As we do, you may find that one of the most tedious, least desirable aspects of your job is to document various pieces of information for the sake of your users. This can either be for the direct benefit of your users who will read the documentation, or perhaps it may be for the indirect benefit of your users because you or your replacement might refer to it when making changes in the future. In either case, creating documentation is often a critical aspect of your job. But if it is not a task that you find yourself longing to do, it might be rather neglected. Python can help here. No, Python cannot write your documentation for you, but it can help you gather, format, and distribute the information to the intended parties.
In this chapter, we are going to focus on: gathering, formatting, and distributing information about the programs you write. The information that you are interested in sharing exists somewhere; it may be in a logfile somewhere; it may be in your head; it may be accessible as a result of some shell command that you execute; it may even be in a database somewhere. The first thing you have to do is to gather that information. The next step in effectively sharing this information is to format the data in a way that makes it meaningful. The format could be a PDF, PNG, JPG, HTML, or even plain text. Finally, you need to get this information to the people who are interested in it. Is it most convenient for the interested parties to receive an email, or visit a website, or look at the files directly on a shared drive?
The first step of information sharing is gathering the information. There are two other chapters in this book dedicated to gathering data: Text Processing (Chapter 3) and SNMP (Chapter 7). Text processing contains examples of the ways to parse and extract various pieces of data from a larger body of text. One specific example in that chapter is parsing the client IP address, number of bytes transmitted, and HTTP status code out of each line in an Apache web server log. And SNMP contains examples of system queries for information ranging from amount of installed RAM to the speed of network interfaces.
Gathering information can be more involved than just locating and extracting certain pieces of data. Often, it can be a process that involves taking information from one format, such as an Apache logfile, and storing it in some intermediate format to be used at a later time. For example, if you wanted to create a chart that showed the number of bytes that each unique IP address downloaded from a specific Apache web server over the course of a month, the information gathering part of the process could involve parsing the Apache logfile each night, extracting the necessary information (in this case, it would be the IP address and âbytes sentâ for each request), and appending the data to some data store that you can open up later. Examples of such data stores include relational databases, object databases, pickle files, CSV files, and plain-text files.
The remainder of this section will attempt to bring together some
of the concepts from the chapters on text processing and data
persistence. Specifically, it will show how to build on the techniques
of data extraction from Chapter 3 and data storage from
Chapter 12. We will use the same library from
the text processing. We will also use the shelve module, introduced in Chapter 12, to store data about HTTP requests from
each unique HTTP client.
Here is a simple module that uses both the Apache log parsing
module created in the previous chapter and the shelve module:
#!/usr/bin/env python
import shelve
import apache_log_parser_regex
logfile = open('access.log', 'r')
shelve_file = shelve.open('access.s')
for line in logfile:
d_line = apache_log_parser_regex.dictify_logline(line)
shelve_file[d_line['remote_host']] = \
shelve_file.setdefault(d_line['remote_host'], 0) + \
int(d_line['bytes_sent'])
logfile.close()
shelve_file.close()This example first imports shelve and apache_log_parser_regex. Shelve is a module from the Python Standard Library. Apache_log_parser_regex is a module we wrote
in Chapter 3. We then open the Apache logfile, access.log, and a shelve file, access.s. We iterate over each line in the
logfile and use the Apache log parsing module to create a dictionary
from each line. The dictionary consists of the HTTP status code for the
request, the clientâs IP address, and the number of bytes transferred to
the client. We then add the number of bytes for this specific request to
the total number of bytes already tallied in the shelve object for this client IP address. If
there is no entry in the shelve
object for this client IP address, the total is automatically set to
zero. After iterating through all the lines in the logfile, we close the
logfile and the shelve object. Weâll
use this example later in this chapter when we get into formatting
information.
You may not think of receiving email as a means of information gathering, but it really can be. Imagine that you have a number of servers, none of which can easily connect to the other, but each of which has email capabilities. If you have a script that monitors web applications on these servers by logging in and out every few minutes, you could use email as an information passing mechanism. Whether the login/logout succeeds or fails, you can send an email with the pass/fail information in it. And you can gather these email messages for reporting or for the purpose of alerting someone if itâs down.
The two most commonly available protocols for retrieving email server are IMAP and POP3. In Pythonâs standard âbatteries includedâ fashion, there are modules to support both of these protocols in the standard library.
POP3 is perhaps the more common of these two protocols, and
accessing your email over POP3 using poplib is quite simple. Example 4-1 shows code that uses poplib to retrieve all of the email that is
stored on the specified server and writes it to a set of files on
disk.
Example 4-1. Retrieving email using POP3
#!/usr/bin/env python
import poplib
username = 'someuser'
password = 'S3Cr37'
mail_server = 'mail.somedomain.com'
p = poplib.POP3(mail_server)
p.user(username)
p.pass_(password)
for msg_id in p.list()[1]:
print msg_id
outf = open('%s.eml' % msg_id, 'w')
outf.write('\n'.join(p.retr(msg_id)[1]))
outf.close()
p.quit()As you can see, we defined the username, password, and mail_server first. Then, we connected to the
mail server and gave it the defined username and password. Assuming
that all is well and we actually have permission to look at the email
for this account, we then iterate over the list of email files,
retrieve them, and write them to a disk. One thing this script doesnât
do is delete each email after retrieving it. All it would take to
delete the email is a call to dele() after retr().
