By the late 1990s, Amazon had proven its success—it showed that people were willing to shop online. Amazon generated $15.7 million in sales in 1996, its first full fiscal year. Just three years later, Amazon saw $1.6 billion in sales, and Jeff Bezos was chosen Person of the Year by Time magazine. Realizing its sales volume was only 0.5% that of Wal-Mart, Amazon set some new business goals. One of these goals was to change from shop to platform.
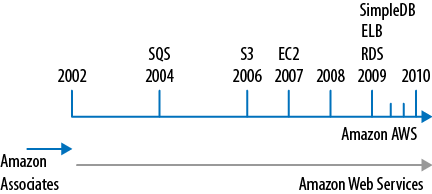
At this time, Amazon was struggling with its infrastructure. It was a classic monolithic system, which was very difficult to scale, and Amazon wanted to open it up to third-party developers. In 2002, Amazon created the initial AWS, an interface to programmatically access Amazon’s features. This first set of APIs is described in the wonderful book Amazon Hacks by Paul Bausch (O’Reilly), which still sits prominently on one of our shelves.
But the main problem persisted—the size of the Amazon website was just too big for conventional (web) application development techniques. Somehow, Jeff Bezos found Werner Vogels (now CTO of Amazon) and lured him to Amazon in 2004 to help fix these problems. And this is when it started for the rest of us. The problem of size was addressed, and slowly AWS transformed from “shop API” to an “infrastructure cloud.” To illustrate exactly what AWS can do for you, we want to take you through the last six years of AWS evolution (see Figure 1-1 for a timeline). This is not just a historical journey, but also a friendly way to introduce the most important components for starting with AWS.
It doesn’t cost much to get started. For example, you don’t have to buy a server to run it.
It scales and continues to run at a low cost. For example, you can scale elastically, only paying for what you need.
The second quality is by design, since dealing with scale was the initial problem AWS was designed to address. The first quality is somewhat of a bonus, but Amazon has really used this quality to its (and our) advantage. No service in AWS is useless, so let’s go through them in the order they were introduced, and try to understand what problems they were designed to solve.
If your system gets too big, the easiest (and perhaps only) solution is to break it up into smaller pieces that have as few dependencies on each other as possible. This is often referred to as decoupling. The first big systems that applied this technique were not web applications; they were applications for big corporations like airlines and banks. These applications were built using tools such as CORBA and the concept of “component-based software engineering.” Similar design principles were used to coin the more recent term service-oriented architecture or SOA which is mostly applied to web applications and their interactions.
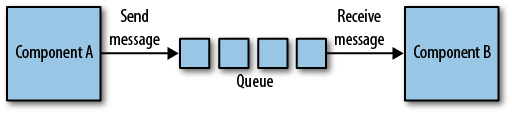
Amazon adopted one of the elements of these broker systems, namely message passing. If you break up a big system into smaller components, they probably still need to exchange some information. They can pass messages to each other, and the order in which these messages are passed is often important. The simplest way of organizing a message passing system, respecting order, is a queue (Figure 1-2). And that is exactly what Amazon built first in 2004: Amazon Simple Queue Service or SQS.
By using SQS, according to AWS, “developers can simply move data between distributed components of their applications that perform different tasks, without losing messages or requiring each component to be always available.” This is exactly what Amazon needed to start deconstructing its own monolithic application. One interesting feature of SQS is that you can rely on the queue as a buffer between your components, implementing elasticity. In many cases, your web shop will have huge peaks, generating 80% of the orders in 20% of the time. You can have a component that processes these orders, and a queue containing them. Your web application puts orders in the queue, and then your processing component can work on the orders the entire day without overloading your web application.
In every application, storage is an issue. There is a very famous quote attributed to Bill Gates that 640 K “ought to be enough for anybody.” Of course, he denies having said this, but it does hit a nerve. We all buy hard disks believing they will be more than enough for our requirements, but within two years we already need more. It seems there is always something to store and there is never enough space to store it. What we need is infinite storage.
To fix this problem once and for all, Amazon introduced Amazon Simple Storage Service or S3. It was released in 2006, two years after Amazon announced SQS. The time Amazon took to release it shows that storage is not an easy problem to solve. S3 allows you to store objects of up to 5 terabytes, and the number of objects you can store is unlimited. An average DivX is somewhere between 600 and 700 megabytes. Building a video rental service on top of S3 is not such a bad idea, as Netflix realized.
