In previous chapters, we explored the advantages of multithreaded programs, examined various program design models, and experimented with simple and more complex synchronization mechanisms. Our ATM program is now a full-fledged, well-synchronized multithreaded server, designed after the boss/worker model and optimized to use a thread pool. On our way, we introduced many other Pthreads features in passing. Itâs now time to examine these features a little more closely and see how we can use them to enhance our ATM server.
Our agenda includes:
- Thread attributes
A thread attribute allows you to create a thread in the detached state. On some systems you can also specify attributes that control a threadâs stack configuration and its scheduling behavior.
- The pthread_once mechanism
By using the pthread_once mechanism, you can ensure that an action is performed onceâand only onceâregardless of how many times the threads in your program attempt to perform it. This function is useful, for instance, when more than one thread shares a file or a procedure and you donât know which thread will execute first.
- Keys
Threads use keys to maintain private copies of a shared data item. A single, globally defined key points to a different memory location, depending upon which thread is executing, thus allowing the thread to access its own copy of the data. Use a key, for example, when your threads make deeply nested procedure calls and you canât easily pass thread-specific information in procedure arguments.
- Cancellation
Cancellation allows you to specify the conditions under which a thread allows itself to be terminated. You can also define a stack on which the terminating thread performs last-second cleanup before exiting. Use cancellation, for example, when threads are searching in parallel for an item in a database. The thread that started the search can terminate the other threads when one of the threads locates the item.
- Scheduling
You use the Pthreads scheduling features to set up a policy that determines which thread the system first selects to run when CPU cycles become available, and how long each thread can run once it is given the CPU. Scheduling is often necessary in real-time applications in which some threads have more important work than others. For example, a thread that controls equipment on a factory floor could be given priority over other threads doing background processing. The Pthreads standard defines scheduling as an optional feature.
- Mutex scheduling attributes
By using mutex attributes, you can avoid the phenomenon known as priority inversion. Priority inversion occurs when multiple threads of various scheduling priorities all compete for a common mutex. A higher priority thread may find that a lower priority thread holds a mutex it needs and may stop dead in its tracks until the mutex is released.
To some extent you might consider these features to be just bells and whistles. Each has a specialized purpose that may or may not apply to your program. Nevertheless, the situations in which they are useful are common enough that itâs good that theyâre available to us in the portable Pthreads interface. Weâll now look at some specific ways in which they can be used.
Threads have certain properties, called attributes, that you can request through the Pthreads library. The Pthreads standard defines attributes that determine the following thread characteristics:
Whether the thread is detached or joinable. All Pthreads implementations provide this attribute.
Size of the threadâs private stack. An implementation provides this attribute if the _POSIX_THREAD_ATTR_STACKSIZE compile-time constant is defined.
Location of the threadâs stack. An implementation provides this attribute if the _POSIX_THREAD_ATTR_STACKADDR compile-time constant is defined.
A threadâs scheduling policy (and other attributes that determine how it may be scheduled). An implementation provides these attributes if the _POSIX_THREAD_PRIORITY_SCHEDULING compile-time constant is defined.
Vendors often define custom attributes as a way of including extensions to the standard in their implementations.
As weâve mentioned before, a thread is created with a set of default attributes. Because the threads weâve been using in our examples thus far are threads of the gray flannel variety, weâve accepted the defaults by passing NULL as an attribute parameter to the pthread_create call. To set a threadâs attributes to something other than the default, weâd perform the following steps:
Define an attribute object of type pthread_attr_t.
Call pthread_attr_init to declare and initialize the attribute object.
Make calls to specific Pthreads functions to set individual attributes in the object.
Specify the fully initialized attribute object to the pthread_create call that creates the thread.
Weâll walk through some specific examples of setting a threadâs stack size, stack location, and detached state in the next few sections. Weâll investigate the thread-scheduling attributes later in this chapter.
A thread uses its private stack to store local variables for each routine it has called (but not yet exited) up to its current point of execution. (It also leaves various pieces of procedure context information on the stack, like bread crumbs, so that it can find its way back to the previously executing routine when it exits the current one.) For instance, consider a worker thread in our ATM server. It calls process_request, does some processing, and pushes some of process_requestâs local variables on the stack. It then calls deposit, pushing some information that allows it to return to the next instruction in process_request when it exits deposit. Now, it pushes depositâs local variables on its stack. Suppose it then calls retrieve_account, and then some number-crunching routine, and then, and then.... Weâd certainly like our thread to have ample stack space for all routines in its current call chain.
Two factors can affect whether a thread will have enough room on its stack:
The size of the local variables to each routine
The number of routines that may be in its call chain at any one time
If our worker thread begins to call routines that locally declare kilobyte-sized buffers, we might have a problem. If it makes nested procedure calls to some pretty hefty libraries (like a Kerberos security library or an X graphics library), weâd better start stretching its stack.
Even nonthreaded processes run out of stack space from time to time. However, an individual threadâs stack is much smaller than that devoted to an entire process. The space for the stacks of all threads in a process is carved out of the memory previously allocated for the stack of the process as a whole. As shown in Figure 4-1, a process stack normally starts in high memory and works its way down in memory without anything in its way until it reaches 0. For a process with individual threads, one threadâs stack is bounded by the start of the next threadâs stack, even if the next thread isnât using all of its stack space.
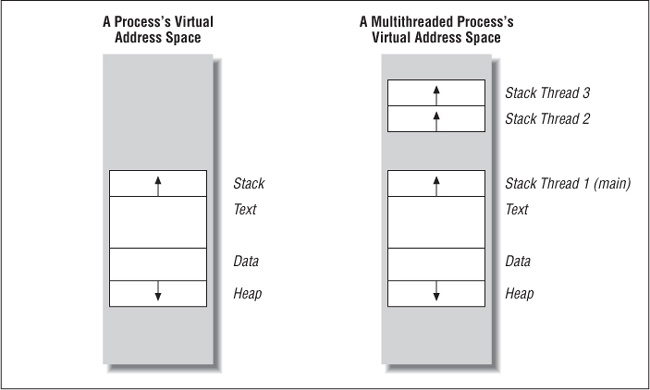
To set a threadâs stack size, we call pthread_attr_init to declare and initialize a custom thread attribute object (pthread_attr_t) in Example 4-1.
Example 4-1. Declaring a Custom Attribute (mattr.c)
#define MIN_REQ_SSIZE 81920 size_t default_stack_size; pthread_attr_t stack_size_custom_attr; . . . pthread_attr_init(&stack_size_custom_attr); . . .
Now that weâve created and initialized our attribute object, we can set and check the value of any attribute in it, using the appropriate Pthreads function. In Example 4-2, weâll read and adjust the threadâs stack size by calling pthread_attr_getstacksize and pthread_attr_setstacksize. The minimum stack size on the platform is always stored in PTHREAD_STACK_MIN and can be used to determine at run time if the default stack will be big enough.
Example 4-2. Checking and Setting Stack Size (mattr.c)
#ifdef _POSIX_THREAD_ATTR_STACKSIZE
pthread_attr_getstacksize(&stack_size_custom_attr,
&default_stack_size);
if (default_stack_size < MIN_REQ_SSIZE) {
.
.
.
pthread_attr_setstacksize(&stack_size_custom_attr,
(size_t)MIN_REQ_SSIZE);
}
#endifIn Example 4-3, weâll create a thread that has the desired attribute (a MIN_REQ_SSIZE stack) by specifying the attribute object in a pthread_create call.
Example 4-3. Using an Attribute Object in pthread_create (mattr.c)
pthread_create(&threads[num_threads],
&stack_size_custom_attr,
(void *) mult_worker,
(void *) p);Take special notice that fiddling with a threadâs stack is inherently nonportable. Stack size and location are platform-dependent; the bytes and bounds of your threadsâ stacks on Platform A may not quite match those of the stacks on Platform B.
The location of a threadâs stack may be of some importance to an application that accesses memory areas with diverse properties, such as a programming languageâs run-time library or an embedded systems environment. An application of this sort can use its threadsâ attribute objects to situate thread stacks as it sees fit.
To check and adjust a threadâs stack location, use pthread_attr_getstackaddr and pthread_attr_setstackaddr. Specify an address within the processâs virtual address space to the pthread_attr_setstackaddr call. When managing thread stack locations in this way, you must take special care that the thread stacks are big enough and that they do not overlap. Dire consequences could result if you donât.
Detaching from a thread informs the Pthreads library that no other thread will use the pthread_join mechanism to synchronize with the threadâs exiting. Because the library doesnât preserve the exit status of a detached thread, it can operate more efficiently and make the library resources that were associated with a thread available for reuse more quickly. If no other thread cares when a particular thread in your program exits, consider detaching that thread.
Back in Chapter 2, we discussed how to use the pthread_detach function to dynamically place a joinable thread into a detached state. In Example 4-4, weâll show you how to do it with an attribute object at thread creation.
Example 4-4. Setting the Detached State in an Attribute Object (mattr.c)
pthread_attr_t detached_attr;
.
.
.
pthread_attr_setdetachedstate(&detached_attr, PTHREAD_CREATE_DETACHED);
.
.
.
pthread_create(&thread, &detached_attr, ...);
.
.
.The pthread_attr_setdetachedstate function sets the detached state in an attribute object to either the PTHREAD_CREATE_DETACHED constant (detached) or the PTHREAD_CREATE_JOINABLE constant (joinable). The pthread_attr_getdetached-state function returns the current detached setting of a thread attribute object.
You can set multiple individual attributes within a single attribute object. In the next example, Example 4-5, weâll use calls to the pthread_attr_setstacksize function and the pthread_attr_setdetachedstate function to set a threadâs stack size and detached state in the same object.
Example 4-5. Setting Multiple Attributes in an Attribute Object (mattr.c)
pthread_attr_t custom_attr;
.
pthread_attr_init(&custom_attr);
.
pthread_attr_setstacksize(&custom_attr, MIN_REQ_SSIZE);
pthread_attr_setdetachedstate(&custom_attr, PTHREAD_CREATE_DETACHED);
.
.
pthread_create(&thread, &custom_attr, ...);
.
.
.Throughout this section, weâve declared and initialized thread attribute objects using the pthread_attr_init call. When weâre finished using a thread attribute object, we can call pthread_attr_destroy to destroy it. Note that existing threads that were created using this object are not affected when the object is destroyed.
When you create many threads that cooperate to accomplish a single task, you must sometimes perform a single operation up front so that all of these threads can proceed. For instance, you may need to open a file or initialize a mutex. Up to now, weâve had our boss thread handle these chores, but thatâs not always feasible.
The pthread_once mechanism is the tool of choice for these situations. It, like mutexes and condition variables, is a synchronization tool, but its specialty is handling synchronization among threads at initialization time. If the pthread_once function didnât exist, weâd have to initialize all data, mutexes, and condition variables before we could create any thread that uses them. After our program has started and spawned its first thread, it would be very difficult for it to create new resources that require protection should some asynchronous event require that it do so.
If weâre writing a library that can be called by a multithreaded application, this becomes more than just an annoyance. Perhaps we donât want (or canât have) a single function for our users to call that allows our library to initialize itself prior to its general use. Neither can we ask each of our library functions to first call an initialization routine. Remember, our libraryâs multithreaded. How do we know whether or not another thread might be trying to initialize the same objects simultaneously?
