Chapter 1. The Big Picture
Are you happy with the quality of the code you write? Probably not, or you wouldn’t be reading this book! This doesn’t mean that you are a “bad” programmer. It means only that you feel that your code has room for improvement—and I’m sure that’s true for every single programmer among us.
I believe that you can dramatically improve the quality of your code by following programming best practices. Two very interesting concepts are implicit in that term:
It is possible to talk about a “best” way of writing code, which implies, conversely, that there is a worst or at least suboptimal way to write code.
These “best” ways can be organized into “practices,” formalized processes for writing high-quality software.
After having written software (and books about writing software) for almost 30 years, I am firmly convinced that these two concepts are both valid and fundamentally important, and that you can’t have one without the other.
Humanity survived its first worldwide software crisis on January 1, 2000—but at a cost of several hundred billion dollars. Users of software, unfortunately, continue to experience localized software crises on a daily basis, as they struggle with poorly written applications that are a direct consequence of the QUAD “methodology” (QUick And Dirty).
Software has the potential to dramatically improve the quality of life of billions of human beings. It can—with the help of robotics—automate tedious and dangerous processes. It can make information and services more widely accessible. It can, should, and must play a role in halting the degradation of our environment. In short, software has an enormous potential, but that potential will never be realized unless we can find a way to substantially improve the quality of the code we write.
This book has a very simple but ambitious purpose: to help Oracle developers and development teams transform the way they write PL/SQL-based applications. To achieve this transformation in your programming life, you will need both to rethink fundamental aspects of application design and construction, and to change day-to-day programming habits.
In the chapters that follow, we’ll examine a wide range of PL/SQL topics: programming standards; program testing, tracing, and debugging; variables and data structures; control logic; error handling; the use of SQL in PL/SQL; the building of procedures, functions, packages, and triggers; and overall program performance. Since this first chapter focuses on “big picture” advice for building successful applications, it seems reasonable to start off the chapter by spending some time and words defining “successful” in the context of software projects.
Successful Applications Are Never an Accident
If you have the privilege of buying a new automobile and rolling it off the dealer’s lot, you don’t say to yourself:
Well, every 50 miles or so, one of my wheels might fall off. The odometer sometimes goes backward, and, oh look! My windows don’t quite close. But that’s all right, because the dealer said that I’ll be getting version 2 in roughly six months. I can’t wait!
Sounds silly, doesn’t it? Yet for people who buy and use software, it has become the norm to think in precisely these terms. Now, if an automobile manufacturer really did deliver cars that were as buggy as many of the applications let loose upon the world, that manufacturer would likely be out of business very soon. While it is certainly possible that a software company will go belly up if its code is too buggy, for the most part our employers keep on going (and we keep on programming), issuing new versions that fix some bugs and introduce others.
Why is there such a difference in the way people view, use, and tolerate cars versus software? I think there are three basic reasons:
Cyberspace, the world of software, is a world of our creation. We determine what is possible and not possible within that world. This total control gives us the ability to “upgrade” that world, fixing problems, adding possibilities, and adding constraints, with relative ease. You just can’t do that with “real” products.
Cyberspace is, at its core, an attempt by software developers to simulate a small slice of the real world, and then automate some processes to help users accomplish things in that real world. Because the world “out there” is so incredibly complex, writing software is a very hard thing to do, and even harder to do well.
Human society (at least those societies in which the Industrial and Information Revolutions have had their way with us) is today unimaginable without computers and the software that makes computers useful. Software permeates almost every aspect of our lives. And that means that for the most part our users are a “captive audience”: they have to use what we give them, no matter how faulty.
I am going to assume that you are reading this book because you would like to pick up some pointers about how to improve the quality of the PL/SQL code that you write. You would like to do so in order to produce applications that are more successful. Perhaps it would be helpful, therefore, to remind ourselves of what it means for an application to be successful.
I believe that for an application to be considered successful, it must satisfy the following criteria (listed in order of importance):
- It meets user requirements
This, to my mind, is the most fundamental of all. I hope the reason is obvious to you. If the application doesn’t do what the user wants it to do, well, then the project is a complete or partial failure, depending on the extent to which it falls short.
- It is maintainable
The code we write today is the code that users will run tomorrow, and next year, and most likely next decade. The Y2K crisis drove home the point that software has a life far beyond our expectations. If we don’t write our code so that it can be easily and quickly maintained, an initial success will quickly turn into a failure.
- It runs fast enough to minimize user frustration
If the application meets user needs, but runs so slowly that it makes you want to pull out the old calculator or slide rule, it cannot be deemed a success.
Now, I have a feeling that you may be reading these three criteria and feeling a stab of disappointment. “That’s the most obvious thing I’ve ever read,” you’re saying to yourself. “Of course, it has to do what the user says it must, and it can’t be slow as molasses, and, yeah sure, about that maintainable thing.”
I agree: these characteristics are or should be obvious. In fact, they are so obvious that we don’t pay them sufficient attention, with the consequence that very few of our application projects are a success! The easiest way to see what I am talking about is to consider what we developers must or should do to ensure that these criteria are met.
Successful Applications Meet User Requirements
What is the only way that we can guarantee that our application code meets user requirements? We must test our code. Without rigorous, comprehensive, and repeatable tests, we have no way of knowing that the application actually works. We simply hope for the best.
Again, this might seem obvious at first glance. But stop and think about how testing occurs in your code and in the “finished product.” Testing is often the last thing we think about, and the last thing we do. That means that we never have enough time to test, and that the application goes into production full of bugs. Those same bugs (and the process of fixing them) eat into the time required to add new functionality, so users generally always feel that critical features are missing.
Sadly, while user requirements might be more or less black and white, user expectations are not: they can and do change as users encounter the reality of programming. That is, users have come to accept applications that do not meet all their needs, and feel that they must settle for “good enough,” “just barely sufficient,” or, worst of all, that they have “no choice but to use this garbage.”
Successful Applications Are Maintainable
I sometimes fantasize that after I retire from active development, as I live out my years in a small, isolated, and very beautiful former coffee farm near the west coast of Puerto Rico, I’ll get a phone call: “Steven, they’ve described the Y2.1K bug in PL/SQL! All of our applications are going to crash in six months. We need you! We’ll pay whatever you require—to fix the bugs you put in your code back in 2010!”
Now that, dear friends, would be quite a good deal: to be paid top dollar to fix bugs I put in my code years or decades before. Of course, it would be much nicer if I wrote my code in such a way that years from now, when bugs are discovered, it would be easy for that next generation of coders to make the necessary fixes on their own.
Sadly, as far as I can tell, most of us (and I do include myself in this critique) are so overwhelmed by meeting immediate deadlines that we feel we don’t have the time to do things the “right way.” Instead, the only option is “quick and dirty,” and the code that results from taking shortcuts is generally almost impossible to maintain.
For an application to be maintainable, it must have associated with it a comprehensive regression test, which must be run after any changes are made to the code to ensure that no bugs have been introduced. The code must also be structured so that any developer can open up a program and feel perfectly at home in the code, even if she didn’t write it, even if she’s never seen it before. The code should be welcoming, rather than threatening.
Successful Applications Run Fast Enough
To ensure that users don’t smash their keyboards through their monitors in frustration, we must optimize execution of our applications. This criterion usually gets the most (and the most explicit) attention, in part, I believe, because performance most directly affects our experience of using the software. We can accept that a particular feature is not yet available, or that a bug doesn’t let us do what we would really like to do. We all have ways of compensating.
If minutes pass, though, whenever I (or the person running the code that is providing a service to me) press the Submit button, I tend to feel my life slipping away from me. Perhaps it is our ingrained fear of mortality, but the pain of waiting for software to finish its job is an especially sharp one.
Optimizing the performance of an application is a complex affair, in part because there are so many different moving parts in software. There has been lots of attention paid (and many tools built) to address this problem. My feeling, in fact, is that achieving adequate performance is the requirement that is most thoroughly dealt with in today’s software, sometimes to the detriment of the other, more challenging criteria.
