Chapter 1. Unix Host Security
Networking is all about connecting computers together, so it follows that a computer network is no more secure than the machines that it connects. A single insecure host can make lots of trouble for your entire network, because it can act as a tool for reconnaissance or a strong base of attack if it is under the control of an adversary. Firewalls, intrusion detection mechanisms, and other advanced security measures are useless if your servers offer easily compromised services. Before delving into the network part of network security, you should first make sure that the machines you are responsible for are as secure as possible.
This chapter offers many methods for reducing the risks involved in offering services on a Unix-based system. Even though each of these hacks can stand on its own, it is worth reading through this entire chapter. If you implement only one type of security measure, you run the risk of all your preparation being totally negated once an attacker figures out how to bypass it. Just as Fort Knox isn’t protected by a regular door with an ordinary dead bolt, no single security feature can ultimately protect your servers. And the security measures you may need to take increase proportionally to the value of what you’re protecting.
As the old saying goes, security isn’t a noun, it’s a verb. That is, security is an active process that must be constantly followed and renewed. Short of unplugging it, there is no single action you can take to secure your machine. With that in mind, consider these techniques as a starting point for building a secure server that meets your particular needs.
Secure Mount Points
Use mount options to help prevent intruders from further escalating a compromise.
The primary way of interacting with a Unix machine is through its filesystem. Thus, when an intruder has gained access to a system, it is desirable to limit what he can do with the files available to him. One way to accomplish this is with the use of restrictive mount options.
A mount option is a flag that controls how the filesystem may be accessed. It is passed to the operating system kernel’s code when the filesystem is brought online. Mount options can be used to prevent files from being interpreted as device nodes, to disallow
binaries from being executed, and to disallow the SUID bit from taking effect (by using the nodev
, noexec, and nosuid flags). Filesystems can also be mounted read-only with the ro option.
These options are specified from the command line by running mount with the -o flag. For example, if you have a separate partition for /tmp that is on the third partition of your first IDE hard disk, you can mount with the nodev, noexec, and nosuid flags, which are enabled by running the following command:
# mount -o nodev,noexec,nosuid /dev/hda3 /tmp
An equivalent entry in your /etc/fstab would look something like this:
/dev/hda3 /tmp ext3 defaults,nodev,noexec,nosuid 1 2
By carefully considering your requirements and dividing up your storage into multiple filesystems, you can utilize these mount options to increase the work that an attacker will have to do in order to further compromise your system. A quick way to do this is to first categorize your directory tree into areas that need write access for the system to function and those that don’t. You should consider using the read-only flag on any part of the filesystem where the contents do not change regularly. A good candidate for this might be /usr, depending on how often updates are made to system software.
Obviously, many directories (such as /home) will need to be mounted as read/write. However, it is unlikely that users on an average multiuser system will need to run SUID binaries or create device files within their home directories. Therefore, a separate filesystem, mounted with the nodev and nosuid options, could be created to house the users’ home directories. If you’ve determined that your users will not need to execute programs stored in their home directories, you can use the noexec mount option as well. A similar solution could be used for /tmp and /var, where it is highly unlikely that any process will legitimately need to execute SUID or non-SUID binaries or access device files. This strategy would help prevent the possibility of an attacker leaving a Trojan horse in a common directory such as /tmp or a user’s home directory. The attacker may be able to install the program, but it will not be able to run, with or without the proper chmod bits.
Tip
Services running in a sandboxed environment [Hack #10] might be broken if nodev is specified on the filesystem running in the sandbox. This is because device nodes such as /dev/log and /dev/null must be available within the chroot() environment.
There are a number of ways that an attacker can circumvent these mount restrictions. For example, the noexec option on Linux can be bypassed by using /lib/ld-linux.so to
execute binaries residing on a filesystem mounted with this option. At first glance, you’d think that this problem could be remedied by making ld-linux.so nonexecutable, but this would render all dynamically linked binaries nonexecutable.
So, unless all of the programs you rely on are statically linked (they’re probably not), the noexec option is of little use in Linux. In addition, an attacker who has already gained root privileges will not be significantly hampered by filesystems mounted with special options, since these can often be remounted with the -o remount option. But by using mount flags, you can easily limit the possible attacks available to a hostile user before he gains root privileges.
Scan for SUID and SGID Programs
Quickly check for potential root-exploitable programs and backdoors.
One potential way for a user to escalate her privileges on a system is to exploit a vulnerability in an SUID or SGID program. SUID and SGID are legitimately used when programs need special permissions above and beyond those that are available to the user who is running them. One such program is passwd. Simultaneously allowing a user to change her password while not allowing any user to modify the system password file means that the passwd program must be run with root privileges. Thus, the program has its SUID bit set, which causes it to be executed with the privileges of the program file’s owner. Similarly, when the SGID bit is set, the program is executed with the privileges of the file’s group owner.
Running ls -l
on a binary that has its SUID bit set should look like this:
-r-s--x--x 1 root root 16336 Feb 13 2003 /usr/bin/passwd
Notice that instead of an execute bit (x) for the owner bits, it has an s. This signifies an SUID file.
Unfortunately, a poorly written SUID or SGID binary can be used to quickly and easily escalate a user’s privileges. Also, an attacker who has already gained root access might hide SUID binaries throughout your system in order to leave a backdoor for future access. This leads us to the need for scanning systems for SUID and SGID binaries. This is a simple process and can be done with the following command:
# find / \( -perm -4000 -o -perm -2000 \) -type f -exec ls -la {} \;
One important thing to consider is whether an SUID program is in fact a shell script rather than an executable, since it’s trivial for someone to change an otherwise innocuous script into a backdoor. Most operating systems ignore any SUID or SGID bits on a shell script, but if you want to find all SUID or SGID scripts on a system, change the argument to the -exec option in the last command and add a pipe so that the command reads:
#find / \( -perm -4000 -o -perm -2000 \) -type f \-exec file {} \; | grep -v ELF
Now, every time an SUID or SGID file is encountered, the file
command will run and determine what type of file is being examined. If it’s an executable, grep will filter it out; otherwise, it will be printed to the screen with some information about what kind of file it is.
Most operating systems use ELF-format executables, but if you’re running an operating system that doesn’t (older versions of Linux used a.out, and AIX uses XCOFF), you’ll need to replace the ELF in the previous grep command with the binary format used by your operating system and architecture. If you’re unsure of what to look for, run the file command on any binary executable, and it will report the string you’re looking for.
For example, here’s an example of running file on a binary in Mac OS X:
$ file /bin/sh
/bin/sh: Mach-O executable ppcTo go one step further, you could even queue the command to run once a day using cron and have it redirect the output to a file. For instance, this crontab entry would scan for files that have either the SUID or SGID bits set, compare the current list to the one from the day before, and then email the differences to the owner of the crontab (make sure this is all on one line):
0 4 * * * find / \( -perm -4000 -o -perm -2000 \) -type f \ > /var/log/sidlog.new && \ diff /var/log/sidlog.new /var/log/sidlog && \ mv /var/log/sidlog.new /var/log/sidlog
This example will also leave a current list of SUID and SGID files in /var/log/sidlog.
Scan for World- and Group-Writable Directories
Quickly scan for directories with loose permissions.
World- and group-writable directories present a problem: if the users of a system have not set their umasks properly, they will inadvertently create insecure files, completely unaware of the implications. With this in mind, it seems it would be good to scan for directories with loose permissions. As in “Scan for SUID and SGID Programs” [Hack #2], this can be accomplished with a find
command:
# find / -type d \( -perm -g+w -o -perm -o+w \) -exec ls -lad {} \;
Any directories that are listed in the output should have the sticky bit set, which is denoted by a t in the directory’s permission bits. Setting the sticky bit on a world-writable directory ensures that even though anyone may create files in the directory, they may not delete or modify another user’s files.
If you see a directory in the output that does not contain a sticky bit, consider whether it really needs to be world-writable or whether the use of groups or ACLs [Hack #4] will work better for your situation. If you really do need the directory to be world-writable, set the sticky bit on it using
chmod +t.
To get a list of directories that don’t have their sticky bit set, run this command:
# find / -type d \( -perm -g+w -o -perm -o+w \) \
-not -perm -a+t -exec ls -lad {} \;If you’re using a system that creates a unique group for each user (e.g., you create a user andrew, which in turn creates a group andrew as the primary group), you may want to modify the commands to not scan for group-writable directories. (Otherwise, you will get a lot of output that really isn’t pertinent.) To do this, run the command without the -perm -g+w portion.
Create Flexible Permissions Hierarchies with POSIX ACLs
When Unix mode-based permissions just aren’t enough, use an ACL.
Most of the time, the traditional Unix file permissions system fits the bill just fine. But in a highly collaborative environment with multiple people needing access to files, this scheme can become unwieldy. Access control lists, otherwise known as ACLs (pronounced to rhyme with “hackles”), are a relatively new feature of open source Unix operating systems, but they have been available in their commercial counterparts for some time. While ACLs do not inherently add “more security” to a system, they do reduce the complexity of managing permissions. ACLs provide new ways to apply file and directory permissions without resorting to the creation of unnecessary groups.
ACLs are stored as extended attributes within the filesystem metadata. As the name implies, they allow you to define lists that either grant or deny access to a given file or directory based on the criteria you provide. However, ACLs do not abandon the traditional permissions system completely. ACLs can be specified for both users and groups and are still separated into the realms of read, write, and execute access. In addition, a control list may be defined for any user or group that does not correspond to any of the other user or group ACLs, much like the “other” mode bits of a file.
Access control lists also have what is called an ACL mask, which acts as a permission mask for all ACLs that specifically mention a user and a group. This is similar to a umask, but not quite the same. For instance, if you set the ACL mask to r--, any ACLs that pertain to a specific user or group and are looser in permissions (e.g., rw-) will effectively become r--. Directories also may contain a default ACL, which specifies the initial ACLs of files and subdirectories created within them.
