We canât talk much about Grails without a solid understanding of Groovy, because itâs so integral to how Grails works.
Groovy is a JVM language with a primary goal of extending Java. By adding a Meta Object Protocol (MOP) to enable metaprogramming, Groovy adds powerful capabilities that enable dynamic programming (changing and adding behavior at runtime), domain-specific languages (DSLs), and a huge number of convenience methods and approaches that simplify your code and make it more powerful.
Groovy compiles to bytecode just like Java does (although it creates different bytecode). As Java developers, we tend to think that only javac can compile source code to create .class files, but there are many JVM languages that do as well (including Groovy, JRuby, Jython, and hundreds more). There are also libraries such as BCEL that you can use to programmatically create bytecode. As a result, Groovy and Java interoperate well; you can call Java methods from Groovy and vice versa, a Java class can extend a Groovy class or implement a Groovy interface, and in general, you donât need to even think about interoperability because it âjust works.â
The Groovy equivalent of javac is groovyc, and because it compiles both Groovy and Java code, itâs simple to use for your project code. Of course in Grails applications, we rarely even think about this process (except when it fails) because Grails scripts handle that, but if youâre manually compiling code (e.g., in a Gradle build or with Gant), itâs about as simple as working with Java code.
Ordinarily, Grails developers donât install a Groovy distribution, because each version of Grails ships with the groovy-all JAR with which it was developed. Groovy is a fundamental part of Grails, so using it in a Grails application is trivial. But itâs easy to install if you want to use Groovy outside of Grails, for example, for scripting or to run standalone utility applications. Just download the version you want, unpack the ZIP file to your desired location, set the GROOVY_HOME environment variable point at the location you chose, and add the $GROOVY_HOME/bin (or %GROOVY_HOME%\bin in Windows) directory to the PATH environment variable. Thatâs all you need to do; run groovy -v from a command prompt to verify that everything is working.
If youâre using Windows, the download page has installers that will install the distribution and configure the environment.
There is also a new tool, GVM (Groovy enVironment Manager). It was inspired by the Ruby RVM and rbenv tools, and it will install one or more versions of Groovy, as well as Grails, Griffon, Gradle, and vert.x. It uses the bash shell, so it works in Linux, OS X, and Windows, if you have Cygwin installed. Itâs very simple to use, and if you have projects that require different versions of Groovy, itâs easy to switch between them. See the GVM site for usage information.
The Groovy console is a great way to prototype code. It doesnât have many text editor or IDE features, but you can run arbitrary Groovy code and inspect the results. You can run it in debug mode and attach to it from a debugger (e.g., your IDE) to dig deeper and look at the call stack. Itâs convenient to test an algorithm or a fix, or to do what-if experiments. And you donât need to create a class or a main() methodâyou can execute any valid code snippet. If Groovy is installed and in your PATH, run the console by executing groovyConsole from the command line. I encourage you to test out the code examples as theyâre shown to make sure you understand how everything works.
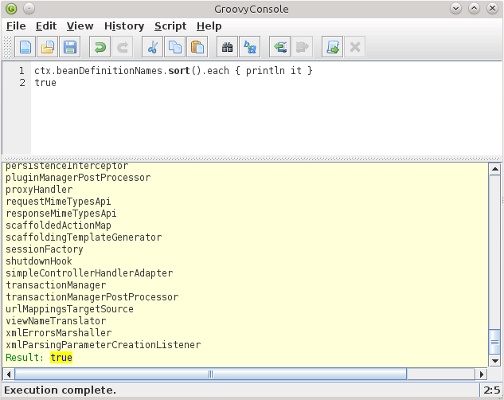
The Groovy console is also a part of Grailsâyou can run grails console from the command line and start the Grails version of the console. Itâs the same application, but it also has Grails-specific hooks like easy access to the Spring ApplicationContext and automatic application of the PersistenceContextInterceptors. You can use it to call Grails object relational mapping (GORM) methods, services, and pretty much anything in your application that isnât related to an HTTP request. As a plugin author, I often troubleshoot bean definition issues by running the following (as shown in Figure 1-1):
ctx.beanDefinitionNames.sort().each{printlnit}true
This grabs all of the Spring bean names (a String[] array) from the ApplicationContext (the ctx binding variable), sorts them (into a new List), and prints each name. The true statement at the end is a trick to avoid printing the entire list again in its toString() form, because the console treats the last statement as the return value of the script and renders it in the output window.
One of Groovyâs strengths comes from its support of optional typing. You can define the types of variables, method parameters, method return values, and so on, like you do in Java, but you often donât need to. Groovy determines the actual type at runtime and invokes the methods on the objects if they exist (or if youâve added support to the metaclass; more on this later). The approach used is often called duck typing; i.e., if it walks and talks like a duck, consider it a duck.
This isnât the same as weak typing. The objects themselves have a concrete type (unlike JavaScript, C, Perl, and so on), but youâre not restricted by the compiler to only invoke methods defined in the specified type of the object. If the object supports the call, it will work.
In fact, youâre not even restricted to hardcoding the method or property names. You can dynamically invoke a method or access a property value by name:
defperson=...StringmethodName=...defvalue=person."$methodName"(1,2)StringpropertyName=...defotherValue=person."$propertyName"
Creating and populating Java collections might not seem that bad if you havenât seen how itâs done in Groovy, but once you have, you wonât want to go back. Hereâs some code to add a few elements to an ArrayList in Java:
List<String>things=newArrayList<String>();things.add("Hello");things.add("Groovy");things.add("World");
And hereâs the equivalent code in Groovy:
List<String>things=["Hello","Groovy","World"]
The difference is rather stark, and using more idiomatic Groovy (thereâs not much need for generics in Groovy), itâs even cleaner:
defthings=['Hello','Groovy','World']
Note that here Iâm taking advantage of Groovyâs support for declaring strings using single or double quotes; this is described in more detail later in the chapter.