So, yes, these criteria are obvious, but meeting them can present quite a challenge. And because it can be so difficult to meet user requirements, write maintainable code, and get our applications working quickly enough, we adjust expectations downward and everyone suffers. Our users have come to expect software to be maddeningly lacking in features, ridiculously buggy, and frustratingly slow.
And that brings us directly to best practices, because without them, you can achieve success in your development project only accidentally—and that just doesn’t happen!
Best Practices for Successful Applications
Best practices are the guidelines you should follow to achieve a “best” or successful application—one that meets the criteria listed in the previous sections. “Best practices” is certainly an overused term, but it is also clear enough in intent to be useful.
When programmers follow best practices, they have made a decision to work against their “quick and dirty” tendency and to consciously, with intention and purpose, seek to transform the way they write their code. Without that focus, without a deliberate act on the part of developers (and their managers as well), there is a very low likelihood that their applications will be successful.
Best practices also must go beyond (and deeper than) words on a page. For best practices to be successfully applied, they must be combined with tools and scripts to make them practical.
Best practices should operate at two levels:
- Big picture
A high-level workflow that provides an overall guide to writing code. “Big picture” best practices for constructing applications and applying fundamental principles are usually decided on before a project starts. Best practices in this category set standards for all of the code written in an application.
- Day-to-day
Concrete recommendations for specific aspects of code construction that are applied in each new program as it is written and maintained.
Both types of best practices are important. The following sections focus on the key “big picture” best practices that will set the stage for the day-to-day recommendations you will find in the rest of the book.
Software is like ballet: choreograph the moves or end up with a mess.
Put into place a practical workflow that emphasizes iterative development based on a shared foundation.
Problem: In software, the ends (production code) are inseparable from the means (the build process).
It is back in 2004. Sunita has just been promoted to development manager at My Flimsy Excuse, Inc., and has been given responsibility for both a newly assembled team (Delaware, Lizbeth, and Jasper), and a critical new application development project. She is feeling a little bit overwhelmed and intimidated. Delaware has been around forever and is famous (infamous?) for both his brilliant coding and his brittle personality. Lizbeth has more quietly, but just as firmly, established herself within the company as a valuable resource; she serves on several standards committees and sends out a monthly “What’s New in the MFE Family” newsletter. Who is Sunita, compared to them?
She calls the first meeting of the team and begins to lay out her ideas for implementing the project. Delaware, attired in a very retro double-breasted suit, immediately breaks in and explains in no uncertain terms why her approach will fail. “We are all very experienced,” he says sternly. “Why not leverage that experience and free us up to do what we do best?” The others nod, and Sunita feels she has little choice but to agree.
So all three developers dive in with enthusiasm, applying to their part of the application their own individual approaches to writing code. Sunita checks in regularly, but she feels more like an outsider than a manager at this stage. She reassures herself that she has a team of professionals building the application; they don’t need lots of direction.
Three months into the project, problems start popping up. Delaware’s code needs to talk to Lizbeth’s code, but the way they have each designed their interfaces makes such communication very difficult. And not long after that, during a rare code review session (insisted upon by Sunita), they discover that they have each built their own error-management code, writing to different tables and storing different information.
But it is too late to turn back now, so the team struggles on, adding new layers of code to achieve some level of interoperability and consistency. The application grows more and more complex; deadlines are missed; performance is very uneven, with some programs running very slowly even with average quantities of data; tensions rise between developers who used to get along just fine. Finally, though, they tell Sunita that they have spent the last few days testing the code and fixing bugs; the application is now ready for QA. But the QA group finds that the application has so many low-level bugs that it can’t get even halfway through an acceptance test.
Stamping “REJECTED” on the application, QA sends it back to Sunita, who admits defeat. The application will not, in its current incarnation, see the light of day.
Solution: Agree on a common development workflow built around standards, testing, and reviews.
Sunita is so disgusted with herself that she asks for a meeting with her boss and submits her resignation. To Sunita’s surprise, her boss, Marguerite, is not surprised at the news of her team’s failure or her intense reaction to it. She says:
Sunita, you are right: this is very bad news, but the danger signals have been there for a while. I suppose perhaps I should have stepped in earlier and made some suggestions, but I thought it was important for you to see it through. No, I do not accept your resignation, but I would like to know what you have learned from this experience. Because now it is time for Round Two. We need this application, and you know the requirements better than anyone in the company. So what should we do now?
Sunita is stunned into silence. She thinks about what has happened over the past half-year and sums it up as follows:
Even if every developer is excellent on his or her own, as a team we must still agree on standard approaches for the common elements of our application: error management, SQL statements, and naming conventions.
Testing can’t be short-changed, and it can’t be put off until the very end of the development process. Feedback (including bad news) is needed all the way through the process.
A manager should make sure that the developers on the team are productive and focused, but she must also make the hard decisions that no individual developer can or will make on his or her own—the developers are simply too close to the code and, hence, the problem.
With those ideas in mind, Sunita convenes her team and lays down the law: they will spend the next week (or two, if needed) researching standards and tools they can use to come up with a standard development style. With that foundation, they start again and this time are able to successfully complete the application.
While each reader, or team, may choose different tools and naming conventions, I believe that we should all follow a workflow that is based on standards and that reinforces best practices. This workflow must be simple enough to remember with ease, and must also be integrated into the tools you use. This way, you can follow the workflow without having to pay conscious attention to it every other minute of the day.
Developers need to focus on two distinct workflows:
Application-level workflow
Single-program construction workflow
In the next section, I’ll explain my approach to the application-level workflow; then we’ll delve into the recommended workflow for individual programs within that application.
Application-level workflow
You are about to start building a new application. Such a wonderful moment! If you are like me, you immediately engage in a beautiful fantasy; this time we are going to “do it right.” We are going to write code that is easy to understand and maintain, that is thoroughly documented and tested, that is fully optimized. Sounds great, but how do you make that happen?
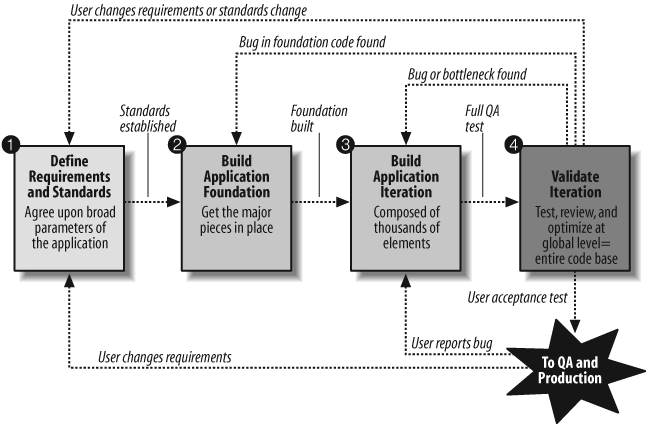
Figure 1-1 offers a high-level workflow that provides a framework in which we can write our code to achieve these objectives. This framework is based on the following principles:
Software is an iterative process: anything you do today, you will need to come back and do again tomorrow.
A shared foundation based on standards is critical to implementing best practices.
Let’s go through each of these four steps.
Step 1: Define requirements and standards.
Before writing any application code, we need the cleanest, clearest possible set of requirements from our users. I can already hear the groans emitted by readers. “Clear requirements from our users? Ha! Anything they tell us today is going to change tomorrow. Our users drive us mad!”
Yes, users can be very frustrating, but usually it isn’t their fault. The requirements they give us are driven by their requirements, which come from the ever-changing and oh-so-complex real world “out there.” So accept the fact that change is a fundamental characteristic of requirements gathering. The best you can do is freeze in place a clear vision of the application needs at this moment.
Given that constraint, however, there is something you can do to improve user requirements: work with your users to think logically through what they need. I emphasize “logically” because we programmers spend lots of time using symbolic logic to solve problems and write algorithms. Compared to most other people, our brains are highly trained instruments of rational processing. With this orientation, we are well equipped to help our users sort out their issues and work out the kinks (contradictions and points of confusion) in their requirements.
Once that is done, attention shifts to the way we will build our code to meet those requirements. Before any programs are written, you need to define the standards that are to be applied to each program. I believe that at a minimum your standards should cover these three areas:
- Naming conventions and coding standards
It is extremely important that everyone on the team write code in a similar fashion. No, we don’t want to turn into Code Fascists, and insist on 100 percent conformance to a single style, but we should work to avoid wide variations.
