution mechanism in threads, but it requires a lot of synchronization.
To take advantage of the shared memory protocols, you can use a variation of boss/worker that uses a shared queue to distribute tasks. This method is known as producer/consumer. The producer thread creates encapsulated tasks and stores them into the shared queue. The consumer threads pull out tasks from the queue when they need more work. You must protect access to the shared queue with some form of mutual exclusion in order to ensure that tasks being inserted into the queue are placed correctly and that tasks being removed from the queue are assigned to a single thread only.
Readers/writer locks
Since it is not a problem to have multiple threads reading the same shared variables, using mutual exclusion to prevent multiple reader threads can create a performance bottleneck. However, if there is any chance that another thread could update the shared variable, mutual exclusion must be used. For situations where shared variables are to be updated much less frequently than they are to be read, a readers/writer lock would be the appropriate synchronization object.
Readers/writer locks allow multiple reader threads to enter the protected area of code accessing the shared variable. Whenever a thread wishes to update (write) the value to the shared variable, the lock will ensure that any prior reader threads have finished before allowing the single writer to make the updates. When any writer thread has been allowed access to the shared variable by the readers/writer lock, new readers or other threads wanting write access are prevented from proceeding until the current writing thread has finished.
This Bookâs Approach to Concurrent Programming
While writing this book, I was reading Feynman Lectures on Computation (Perseus Publishing, 1996). In Chapter 3, Feynman lectures on the theory of computation. He starts by describing finite state machines (automata) and then makes the leap to Turing machines. At first I was a bit aghast that there was nothing at all about push-down automata or context-free languages, nothing about nondeterministic finite-state machines, and nothing about how this all tied into grammars or recognizing strings from languages. A nice progression covering this whole range of topics was how I was taught all this stuff in my years studying computer science.
I quickly realized that Feynman had only one lecture to get through the topic of Turing machines and the ideas of computability, so he obviously couldnât cover all the details that I learned over the course of eight weeks or so. A bit later, I realized that the target audience for his lecture series wasnât computer science students, but students in physics and mathematics. So he only needed to cover those topics that gave his students the right background and enough of a taste to get some insight into the vast field of computability theory.
This is what Iâm hoping to do with this book. I donât want to give you all the history or theory about concurrent and parallel programming. I want to give you a taste of it and some practical examples so that you (the brilliant person and programmer that I know you to be) can take them and start modifying your own codes and applications to run in parallel on multicore processors. The algorithms in the later chapters are algorithms you would find in an introductory algorithms course. While you may never use any of the concurrent algorithms in this book, the codes are really meant to serve as illustrations of concurrent design methods that you can apply in your own applications. So, using the words of chef Gordon Ramsay, I want to present a âsimple and rusticâ introduction to concurrent programming that will give you some practice and insight into the field.
Get The Art of Concurrency now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