There isnât a separate syntax for a Set, but you can use type coercion for that. Either:
Setthings=['Hello','Groovy','World']
or:
defthings=['Hello','Groovy','World']asSet
The syntax for a Map is similar, although a bit larger, because we need to be able to specify keys and values delimited with colons:
defcolors=['red':1,'green':2,'blue':3]
We can make that even more compact because, when using strings as keys that have no spaces, we can omit the quotes:
defcolors=[red:1,green:2,blue:3]
You might be wondering what the type of these collections isâsome funky Groovy-specific interface implementations that handle all the details of the Groovy magic happening under the hood? Nope, Lists and Sets are just regular java.util.ArrayList and java.util.HashSet instances. Maps are java.util.LinkedHashMap instances instead of the more common java.util.HashMap; this is a convenience feature that maintains the order in the map based on the declaration order. If you need the features of other implementations such as LinkedList or TreeMap, just create them explicitly like you do in Java.
Lists and Maps support array-like subscript notation:
defthings=['Hello','Groovy','World']assertthings[1]=='Groovy'assertthings[-1]=='World'defcolors=[red:1,green:2,blue:3]assertcolors['red']==1
Maps go further and let you access a value using a key directly as long as there are no spaces:
defcolors=[red:1,green:2,blue:3]assertcolors.green==2
Youâve heard of POJOsâPlain Old Java Objectsâand JavaBeans. These are simple classes without a lot of extra functionality and, in the case of JavaBeans, they follow conventions such as having a zero-argument constructor and having getters and setters for their attributes. In Groovy, we create POGOsâPlain Old Groovy Objectsâthat are analogous and work the same way, although theyâre more compact.
Consider a POJO that represents a person in your application. People have names, so this Person class should have firstName, initial, and lastName attributes to store the personâs full name. In Java, we represent those as private String fields with getter methods, and setter methods if weâre allowing the attributes to be mutable. But often we donât do any work when setting or getting these valuesâwe just store them and retrieve them. But dropping this encapsulation and replacing each private field, getter, and setter with a public field would be limiting in the future because, at some point, there might be a reason to manipulate the value before storing or retrieving it. So we end up with a lot of repetetive boilerplate in these POJOs. Sure, our IDEs and other tools can autogenerate the code and we can ignore it and pretend that itâs not there, but it is, and it unnecessarily bulks up our codebase.
Groovy fixes this mess for us by automatically generating getters and setters for public properties during compilation. But thatâs only the case if theyâre not already there; so this gives you the flexibility of defining attributes as public fields while retaining the ability to override the behavior when setting or getting the values. Groovy converts the public field to a private field but pretends the public field is still there. When you read the value, it calls the getter; and when you set the value, it calls the setter.
Consider this POGO:
classThing{Stringnameintcount}
The default scope for classes, fields, and methods is public (more on this later), so this is a public class and the two fields are public. The compiler, however, will convert these to private fields and add getName(), setName(), getCount(), and setCount() methods. This is most clear if you access this class from Java; if you try to access the name or count fields, your code wonât compile.
Although Groovy generates getters and setters for you, you can define your own:
classThing{StringnameintcountvoidsetName(Stringname){// do some work before setting the valuethis.name=name// do some work after setting the value}}
and in this case, only the setName(), getCount(), and setCount() methods will be added.
You can also have read-only and write-only properties. You can create an immutable read-only property by making the field final and setting it in a parameterized constructor:
classThing{finalStringnameintcountThing(Stringname){this.name=name}}
Because itâs final, the compiler doesnât even generate a setter method, so it cannot be updated. If you want to retain the ability to update it internally, make the field private and create a getter method. Because itâs private, the compiler wonât generate the setter:
classThing{privateStringnameintcountStringgetName(){name}}
Youâll need a parameterized constructor to set the value, or set it in another method. Creating a write-only property is similar; use a private field and create only the setter:
classThing{privateStringnameintcountvoidsetName(Stringname){this.name=name}}
Warning
In general, it is safe to replace getter and setter method calls with property access; for example, person.firstName is a lot more compact than person.getFirstName() and equivalent. One case where itâs not safe is with the getClass() method and Maps. If you try to determine the class of a Map instance using the .class property form of the getClass() method, Groovy will look up the value stored under the "class" key and probably return null. I always use getClass() even when I know the object isnât a Map just to be on the safe side.
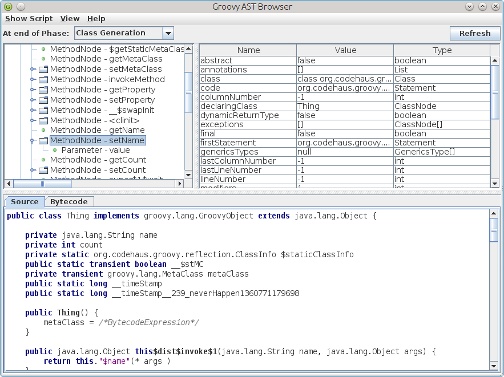
During compilation, Groovy represents your code in memory as an Abstract Syntax Tree (AST). The Groovy consoleâs AST browser is one way to see what is going on under the hood. There are several compilation phases (parsing, conversion, semantic analysis, and so on), and the AST browser will show you graphically what the structure looks like at each phase. This can help to diagnose issues, and is particularly helpful when you write your own AST transformations, where you can hook into the bytecode generation process and add your own programmatically. Figure 1-2 shows the state at the Class Generation phase.
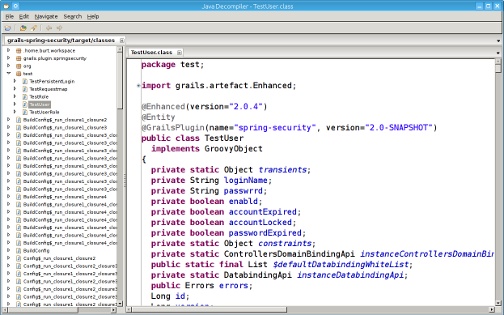
I highly recommend decompiling Groovy .class files to get a sense of what is added during the compilation process. Itâs one thing to believe that getters and setters are added for you, but itâs another to actually see them. And there can be a lot of generated code in some of your classes; for example (jumping ahead a bit here), Grails uses several AST transformations to add compile-time metaprogramming methods to controllers, domain classes, and other artifacts. JD-GUI is an excellent free decompiler that Iâve had a lot of success with. Figure 1-3 shows an example class.
Another option that doesnât require third-party software is javap, which is part of the JDK install. Running it with no switches will display the method signatures, e.g., javap target/classes/com.foo.Bar, and passing the -c switch will decompile the code into a readable form of the bytecode, not the Groovy or analogous Java source; e.g., javap -c target/classes/com.foo.Bar. The output isnât anywhere near as readable as what you get with a decompiler like JD-GUI, but it can be more convenient for a quick look.