Letâs walk through an example that will help us illustrate the point. Weâll use the communication module from our ATM serverâthat part of the server that receives requests from clients and unpacks them. The interface to the communication module is as shown in Example 4-6.
Example 4-6. Interface to the ATM Server Communication Module (atm_com_svr.c)
void server_comm_get_request(int *, char *); void server_comm_send_response(int, char *); void server_comm_close_conn(int); void server_comm_shutdown(void);
Letâs pretend that this is legacy code that weâve been asked to incorporate into a multithreaded program. Weâll also pretend that it contains an initialization routine and that we donât want to completely rewrite it to eliminate the routine.
The server_comm_get_request routine shown in Example 4-7 is typical of the interfaces in this module.
Example 4-7. Original server_comm_get_request Routine (atm_com_svr.c)
void server_comm_get_request(int *conn, char *req_buf)
{
int i, nr, not_done = 1;
fd_set read_selects;
if (!srv_comm_inited) {
server_comm_init();
srv_comm_inited = TRUE;
}
/* loop, processing new connection requests until a client
buffer is read in on an existing connection. */
while (not_done) {
.
.
.
}If the server_comm_inited flag is FALSE, the server_comm_get_request routine calls an initialization routine (server_comm_init) and sets the flag to TRUE. If we allow multiple threads to call server_comm_init concurrently, we introduce a race condition on the srv_comm_inited flag and on all of server_comm_initâs global variables and initializations. Consider: threads A and B enter the routine at the same time. Thread A checks the value of srv_comm_inited and finds FALSE. Thread B checks the value and also finds it FALSE. Then they both go forward and call srv_comm_init.
Weâll consider two viable solutions:
Adding a mutex to protect the srv_comm_inited flag and server_comm_init routine. Using PTHREAD_MUTEX_INITIALIZER, weâll statically initialize this mutex.
Designating that the entire routine needs special synchronization handling by calling the pthread_once function.
If we choose to protect the srv_comm_inited flag and server_comm_init routine by a statically initialized mutex, our code would look like that in Example 4-8.
Example 4-8. The ATM with Static Initialization (atm_com_svr_init.c)
pthread_mutex_t init_mutex = PTHREAD_MUTEX_INITIALIZER;
void server_comm_get_request(int *conn, char *req_buf)
{
int i, nr, not_done = 1;
fd_set read_selects;
pthread_mutex_lock(&init_mutex)
if (!srv_comm_inited) {
server_comm_init();
srv_comm_inited = TRUE;
}
pthread_mutex_unlock(&init_mutex);
/* loop, processing new connection requests until a client
buffer is read in on an existing connection. */
while (not_done) {
.
.
.
}Using a statically defined mutex to protect the initialization flag and routine works in this simple case but has its drawbacks as a module grows more complex:
When the initialization routine introduces dynamically allocated mutexes, it must initialize them dynamically. This is not an insurmountable problem; as long as at least one mutex is statically defined, it can control the initialization of all the other mutexes.
The mutex protecting the initialization flag routine will continue to act as a synchronization point long after it is needed. Each time any thread enters the library, it will lock and unlock the mutex to read the flag and learn the old news: initialization is complete. (Using the pthread_once function may also involve this type of overhead. However, because the purpose of the pthread_once call is known to the library, a clever library could optimize its use after initialization is complete.)
You cannot define custom attributes for a statically initialized mutex. You can work around this problem, too; as long as at least one mutex is statically defined, it can control the initialization of all other mutexes that have custom attributes.
If we use the server_comm_init routine only through the pthread_once mechanism, we can make the following synchronization guarantees:
No matter how many times it is invoked by one or more threads, the routine will be executed only once by its first caller.
No caller will exit from the pthread_once mechanism until the routineâs first caller has returned.
To use the pthread_once mechanism, you must declare a variable known as a once block (pthread_once_t), and you must statically initialize it to the value PTHREAD_ONCE_INIT. The Pthreads library uses a once block to maintain the state of pthread_once synchronization for a particular routine. Note that we are statically initializing the once block to the PTHREAD_ONCE_INIT value. If the Pthreads standard allowed us to dynamically initialize it (that is, if the library defined a pthread_once_init call), weâd run into a race condition if multiple threads tried to initialize a given routineâs once block at the same time.
In our ATM server, weâll call the once block srv_comm_inited_once and declare and initialize it globally:
pthread_once_t srv_comm_inited_once = PTHREAD_ONCE_INIT;
Now that weâve declared a once block, the server_comm_get_request routine no longer has to test a flag to determine whether to proceed with initialization. Instead, as shown in Example 4-9, it calls pthread_once, specifying the once block and the routine weâve associated with itâserver_comm_init.
Example 4-9. Using a Once Block in the ATM (atm_com_svr_once.c)
void server_comm_get_request(int *conn, char *req_buf)
{
int i, nr, not_done = 1;
fd_set read_selects;
pthread_once(&srv_comm_inited_once, server_comm_init);
/* loop, processing new connection requests until a client
buffer is read in on an existing connection. */
while (not_done) {
.
.
.
}Weâll change the other interface routines in our ATM serverâs communication module in the same manner. Any number of threads can call into the module. Each interface call will initially involve a call to pthread_once, but only the first thread will actually enter server_comm_init and execute our moduleâs initialization routine.
You can declare multiple once blocks in a program, associating each with a different routine. Be careful, though. Once you associate a routine with the pthread_once mechanism, you must always call it through a pthread_once call, using the same once block. You cannot call the routine directly elsewhere in your program without subverting the synchronization the pthread_once mechanism is meant to provide
Notice that the pthread_once interface does not allow you to pass arguments to the routine that is protected by the once block. If youâre trying to fit a predefined routine with arguments into the pthread_once mechanism, youâll have to fiddle a bit with global variables, wrapper routines, or environment variables to get it to work properly.
As a thread calls and returns from one routine or another, the local data on its stack comes and goes. To maintain long-lived data associated with a thread, we normally have two options:
Pass the data as an argument to each call the thread makes.
Store the data in a global variable associated with the thread.
These are perfectly good ways of preserving some types of data for the lifetime of a thread. However, in some instances, neither solution would work. Consider what might happen if youâre rewriting a library of related routines to support multithreading. Most likely you donât have the option of redefining the libraryâs call arguments. Because you donât necessarily know at compile time how many threads will be making library calls, itâs very difficult to define an adequate number of global variables with the right amount of storage. Fortunately, the Pthreads standard provides a clever way of maintaining thread-specific data in such cases.
Pthreads bases its implementation of thread-specific data on the concept of a keyâa kind of pointer that associates data with a specific thread. Although all threads refer to the same key, each thread associates the key with different data. This magic is accomplished by the threads library, which stores the pointer to data on a per-thread basis and keeps track of which item of data is associated with each thread.
Suppose you were writing a communication module that allowed you to open a connection to another host name and read and write across it. A single-threaded version might look like Example 4-10.
Example 4-10. A Communications Module (specific.c)
static int cur_conn;
int open_connection(char *host)
{
.
.
.
cur_conn = ....
.
.
.
}
int send_data(char *data)
{
.
.
.
write(cur_conn,...)
.
.
.
}
int receive_data(char **data)
{
.
.
.
read(cur_conn,...)
.
.
.
}Weâve made the static variable cur_conn internal to this module. It stores the connection identifier between calls to send and receive data. When we add multiple threads to this module, weâll probably want them to communicate concurrently with the same or different hosts. As written, though, this module would have a rather surprising side effect for the thread that first opens a connection and starts to use it. Each subsequent open_connection call will reset the stored connection (cur_conn) in all threads!
If we couldnât use thread-specific data with keys, weâd still have a few ways of fixing this problem:
Add the connection identifier as an output argument to the open_connection call and as an input argument to the receive_data and send_data calls.
Although this would certainly work, itâs a rather awkward solution for a couple of reasons. First, it forces each routine that currently uses the module to change as well. Any routine that makes calls to the module must store the connection identifier it receives from the open_connection call so it can use it in subsequent receive_data and send_data calls. Second, the connection variable is just an arbitrary value with meaning only within the module. As such, it should naturally be hidden within the module. If we did not force its use as a parameter to our moduleâs interfaces, the caller would otherwise never reference it. It shouldnât even need to know about it.
Add an array (cur_conn) that contains entries for multiple connections.
This alone would not work, because the current version of our module has no way of returning to the caller of open_connection the index of the array entry at which it stored the connection identifier. We could proceed to add an argument to open_connection, receive_data, and send_data to pass back and forth an index into the cur_conn array, but that leads to the same disadvantages as our first solution. Furthermore, we donât know how much space to allocate for the array because the number of threads making connections can vary during the run of the program.
Now we can see more clearly the advantages of using thread-specific data. This way, our module can use a key to point to the connection identifier. We need no new arguments in the calls to the module. Each time a thread calls one of the routines in our module, our code uses the key to obtain its own particular connection identifier value.
Certain applications also use thread-specific data with keys to associate special properties with a thread in one routine and then retrieve them in another. Some examples include:
A resource management module (such as a memory manager or a file manager) could use a key to point to a record of the resources that have been allocated for a given thread. When the thread makes a call to allocate more resources, the module uses the key to retrieve the threadâs record and process its request.
A performance statistics module for threads could use a key to point to a location where it saves the starting time for a calling thread.
A debugging module that maintains mutex statistics could use a key to point to a per-thread count of mutex locks and unlocks.
A thread-specific exception-handling module, when servicing a try call (which starts execution of the normal code path), could use a key to point to a location to which to jump in case the thread encounters an exception. The occurrence of an exception triggers a catch call to the module. The module checks the key to determine where to unwind the threadâs execution.
A random number generation module could use a key to point to a location where it maintains a unique seed value and number stream for each thread that calls it to obtain random numbers.
These examples share some common characteristics:
They are libraries with internal state.
They donât require their callers to provide context in interface arguments. They donât burden the caller with maintaining this type of context in the global environment.
In a nonthreaded environment, the data to which the key refers would normally be stored as static data.
Note that thread-specific data is not a distinct data section like global, heap, and stack. It offers no special system protection or performance guarantees; itâs as private or shared as other data in the same data section. There are no special advantages to using thread-specific data if you arenât writing a library and if you know exactly how many threads will be in your program at a given time. If this is the case, just allocate a global array with an element for each known thread and store each threadâs data in a separate element.
Letâs rewrite our ATM serverâs communication module so that it uses a key to point to the connection information for each thread. When a thread calls the open_connection routine, the routine will store the thread-specific connection identifier using a key. Weâll initialize the key, as shown in Example 4-11.
Example 4-11. A Communication Module Using Keys (specific.c)
#include <pthread.h>
static pthread_key_t conn_key;
int init_comm(void)
{
.
.
.
pthread_key_create(&conn_key, (void *)free_conn);
.
.
.
}
void free_conn(int *connp)
{
free(connp);
}Weâve defined conn_key, the key weâre using to point to the thread-specific connection identifier, as a static variable within the module. We initialize it by calling pthread_key_create in the init_comm routine. The pthread_key_create call takes two arguments: the key and a destructor routine. The library uses the destructor routine to clean up the data stored in the key when a thread stores a new value in the key or exits. Weâll discuss destructor routines some more in a moment.
When youâre done with a key, call pthread_key_delete to allow the library to recover resources associated with the key itself.