According to AWS, S3 is “designed to provide 99.999999999% durability and 99.99% availability of objects over a given year.” This is a bit abstract, and people often ask us what it means. We have tried to calculate it ourselves, but the tech reviewers did not agree with our math skills. So this is the perfect opportunity to quote someone else. According to Amazon Evangelist Jeff Barr, this many 9s means that, “If you store 10,000 objects with us, on average we may lose one of them every 10 million years or so.” Impressive! S3 as a service is covered by a service level agreement (SLA), making these numbers not just a promise but a full contract.
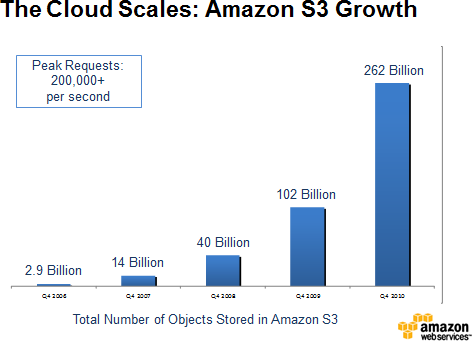
S3 was extremely well received. Even Microsoft was (or is) one of the customers using S3 as a storage solution, as advertised in one of the announcements of AWS: “Global enterprises like Microsoft are using Amazon S3 to dramatically reduce their storage costs without compromising scale or reliability”. In only two years, S3 grew to store 10 billion objects. In early 2010, AWS reported to store 102 billion objects in S3. Figure 1-3 illustrates the growth of S3 since its release.
Though we still think that S3 is the most revolutionary of services because no one had solved the problem of unlimited storage before, the service with the most impact is undoubtedly Amazon Elastic Compute Cloud or EC2. Introduced as limited beta in the same year that S3 was launched (2006), EC2 turned computing upside down. AWS used XEN virtualization to create a whole new cloud category, Infrastructure as a Service, long before people started googling for IaaS. Though server virtualization already existed for quite a while, buying one hour of computing power in the form of a Linux (and later Windows) server did not exist yet.
Remember, Amazon was trying to decouple, to separate its huge system into components. For Amazon, EC2 was the logical missing piece of the puzzle because Amazon was in the middle of implementing a strict form of SOA. In Amazon’s view, it was necessary to change the organization. Each team would be in charge of a functional part of the application, like wish lists or search. Amazon wanted each (small) team not only to build its own infrastructure, but also for developers to operate their apps themselves. Werner Vogels said it in very simple terms: “You build it, you run it.”
In 2007, EC2 was opened to everyone, but it took more than a year before AWS announced general availability, including SLA. There were some very important features added in the meantime, most of them as a result of working with the initial community of EC2 users. During this period of refining EC2, AWS earned the respect of the development community. It showed that Amazon listened and, more importantly, cared. And this is still true today. The Amazon support forum is perhaps its strongest asset.
By offering computing capacity per hour, AWS created elasticity of infrastructures from the point of view of the application developer (which is also our point of view.) When it was this easy to launch servers, which Amazon calls instances, a whole new range of applications became reachable to a lot of people. Event-driven websites, for example, can scale up just before and during the event and can run at low capacity the rest of the time. Also, computational-intensive applications, such as weather forecasting, are much easier and cheaper to build. Renting one instance for 10,000 hours is just as cheap as renting 10,000 instances for an hour.
Amazon’s big system is decoupled with the use of SQS and S3. Components can communicate effectively using queues and can share large amounts of data using S3. But these services are not sufficient as glue between the different applications. In fact, most of the interesting data is structured and is stored in shared databases. It is the relational database that dominates this space, but relational databases are not terribly good at scaling, at least for commodity hardware components. Amazon introduced Relational Database Server (RDS) recently, sort of “relational database as a service,” but its own problem dictated that it needed something else first.
Although normalizing data is what we have been taught, it is not the only way of handling information. It is surprising what you can achieve when you limit yourself to a searchable list of structured records. You will lose some speed on each individual transaction because you have to do more operations, but you gain infinite scalability. You will be able to do many more simultaneous transactions. Amazon implemented this in an internal system called Dynamo, and later, AWS launched Amazon SimpleDB.
It might appear that the lack of joins severely limits the usefulness of a database, especially when you have a client-server architecture with dumb terminals and a mainframe server. You don’t want to ask the mainframe seven questions when one would be enough. A browser is far from a dumb client, though. It is optimized to request multiple sources at the same time. Now, with a service specially designed for many parallel searches, we have a lot of possibilities. By accessing a user’s client ID, we can get her wish list, her shopping card, and her recent searches, all at the same time.
