One of the most interesting potential uses for S3 is as an unlimited data store on top of which other filesystem interface abstractions can be built. Appendix A lists a number of products or services that use S3 as an underlying storage repository but expose it via different file or storage management protocols.
Some of these tools are designed to make S3 storage resources accessible to existing network-based tools that do not recognize S3âfor example, as a File Transfer Protocol (FTP) or a Web-based Distributed Authoring and Versioning (WebDAV) serviceâand others aim to make the storage space in S3 available as a lower-level filesystem resource. Both of these approaches provide benefits, but it is the S3-based filesystem approach that we will concentrate on in this section, because it presents the most interesting possibilities. It also presents the most difficult challenges.
If it proves to be feasible to build whole filesystems on top of S3, many of the serviceâs limitations could be overcome in a very elegant way. Rather than having to use specialized S3 tools to access your storage space, you can make the service look and behave like a standard disk drive that stores data reliably in the cloud behind the scenes. On your computer you could copy files to and from this disk, even rename and rearrange them. In the background the changes you make would automatically be translated into API requests and stored in S3. This approach also makes it possible to use advanced disk management protocols, like RAID mirroring, to automatically manage synchronization between a local file system and S3, effectively giving you an effortless, online backup of all your files.
Great promise and potential, sadly, does not always lead to practical outcomes. There are a number of difficult issues that S3-backed filesystems must overcome to be considered reliable, economical, and agile enough to be used in real-world applications. There is some debate among S3 domain experts in the AWS forums as to whether it will ever be possible to achieve these three vital characteristics when using S3. This debate is highly technical and well beyond the scope of this book, so we will merely describe the main difficulties such filesystems face and leave it to you, the reader, to investigate further and make your own judgment about whether the filesystems approach is suitable for your purposes. After imparting these words of warning, we will proceed with an example that shows how to set up an S3-based filesystem to whet your appetite.
There are three main criteria an S3-backed filesystem must meet to be practical:
- Reliability
You must be able to rely on a data storage system to keep your information safe in a range of circumstances, especially when things go wrong. The difficulty for filesystems based on S3 is that there are two circumstances in which latency can cause the S3 version of your data and the local version to fall out of synch, at which point a local system failure will cause you to lose any data that has not been replicated in S3. In the worst case scenario, an entire S3-backed filesystem could be corrupted if the data in S3 is not up-to-date.
The first latency problem is the time it takes for data to be copied over the network between your computer and the S3. Network resources are generally much more constrained than filesystem resources, so there will always be a delay before local changes can be reflected in S3. The second latency problem is caused by S3 itself, which does not provide a guarantee that you will always be able to retrieve the latest version of your data (see the discussion in S3 Architectureâ in Chapter 3).
- Economy
S3 account holders are charged by Amazon based on the amount of data they transfer to and from S3, and the number of requests that are performed. If an S3-backed filesystem cannot adequately translate filesystem changes to efficient S3 operations, the potential exists for a great deal of data to be transferred back and forth and for a large number of requests to be performed in doing this. Such inefficiencies could cause the S3 usage costs to quickly add up and make an S3-backed filesystem prohibitively expensive.
This issue is less serious when the S3-backed filesystem exists on an Amazon Elastic Compute Cloud (EC2) instance, because data transfer between EC2 and S3 buckets located in the United States is free; however, the per-request charges can still add up, even when you are not being charged for bandwidth.
- Performance
A filesystem that stores data using network-based services is inevitably slower than a physical disk drive attached to a computer. S3-backed filesystems can minimize or even eliminate delays caused by S3 network transmissions by caching the filesystem locally and using intelligent algorithms to ensure that the least amount of data is sent over the network as possible. However, the more data that is cached, the greater the risk that the local filesystem and the version stored in S3 will fall out of synch, and the greater the risk that a local system crash could cause data loss.
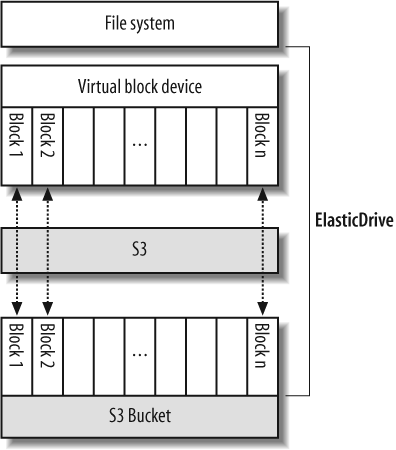
ElasticDrive (http://www.elasticdrive.com/) is a proprietary tool to make S3 available as a low-level filesystem resource via Filesystem in Userspace (FUSE). ElasticDrive presents a virtual block device on your computer that looks like any other data-storage block device, and you can build any filesystem you like on the device, including RAID systems. Behind the scenes, the blocks that comprise the virtual block device are cached and automatically synchronized with S3 as shown by Figure 4-1. The intended result is that your local filesystem is seamlessly backed up to S3.