Closures are an important aspect of Groovy. As a Grails developer youâll use them a lot; they define controller actions (although in 2.0, methods are supported and are preferred) and taglib tags and are used to implement the constraints and mapping blocks in domain classes, the init and destroy blocks in BootStrap.groovy, and in fact most of the blocks in the configuration classes in grails-app/conf. They also provide the functionality that makes builders and DSLs so powerful. But what are they?
A closure is a block of code enclosed in braces. Closures are similar to function pointers in C and C++ in that you can assign them to a variable and pass them as method parameters and invoke them inside the methods. Theyâre also similar to anonymous inner classes, although they donât implement an interface or (at least explicitly) extend a base class (but they can be used to implement interfacesâmore on that later).
A closure can be as simple as:
defhello={println"hello"}
A closure can be invoked by calling its call method:
defhello={println"hello"}hello.call()
but Groovy lets you use a more natural method call syntax (it invokes the call method for you):
defhello={println"hello"}hello()
Like methods, closures can have parameters, and there are three variants. In the hello example, because thereâs nothing declared, there is one parameter with the default name it. So a modified closure that prints what itâs sent would be:
defprintTheParam={printlnit}
and you could call it like this:
printTheParam('hello')
You can omit parentheses like you can with method calls:
printTheParam'hello'
Named arguments use -> to delimit the parameters from the code:
defprintTheParam={whatToPrint->printlnwhatToPrint}
and, like method arguments, they can be typed:
defadd={intx,inty->x+y}
If the closure has no arguments, use the -> delimiter and the it parameter will not be available:
defprintCurrentDate={->printlnnewDate()}
You can determine the number of parameters that a closure accepts with the getMaximumNumberOfParameters() method and get the parameter types (a Class[] array) with getParameterTypes().
A closure is a subclass of groovy.lang.Closure that is generated by the Groovy compiler; you can see this by running:
printlnhello.getClass().superclass.name
The class itself will have a name like ConsoleScript14$_run_closure1. Nested closures extend this naming convention; for example, if you look in the classes directory of a Grails application, youâll see names like BuildConfig$_run_closure1_closure2.class, which are the result of having repositories, dependencies, and plugins closures defined within the top-level grails.project.dependency.resolution closure.
The dollar sign in the class and filename will look familiar if youâve used anonymous inner classes before. In fact, thatâs how theyâre implemented. Theyâre different from anonymous inner classes in that they can access nonfinal variables outside of their scope. This is the âcloseâ part of closureâthey enclose their scope, making all of the variables in the scope the closure is in available inside the closure. This can be emulated by an inner class by using a final variable with mutable state, although itâs cumbersome. For example, this Java code doesnât compile, because i isnât final, and making it final defeats the purpose, because it needs to be changed inside the onClick method:
interfaceClickable{voidonClick()}inti=0;Clickablec=newClickable(){publicvoidonClick(){System.out.println("i: "+i);i++;}};
We can fix it with a final 1-element array (because the array values are still mutable):
finalint[]i={0};Clickablec=newClickable(){publicvoidonClick(){System.out.println("i: "+i[0]);i[0]++;}};
but itâs an unnatural coding approach. The Groovy equivalent with a closure is a lot cleaner:
inti=0defc={->println"i: $i"i++}asClickable
So how does Groovy break this JVM rule that anonymous inner classes canât access nonfinal variables? It doesnâtâit uses a trick like the one above. Instead of using arrays like the above example, thereâs a holder class, groovy.lang.Reference. Enclosed variable values are stored in final Reference instances, and Groovy transparently makes the values available for you. The only time youâll see this occurring is when youâre stepping through code in debug mode in an IDE.
The previous example demonstrates interface coercion; because the Clickable interface has only one method, the closure can implement that method if it has the same parameter type(s). The as keyword tells the Groovy compiler to create a JDK dynamic proxy implementing the interface. This is the simple version, but it also works for interfaces with multiple methods.
To implement an interface with more than one method, create a Map with method names as keys and closures with the corresponding parameter types as values:
importjava.sql.Connectiondefconn=[close:{->println"closed"},setAutoCommit:{booleanautoCommit->println"autocommit: $autoCommit"}]asConnection
One useful aspect of this approach is that you arenât required to implement every method. Calling close or setAutoCommit will invoke the associated closures as if they were methods, but calling an unimplemented method (e.g., createStatement()) will throw an UnsupportedOperationException. This technique was more common before anonymous inner class support was added to Groovy in version 1.7, but itâs still very useful for creating mock objects when testing. You can implement just the methods that will be called and configure them to work appropriately for the test environment (e.g., to avoid making a remote call or doing database access) and switch out the mock implementation in place of the real one.
Although itâs rare to do so, you can create a closure programmatically (most likely from Java). You might do this if you have some reason to implement some code in Java but need to pass a closure as a parameter to a Groovy method. The Closure class is abstract but doesnât have any abstract methods. Instead, you declare one or more doCall methods with the supported call signatures:
Closure<String>closure=newClosure<String>(this,this){publicStringdoCall(intx){returnString.valueOf(x);}publicStringdoCall(intx,inty){returnString.valueOf(x*y);}};
This can be invoked from Groovy just like one created the typical way:
closure(6)// prints "6"closure(6,2)// prints "12"closure(1,2,3)// throws a groovy.lang.MissingMethodException// since there's no 3-param doCall()
this inside a closure is probably not what you expect. Intuitively, it seems like it should be the closure itself, but it turns out that itâs actually the class instance where the closure is defined. As such, itâs probably not of much useâthe owner and delegate are much more useful.
The owner of a closure is the surrounding object that contains the closure. It functions as the target of method invocations inside the closure, and if the method isnât defined, then a MissingMethodException will be thrown. In this example, if we create a new class instance and call the callClosure method (new SomeClass().callClosure()), it will print Woof!, because the dogAndCat closure calls the existing woof method, but it will then fail on the meow call because it doesnât exist:
classSomeClass{voidcallClosure(){defdogAndCat={woof()meow()}dogAndCat()}voidwoof(){println"Woof!"}}
You can assign a delegate for a closure to handle method calls. By default, the delegate is the owner, but you can change it with the setDelegate method. This is frequently used when parsing DSLs. The DSL can be implemented as a closure, and inner method calls and property access can be routed to a helper (i.e., the DSL builder), which implements the logic required when a method or property is called thatâs not locally defined but is valid in the DSL.