- SQL access
SQL is so easy to write in PL/SQL that almost all of us take it totally for granted: we write SQL statements wherever, whenever, and however we like. Sound reasonable? Well, you’re wrong. It doesn’t make any sense at all. Think about it: SQL statements are among the most volatile elements of your code, changing along with the underlying table structures and relationships. In addition, those queries, updates, and other SQL operations are the source of most performance problems in your application. The only thing that makes sense about SQL in your PL/SQL code is that you proactively set guidelines for when, where, and how SQL statements are to be written into the code.
- Error management
If errors are raised, handled, and communicated inconsistently (or not at all), users will have a hard time understanding how to deal with problems when they occur, and developers will have an even harder time debugging and fixing their applications.
I am sure you can come up with other areas of standardization that are appropriate to your application, but you need rules for at least the above three items. So now you may be asking, “Well, what are the rules for these areas?” You will find details for each item in the chapters listed in the next section.
Step 2: Build the application foundation.
Once you set some rules, you need to think about how to best and most smoothly implement those rules. I suggest that you focus on two different areas:
- Formalize a process that inherently supports the rules to be followed
If rules are nothing more than a set of checklists in a document, programmers will never be able to remember them, much less follow them. So you need to come up with clearly defined processes, backed up by tools, that make it easy for developers to follow the rules with a minimum of thought and energy.
- Automate the implementation of rules
Without a doubt, the best way to follow rules is to have them implemented automatically for you. Press a button on a screen and, whoosh!, here comes the code, all following the standards. Done! Whenever possible, you should also automate the verification of compliance with rules.
In other words, get everything ready and in place so that as a developer writes a program for your application, it can easily follow the rules.
So let’s revisit the three focus areas listed in step 1, and address formalization and automation of the rules.
- Naming conventions and coding standards
The best way to formalize the process of following coding standards is to create code templates and snippets, and make them available in your editor of choice. Automation in this case would mean automated review of code to determine where that code does not follow best practices. Chapter 2 provides additional information.
- SQL access
The fundamental shift to be made when it comes to SQL is to think of data access as a service, not as code that you need to write—over and over again. In general, the rule I try to follow with SQL is: don’t write it! Chapter 7 covers this concept.
- Error management
The best, perhaps only, way to implement application-wide, consistent error logging, raising, and handling is to use a single, shared package, supported by a well-designed set of tables, to do all the work for the development team. This approach makes exception management so easy that everyone follows the standards without even knowing it! See Chapter 6 for more information on this idea.
OK, the foundation is now in place. Your developers have been trained in what is available and in how to use it. This is a critical step; if developers are not informed of which libraries and utility code are available to them, your team will be doomed to minimal code reuse and maximum wasting of time and resources.
And now it’s time to build an application!
Step 3: Build the next application iteration.
There certainly is a lot to talk about in this step, but we will defer the discussion for now and address it (from the standpoint of workflow) in the section "Single-program construction workflow,” later in this chapter, and in the detailed best practices throughout this book. The main point to consider at this level of the workflow is that after working on lots of individual programs, you eventually reach a point where you are ready to put all those pieces together into an iteration of the application.
Then, it’s time to check whether the application meets the criteria for success—that is, to validate this iteration of the application.
Step 4: Validate the application iteration
If you are going to set rules, it seems only reasonable that you should go back and check to make sure that they have been followed. Let’s look again at our application criteria and see what you need to do to satisfy them:
- Successful applications meet user requirements
Run all the regression tests for the code and make sure you get a green light at the code level. Do a round of acceptance testing (run by users and QA teams).
- Successful applications are maintainable
For all the code in your application, check whether coding standards have been followed; format the code according to the application standard (preferably using an automated “pretty printer”); identify code that is overly complex; and so on. The best way to do this is to combine peer review (people look at your code and give you feedback) with automated review.
- Successful applications run fast enough
Analyze performance of the entire application to identify bottlenecks. This analysis should be both objective (stress testing and other benchmarking) and subjective (user experience).
And what news will we get from all of this analysis? In the early iterations, we get lots of negative (uh, I mean, constructive) feedback: we’ve violated all kinds of rules, our code runs too slowly, and bugs have somehow crept into our code.
Depending on the source of the problem, we must then go back and “do it again.” If a problem is identified in the requirements, we will have to return to the first step, adjust those requirements, and then work on a new iteration. If a bug is found in the foundation code, we will need to fix that. Usually, though, when we validate an iteration, we simply find that there is code that must be changed in the application-level logic, and so our attention shifts back to step 3.
We repeat this process many times, until validation gives us a green light: all is well in our application, and it can move to production. Then the phone calls come flooding in from the users: “Thank you so much for building us such a wonderful application!” and “You have made our lives so much easier!”
Ah, if only it were so. We certainly do get calls, but usually they are in the form of bug reports or along the lines of “We changed our minds and need something different.” And then back we go into the application iteration. Don’t think of it as a bad thing—think of it as a jobs program!
Single-program construction workflow
The high-level workflow discussed in the previous section is critical, but when you get right down to it, software is all about the details—the individual lines of code, and the identifiers and operators within those lines. I suppose you could say that about everything: our bodies are made of atoms, for example. Yet with software, we programmers are responsible for all of the details (at the level of abstraction of our particular programming language, in any case), so it is inevitable that most of our time will be spent among these details.
This section offers a high-level workflow (summarized in Figure 1-2), not for the application as a whole, but for an individual program, procedure, or function. I hope that for many of you these ideas are obvious. I find, though, that even if we acknowledge each of these elements of a workflow, we often shortchange critical aspects, so let’s review the elements.
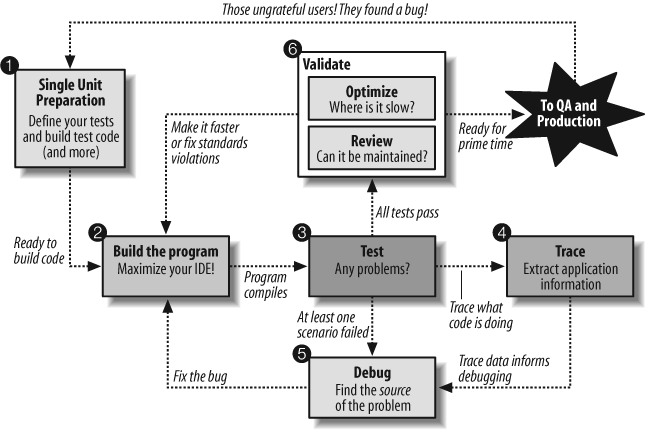
Step 1: Prepare for program construction.
Let’s start with the most important, most neglected, and most psychologically difficult step for programmers: prepare for program construction. Why do I say that this step is difficult? Because programmers are, for the most part, human beings who like to write programs—and that really means that we like to write cool algorithms. Our brains are attracted to solving such problems. And so we feel compelled to dive in and start writing those algorithms, before we’ve even thought through what we need to do.
Bad idea! Instead, we need to hold off on writing the algorithms and instead prepare for that glorious moment of coding. We need to clarify what the user needs, and we need to think about how to verify that what we have done works. This is an important step: the time you invest here will reap benefits for the rest of the life of your program.
The program preparation step consists of four main substeps: validate requirements, construct the program header, define tests, and build test code. I won’t get into the details of these substeps in this section, but I’ll revisit this preparation step and make sure it gets the attention it deserves later in this chapter, in the section titled “Deferred satisfaction is a required emotion for best practices.”
Step 2: Build an iteration of the program.
At this point you have done all your preparation. You have clarity about what is needed. You have defined your tests and written your test code (don’t worry—soon, you won’t find that idea so strange). Finally, you are allowed to focus on those fascinating algorithms and implement an iteration of the program. At some point, you will get your program to compile and then you will have stabilized that iteration.
And the best way to do that? Ah, well, that is what most of this book is about, so check out all those chapters that come after Chapter 1 to learn how to greatly improve the code you write.
Step 3: Test the program iteration.