IMAP is nearly as easy as POP3, but itâs not as well documented in the Python Standard Library documents. Example 4-2 shows IMAP code that does the same thing as the code did in the POP3 example.
Example 4-2. Retrieving email using IMAP
#!/usr/bin/env python
import imaplib
username = 'some_user'
password = '70P53Cr37'
mail_server = 'mail_server'
i = imaplib.IMAP4_SSL(mail_server)
print i.login(username, password)
print i.select('INBOX')
for msg_id in i.search(None, 'ALL')[1][0].split():
print msg_id
outf = open('%s.eml' % msg_id, 'w')
outf.write(i.fetch(msg_id, '(RFC822)')[1][0][1])
outf.close()
i.logout()As we did in the POP3 example, we defined the username, password, and mail_server at the top of the script. Then,
we connected to the IMAP server over SSL. Next, we logged in and set
the email directory to INBOX. Then we started
iterating over a search of the entire directory. The search() method is poorly documented in the
Python Standard Library documentation. The two mandatory parameters
for search() are character set and
search criterion. What is a valid character set? What format should we
put in there? What are the choices for search criteria? What format is
required? We suspect that a reading of the IMAP RFC could be helpful,
but fortunately there is enough documentation in the example for IMAP
to retrieve all messages in the folder. For each iteration of the
loop, we write the contents of the email to disk. A small word of
warning is in order here: this will mark all email in that folder as
âread.â This may not be a problem for you, and itâs not a big problem
as it may be if this deleted the messages, but itâs something that you
should be aware of.
Letâs also look at the more complicated path of manually gathering information. By this, we mean information that you gather with your own eyes and key in with your own hands. Examples include a list of servers with corresponding IP addresses and functions, a list of contacts with email addresses, phone numbers, and IM screen names, or the dates that members of your team are planning to be on vacation. There are certainly tools available that can manage most, if not, all of these types of information. There is Excel or OpenOffice Spreadsheet for managing the server list. There is Outlook or Address Book.app for managing contacts. And either Excel/OpenOffice Spreadsheet or Outlook can manage vacations. This may be the solution for the situations that arise when technologies are freely available and use an editing data format that is plain text and which provides output that is configurable and supports HTML (or preferably XHTML).
Celebrity Profile: ReSTless: Aaron Hillegass

Aaron Hillegass, who has worked for NeXT and Apple, is an expert on developing applications for the Mac. He is the author of Cocoa Programming for Mac OS X (Big Nerd Ranch) and teaches classes on Cocoa programming at Big Nerd Ranch.
Please download the full source for ReSTless from the bookâs code repository at http://www.oreilly.com/9780596515829. Here is how to call a Python script from a fancy Cocoa application:
#import "MyDocument.h"
@implementation MyDocument
- (id)init
{
if (![super init]) {
return nil;
}
// What you see for a new document
textStorage = [[NSTextStorage alloc] init];
return self;
}
- (NSString *)windowNibName
{
return @"MyDocument";
}
- (void)prepareEditView
{
// The layout manager monitors the text storage and
// layout the text in the text view
NSLayoutManager *lm = [editView layoutManager];
// Detach the old text storage
[[editView textStorage] removeLayoutManager:lm];
// Attach the new text storage
[textStorage addLayoutManager:lm];
}
- (void)windowControllerDidLoadNib:(NSWindowController *) aController
{
[super windowControllerDidLoadNib:aController];
// Show the text storage in the text view
[self prepareEditView];
}
#pragma mark Saving and Loading
// Saves (the URL is always a file:)
- (BOOL)writeToURL:(NSURL *)absoluteURL
ofType:(NSString *)typeName
error:(NSError **)outError;
{
return [[textStorage string] writeToURL:absoluteURL
atomically:NO
encoding:NSUTF8StringEncoding
error:outError];
}
// Reading (the URL is always a file:)
- (BOOL)readFromURL:(NSURL *)absoluteURL
ofType:(NSString *)typeName
error:(NSError **)outError
{
NSString *string = [NSString stringWithContentsOfURL:absoluteURL
encoding:NSUTF8StringEncoding
error:outError];
// Read failed?
if (!string) {
return NO;
}
[textStorage release];
textStorage = [[NSTextStorage alloc] initWithString:string
attributes:nil];
// Is this a revert?