Enabling ACLs
Most filesystems in common use today under Linux (Ext2/3, ReiserFS, JFS, and XFS) are capable of supporting ACLs. If you’re using Linux, make sure one of the following kernel configuration options is set, corresponding to the type of filesystem you’re using:
CONFIG_EXT2_FS_POSIX_ACL=y CONFIG_EXT3_FS_POSIX_ACL=y CONFIG_REISERFS_FS_POSIX_ACL=y CONFIG_JFS_POSIX_ACL=y CONFIG_FS_POSIX_ACL=y CONFIG_XFS_POSIX_ACL=y
To enable ACLs in FreeBSD, mount any filesystems you want to use them on with the acls mount option:
#mount -o acls -u /usr#mount/dev/ad0s1a on / (ufs, local) devfs on /dev (devfs, local) /dev/ad0s1e on /tmp (ufs, local, soft-updates) /dev/ad0s1f on /usr (ufs, local, soft-updates, acls) /dev/ad0s1d on /var (ufs, local, soft-updates)
The -u option updates the mount, which lets you change the mount options for a currently mounted filesystem. If you want to undo this, you can disable ACLs by using the noacls option instead. To enable ACLs automatically at boot for a filesystem, modify the filesystem’s /etc/fstab entry to look like this:
/dev/ad0s1f /usr ufs rw,acls 2 2
Managing ACLs
Once they’ve been enabled, ACLs can be set, modified, and removed using the setfacl
command. To create or modify an ACL, use the -m option, followed by an ACL specification and a filename or list of filenames. You can delete an ACL by using the -x option and specifying an ACL or list of ACLs.
There are three general forms of an ACL: one for users, another for groups, and one for others. Let’s look at them here:
# User ACL u:[user]:<mode> # Group ACL g:[group]:<mode> # Other ACL o:<mode>
Notice that in user and group ACLs, the actual user and group names that the ACL applies to are optional. If these are omitted, it means that the ACL will apply to the base ACL, which is derived from the file’s mode bits. Thus, if you modify these, the mode bits will be modified, and vice versa.
See for yourself by creating a file and then modifying its base ACL:
$touch myfile$ls -l myfile-rw-rw-r-- 1 andrew andrew 0 Oct 13 15:57 myfile $setfacl -m u::---,g::---,o:--- myfile$ls -l myfile---------- 1 andrew andrew 0 Oct 13 15:57 myfile
From this example, you can also see that multiple ACLs can be listed by separating them with commas.
You can also specify ACLs for an arbitrary number of groups or users:
$touch foo$setfacl -m u:jlope:rwx,g:wine:rwx,o:--- foo$getfacl foo# file: foo # owner: andrew # group: andrew user::rw- user:jlope:rwx group::--- group:wine:rwx mask::rwx other::---
Now if you changed the mask to r--, the ACLs for jlope and wine would effectively become r-- as well:
$setfacl -m m:r-- foo$getfacl foo# file: foo # owner: andrew # group: andrew user::rw- user:jlope:rwx #effective:r-- group::--- group:wine:rwx #effective:r-- mask::r-- other::---
As mentioned earlier, a directory can have a default ACL that will automatically be applied to files that are created within that directory. To designate an ACL as the default, prefix it with a d::
$mkdir mydir$setfacl -m d:u:jlope:rwx mydir$getfacl mydir# file: mydir # owner: andrew # group: andrew user::rwx group::--- other::--- default:user::rwx default:user:jlope:rwx default:group::--- default:mask::rwx default:other::--- $touch mydir/bar$getfacl mydir/bar# file: mydir/bar # owner: andrew # group: andrew user::rw- user:jlope:rwx #effective:rw- group::--- mask::rw- other::---
As you may have noticed from the previous examples, you can list ACLs by using the
getfacl command. This command is pretty straightforward and has only a few options. The most useful is the -R option, which allows you to list ACLs recursively and works very much like ls -R.
Protect Your Logs from Tampering
Use file attributes to prevent intruders from removing traces of their break-ins.
In the course of an intrusion, an attacker will more than likely leave telltale signs of his actions in various system logs. This is a valuable audit trail that should be well protected. Without reliable logs, it can be very difficult to figure out how the attacker got in, or where the attack came from. This information is crucial in analyzing the incident and then responding to it by contacting the appropriate parties involved [Hack #125]. However, if the break-in attempt is successful and the intruder gains root privileges, what’s to stop him from removing the traces of his misbehavior?
This is where file attributes come in to save the day (or at least make it a little better). Both Linux and the BSDs have the ability to assign extra attributes to files and directories. This is different from the standard Unix permissions scheme in that the attributes set on a file apply universally to all users of the system, and they affect file accesses at a much deeper level than file permissions or ACLs [Hack #4]. In Linux, you can see and modify the attributes that are set for a given file by using the lsattr and chattr commands, respectively. Under the BSDs, you can use ls
-lo to view the attributes and use chflags to modify them.
One useful attribute for protecting log files is append-only. When this attribute is set, the file cannot be deleted, and writes are only allowed to append to the end of the file.
To set the append-only flag under Linux, run this command:
#chattr +afilename
Under the BSDs, use this:
#chflags sappndfilename
See how the +a attribute works by creating a file and setting its append-only attribute:
#touch /var/log/logfile#echo "append-only not set" > /var/log/logfile#chattr +a /var/log/logfile#echo "append-only set" > /var/log/logfilebash: /var/log/logfile: Operation not permitted
The second write attempt failed, since it would overwrite the file. However, appending to the end of the file is still permitted:
#echo "appending to file" >> /var/log/logfile#cat /var/log/logfileappend-only not set appending to file
Obviously, an intruder who has gained root privileges could realize that file attributes are being used and just remove the append-only flag from the logs by running chattr
-a. To prevent this, you’ll need to disable the ability to remove the append-only attribute. To accomplish this under Linux, use its capabilities mechanism. Under the BSDs, use the securelevel facility.
The
Linux capabilities model divides up the privileges given to the all-powerful root account and allows you to selectively disable them. To prevent a user from removing the append-only attribute from a file, you need to remove the CAP_LINUX_IMMUTABLE capability. When present in the running system, this capability allows the append-only attribute to be modified. To modify the set of capabilities available to the system, use a simple utility called lcap
(http://snort-wireless.org/other/lcap-0.0.6.tar.bz2.
To unpack and compile the tool, run this command:
# tar xvfj lcap-0.0.6.tar.bz2 && cd lcap-0.0.6 && make
Then, to disallow modification of the append-only flag, run:
#./lcap CAP_LINUX_IMMUTABLE#./lcap CAP_SYS_RAWIO
The first command removes the ability to change the append-only flag, and the second command removes the ability to do raw I/O. This is needed so that the protected files cannot be modified by accessing the block device on which they reside. It also prevents access to /dev/mem and /dev/kmem, which would provide a loophole for an intruder to reinstate the CAP_LINUX_IMMUTABLE capability.
To remove these capabilities at boot, add the previous two commands to your system startup scripts (e.g., /etc/rc.local). You should ensure that capabilities are removed late in the boot order, to prevent problems with other startup scripts. Once lcap has removed kernel capabilities, you can only reinstate them by rebooting the system.
The BSDs accomplish the same thing through the use of securelevels. The securelevel is a kernel variable that you can set to disallow certain functionality. Raising the securelevel to 1 is functionally the same as removing the two previously discussed Linux capabilities. Once the securelevel has been set to a value greater than 0, it cannot be lowered. By default, OpenBSD will raise the securelevel to 1 when in multiuser mode. In FreeBSD, the securelevel is –1 by default.
To change this behavior, add the following line to /etc/sysctl.conf:
kern.securelevel=1
Before doing this, you should be aware that adding append-only flags to your log files will most likely cause log rotation scripts to fail. However, doing this will greatly enhance the security of your audit trail, which will prove invaluable in the event of an incident.
Delegate Administrative Roles
Let others do your work for you without giving away root privileges.
The sudo utility can help you delegate some system responsibilities to other people, without having to grant full root access. sudo is a setuid root binary that executes commands on an authorized user’s behalf, after she has entered her current password.
As root, run /usr/sbin/visudo to edit the list of users who can call sudo. The default sudo list looks something like this:
root ALL=(ALL) ALL
Unfortunately, many system administrators tend to use this entry as a template and grant unrestricted root access to all other admins unilaterally:
root ALL=(ALL) ALL rob ALL=(ALL) ALL jim ALL=(ALL) ALL david ALL=(ALL) ALL
While this may allow you to give out root access without giving away the root password, this method is truly useful only when all of the sudo users can be completely trusted. When properly configured, the sudo utility provides tremendous flexibility for granting access to any number of commands, run as any arbitrary user ID (UID).
The syntax of the sudo line is:
user machine=(effective user) command
The first column specifies the sudo user. The next column defines the hosts in which this sudo entry is valid. This allows you to easily use a single sudo configuration across multiple machines.
For example, suppose you have a developer who needs root access on a development machine, but not on any other server:
peter beta.oreillynet.com=(ALL) ALL
The next column (in parentheses) specifies the effective user who may run the commands. This is very handy for allowing users to execute code as users other than root:
peter lists.oreillynet.com=(mailman) ALL
Finally, the last column specifies all of the commands that this user may run:
david ns.oreillynet.com=(bind) /usr/sbin/rndc,/usr/sbin/named
If you find yourself specifying large lists of commands (or, for that matter, users or machines), take advantage of sudo’s alias syntax. An alias can be used in place of its respective entry on any line of the sudo configuration:
User_Alias ADMINS=rob,jim,david User_Alias WEBMASTERS=peter,nancy Runas_Alias DAEMONS=bind,www,smmsp,ircd Host_Alias WEBSERVERS=www.oreillynet.com,www.oreilly.com,www.perl.com Cmnd_Alias PROCS=/bin/kill,/bin/killall,/usr/bin/skill,/usr/bin/top Cmnd_Alias APACHE=/usr/local/apache/bin/apachectl WEBMASTERS WEBSERVERS=(www) APACHE ADMINS ALL=(DAEMONS) ALL
It is also possible to specify a
system group instead of a user, to allow any user who belongs to that group to execute commands. Just prefix the group name with a %, like this:
%wwwadmin WEBSERVERS=(www) APACHE
Now any user who is part of the wwwadmin group can execute apachectl as the www user on any of the web server machines.
One very useful feature is the
NOPASSWD: flag. When present, the user won’t have to enter a password before executing the command. For example, this will allow the user rob to execute kill, killall, skill, and top on any machine, as any user, without entering a password:
rob ALL=(ALL) NOPASSWD: PROCS
Finally, sudo can be a handy alternative to su for running commands at startup out of the system rc files:
(cd /usr/local/mysql; sudo -u mysql ./bin/safe_mysqld &) sudo -u www /usr/local/apache/bin/apachectl start
For that to work at boot time, the default line root ALL=(ALL) ALL must be present.