The program compiles, which is an exciting moment in and of itself. Yet, sadly, there is more we need to do. Now it is time to test the iteration and see whether there are any problems with the program. In other words, we run the program and examine its behavior: does it do what we expect it to do? Note that when you test a program you don’t care how it gets the job done (what kind of algorithm is used to solve the problem). The program is, from the standpoint of testing, a “black box.”
The news that we usually get from our testing is simultaneously good and bad. The bad news is that our tests have identified some bugs, which means that we have to go back and fix them. The good news is that our tests have identified some bugs, which means that they can likely be fixed before our users start working with the application. Outcomes from testing are, therefore, inputs to the debugging process. Chapter 3 offers more details on the testing process.
Step 4: Trace execution of the program.
Oracle offers many options for system tracing. The built-in package DBMS_TRACE, for example, provides a type of tracing that generates information about the underlying database activity. Application tracing is different. With this type of tracing, as you run your program, you record or build a trace of information about what is happening inside the program—for example, which company ID was passed in, what company name it found, and so on. Tracing is a form of program instrumentation in which you add statements to your code that either change program behavior or extract information from the program.
Trace output (both system and application) serves as critical raw data to the debugging process, but tracing is fundamentally different from debugging (described in the next section). Chapter 3 discusses the tracing process in detail.
Step 5: Debug the program.
When you debug a program, you take the results of testing and tracing and then step through your code, line by line (using a visual source code debugger, I hope), in search of the source of each problem you have uncovered. After you have used logic to narrow down a problem to specific lines of code, you make changes to your program, recompile . . . and then start the process over again.
At some point along the way, you run your tests and you get a big surprise: a green light! Your tests show you that your program works. You can now move on to the next stage: validation. Chapter 3 offers more details on the debugging process.
Step 6: Validate the program: optimize and review.
The validation that should eventually occur for a single program mirrors the validation for an entire application, described earlier in “Step 4: Validate the application iteration.” For each particular program, you need to identify any obvious performance problems and check to make sure that you have followed the coding conventions and naming standards. Based on the feedback from these two types of validation, you go back and do the following:
Make changes to your program.
Run your regression tests, ensuring that you have not introduced any bugs.
Revalidate, and go through the cycle again.
At some point, your test program returns a thumbs-up (all tests succeed) and your code review process declares your program “clean.” You can now check in that program and essentially hand it off to QA, knowing that it is in good shape.
The next thing you know, the users are reporting bugs. So ungrateful! Now when a user reports a bug, she is actually reporting at least two bugs: the bug in your code (one or more programs) and the bug in your test code. After all, if your test code “worked,” the bug would have been found and fixed earlier in the process.
So, whenever a user reports a bug (and really, the same goes for enhancement requirements), you will first want go back to step 1 (preparation, for which I explore more details in the next section). Add the test cases needed to describe the tests you missed, update your test code to reflect those new test cases, and then run your test code to verify reproduction of the bug. Now you are ready to use your debugger to track down the cause of the problem, and fix it. That way, your test definitions stay current, get more and more complete over time, and continue to help you even past the initial production release of the software.
Which steps do you perform?
I expect that the steps I’ve discussed will make sense to most developers. From my many trainings and conversations with PL/SQL programmers, however, I have concluded the following:
Very little preparation is done (I’ll say more about what this means in the next section).
Testing is sporadic.
Tracing is usually based on the DBMS_OUTPUT.PUT_LINE function, which is problematic for a number of reasons, and is applied after the fact.
Code review is hardly ever done.
Optimization is performed manually (and rarely by the person who originally wrote the code), which means that developers need to understand EXPLAIN plans. Ugh.
In other words, for most programmers, the “workflow” of development is pretty simple: write some code and get it to compile. Run some scenarios and then spend lots of time in the debugger trying to figure out what might be going wrong and what might fix it.
You can do better! Full utilization of the workflow I’ve described, based on a solid set of tools, will result in a more balanced approach. You’ll spend less time debugging and much more time writing code that avoids bugs and focuses on improving code quality.
Deferred satisfaction is a required emotion for best practices.
Hold off on implementing the body of your program until your header is stable and your tests are defined.
If we give in to our “base impulse” and simply start writing code, implementing interesting algorithms, we will always struggle to apply best practices. We need to start off on the right foot by preparing for the coding phase. I believe there are four key steps to preparation, shown in Figure 1-3.
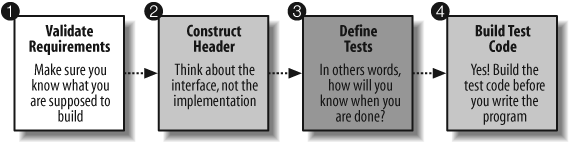
Step 1. Validate program requirements
Sometimes your users give you very little documentation, and other times they overwhelm you with nice-looking documents that contain graphics, charts, and lots and lots of text. In both cases (and everything in between), do not assume that what the users say is right or complete. As I pointed out earlier, your users may not have developed the same ability to think clearly and logically that programmers have. So help them! Use your logical skills to help users identify illogical ideas or gaps in their requirements.
Before you start writing any code, make sure that both you and your users have a clear understanding of what is needed (and why). So ask lots of questions, shine light in the dark corners, and challenge users to make sure that they have thought through all the requirements. Remember too that what users ask for is not always the easiest way to solve a problem. Don’t assume that users have already considered other approaches—and I am not talking only about programming algorithms; I am talking about business processes as well.
Step 2. Implement just the header of the program
OK, at this point let’s assume that you are reasonably confident that your users know what they need and have clearly communicated those requirements to you. Now can you write your program? Yes, but just a little bit of it: only the header of the program and enough to get your program to compile.
At this stage, it’s time to think not about how the program will be implemented (oh, but I really like to come up with clever algorithms!), but instead about:
- What is a good name for the program?
If your name does not accurately represent the purpose of the program, it will mislead anyone who reads your code.
- What are the inputs (IN arguments) and outputs (OUT arguments or RETURN clause, if a function)?
In other words, when you call this program, what information will you need to provide and what will you get back? Come up with good names for those arguments, based on your naming conventions.
- Should the program be overloaded for convenience?
One of the biggest advantages to keeping your code in packages (you are using packages, aren’t you?) is that you can easily implement several different versions of a procedure or function, each having a different signature. For more details on overloading, see Chapter 8.
This may all seem rather obvious to you, but in practice, we find ourselves hurrying through naming and interface decisions, because we are so eager to move on to the “fun” part: problem solving, constructing cool algorithms, and so on. This planning will pay off, however.
Once you are happy with your header, add just enough code to get the program to compile. Usually this means adding a body with NULL; (for procedures) or RETURN NULL; (for functions). At this stage, your program is really nothing more than a stub, an executable placeholder for the program.
Let’s look at an example. Suppose that I need to build a program in my strings toolbox package, tb_strong_utils, that accepts a string and a start and end location, and returns the substring between those two positions. I add this header to my package specification:
PACKAGE tb_string_utils
IS
/* Lots of other, existing programs above. */
/* Return substring between start and end locations */
FUNCTION betwnstr (
string_in IN VARCHAR2
, start_in IN PLS_INTEGER
, end_in IN PLS_INTEGER
)
RETURN VARCHAR2;
END tb_string_utils;Next, I add only the following code to the package body:
PACKAGE BODY tb_string_utils
IS
/* Lots of other, existing programs above. */
/* Return substring between start and end locations */
FUNCTION betwnstr (
string_in IN VARCHAR2
, start_in IN PLS_INTEGER
, end_in IN PLS_INTEGER
)
RETURN VARCHAR2
IS
BEGIN
RETURN 'VALUE UNLIKELY TO BE RETURNED';
END betwnstr;
END tb_string_utils;And that is all the code I will write at this stage. Now it’s time to move on to everyone’s favorite activity—testing!
Step 3. Define the tests that must be run
We won’t start with actual testing at this point. But we should think about the tests that will need to be run on the program to verify that it works. In other words, the question that should consume you at this stage of (pre) development is: how will I know when I am done with this program?