There are alternatives to SimpleDB, and some are more relational than others. And with the emergence of big data, this field, also referred to as NoSQL, is getting a lot of attention. But there are a couple of reasons why it will take time before SimpleDB and others will become successful. The most important reason is that we have not been taught to think without relations. Another reason is that most frameworks imply a relational database for their models. But SimpleDB is incredibly powerful. It will take time, but slowly but SimpleDB will surely find its place in (web) development.
The core principle of AWS is optimization, measured in hardware utilization. From the point of view of a cloud provider like AWS, you need economies of scale. As a developer or cloud consumer, you need tools to operate these infrastructure services. By listening to its users and talking to prospective customers, AWS realized this very point. And almost all the services introduced in this last phase are meant to help developers optimize their applications.
One of the steps of optimization is creating a service to take over the work of a certain task. An example we have seen before is S3, which offers storage as a service. A common task in web (or Internet) environments is load balancing. And just as with storage or queues, it would be nice to have something that can scale more or less infinitely. AWS introduced a service called Elastic Load Balancing or ELB to do exactly this.
When the workload is too much for one instance, you can start some more. Often, but not always, such a group of instances doing the same kind of work is behind an Elastic Load Balancer (also called an ELB). To manage a group like this, AWS introduced Auto Scaling. With Auto Scaling you can define rules for growing and shrinking a group of instances. You can automatically launch a number of new instances when CPU utilization or network traffic exceeds certain thresholds, and scale down again on other triggers.
To optimize use, you need to know what is going on; you need to know how the infrastructure assets are being used. AWS introduced CloudWatch to monitor many aspects of the infrastructure assets. With CloudWatch, it is possible to measure metrics like CPU utilization, network IO, and disk IO over different dimensions like an instance or even all instances in one region.
AWS is constantly looking to optimize from the point of view of application development. It tries to make building web apps as easy as possible. In 2009, it created RDS, a managed MySQL service, which eases the burden of optimization, backups, scaling, etc. Early in 2010, AWS introduced the high availability version of RDS. AWS also complemented S3 with CloudFront, a very cheap content delivery network, or CDN. CloudFront now supports downloads and streaming and has many edge locations around the world.
AWS first launched on the east coast of the United States, in northern Virginia. From the start, the regions were designed with the possibility of failure in mind. A region consists of availability zones, which are physically separate data centers. Zones are designed to be independent, so failure in one doesn’t affect the others. When you can, use this feature of AWS, because it can harden your application.
While AWS was adding zones to the US East region, it also started building new regions. The second to come online was Europe, in Ireland. And after that, AWS opened another region in the US, on the west coast in northern California. One highly anticipated new region was expected (and hinted at) in Asia Pacific. And in April 2010, AWS opened region number four in Singapore.
In 2001, the Agile Manifesto for software development was formulated because a group of people felt it was necessary to have more lightweight software development methodologies than were in use at that time. Though this movement has found its place in many different situations, it can be argued that the Web was a major factor in its widespread adoption. Application development for the Web has one major advantage over packaged software: in most cases it is distributed exactly once. Iterative development is much easier in such an environment.
Iterative (agile) infrastructure engineering is not really possible with physical hardware. There is always a significant hardware investment, which almost always results in scarcity of these resources. More often than not, it is just impossible to take out a couple of servers to redesign and rebuild a critical part of your infrastructure. With AWS, you can easily build your new application server, redirect production traffic when you are ready, and terminate the old servers. For just a few dollars, you can upgrade your production environment without the usual stress.
This particular advantage of clouds over physical hardware is important. It allows for applying an agile way of working to infrastructures, and lets you iteratively grow into your application. You can use this to create room for mistakes, which are made everywhere. It also allows for stress testing your infrastructure and scaling out to run tens or even hundreds of servers. And, as we did in the early days of Layar, you can move your entire infrastructure from the United States to Europe in just a day.
In the following sections, we will look at the AWS services you can expect to use in the different iterations of your application.