One example is the mapping block in Grails domain classes. This is a static closure that, if defined, will be used to customize how the class and fields map to the database:
classUser{StringusernameStringpasswordstaticmapping={versionfalsetable'users'passwordcolumn:'passwd'}}
If you were to invoke the mapping closure (User.mapping()), you would get a MissingMethodException for each of the three lines in the closure, because the owner of the closure is the User class and thereâs no version, table, or password methods (and none added to the metaclass). Itâs more clear that these are method calls if we add in the optional parentheses that were omitted:
staticmapping={version(false)table('users')password(column:'passwd')}
Now we see that itâs expected that thereâs a version method that takes a boolean parameter, a table method that takes a String, and a password method that takes a Map. Grails sets the delegate of the closure to an instance of org.codehaus.groovy.grails.orm.hibernate.cfg.HibernateMappingBuilder, if youâre using Hibernate; otherwise, itâll be an analogous NoSQL implementation if youâre using a different persistence provider, and that does have a version and a table method as expected. Thereâs no password method though. But thereâs missing-method handling that looks for a field of the same name as the missing method, and when it finds a match and the parameter is a map, it uses the map data to configure the corresponding column.
So this lets us use an intuitive syntax composed of regular method calls that are handled by a delegate, usually doing a lot of work behind the scenes with a small amount of actual code.
One of Groovyâs most popular features is its reduced verbosity compared to Java. Itâs been said that Groovy is a âlow ceremonyâ language. If youâre new to Groovy, you may not yet appreciate how much less code it takes to get things done compared to Java, especially if you use your IDEâs code-generation functions. But, once you get used to Groovy, you might find that you donât even need to use an IDE anymore, except perhaps when you want to attach a debugger to work on a particularly gnarly bug.
Youâve already seen how property access and the compact syntax for collections and maps can help condense your code, but there are a lot more ways.
Itâs rare to see constructors in Groovy classes. This is because the Groovy compiler adds a constructor that takes a Map and sets field values to map values where the key corresponds to a field name. This gives you named parameters for this constructor syntax, so itâs both more convenient and clearer which values are which. For example, a simple POGO like this:
classPerson{StringfirstNameStringinitialStringlastNameIntegerage}
can be constructed by setting some or all of the field values:
defauthor=newPerson(firstName:'Hunter',initial:'s',lastName:'Thompson')defillustrator=newPerson(firstName:'Ralph',lastName:'Steadman',age:76)defsomeoneElse=newPerson()
In the examples, Iâm taking advantage of Groovy letting me omit the [ and ] map characters, because it makes the invocations cleaner.
This is especially useful for classes with many fields; in Java, you have to either define multiple constructors with various signatures or pass lots of nulls where you donât have a value.
However, note that the Map constructor relies on the default constructor thatâs added to all classes that donât define any explicit constructors. It calls that constructor, then sets properties from the provided Map (this is defined in MetaClassImpl.invokeConstructor(), if youâre curious). But if you declare one or more parameterized constructors, the compiler doesnât generate an empty one for you, and the Map constructor will fail.
Also, because itâs not a real constructor thatâs added to the bytecode, you can use this with Java classes that have a default constructor, too. So you could replace this code:
MutablePropertyValuespropertyValues=...defbeanDef=newGenericBeanDefinition()beanDef.setBeanClassName('com.foo.bar.ClassName')beanDef.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE)beanDef.setPropertyValues(propertyValues)
with this:
MutablePropertyValuespropertyValues=...defbeanDef=newGenericBeanDefinition(beanClassName:'com.foo.bar.ClassName',autowireMode:AbstractBeanDefinition.AUTOWIRE_BY_TYPE,propertyValues:propertyValues)
Groovy also relaxes the requirement to catch and declare checked exceptions. Checked exceptions are widely regarded as a failure in the Java language, and a lot of the time, there isnât much you can do once you catch one. So in Groovy, you donât have to wrap calls to methods that throw checked exceptions in try/catch blocks, and you donât have to declare checked exceptions in method signatures.
For example, consider java.sql.SQLException. A lot of the time, a SQLException will be caused by one of two things: temporary connectivity issues with the database and errors in your SQL. If you canât connect to the database, you probably just have to punt and show an error page, and bad SQL is usually a development-time problem that youâll fix. But youâre forced to wrap all JDBC code in try/catch blocks, thereby polluting your code.
You can still catch checked (and unchecked) exceptions in Groovy, and when you can handle an exception and retry or perform some action after catching it, you certainly should. Itâs a good idea to also declare thrown exceptions in your method signatures, both for use by Java and also as a self-documenting code technique.
In Java, only boolean variables and expressions (including unboxed Boolean variables) can evaluate to true or false, for example, with if checks or as the argument to assert. But Groovy extends this in convenient ways. null object references evaluate to false. Nonempty collections, arrays, and maps; iterators and enumerations with more elements; matching regex patterns; Strings and GStrings (and other implementations of CharSequence) with nonzero length; and nonzero numbers and Characters will all evaluate to true.
This is especially helpful with strings as well as with collections and maps. So, for example, you can replace:
defsomeCollection=someMethod(...)if(someCollection!=null&&!someCollection.isEmpty()){...}
with:
defsomeCollection=someMethod(...)if(someCollection){...}
and:
Strings=someMethod(...)if(s!=null&&s.length()>0){...}
with:
Strings=someMethod(...)if(s){...}
Semicolons are for the most part unnecessary in Groovy, the exception being the traditional for loop (although youâll most likely prefer the semicolon-free Groovy for/in version). Also, if you want to have multiple statements on one line, you still need to delimit them with semicolons.
You can omit the return keyword in a method or closure, because Groovy treats the last expression value as the return value if you donât use return.
Scope modifiers are often omitted in Groovy because the default scope is public. You can still define private or protected fields and methods. Because package scope is the default in Java and thereâs no keyword for that, Groovy added the groovy.transform.PackageScope annotation in version 1.8 for classes, methods, and fields.