Although the pthread_key_create function initializes a key that threads can use, it neither allocates memory for the data to be associated with the key, nor associates the data to the key. Next weâll show you how to handle the actual data.
The chief trick to using keys is that you must never assign a value directly to a key, nor can you use a key itself in an expression. You must always use pthread_setspecific and pthread_getspecific to refer to any data item that is being managed by a key. In Example 4-12, our communication moduleâs open_connection routine calls pthread_setspecific to associate the conn_key key with a thread-specific pointer to an integer.
Example 4-12. Storing Data in a Key (specific.c)
int open_connection(char *host)
{
int *connp;
.
.
.
connp = (int *)malloc(sizeof(int));
*connp = ...
pthread_setspecific(conn_key, (void *)connp);
.
.
.
}When a thread calls the open_connection routine, the routine calls malloc to allocate storage for an integer on the heap and sets the pointer connp to point at it. The routine then uses connp to set up a connection and store the connection identifier. Once the connection is complete, the pthread_setspecific call stores connp in a thread-specific location associated with conn_key.
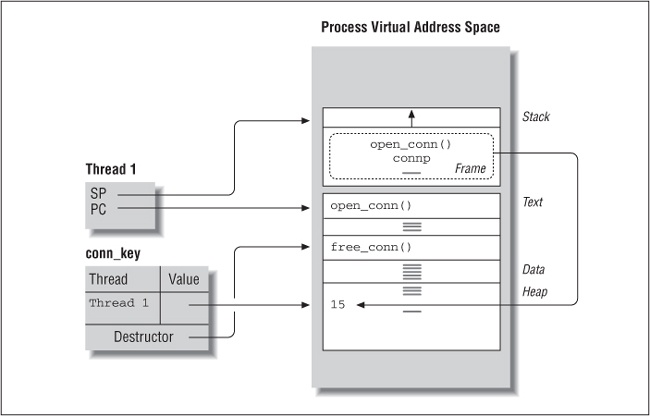
The pthread_setspecific routine takes, as an argument, a pointer to the data to be associated with the keyânot the data itself. Figure 4-2 shows what the conn_key key would look like after the first thread used it to store its thread-specific value.
The open_connection routine, executing in Thread 1âs context, pushes the connp variable onto the threadâs stack. After the call to malloc, connp points to storage for an integer in the heap section of the process. The detailed communication code then uses the connp pointer to set the value of the connection identifier to 15. Once the connection is set up, the pthread_setspecific call stores the pointer to the allocated heap storage for this thread with the conn_key key. When Thread 1 returns from its open_connection procedure call, its stack frame for the procedure call is deallocated, including its connp pointer. The only place in which a pointer to Thread 1âs connection identifier remains is within the key.
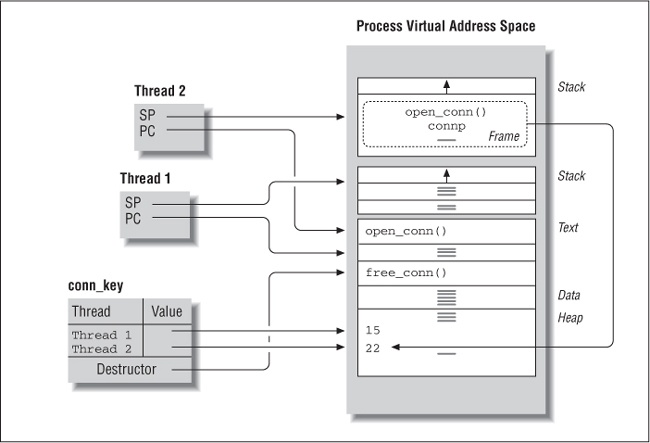
When another thread calls open_connection, as shown in Figure 4-3, the process is repeated.
Now Thread 2 has a stack frame for its open_connection procedure call. After the call to malloc, connp points to storage for an integer in a different area of the processâs heap section. The detailed communications code comes up with a different connection identifier for Thread 2, but the pthread_setspecific call stores a pointer to this value, 22, in the very same key as it stored a pointer to Thread 1âs connection identifier. When Thread 2 returns from its open_connection procedure call, its stack frame for the procedure call is deallocated, including its connp pointer. The only place in which a pointer to Thread 2âs connection identifier remains is within the key.
The send_data and receive_data routines call pthread_getspecific to retrieve the connection identifier for the calling thread. Each routine uses a pointer, saved_connp, to point to the connection identifier, as shown in Example 4-13.
Example 4-13. Retrieving Data from a Key (specific.c)
int send_data(char *data)
{
int *saved_connp;
.
.
.
pthread_getspecific(conn_key, (void **)&saved_connp);
write(*saved_connp,...);
.
.
.
}
int receive_data(char **data)
{
int *saved_connp;
.
.
.
saved_connp = pthread_getspecific(conn_key);
read(*saved_connp,...)
.
.
.
}When Thread 1 calls the send_data orreceive_data routine, as shown in Figure 4-4, the routine calls pthread_getspecific to return to saved_connp the thread-specific connection identifier associated with the conn_key key. It now has access to its connection identifier (15) and can write or read across the connection. When the second thread calls send_data or receive_data, it likewise retrieves its connection identifier (22) using the key.
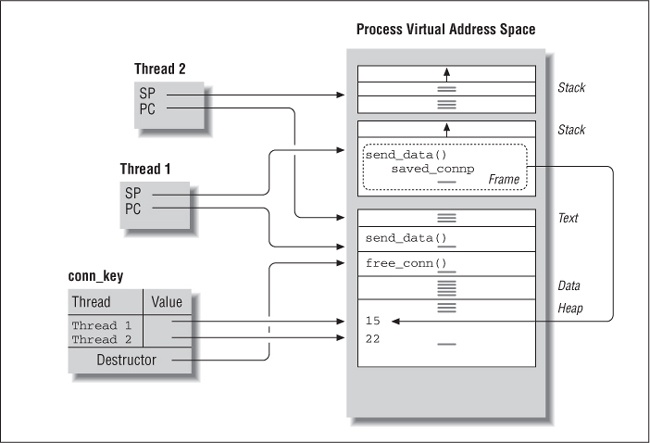
The pthread_getspecific function returns NULL if no value has been associated with a key. If a thread received a NULL return value from its call to receive_data or send_data, itâs likely that it neglected to make a prior call to open_connection.
Weâve shown that keys often store pointers to thread-specific data thatâs been allocated on the heap. Memory leaks can occur when threads exit and leave their thread-specific data that was associated with keys. For this reason we must specify a destructor routine, or destructor for short, when we create a key. When a thread exits, the library invokes the destructor on the threadâs behalf, passing to it the pointer to the thread-specific data currently associated with the key. In this manner, the destructor acts as a convenient plug for potential memory leaks, deallocating memory that would otherwise be forgotten and go to waste.
The destructor can be any routine you choose. In our init_comm routine shown in Example 4-11, we used a routine named free_conn. For the simple integer being stored, free_conn could have simply consisted of a free system call. If we were using more complex data, such as a linked list, the destructor would be a more complex routine that walked down the list, freeing each node. An even more complex example would be a data structure that includes handles on system resources, such as sockets and files, that the destructor would need to close.
Cancellation allows one thread to terminate another. One reason you may want to cancel a thread is to save system resources (such as CPU time) when your program determines that the threadâs activity is no longer necessary. In an odd sense, you can consider cancellation to be a very rough synchronization mechanism: after youâve canceled a thread, you know exactly where it is in its execution! A simple example of a thread you might want to cancel would be a thread performing a read-only data search. If one thread returns the results you are looking for, all other threads running the same routine could be canceled.
Okay, so youâve decided that youâd like to cancel a thread. Now you must reckon whether the thread youâve targeted can be canceled at all. The ability of a thread to go away or not go away when asked by another thread is known as its cancelability state. Letâs assume that you can indeed cancel this thread. Now you must consider when it might go awayâmaybe immediately, maybe a bit later. The degree to which a thread persists after it has been asked to go away is known as its cancelability type. Finally, some threads are able to perform some special cleanup processing as part of being terminated (either through cancellation or through a pthread_exit call). These threads have an associated cleanup stack.
Weâll get into cancelability states, cancelability types, and cleanup stacks a little bit later (probably not late enough for those of you who winced at the use of the term cancelability). Right now, remember that threads donât have a parent/child relationship as processes do. So, any thread can cancel any other thread, as long as the canceling thread has the thread handle of its victim. Because you want your application to be solidly structured, youâll cancel threads only from the thread that initially created them.
Cancellation is not as convenient as you might think at first. Most tasks that make multithreading worthwhile involve taking thread-shared data through some intermediate states before bringing it to some final state. Any thread accessing this data must take and release locks, as appropriate, to maintain proper synchronization. If a thread is to be terminated in the middle of such a prolonged operation, you must first release its locks to prevent deadlock. Often, you must also reset the data to some correct or consistent state. A good example of this would be fixing forward or backward pointers that a thread may have left hanging in a linked list.
For this reason, you must use cancellation very carefully. The simplest approach is to restrict the use of cancellation to threads that execute only in simple routines that do not hold locks or ever put shared data in an inconsistent state. Another option is to restrict cancellation to certain points at which a thread is known to have neither locks nor resources. Lastly, you could create a cleanup stack for the thread that is to be canceled; it can then use the cleanup stack to release locks and reset the state of shared data.
These options are all well and good when you are in charge of all the code your threads might execute. What if your threads call library routines that you donât control? You may have no idea of the detailed operation of these interfaces. One solution to this problem is to create cancellation-safe library routines, a topic weâll defer to the next chapter along with other issues of integration into a UNIX environment.
Because canceling a thread that holds locks and manipulates shared data can be a tricky procedure, the Pthreads standard provides a mechanism by which you can set a given threadâs cancelability (that is, its ability to allow itself to be canceled). In short, a thread can set its cancelability state and cancelability type to any of the combinations listed in Table 4-1, thereby ensuring that it can safely obtain locks or modify shared data when it needs to.
A thread can switch back and forth any number of times across the various permitted combinations of cancelability state and type. When a thread holds no locks and has no resources allocated, asynchronous cancellation is a valid option. When a thread must hold and release locks, it might temporarily disable cancellation altogether.
Note that the Pthreads standard gives you no attribute that would allow you to set a threadâs cancelability state or type when you create it. A thread can set its own cancelability only at run time, dynamically, by calling into the Pthreads library.
Table 4-1. Cancelability of a Thread
Cancelability State | Cancelability Type | Description |
|---|---|---|
PTHREAD_CANCEL_DISABLE | Ignored | Disabled. The thread can never be canceled. Calls to pthread_cancel have no effect. The thread can safely acquire locks and resources. |
PTHREAD_CANCEL_ENABLE | PTHREAD_CANCEL_ASYNCHRONOUS | Asynchronous cancellation. Cancellation takes effect immediately.[a] |
PTHREAD_CANCEL_ENABLE | PTHREAD_CANCEL_DEFERRED | Deferred cancellation (the default). Cancellation takes effect only if and when the thread enters a cancellation point. The thread can hold and release locks but must keep data in some consistent state. If a pending cancellation exists at a cancellation point, the thread can terminate without leaving problems behind for the remaining threads. |
[a] The Pthreads standard states that cancellation will take place âat any time.â We trust that most implementations interpret this phrase to mean âas soon as possible.â The thread must avoid taking out locks and performing sensitive operations on shared data. | ||
When a thread has enabled cancellation (that is, it has set its cancelability state to PTHREAD_CANCEL_ENABLE) and is using deferred cancellation (that is, it has set its cancelability type to PTHREAD_CANCEL_DEFERRED), time can elapse between the time itâs asked to cancel itself and the time itâs actually terminated.