When asking the question, “Does the application have to be highly available?”, the answer is usually a clear and loud “yes.” This is often expensive, but the expectation is set and we work very hard to live up to it. If you ask the slightly different question, “Is it acceptable to risk small periods of downtime provided we can restore quickly without significant loss of data?”, the answer is the same, especially when it becomes clear that this is much less expensive. Restoring quickly without significant loss of data is difficult with hardware, because you don’t always have spare systems readily available. With AWS, however, you have all the spare resources you want. Later, we’ll show you how to install the necessary command-line tools, but all you need to start five servers is:
$ ec2-run-instances ami-480df921 -n 5
When it is necessary to handle more traffic, you can add servers—called instances in EC2—to relieve the load on the existing infrastructure. After adjusting the application so it can handle this changing infrastructure, you can have any number of instances doing the same work. This way of scaling—scaling out—offers an interesting opportunity. By creating more instances doing the same work, you just made that part of your infrastructure highly available. Not only is your system able to handle more traffic or more load, it is also more resilient. One failure will no longer bring down your app.
After a certain amount of scaling out, this method won’t work anymore. Your application is probably becoming too complex to manage. It is time for something else; the application needs to be broken up into smaller, interoperating applications. Luckily, the system is agile and we can isolate and extract one component at a time. This has significant consequences for the application. The application needs to implement ways for its different parts to communicate and share information. By using the AWS services, the quality of the application only gets better. Now entire components can fail and the app itself will remain functional, or at least responsive.
AWS has many useful and necessary tools to help you design for failure. You can assign Elastic IP addresses to an instance, so if the instance dies or you replace it, you reassign the Elastic IP address. You can also use Elastic Block Store (EBS) volumes for instance storage. With EBS, you can “carry around” your disks from instance to instance. By making regular snapshots of the EBS volumes, you have an easy way to back up your data. An instance is launched from an image, a read-only copy of the initial state of your instance. For example, you can create an image containing the Ubuntu operating system with Apache web server, PHP, and your web application installed. And a boot script can automatically attach volumes and assign IP addresses. Using these tools will allow you to instantly launch a fresh copy of your application within minutes.
Most applications start with some sort of database, and the most popular database is MySQL. The AWS RDS offers MySQL as a service. RDS offers numerous advantages like backup/restore and scalability. The advantages it brings are significant. If you don’t use this service, make sure you have an extremely good reason not to. Scaling a relational database is notoriously hard, as is making it resilient to failure. With RDS, you can start small, and if your traffic grows you can scale up the database as an immediate solution. That gives you time to implement optimizations to get the most out of the database, after which you can scale it down again. This is simple and convenient: priceless. The command-line tools make it easy to launch a very powerful database:
$ rds-create-db-instance kulitzer \
--db-instance-class db.m1.small \
--engine MySQL5.1 \
--allocated-storage 5 \
--db-security-groups default \
--master-user-password Sdg_5hh \
--master-username arjan \
--backup-retention-period 2Having the freedom to fail (occasionally, of course) also offers another opportunity: you can start searching for the boundaries of the application’s performance. Experiencing difficulties because of increasing traffic helps you get to know the different components and optimize them. If you limit yourself in infrastructure assets, you are forced to optimize to get the most out of your infrastructure. Because the infrastructure is not so big yet, it is easier to understand and identify the problem, making it easier to improve. Also, use your freedom to play around. Stop your instance or scale your RDS instance. Learn the behavior of the tools and technologies you are deploying. This approach will pay back later on, when your app gets critical and you need more resources to do the work.
One straightforward way to optimize your infrastructure is to offload the “dumb” tasks. Most modern frameworks have facilities for working with media or static subdomains. The idea is that you can use extremely fast web servers or caches to serve out this static content. The actual dynamics are taken care of by a web server like Apache, for example. We are fortunate to be able to use CloudFront. Put your static assets in an S3 bucket and expose them using a CloudFront distribution. The advantage is that you are using a full-featured content delivery network with edge locations all over the world. But you have to take into account that a CDN caches aggressively, so change will take some time to propagate. You can solve this by implementing invalidation, building in some sort of versioning on your assets, or just having a bit of patience.
The initial setup is static. But later on, when traffic or load is picking up, you need to start implementing an infrastructure that can scale. With AWS, the biggest advantage you have is that you can create an elastic infrastructure, one that scales up and down depending on demand. Though this is a feature many people want, and some even expect out of the box, it is not applicable to all parts of your infrastructure. A relational database, for example, does not easily scale up and down automatically. Work that can be distributed to identical and independent instances is extremely well suited to an elastic setup. Luckily, web traffic fits this pattern, especially when you have a lot of it.