You can often omit parentheses in method calls. This is only true if the method has arguments, because otherwise the call would look like property access. So, for example, all but the last of these are valid:
println("Using parentheses because I can")println"Omitting parentheses because I can"println()println// not valid; looks like property access// for a nonexistent getPrintln() method
You canât omit parentheses from the right side of an assignment, however:
intsum=MathUtils.add(2,2)// okintproduct=MathUtils.multiply2,2// invalid, doesn't compile
Another space saver is the extended list of default imports. Java automatically imports everything from the java.lang package, and Groovy extends this to include java.io.*, java.net.*, java.util.*, groovy.lang.*,
and groovy.util.*, as well as the java.math.BigDecimal and java.math.BigInteger classes.
In general, you can rename a .java source file to .groovy and it will still be valid, although there are a few exceptions.
Because Groovy uses braces to declare closures, you cannot initialize an array the standard Java way:
int[]oddUnderTen={1,3,5,7,9};
Instead, we create the array using List syntax and cast it to the correct array type:
int[]oddUnderTen=[1,3,5,7,9]
or:
defoddUnderTen=[1,3,5,7,9]asint[]
One other gotcha is that in is a keyword, used by the Groovy for loop, (e.g., for (bar in bars) { ... }); def is also a keyword. So Java code that uses either of these as a variable name will need to be updated.
There is also no do/while loop in Groovy, so any code like this will need to be reworked:
do{// stuff}while(<truthexpression>);
Another small difference is that you canât initialize more than one variable in the first part of a for loop, so this is invalid:
for(intcount=someCalculation(),i=0;i<count;i++){...}
and youâll need to initialize the count variable outside the loop (a rare case where Groovy is more verbose than Java!):
intcount=someCalculation()for(inti=0;i<count;i++){...}
or you could just skip the whole for loop and use times:
someCalculation().times{...}
or a range with a loop, if you need access to the loop variable:
for(iin0..someCalculation()-1){...}
Annotation values that have array types use a different syntax in Groovy than Java. In Java, you use { and } to define multivalued attributes:
@Secured({'ROLE_ADMIN','ROLE_FINANCE_ADMIN','ROLE_SUPERADMIN'})
but because these are used to define closures in Groovy, you must use [ and ] instead:
@Secured(['ROLE_ADMIN','ROLE_FINANCE_ADMIN','ROLE_SUPERADMIN'])
The previous examples will cause compilation errors if you rename a .java class to .groovy and try to compile it, or copy/paste Java code into an existing Groovy class. But checking for object equality actually works differently in Groovy.
In Java, == is mostly used for comparing numbers and other primitives, because comparing objects with == just compares object references but not the data in the instances. We use the equals method to test if two objects are equivalent and can be considered equal even though theyâre not the same instances. But itâs rare to need the == object comparison, so Groovy overloads it to call equals (or compareTo, if the objects implement Comparable). And, if you do need to check that two references are the same object, use the is methodâe.g., foo.is(bar).
Groovyâs == overload is convenient and avoids having to check for null values, but because it works differently than the Java operator, you might want to consider not using it. Itâs simple enough to replace x == y with x?.equals(y), which isnât that many more characters and is still null-safe. Working with both Java and Groovy will keep you from introducing subtle bugs in your Java code. (Iâm speaking from experience hereâ¦.)
Overloaded method selection is another runtime difference between Java and Groovy. Javaâs type checking is stricter, so it uses the compilation type of a variable to choose which method to call, whereas Groovy uses the runtime type, because itâs dynamically checking all method invocations for metamethods, invokeMethod interception, etc.
So, for example, consider a few versions of a close utility method:
voidclose(Closeablec){try{c.close()}catch(e){println"Error closing Closeable"}}voidclose(Connectionc){try{c.close()}catch(e){println"Error closing Connection"}}voidclose(Objecto){try{o.close()}catch(e){println"Error closing Object"}}
In Java, this code will invoke the close(Object) variant, because the compiler only knows the compile-time type of the connection variable:
Objectconnection=createConnection();// a method that returns a Connection// work with the connectionclose(connection);
But, if this were Groovy, the close(Connection) method would be chosen, because itâs resolved at runtime and is based not on the compile type but the actual runtime type of the connection. This is arguably a better approach, but because itâs different from the Java behavior, itâs something that you should be aware of.
There are multiple ways to express string literals in Groovy. The approach used in Javaâdouble-quoted stringsâis supported of course, but Groovy also lets you use single quotes if you prefer. Multiline strings (sometimes called heredocs in other languages) are also supported, using triple quotes (either single or double). GStrings make things a lot more interesting, though.
The biggest benefit of GStrings is avoiding the clumsy string concatenation thatâs required in Java:
StringfullName=person.getFirstName()+" ";if(person.getInitial()!=null){fullName+=person.getInitial()+" ";}fullName+=person.getLastName();
Using a StringBuilder (the preferred approach when concatenating in a loop) wouldnât be much better in this case. But using a GString (along with property syntax), we can join the data in a single line of code:
deffullName="$person.firstName ${person.initial ? person.initial + ' ': ''}$person.lastName"
GStrings also work with multiline strings as long as you use three double quotes; this is convenient for tasks such as filling in templates for emails:
deftemplate="""\Dear $name,Thanks for signing up for the Ralph's Bait and Tackle online store!We appreciate your business and look forward to blah blah blah â¦Ralph"""
Here, Iâm using the backslash character at the beginning of the string to avoid having an initial blank line. You can use three single quotes to create multiline strings, but they behave like regular strings that use single quotes, in that they do not support expression replacement.
Using the subscript operator lets you conveniently access substrings:
Stringstr='GroovyStringsaregroovy'assertstr[4]=='v'// a String of length 1, not a charassertstr[0..5]=='Groovy'// the first 6 charsassertstr[19..-1]=='groovy'// the last 6 charsassertstr[15..17]=='are'// a substring in the middleassertstr[17..15]=='era'// a substring in the middle, reversed
Unlike Java where the this keyword only makes sense in instance scope, this resolves to the class in static scope. One use of this feature is when defining static loggers. In Log4j and SLF4J, you can define a logger with a class or the class name (or any string you like), but in Java, thereâs no way (no convenient one anyway) to get the class name in static scope. This can lead to copy/paste problems. For example:
privatestaticfinalLoggerLOG=Logger.getLogger(Foo.class);
has the class hardcoded, so if you forget to change it and copy that to a different class, youâll be logging as the wrong category. Instead, in Groovy, you can use:
privatestaticfinalLoggerLOG=Logger.getLogger(this)
which is more portable (and similar to the analogous instance version private final Logger log = Logger.getLogger(getClass())).
