Most modern commercial DBMS products have implemented parallel features, and Oracle is no exception. With every release, Oracle has consistently improved its support for parallel processing. Oracle’s support for parallel processing can be divided into the following two specific feature sets:
As you delve into Oracle’s parallel feature set, you’ll encounter several very similar terms that all begin with the word “parallel.” Read through the following definitions; they will help you understand these terms before you read further:
- Parallel Server
The same as Oracle Parallel Server.
- Parallel execution
Refers to Oracle’s ability to apply multiple CPUs to the task of executing a single SQL statement in order to complete execution faster than would be possible using only a single CPU.
- Parallel Query
Refers to Oracle’s ability to execute SELECT statements in parallel, using multiple CPUs. When parallel features first were introduced into Oracle years ago, the only support was for parallel SELECT statements, and at that point the feature was known as Parallel Query and was available through the Parallel Query Option (PQO). Now, Parallel Query is only a subset of Oracle’s parallel execution features.
Oracle’s parallel execution features enable Oracle to divide a task among multiple processes in order to complete the task faster. This allows Oracle to take advantage of multiple CPUs on a machine. The parallel processes acting on behalf of a single task are called parallel slave processes . Parallel execution features first were introduced in Oracle Version 7.1 in the form of the Parallel Query Option, which supported only parallel SELECT statements. Since then many new functions have been added. In Oracle7, support for parallel execution was a separately installed option. However, in Oracle8 and Oracle8i, it is embedded into the Oracle RDBMS product.
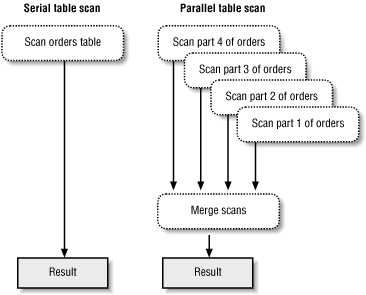
Let’s look at a simple example that illustrates how parallel execution works in Oracle. The following SQL statement counts the number of orders in the orders table:
SQL> SELECT COUNT(*) FROM orders;
When you execute this statement serially—that is, without using any parallel execution features—a single process scans the orders table and counts the number of rows. However, if you had a four-processor machine and used Oracle’s parallel execution features, the orders table would be split into four parts. A process would be started on each CPU, and the four parts of the table would be scanned simultaneously. The results of each of the four processes then would be merged to arrive at the total count. Figure 1.6 illustrates this situation.
Oracle’s parallel execution support extends far beyond simply executing SELECT statements in parallel. The full range of features includes all of the following:
- Parallel Query
Large queries (SELECT statements) can be split into smaller tasks and executed in parallel by multiple slave processes in order to reduce the overall elapsed time. The task of scanning a large table, for example, can be performed in parallel by multiple slave processes. Each process scans a part of the table, and the results are merged together at the end. Oracle’s parallel query feature can significantly improve the performance of large queries and is very useful in decision support applications, as well as in other environments with large reporting requirements.
- Parallel DML
In addition to SELECT statements, Oracle can execute DML operations such as INSERT, UPDATE, and DELETE in parallel. There are some restrictions on this capability, however. UPDATE and DELETE operations can be parallelized only on partitioned tables. INSERT INTO . . . SELECT . . . FROM statements can be parallelized for nonpartitioned as well as partitioned tables. Parallel DML is particularly advantageous in data warehouse environments that maintain summary and historical tables. The time needed to rebuild or otherwise maintain these tables is reduced because the work can be done in parallel. Parallel DML also is useful in OLTP systems to improve the performance of long-running batch jobs.
- Parallel DDL
Oracle now has the ability to parallelize table and index creation. Statements such as the following can be parallelized:
CREATE TABLE...AS SELECT...FROM CREATE INDEX ALTER INDEX REBUILD
Data warehouse applications frequently require summary and temporary tables to be built, and the parallel object creation feature can be very useful in performing such tasks. OLTP applications can use this feature to rebuild indexes at regular intervals in order to keep those indexes efficient.
- Parallel data loading
Bulk data loading can be parallelized by splitting the input data into multiple files and running multiple SQL*Loader sessions simultaneously to load data into a table. Loading large amounts of data in bulk is a necessary requirement of all data warehouse applications, and Oracle’s parallel loading feature can greatly reduce the time needed to load that data.
- Parallel recovery
Oracle’s parallel recovery feature can reduce the time needed for instance and media recovery. With parallel recovery, multiple parallel slave processes will be used to perform recovery operations. The system monitor (SMON) background process reads the redo log files, and the parallel slave processes apply the changes to the datafiles. Recovery of a large database takes a significant amount of time, and parallel recovery can be used to reduce that time.
- Parallel replication propagation
If you are using replication to maintain copies of database objects in multiple databases, you can use parallel propagation to update those copies efficiently. Changes made in one database can be propagated to another database using multiple slave processes to speed up the propagation.
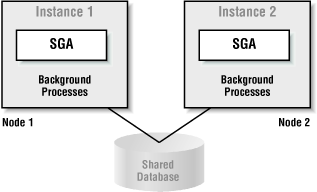
Oracle Parallel Server (OPS) enables one database to be mounted and opened concurrently by multiple instances. Each OPS instance is like any standalone Oracle instance and runs on a separate node having its own CPU and memory. The database resides on a disk subsystem shared by all nodes. OPS takes parallelism to a higher plane by allowing you to spread work not only over multiple CPUs, but also over multiple nodes. OPS offers many more advantages that we’ll explain later in this section.
Figure 1.7 illustrates an OPS database comprised of two nodes. Each node runs one Oracle instance. Each instance has its own set of background processes and its own System Global Area (SGA). Both of the instances mount and open a database residing on a shared disk subsystem.
Oracle Parallel Server is a separately installable option available with the Oracle RDBMS software. If you are planning to run a parallel server database, you need to install this option, along with the Oracle RDBMS software, on a system with a shared disk architecture. In addition, even after installation, you need to enable the parallel server option. Chapter 6, and Chapter 7, cover this subject in detail.
Because a parallel server system is a multi-instance configuration, such a system provides some distinct advantages over a single-instance (often referred to as a standalone-instance) system. These advantages include:
High availability
Better scalability
Load balancing
When one instance goes down, other instances continue functioning. This increases availability, because the failure of one instance does not result in the database’s becoming unavailable to users. Users connected to other instances continue working without disruption. Users connected to the instance that failed can reconnect to any of the surviving instances.
If you get more users on an OPS system than can be handled by the existing nodes, you can add another node easily and start an additional instance on that node. Doing so results in better scalability than you typically would get with a single-instance system. Oracle also has features that allow you to balance the workload among the instances of an OPS database, enabling you to optimize the load on each node.
Managing an OPS database is a much more complex task than managing a stand-alone, single-instance database. Not only do you have the complexity of dealing with multiple instances, you also have several performance issues that come about as a result. Part III, discusses the unique aspects of managing Oracle Parallel Server.
Tip
Parallel execution and the Oracle Parallel Server Option are two separate Oracle features that can work independently as well as together. Parallel execution features can be utilized on databases with or without the Oracle Parallel Server Option. Without OPS, the parallel slave processes on behalf of a task run on only one instance, whereas with OPS the parallel slave processes on behalf of a task run on one or more instances.
Get Oracle Parallel Processing now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