There is a very good chance that many readers of this book are now saying to themselves, “Why would I think about testing now? I haven’t even written my program yet. How would I know what to test?” Ah, that sounds so sensible—or does it? In fact, I believe that this perspective is total nonsense, and a significant contributor to poorly tested code! If you wait until after you write your program to (a) think about testing, (b) write your test code, and (c) run your tests, you will then face these challenges:
- You won’t have enough time to test
It always takes more time than expected to write your code, and deadlines can’t always be shifted. So you will usually end up short-changing the time available to test.
- How will you know when you are done?
In other words, when I say “after you write your program,” I assume you have a way to tell when you are done. Without a clearly defined list of test cases that a program must pass, how will you even know you are finished?
- You will tend to test for success
If you write your tests after you implement your program, you are likely to write your test code in such a way as to show success, even when there are problems. No, I am not accusing you of cheating or intellectual dishonesty of any kind. It’s just how our brains work.
This idea of thinking about and writing down tests before you write your program is known as Test-Driven Development (TDD). Closely associated with Extreme Programming and Agile Software methodology, TDD formalizes this idea of “test first.” For detailed information on TDD, see Chapter 3 and check out www.testdriven.com.
You can write down your test cases in a word-processing document or a spreadsheet, but if you do, the information won’t be connected to your test code or your program. Ideally, you should record test cases within a testing framework or tool. Chapter 3 also contains a list of automated testing tools for PL/SQL.
Don’t worry about thinking up all your test cases in advance. That is much too difficult (even, perhaps, impossible) a task. The most important thing to do when trying out this “test first” approach is to get started. Testing is always very intimidating, and testing before writing code may simply feel wrong until you get used to it. So pick a relatively simple program and start the process with that. Think of just a few test cases, and then proceed through the workflow. You can always add more tests later on.
Step 4. Build your test code
Build test code before the program? Ah, now we are stepping into truly foreign territory! “Fine,” you say:
I will think about what I want to test before I write my program. I imagine that will help with my implementation work anyway. But actually write the test code? Ridiculous! That takes too long, and I don’t really know how to go about it anyway. In any case, why do it now? I don’t even need that test code until I am done writing my code.
Let me analyze and counter each of these objections.
Objection | Counter-objection |
It takes too long. | This is a very valid concern. If you write the test code by hand, you will need days (at least) to complete the task. If, on the other hand, you use a tool to automate the process of writing (generating) your code, it won’t take very long at all. |
I don’t really know how to go about it. | It’s good to be honest about such things, isn’t it? How do you go about writing a program to automatically test another program? It’s not easy stuff. I more or less know how to answer the question because I have built several testing tools and scripts. Most PL/SQL developers, however, will be stumped and frustrated. |
I don’t even need the test code until I am done writing my code. | Yes, this is the way many of us think, and it is so very, fundamentally wrong. You see testing as something that comes after writing code. Instead, you should think about how you can integrate testing into the development process. With your test code in place at the very start, you can run your tests after each small change or added feature. You will get instant feedback on progress (another feature implemented) or setbacks (something that worked an hour ago is broken now). |
No doubt about it: you need help to accomplish this step. The description of testing approaches and tools in Chapter 3 will give you a good start.
Contracts work for the real world; why not software, too?
Match strict input expectations with guaranteed output results.
Problem: What is never discussed is never agreed upon.
Sunita comes late to the weekly team meeting one Friday morning to find Delaware and Lizbeth engaged in a heated discussion over Delaware’s new excuse_in_use utility function. Lizbeth says:
The excuse_in_use Boolean function you wrote sometimes returns null and that makes it a pain to use. I always have to wrap calls to it with NVL and decide—yet again—that NULL=FALSE. Having to worry about null values in computations can really cause trouble in the form of hard-to-catch bugs. Can’t excuse_in_use just return TRUE or FALSE, period?
Delaware counters:
Well, it wouldn’t be such a problem if callers like your customer_support package could be counted on not to pass null excuses into the function. But how am I supposed to know what you want when you hand me a null excuse to test? Since we’ve never discussed it, I figure the best policy for null is to hand out what is handed in, which is to say exactly no information. The program is more robust because it handles more input combinations without failing. It’s called defensive programming.
Sunita breaks in to put a stop to the bickering:
You are both arguing plenty, but communicating very little. Delaware, defensive programming is a fine approach when the potential callers of a module are unknown or otherwise unpredictable, but Lizbeth sits in the cube right next to you! Maybe we should defend less and cooperate more by coming up with some clear agreements about how our code should behave.
They look over Delaware’s code, which tracks excuses using a package-private collection indexed by the excuse strings:
PACKAGE BODY excuse_tracker
IS
TYPE used_aat IS TABLE OF BOOLEAN INDEX BY excuse_excuse_t;
g_excuses_used used_aat;
FUNCTION excuse_in_use (excuse_in IN excuse_excuse_t)
RETURN BOOLEAN
IS
BEGIN
IF excuse_in IS NULL
THEN
RETURN null;
ELSE
RETURN g_excuses_used.EXISTS (excuse_in);
END IF;
END excuse_in_use;
...other programs...
END excuse_tracker;Sunita goes on:
In this case, Lizbeth does not want Delaware’s excuse_in_use function to ever return a null value instead of a proper Boolean, and similarly, Delaware does not want Lizbeth’s program to call his function with a null value for its input argument. So let’s just satisfy both of them by requiring Delaware’s function to only return TRUE or FALSE, but only under the obligation that Lizbeth’s code does not pass in a null value. In fact, this is a very good rule in general for all Boolean functions, and we should probably always follow it.
Solution: Contracts capture agreements.
“I propose that we make a pact, or contract, with one another that this is how our Boolean functions will always behave,” Sunita continues. “If we all agree to and stick by this contract, then there will never be any question what to expect of these functions, nor what is required to use them.” The team solemnly swears (with a giggle here and there) to always both require and produce non-null data for Boolean functions. The contract is given a name: {NOT NULL IN, NOT NULL OUT} or NNINNO.
Tip
This contract is offered as a best practice in Chapter 8 in the section "Black or white programs don’t know from NULL..”
Just for kicks, Sunita writes up their agreement as a fancy-looking contract and tapes it to the wall of the meeting room. It’s the team’s first contract—simple, yet very important. And by taking this first step, they are starting down a path of implementing a powerful coding pattern as a best practice for the whole group.
About Design by Contract.
The team doesn’t realize it, but Sunita is introducing them to a software engineering paradigm called Design by Contract. The basic idea behind Design by Contract is to express and enforce agreements about software program behavior using the analogy of legal contracts from the domain of human affairs. Each party to a legal contract has both obligations and expected benefits under the contract. In software, the parties to a contract are a given program and its callers. The callers are expected to provide valid inputs to the program whenever they call it; if they do not, they have violated the contract. Similarly, the program is expected to guarantee correct output as long as the inputs are valid; if it does not, it has violated the contract. The program is not even required to execute when inputs are invalid.
In Design by Contract, contract elements are formally expressed as either preconditions or postconditions:
- Preconditions
These capture what must be true upon entry to the program. In practice, these are often rules governing the acceptable input parameter values. Preconditions are an obligation of the caller and a benefit to the program, since the program code can count on the preconditions being true. In our example, Delaware’s code benefits from the contract agreement that null inputs are not acceptable, since it does not need to specify a special case for null.
- Postconditions
These capture what must be true upon exit of the program. They represent the fundamental obligation of the program to compute some well-defined result based on the preconditions having been met. Postconditions are an obligation for the program and a benefit to callers of the program. In our example, Lizbeth’s code benefits when excuse_in_use agrees never to return a null value.
For more information about applying the Design by Contract paradigm to PL/SQL programming, see the link from the book’s web site.
Enforcing contracts in code.