The Groovy JDK (GDK) is a Javadoc-style set of pages that describe methods added to the metaclass of JDK classes to extend them with extra functionality and make them easier to work with. There are currently over 1,000 methods listed. I strongly encourage you to check out the information there and familiarize yourself with whatâs available. You may find that youâve coded something that was already available and, in general, will probably realize that youâre working harder than you need to by not taking advantage of these built-in methods and features.
Many of the methods added to JDK metaclasses are implemented in the org.codehaus.groovy.runtime.DefaultGroovyMethods class. At its largest, this was a gigantic class (over 18,000 lines) with around 1,000 methods. In recent versions of Groovy, this large class is being refactored into several more focused classes, including ResourceGroovyMethods, IOGroovyMethods, StringGroovyMethods, and others. Many of the convenience methods that you use on a regular basis are implemented here, for example, the sort method thatâs added to the Collection interface (it sorts lists and creates sorted lists from nonlist collections) is implemented by the public static <T> List<T> sort(Collection<T> self) method. Itâs interesting to browse this class to see how things work under the covers, and you can use these methods yourself (although this is an internal class, so there may be some risk using it directly, because itâs not a public API class).
org.codehaus.groovy.runtime.InvokerHelper is another utility class with a lot of interesting functionality that you should check out.
Groovyâs Meta Object Protocol (MOP) is the key to Groovyâs power and itâs what enables most of its coolest features. Every class gets a metaclass, which intercepts all method calls and enables customization of how methods are invoked, and also enables adding or removing methods. This is what makes Groovy a dynamic language; unlike Java, which compiles methods into class bytecode and doesnât allow changes at runtime. Because Groovyâs MOP is intercepting all method calls, it can simulate adding a method as if it had been compiled in at startup. This makes JVM classes open classes that can be modified at any time.
And thatâs just runtime metaprogramming; with compile-time metaprogramming using Abstract Syntax Tree (AST) transformations, you can also add actual methods to the class bytecode that are visible from Java.
Every Groovy class implements the groovy.lang.GroovyObject interface (itâs added by the compiler) that includes these methods:
ObjectinvokeMethod(Stringname,Objectargs)ObjectgetProperty(Stringproperty)voidsetProperty(Stringproperty,ObjectnewValue)MetaClassgetMetaClass()voidsetMetaClass(MetaClassmetaClass)
Note
Java classes can also implement GroovyObject to add Groovy-like behavior. The most convenient approach for this is to subclass the groovy.lang.GroovyObjectSupport adapter class, which implements the interface and provides sensible default implementations of the methods that can be overridden as needed.
When you invoke a method in Groovy (including accessing a property, because that calls the corresponding getter method), itâs actually dispatched to the objectâs metaclass. This provides an AOP-like interception layer. The calls are implemented with reflection, which is slower than direct method invocation. But each new release of Java adds reflection speed improvements, and Groovy has several optimizations to reduce the cost of this overhead, the most significant being call site caching. Early versions of Groovy were quite slow, but modern Groovy has seen huge performance boosts and is often nearly as fast as Java. And because network latency and database access tend to contribute most to total web request time, the small increase in invocation time that Groovy can add tends to be insignificant, because itâs such a small percentage of the total time.
The syntax for adding a method at runtime is essentially just one that registers a closure in the metaclass thatâs associated with the specified method name and signature:
List.metaClass.removeRight={intindex->delegate.remove(delegate.size()-1-index)}
The List interface has a remove method, but this addition removes the item considering the position from the right instead of the left like remove:
assert3==[1,2,3].removeRight(0)assert2==[1,2,3].removeRight(1)assert1==[1,2,3].removeRight(2)
Recall that closures have a delegate that handles method calls invoked inside the closure. When adding methods to the metaclass, you can access the instance in which closure is invoked with the delegate property; in this example, itâs the list instance that removeRight is called on.
Because all Groovy objects implement GroovyObject, you can override the invokeMethod method in your class to handle method invocations. There are a few variants of behavior though. By default, itâs only called for methods that donât exist (analogous to methodMissing, which weâll see in a bit), so for example:
classMathUtils{intadd(inti,intj){i+j}definvokeMethod(Stringname,args){println"You called $name with args $args"}}defmu=newMathUtils()printlnmu.add(2,3)printlnmu.multiply(2,3)
will generate this output:
5Youcalledmultiplywithargs[2,3]
because there is an add method but no multiply. If we change the class to implement the GroovyInterceptable marker interface (which extends GroovyObject):
classMathUtilsimplementsGroovyInterceptable{...}
then the result is a java.lang.StackOverflowError. Hmmm. Whatâs up there? We tend to think of println as just an alias for System.out.println, but itâs actually a metamethod added to the Object class that calls System.out.println, so it will be intercepted along with the calls to add and multiply. So the fix is to use System.out.println directly:
classMathUtilsimplementsGroovyInterceptable{intadd(inti,intj){i+j}definvokeMethod(Stringname,args){System.out.println"You called $name with args $args"}}defmu=newMathUtils()printlnmu.add(2,3)printlnmu.multiply(2,3)
and then weâll see this output:
Youcalledaddwithargs[2,3]nullYoucalledmultiplywithargs[2,3]null
Overriding getProperty and/or setProperty always intercepts the property gets and sets, so the output of:
classPerson{privateStringnamedefgetProperty(StringpropName){println"getProperty $propName"if('name'.equals(propName)){returnthis.name}}voidsetProperty(StringpropName,value){println"setProperty $propName -> $value"if('name'.equals(propName)){this.name=value}}}defp=newPerson(name:'me')printlnp.name
will be:
getPropertynameme
You might have expected to see output indicating that setProperty was called, since the map constructor is used and it sets property values from the map, in this case the name property to 'me'. But the implementation of this feature bypasses setProperty (this seems like a bug). But if you explicitly set the property:
p.name='you'
it works as expected:
setPropertyname->you
GroovyObject doesnât have methodMissing or propertyMissing methods, but if you implement one or both of them, theyâll be called for undefined method calls and property accesses. The signatures are similar to invokeMethod and getProperty:
classPerson{StringnamedefpropertyMissing(StringpropName){if('eman'.equals(propName)){returnname.reverse()}thrownewMissingPropertyException(propName,getClass())}defmethodMissing(StringmethodName,args){if('knight'.equals(methodName)){name='Sir'+namereturn}thrownewMissingMethodException(methodName,getClass(),args)}}defp=newPerson(name:'Ralph')printlnp.nameprintlnp.emanp.knight()printlnp.name
which results in the output:
RalphhplaRSirRalph
and, if you try to access a property or method that doesnât exist or have special handling (e.g., println p.firstName or p.king()), then youâll get the standard MissingPropertyException or MissingMethodException.