These pending cancellations are delivered to a thread at defined locations in its code path. These locations are known as cancellation points, and they come in two flavors:
Automatic cancellation points (pthread_cond_wait, pthread_cond_timedwait, and pthread_join). The Pthreads library defines these function calls as cancellation points because they can block the calling thread. Rather than maintain the overhead of a blocked routine thatâs destined to be canceled, the Pthreads library considers these calls to be a license to kill the thread. Note that, if the thread for which the cancellation is pending does not call any of these functions, it may never actually be terminated. This is one of the reasons you may need to consider using a programmer-defined cancellation point.
Programmer-defined cancellation points (pthread_testcancel). To force a pending cancellation to be delivered at a particular point in a threadâs code path, insert a call to pthread_testcancel. The pthread_testcancel function causes any pending cancellation to be delivered to the thread at the program location where it occurs. If no cancellation is pending on the thread, nothing happens. Thus, you can freely insert this call at those places in a threadâs code path where itâs safe for the thread to terminate. Itâs also prudent to call pthread_testcancel before a thread starts a time-consuming operation. If a cancellation is pending on the thread, itâs better to terminate it as soon as possible, rather than have it continue and consume system resources needlessly.
The Pthreads standard also defines cancellation points at certain standard system and library calls. Weâll address this topic in Chapter 5.
Example 4-14 illustrates the basic mechanics of cancellation. The main routine creates three threads: bullet_proof, ask_for_it, and sitting_duck. Each thread selects a different cancellation policy: the bullet_proof routine disables cancellation, the ask_for_it routine selects deferred cancellation, and the sitting_duck routine enables asynchronous cancellation.
The main routine waits until all of the threads have started and entered an infinite loop. It then tries to cancel each thread with a pthread_cancel call. By issuing a join on each thread, it waits until all threads have terminated.
Example 4-14. The Simple Cancellation Exampleâmain (cancel.c)
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <pthread.h>
#define NUM_THREADS 3
int count = NUM_THREADS;
pthread_mutex_t lock=PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t init_done=PTHREAD_COND_INITIALIZER;
int id_arg[NUM_THREADS] = {0,1,2};
extern int
main(void)
{
int i;
void *statusp;
pthread_t threads[NUM_THREADS];
/**** Create the threads ****/
pthread_create(&(threads[0]), NULL, ask_for_it, (void *) &(id_arg[0]));
pthread_create(&(threads[1]), NULL, sitting_duck, (void *) &(id_arg[1]));
pthread_create(&(threads[2]), NULL, bullet_proof, (void *) &(id_arg[2]));
printf("main(): %d threads created\n",count);
/**** wait until all threads have initialized ****/
pthread_mutex_lock(&lock);
while (count != 0) {
pthread_cond_wait(&init_done, &lock);
}
pthread_mutex_unlock(&lock);
printf("main(): all threads have signaled that they're ready\n");
/**** cancel each thread ****/
for (i = 0; i < NUM_THREADS; i++) {
pthread_cancel(threads[i]);
}
/**** wait until all threads have finished ****/
for (i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], &statusp);
if (statusp == PTHREAD_CANCELED) {
printf("main(): joined to thread %d, statusp=PTHREAD_CANCELED\n", i);
} else {
printf("main(): joined to thread %d \n", i);
}
}
printf("main(): all %d threads have finished. \n", NUM_THREADS);
return 0;
}When a thread, like bullet_proof, disables cancellation, it is impervious to pthread_cancel calls from other threads, as shown in Example 4-15.
Example 4-15. The Simple Cancellation Exampleâbullet_proof (cancel.c)
void *bullet_proof(int *my_id)
{
int i=0, last_state;
char *messagep;
messagep = (char *)malloc(MESSAGE_MAX_LEN);
sprintf(messagep, "bullet_proof, thread #%d: ", *my_id);
printf("%s\tI'm alive, setting general cancelability OFF\n", messagep);
/* We turn off general cancelability here */
pthread_setcancelstate(PTHREAD_CANCEL_DISABLE, &last_state);
pthread_mutex_lock(&lock);
{
printf("\n%s signaling main that my init is done\n", messagep);
count -= 1;
/* Signal to program that loop is being entered */
pthread_cond_signal(&init_done);
pthread_mutex_unlock(&lock);
}
/* Loop forever until picked off with a cancel */
for(;;i++) {
if (i%10000 == 0)
print_count(messagep, *my_id, i);
if (i%100000 == 0)
printf("\n%s This is the thread that never ends... #%d\n", messagep, i);
}
/* Never get this far */
return(NULL);
}The bullet_proof thread calls pthread_setcancelstate to set its cancelability state to disabled (PTHREAD_CANCEL_DISABLE). After it enters its loop, it repeatedly taunts main until the program ends. Because the main thread has issued a pthread_join call to wait on the bullet_proof thread, weâll need to shoot the whole program with a CTRL-C to get bullet_proof to stop.
The ask_for_it thread calls pthread_setcancelstate to set its cancelability state to enabled (PTHREAD_CANCEL_ENABLE) and pthread_setcanceltype to set its cancelability type to deferred (PTHREAD_CANCEL_DEFERRED). (It actually didnât need to explicitly do so, as deferred cancellation is the default for all threads.) After main has issued a pthread_cancel for it, the ask_for_it thread terminates when it enters the next cancellation point, as shown in Example 4-16.
Example 4-16. The Simple Cancellation Exampleâask_for_it (cancel.c)
void *ask_for_it(int *my_id)
{
int i=0, last_state, last_type;
char *messagep;
messagep = (char *)malloc(MESSAGE_MAX_LEN);
sprintf(messagep, "ask_for_it, thread #%d: ", *my_id);
/* We can turn on general cancelability here and disable async cancellation. */
printf("%s\tI'm alive, setting deferred cancellation ON\n", messagep);
pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, &last_state);
pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED, &last_type);
pthread_mutex_lock(&lock);
{
printf("\n%s signaling main that my init is done\n", messagep);
count -= 1;
/* Signal to program that loop is being entered */
pthread_cond_signal(&init_done);
pthread_mutex_unlock(&lock);
}
/* Loop forever until picked off with a cancel */
for(;;i++) {
if (i%1000 == 0)
print_count(messagep, *my_id, i);
if (i%10000 == 0)
printf("\n%s\tLook, I'll tell you when you can cancel me.%d\n", messagep, i);
pthread_testcancel();
}
/* Never get this far */
return(NULL);
}Weâll force the delivery of mainâs cancellation request by adding a pthread_testcancel call to its loop. After main calls pthread_cancel, ask_for_it will terminate when it encounters pthread_testcancel in the next iteration of the loop.
The sitting_duck thread calls pthread_setcancelstate to set its cancelability state to enabled (PTHREAD_CANCEL_ENABLE) and pthread_setcanceltype to set its cancelability type to asynchronous (PTHREAD_CANCEL_ASYNCHRONOUS). When main issues a pthread_cancel for it, the sitting_duck thread terminates immediately, regardless of what it is doing.
If we leave our thread in this state, it can be canceled during library and system calls as well. However, unless these calls are documented as âasynchronous cancellation-safe,â we should guard against this. (The Pthreads standard requires that only three routines be asynchronous cancellation-safe: pthread_cancel, pthread_setcanceltype, and pthread_setcancelstate.) If we donât, our thread could be canceled in the middle of such a call, leaving its call state in disarray and potentially messing up things for the other threads in the process. In Example 4-17, weâll protect the printf call against asynchronous cancellation by setting cancellation to deferred for the duration of the call. Note that the print_count routine called by the sitting_duck thread would also need to take this precaution before it makes library or system calls.
Example 4-17. The Simple Cancellation Exampleâsitting_duck (cancel.c)
void *sitting_duck(int *my_id)
{
int i=0, last_state, last_type, last_tmp;
char messagep;
messagep = (char *)malloc(MESSAGE_MAX_LEN);
sprintf(messagep, "sitting_duck, thread #%d: ", *my_id);
pthread_mutex_lock(&lock);
{
printf("\n%s signaling main that my init is done\n", messagep);
count -= 1;
/* Signal to program that loop is being entered */
pthread_cond_signal(&init_done);
pthread_mutex_unlock(&lock);
}
/* Now, we're safe to turn on async cancelability */
printf("%s\tI'm alive, setting async cancellation ON\n", messagep);
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, &last_type);
pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, &last_state);
/* Loop forever until picked off with a cancel */
for(;;i++) {
if (i%1000) == 0)
print_count(messagep, *my_id, i);
if (i%10000 == 0) {
pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED, &last_tmp);
printf("\n%s\tHum, nobody here but us chickens. %d\n", messagep, i);
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, &last_tmp);
}
}
/* Never get this far */
return(NULL);
}When the sitting_duck thread has asynchronous cancellation enabled, it is canceled when main requests its cancellationâwhether itâs blocked by the scheduler or in the middle of its print_count loop.
Pthreads associates a cleanup stack with each thread. The stack allows a thread to do some final processing before it terminates. Although weâre discussing cleanup stacks as a way to facilitate a threadâs cancellation, you can also use cleanup stacks in threads that call pthread_exit to terminate themselves.
A cleanup stack contains pointers to routines to be executed just before the thread terminates. By default the stack is empty; you use pthread_cleanup_push to add routines to the stack, and pthread_cleanup_pop to remove them. When the library processes a threadâs termination, the thread executes routines from the cleanup stack in last-in first-out order.
Weâll adjust Example 4-17 to show how cleanup stacks work. Weâll keep the main routine the same but have it start all the threads it creates in the sitting_duck routine. Weâll change sitting_duck so that it uses the cleanup stack of the thread in which it is executing. Finally, weâll create a new routine, last_breath, so that our threads have something they can push on the stack. The sitting_duck routine calls pthread_cleanup_push to put the last_breath routine on top of the threadâs cleanup stack. At its end, it calls pthread_cleanup_pop to remove the routine from the stack, as shown in Example 4-18.
Example 4-18. Cleanup Stacksâlast_breath and sitting_duck (cancel.c)
/*
* Cleanup routine: last_breath
*/
void last_breath(char *messagep)
{
printf("\n\n%s last_breath cleanup routine: freeing 0x%x\n\n", messagep,
messagep);
free(messagep);
}
/*
* sitting_duck routine
*/
void *sitting_duck(int *my_id)
{
int i=0, last_state, last_type, last_tmp;
char *messagep;
messagep = (char *)malloc(MESSAGE_MAX_LEN);
sprintf(messagep, "sitting_duck, thread #%d: ", *my_id);
/* Push last_breath routine onto stack */
pthread_cleanup_push((void *)last_breath, (void *)messagep);
pthread_mutex_lock(&lock);
{
printf("\n%s signaling main that my init is done\n", messagep);
count -= 1;
/* Signal program that loop is being entered */
pthread_cond_signal(&init_done);
pthread_mutex_unlock(&lock);
}
printf("%s\tI'm alive, setting general cancelability ON, async cancellation
ON\n", messagep);
/* Now we're safe to turn on async cancelability */
pthread_setcancelstate(PTHREAD_CANCEL_ENABLE, &last_state);
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, &last_type);
/* Loop forever until picked off with a cancel */
for(;;i++) {
if (i%1000) == 0)
print_count(messagep, *my_id, i);
if (i%10000 == 0) {
pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED, &last_tmp);
printf("\n%s\tHum, nobody here but us chickens. %d\n", messagep, i);
pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS, &last_tmp);
}
}
/* Never get this far */
return(NULL);
/* This pop is required by the standard, every push must
have a pop in the same lexical block. */
pthread_cleanup_pop(0);
}Other cleanup routines might perform additional tasks, such as resetting shared resources to some consistent state, freeing resources the thread still has allocated, and releasing the locks the thread still holds. We can design our own cleanup routines or simply use standard library calls like pthread_mutex_unlock or free if they would suffice.