Let’s see what enforcing our NNINNO contract might look like in code,” says Sunita. She rewrites Delaware’s excuse_in_use program using contract-oriented principles:
FUNCTION excuse_in_use (excuse_in IN excuse_excuse_t)
RETURN BOOLEAN
IS
c_progname CONSTANT progname_t:='EXCUSE_IN_USE';
l_return BOOLEAN;
BEGIN
-- check caller obligations
assert_precondition(condition_in => excuse_in is not null
,progname_in => c_progname
,msg_in => 'excuse_in not null');
-- compute return value
l_return := g_excuses_used.EXISTS (excuse_in);
-- check return obligations
assert_postcondition(condition_in => l_return is not null
,progname_in => c_progname
,msg_in => 'l_return not null');
RETURN l_return;
END excuse_in_use;The team members all look over the code while Sunita explains the purpose of each line:
First, we declare a constant self-identification token c_progname that is passed to the contract-enforcing assertion programs. This is an invaluable debugging aid when the ASSERTFAIL exception signals a contract violation, as we’ll see later.
Next, since the program is a function, it declares a local variable of the return datatype and returns that variable in exactly one place: the very last line of the function. This enables the postcondition to be tested in a single well-defined place (i.e., immediately before the return). See Chapter 8 in the section "One way in, one way out: multiple exits confuse me..”
The program makes use of two special assertion programs: one for testing preconditions and the other for testing postconditions.
The program checks precondition requirements as the first executable instructions of the main body of code. Under the contract, if precondition requirements are not met, then the program should not continue and instead should raise the ASSERTFAIL exception.
The program actually computes the return value and assigns it to the local variable reserved for that purpose.
Finally, the postcondition is checked immediately prior to the RETURN statement. In our example, this check may seem trivial and therefore unnecessary since we know that EXISTS always returns TRUE or FALSE and never null. However, consider that if a new or alternate implementation of excuse_in_use is someday created, we may want to replace the logic in this program with a call to the new program; at that point, we may not be so certain about whether l_return can be NULL or not.
Sunita continues:
So, Lizbeth, with this new implementation you don’t have to worry about getting NULL back from the function and can dispense with all those ugly NVLs in your code. However, your code must always supply non-NULL excuses to the function, or the contract precondition is violated and it is your code at fault. Let’s see what will happen in that case, so you know what to expect if you violate your contract.
To test the contractual obligations in the excuse_tracker package, Sunita has Jasper write this simple “driver” procedure:
PROCEDURE try_excuse_in_use (excuse_in IN VARCHAR2)
IS
BEGIN
IF excuse_tracker.excuse_in_use (excuse_in)
THEN
DBMS_OUTPUT.put_line ('Excuse in use: "' || excuse_in || '"');
ELSE
DBMS_OUTPUT.put_line ('Excuse not in use: "' || excuse_in || '"');
END IF;
END try_excuse_in_use;And then they give it a try by running this anonymous block:
SQL>SET SERVEROUTPUT ON FORMAT WRAPPEDSQL>BEGIN2try_excuse_in_use ('lame excuse');3try_excuse_in_use (NULL);4END;5/Excuse not in use: "lame excuse" BEGIN * ERROR at line 1: ORA-20999: ASSERTFAIL:EXCUSE_TRACKER:EXCUSE_IN_USE:PRE:excuse_in not null ORA-06512: at "HR.EXCUSE_TRACKER", line 68 ORA-06512: at "HR.EXCUSE_TRACKER", line 95 ORA-06512: at "HR.EXCUSE_TRACKER", line 36 ORA-06512: at "HR.TRY_EXCUSE_IN_USE", line 4 ORA-06512: at line 3
Sunita then points out the key aspects of this contracting exercise and the debugging information exposed by the error message sent back to the caller of excuse_tracker.excuse_in_use:
The ASSERTFAIL exception is reserved for signaling contract violations. Nothing else raises that exception in the application. By definition, contract violations are always bugs. So this exception tells the team unambiguously that there is a bug in the code.
The contract violation was detected by the excuse_in_use program of the excuse_tracker package. Thus, the assertion routine tells the team exactly where the contract was violated.
The contract element violated was a precondition and therefore the bug is in the calling code. Thus the assertion routine and the unhandled exception stack tell the team exactly where to look to resolve the problem: line 4 of try_excuse_in_use.
The specific contract condition violated is that the excuse_in parameter value is required to be non-NULL.
Delaware fusses a bit, concerned about writing all the extra code for precondition and postcondition checks, but Lizbeth counters by reminding him about all the time that will be saved by getting such clear and accurate information about misuse of program units. Sunita beams at the level of communication between her team members, but she doesn’t deceive herself that everyone is now 100 percent on board with contract-driven programming. She calls the meeting to a close with a short speech:
I think we can all agree that our contract helped clear up the ambiguity around (and simplify the code needed to run) this function. I strongly suggest that you apply these ideas to your next several programs, and then let’s meet and discuss how it has gone. I’m sure you will run into rough spots and issues; the best way to address them is as a team.
Don’t act like a bird: admit weakness and ignorance.
Ask for help (or at least take a break) after 30 minutes on a problem.
Problem: Steven is a hypocritical programmer.
I spend a lot of my time in public talking about best practices. In other words, I stand up in front of other developers and act “holier than thou,” offering advice and admonitions along the lines of “Do this, don’t do that, and certainly never do the other thing.”
Occasionally, I am honest enough to point out that I do not always follow all my best practices. And students in my classes are, not infrequently, delighted to point out violations of best practices in my own code as I show it up on the big screen.
I do think that lots of my code is at least reasonably well written. Sometimes, though, the way that I ignore my own recommendations is so over the top and painful that my hypocrisy is brought to the fore. Along these lines, I feel compelled to make a confession. Back in June 2007, I was in Europe presenting the Quest Code Tester product to developers, DBAs, and managers in Paris, Brussels, and Maidenhead (U.K.). When not in the public eye, I kept myself very busy debugging some of Quest Code Tester’s backend code (on which I am the lead developer) as well as working on the second edition of Oracle PL/SQL Best Practices for O’Reilly (the book you are now reading).
Now, as I’m sure you all know, debugging code can be a frustrating and time-consuming adventure (even if you take advantage of Toad’s great source code debugger). And that brings me to the source of my hypocrisy. On June 13, I sat in my room at the Holiday Inn in Maidenhead from 7 P.M. to midnight putting dents in the desk with my head. My problem? In Quest Code Tester, you can define dynamic test cases based on predefined groups of values or values retrieved via a query from a test data table. That wasn’t the problem—in fact, that is a great feature. Unfortunately, the results of these tests (generated at test time) were not rolling up properly when the program being tested raised an unhandled exception. In other words, they were showing success when they should have shown failure, and vice-versa.
No doubt about it: the code that performed the rollup was complicated stuff, made more challenging by my reliance on a three-level, string-indexed, nested collection structure. Those things are not at all easy to debug. My debugging adventure also turned into one of those scenarios in which, as you fix one bug, you realize that the code you thought was working by design was actually working by accident. That is, bugs that were previously being masked were now exposed by other fixes. Wow, software can be incredibly complex!
So, I would fix one bug and then find others, fix those, and then . . . it was 10 P.M. and I started to encounter behavior (duplicate result rows with different outcomes) that I simply could not explain. So I struggled for two more hours, eyes tired, back sore, thirsty, and increasingly angry, until I gave up and went to bed.
Solution: Give your brain a break, and ask others for help.
I woke up, six hours later, with an idea hopping around excitedly in my head: I could suddenly and very clearly see why I was getting duplicates and where the problem must be occurring in my code. I hurried to my laptop (easy: it was four feet away) and 10 minutes later confirmed my analysis. I fixed that bug, found another, analyzed it, and fixed it. After 30 minutes, my code was working for all known test scenarios.
I sat back in my chair, a little bit stunned—excited, sure, at having found the solution, but also thoroughly disgusted at myself for wasting so much time the night before. How could I have done that? I knew better. But more than that, I regularly preached better. What a hypocrite!
So, this is what I learned (or was so painfully reminded of) from my terrible, horrible, no good, very bad[2] evening with the qu_result_xp package (and other similar experiences):
- Apply the Thirty Minute Rule rigorously
This rule really does work. Do not spend hours banging your head against the wall of your code. Ask for help. If your manager has not set up a process or fostered a culture that says it’s OK to admit ignorance, you will have to do it yourself. This is especially important if you are (or are seen as) a senior developer on your team. Go to one of your junior team members and ask for help. They will be flattered, their self-esteem will increase, and they will help you to solve your problem.