if (editView) {
[self prepareEditView];
}
return YES;
}
#pragma mark Generating and Saving HTML
- (NSData *)dataForHTML
{
// Create a task to run rst2html.py
NSTask *task = [[NSTask alloc] init];
// Guess the location of the executable
NSString *path = @"/usr/local/bin/rst2html.py";
// Is that file missing? Try inside the python framework
if (![[NSFileManager defaultManager] fileExistsAtPath:path]) {
path = @"/Library/Frameworks/Python.framework/Versions/Current/bin/rst2html.py";
}
[task setLaunchPath:path];
// Connect a pipe where the ReST will go in
NSPipe *inPipe = [[NSPipe alloc] init];
[task setStandardInput:inPipe];
[inPipe release];
// Connect a pipe where the HMTL will come out
NSPipe *outPipe = [[NSPipe alloc] init];
[task setStandardOutput:outPipe];
[outPipe release];
// Start the process
[task launch];
// Get the data from the text view
NSData *inData = [[textStorage string] dataUsingEncoding:NSUTF8StringEncoding];
// Put the data in the pipe and close it
[[inPipe fileHandleForWriting] writeData:inData];
[[inPipe fileHandleForWriting] closeFile];
// Read the data out of the pipe
NSData *outData = [[outPipe fileHandleForReading] readDataToEndOfFile];
// All done with the task
[task release];
return outData;
}
- (IBAction)renderRest:(id)sender
{
// Start the spinning so the user feels like waiting
[progressIndicator startAnimation:nil];
// Get the html as an NSData
NSData *htmlData = [self dataForHTML];
// Put the html in the main WebFrame
WebFrame *wf = [webView mainFrame];
[wf loadData:htmlData
MIMEType:@"text/html"
textEncodingName:@"utf-8"
baseURL:nil];
// Stop the spinning so the user feels done
[progressIndicator stopAnimation:nil];
}
// Triggered by menu item
- (IBAction)startSavePanelForHTML:(id)sender
{
// Where does it save by default?
NSString *restPath = [self fileName];
NSString *directory = [restPath stringByDeletingLastPathComponent];
NSString *filename = [[[restPath lastPathComponent]
stringByDeletingPathExtension]
stringByAppendingPathExtension:@"html"];
// Start the save panel
NSSavePanel *sp = [NSSavePanel savePanel];
[sp setRequiredFileType:@"html"];
[sp setCanSelectHiddenExtension:YES];
[sp beginSheetForDirectory:directory
file:filename
modalForWindow:[editView window]
modalDelegate:self
didEndSelector:@selector(htmlSavePanel:endedWithCode:context:)
contextInfo:NULL];
}
// Called when the save panel is dismissed
- (void)htmlSavePanel:(NSSavePanel *)sp
endedWithCode:(int)returnCode
context:(void *)context
{
// Did the user hit Cancel?
if (returnCode != NSOKButton) {
return;
}
// Get the chosen filename
NSString *savePath = [sp filename];
// Get the HTML data
NSData *htmlData = [self dataForHTML];
// Write it to the file
NSError *writeError;
BOOL success = [htmlData writeToFile:savePath
options:NSAtomicWrite
error:&writeError];
// Did the write fail?
if (!success) {
// Show the user why
NSAlert *alert = [NSAlert alertWithError:writeError];
[alert beginSheetModalForWindow:[editView window]
modalDelegate:nil
didEndSelector:NULL
contextInfo:NULL];
return;
}
}
#pragma mark Printing Support
- (NSPrintOperation *)printOperationWithSettings:(NSDictionary *)printSettings
error:(NSError **)outError
{
// Get the information from Page Setup
NSPrintInfo *printInfo = [self printInfo];
// Get the view that displays the whole HTML document
NSView *docView = [[[webView mainFrame] frameView] documentView];
// Create a print operation
return [NSPrintOperation printOperationWithView:docView
printInfo:printInfo];
}
@end
While there are a number of alternatives, the specific plain-text format that weâre going to suggest here is reStructuredText (also referred to as reST). Here is how the reStructuredText website describes it:
reStructuredText is an easy-to-read, what-you-see-is-what-you-get plaintext markup syntax and parser system. It is useful for in-line program documentation (such as Python docstrings), for quickly creating simple web pages, and for standalone documents. reStructuredText is designed for extensibility for specific application domains. The reStructuredText parser is a component of Docutils. reStructuredText is a revision and reinterpretation of the StructuredText and Setext lightweight markup systems.
ReST is the preferred format for Python documentation. If you create a Python package of your code and decide to upload it to the PyPI, reStructuredText is the expected documentation format. Many individual Python projects are also using ReST as the primary format for their documentation needs.
So why would you want to use ReST as a documentation format? First, because the format is uncomplicated. Second, there is an almost immediate familiarity with the markup. When you see the structure of a document, you quickly understand what the author intended. Here is an example of a very simple ReST file:
======= Heading ======= SubHeading ---------- This is just a simple little subsection. Now, we'll show a bulleted list: - item one - item two - item three
That probably makes some sort of structured sense to you without having to read the documentation about what constitutes a valid reStructuredText file. You might not be able to write a ReST text file, but you can probably follow along enough to read one.