Use sudo with the usual caveats that apply to setuid binaries. Particularly if you allow sudo to execute interactive commands (like editors) or any sort of compiler or interpreter, you should assume that it is possible that the sudo user will be able to execute arbitrary commands as the effective user. Still, under most circumstances this isn’t a problem, and it’s certainly preferable to giving away undue access to root privileges.
Rob Flickenger
Automate Cryptographic Signature Verification
Use scripting and key servers to automate the chore of checking software authenticity.
One of the most important things you can do for the security of your system is to make yourself familiar with the software you are installing. You probably will not have the time, knowledge, or resources to go through the source code for all of the software that you install. However, verifying that the software you are compiling and installing is what the authors intended can go a long way toward preventing the widespread distribution of Trojan horses.
Recently, Trojaned versions of several pivotal pieces of software (such as tcpdump, libpcap, sendmail, and OpenSSH) have been distributed. Since this is an increasingly popular attack vector, verifying your software is critically important.
Why does this need to be automated? It takes little effort to verify software before installing it, but either through laziness or ignorance, many system administrators overlook this critical step. This is a classic example of “false” laziness, since it will likely lead to more work for the sysadmin in the long run.
This problem is difficult to solve, because it relies on the programmers and distributors to get their acts together. Then there’s the laziness aspect. Software packages often don’t even come with a signature to use for verifying the legitimacy of what you’ve downloaded, and even when signatures are provided with the source code, to verify the code you must hunt through the software provider’s site for the public key that was used to create the signature. After finding the public key, you have to download it, verify that the key is genuine, add it to your keyring, and finally check the signature of the code.
Here is what this would look like when checking the signature for Version 1.3.28 of the Apache web server using GnuPG (http://www.gnupg.org):
#gpg -import KEYS#gpg -verify apache_1.3.28.tar.gz.asc apache_1.3.28.tar.gzgpg: Signature made Wed Jul 16 13:42:54 2003 PDT using DSA key ID 08C975E5 gpg: Good signature from "Jim Jagielski <jim@zend.com>" gpg: aka "Jim Jagielski <jim@apache.org>" gpg: aka "Jim Jagielski <jim@jaguNET.com>" gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Fingerprint: 8B39 757B 1D8A 994D F243 3ED5 8B3A 601F 08C9 75E5
As you can see, it’s not terribly difficult to do, but this step is often overlooked when people are in a hurry. This is where this hack comes to the rescue. We’ll use a little bit of shell scripting and what are known as key servers to reduce the number of steps required to perform the verification process.
Key servers are a part of a public-key cryptography infrastructure that allows you to retrieve keys from a trusted third party. A nice feature of GnuPG is its ability to query key servers for a key ID and to download the result into a local keyring. To figure out which key ID to ask for, we rely on the fact that the error message generated by GnuPG tells us which key ID it was unable to find locally when trying to verify the signature.
In the previous example, if the key that GnuPG was looking for had not been imported prior to verifying the signature, it would have generated an error like this:
gpg: Signature made Wed Jul 16 13:42:54 2003 PDT using DSA key ID 08C975E5 gpg: Can't check signature: public key not found
The following script takes advantage of that error:
#!/bin/sh
VENDOR_KEYRING=vendors.gpg
KEYSERVER=search.keyserver.net
KEYID="0x\Qgpg --verify $1 $2 2>&1 | grep 'key ID' | awk '{print $NF}'\Q"
gpg --no-default-keyring --keyring $VENDOR_KEYRING --recv-key \
--keyserver $KEYSERVER $KEYID
gpg --keyring $VENDOR_KEYRING --verify $1 $2The first line of the script specifies the keyring in which the result from the key server query will be stored. You could use pubring.gpg (which is the default keyring for GnuGP), but using a separate file will make managing vendor public keys easier. The second line of the script specifies which key server to query (the script uses search.keyserver.net; another good one is pgp.mit.edu). The third line attempts (and fails) to verify the signature without first consulting the key server. It then uses the key ID it saw in the error, prepending an 0x in order to query the key server on the next line. Finally, GnuPG attempts to verify the signature and specifies the keyring in which the query result was stored.
This script has shortened the verification process by eliminating the need to search for and import the public key that was used to generate the signature. Going back to the example of verifying the Apache 1.3.28 source code, you can see how much more convenient it is now to verify the package’s authenticity:
# checksig apache_1.3.28.tar.gz.asc apache_1.3.28.tar.gz
gpg: requesting key 08C975E5 from HKP keyserver search.keyserver.net
gpg: key 08C975E5: public key imported
gpg: Total number processed: 1
gpg: imported: 1
gpg: Warning: using insecure memory!
gpg: please see http://www.gnupg.org/faq.html for more information
gpg: Signature made Wed Jul 16 13:42:54 2003 PDT using DSA key ID 08C975E5
gpg: Good signature from "Jim Jagielski <jim@zend.com>"
gpg: aka "Jim Jagielski <jim@apache.org>"
gpg: aka "Jim Jagielski <jim@jaguNET.com>"
gpg: checking the trustdb
gpg: no ultimately trusted keys found
gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Fingerprint: 8B39 757B 1D8A 994D F243 3ED5 8B3A 601F 08C9 75E5This small, quick script has reduced both the number of steps and the amount of time needed to verify a source package. As with any good shell script, it should help you to be lazy in a good way: by doing more work properly, but with less effort on your part.
Check for Listening Services
Find out whether unneeded services are listening and looking for possible backdoors.
One of the first things you should do after a fresh operating system install is see what services are running and remove any unneeded services from the system startup process. You could use a port scanner (such as Nmap [Hack #66]) and run it against the host, but if one didn’t come with the operating system install, you’ll likely have to connect your fresh (and possibly insecure) machine to the network to download one.
Also, Nmap can be fooled if the system is using firewall rules. With proper firewall rules, a service can be completely invisible to Nmap unless certain criteria (such as the source IP address) also match. When you have shell access to the server itself, it is usually more efficient to find open ports using programs that were installed with the operating system. One option is netstat, a program that will display various network-related information and statistics.
To get a list of listening ports and their owning processes under Linux, run this command:
# netstat -luntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1679/sshd
udp 0 0 0.0.0.0:68 0.0.0.0:* 1766/dhclientFrom the output, you can see that this machine is probably a workstation, since it just has a DHCP client running along with an SSH daemon for remote access. The ports in use are listed after the colon in the Local
Address column (22 for sshd and 68 for dhclient). The absence of any other listening processes means that this is probably a workstation, not a network server.
Unfortunately, the BSD version of netstat
does not let us list the processes and the process IDs (PIDs) that own the listening port. Nevertheless, the BSD netstat command is still useful for listing the listening ports on your system.
To get a list of listening ports under FreeBSD, run this command:
# netstat -a -n | egrep 'Proto|LISTEN'
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 *.587 *.* LISTEN
tcp4 0 0 *.25 *.* LISTEN
tcp4 0 0 *.22 *.* LISTEN
tcp4 0 0 *.993 *.* LISTEN
tcp4 0 0 *.143 *.* LISTEN
tcp4 0 0 *.53 *.* LISTEN
Again, the ports in use are listed in the Local Address column. Many seasoned system administrators have memorized the common port numbers for popular services and will be able to see at a glance that this server is running SSHD, SMTP, DNS, IMAP, and IMAP+SSL services. If you are ever in doubt about which services typically run on a given port, either eliminate the -n switch from the netstat command (which tells netstat to use names but can take much longer to run when looking up DNS addresses) or manually grep the
/etc/services file:
# grep -w 993 /etc/services
imaps 993/udp # imap4 protocol over TLS/SSL
imaps 993/tcp # imap4 protocol over TLS/SSLThe /etc/services file should only be used as a guide. If a process is listening on a port listed in the file, it doesn’t necessarily mean that the service listed in /etc/services is what it is providing.
Also notice that, unlike in the output of netstat on Linux, with the BSD version you don’t get the PIDs of the daemons themselves. You might also notice that no UDP ports were listed for DNS. This is because UDP sockets do not have a LISTEN state in the same sense that TCP sockets do. In order to display UDP sockets, you must add udp4 to the argument for egrep, thus making it 'Proto|LISTEN|udp4'. However, due to the way UDP works, not all UDP sockets will necessarily be associated with a daemon process.
Under FreeBSD, there is another command that will give us just what we want. The sockstat
command performs only a small subset of what netstat can do and is limited to listing information on Unix domain sockets and Inet sockets, but it’s ideal for this hack’s purposes.
To get a list of listening ports and their owning processes with sockstat, run this command:
# sockstat -4 -l
USER COMMAND PID FD PROTO LOCAL ADDRESS FOREIGN ADDRESS
root sendmail 1141 4 tcp4 *:25 *:*
root sendmail 1141 5 tcp4 *:587 *:*
root sshd 1138 3 tcp4 *:22 *:*
root inetd 1133 4 tcp4 *:143 *:*
root inetd 1133 5 tcp4 *:993 *:*
named named 1127 20 tcp4 *:53 *:*
named named 1127 21 udp4 *:53 *:*
named named 1127 22 udp4 *:1351 *:*Once again, you can see that SSHD, SMTP, DNS, IMAP, and IMAP+SSL services are running, but now you have the process that owns the socket plus its PID. You can now see that the IMAP services are being spawned from inetd instead of standalone daemons, and that sendmail and named are providing the SMTP and DNS services.
For most other Unix-like operating systems, you can use the lsof
utility (http://ftp.cerias.purdue.edu/pub/tools/unix/sysutils/lsof/). lsof is short for “list open files” and, as the name implies, it allows you to list files that are open on a system, in addition to the processes and PIDs that have them open. Since sockets and files work the same way under Unix, lsof can also be used to list open sockets. This is done with the -i command-line option.