Let’s start with the hard parts of our infrastructure. First is the relational database. We started out with an RDS instance, which we said is easily scalable. It is, but, unaided, you will reach its limits relatively quickly. Relational data needs assistance to be fast when the load gets high. The obvious choice for optimization is caching, for which there are solutions like Memcached. But RDS is priceless if you want to scale. With minimum downtime, you can scale from what you have to something larger (or smaller):
$ rds-modify-db-instance kulitzer \
--db-instance-class db.m1.xlarge \
--apply-immediatelyWe have a strategy to get the most out of a MySQL-based data store, so now it is time to set up an elastic fleet of EC2 instances, scaling up and down on demand. AWS has two services designed to take most of the work out of your hands:
Amazon ELB
Amazon Auto Scaling
ELB is, for practical reasons, infinitely scalable, and works closely with EC2. It balances the load by distributing it to all the instances behind the load balancer. The introduction of sticky sessions (sending all requests from a client session to the same server) is recent, but with that added, ELB is feature-complete. With Auto Scaling, you can set up an autoscaling group to manage a certain group of instances. The autoscaling group launches and terminates instances depending on triggers, for example on percentage of CPU utilization. You can also set up the autoscaling group to add and remove these instances from the load balancer. All you need is an image that launches into an instance that can independently handle traffic it gets from the load balancer.
ELB’s scalability comes at a cost. The management overhead of this scaling adds latency to the transactions. But in the end, human labor is more expensive, and client performance does not necessarily need ultra low latencies in most cases. Using ELB and Auto Scaling has many advantages, but if necessary, you can build your own load balancers and autoscaling mechanism. All the AWS services are exposed as APIs. You can write a daemon that uses CloudWatch to implement triggers that launch/terminate instances.
The most expensive part of the infrastructure is the relational database component. None of the assets involved here scales easily, let alone automatically. The most expensive operation is the join. We already minimized the use of joins by caching objects, but that is not enough. All the big boys and girls try to get rid of their joins altogether. Google has BigTable and Amazon has SimpleDB, both of which are part of what is now known as NoSQL. Other examples of NoSQL databases are MongoDB and Cassandra, and they have the same underlying principle of not joining.
The most radical form of minimizing the use of joins is to decouple, and a great way to decouple is to use queues. Two applications performing subtasks previously performed by one application are likely to need less severe joins. Internally, Amazon has implemented an effective organization principle to enforce this behavior. Amazon reorganized along the lines of the functional components. Teams are responsible for everything concerning their particular applications. These decoupled applications communicate using Amazon SQS and Amazon Simple Notification Service (SNS), and they share using Amazon SimpleDB and Amazon S3.
These teams probably use MySQL and Memcached and ELB to build their applications. But the size of each component is reduced, and the traffic/load on each is now manageable once more. This pattern can be repeated again and again, of course.
Perhaps by chance, but probably by design, AWS empowers development teams to become truly agile. It does this in two ways:
Getting rid of the long-term aspect of the application infrastructure (investment)
Building tools to help overcome the short-term aspect of operating the application infrastructure (failure)
There is no need to distinguish between building and running, and according to Werner Vogels, it is much better than that:
Giving developers operational responsibilities has greatly enhanced the quality of the services, both from a customer and a technology point of view. The traditional model is that you take your software to the wall that separates development and operations, and throw it over and then forget about it. Not at Amazon. You build it, you run it. This brings developers into contact with the day-to-day operation of their software. It also brings them into day-to-day contact with the customer. This customer feedback loop is essential for improving the quality of the service.
This lesson is interesting, but this particular change in an organization is not always easy to implement. It helped that Vogels was the boss, though it must have cost him many hours, days, and weeks to convince his colleagues. If you are not the boss, it is even more difficult, though not impossible. As we have seen before, AWS offers ways to be agile with infrastructures. You can tear down servers, launch new ones, reinstall software, and undo entire server upgrades, all in moments.
In bigger organizations, there is an IT department. Communication between the organization and its IT department can difficult or even entirely lacking. The whole activity of operating applications can be surrounded with frustration, and everyone feels powerless. Smaller companies often have a hosting provider, which can be very similar to an IT department. A hosting provider tends to be a bit better than an IT department because you can always threaten to replace it. But the lock-in is significant enough to ignore these issues; for a small company it is generally more important to focus on development than to spend time and energy on switching hosting providers.