Third, converting from ReST to HTML is simple. And itâs that third point that weâre going to focus on in this section. We wonât try to give a tutorial on reStructuredText here. If you want a quick overview of the markup syntax, visit http://docutils.sourceforge.net/docs/user/rst/quickref.html.
Using the document that we just showed you as an example, weâll walk through the steps converting ReST to HTML:
In [2]: import docutils.core
In [3]: rest = '''=======
...: Heading
...: =======
...: SubHeading
...: ----------
...: This is just a simple
...: little subsection. Now,
...: we'll show a bulleted list:
...:
...: - item one
...: - item two
...: - item three
...: '''
In [4]: html = docutils.core.publish_string(source=rest, writer_name='html')
In [5]: print html[html.find('<body>') + 6:html.find('</body>')]
<div class="document" id="heading">
<h1 class="title">Heading</h1>
<h2 class="subtitle" id="subheading">SubHeading</h2>
<p>This is just a simple
little subsection. Now,
we'll show a bulleted list:</p>
<ul class="simple">
<li>item one</li>
<li>item two</li>
<li>item three</li>
</ul>
</div>This was a simple process. We imported docutils.core. Then we defined a string that
contained our reStructuredText, and ran the string through docutils.core.publish_string(), and then told
it to format it as HTML. Then we did a string slice and extracted the
text between the <body> and
</body> tags. The reason we sliced this
div area is because docutils, the
library we used to convert to HTML, puts an embedded stylesheet in the
generated HTML page so that it doesnât look too plain.
Now that you see how simple it is, letâs take an example that is slightly more in the realm of system administration. Every good sysadmin needs to keep track of the servers they have and the tasks those servers are being used for. So, hereâs an example of the way to create a plain-text server list table and convert it to HTML:
In [6]: server_list = '''============== ============ ================
...: Server Name IP Address Function
...: ============== ============ ================
...: card 192.168.1.2 mail server
...: vinge 192.168.1.4 web server
...: asimov 192.168.1.8 database server
...: stephenson 192.168.1.16 file server
...: gibson 192.168.1.32 print server
...: ============== ============ ================'''
In [7]: print server_list
============== ============ ================
Server Name IP Address Function
============== ============ ================
card 192.168.1.2 mail server
vinge 192.168.1.4 web server
asimov 192.168.1.8 database server
stephenson 192.168.1.16 file server
gibson 192.168.1.32 print server
============== ============ ================
In [8]: html = docutils.core.publish_string(source=server_list,
writer_name='html')
In [9]: print html[html.find('<body>') + 6:html.find('</body>')]
<div class="document">
<table border="1" class="docutils">
<colgroup>
<col width="33%" />
<col width="29%" />
<col width="38%" />
</colgroup>
<thead valign="bottom">
<tr><th class="head">Server Name</th>
<th class="head">IP Address</th>
<th class="head">Function</th>
</tr>
</thead>
<tbody valign="top">
<tr><td>card</td>
<td>192.168.1.2</td>
<td>mail server</td>
</tr>
<tr><td>vinge</td>
<td>192.168.1.4</td>
<td>web server</td>
</tr>
<tr><td>asimov</td>
<td>192.168.1.8</td>
<td>database server</td>
</tr>
<tr><td>stephenson</td>
<td>192.168.1.16</td>
<td>file server</td>
</tr>
<tr><td>gibson</td>
<td>192.168.1.32</td>
<td>print server</td>
</tr>
</tbody>
</table>
</div>Another excellent choice for a plain text markup format is Textile. According to its website, âTextile takes plain text with *simple* markup and produces valid XHTML. Itâs used in web applications, content management systems, blogging software and online forums.â So if Textile is a markup language, why are we writing about it in a book about Python? The reason is that a Python library exists that allows you to process Textile markup and convert it to XHTML. You can write command-line utilities to call the Python library and convert Textile files and redirect the output into XHTML files. Or you can call the Textile conversion module from within some script and programmatically deal with the XHTML that is returned. Either way, the Textile markup and the Textile processing module can be hugely beneficial to your documenting needs.