To get a list of listening ports and the processes that own them using lsof, run this command:
# lsof -i -n | egrep 'COMMAND|LISTEN'
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
named 1127 named 20u IPv4 0xeb401dc0 0t0 TCP *:domain (LISTEN)
inetd 1133 root 4u IPv4 0xeb401ba0 0t0 TCP *:imap (LISTEN)
inetd 1133 root 5u IPv4 0xeb401980 0t0 TCP *:imaps (LISTEN)
sshd 1138 root 3u IPv4 0xeb401760 0t0 TCP *:ssh (LISTEN)
sendmail 1141 root 4u IPv4 0xeb41b7e0 0t0 TCP *:smtp (LISTEN)
sendmail 1141 root 5u IPv4 0xeb438fa0 0t0 TCP *:submission (LISTEN)Again, you can change the argument to egrep to display UDP sockets. However, this time use UDP instead of udp4, which makes the argument 'COMMAND|LISTEN|UDP'. As mentioned earlier, not all UDP sockets will necessarily be associated with a daemon process.
Prevent Services from Binding to an Interface
Keep services from listening on a port instead of firewalling them.
Sometimes, you might want to limit a service to listen on only a specific interface. For instance, Apache [Hack #55] can be configured to listen on a specific interface as opposed to all available interfaces. You can do this by using the Listen directive in your configuration file and specifying the IP address of the interface:
Listen 192.168.0.23:80
If you use VirtualHost entries, you can specify interfaces to bind to on a per-virtual-host basis:
<VirtualHost 192.168.0.23> ... </VirtualHost>
You might even have services that are listening on a TCP port but don’t need to be. Database servers such as MySQL are often used in conjunction with Apache and are frequently set up to coexist on the same server when used in this way. Connections that come from the same machine that MySQL is installed on use a domain socket in the filesystem for communications. Therefore, MySQL doesn’t need to listen on a TCP socket. To keep it from listening, you can either use the --skip-networking command-line option when starting MySQL or specify it in the [mysqld] section of your my.cnf file:
[mysqld] ... skip-networking ...
Another program that you’ll often find listening on a port is your X11 server, which listens on TCP port 6000 by default. This port is traditionally used to enable remote clients to connect to your X11 server so they can draw their windows and accept keyboard and mouse input; however, with the advent of SSH and X11 forwarding, this really isn’t needed anymore. With X11 forwarding enabled in ssh, any client that needs to connect to your X11 server will be tunneled through your SSH connection and will bypass the listening TCP port when connecting to your X11 server.
To get your X Windows server to stop listening on this port, all you need to do is add -nolisten tcp to the command that is used to start the server. This can be tricky, though—figuring out which file controls how the server is started can be a daunting task. Usually, you can find what you’re looking for in /etc/X11.
If you’re using gdm, open gdm.conf and look for a line similar to this one:
command=/usr/X11R6/bin/X
Then, just add -nolisten tcp to the end of the line.
If you’re using xdm, look for a file called Xservers and make sure it contains a line similar to this:
:0 local /usr/X11R6/bin/X -nolisten tcp
Alternatively, if you’re not using a managed display and instead are using startx
or a similar command to start your X11 server, you can just add -nolisten
tcp to the end of your startx command. To be sure that it is passed to the X server process, start it after an extra set of hyphens:
$ startx -- -nolisten tcp
Once you start X, fire up a terminal and see what is listening using lsof or netstat [Hack #8]. You should no longer see anything bound to port 6000.
Restrict Services with Sandboxed Environments
Mitigate system damage by keeping service compromises contained.
Sometimes, keeping up with the latest patches just isn’t enough to prevent a break-in. Often, a new exploit will circulate in private circles long before an official advisory is issued, during which time your servers might be open to unexpected attack. With this in mind, it’s wise to take extra preventative measures to contain the possible effects of a compromised service. One way to do this is to run your services in a sandbox. Ideally, this minimizes the effects of a service compromise on the overall system.
Most Unix and Unix-like systems include some sort of system call or other mechanism for sandboxing that offers various levels of isolation between the host and the sandbox. The least restrictive and easiest to set up is a chroot()
environment, which is available on nearly all Unix and Unix-like systems. FreeBSD also includes another mechanism called jail()
, which provides some additional restrictions beyond those provided by chroot().
Tip
If you want to set up a restricted environment but don’t feel that you need the level of security provided by a system-call-based sandboxed environment, see “Restrict Shell Environments” [Hack #20].
Using chroot()
chroot()
very simply changes the root directory of a process and all of its children. While this is a powerful feature, there are many caveats to using it. Most importantly, there should be no way for anything running within the sandbox to change its effective user ID (EUID) to 0, which is root’s UID. Naturally, this implies that you don’t want to run anything as root within the jail.
There are many ways to break out of a chroot() sandbox, but they all rely on being able to get root privileges within the sandboxed environment. Possession of UID 0 inside the sandbox is the Achilles heel of chroot(). If an attacker is able to gain root privileges within the sandbox, all bets are off. While the attacker will not be able to directly break out of the sandboxed environment, he may be able to run functions inside the exploited processes’ address space that will let him break out.
There are a few services that support chroot() environments by calling the function within the program itself, but many services do not. To run these services inside a sandboxed environment using chroot(), you need to make use of the chroot
command. The chroot command simply calls chroot() with the first command-line argument and attempts to execute the program specified in the second argument. If the program is a statically linked binary, all you have to do is copy the program to somewhere within the sandboxed environment; however, if the program is dynamically linked, you will need to copy all of its supporting libraries to the environment as well.
See how this works by setting up bash
in a chroot() environment. First try to run chroot without copying any of the libraries bash needs:
#mkdir -p /chroot_test/bin#cp /bin/bash /chroot_test/bin/#chroot /chroot_test /bin/bashchroot: /bin/bash: No such file or directory
Now find out what libraries bash needs by using the ldd
command. Then copy the libraries into your chroot() environment and attempt to run chroot again:
#ldd /bin/bashlibtermcap.so.2 => /lib/libtermcap.so.2 (0x4001a000) libdl.so.2 => /lib/libdl.so.2 (0x4001e000) libc.so.6 => /lib/tls/libc.so.6 (0x42000000) /lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000) #mkdir -p chroot_test/lib/tls && \>(cd /lib; \>cp libtermcap.so.2 libdl.so.2 ld-linux.so.2 /chroot_test/lib; \>cd tls; cp libc.so.6 /chroot_test/lib/tls)#chroot /chroot_test /bin/bashbash-2.05b# bash-2.05b#echo /*/bin /lib
Setting up a chroot() environment mostly involves trial and error in getting the permissions right and getting all of the library dependencies in place. Be sure to consider the implications of having other programs such as mknod
or mount available in the chroot() environment. If these are available, the attacker may be able to create device nodes to access memory directly or to remount filesystems, thus breaking out of the sandbox and gaining total control of the overall system.
This threat can be mitigated by putting the directory on a filesystem mounted with options that prohibit the use of device files [Hack #1], but that isn’t always convenient. It is advisable to make as many of the files and directories in the chroot()-ed directory as possible owned by root and writable only by root, in order to make it impossible for a process to modify any supporting files (this includes files such as libraries and configuration files). In general, it is best to keep permissions as restrictive as possible and to relax them only when necessary (for example, if the permissions prevent the daemon from working properly).
The best candidates for a chroot() environment are services that do not need root privileges at all. For instance, MySQL listens for remote connections on port 3306 by default. Since this port is above 1024, mysqld can be started without root privileges and therefore doesn’t pose the risk of being used to gain root access. Other daemons that need root privileges can include an option to drop these privileges after completing all the operations for which they need root access (e.g., binding to a port below 1024), but care should be taken to ensure that the programs drop their privileges correctly. If a program uses seteuid()
rather than setuid() to drop its privileges, an attacker can still exploit it to gain root access. Be sure to read up on current security advisories for programs that will run only with root privileges.
You might think that simply not putting compilers, a shell, or utilities such as mknod in the sandbox environment might protect them in the event of a root compromise within the restricted environment. In reality, attackers can accomplish the same functionality by changing their code from calling system("/bin/sh") to calling any other C library function or system call that they desire. If you can mount the filesystem the chroot()-ed program runs from using the read-only flag [Hack #1], you can make it more difficult for attackers to install their own code, but this is still not quite bulletproof. Unless the daemon you need to run within the environment can meet the criteria discussed earlier, you might want to look into using a more powerful sandboxing mechanism.
Using FreeBSD’s jail()
One
such mechanism is available under FreeBSD and is implemented through the jail()
system call. jail() provides many more restrictions in isolating the sandbox environment from the host system and offers additional features, such as assigning IP addresses from virtual interfaces on the host system. Using this functionality, you can create a full virtual server or just run a single service inside the sandboxed environment.
Just as with chroot(), the system provides a jail
command that uses the jail() system call. Here’s the basic form of the jail command, where ipaddr is the IP address of the machine on which the jail is running:
jail new root hostname ipaddr command
The hostname can be different from the main system’s hostname, and the IP address can be any IP address that the system is configured to respond to. You can actually give the appearance that all of the services in the jail are running on a separate system by using a different hostname and configuring and using an additional IP address.
Now, try running a shell inside a jail:
#mkdir -p /jail_test/bin#cp /stand/sh /jail_test/bin/sh#jail /jail_test jail_test 192.168.0.40 /bin/sh#echo /*/bin
This time, no libraries need to be copied, because the binaries in /stand are statically linked.
On the opposite side of the spectrum, you can build a jail that can function as a nearly fully functional virtual server with its own IP address. The steps to do this basically involve building FreeBSD from source and specifying the jail directory as the install destination. You can do this by running the following commands:
#mkdir /jail_test#cd /usr/src#make world DESTDIR=/jail_test#cd etc && make distribution DESTDIR=/jail_test#mount_devfs devfs /jail_test/dev#cd /jail_test && ln -s dev/null kernel
However, if you’re planning to run just one service from within the jail, this is definitely overkill. (Note that in the real world you’ll probably need to create /dev/null and /dev/log device nodes in your sandbox environment for most daemons to work correctly.)