There are a few more things about the pthread_cleanup_pop function you should know. First, pthread_cleanup_pop takes a single argumentâan integer that can have either of two values:
If the value of this argument is 1, the thread that called pthread_cleanup_pop executes the cleanup routine whose pointer is being removed from the cleanup stack. Afterwards, the thread resumes at the line following its pthread_cleanup_pop call. This allows a thread to execute a cleanup routine whether or not it is actually being terminated.
If the value of this argument is 0, as it is in Example 4-18, the pointer to the routine is popped off the cleanup stack, but the routine itself does not execute.
Second, the Pthreads standard requires that there be one pthread_cleanup_pop for each pthread_cleanup_push within a given lexical scope of code. (Lexical scope refers to the code within a basic block of a C programâthat set of instructions bounded by the curly braces { and }.) Why is this required? After all, the pthread_cleanup_pop function call we planted in sitting_duck occurs after an infinite loop and is never called. The reason is that this requirement makes it easier for Pthreads library vendors to implement cleanup routines. The pthread_cleanup_push and pthread_cleanup_pop function calls are easily and commonly implemented as macros that define the start and end of a block. Picture the pthread_cleanup_push routine as a macro that ends with an open curly brace ({ ) and the pthread_cleanup_pop routine as a macro that begins with a close curly brace ( }). Itâs not hard to see why a C compiler would complain if we omitted the pthread_cleanup_pop call.
The worker threads in our ATM server are likely candidates for cancellation. There are a couple of reasons why we might want to terminate a worker that is processing an account request:
To allow a customer to abort a transaction that is in progress
To allow the system to abort a transaction for security reasons or when it is shutting down
Remember that our worker threads do hold locks and do manipulate shared dataâaccounts in the bankâs database. Dealing with the possibility of cancellation in our worker threads will have some interesting challenges.
In the remainder of this discussion, weâll focus on those changes to the server required to make its worker threads cancelable, without worrying about how the cancellation requests are generated. As a general model for a thread performing any type of request, weâll look at how a worker thread processes a deposit request.
The basic steps a worker thread performs in processing a deposit request are shown in the following pseudocode:
1 process_request 2 switch based on transaction type to deposit() 3 deposit() 4 parse request arguments 5 check arguments 6 lock account mutex 7 retrieve account from database 8 check password 9 modify account to add deposit amount 10 store modified account with database 11 unlock account mutex 12 send response to client 13 free request buffer 14 return and implicit termination
Up to Step 5, the thread would have little difficulty accommodating a cancellation request and terminating. After Step 5, it performs some tasks that make us consider ways in which it must respond to cancellation:
At Step 6, the thread obtains a lock on an account. At this moment, it must ensure somehow that, if it is the victim of cancellation, it can release the lock so that other threads can use the account after its demise. We can handle this from a cleanup routine that weâll push onto the cleanup stack.
At Step 10, the thread commits a change to the account but has yet to send an acknowledgment to the client. Letâs assume that, after we commit a change to an account, we want to make every effort to send a âtransaction completedâ response to the client. Weâll give the thread a chance to do this by having it turn off cancellation before it writes a new balance. From that point to its termination at the end of process_request, it cannot be canceled.
At Step 13, the thread frees the request buffer. The buffer was originally allocated by the boss thread, which passed it to the worker as an argument to the process_request routine. Because the boss does not save its pointer to this buffer, the worker is the only thread that knows where in the heap the buffer resides. If the worker doesnât free the buffer, nothing will. This is another chore weâll assign to the cleanup routine.
Weâll rewrite our process_request and deposit routines to illustrate these changes in Example 4-19. Weâll tackle process_request first. Note that, by default, threads starting in process_request will have deferred cancellation enabled.
Example 4-19. Changes to process_request for Cancellation (atm_svr_cancel.c)
void process_request(workorder_t *workorderp)
{
char resp_buf[COMM_BUF_SIZE];
int trans_id;
/**** Deferred cancellation is enabled by default ****/
pthread_cleanup_push((void *)free, (void *)workorderp);
sscanf(workorderp->req_buf, "%d", &trans_id);
pthread_testcancel();
switch(trans_id) {
case CREATE_ACCT_TRANS:
create_account(resp_buf);
break;
case DEPOSIT_TRANS:
deposit(workorderp->req_buf, resp_buf);
break;
case WITHDRAW_TRANS:
withdraw(workorderp->req_buf, resp_buf);
break;
case BALANCE_TRANS:
balance(workorderp->req_buf, resp_buf);
break;
default:
handle_bad_trans_id(workorderp->req_buf, resp_buf);
break;
}
/* Cancellation may be disabled by the time we get here, but this
won't hurt either way. */
pthread_testcancel();
server_comm_send_response(workorderp->conn, resp_buf);
pthread_cleanup_pop(1);
}This version of process_request starts by calling pthread_cleanup_push to place a pointer to the free system routine at the top of the threadâs cleanup stack. It passes a single parameter to freeâthe address of its request buffer. Weâve placed a matching call to pthread_cleanup_pop at the end of process_request. We pass pthread_cleanup_pop an argument of 1 so that free will run and deallocate the buffer regardless of whether or not the thread is actually canceled. If the thread is canceled, the buffer will be freed before it terminates; if not, the buffer will be freed at the pthread_cleanup_pop call.
Weâll now look at the changes to deposit in Example 4-20.
Example 4-20. A Cancelable ATM Deposit Routine (atm_svr_cancel.c)
void deposit(char *req_buf, char *resp_buf)
{
int rtn;
int temp, id, password, amount, last_state;
account_t *accountp;
/* Parse input string */
sscanf(req_buf, "%d %d %d %d ", &temp, &id, &password, &amount);
.
.
.
pthread_testcancel();
pthread_cleanup_push((void *)pthread_mutex_unlock, (void *)&account_mutex[id]);
pthread_mutex_lock(&account_mutex[id]);
/* Retrieve account from database */
rtn = retrieve_account( id, &accountp);
.
.
.
pthread_testcancel();
pthread_setcancelstate(PTHREAD_CANCEL_DISABLE, &last_state);
/* Store back to database */
if ((rtn = store_account(accountp)) < 0) {
.
.
.
pthread_cleanup_pop(1);
}This version of the deposit routine pushes the address of the pthread_mutex_unlock function onto the threadâs cleanup stack before calling pthread_mutex_lock to obtain the mutex. As we did in the process_request routine, weâve placed a matching call to pthread_cleanup_pop at the end of deposit. We pass pthread_cleanup_pop an argument of 1 so that pthread_mutex_unlock will be run at the pthread_cleanup_pop call, if the thread is not previously terminated and the mutex unlocked, as the result of a cancellation request.
Because deferred cancellation is enabled for the thread, we can be sure that it can be cancelled only at a cancellation point. However, if there were a cancellation point between the calls to pthread_cleanup_push and pthread_mutex_lock we could get into trouble. If our thread were cancelled at that time, the cleanup would try to unlock a mutex that hasnât yet been locked! The consequences of such extravagance are undefined by the Pthreads standard, so we most surely want to avoid them. Our code is safe because thereâs no such cancellation point between the calls. For the same reason, the order in which we make the calls is immaterial.
Letâs see what this means for our process_request routine. Remember that the request buffer was allocated by the boss thread and passed to the worker thread in the pthread_create call. Even though the new thread executing process_request immediately pushes the address of free onto its cleanup stack, its push inarguably happens sometime after the boss performed the initial malloc. Is this a case of too little too late?
Not necessarily. In our example of cancellation, the boss thread implicitly hands off responsibility for the request buffer to the worker thread thatâs executing process_request. The boss thread knows for certain that process_request is the first routine any newly created worker thread will run. By default, all threads are created with deferred cancellation enabled, and this is the cancelability type of the thread at the time it pushes the address of free onto the stack. If it doesnât encounter a cancellation point before we push free on the cleanup stack, thereâs no exposure. However, because some system and library calls contain cancellation points, a thread is best off when it expects to be canceled at any time. If any of your code relies on a particular thread not having any cancellation points, be sure to include a comment to that effect.
Just before the deposit routine writes the new balance to the account database, it disables cancellation by calling pthread_setcancelstate. Subsequently, the thread can complete the deposit routine without fear of cancellation. In fact, when the thread exits the deposit and returns to process_request, cancellation is still disabled.
Weâve made a lot of changes to our process_request and deposit routines to allow other threads to cancel a worker thread in the middle of a deposit request. Each change adds overhead to the real work of our ATM server. These safeguards against unexpected cancellation are charged against the performance of a thread each time it executes process_request or deposit, not just when itâs destined to be canceled. Consequently, we should carefully consider whether making our threads cancelable is worth the extra performance cost. If the threads in question run for only a short period of time before exiting, the complexity is hardly worthwhile. However, if the threads run for a long period of time and consume many system resources, the performance gains of a cancellation policy may certainly outweigh its inevitable overhead.
Following this line of reasoning, the Pthreads standard defines most blocking system calls, plus many others that can take a long time to execute, as cancellation points. Some implementations may include other library and system calls. See your platformâs documentation for information on exactly which calls it defines as cancellation points.
The operating system continuously selects a single thread to run from a systemwide collection of all threads that are not waiting for the completion of an I/O request or are not blocked by some other activity. Many threaded programs have no reason to interfere with the default behavior of the systemâs scheduler. Nevertheless, the Pthreads standard defines a thread-scheduling interface that allows programs with real-time tasks to get involved in the process.
Using the Pthreads scheduling feature, you can designate how threads share the available processing power. You may decide that all threads should have equal access to all available CPUs, or you can give some threads preferential treatment. In some applications, itâs beneficial to give those threads that perform important tasks an advantage over those that perform background work. For instance, in a process-control application, a thread that responds to input for special devices could be given priority over a thread that simply maintains the log. Used in conjunction with POSIX real-time extensions, such as memory locking and real-time clocks, the Pthreads scheduling feature lets you create real-time applications in which the threads with important tasks can be guaranteed to complete their tasks in a predictable, finite amount of time.[15]
Note that, even though the Pthreads standard specifies a scheduling interface, it allows vendors to support or not support its programming interface at their option. If your system supports the scheduling programming interface, the compile-time constant _POSIX_THREAD_PRIORITY_SCHEDULING will be TRUE.[16]
The eligibility of any given thread for special scheduling treatment is determined by the settings of two thread-specific attributes:
A threadâs scheduling priority, in relation to that of other threads, determines which thread gets preferential access to the available CPUs at any given time.