You can install the Textile Python module, with easy_install textile. Or you can install it
using your systemâs packaging system if itâs included. For Ubuntu, the
package name is python-textile, and you can install it with
apt-get install python-textile. Once
Textile is installed, you can start using it by simply importing it,
creating a Textiler object, and
calling a single method on that object. Here is an example of code that
converts a Textile bulleted list to XHTML:
In [1]: import textile
In [2]: t = textile.Textiler('''* item one
...: * item two
...: * item three''')
In [3]: print t.process()
<ul>
<li>item one</li>
<li>item two</li>
<li>item three</li>
</ul>We wonât try to present a Textile tutorial here. There are plenty of resources on the Web for that. For example, http://hobix.com/textile/ provides a good reference for using Textile. While we wonât get too in-depth into the ins and outs of Textile, we will look at the way Textile works for one of the examples of manually gathered information we described earlierâa server list with corresponding IP addresses and functions:
In [1]: import textile In [2]: server_list = '''|_. Server Name|_. IP Address|_. Function| ...: |card|192.168.1.2|mail server| ...: |vinge|192.168.1.4|web server| ...: |asimov|192.168.1.8|database server| ...: |stephenson|192.168.1.16|file server| ...: |gibson|192.168.1.32|print server|''' In [3]: print server_list |_. Server Name|_. IP Address|_. Function| |card|192.168.1.2|mail server| |vinge|192.168.1.4|web server| |asimov|192.168.1.8|database server| |stephenson|192.168.1.16|file server| |gibson|192.168.1.32|print server| In [4]: t = textile.Textiler(server_list) In [5]: print t.process() <table> <tr> <th>Server Name</th> <th>IP Address</th> <th>Function</th> </tr> <tr> <td>card</td> <td>192.168.1.2</td> <td>mail server</td> </tr> <tr> <td>vinge</td> <td>192.168.1.4</td> <td>web server</td> </tr> <tr> <td>asimov</td> <td>192.168.1.8</td> <td>database server</td> </tr> <tr> <td>stephenson</td> <td>192.168.1.16</td> <td>file server</td> </tr> <tr> <td>gibson</td> <td>192.168.1.32</td> <td>print server</td> </tr> </table>
So you can see that ReST and Textile can both be used effectively to integrate the conversion of plain text data into a Python script. If you do have data, such as server lists and contact lists, that needs to be converted into HTML and then have some action (such as emailing the HTML to a list of recipients or FTPing the HTML to a web server somewhere) taken upon it, then either the docutils or the Textile library could be a useful tool for you.
The next step in getting your information into the hands of your audience is formatting the data into a medium that is easily read and understood. We think of that medium as being something at least comprehensible to the user, but better yet, it can be something attractive. Technically, ReST and Textile encompass both the data gathering and the data formatting steps of information sharing, but the following examples will focus specifically on converting data that weâve already gathered into a more presentable medium.
The following two examples will continue the example of parsing an Apache logfile for the client IP address and the number of bytes that were transferred. In the previous section, our example generated a shelve file that contained some information that we want to share with other users. So, now, we will create a chart object from the shelve file to make the data easy to read:
#!/usr/bin/env python
import gdchart
import shelve
shelve_file = shelve.open('access.s')
items_list = [(i[1], i[0]) for i in shelve_file.items()]
items_list.sort()
bytes_sent = [i[0] for i in items_list]
#ip_addresses = [i[1] for i in items_list]
ip_addresses = ['XXX.XXX.XXX.XXX' for i in items_list]
chart = gdchart.Bar()
chart.width = 400
chart.height = 400
chart.bg_color = 'white'
chart.plot_color = 'black'
chart.xtitle = "IP Address"
chart.ytitle = "Bytes Sent"
chart.title = "Usage By IP Address"
chart.setData(bytes_sent)
chart.setLabels(ip_addresses)
chart.draw("bytes_ip_bar.png")
shelve_file.close()In this example, we imported two modules, gdchart and shelve. We then
opened the shelve file we created
in the previous example. Since the shelve object shares the same interface as
the builtin dictionary object, we
were able to call the Items()
method on it. items() returns a
list of tuples in which the first element of the tuple is the
dictionary key and the second element of the tuple is the value for
that key. We are able to use the items() method to help sort the data in a
way that will make more sense when it is plotted. We use a list
comprehension to reverse the order of the previous tuple. Instead of
being tuples of (ip_address,
bytes_sent), it is now (bytes_sent,
ip_addresses). We then sort this list and since the bytes_sent element is first, the list.sort() method will sort by that field
first. We then use list comprehensions again to pull the bytes_sent and the ip_addresses fields. You may notice that
weâre inserting an obfuscated
XXX.XXX.XXX.XXX for the IP
addresses because weâve taken these logfiles from a production web
server.
After getting the data that is going to feed the chart out of
the way, we can actually start using gdchart to make a graphical representation
of the data. We first create a gdchart.Bar object.
This is simply a chart object for which weâll be setting some
attributes and then weâll render a PNG file. We then define the size
of the chart, in pixels; we assign colons to use for the background
and foreground; and we create titles. We set the data and labels for
the chart, both of which we are pulling from the Apache log parsing
module. Finally, we draw() the
chart out to a file and then close our shelve object. Figure 4-1 shows the chart image.