A free trial version of ElasticDrive is available. This version imposes a maximum size limit for your virtual block device, however, it should still be sufficient to evaluate the product. As we noted previously, there are still some open questions about how reliable and effective S3-backed filesystems are in general, so bear this in mind when you are evaluating this tool and be sure to test it thoroughly with test data. Our guide is based on ElasticDrive version 0.4.0.
ElasticDrive has the following requirements:
The FUSE kernel module is available.
The FUSE utility programs are available.
FUSE and Python development libraries are installed.
In this application, we will step through the installation and configuration process for ElasticDrive on Fedora version 4 (this is the version available in EC2 as Amazonâs âGetting Startedâ public AMI). The process will be similar on other distributions, though the exact commands and application paths may differ.
Note
EC2 is the best environment in which to test this approach due to the lower S3 usage cost for bandwidth and the greater S3 access speed available. Refer to later chapters for information on deploying applications on EC2 servers.
Install the FUSE and development libraries the tool requires.
Note
We will assume that you have logged in to the computer as the root (administrative) user when you perform the commands listed in this section.
$ yum install fuse fuse-devel python-devel
Obtain a free evaluation version of the ElasticDrive application and the related documentation from the vendorâs web site. Extract the distribution tar file.
$ tar xvzf elasticdrive-0.4.0_dist.tar.gz
Run the ElasticDrive installation script in the distribution directory.
$ cd elasticdrive-0.4.0_dist $./install
Follow the configuration instructions included with the
program to configure ElasticDrive by editing the /etc/elasticdrive.ini file. You must
update the S3 fuseblock variable
to contain your S3 account credentials, the name of the bucket to
use for storage, and the size of the virtual block device you wish
to create. Here are the configuration settings we applied in
elasticdrive.ini to create a
50MB virtual block device linked to the S3 bucket elasticdrive-test.
[global] configured=1 fusermount="/usr/bin/fusermount" pidfile="/var/run/elasticdrive.pid" [logging] filename='/var/log/elasticdrive.log' level=logging.DEBUG [servers] modules="" [engines] modules="" [drives] # fuseblock|/path/to/fuse/fuse="file:///tmp/foo.img?size=2000000000" fuseblock|/home/jmurty/fuse="s3://S3ACCESSKEY:S3SECRETKEY@aws.amazon.com/ ?bucket=elasticdrive-test&stripesize=65536&maxthreads=5&ttl=40&size=52428800"
Note
In the printout above, the last two lines in the elasticdrive.ini configuration file are broken over two lines. In the real file the setting must be on a single line.
Create the mount folder you specified in the fuseblock path.
$ mkdir -p /home/jmurty/fuse
With ElasticDrive now configured, it is time to fire it up and try it out. Run the application as a daemon, and confirm that it started correctly by looking at the log file /var/log/elasticdrive.log.
$ elasticdrive.py /etc/elasticdrive.ini $tail /var/log/elasticdrive.log
Once you have confirmed that ElasticDrive runs without any errors, you can set up the virtual block device it provides to work as a standard filesystem. In this example we will create a filesystem on the block device, format it as the commonly used Linux filesystem called ext3, and mount it as a loop-back device.
Format the ed0 directory exposed within the fuse path as an ext3 filesystem.
# Create an ext3 filesystem on the device $ /sbin/mke2fs -b 4096 /home/jmurty/fuse/ed0
Once you have formatted the virtual block device, you should be able to see a list of block stripe files stored in the S3 bucket that ElasticDrive is using. As you write data to the device, the blocks will be synchronized with S3 as stripe objects.
Now we will mount the new filesystem and write some data to it.
# Mount the new filesystem as a standard drive $ mkdir /mnt/elastic $ mount /home/jmurty/fuse/ed0 /mnt/elastic -o loop # Create some files on the virtual drive $echo "Hello filesystem" > /mnt/elastic/hello.txt
The virtual drive you have just created should work just as you would expect a standard disk drive to work. In the background the ElasticDrive application will cache the filesystem changes you make and store them in S3 at intervals. If you have debugging turned on, you can watch this process occurring in the ElasticDrive log file. The best way to see some log activity is to copy a few hundred kilobytes of data to the drive and then unmount it to force ElasticDrive to write the data to S3.
Get Programming Amazon Web Services now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

