Chapter 7. MongoDB
MongoDB is one of the more prominent NoSQL databases at this time. In our MongoDB implementations the requirements are that of an old-fashioned database:
- Backup/restore
- Easy (horizontal) scalability
- Resilience to external influence
- Reliability
You can find the entire project on github.
How It Works
For those who are new to MongoDB we’ll briefly introduce the key concepts with their implementation. We work with MongoDB Replica Set for high availability. We’ll use Route 53 to make sure it can be reached. We’ll use SimpleDB for backup administration. And we’ll use Amazon SQS (Simple Queue Service) for a simple task queue.
Replica Set
The high-availability version of MongoDB is called a Replica Set (Figure 7-1). In short, this is a collection of nodes, some of which hold data (members), and of those nodes holding data, one is master. The group uses a voting process to determine the master if there isn’t one or if the current one is not healthy anymore. Nondata member nodes are called arbiters.
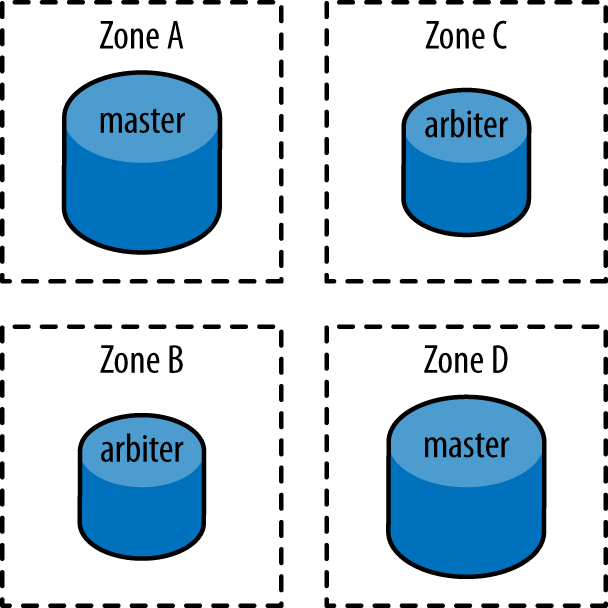
Figure 7-1. MongDB Replica Set
A Replica Set is only operational if the majority is up. For instance, if you have three Availability Zones, you need at least three nodes: two members holding data and one arbiter. Keep in mind that if you lose an entire Availability Zone, you want to keep an operational Replica Set.
Set configuration
We are lucky that elections are part of MongoDB. ...
Get Resilience and Reliability on AWS now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