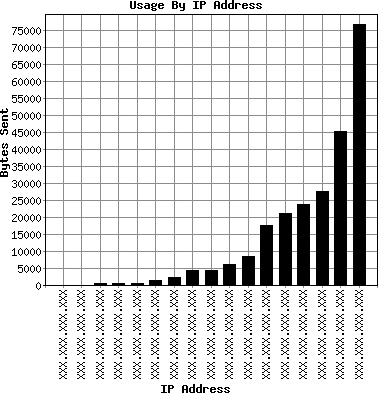
Here is another example of a script for visually formatting the shelve data, but this time, rather than a bar chart, the program creates a pie chart:
#!/usr/bin/env python
import gdchart
import shelve
import itertools
shelve_file = shelve.open('access.s')
items_list = [(i[1], i[0]) for i in shelve_file.items() if i[1] > 0]
items_list.sort()
bytes_sent = [i[0] for i in items_list]
#ip_addresses = [i[1] for i in items_list]
ip_addresses = ['XXX.XXX.XXX.XXX' for i in items_list]
chart = gdchart.Pie()
chart.width = 800
chart.height = 800
chart.bg_color = 'white'
color_cycle = itertools.cycle([0xDDDDDD, 0x111111, 0x777777])
color_list = []
for i in bytes_sent:
color_list.append(color_cycle.next())
chart.color = color_list
chart.plot_color = 'black'
chart.title = "Usage By IP Address"
chart.setData(*bytes_sent)
chart.setLabels(ip_addresses)
chart.draw("bytes_ip_pie.png")
shelve_file.close()This script is nearly identical to the bar chart example, but we
did have to make a few variations. First, this script creates an
instance of gdchart.Pie rather than
gdchart.Bar. Second, we set the
colors for the individual data points rather than just using black for
all of them. Since this is a pie chart, having all data pieces black
would make the chart impossible to read, so we decided to alternate
among three shades of grey. We were able to alternate among these
three choices by using the cycle()
function from the itertools module.
We recommend having a look at the itertools module. There are lots of fun
functions in there to help you deal with iterable objects (such as
lists). Figure 4-2 is the result of our pie graph
script.
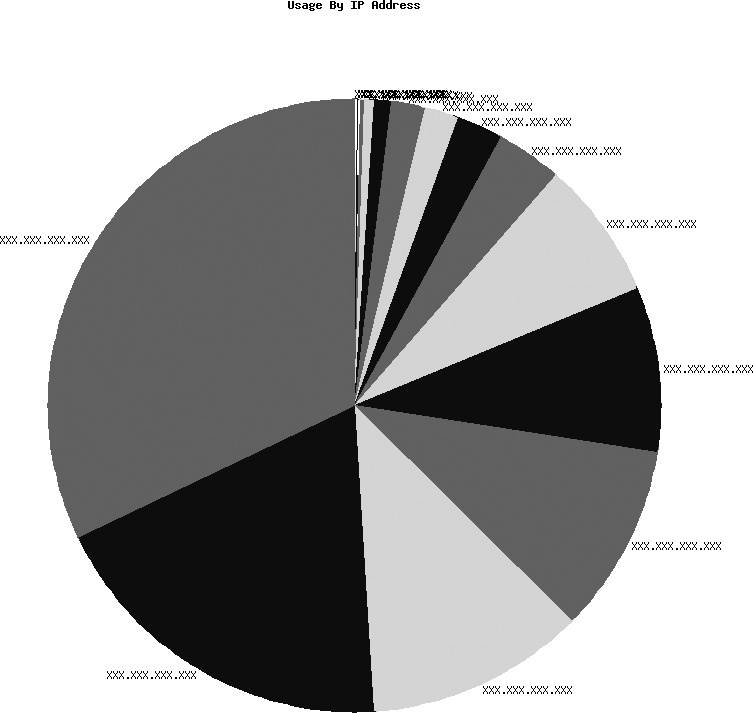
The only real problem with the pie chart is that the (obfuscated) IP addresses get mingled together toward the lower end of the bytes transferred. Both the bar chart and the pie chart make the data in the shelve file much easier to read, and creating each chart was surprisingly simple. And plugging in the information was startlingly simple.
Another way to format information from a data file is to save it in a PDF file. PDF has gone mainstream, and we almost expect all documents to be able to convert to PDF. As a sysadmin, knowing how to generate easy-to-read PDF documents can make your life easier. After reading this section, you should be able to apply your knowledge to creating PDF reports of network utilization, user accounts, and so on. We will also describe the way to embed a PDF automatically in multipart MIME emails with Python.
The 800 pound gorilla in PDF libraries is ReportLab. There is a
free version and a commercial version of the software. There
are quite a few examples you can look at in the ReportLab PDF library
at http://www.reportlab.com/docs/userguide.pdf.
In addition to reading this section, we highly recommend that you read
ReportLabâs official documentation. To install ReportLab on
Ubuntu, you can simply apt-get install
python-reportlab. If youâre not on Ubuntu, you can seek out
a package for your operating system. Or, there is always the source
distribution to rely on.
Example 4-3 is an example of a âHello Worldâ PDF created with ReportLab.
Example 4-3. âHello Worldâ PDF
#!/usr/bin/env python
from reportlab.pdfgen import canvas
def hello():
c = canvas.Canvas("helloworld.pdf")
c.drawString(100,100,"Hello World")
c.showPage()
c.save()
hello()There are a few things you should notice about our âHello Worldâ
PDF creation. First, we creat a canvas object. Next, we use the
drawString() method to do the
equivalent of file_obj.write() to a
text file. Finally, showPage()
stops the drawing, and save()
actually creates the PDF. If you run this code, you will get a big
blank PDF with the words âHello Worldâ at the bottom.