- Get help from anyone handy
If you are stuck and cannot turn to another programmer for help, then ask a nonprogrammer for a sympathetic ear. My friend and Quest Code Tester codeveloper, Leonid, told me that he used to ask his grandmother (not known for her programming skills) to listen to him talk about his work. Externalizing your thoughts, even to someone ignorant of the content, helps you organize and clarify them.
- Take a break
If you are stuck and alone and cannot turn to another programmer—or any other human being—then STOP! Take a break. Get away from your work. Best alternative: get some exercise. Move your body. Go out for a walk or a run. Jump up and down, stretch, do sit-ups. Let your brain relax and make its connections—suddenly, as if by a miracle, that incredible brain of yours will start working on a solution! And when you come back from your break, try talking out loud to yourself, describing the problem. Or take out a piece of paper and write it down. The key thing is to get it outside of your head. You will then find it easier to visualize the problem and the solution.
- Watch out for irrationality
You will know that you are past the point of productive work when you find yourself thinking in less than rational ways. I can still remember back in 1992 when I was building a debugger for SQL*Forms 3 on Oracle’s brand-new PC implementation (the first software to use memory above the 640K limit!). I started to get runtime errors, and I discovered that if I added a tab character to the code, the location of the error would change. I sat there for hours trying to find the source of the problem (typing in extra spaces, returns, etc.), when OBVIOUSLY it was a bug down deep in Oracle. PL/SQL does not care about whitespace. When you find yourself saying “What my program is doing is impossible and makes no sense,” you really should stop and take a break.
Team leaders and development managers have a special responsibility to cultivate an environment in which we are encouraged to admit what we do not know, and to ask for help sooner rather than later. Ignorance isn’t a problem unless it is hidden from view. And by asking for help, you also validate the knowledge and experience of others, building the overall self-esteem and confidence of the team.
To be very honest with you, I don’t think I am all that great a programmer. I have a quick mind and am good at communicating ideas. But I need lots more discipline and patience as I write my code. And I need to apply my (and others') best practices more regularly and thoroughly.
So remember: do as I say, not as I do!
Five heads are better than one.
Review and walk through one another’s code; then do automated code reviews.
Problem: Sunita spent six months developing comprehensive coding standards for her group.
Huh? That’s a problem? Well, not in and of itself. The problem with what Sunita did is that she produced a rather thick document (50 pages of top-notch ideas and advice), made copies, and distributed it to everyone on the team. She then assumed that the team members would diligently follow the coding standards, so she turned her attention to other pressing matters. Months went by, and Lizbeth, Delaware, and Jasper wrote lots of code in their separate cubicles, pushing hard to meet deadlines.
A few weeks before it is time to deliver the application to users, Sunita finds that she has a couple of days free from the burdens of management tasks (paperwork, for the most part). So she decides to get in touch with the code base, both to refresh her familiarity with PL/SQL and to get a comfort level about the application-specific algorithms.
She opens up a package body and starts reading through the code. As she does so, she finds herself bothered by ... something ... she can’t quite put her finger on it, and then she realizes what it is: this code is not following the standards she defined months before! Names of variables, program comment header blocks, exception handling: none of it looks anything like the standard.
“Well,” she thinks, “that package was written by Delaware.” (She has always had her doubts about whether he would accept her ideas.) “Let’s check Lizbeth’s code.”
So she opens another file and is immediately pleased. Lizbeth’s code looks completely different from Delaware’s. Finally, someone is following the standards! But on closer review, her sunny feelings turn to despair. It’s true that Lizbeth’s code is noticeably different from Delaware’s, but she isn’t following the group standard, either! Instead, she has her own naming conventions and her own approach to exception handling.
Sunita calls a meeting and asks everyone what the heck is going on. There are lots of downcast eyes and clearing of throats. “Well?” Sunita demands, “What did you do with those coding standards I put together?” It turns out that those 50-page tomes were placed in desk drawers and never looked at again.
Solution: Move beyond documents to a review process that directly engages the development team.
Sunita had the correct idea: it is crucial for everyone on a development team to write code more or less the same way (Chapter 2 offers a number of specific recommendations for what that “same way” should look like). But she was incredibly naïve to think that simply writing a document and circulating it would result in those standards being followed.
The only way to ensure that standards are followed is to review (look at, read, walk through) the code that has been written. Sunita’s big mistake was that she hadn’t formalized a review process—such a review would have caught problems early in the process.
Code review involves having other developers actually read and review your source code. This review process can take many different forms, including:
- The buddy system
Each programmer is assigned another programmer to be ready at any time to look at his buddy’s code and to offer feedback.
- Formal code walkthroughs
On a regular basis (and certainly as a “gate” before any program moves to production status), a developer presents or “walks through” her code before a group of programmers.
- Pair programming
No one codes alone! Whenever you write software, you do it in pairs, where one person handles the tactical work (thinks about the specific code to be written and does the typing), while the second person takes the strategic role (keeps an eye on the overall architecture, looks out for possible bugs, and generally critiques—always constructively). Pair programming is an integral part of Extreme Programming.
Consistent code review results in dramatic improvements in overall code quality. The architecture of the application tends to be sounder, and the number of bugs in production code goes way down. A further advantage is that expertise on the development team is more broadly and evenly spread, as everyone learns from everyone else.
To make this process work, the development manager or team leader must take the initiative to set up the code review process and must give developers the time (and training) to do it right. Ideally, the most experienced and self-confident developer should go first, to demonstrate that there is nothing wrong with being wrong, with making mistakes and having them pointed out.
Code review should not, however, be seen simply (or primarily) as an enforcement mechanism for standards. Code review is an excellent way of sharing knowledge and ideas, as well as strengthening the sense (and reality) of teamwork.
Resources
Use the tools and books listed below to help you set up peer (manual) and automated reviews:
- Automated code analysis and review options
Toad and SQL Navigator from Quest Software offer CodeXpert, the most powerful automated process for reviewing code. PL/SQL Developer also provides integrated “lint checking” of some of the most common programming mistakes.
- Handbook of Walkthroughs, Inspections, and Technical Reviews (Dorset House)
This book, by Daniel Freedman and Gerald M. Weinberg, is now in its third edition. It uses a question-and-answer format to show you exactly how to implement reviews for all sorts of product and software development.
- Extreme Programming Explained (Addison-Wesley)
This first book on Extreme Programming, by Kent Beck, offers many insights into pair programming.
Don’t write code that a machine could write for you instead.
Generate code whenever possible.
Problem: Jasper is starting to feel more like a robot than a human being.
Lately, it seems to Jasper that he isn’t using a single ounce of creativity in his brain. Instead, he finds himself relying on copy-paste-and-change to write his programs. The latest frustration in this area arises when Sunita announces that she wants him to write functions to return single rows of data from key tables for a given primary key value. He writes this one first:
FUNCTION excuse_for (id_in IN mfe_excuses.id%TYPE)
RETURN mfe_excuses%ROWTYPE
IS
retval mfe_excuses%ROWTYPE;
BEGIN
SELECT * INTO retval
FROM mfe_excuses
WHERE id = id_in;
RETURN retval;
END excuse_for;Then he has to do the same thing for customers, so he copies and pastes, changes the names of the tables, and ends up with this:
FUNCTION customer_for (id_in IN mfe_customers.id%TYPE)
RETURN mfe_customers%ROWTYPE
IS
retval mfe_customers%ROWTYPE;
BEGIN
SELECT * INTO retval
FROM mfe_customers
WHERE id = id_in;
RETURN retval;
END excuse_for;Unfortunately, he now has another 25 tables for which he needs to build these functions. How boring! But he does it, with every fiber of his soul rebelling, and finally he is done.
Then he shows the code to Sunita, who says, “What if the query raises TOO_MANY_ROWS? Don’t we want to log that error? It certainly would be good to know about any violations of our primary keys!”
Holding back a scream, Jasper forces himself to nod, writes the exception section, and then does a copy-and-paste 25 more times. And all he can think about as he is doing this is, “What a terrible way to spend my time!”
Solution: If you can recognize a pattern in what you are writing, generate code from that pattern.