Scheduling policy
A threadâs scheduling policy is a way of expressing how threads of the same priority run and share the available CPUs.
Weâll be using these terms throughout the discussions that follow. Once weâve set the stage with some background information about scheduling scope, weâll consider the scheduling priority and policy thread attributes in much greater detail.
The concept of scheduling scope refers to the inclusiveness of the scheduling activity in which a thread participates. In other words, scope determines how many threadsâand which threadsâa given thread must compete against when itâs time for the scheduler to select one of them to run on a free CPU.
Because some operating system kernels know little about threads, the scope of thread scheduling depends upon the abilities of an implementation.[17] A given implementation may allow you to schedule threads either in process scope or in system scope. When scheduling occurs in process scope, threads are scheduled against only other threads in the same program. When scheduling occurs in system scope, threads are scheduled against all other active threads systemwide. Implementations may also provide a thread attribute that allows you to set the scheduling scope on a per-thread basis. Here, too, you can choose that a thread participate in scheduling in either process or system scope.
The discussion of scheduling scope is complicated when multiprocessing systems are involved. Many operating systems allow collections of CPUs to be treated as separate units for scheduling purposes. In Digital UNIX, for example, such a grouping is called a processor set and can be created by system calls or administrative commands. The Pthreads standard does recognize that such groupings may exist and refers to them as scheduling allocation domains. However, to avoid forcing all vendors to implement specific allocation domain sizes, the standard leaves all policies and interfaces relating to them undefined. As a result, thereâs a wide range of standard-compliant implementations out there. Some vendors, such as Digital, provide rich functionality, and others provide very little, even placing all CPUs in a single allocation domain.
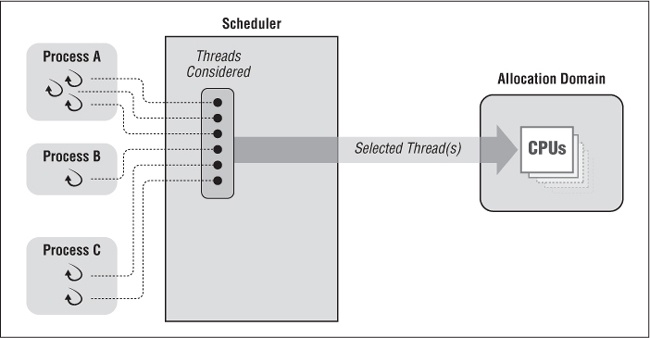
Figure 4-5 shows a system using only system scheduling scope and a single allocation domain. On one side of the scheduler we have processes containing one or more threads that need to be scheduled. On the other side the scheduler has the available CPU processing power of the system combined into the one allocation domain. The scheduler compares the priorities of all runnable threads of all processes systemwide when selecting a thread to run on an available CPU. It gives the thread with the highest priority first preference, regardless of which process it belongs to.
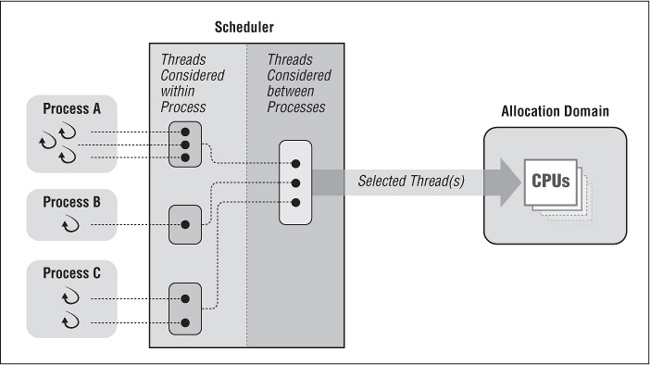
Figure 4-6 shows a system with only process scope and a single allocation domain.
The standard requires a scheduler that supports process scope to compare the scheduling priority of a thread only to the priorities of other threads of the same process. How the scheduler makes the comparison is also undefined. As a result, the priorities set by the Pthreads library on a system that provides this type of scheduling may not necessarily have any systemwide meaning.
For instance, consider such a scheduler on a multiprocessing system on which the threads of a given process (Process A) are competing for CPUs. Process A has three threads, one with very high priority and two with medium priority. The scheduler can place the high priority thread on one of the CPUs and thus meet the standardâs requirements for process-scope scheduling. It need do no moreâeven if other CPUs in the allocation domain have lower priority threads from other processes running on them. The scheduler can leave Process Aâs remaining runnable medium priority threads waiting for its high priority thread to finish running. Thus, this type of scheduling can deny a multithreaded application the benefit of multiple CPUs within the allocation domain.
An implementation that uses system-scope scheduling with a single allocation domain, such as the one we showed in Figure 4-5, behaves quite differently. If the threads of a process in system scope have high enough priorities, they will be scheduled on multiple CPUs at the same time. System-scope scheduling is thereby much more useful than process-scope scheduling for real-time or parallel processing applications when only a single allocation domain is available.
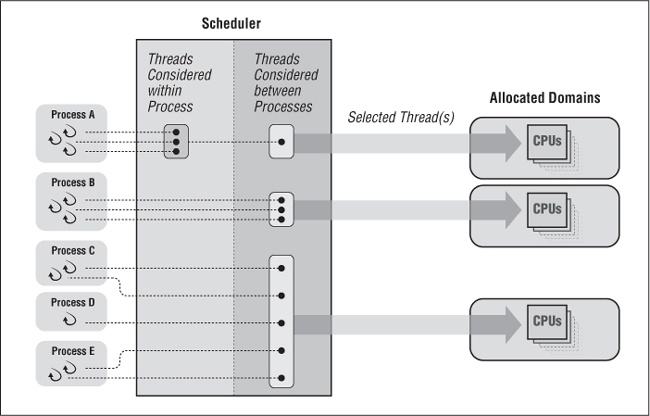
Figure 4-7 shows a system with multiple allocation domains supporting both process and system scope. The threads of Process A all have process scheduling scope and exclusive access to an allocation domain. Process Bâs threads have system scope and their own allocation domain as well. The threads of all other processes have system scope and are assigned to the remaining allocation domain.
Because the threads of Process A and Process B donât share an allocation domain with those of other processes, they will execute more predictably. Their threads will never wait for a higher priority thread of another process to finish or preempt another processâs lower priority thread. Because Process Bâs threads use system scope, they will always be able to simultaneously access the multiple CPUs within its domain. However, because Process Aâs threads use process scope, they may not always be able to do so. It depends on the implementation on which they run.
You should take into account one potential pitfall of using multiple scheduler allocation domains if your implementation allows you to define them. When none of the threads in Process A or B are running on the CPUs in their allocation domains, the CPUs are idle, regardless of the load on other CPUs in other domains. You may in fact obtain higher overall CPU utilization by limiting the number of allocation domains. Be certain that you understand the characteristics of your application and its threads before you set scheduling policies that affect its performance and behavior.
If an implementation allows you to select the scheduling scope of a thread using a per-thread attribute, youâll probably set up the threadâs attribute object, as shown in Example 4-21.
Example 4-21. Setting Scheduling Scope in an Attribute Object (sched.c)
pthread_attr_t custom_sched_attr;
.
.
.
pthread_attr_init(&custom_sched_attr);
pthread_attr_setscope(&custom_sched_attr, PTHREAD_SCOPE_SYSTEM);
pthread_create(&thread, &custom_sched_attr, ...);
.
.
.The pthread_attr_setscope function sets the scheduling-scope attribute in a thread attribute object to either system-scope scheduling (PTHREAD_SCOPE_SYSTEM), as in Example 4-21, or process-scope scheduling (PTHREAD_SCOPE_PROCESS). Conversely, youâd use pthread_attr_getscope to obtain the current scope setting of an attribute object.
For the remainder of our discussion, weâll try to ignore scope. We canât avoid using terms that have different meanings depending upon what type of scheduling scope is active. As a cheat sheet for those occasions when these terms appear, refer to the following:
When we say pool of threads, we mean:
In process scope: all other threads in the same process
In system scope: all threads of all processes in the same allocation domain
When we say scheduler, we mean:
In process scope: the Pthreads library and/or the scheduler in the operating systemâs kernel
In system scope: the scheduler in the operating systemâs kernel
When we say processing slot, we mean:
In process scope: the portion of CPU time allocated to the process as a whole within its allocation domain
In system scope: the portion of CPU time allocated to a specific thread within its allocation domain
In selecting a thread for a processing slot, the scheduler first considers whether it is runnable or blocked. A blocked thread must wait for some particular event, such as I/O completion, a mutex, or a signal on a condition variable, before it can continue its execution. By contrast, a runnable thread can resume execution as soon as itâs given a processing slot.
After it has weeded out the blocked threads, the scheduler must select one of the remaining runnable threads to which it will give the processing slot. If there are enough slots for all runnable threads (for instance, there are four CPUs and four threads), the scheduler doesnât need to apply its scheduling algorithm at all, and all runnable threads will get a chance to run simultaneously.
The selection algorithm that the scheduler uses is affected by each runnable threadâs scheduling priority and scheduling policy. As we mentioned before, these are per-thread attributes; weâll show you how to set them in a few pages.
The scheduler begins by looking at an array of priority queues, as shown in Figure 4-8. There is a queue for each scheduling priority and, at any given priority level, the threads that are assigned that priority reside. When looking for a thread to run in a processing slot, the scheduler starts with the highest priority queue and works its way down to the lower priority queues until it finds the first thread.
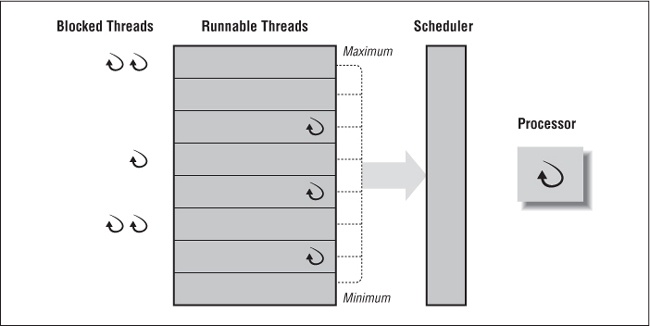
In this illustration only three of the priority queues hold runnable threads. When running threads either involuntarily give up their processing slot (more on this later) or go from blocked to runnable, they are placed at the end of the queue for their priority. Over time, the population of the priority queues will grow and decline.
Whenever a thread with a higher priority than the current running thread becomes runnable, it interrupts the running thread and replaces it in the processing slot. From the standpoint of the thread thatâs been replaced, this is known as an involuntary context switch.
A threadâs scheduling policy determines how long it runs when it moves from the head of its priority queue to a processing slot. The two main scheduling policies are SCHED_FIFO and SCHED-RR:
SCHED_FIFO
This policy (first-in first-out) lets a thread run until it either exits or blocks. As soon as it becomes unblocked, a blocked thread that has given up its processing slot is placed at the end of its priority queue.
SCHED_RR
This policy (round robin) allows a thread to run for only a fixed amount of time before it must yield its processing slot to another thread of the same priority. This fixed amount of time is usually referred to as a quantum. When a thread is interrupted, it is placed at the end of its priority queue.