To start your jails automatically at boot, you can modify /etc/rc.conf, which provides several variables for controlling a given jail’s configuration:
jail_enable="YES" jail_list=" test" ifconfig_lnc0_alias0="inet 192.168.0.41 netmask 255.255.255.255" jail_test_rootdir="/jail_test" jail_test_hostname="jail_test" jail_test_ip="192.168.0.41" jail_test_exec_start="/bin/sh /etc/rc" jail_test_exec_stop="/bin/sh /etc/rc.shutdown" jail_test_devfs_enable="YES" jail_test_fdescfs_enable="NO" jail_test_procfs_enable="NO" jail_test_mount_enable="NO" jail_test_devfs_ruleset="devfsrules_jail"
Setting jail_enable to YES will cause /etc/rc.d/jail start to execute at startup. This in turn reads the rest of the jail_X variables from rc.conf, by iterating over the values for jail_list (multiple jails can be listed, separated by spaces) and looking for their corresponding sets of variables. These variables are used for configuring each individual jail’s root directory, hostname, IP address, startup and shutdown scripts, and what types of special filesystems will be mounted within the jail.
For the jail to be accessible from the network, you’ll also need to configure a network interface with the jail’s IP address. In the previous example, this is done with the ifconfig_lnc0_alias0 variable. For setting IP aliases on an interface to use with a jail, this takes the form of:
ifconfig_<iface>_alias<alias number>="inet <address> netmask 255.255.255.255"
So, if you wanted to create a jail with the address 192.168.0.42 and use the same interface as above, you’d put something like this in your rc.conf:
ifconfig_lnc0_alias1="inet 192.168.0.42 netmask 255.255.255.255"
One thing that’s not entirely obvious is that you’re not limited to using a different IP address for each jail. You can specify multiple jails with the same IP address, as long as you’re not running services within them that listen on the same port.
By now you’ve seen how powerful jails can be. Whether you want to create virtual servers that can function as entire FreeBSD systems within a jail or just to compartmentalize critical services, they can offer another layer of security in protecting your systems from intruders.
Use proftpd with a MySQL Authentication Source
Make sure that your database system’s OS is running as efficiently as possible with these tweaks.
proftpd is a powerful FTP daemon with a configuration syntax much like Apache. It has a whole slew of options not available in most FTP daemons, including ratios, virtual hosting, and a modularized design that allows people to write their own modules.
One such module is mod_sql , which allows proftpd to use a SQL database as its backend authentication source. Currently, mod_sql supports MySQL and PostgreSQL. This can be a good way to help lock down access to your server, as inbound users will authenticate against the database (and therefore not require an actual shell account on the server). In this hack, we’ll get proftpd authenticating against a MySQL database.
First, download and build the source to proftpd and mod_sql:
~$bzcat proftpd-1.2.6.tar.bz2 | tar xf -~/proftpd-1.2.6/contrib$tar zvxf ../../mod_sql-4.08.tar.gz~/proftpd-1.2.6/contrib$cd .. ~/proftpd-1.2.6$ ./configure --with-modules=mod_sql:mod_sql_mysql \ --with-includes=/usr/local/mysql/include/ \ --with-libraries=/usr/local/mysql/lib/
Tip
Substitute the path to your MySQL install, if it isn’t in /usr/local/mysql/.
Now, build the code and install it:
rob@catlin:~/proftpd-1.2.6$ make && sudo make install
Next, create a database for proftpd to use (assuming that you already have MySQL up and running):
$ mysqladmin create proftpd
Then, permit read-only access to it from proftpd:
$mysql -e "grant select on proftpd.* to proftpd@localhost \identified by 'secret';"
Create two tables in the database, with this schema:
CREATE TABLE users ( userid varchar(30) NOT NULL default '', password varchar(30) NOT NULL default '', uid int(11) default NULL, gid int(11) default NULL, homedir varchar(255) default NULL, shell varchar(255) default NULL, UNIQUE KEY uid (uid), UNIQUE KEY userid (userid) ) TYPE=MyISAM; CREATE TABLE groups ( groupname varchar(30) NOT NULL default '', gid int(11) NOT NULL default '0', members varchar(255) default NULL ) TYPE=MyISAM;
One quick way to create the tables is to save this schema to a file called proftpd.schema and run a command like mysql proftpd < proftpd.schema.
Now, you need to tell proftpd to use this database for authentication. Add the following lines to your /usr/local/etc/proftpd.conf file:
SQLConnectInfo proftpd proftpd secret SQLAuthTypes crypt backend SQLMinUserGID 111 SQLMinUserUID 111
The SQLConnectInfo line takes the form database user password. You could also specify a database on another host (even on another port) with something like this:
SQLConnectInfo proftpd@dbhost:5678 somebody somepassword
The SQLAuthTypes line lets you create users with passwords stored in the standard Unix crypt format, or MySQL’s PASSWORD() function. Be warned that if you’re using mod_sql’s logging facilities, the password might be exposed in plain text, so keep those logs private.
The SQLAuthTypes line as specified won’t allow blank passwords; if you need that functionality, also include the empty keyword. The SQLMinUserGID and SQLMinUserUID lines specify the minimum group and user ID that proftpd will permit on login. It’s a good idea to make this greater than 0 (to prohibit root logins), but it should be as low as you need to allow proper permissions in the filesystem. On this system, we have a user and a group called www, with both the user ID (UID) and the group ID (GID) set to 111. As we’ll want web developers to be able to log in with these permissions, we’ll need to set the minimum values to 111.
Finally, you’re ready to create users in the database. The following line creates the user jimbo, with effective user rights as www/www, and dumps him in the /usr/local/apache/htdocs directory at login:
mysql -e "insert into users values ('jimbo',PASSWORD('sHHH'),'111', \
'111', '/usr/local/apache/htdocs','/bin/bash');" proftpdThe password for jimbo is encrypted with MySQL’s PASSWORD() function before being stored. The /bin/bash line is passed to proftpd to pass proftpd’s RequireValidShell directive. It has no bearing on granting actual shell access to the user jimbo.
At this point, you should be able to fire up proftpd and log in as user jimbo, with a password of sHHH. If you are having trouble getting connected, try running proftpd in the foreground with debugging on, like this:
# proftpd -n -d 5
Watch the messages as you attempt to connect, and you should be able to track down the problem. In my experience, it’s almost always due to a failure to set something properly in proftpd.conf, usually regarding permissions.
The mod_sql module can do far more than I’ve shown here; it can connect to existing MySQL databases with arbitrary table names, log all activity to the database, modify its user lookups with an arbitrary WHERE clause, and much more.
See Also
The mod_sql home page at
http://www.lastditcheffort.org/~aah/proftpd/mod_sql/The proftpd home page at
http://www.proftpd.org
Rob Flickenger
Prevent Stack-Smashing Attacks
Learn how to prevent stack-based buffer overflows.
In C and C++, memory for local variables is allocated in a chunk of memory called the stack. Information pertaining to the control flow of a program is also maintained on the stack. If an array is allocated on the stack and that array is overrun (that is, more values are pushed into the array than the available space allows), an attacker can overwrite the control flow information that is also stored on the stack. This type of attack is often referred to as a stack-smashing attack.
Stack-smashing attacks are a serious problem, since they can make an otherwise innocuous service (such as a web server or FTP server) execute arbitrary commands. Several technologies attempt to protect programs against these attacks. Some are implemented in the compiler, such as IBM’s ProPolice patches for GCC (http://www.trl.ibm.com/projects/security/ssp/). Others are dynamic runtime solutions, such as LibSafe. While recompiling the source gets to the heart of the buffer overflow attack, runtime solutions can protect programs when the source isn’t available or recompiling simply isn’t feasible.
All of the compiler-based solutions work in much the same way, although there are some differences in the implementations. They work by placing a canary (which is typically some random value) on the stack between the control flow information and the local variables. The code that is normally generated by the compiler to return from the function is modified to check the value of the canary on the stack; if it is not what it is supposed to be, the program is terminated immediately.
The idea behind using a canary is that an attacker attempting to mount a stack-smashing attack will have to overwrite the canary to overwrite the control flow information. Choosing a random value for the canary ensures that the attacker cannot know what it is and thus cannot include it in the data used to “smash” the stack.
When a program is distributed in source form, the program’s developer cannot enforce the use of ProPolice, because it’s a nonstandard extension to the GCC compiler (although ProPolice-like features have been added to GCC 4.x, that version of GCC isn’t in common use). Using ProPolice is the responsibility of the person compiling the program. ProPolice is available with some BSD and Linux distributions out of the box. You can check to see if your copy of GCC contains ProPolice functionality by using the -fstack-protector option to GCC. If your GCC is already patched, the compilation should proceed normally. Otherwise, you’ll get an error like this:
cc1: error: unrecognized command line option "-fstack-protector"
When ProPolice is enabled and an overflow is triggered and detected in a program, rather than receiving a SIGSEGV, the program will receive a SIGABRT and dump core. In addition, a message will be logged informing you of the overflow and the offending function in the program:
May 25 00:17:22 zul vulnprog: stack overflow in function Get_method_from_request
For Linux systems, Avaya Labs’s LibSafe technology is not implemented as a compiler extension, but instead takes advantage of a feature of the dynamic loader that preloads a dynamic library with every executable. Using LibSafe does not require the source code for the programs it protects, and it can be deployed on a system-wide basis.
LibSafe replaces the implementation of several standard functions that are vulnerable to buffer overflows, such as gets(), strcpy(), and scanf(). The replacement implementations attempt to compute the maximum possible size of a statically allocated buffer used as a destination buffer for writing, using a GCC built-in function that returns the address of the frame pointer. That address is normally the first piece of information on the stack following local variables. If an attempt is made to write more than the estimated size of the buffer, the program is terminated.
Unfortunately, there are several problems with the approach taken by LibSafe. First, it cannot accurately compute the size of a buffer; the best it can do is limit the size of the buffer to the difference between the start of the buffer and the frame pointer. Second, LibSafe’s protections will not work with programs that were compiled using the -fomit-frame-pointer
flag to GCC, an optimization that causes the compiler not to put a frame pointer on the stack. Although relatively useless, this is a popular optimization for programmers to employ. Finally, LibSafe does not work on SUID binaries without static linking or a similar trick. Still, it does provide at least some protection against conventional stack-smashing attacks.
The newest versions of LibSafe also provide some protection against format-string attacks. The format-string protection also requires access to the frame pointer because it attempts to filter out arguments that are not pointers into either the heap or the local variables on the stack.
In addition to user-space solutions, you can opt to patch your kernel to use nonexecutable stacks and detect buffer overflow attacks [Hack #13].
Lock Down Your Kernel with grsecurity
Harden your system against attacks with the grsecurity kernel patch.