There are also static versions of methodMissing and propertyMissing, $static_methodMissing and $static_propertyMissing.
classPerson{Stringnamestatic$static_propertyMissing(StringpropName){println"static_propertyMissing $propName"}static$static_methodMissing(StringmethodName,args){println"static_methodMissing $methodName"}}printlnPerson.foo()printlnPerson.bar
The output from the above code is:
static_propertyMissingfoostatic_methodMissingfoonullstatic_propertyMissingbarnull
$static_methodMissing works slightly differently from methodMissing in that if thereâs no method with the specified name, it looks for a closure property with that name to invoke as if it were a method. This results in a message about a missing foo property and a missing foo method.
Groovy adds several operators to the standard set of Java operators.
The most commonly used is the null-safe dereference operator, ?., which lets you avoid a NullPointerException when calling a method or accessing a property on a null object. Itâs especially useful in a chain of such accesses where a null value could occur at some point in the chain.
For example, you can safely call:
Stringname=person?.organization?.parent?.name
and if person, person.organization, or organization.parent are null, then null is returned as the expression value. The Java alternative is a lot more verbose:
Stringname=null;if(person!=null){if(person.getOrganization()!=null){if(person.getOrganization().getParent()!=null){name=person.getOrganization().getParent().getName();}}}
The Elvis operator, ?:, lets you condense ternary expressions; these two are equivalent:
Stringname=person.name?:defaultName
and:
Stringname=person.name?person.name:defaultName
They both assign the value of person.name to the name variable if it is âGroovy trueâ (in this case, not null and has nonzero length, because itâs a string), but using the Elvis operator is more DRY.
The spread operator, *., is convenient when accessing a property or calling a method on a collection of items and collecting the results. Itâs essentially a shortcut for the collect GDK method, although itâs limited to accessing one property or calling one method, for example:
defnumbers=[1.41421356,2.71828183,3.14159265]assert[1,2,3]==numbers*.intValue()
The spaceship operator <=> is useful when comparing values; for example, when implementing the compareTo method of the Comparable interface. For example, given a POGO where you want to sort by two properties, the spaceship operator makes the implementation very compact:
classPersonimplementsComparable<Person>{StringfirstNameStringlastNameintcompareTo(Personp){lastName<=>p?.lastName?:firstName<=>p?.firstName}StringtoString(){"$firstName $lastName"}}defzakJones=newPerson(firstName:'Zak',lastName:'Jones')defjedSmith=newPerson(firstName:'Jed',lastName:'Smith')defalJones=newPerson(firstName:'Al',lastName:'Jones')defpersons=[zakJones,jedSmith,alJones]assert[alJones,zakJones,jedSmith]==persons.sort(false)
because the operator returns â1 if the left is less than the right, 0 if theyâre equal, and 1 if the right is more than the left. So when the first expression (lastName <=> p?.lastName) is nonzero, its value is used as the return value and the sort is done by lastName. If the last names match, then the Elvis operator kicks in and the second expression (firstName <=> p?.firstName) is used to do a secondary sort by firstName.
You can also use the operator for one-off sorting regardless of whether the items are Comparable, for example:
assert[alJones,jedSmith,zakJones]==persons.sort(false,{a,b->a?.firstName<=>b?.firstName})
which sorts just by firstName. Of course Groovy being Groovy, thereâs a shorter way of doing that:
assert[alJones,jedSmith,zakJones]==persons.sort(false,{it.firstName})
If you have a need to bypass a getter method (or if there is none) and directly access a field, you can use the .@ operator. For example, this class uses some simple logic to return a default value if none is specified, but if you want to know if the value is unspecified, you still can:
classThing{privatestaticfinalStringDEF_NAME='foo'StringnameStringgetName(){name==null?DEF_NAME:name}}assert'bar'==newThing(name:'bar').nameassert'foo'==newThing().nameassertnull==newThing().@name
Note, however, that this operator only works on the current class; if the field is in a subclass, the operator cannot access it, and you have to use standard reflection.
The as operator is very useful, because it can perform many type coercions. For example, thereâs no native syntax for a Set like there is for a List, but you can use as with List syntax to create a Set:
defthings=['a','b','b','c']asSetassertthings.getClass().simpleName=='HashSet'assertthings.size()==3
The in operator is a convenient shortcut for the contains method in a collection:
assert1in[1,2,5]assert!(3in[1,2,5])
The .& operator lets you get a reference to a method and treat it like a closure. This might be useful if youâre working with higher order methods where you pass a closure as a parameter and want the option to pass a method; the .& operator creates an instance of org.codehaus.groovy.runtime.MethodClosure that invokes your method when itâs invoked.
classMathUtils{defadd(x,y){x+y}}defdoMath(x,y,Closurec){c(x,y)}defadd=newMathUtils().&adddefmultiply={x,y->x*y}assert8==doMath(4,2,multiply)assert6==doMath(4,2,add)assert2==doMath(4,2,{x,y->x/y})
Operator overloading is a powerful technique for compressing code, ideally in an intuitive way. Itâs important that if you add an operator overload that it make senseâbe sure to think about how cryptic the code can get if you add an operator overload that isnât an appropriate choice.