The Pthreads standard defines an additional policy, SCHED_OTHER, and leaves its behavior up to the implementors. On most systems, selecting SCHED_OTHER will give a thread a policy that uses some sort of time sharing with priority adjustment. By default, all threads start life with the SCHED_OTHER policy. After all, time sharing with priority adjustment is the typical UNIX scheduling algorithm for processes. It works like SCHED_RR, giving threads a quantum of time in which to run. Unlike SCHED_FIFO and SCHED_RR, however, it causes the scheduler to occasionally adjust a threadâs priority without any input from the programmer. This priority adjustment favors threads that donât use all their quantum before blocking, increasing their priority. The idea behind this policy is that it gives interactive I/O-bound threads preferential treatment over CPU-bound threads that consume all their quantum.
The definitions of SCHED_FIFO, SCHED_RR, and SCHED_OTHER actually come from the POSIX real-time extensions (POSIX.1b). Any Pthreads implementation that uses the compile-time constant _POSIX_THREAD_PRIORITY_SCHEDULING will also recognize them. As weâll continue our discussion, weâll find other POSIX.1b features that are useful in manipulating priorities.
Although you can set different scheduling priorities and policies for each thread in an application, and even dynamically change them in a running thread, most applications donât need this complexity.
A real-time application designer would typically first make a broad division between those tasks that must be completed in a finite amount of time and those that are less time critical. Those threads with real-time tasks would be given a SCHED_FIFO policy and high priority. The remaining threads would be given a SCHED_RR policy and a lower priority. The scheduling priority of all of these threads would be set to be higher than those of any other threads on the system. Ideally the host would be capable of system-scope scheduling.
As shown in Figure 4-9, the real-time threads of the real-time application will always get access to the CPU when they are runnable, because they have higher priority than any other thread on the system. When a real-time thread gets the CPU it will complete its task without interruption (unless, of course, it blocksâbut that would be a result of poor design). No other thread can preempt it; no quantum stands in its way. These threads behave like event (or interrupt) handlers; they wait for something to happen and then process it to completion within the shortest time possible.
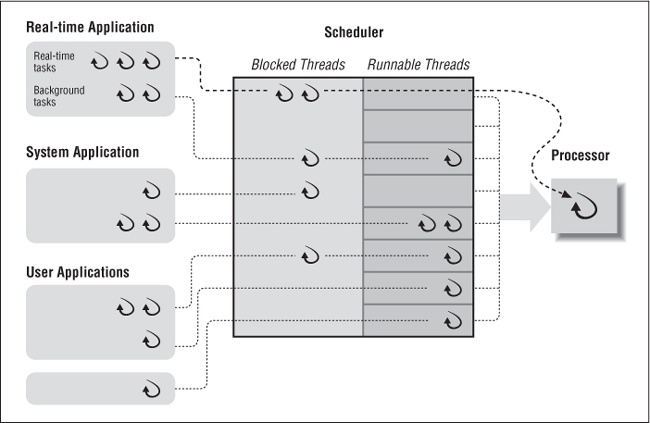
Because of their high priority, the non-real-time threads in the application also get preferential treatment, but they must share the CPU with each other as their quantums expire. These threads usually perform the background processing for the application.
An example of this kind of real-time application would be a program that runs chemical processing equipment. The threads that deploy hardware control algorithmsâperiodically reading sensors, computing new control values, and sending signals to actuatorsâwould run with the SCHED_FIFO policy and a high priority. Other threads that performed the less critical tasksâupdating accounting records for chemicals used and recording the hours for employees running the equipmentâwould run with the SCHED_RR policy and at a lower priority.
You can set a threadâs scheduling policy and priority in the thread attribute object you specify in the pthread_create call that creates the thread. Assume that we have a thread attribute object named custom_sched_attr. Weâve initialized it with a call to pthread_attr_init. We specify it in calls to pthread_attr_setschedpolicy to set the scheduling policy and pthread_attr_setschedparam to set the scheduling priority, as shown in Example 4-22.
Example 4-22. Setting a Threadâs Scheduling Attributes (sched.c)
pthread_attr_t custom_sched_attr; int fifo_max_prio, fifo_min_prio; struct sched_param fifo_param; . . . pthread_attr_init(&custom_sched_attr); pthread_attr_setinheritsched(&custom_sched_attr, PTHREAD_EXPLICIT_SCHED); pthread_attr_setschedpolicy(&custom_sched_attr, SCHED_FIFO); fifo_max_prio = sched_get_priority_max(SCHED_FIFO); fifo_min_prio = sched_get_priority_min(SCHED_FIFO); fifo_mid_prio = (fifo_min_prio + fifo_max_prio)/2; fifo_param.sched_priority = fifo_mid_prio; pthread_attr_setschedparam(&custom_sched_attr, &fifo_param); pthread_create(&(threads[i]), &custom_sched_attr, ....);
The way in which pthread_attr_setschedparam is used demands a little more explanation.
When you use pthread_attr_setschedpolicy to set a threadâs policy to SCHED_FIFO or SCHED_RR, you can also call pthread_attr_setschedparam to set its parameters. The pthread_attr_setschedparam function takes two arguments: the first is a thread attribute object, the second is a curious thing defined in the POSIX.1b standard and known as astruct sched_param. It looks like this:
struct sched_param {
int sched_priority;
}Thatâs it. The struct sched_param has only a single required member and specifies a single attributeâa scheduling priority. (Some Pthreads implementations may store other information in this structure.) Letâs see how we stick a priority into this thing.
The POSIX.1b standard specifies that there must be at least 32 unique priority values apiece for the SCHED_RR and SCHED_FIFO priorities. (The standard does not require that there be defined priorities for SCHED_OTHER.) The absolute values and actual range of the priorities depend upon the implementation, but one thingâs for certainâyou can use sched_get_priority_max and sched_get_priority_min to get a handle on them.
In our example, we call sched_get_priority_max and sched_get_priority_min to obtain the maximum and minimum priority values for the SCHED_FIFO policy. We add the two together and divide by two, coming up with a priority level thatâs happily in the middle of the SCHED_FIFO priority range. Itâs this priority value that we insert in the priority member of our struct sched_param. A call to pthread_attr_setschedparam and, voila!âour thread has a nice middling priority with which to work.
Before we leave our discussion of setting a threadâs scheduling attributes statically when the thread is created, weâll make one final point. If you must retrieve the scheduling attribute settings from a thread attribute object, you can use the functions pthread_attr_getschedpolicy and pthread_attr_getschedparam. They work in the same way as the corresponding functions for other thread attributes.
Now weâll look at a way to set the scheduling policy and priority of a selected thread while itâs running. In Example 4-23, we set a target threadâs policy to SCHED_FIFO and its priority to the priority level stored in the variable fifo_min_prio.
Example 4-23. Setting Policy and Priority Dynamically (sched.c)
fifo_sched_param.sched_priority = fifo_min_prio; pthread_setschedparam(threads[i], SCHED_FIFO, &fifo_min_prio);
As you can see, the pthread_setschedparam call sets both policy and priority at the same time. Conversely, the pthread_getschedparam function returns the current policy and priority for a specified thread. Be careful when you use the pthread_setschedparam function to dynamically adjust another threadâs priority. If you raise a threadâs priority higher than your own and it is runnable, it will preempt you when you make the call.
If you decide to use scheduling, you donât need to individually set the scheduling attributes of each thread you create. Instead, you can specify that each thread should inherit its scheduling characteristics from the thread that created it. Like other per-thread scheduling attributes, the inheritance attribute is specified in the attribute object used at thread creation, as shown in Example 4-24.
Example 4-24. Setting Scheduling Inheritance in an Attribute Object (sched.c)
pthread_attr_t custom_sched_attr;
.
.
.
pthread_attr_init(&custom_sched_attr);
pthread_attr_setinheritsched(&custom_sched_attr, PTHREAD_INHERIT_SCHED)
.
.
.
pthread_create(&thread, &custom_sched_attr, ...);The pthread_attr_setinheritsched function takes a thread attribute object as its first argument and as its second argument either the PTHREAD_INHERIT_SCHED flag or the PTHREAD_EXPLICIT_SCHED flag. You can obtain the current inheritance attribute from an attribute object by calling pthread_attr_getinheritsched.
Weâre now ready to assign different scheduling priorities to the worker threads in our ATM server, based on the type of transaction they are processing. To illustrate how our server might use scheduling attributes, weâll give highest priority to the threads that service deposit requests. After all, time is money and the sooner the bank has your money the sooner they can start making money with it. Specifically, weâll add code to our server so that deposit threads run at a high priority with a SCHED_FIFO scheduling policy and the other threads run at a lower priority using a SCHED_RR scheduling policy.
We donât need to change worker thread code; only the boss thread concerns itself with setting scheduling attributes. Weâll globally declare some additional thread attribute objects (pthread_attr_t) in our atm_server_init routine in Example 4-25 and prepare them to be used by the boss thread when it creates worker threads.
Example 4-25. Creating Attribute Objects for Worker Threads (sched.c)
/* global variables */
.
.
.
pthread_attr_t custom_attr_fifo, custom_attr_rr;
int fifo_max_prio, rr_min_prio;
struct sched_param fifo_param, rr_param;
atm_server_init()
{
.
.
pthread_attr_init(&custom_attr_fifo);
pthread_attr_setschedpolicy(&custom_attr_fifo, SCHED_FIFO);
fifo_param.sched_priority = sched_get_priority_max(SCHED_FIFO);
pthread_attr_setschedparam(&custom_attr_fifo, &fifo_param);
pthread_attr_init(&custom_attr_rr);
pthread_attr_setschedpolicy(&custom_attr_rr, SCHED_RR);
rr_param.sched_priority = sched_get_priority_min(SCHED_RR);
pthread_attr_setschedparam(&custom_attr_rr, &rr_param);
.
.
.
}The boss thread will use the custom_attr_fifo attribute object when creating deposit threads. The atm_server_init routine sets this attribute object to use the SCHED_FIFO scheduling policy and the maximum priority defined for the policy. The boss thread will use the custom_attr_rr attribute object for all other worker threads. It is set with the SCHED_RR scheduling policy and the minimum priority defined for the policy. The boss thread uses these attribute objects in the serverâs main routine:
Example 4-26. Creating threads with custom scheduling attributes (sched.c)
extern int
main(void)
.
.
.
atm_server_init(argc, argv);
for(;;) {
/*** Wait for a request ***/
workorderp = (workorder_t *)malloc(sizeof(workorder_t));
server_comm_get_request(&workorderp->conn, workorderp->req_buf);
sscanf(workorderp->req_buf, "%d", &trans_id);
.
.
.
switch(trans_id) {
case DEPOSIT_TRANS:
pthread_create(worker_threadp, &custom_attr_fifo, process_request,
(void *)workorderp);
break;
default:
pthread_create(worker_threadp, &custom_attr_rr, process_request,
(void *)workorderp);
break;
}
pthread_detach(*worker_threadp);
}
server_comm_shutdown();
return 0;
}In our serverâs main routine, the boss thread checks the request type before creating a thread to process it. If the request is a deposit, the boss specifies the custom_attr_fifo attribute object in the pthread_create call. Otherwise, it uses the custom_attr_rr attribute object.
