Oracle’s SQL*Loader utility loads data into Oracle tables from external files. With some restrictions, SQL*Loader supports the loading of data in parallel. If you have a large amount of data to load, SQL*Loader’s parallel support can dramatically reduce the elapsed time needed to perform that load.
SQL*Loader supports parallel loading by allowing you to initiate multiple concurrent direct path load sessions that all load data into the same table or into the same partition of a partitioned table. Unlike the case when you execute a SQL statement in parallel, the task of dividing up the work falls on your shoulders. Follow these steps to use parallel data loading:
Create multiple input datafiles.
Create a SQL*Loader control file for each input datafile.
Initiate multiple SQL*Loader sessions, one for each control file and datafile pair.
When you initiate the SQL*Loader sessions, you must tell SQL*Loader that you are performing a parallel load. You do that by adding the PARALLEL=TRUE parameter to the SQL*Loader command line. For example, the following commands could be used to initiate a load performed in parallel by four different sessions:
SQLLOAD scott/tiger CONTROL=part1.ctl DIRECT=TRUE PARALLEL=TRUE SQLLOAD scott/tiger CONTROL=part2.ctl DIRECT=TRUE PARALLEL=TRUE SQLLOAD scott/tiger CONTROL=part3.ctl DIRECT=TRUE PARALLEL=TRUE SQLLOAD scott/tiger CONTROL=part4.ctl DIRECT=TRUE PARALLEL=TRUE
Note that the commands here should be executed from four different operating system sessions. The intent is to get four SQL*Loader sessions going at once, not to run four sessions one at a time. For example, if you are using the Unix operating system, you might open four command-prompt windows and execute one SQL*Loader command in each window.
Another important thing to note here is that you need to use the direct path in order to perform a load in parallel, as explained in the next section. This is achieved by the command-line argument DIRECT=TRUE. Parallel loads are not possible using the conventional path option.
Parallel loads must be done using the direct path. When you initiate a direct path load, SQL*Loader formats the input data into Oracle data blocks and writes those blocks directly to the datafiles. The blocks are always added above the target table’s high-water mark (HWM). Direct path loads bypass SQL command processing, and they bypass the database buffer cache in the SGA. The result is much higher performance than you can get using a conventional path load.
Each parallel load session inserts into the table by allocating one or more new extents, as illustrated in Figure 4.1.
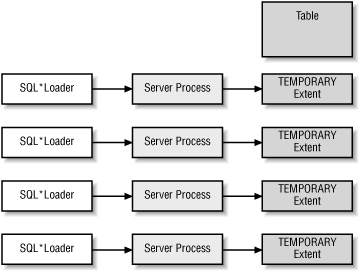
The extents used by SQL*Loader are marked as TEMPORARY during the load process. After the loading is complete, the last loaded extent from each parallel load process is trimmed to release any free space. Then the extents are added to the existing segment of the table or partition above the high-water mark. The HWM is then adjusted to reflect the added data. You need to consider two important issues with respect to parallel data loading:
Free space below the high-water mark will not be used.
A table’s initial extent can never be used.
Parallel direct path loads do not use any space below the high-water mark. Therefore, if you have significant unused space below the HWM prior to loading, you should consider rebuilding the table in order to reset the HWM before you start the load.
Parallel direct path loads insert data into new extents and do not use any existing extents. Therefore, the initial extent of a table can never be used by a parallel load. If all the data in a table is to come from parallel loads, you should create a very small initial extent in order to conserve disk space. If you feel that you must use the space in the initial extent, you’ll have to load the data into the table without using SQL*Loader’s parallel feature.
Parallel direct path loading significantly improves data loading performance. However, that performance improvement comes with a price. The following restrictions apply to parallel direct path loads:
Indexes are not maintained when a parallel direct path load is performed. You will need to rebuild all indexes on the table being loaded after the load is complete.
There is no communication between the concurrent load sessions. Therefore, you can only append rows to a table. The TRUNCATE, REPLACE, and INSERT options of SQL*Loader cannot be used for a parallel direct path load.
All referential integrity and CHECK constraints on the table being loaded must be disabled for the duration of the load.
All triggers on the table being loaded must be disabled for the duration of the load.
Since parallel data loading uses the direct path, all the restrictions of a direct path load also apply to parallel loads. For example, you can’t use direct path loads on clustered tables. Also, the table being loaded must not be involved in any active transactions. For more information on direct path load and its restrictions, please refer to Oracle Corporation’s Oracle8 Utilities manual.
There are several things you can do to improve the performance of a parallel load. Consider doing the following:
Spreading the table to be loaded across multiple disk drives
Using SQL*Loader’s UNRECOVERABLE option
I/O bottlenecks are a prime source of performance degradation. Spreading the data to be loaded across multiple disk drives reduces I/O contention between the load processes and helps ensure that the load process is not limited by the throughput of a single disk. First, you must have multiple datafiles for your table, and these datafiles must be on separate disks. Then you can specify a database filename using the FILE keyword of the OPTIONS clause in the SQL*Loader control file. Note the fourth line in this example:
LOAD DATA INFILE 'load1.dat' INSERT INTO TABLE emp OPTIONS (FILE='/u06/oradata/TPRD/data1.dbf') (empno POSITION(01:04) INTEGER EXTERNAL NULLIF empno=BLANKS ...
SQL*Loader then will allocate the extents for each load session in the datafile specified. To maximize throughput, make sure that the control file for each SQL*Loader session specifies a different datafile.
You can specify the UNRECOVERABLE option for the SQL*Loader sessions involved in a parallel load to avoid the generation of redo for that load. This saves a lot of time and redo log space. However, it also makes the table unrecoverable in the event of a media failure. For this reason, you should back up the tables that were loaded after the load completes.
Get Oracle Parallel Processing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