Life is short—and way too much of it is consumed by time spent in front of a computer screen, moving digits with varying accuracy over the keyboard. It seems to me that we should be aggressive about finding ways to build our applications with an absolute minimum of time and effort while still producing quality goods. A key component of such a strategy is code generation: rather than write the code yourself, you let some other piece of software write the code for you.
Code generation comes in particularly handy when you have to write code that is repetitive in structure (i.e., it can be expressed generally by a pattern). There is, for example, a clear pattern to the code that Jasper was writing; that’s why, in fact, he could “get away with” using copy-and-paste to build the code.
Jasper had the right idea: he got angry with the wasting of his time. Programmers should have a very low tolerance for that sort of thing. Jasper’s problem is that he didn’t take action to avoid the wasting of his time. Let’s take a look at what he could have done instead.
When Jasper realized that he was writing the same code over and over again, with minor changes, he should have asked himself, “Which part is changing?” He would then have seen (one would hope) that the table name and the primary key column name were the only dynamic parts of the pattern. Everything else stayed the same. From that basic insight, he could then write a program like this genlookup procedure:
PROCEDURE genlookup (tab_in IN VARCHAR2, col_in IN VARCHAR2)
IS
BEGIN
DBMS_OUTPUT.put_line ('CREATE OR REPLACE FUNCTION ' || tab_in
|| '_row_for (' );
DBMS_OUTPUT.put_line ( ' ' || col_in|| '_in IN ' || tab_in
|| '.' || col_in || '%TYPE)' );
DBMS_OUTPUT.put_line (' RETURN ' || tab_in || '%ROWTYPE');
DBMS_OUTPUT.put_line ('IS');
DBMS_OUTPUT.put_line (' l_return ' || tab_in || '%ROWTYPE;');
DBMS_OUTPUT.put_line ('BEGIN');
DBMS_OUTPUT.put_line (' SELECT * INTO l_return FROM ' || tab_in);
DBMS_OUTPUT.put_line (' WHERE ' || col_in || ' = ' || col_in ||
'_in;');
DBMS_OUTPUT.put_line (' RETURN l_return;');
DBMS_OUTPUT.put_line ('EXCEPTION');
DBMS_OUTPUT.put_line (' WHEN NO_DATA_FOUND THEN');
DBMS_OUTPUT.put_line (' l_return.' || col_in
|| ' := NULL; RETURN l_return;');
DBMS_OUTPUT.put_line (' WHEN OTHERS THEN mfe_error.log_error;');
DBMS_OUTPUT.put_line ('END ' || tab_in || '_row_for;');
DBMS_OUTPUT.put_line ('/');
END;And then he could write a “driver” for this procedure that queries the table and its primary key column from the Oracle data dictionary constraint views, as follows:
BEGIN
FOR l_mfe_table IN (SELECT ccol.table_name, ccol.column_name pkycol_name
FROM user_constraints cons, user_cons_columns ccol
WHERE cons.owner = ccol.owner
AND cons.constraint_name = ccol.constraint_name
AND cons.table_name LIKE '%EMP%'
AND cons.constraint_type = 'P')
LOOP
genlookup (l_mfe_table.table_name, l_mfe_table.pkycol_name);
END LOOP;
END;Once this code is in place, whenever anyone has an idea for fixing or improving these one-row lookup functions in the future, Jasper will simply run the driver block, and all the code will be regenerated. And if a new table is added, Jasper won’t have to do anything except run the script to generate the code.
Now that is a whole lot better than taking a risk with repetitive stress injury (RSI) through copy-and-paste keystrokes! By the way, both of the above blocks of code may be found in the genlookup.sp file available on the book’s web site.
I am a great believer in identifying patterns in our requirements and tasks, and then generating code to complete those tasks. My beliefs in this area are so passionate, in fact, that I have created a tool specifically to allow me (and you!) to translate abstract patterns into templates and then generate code from those templates. This freeware tool, called the Quest CodeGen Utility, is provided by Quest Software and is available at www.qcgu.net. If you are allergic to wasting your time and performing repetitive tasks, you will definitely want to download and check out this product. It comes with hundreds of predefined templates and also allows you to build your own via the tool’s Code Generation Markup Language (CGML).
Finally, if you read this section and find yourself thinking, “Gee, I don’t see all that many patterns in the code I’ve been writing,” then you may need to strengthen your pattern-recognition skills. An excellent way to get better at recognizing patterns (and have fun while you are doing it) is to play the game of Set (www.setgame.com).
We need more than brains to write software.
Take care of your “host body”: fingers, wrists, back, etc.
Science fiction is an awful lot of fun to read in books and watch in the movies. It’s amazing what computers and cyborgs and so on can accomplish when they are not constrained by the economic and technical realities encountered on Planet Earth.
Well, we not only live in the real world, we write software that attempts to mimic within cyberspace a small fraction of that real world. And since the real world is always changing, there is always great pressure on us and our applications to “keep up.” That results in great job security, but also tremendous challenges.
One fundamental reality we must keep in mind as we explore best practices for writing software is that our programs are written almost entirely by us, human beings. Sure, we can and should take advantage of the code-generation tools discussed earlier, but for the most part, software development doesn’t happen without our sitting in front of a screen and typing. The ramifications of this simple, undeniable fact are far-reaching:
The software we write and how we go about writing it are affected greatly by the physiology (hard-wiring) of our brains, and the psychology of humans as we interact with one another and our environment.
Our brains can handle only so much complexity at a time (though we certainly can train our gray matter to juggle larger and larger volumes of data and structures). We need to find ways to organize our activity so that we don’t get overwhelmed, confused, and lost.
We are lucky that we are able to make a living off the product of our brains. Our brains need our host bodies in order to function, so we need to make sure we take care of those hosts. Humans didn’t evolve in order to sit in front of a monitor 6, 8, or 10 hours a day.
Here are my top recommendations for taking care of your host body. You can think of these as best practices for you, rather than your code:
- Drink lots of water
You probably hear this advice a lot. Without a doubt, you will generally be much healthier if you drink more water and less coffee, Coke, and other caffeinated, sugared products. But specifically when it comes to brain work, if you get dehydrated, it’s like a car engine without enough oil. Your brain gets sluggish and dull. Here is my concrete suggestion: the next time you come back from a heavy lunch and find yourself nodding off at your desk, do not get a cup of coffee. Do not refill your cup with soda. Instead, drink down a large glass of water. You will immediately feel more awake, alive, and ready to take on your challenges.
- Take lots of breaks, move around, get exercise, and go outside
If your body becomes too sedentary, it will be hard for your brain to stay focused. Plus, if you don’t move around, various parts of your body will start to decay and hurt. It’s a basic case of “Use it or lose it.” Of course, it’s hard to think about any sort of vigorous exercise routine if your lower back hurts and your knees are cracking. So start simple: do some sit-ups every day. You can do these without any special equipment, and as your abdomen gets stronger, your back will feel better. You will sit up straighter. You will feel better about yourself. Finally, spend as much time as you can out of doors. Indoor air is usually stale, recycled, and unhealthy. And if you go outside, you might even feel the sun on your face. Small joys!
- Make sure your workspace is comfortable and ergonomic
Don’t compromise mobility or range of motion for the sake of a few programs. I strongly recommend that you buy an ergonomic keyboard like Microsoft’s Natural Keyboard. It will greatly reduce the strain on your wrists; believe me, you will adjust to its different key configuration in a matter of an hour. Make sure that your monitor, chair, and desk are properly aligned so you do not feel stress in your shoulders, neck, back, arms, or hands as you type. Don’t rest your hands or wrists directly on hard desk surfaces. I recently discovered the IMAK wrist glove and now use it whenever I am away from my home office. It provides great support and comfort for my wrist.
Writing software is lots of fun, but remember to keep it in perspective: it’s not worth sacrificing your physical health to write lots of exciting, cool code. Keep in mind, as well, that tradeoffs of this kind are totally unnecessary.
[2] * I draw that phrase from my days of reading books to my son, Eli. It’s a reference to the book Alexander and the Terrible, Horrible, No Good, Very Bad Day by Judith Viorst. If you have small children and are not already familiar with this book, I recommend that you get it.
Get Oracle PL/SQL Best Practices, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