We may take great pains to apply scheduling to the threads in our program, designating those threads that should be given preferential access to the CPU when theyâre ready to run. However, what if our high priority threads must contend for the same resources as our lower priority threads? Itâs likely that at times a high priority thread will stall waiting for a mutex lock held by a lower priority thread. This is the priority inversion phenomenon of which we spoke earlier. The mutex plainly doesnât recognize that some threads that ask for it are more important than others.
Consider a real-time multithreaded application that controls the operation of a power plant. One controls fuel intake and must react quickly and predictably to changes in flow rate and line pressure; this thread has high priority. Another thread collects statistics on plant operations for monthly reports and collects information on the state of the plant once an hour; this thread is assigned a lower priority. An additional thread, of medium priority in the application, perhaps, faxes sandwich orders at lunch time.
Both the fuel-control and statistic-gathering threads must control a mechanical arm to position a temperature sensor at various locations within the plant to take temperature readings. Each contends for a single mutex that synchronizes access to the arm.
Weâll start with a situation in which all threads are blocked and the mutex is unlocked. Suppose that the sequence of events listed in the left column of Table 4-2 occurs. The statistics-gathering thread runs first, grabs the mutex, and ends up by blocking the fuel-control thread that is ready to run.
Table 4-2. Priority Inversion in a Power Plant Application (1)
Event | Fuel-Control Thread | Medium Priority Thread | Statistics-Gathering Thread | Arm Mutex |
|---|---|---|---|---|
Start | Blocked | Blocked | Blocked | Unlocked |
The statistics-gathering thread must take a temperature. | Blocked | Blocked | Running | Unlocked |
The statistics-gathering thread acquires the mutex. | Blocked | Blocked | Running | Locked by statistics-gathering thread |
An event occurs, waking the fuel-control thread. It preempts the statistics thread. | Running | Blocked | Runnable | Locked by statistics-gathering thread |
The fuel-control thread tries to get the mutex and blocks. The statistics thread regains the CPU. | Blocked on mutex | Blocked | Running | Locked by statistics-gathering thread |
The situation can actually get worse when, as shown in Table 4-3, the medium priority thread awakens. It has a higher priority than the statistics-gathering thread and does not need to wait for the mutex the medium thread currently holds. Itâs runnable and will preempt the statistics-gathering thread. Now the fuel-control thread must wait for the medium priority thread, tooâand this thread doesnât even need to use the arm!
Table 4-3. Priority Inversion in a Power Plant Application (2)
Event | Fuel-Control Thread | Medium Priority Thread | Statistics-Gathering Thread | Arm Mutex |
|---|---|---|---|---|
An event occurs, waking the medium priority thread. It preempts the statistics-gathering thread. | Blocked on mutex | Running | Runnable | Locked by statistics-gathering thread |
If the sirens and flashing lights werenât so distracting, weâd redesign the application so that the fuel-control and statistics-gathering threads no longer use a common resource. But we need to introduce a new Pthreads feature, and besides, we have only so much time before we have to evacuate the plant.
The Pthreads standard allows (but does not require) implementations to design mutexes that can give a priority boost to low priority threads that hold them. We can associate a mutex with either of two priority protocols that provide this feature: priority ceiling or priority inheritance. Weâll start with a discussion of priority ceiling, the simpler of the two protocols.
The priority ceiling protocol associates a scheduling priority with a mutex. Thus equipped, a mutex can assign its holder an effective priority equal to its own, if the mutex holder has a lower priority to begin with.
Letâs apply this feature to our power plant example and see what happens. Weâll associate a high priority with the mutex that controls access to the arm and revisit the earlier sequence of events. Table 4-4 illustrates the results.
Table 4-4. Priority Inversion in a Power Plant Application
Event | Fuel-Control Thread | Medium Priority Thread | Statistics-Gathering Thread | Arm Mutex (High Priority) |
|---|---|---|---|---|
Start | Blocked | Blocked | Blocked | Unlocked |
The statistics-gathering thread must take a temperature. | Blocked | Blocked | Running | Unlocked |
The statistics-gathering thread acquires the mutex. It gets an effective priority of high. | Blocked | Blocked | Running | Locked by statistics-gathering thread |
An event occurs, waking the fuel-control thread. It does not preempt the statistics-gathering thread, which is also at high priority. | Runnable | Blocked | Running | Locked by statistics-gathering thread |
An event occurs, waking the medium priority thread. It does not preempt the statistics-gathering thread, which is also at high priority. | Runnable | Runnable | Running | Locked by statistics-gathering thread |
At this point, the statistics-gathering thread will complete its operation at the highest priority and in the shortest period of time. Table 4-5 shows the sequence of events that occurs when it releases the mutex.
Table 4-5. Priority Inversion in a Power Plant Application
Event | Fuel-Control Thread | Medium Priority Thread | Statistics-Gathering Thread | Arm Mutex (High Priority) |
|---|---|---|---|---|
The statistics-gathering thread unlocks the mutex. It reverts to low priority and is preempted by the highest priority runnable thread. This is the fuel-control thread. | Running | Runnable | Runnable | Unlocked |
The fuel-control thread tries to get the mutex and succeeds. | Running | Runnable | Running | Locked by fuel thread |
Now the fuel-control thread can do its work, having to wait only for the statistics-gathering threadânot for the medium priority thread as well. Although the fuel-control thread must wait, it waits for a shorter period of time and in a more predictable manner.
If your platform supports the priority ceiling protocol, the compile-time constant _POSIX_THREAD_PRIO_PROTECT will be defined. Example 4-27 shows how to create a mutex that uses the priority ceiling protocol.
Example 4-27. Setting a Priority Ceiling on a Mutex (mutex_ceiling.c)
pthread_mutex_t m1; pthread_mutexattr_t mutexattr_prioceiling; int mutex_protocol, high_prio; . high_prio = sched_get_priority_max(SCHED_FIFO); . pthread_mutexattr_init(&mutexattr_prioceiling); pthread_mutexattr_getprotocol(&mutexattr_prioceiling, &mutex_protocol); pthread_mutexattr_setprotocol(&mutexattr_prioceiling, PTHREAD_PRIO_PROTECT); pthread_mutexattr_setprioceiling(&mutexattr_prioceiling, high_prio); pthread_mutex_init(&m1, &mutexattr_prioceiling);
We first declare a mutex attribute object (pthread_mutex_attr_t) and initialize it by calling pthread_mutexattr_init. Our call to pthread_mutexattr_getprotocol returns the priority protocol that is associated with our mutex by default. The priority protocol attribute can have one of three values:
If the pthread_mutexattr_getprotocol call does not show that the mutex is using the priority ceiling protocol, we call the pthread_mutexattr_setprotocol function to set this protocol in the mutexâs attribute object. After weâve done so, we call pthread_mutexattr_setprioceiling to set the fixed priority ceiling attribute in the mutex object. (Conversely, a call to pthread_mutexattr_getprioceiling would return the current value of this attribute.) The priority passed is an integer argument set up in the same manner as a threadâs priority value. Finally, we initialize the mutex by specifying the mutex attribute object to pthread_mutex_init.
The priority inheritance protocol lets a mutex elevate the priority of its holder to that of the waiting thread with the highest priority. If we applied the priority inheritance protocol to the arm mutex in our power plant example, the result would be that the statistics-gathering thread wouldnât unconditionally receive a priority boost as soon as it won the mutex lock; it would be elevated to high priority only when the fuel-control thread starts to wait on the mutex. Because the priority inheritance protocol awards a priority boost to a mutex holder only when itâs absolutely needed, it can be more efficient than the priority ceiling protocol.
If your platform supports the priority inheritance feature, the compile-time constant _POSIX_THREAD_PRIO_INHERIT will be TRUE. Example 4-28 shows how to create a mutex with the priority inheritance attribute. The process is nearly identical to the one we used to set up the priority ceiling protocol for the mutex in Example 4-27.
Example 4-28. Setting Priority Inheritance on a Mutex (mutex_priority.c)
pthread_mutex_t m1;
pthread_mutexattr_t mutexattr_prioinherit;
int mutex_procotol;
.
.
.
pthread_mutexattr_init(&mutexattr_prioinherit);
pthread_mutexattr_getprotocol(&mutexattr_prioinherit, &mutex_protocol);
if (mutex_protocol != PTHREAD_PRIO_INHERIT) {
pthread_mutexattr_setprotocol(&mutexattr_prioinherit, PTHREAD_PRIO_INHERIT);
}
pthread_mutex_init(&m1, &mutexattr_prioinherit);Letâs return to our ATM server example. In its most recent version, we introduced a scheduling framework and started to assign different priorities to different threads. Having done so, weâve introduced a risk that our threads may encounter priority inversion situations. A high priority thread could attempt to perform a deposit transaction on the same account for which a low priority thread is already processing a different transaction. When it does so, the high priority thread will very likely need to wait on the mutex that the low priority thread currently holds. We can help out our high priority threads by assigning this mutex a scheduling attribute of some sort.
Which protocol should we useâpriority ceiling or priority inheritance? If we use the priority ceiling protocol, we would have to associate a very high priority ceiling with the mutexes that guard the accounts. Overall, this would have a rather negative effect on our serverâs behavior and the performance of deposit transactions in particular. Low priority threads would always be given a priority boost whenever they obtained a mutex, regardless of whether a deposit thread needs to lock the same mutex. Because each worker thread holds the mutex for an account for a significant length of time, the schedulerâs priority queues would fill with runnable, high priority threads. A deposit thread would just be another high priority thread in the queue and would not get any special treatment. This is not what we want.
For a program like our ATM server, it makes much more sense to use the priority inheritance protocol. If we assign the priority inheritance attribute to each of our account mutexes, each mutex would boost the priority of its owner only when a high priority thread is waiting. This would give our high priority deposit threads a better chance to access accounts. The scheduler continues to favor the deposit threads, and when a deposit thread is blocked by a low priority thread that is holding a required mutex, the mutexâs priority inheritance policy ensures that the low priority thread gets a needed boost. As a result, the low priority thread can get its business done quickly, release the mutex, and get out of the way of our important deposit threads. The worst case would be when the deposit thread must wait for one in-progress operation on the account before it can start its transaction.
To associate the priority inheritance protocol with our mutexes, weâll change our serverâs initialization routine as shown in Example 4-29.
Example 4-29. Initializing Priority-Savvy Mutex in the ATM (mutex_priority.c)
.
.
.
pthread_mutex_attr_t mutexattr_prioinherit;
.
.
.
void atm_server_init(int argc, char **argv)
{
.
.
.
pthread_mutexattr_setprotocol(&mutexattr_prioinherit, PTHREAD_PRIO_INHERIT);
for (i = 0; i < MAX_NUM_ACCOUNTS; i++)
pthread_mutex_init(&account_mutex[i], &mutexattr_prioinherit);
.
.
.
}[15] See the book POSIX.4: Programming for the Real World by Bill O. Gallmeister, from OâReilly & Associates, for in-depth discussion of the POSIX real-time extensions.
[16] If your implementation supports the POSIX real-time extensions, you can use the sched_yield call to force some broad form of scheduling. A sched_yield call places the calling thread at the end of its scheduling priority queue and lets another thread of the same priority take its place.
[17] As weâll discuss in Chapter 6, some systems provide the abstraction of a thread within the container of the process without any help from the kernel. On these systems the lower-level operating system kernel schedules processes to run, not threads.
Get PThreads Programming now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