If youâve downloaded the source distribution for ReportLab, you can use the tests theyâve included as example-driven documentation. That is, when you run the tests, theyâll generate a set of PDFs for you, and you can compare the test code with the PDFs to see how to accomplish various visual effects with the ReportLab library.
Now that youâve seen how to create a PDF with ReportLab, letâs see how you can use ReportLab to create a custom disk usage report. Creating a custom disk usage report could be useful. See Example 4-4.
Example 4-4. Disk report PDF
#!/usr/bin/env python
import subprocess
import datetime
from reportlab.pdfgen import canvas
from reportlab.lib.units import inch
def disk_report():
p = subprocess.Popen("df -h", shell=True,
stdout=subprocess.PIPE)
return p.stdout.readlines()
def create_pdf(input,output="disk_report.pdf"):
now = datetime.datetime.today()
date = now.strftime("%h %d %Y %H:%M:%S")
c = canvas.Canvas(output)
textobject = c.beginText()
textobject.setTextOrigin(inch, 11*inch)
textobject.textLines('''
Disk Capacity Report: %s
''' % date)
for line in input:
textobject.textLine(line.strip())
c.drawText(textobject)
c.showPage()
c.save()
report = disk_report()
create_pdf(report)This code will generate a report that displays the current disk
usage, with a datestamp and the words, âDisk Capacity Report.â For
such a small handful of lines of codes, this is quite impressive.
Letâs look at some of the highlights of this example. First, the
disk_report() function that simply
takes the output of df -h and
returns it as a list. Next in the create_pdf() function, letâs create a
formatted datestamp. The most important part of this example is the
textobject.
The textobject function is
used to create the object that you will place in a PDF. We create a
textobject by calling beginText(). Then we define the way we want
the data to pack into the page. Our PDF approximates an 8.5Ã11âinch
document, so to pack our text near the top of the page, we told the
text object to set the text origin at 11 inches. After that we created
a title by writing out a string to the text object, and then we
finished by iterating over our list of lines from the df command. Notice that we used line.strip() to remove the newline
characters. If we didnât do this, we would have seen blobs of black
squares where the newline characters were.
You can create much more complex PDFs by adding colors and pictures, but you can figure that out by reading the excellent userguide associated with the ReportLab PDF library. The main thing to take away from these examples is that the text is the core object that holds the data that ultimately gets rendered out.
After youâve gathered and formatted your data, you need to get it to the people who are interested in it. In this chapter, weâll mainly focus on ways to email the documentation to your recipients. If you need to post some documentation to a web server for your users to look at, you can use FTP. We discuss using the Python standard FTP module in the next chapter.
Dealing with email is a significant part of being a sysadmin. Not only do we have to manage email servers, but we often to need come up with ways to generate warning messages and alerts via email. The Python Standard Library has terrific support for sending email, but very little has been written about it. Because all sysadmins should take pride in a carefully crafted automated email, this section will show you how to use Python to perform various email tasks.
There are two different packages in Python that allow you to
send email. One low level package, smtplib, is an
interface that corresponds to the various RFCâs for the SMTP protocol. It sends
email. The other package, email, assists with parsing and generating
emails. Example 4-5 uses smtplib to build a string that represents
the body of an email message and then uses the email package to send
it to an email server.
Example 4-5. Sending messages with SMTP
#!/usr/bin/env python import smtplib mail_server = 'localhost' mail_server_port = 25 from_addr = 'sender@example.com' to_addr = 'receiver@example.com' from_header = 'From: %s\r\n' % from_addr to_header = 'To: %s\r\n\r\n' % to_addr subject_header = 'Subject: nothing interesting' body = 'This is a not-very-interesting email.' email_message = '%s\n%s\n%s\n\n%s' % (from_header, to_header, subject_header, body) s = smtplib.SMTP(mail_server, mail_server_port) s.sendmail(from_addr, to_addr, email_message) s.quit()
Basically, we defined the host and port for the email server
along with the âtoâ and âfromâ addresses. Then we built up the email
message by concatenating the header portions together with the email
body portion. Finally, we connected to the SMTP server and sent it
to to_addr and from from_addr. We should also note that we
specifically formatted the From:
and To: with \r\n to conform to the RFC
specification.
See Chapter 10, specifically the section Scheduling Python Processes,â for an example of code that creates a cron job that sends mail with Python. For now, letâs move from this basic example onto some of the fun things Python can do with mail.
Our last example was pretty simple, as it is trivial to send email from Python, but unfortunately, quite a few SMTP servers will force you to use authentication, so it wonât work in many situations. Example 4-6 is an example of including SMTP authentication.