Hardening a Unix system can be a difficult process that typically involves setting up all the services that the system will run in the most secure fashion possible, as well as locking down the system to prevent local compromises. However, putting effort into securing the services that you’re running does little for the rest of the system and for unknown vulnerabilities. Luckily, even though the standard Linux kernel provides few features for proactively securing a system, there are patches available that can help the enterprising system administrator do so. One such patch is grsecurity (http://www.grsecurity.net).
grsecurity started out as a port of the OpenWall patch (http://www.openwall.com) to the 2.4.x series of Linux kernels. This patch added features such as nonexecutable stacks, some filesystem security enhancements, restrictions on access to /proc, as well as some enhanced resource limits. These features helped to protect the system against stack-based buffer overflow attacks, prevented filesystem attacks involving race conditions on files created in /tmp, limited users to seeing only their own processes, and even enhanced Linux’s resource limits to perform more checks.
Since its inception, grsecurity has grown to include many features beyond those provided by the OpenWall patch. grsecurity now includes many additional memory address space protections to prevent buffer overflow exploits from succeeding, as well as enhanced chroot() jail restrictions, increased randomization of process and IP IDs, and increased auditing features that enable you to track every process executed on a system. grsecurity also adds a sophisticated access control list system that makes use of Linux’s capabilities system. This ACL system can be used to limit the privileged operations that individual processes are able to perform on a case-by-case basis.
Tip
The gradm utility handles configuration of ACLs. If you already have grsecurity installed on your machine, feel free to skip ahead to “Restrict Applications with grsecurity” [Hack #14].
Patching the Kernel
To compile a kernel with grsecurity, you will need to download the patch that corresponds to your kernel version and apply it to your kernel using the patch utility. For example, if you are running Linux 2.6.14.6:
#cd /usr/src/linux-2.6.14.6#zcat ~andrew/grsecurity-2.1.8-2.6.14.6-200601211647.patch.gz | patch -p1
While the command is running, you should see a line for each kernel source file that is being patched. After the command has finished, you can make sure that the patch applied cleanly by looking for any files that end in .rej. The patch program creates these when it cannot apply the patch cleanly to a file. A quick way to see if there are any .rej files is to use the find
command:
# find ./ -name \*.rej
If there are any rejected files, they will be listed on the screen. If the patch applied cleanly to all files, you should be returned to the shell prompt without any additional output.
After the patch has been applied, you can configure the kernel to enable grsecurity’s features by running make
config to use text prompts, make
menuconfig for a curses-based interface, or make xconfig to use a QT-based GUI (use gconfig for a GTK-based one). If you went the graphical route and used make xconfig, expand the Security options tree and you should see something similar to Figure 1-1.
There are now two new subtrees: PaX and Grsecurity. If you ran make
menuconfig or make
config, the relevant kernel options have the same names as the menu options described in this example.
Configuring Kernel Options
To enable grsecurity and configure which features will be enabled in the kernel, expand the Grsecurity subtree and click the checkbox labeled Grsecurity. You should see the dialog shown in Figure 1-2.
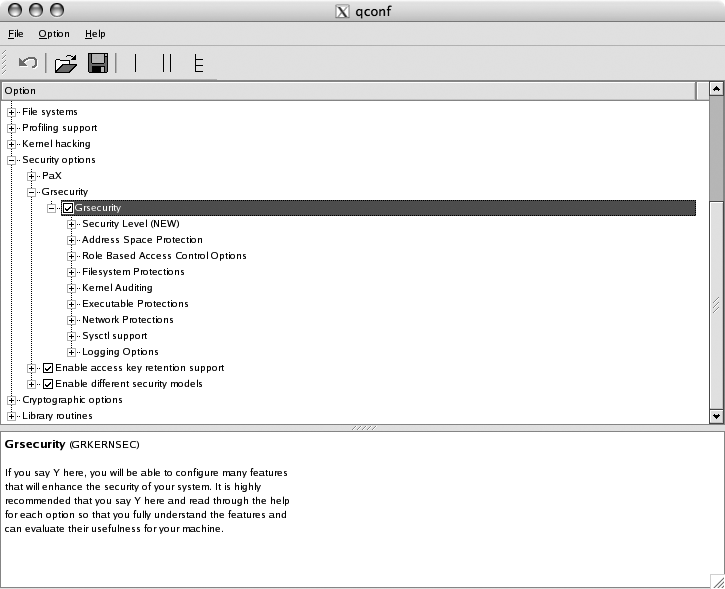
After you’ve done that, you can enable predefined sets of features under the Security Level subtree, or set it to Custom and go through the menus to pick and choose which features to enable.
Low security
Choosing Low is safe for any system and should not affect any software’s normal operation. Using this setting will enable linking restrictions in directories with mode 1777. This prevents race conditions in /tmp from being exploited, by only following symlinks to files that are owned by the process following the link. Similarly, users won’t be able to write to FIFOs that they do not own if they are within a directory with permissions of 1777.
In addition to the tighter symlink and FIFO restrictions, the Low setting increases the randomness of process and IP IDs. This helps to prevent attackers from using remote detection techniques to correctly guess the operating system your machine is running [Hack #65], and it also makes it difficult to guess the process ID of a given program.
The Low security level also forces programs that use chroot() to change their current working directory to / after the chroot() call. Otherwise, if a program left its working directory outside of the chroot() environment, it could be used to break out of the sandbox. Choosing the Low security level also prevents non-root users from using dmesg
, a utility that can be used to view recent kernel messages.
Medium security
Choosing Medium enables all of the same features as the Low security level, but this level also includes features that make chroot()-based sandboxed environments more secure. The ability to mount filesystems, call chroot(), write to sysctl variables, or create device nodes within a chroot()-ed environment are all restricted, thus eliminating much of the risk involved in running a service in a sandboxed environment under Linux. In addition, the Medium level randomizes TCP source ports and logs failed fork() calls, changes to the system time, and segmentation faults.
Enabling the Medium security level also restricts total access to /proc to those who are in the wheel group. This hides each user’s processes from other users and denies writing to /dev/kmem, /dev/mem, and /dev/port. This makes it more difficult to patch kernel-based root kits into the running kernel. The Medium level also randomizes process memory address space layouts, making it harder for an attacker to successfully exploit buffer overrun attacks, and removes information on process address space layouts from /proc. Because of these /proc restrictions, you will need to run your identd daemon (if you are running one) as an account that belongs to the wheel group. According to the grsecurity documentation, none of these features should affect the operation of your software, unless it is very old or poorly written.
High security
To enable nearly all of grsecurity’s features, you can choose the High security level. In addition to the features provided by the lower security levels, this level implements additional /proc restrictions by limiting access to device and CPU information to users who are in the wheel group. The High security level further restricts sandboxed environments by disallowing chmod to set the SUID or SGID bit when operating within such an environment.
Additionally, applications that are running within such an environment will not be allowed to insert loadable modules, perform raw I/O, configure network devices, reboot the system, modify immutable files, or change the system’s time. Choosing this security level also lays out the kernel’s stack randomly, to prevent kernel-based buffer overrun exploits from succeeding. In addition, it hides the kernel’s symbols—making it even more difficult for an intruder to install Trojan code into the running kernel—and logs filesystem mounting, remounting, and unmounting.
The High security level also enables grsecurity’s
PaX code, which enables nonexecutable memory pages, among other things. Enabling this causes many buffer overrun exploits to fail, since any code injected into the stack through an overrun will be unable to execute. It is still possible to exploit a program with buffer overrun vulnerabilities, although this is made much more difficult by grsecurity’s address space layout randomization features. However, some programs—such as XFree86, wine, and Java virtual machines—expect that the memory addresses returned by malloc() will be executable. Since PaX breaks this behavior, enabling it will cause those programs and others that depend on it to fail.
Luckily, PaX can be disabled on a per-program basis with the
paxctl utility (http://pax.grsecurity.net). For instance, to disable nonexecutable memory for a given program, you can run a command similar to this one:
# paxctl -ps /usr/bin/java
Other programs also make use of special GCC features, such as trampoline functions, which allow a programmer to define a small function within a function so that the defined function is visible only to the enclosing function. Unfortunately, GCC puts the trampoline function’s code on the stack, so PaX will break any programs that rely on this. However, PaX can provide emulation for trampoline functions, which can be enabled on a per-program basis with paxctl by using the -E switch.
Customized security settings
If you do not like the sets of features that are enabled with any of the predefined security levels, you can just set the kernel option to Custom and enable only the features you need.
After you’ve set a security level or enabled the specific options you want to use, just recompile your kernel and modules as you normally would:
#make clean && make bzImage#make modules && make modules_install
Then, install your new kernel and reboot with it. In addition to the kernel restrictions already in effect, you can now use gradm to set up ACLs for your system [Hack #14].
As you can see, grsecurity is a complex but tremendously useful modification of the Linux kernel. For more detailed information on installing and configuring the patches, consult the extensive documentation at http://www.grsecurity.net/papers.php.
Restrict Applications with grsecurity
Use Linux capabilities and grsecurity’s ACLs to restrict applications on your system.
Now that you have installed the grsecurity patch [Hack #13], you’ll probably want to make use of its flexible Role-Based Access Controls (RBAC) system to further restrict the privileged applications on your system, beyond what grsecurity’s kernel security features provide.
Tip
If you’re just joining us and are not familiar with grsecurity, read “Lock Down Your Kernel with grsecurity” [Hack #13] first.
To restrict specific applications, you will need to make use of the gradm
utility, which can be downloaded from the main grsecurity site (http://www.grsecurity.net). You can compile and install it in the usual way: unpack the source distribution, change into the directory that it creates, and then run make && make install. This command installs gradm in /sbin, creates the /etc/grsec directory containing a default policy, and installs the manual page.
As part of running make install, you’ll be prompted to set a password that will be used for gradm to authenticate itself with the kernel. You can change the password later by running gradm with the -P option:
# gradm -P
Setting up grsecurity RBAC password
Password:
Re-enter Password:
Password written to /etc/grsec/pw.You’ll also need to set a password for the admin role:
# gradm -P admin
Setting up password for role admin
Password:
Re-enter Password:
Password written to /etc/grsec/pw.Then, use this command to enable grsecurity’s RBAC system:
# /sbin/gradm -E
Once you’re finished setting up your policy, you’ll probably want to add that command to the end of your system startup. Add it to the end of /etc/rc.local or a similar script that is designated for customizing your system startup.