The general approach for creating an operator overload is to implement the method that corresponds to the operator. The method must return this (or another instance) to work correctly. So, for example, if we have a Person class that has a collection of children:
classPerson{StringnameListchildren=[]}
Adding a child to a Person instance is simple enough:
defparent=newPerson(...)defchild=newPerson(...)parent.children.addchild// or parent.children << child
But we can use the left-shift operator here to add a child:
classPerson{StringnameListchildren=[]defleftShift(Personchild){children<<childthis}}
and then the code becomes simply:
defparent=newPerson(...)defchild=newPerson(...)parent<<child
The plus method would be another possibility (or you might implement both).
classPerson{StringnameListchildren=[]defplus(Personchild){children<<childthis}}
and then you would use it like this:
defparent=newPerson(...)defchild=newPerson(...)parent+=child
because parent += child is the equivalent of parent = parent + child. Note that internally weâre still using << to add the child to the children list instead of switching to +=, because += creates a new List and copies the old list into it and then adds the new one. This is a lot more expensive than just adding to the current instance and should be avoided in general unless you have a reason to create a new list instance.
Table 1-1 shows the available overloadable operators and their corresponding implementation methods.
Table 1-1. Overloadable operators
| Operator | Implementation method |
|---|---|
a + b |
|
a - b |
|
a * b |
|
a ** b |
|
a / b |
|
a % b |
|
a | b |
|
a & b |
|
a ^ b |
|
a++ or ++a |
|
a-- or --a |
|
a[b] |
|
a[b] = c |
|
a << b |
|
a >> b |
|
switch(a) { case(b) : } |
|
~a |
|
-a |
|
+a |
|
Thereâs a natural tendency to embrace Groovy fully once it becomes apparent how much it has to offer over Java. Writing highly idiomatic Groovy code can lead to the code being hard to understand, though. Iâve written cryptic code with no comments that Iâve looked at months later and had to relearn how it works as if someone else had written it, because it was old enough that I didnât remember working on it, and I had sabotaged myself by writing the code in a way that made sense at the time but not when I came back to it.
The phrase I use for this is âbe lazy but not sloppy.â By this, I mean save yourself time (and typing) and take advantage of Groovyâs cool featuresâbut donât overdo it and make your code hard to work with and understand.
One example of being âtoo groovyâ is overusing the def keyword. Optional typing is very convenient, but specifying the type can help other readers of your code (and even yourself). Naming variables and methods well makes code more self-documenting, and the same goes for whether to type variables. For example, consider this relatively information-free line of code:
deffoo=bar(5,true)
Itâs not at all clear what foo is or what you can do with it. If itâs a string, call it a String (or whatever the type is).
I usually donât type both sides of an assignment, so because itâs clear that strings is a List from the right side of the assignment, Iâm okay with:
defstrings=[]
but when the right side is a method invocation, Iâll type the left:
List<String>strings=someMethod('Hello','Groovy','World')
and I often add the generic type even though Groovy ignores itâagain as a self-documentation practice and not because it has any other runtime effect. The same goes for the return type and parameter type(s) of methods; if itâs void, I specify void someMethod(...) instead of def someMethod(...), so the caller knows that thereâs nothing being returned.
each is a convenient way of looping, but I rarely use it, because it has almost no benefit over the for/in loop. For example, I would use:
for(stringinstrings){...}
instead of:
strings.each{string->...}
because theyâre equivalent, basically the same number of characters, and both are null-safe. And the for loop has the benefit that you can break out of it if thereâs a reason to stop looping, whereas each cannot, because returning from the closure that you pass to the each method returns from the closure, not each.
Of course, these are arguments about preferencesâthereâs no right or wrong here. And I will certainly drop the type of a method parameter if it makes testing easier by letting me substitute a more convenient value that uses duck typing.
Another example of being âtoo groovyâ is using a closure as a method where you donât use any features of the closure. If you donât set the delegate or use any other closure-specific feature, then thereâs no reason to use:
deffoo={<params>->...}
instead of:
<returntype>foo(<params>){...}
and, in fact, using the method has the not-insignificant benefit of letting you specify the return type. Plus, things like AOP and method proxying that arenât Groovy-aware wonât work at all with closures, because theyâre only treated like methods by Groovyâtheyâre just public fields and are ignored by Java.
One real example of this is Grails services. Unlike controllers and taglibs, services are implemented with methods. A transactional service is implemented by Spring as a proxy that subclasses your service class and intercepts all method calls to start or join a transaction as needed and manage error handling, automatic rollbacks, and so on. If you have a public closure in a service, it will be callable from Groovy just like a method, but it will not be transactional. The proxy only works with methods and completely ignores the closures, so you will introduce bugs that can be hard to track down by using closures here.
Groovy 2.0 and 2.1 add new features that make your code faster and provide more compiler checks. Groovy is a dynamic language and, as weâve seen, this adds a tremendous amount of power and flexibility. But there are costs to this flexibility. One is that itâs easier to introduce typos and mistakes into Groovy code than Java, because the compiler is more forgiving. For example, a one-character mistake such as:
inthc=someObject.hashcode()
will compile but fail with a groovy.lang.MissingMethodException at runtime (unless there is actually a hashcode method in the class). The compiler doesnât catch the mistake, because the code satisfies the Groovy grammar, but the compiler cannot know whether a hashcode method will be added to the metaclass before its first use in application code. And it canât assume that you meant to call the hashCode method.
Good testing should find errors like this, but Groovy now provides an option to make the compiler more aggressive: the @TypeChecked annotation. This can be applied at the class level or on individual methods, and the code within the scope of the annotation will be compiled more like Java than Groovy. You lose flexibility with this annotation but add earlier error checking.
@CompileStatic is the other new interesting annotation in 2.0. This adds the same checks as the @TypeChecked annotation and also compiles your Groovy code to nearly the same bytecode as that from the equivalent Java code. This means that you lose Groovyâs metaprogramming support and some other dynamic features (although you retain many of the syntactic sugar features such as list and map comprehensions) but will see Java-like performance for the annotated code. Code that you would previously write in Java for maximum performance can now be written in Groovy.
Groovy 2.0 and 2.1 also have support for the new invokedynamic bytecode instruction that was added to support dynamic languages like Groovy and improve performance automatically. This differs from using @CompileStatic in that you donât make any changes to your code. Instead, you use a different compiler and runtime JAR. The âindyâ version of Groovy takes advantage of the existence of the invokedynamic instruction in JDK 7 and later (with performance being much better in JDK 8).
See the Groovy 2.0 release notes and Groovy 2.1 release notes for more information about these and other new features.
Get Programming Grails now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