Example 4-6. SMTP authentication
#!/usr/bin/env python
import smtplib
mail_server = 'smtp.example.com'
mail_server_port = 465
from_addr = 'foo@example.com'
to_addr = 'bar@exmaple.com'
from_header = 'From: %s\r\n' % from_addr
to_header = 'To: %s\r\n\r\n' % to_addr
subject_header = 'Subject: Testing SMTP Authentication'
body = 'This mail tests SMTP Authentication'
email_message = '%s\n%s\n%s\n\n%s' % (from_header, to_header, subject_header, body)
s = smtplib.SMTP(mail_server, mail_server_port)
s.set_debuglevel(1)
s.starttls()
s.login("fatalbert", "mysecretpassword")
s.sendmail(from_addr, to_addr, email_message)
s.quit()The main difference with this example is that we specified a
username and password, enabled a debuglevel,
and then started SSL by using the starttls() method. Enabling debugging when
authentication is involved is an excellent idea. If we take a look
at a failed debug session, it will look like this:
$ python2.5 mail.py send: 'ehlo example.com\r\n' reply: '250-example.com Hello example.com [127.0.0.1], pleased to meet you\r\n' reply: '250-ENHANCEDSTATUSCODES\r\n' reply: '250-PIPELINING\r\n' reply: '250-8BITMIME\r\n' reply: '250-SIZE\r\n' reply: '250-DSN\r\n' reply: '250-ETRN\r\n' reply: '250-DELIVERBY\r\n' reply: '250 HELP\r\n' reply: retcode (250); Msg: example.com example.com [127.0.0.1], pleased to meet you ENHANCEDSTATUSCODES PIPELINING 8BITMIME SIZE DSN ETRN DELIVERBY HELP send: 'STARTTLS\r\n' reply: '454 4.3.3 TLS not available after start\r\n' reply: retcode (454); Msg: 4.3.3 TLS not available after start
In this example, the server with which we attempted to
initiate SSL did not support it and sent us out. It would be quite
simple to work around this and many other potential issues by
writing scripts that included some error handle code to send mail
using a cascading system of server attempts, finally finishing at
localhost attempt to send mail.
Sending text-only email is so passé. With Python we can send messages using the MIME standard, which lets us encode attachments in the outgoing message. In a previous section of this chapter, we covered creating PDF reports. Because sysadmins are impatient, we are going to skip a boring diatribe on the origin of MIME and jump straight into sending an email with an attachment. See Example 4-7.
Example 4-7. Sending a PDF attachment email
import email
from email.MIMEText import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.MIMEBase import MIMEBase
from email import encoders
import smtplib
import mimetypes
from_addr = 'noah.gift@gmail.com'
to_addr = 'jjinux@gmail.com'
subject_header = 'Subject: Sending PDF Attachemt'
attachment = 'disk_usage.pdf'
body = '''
This message sends a PDF attachment created with Report
Lab.
'''
m = MIMEMultipart()
m["To"] = to_addr
m["From"] = from_addr
m["Subject"] = subject_header
ctype, encoding = mimetypes.guess_type(attachment)
print ctype, encoding
maintype, subtype = ctype.split('/', 1)
print maintype, subtype
m.attach(MIMEText(body))
fp = open(attachment, 'rb')
msg = MIMEBase(maintype, subtype)
msg.set_payload(fp.read())
fp.close()
encoders.encode_base64(msg)
msg.add_header("Content-Disposition", "attachment", filename=attachment)
m.attach(msg)
s = smtplib.SMTP("localhost")
s.set_debuglevel(1)
s.sendmail(from_addr, to_addr, m.as_string())
s.quit()So, we used a little magic and encoded our disk report PDF we created earlier and emailed it out.
Trac is a wiki and issue tracking system. It is typically used for software development, but can really be used for anything that you would want to use a wiki or ticketing system for, and it is written in Python. You can find the latest copy of the Trac documentation and package here: http://trac.edgewall.org/. It is beyond the scope of this book to get into too much detail about Trac, but it is a good tool for general trouble tickets as well. One of the other interesting aspects of Trac is that it can be extended via plug-ins.
Weâre mentioning it last because it really fits into all three of the categories that weâve been discussing: information gathering, formatting, and distribution. The wiki portion allows users to create web pages through browsers. The information they put into those passages is rendered in HTML for other users to view through browsers. This is the full cycle of what weâve been discussing in this chapter.
Similarly, the ticket tracking system allows users to put in requests for work or to report problems they encounter. You can report on the tickets that have been entered via the web interface and can even generate CSV reports. Once again, Trac spans the full cycle of what weâve discussed in this chapter.
We recommend that you explore Trac to see if it meets your needs. You might need something with more features and capabilities or you might want something simpler, but itâs worth finding out more about.
In this chapter, we looked at ways to gather data, in both an automated and a manual way. We also looked at ways to put that data together into a few different, more distributable formats, namely HTML, PDF, and PNG. Finally, we looked at how to get the information out to people who are interested in it. As we said at the beginning of this chapter, documentation might not be the most glamorous part of your job. You might not have even realized that you were signing up to document things when you started. But clear and precise documentation is a critical element of system administration. We hope the tips in this chapter can make the sometimes mundane task of documentation a little more fun.
Get Python for Unix and Linux System Administration now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