Let’s start with one side: the IT department or hosting provider. Its responsibility is often enormous. IT department members have to make decisions on long-term investments with pricetags that exceed most product development budgets. These investments can become difficult projects with a huge impact on users. At the same time, the IT department has to make sure everything runs fine 24/7. It is in a continuous battle between dealing with ultra long term and ultra short term; there seems to be nothing in between.
Now for the development team. The work of the development team is exactly in between the long term and the short term. The team is asked to deliver in terms of weeks and months, and often makes changes in terms of days. During the development and testing phases, bugs and other problems are part of the process, part of the team’s life. But once in production, the application is out of the team’s hands, whether they like it or not.
Organizations can handle these dynamics by creating complex processes and tools. Because each group typically has no understanding of the other’s responsibilities, they tend to formalize the collaboration/communication between the teams, making it impersonal. But as the Agile Manifesto states, in developing software individuals and interactions are more valuable than processes and tools. With AWS, the investment part of infrastructures is nonexistent. And AWS helps you manage the ultra short term by providing the tools to recover from failure. With AWS, you can merge the responsibility of running the application with the responsibility of building it. And by doing this, you turn the focus on the people and their interactions instead of on creating impersonal and bureaucratic processes.
Deploying software means moving the application from development to the “other side,” called production. Of course, the other side—the IT department in the traditional structure—has already committed to a particular SLA. As soon as the application is moved, the IT department is on its own. As a consequence, members want or need to know everything necessary to run the application, and they require documentation to do so.
This documentation is an SLA itself. If there is a problem related to the software that is not included in the documentation, fingers will point to the development team. The documentation becomes a full description of every aspect of the application, for fear of liability.
But in the end, there is only one thing that matters, and that is whether the application is running. This is not very difficult to determine if the responsibility is shared; the team members will quickly discuss a solution instead of discussing who is to blame. So the thing to do is to build working software together, as a team. Remove the SLAs and merge the functions of two teams into one. When something doesn’t work, it needs to be fixed—it does not always have to be debated first. Documentation in this context becomes less important as a contract between parts, and becomes an aid to keep the application running.
Wherever IT is present, there is an SLA. The SLA is regarded as a tool in managing the process of IT infrastructure, where the bottom line is the number of nines. In reality it is a tool designed to facilitate cooperation, but is often misused for the purpose of deciding who is responsible for problems: development or operations.
It can be difficult to negotiate this contract at the time of application development. There is a huge difference between “we need to store audio clips for thousands of customers” and “storage requirements are estimated to grow exponentially from 500 GB to 5 TB in three years.” The problem is not so much technical as it is that expectations (dreams, often) are turned into contract clauses.
You can change contract negotiation into customer collaboration. All you need to do is merge the two responsibilities: building and running the application becomes a shared challenge, and success is the result of a shared effort. Of course, in this particular example it helps to have Amazon S3, but the point is that requirements change, and collaboration with the customer is better suited for handling those changes than complex contract negotiations.
At the end of the project, just two weeks before launch, the CEO is shown a sneak preview of the new audio clip platform. She is very excited, and proud of the team effort. The meeting is positive and she is reassured everything is planned for. Even if the dreams of millions of customers come true, the platform will not succumb to its success because it’s ready to handle a huge number of users.
In the evening, she is telling her boyfriend about her day. She shares her excitement and they both start to anticipate how they would use the new platform themselves. At some point he says, “Wouldn’t it be great to have the same platform for video clips?” Of course, he doesn’t know that this whole project was based on a precondition of audio-only; neither does the CEO.
In the morning, she calls the project manager and explains her idea. She is still full of energy and says enthusiastically, “the functionality is 100% perfect, only we want audio and video.” The project manager knows about the precondition, and he also knows that video files are significantly bigger than audio files. However, the CEO doesn’t want to hear buts and objections about moving away from the plan; she wants this product to change before launch.
In this chapter we walked you through the recent history of AWS. We showed how each of the AWS services was created to solve a particular problem with Amazon’s platform. We gave you a brief overview of the different AWS services you can use to build, monitor, and scale your cloud infrastructure. And finally, we talked about how developing with AWS is naturally agile and allows you to make the infrastructure building and running part of the development process.
In the rest of the book, we’ll show how all these services actually work, so get ready to stop reading and start doing! In the next chapter, we will start with migrating a simple web application to AWS using EC2, RDS, S3, and CloudFront.
Get Programming Amazon EC2 now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