The default policy installed in /etc/grsec/policy is quite restrictive, so you’ll want to create a policy for the services and system binaries that you want to use. For example, after the RBAC system has been enabled, ifconfig
will no longer be able to change interface characteristics, even when run as root:
# /sbin/ifconfig eth0:1 192.168.0.59 up
SIOCSIFADDR: Permission denied
SIOCSIFFLAGS: Permission denied
SIOCSIFFLAGS: Permission deniedThe easiest way to set up a policy for a particular command is to specify that you want to use grsecurity’s learning mode, rather than specifying each one manually. If you’ve enabled RBAC, you’ll need to temporarily disable it for your shell by running gradm -a admin. You’ll then be able to access files within /etc/grsec; otherwise, the directory will be hidden to you.
Add an entry like this to /etc/grsec/policy:
subject /sbin/ifconfig l
/ h
/etc/grsec h
-CAP_ALLThis is about the most restrictive policy possible, because it hides the root directory from the process and removes any privileges that it may need. The l next to the binary that the policy applies to says to use learning mode.
After you’re done editing the policy, you’ll need to disable RBAC and then re-enable it with learning mode:
#gradm -a adminPassword: #gradm -D#gradm -L /etc/grsec/learning.logs -E
Now, try to run the ifconfig command again:
#/sbin/ifconfig eth0:1 192.168.0.59 up#/sbin/ifconfig eth0:1eth0:1 Link encap:Ethernet HWaddr 08:00:46:0C:AA:DF inet addr:192.168.0.59 Bcast:192.168.0.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
When the command succeeds, grsecurity will create learning log entries. You can then use gradm to generate an ACL for the program based on these logs:
#gradm -a adminPassword: #gradm -L /etc/grsec/learning.logs -O stdoutBeginning full learning object reduction for subject /sbin/ifconfig...done. ### THE BELOW SUBJECT(S) SHOULD BE ADDED TO THE DEFAULT ROLE ### subject /sbin/ifconfig { user_transition_allow root group_transition_allow root / h /sbin/ifconfig rx -CAP_ALL +CAP_NET_ADMIN +CAP_SYS_ADMIN }
Now, you can replace the learning policy for /sbin/ifconfig in /etc/grsec/policy with this one, and ifconfig should work. You can then follow this process for each program that needs special permissions to function. Just make sure to try out anything you will want to do with those programs, to ensure that grsecurity’s learning mode will detect that it needs to perform a particular system call or open a specific file.
Using grsecurity to lock down applications can seem like tedious work at first, but it will ultimately create a system that gives each process only the permissions it needs to do its job—no more, no less. When you need to build a highly secured platform, grsecurity can provide finely grained control over just about everything the system can possibly do.
Restrict System Calls with systrace
Keep your programs from performing tasks they weren’t meant to do.
One of the more exciting features in NetBSD and OpenBSD is systrace, a system call access manager. With systrace, a system administrator can specify which programs can make which system calls, and how those calls can be made. Proper use of systrace can greatly reduce the risks inherent in running poorly written or exploitable programs. systrace policies can confine users in a manner completely independent of Unix permissions. You can even define the errors that the system calls return when access is denied, to allow programs to fail in a more proper manner. Proper use of systrace requires a practical understanding of system calls and what functionality programs must have to work properly.
First of all, what exactly are system calls? A system call is a function that lets you talk to the operating-system kernel. If you want to allocate memory, open a TCP/IP port, or perform input/output on the disk, you’ll need to use a system call. System calls are documented in section 2 of the manual pages.
Unix also supports a wide variety of C library calls. These are often confused with system calls but are actually just standardized routines for things that could be written within a program. For example, you could easily write a function to compute square roots within a program, but you could not write a function to allocate memory without using a system call. If you’re in doubt whether a particular function is a system call or a C library function, check the online manual.
You might find an occasional system call that is not documented in the online manual, such as break(). You’ll need to dig into other resources to identify these calls.
Tip
break() is a very old system call used within libc, but not by programmers, so it seems to have escaped being documented in the manpages.
systrace denies all actions that are not explicitly permitted and logs the rejections using syslog. If a program running under systrace has a problem, you can find out which system call the program wants to use and decide whether you want to add it to your policy, reconfigure the program, or live with the error.
systrace has several important pieces: policies, the policy-generation tools, the runtime access management tool, and the sysadmin real-time interface. This hack gives a brief overview of policies; “Create systrace Policies Automatically” [Hack #16] shows how to use the systrace tools.
The systrace(1) manpage includes a full description of the syntax used for policy descriptions, but I generally find it easier to look at some examples of a working policy and then go over the syntax in detail. Since named, the name server daemon, has been a subject of recent security discussions, let’s look at the policy that OpenBSD provides for named.
Before reviewing the named policy, let’s review some commonly known facts about its system-access requirements. Zone transfers and large queries occur on port 53/TCP, while basic lookup services are provided on port 53/UDP. OpenBSD chroots named
into /var/named by default and logs everything to /var/log/messages.
Each systrace policy file is in a file named after the full path of the program, replacing slashes with underscores. The policy file usr_sbin_named contains quite a few entries that allow access beyond binding to port 53 and writing to the system log. The file starts with:
# Policy for named that uses named user and chroots to /var/named # This policy works for the default configuration of named. Policy: /usr/sbin/named, Emulation: native
The Policy statement gives the full path to the program this policy is for. You can’t fool systrace
by giving the same name to a program elsewhere on the system. The Emulation entry shows which Application Binary Interface (ABI) this policy is for. Remember, BSD systems expose ABIs for a variety of operating systems. systrace can theoretically manage system-call access for any ABI, although only native and Linux binaries are supported at the moment.
The remaining lines define a variety of system calls that the program may or may not use. The sample policy for named includes 73 lines of system-call rules. The most basic look like this:
native-accept: permit
When /usr/sbin/named tries to use the accept() system call to accept a connection on a socket, under the native ABI, it is allowed. Other rules are far more restrictive. Here’s a rule for bind(), the system call that lets a program request a TCP/IP port to attach to:
native-bind: sockaddr match "inet-*:53" then permit
sockaddr is the name of an argument taken by the accept() system call. The match keyword tells systrace to compare the given variable with the string inet-*:53, according to the standard shell pattern-matching (globbing) rules. So, if the variable sockaddr matches the string inet-*:53, the connection is accepted. This program can bind to port 53, over both TCP and UDP protocols. If an attacker had an exploit to make named attach a command prompt on a high-numbered port, this systrace
policy would prevent that exploit from working.
At first glance, this seems wrong:
native-chdir: filename eq "/" then permit native-chdir: filename eq "/namedb" then permit
The eq keyword compares one string to another and requires an exact match. If the program tries to go to the root directory, or to the directory /namedb, systrace
will allow it. Why would you possibly want to allow named to access the root directory? The next entry explains why:
native-chroot: filename eq "/var/named" then permit
We can use the native chroot() system call to change our root directory to /var/named, but to no other directory. At this point, the /namedb directory is actually /var/named/namedb. We also know that named logs to syslog. To do this, it will need access to /dev/log:
native-connect: sockaddr eq "/dev/log" then permit
This program can use the native connect() system call to talk to /dev/log and only /dev/log. That device hands the connections off elsewhere.
We’ll also see some entries for system calls that do not exist:
native-fsread: filename eq "/" then permit native-fsread: filename eq "/dev/arandom" then permit native-fsread: filename eq "/etc/group" then permit
systrace
aliases certain system calls with very similar functions into groups. You can disable this functionality with a command-line switch and only use the exact system calls you specify, but in most cases these aliases are quite useful and shrink your policies considerably. The two aliases are fsread
and fswrite. fsread is an alias for stat(), lstat(), readlink(), and access(), under the native and Linux ABIs. fswrite is an alias for unlink(), mkdir(), and rmdir(), in both the native and Linux ABIs. As open() can be used to either read or write a file, it is aliased by both fsread and fswrite, depending on how it is called. So named can read certain /etc files, it can list the contents of the root directory, and it can access the groups file.
systrace
supports two optional keywords at the end of a policy statement: errorcode and log. The errorcode is the error that is returned when the program attempts to access this system call. Programs will behave differently depending on the error that they receive. named will react differently to a “permission denied” error than it will to an “out of memory” error. You can get a complete list of error codes from the errno manpage. Use the error name, not the error number. For example, here we return an error for nonexistent files:
filename sub "<non-existent filename>" then deny[enoent]
If you put the word log at the end of your rule, successful system calls will be logged. For example, if you wanted to log each time named attached to port 53, you could edit the policy statement for the bind() call to read:
native-bind: sockaddr match "inet-*:53" then permit log
You can also choose to filter rules based on user ID and group ID, as the example here demonstrates:
native-setgid: gid eq "70" then permit
This very brief overview covers the vast majority of the rules you will see. For full details on the systrace grammar, read the systrace manpage. If you want some help with creating your policies, you can also use systrace’s automated mode [Hack #16].
Tip
The original article that this hack is based on is available online at http://www.onlamp.com/pub/a/bsd/2003/01/30/Big_Scary_Daemons.html.
Michael Lucas
Create systrace Policies Automatically
Let systrace’s automated mode do your work for you.
In a true paranoid’s ideal world, system administrators would read the source code for each application on their system and be able to build system-call access policies by hand, relying only on their intimate understanding of every feature of the application. Most system administrators don’t have that sort of time, though, and would have better things to do with that time if they did.
Luckily, systrace includes a policy-generation tool that will generate a policy listing for every system call that an application makes. You can use this policy as a starting point to narrow down the access you will allow the application. We’ll use this method to generate a policy for inetd .
Use the -A flag to systrace, and include the full path to the program you want to run:
# systrace -A /usr/sbin/inetd
To pass flags to inetd, add them at the end of the command line.
Then use the program for which you’re developing a policy. This system has ident, daytime, and time services open, so run programs that require those services. Fire up an IRC client to trigger ident requests, and telnet to ports 13 and 37 to get time services. Once you have put inetd through its paces, shut it down. inetd has no control program, so you need to kill it by using the process ID.
Checking the process list will show two processes:
# ps -ax | grep inet
24421 ?? Ixs 0:00.00 /usr/sbin/inetd
12929 ?? Is 0:00.01 systrace -A /usr/sbin/inetdDo not kill the systrace process (PID 12929 in this example); that process has all the records of the system calls that inetd has made. Just kill the inetd process (PID 24421), and the systrace process will exit normally.
Now check your home directory for a .systrace directory, which will contain systrace’s first stab at an inetd policy. Remember, policies are placed in files named after the full path to the program, replacing slashes with underscores.
Here’s the output of ls:
# ls .systrace
usr_libexec_identd usr_sbin_inetdsystrace created two policies, not one. In addition to the expected policy for /usr/sbin/inetd, there’s one for /usr/libexec/identd. This is because inetd implements time services internally, but it needs to call a separate program to service other requests. When inetd spawned identd, systrace captured the identd system calls as well.
By reading the policy, you can improve your understanding of what the program actually does. Look up each system call the program uses, and see if you can restrict access further. You’ll probably want to look for ways to further restrict the policies that are automatically generated. However, these policies make for a good starting point.
Applying a policy to a program is much like creating the systrace policy itself. Just run the program as an argument to systrace, using the -a option:
# systrace -a /usr/sbin/inetd
If the program tries to perform system calls not listed in the policy, they will fail. This may cause the program to behave unpredictably. systrace will log failed entries in /var/log/messages.
To edit a policy, just add the desired statement to the end of the rule list, and it will be picked up. You could do this by hand, of course, but that’s the hard way. systrace includes a tool to let you edit policies in real time, as the system call is made. This is excellent for use in a network operations center environment, where the person responsible for watching the network monitor can also be assigned to watch for system calls and bring them to the attention of the appropriate personnel. You can specify which program you wish to monitor by using systrace’s -p flag. This is called attaching to the program.
For example, earlier we saw two processes containing inetd. One was the actual inetd process, and the other was the systrace process managing inetd. Attach to the systrace process, not the actual program (to use the previous example, this would be PID 12929), and give the full path to the managed program as an argument:
# systrace -p 12929 /usr/sbin/inetd
At first nothing will happen. When the program attempts to make an unauthorized system call, however, a GUI will pop up. You will have the option to allow the system call, deny the system call, always permit the call, or always deny it. The program will hang until you make a decision, however, so decide quickly.
Note that these changes will only take effect so long as the current process is running. If you restart the program, you must also restart the attached systrace monitor, and any changes you previously set in the monitor will be gone. You must add those rules to the policy if you want them to be permanent.
Tip
The original article that this hack is based on is available online at http://www.onlamp.com/pub/a/bsd/2003/02/27/Big_Scary_Daemons.html.
Michael Lucas
Control Login Access with PAM
Seize fine-grained control of when and from where your users can access your system.
Traditional Unix authentication doesn’t provide much granularity in limiting a user’s ability to log in. For example, how would you limit the hosts that users can come from when logging into your servers? Your first thought might be to set up TCP wrappers or possibly firewall rules [Hack #44].
But what if you want to allow some users to log in from a specific host, but disallow others from logging in from it? Or what if you want to prevent some users from logging in at certain times of the day because of daily maintenance, but allow others (e.g., administrators) to log in at any time they wish? To get this working with every service that might be running on your system, you would traditionally have to patch each of them to support this new functionality. This is where pluggable authentication modules (PAM) enters the picture.
PAM allows for just this sort of functionality (and more) without the need to patch all of your services. PAM has been available for quite some time under Linux, FreeBSD, and Solaris and is now a standard component of the traditional authentication facilities on these platforms. Many services that need to use some sort of authentication now support PAM.
Modules are configured for services in a stack, with the authentication process proceeding from top to bottom as the access checks complete successfully. You can build a custom stack for any service by creating a file in /etc/pam.d with the same name as the service. If you need even more granularity, you can include an entire stack of modules by using the pam_stack
module. This allows you to specify another external file containing a stack. If a service does not have its own configuration file in /etc/pam.d, it will default to using the stack specified in /etc/pam.d/other.
There are several types of entries available when configuring a service for use with PAM. These types allow you to specify whether a module provides authentication, access control, password change control, or session setup and teardown. Right now, we are interested in only one of the types: the account type. This entry type allows you to specify modules that will control access to accounts that have been authenticated.
In addition to the service-specific configuration files, some modules have extended configuration information that can be specified in files within the /etc/security directory. For this hack, we’ll mainly use two of the most useful modules of this type: pam_access
and pam_time.
Limiting Access by Origin
The
pam_access module allows you to limit where a user or group of users may log in from. To make use of it, you’ll first need to configure the service with which you want to use the module. You can do this by editing the service’s PAM config file in /etc/pam.d.
Here’s an example of what /etc/pam.d/login might look like:
#%PAM-1.0 auth required pam_securetty.so auth required pam_stack.so service=system-auth auth required pam_nologin.so account required pam_stack.so service=system-auth password required pam_stack.so service=system-auth session required pam_stack.so service=system-auth session optional pam_console.so
Notice the use of the pam_stack module; it includes the stack contained within the
system-auth file. Let’s see what’s inside /etc/pam.d/system-auth:
#%PAM-1.0 # This file is auto-generated. # User changes will be destroyed the next time authconfig is run. auth required /lib/security/$ISA/pam_env.so auth sufficient /lib/security/$ISA/pam_unix.so likeauth nullok auth required /lib/security/$ISA/pam_deny.so account required /lib/security/$ISA/pam_unix.so password required /lib/security/$ISA/pam_cracklib.so retry=3 type= password sufficient /lib/security/$ISA/pam_unix.so nullok use_authtok md5 shadow password required /lib/security/$ISA/pam_deny.so session required /lib/security/$ISA/pam_limits.so session required /lib/security/$ISA/pam_unix.so
To add the pam_access module to the login service, you could add another account entry to the login configuration file, which would, of course, just enable the module for the login service. Alternatively, you could add the module to the system-auth file, which would enable it for most of the PAM-aware services on the system.
To add pam_access to the login service (or any other service, for that matter), simply add a line like this to the service’s configuration file after any preexisting account entries:
account required pam_access.so
Now that you’ve enabled the pam_access module for our services, you can edit /etc/security/access.conf to control how the module behaves. Each entry in the file can specify multiple users, groups, and hostnames to which the entry applies, and specify whether it’s allowing or disallowing remote or local access. When pam_access is invoked by an entry in a service configuration file, it looks through the lines of access.conf and stops at the first match it finds. Thus, if you want to create default entries to fall back on, you’ll want to put the more specific entries first, with the general entries following them.
The general form of an entry in access.conf is:
permission
: users
: origins
where permission can be either + or -. This denotes whether the rule grants or denies access, respectively.
The
users portion allows you to specify a list of users or groups, separated by whitespace. In addition to simply listing users in this portion of the entry, you can use the form user
@
host, where host is the local hostname of the machine being logged into. This allows you to use a single configuration file across multiple machines, but still specify rules pertaining to specific machines.
The
origins portion is compared against the origin of the access attempt. Hostnames can be used for remote origins, and the special LOCAL keyword can be used for local access. Instead of explicitly specifying users, groups, or origins, you can also use the ALL and EXCEPT keywords to perform set operations on any of the lists.
Here’s a simple example of locking out the user andrew (Eep! That’s me!) from a host named colossus:
- : andrew : colossus
Note that if a group that shares its name with a user is specified, the module will interpret the rule as applying to both the user and the group.
Restricting Access by Time
Now that we’ve covered how to limit where a user may log in from and how to set up a PAM module, let’s take a look at how to limit what time a user may log in by using the pam_time module. To configure this module, you need to edit /etc/security/time.conf. The format for the entries in this file is a little more flexible than that of access.conf, thanks to the availability of the NOT (!), AND (&), and OR (|) operators.
The general form for an entry in time.conf is:
services;devices;users;times
The services portion of the entry specifies what PAM-enabled service will be regulated. You can usually get a full list of the available services by looking at the contents of your /etc/pam.d directory.
For instance, here are the contents of /etc/pam.d on a Red Hat Linux system:
$ ls -1 /etc/pam.d
authconfig
chfn
chsh
halt
internet-druid
kbdrate
login
neat
other
passwd
poweroff
ppp
reboot
redhat-config-mouse
redhat-config-network
redhat-config-network-cmd
redhat-config-network-druid
rhn_register
setup
smtp
sshd
su
sudo
system-auth
up2date
up2date-config
up2date-nox
vlockTo set up pam_time for use with any of these services, you’ll need to add a line like this to the file in /etc/pam.d that corresponds to the service you want to regulate:
account required /lib/security/$ISA/pam_time.so
The devices portion specifies the terminal device from which the service is being accessed. For console logins, you can use !ttyp*
, which specifies all TTY devices except for pseudo-TTYs. If you want the entry to affect only remote logins, use ttyp*. You can restrict it to all users (console, remote, and X11) by using tty*.
For the users portion of the entry, you can specify a single user or a list of users, separated with
| characters.
Finally, the times portion is used to specify the times when the rule will apply. Again, you can stipulate a single time range or multiple ranges, separated with | characters. Each time range is specified by a combination of one or more two-character abbreviations denoting the day or days that the rule will apply, followed by a range of hours for those days.
The abbreviations for the days of the week are Mo, Tu, We, Th, Fr, Sa, and Su. For convenience, you can use Wk to specify weekdays, Wd to specify the weekend, or Al to specify every day of the week. If using the latter three abbreviations, bear in mind that repeated days will be subtracted from the set of days to which the rule applies (e.g., WkSu would effectively be just Sa). The range of hours is simply specified as two 24-hour times, minus the colons, separated by a dash (e.g., 0630-1345 is 6:30 A.M. to 1:45 P.M.).
If you wanted to disallow access to the user andrew from the local console on weekends and during the week after hours, you could use an entry like this:
system-auth;!ttyp*;andrew;Wk1700-0800|Wd0000-2400
Or perhaps you want to limit remote logins through SSH during a system maintenance window lasting from 7 P.M. Friday to 7 A.M. Saturday, but you want to allow a sysadmin to log in:
sshd;ttyp*;!andrew;Fr1900-0700
As you can see, there’s a lot of flexibility for creating entries, thanks to the logical Boolean operators that are available. Just make sure that you remember to configure the service file in /etc/pam.d for use with pam_time when you create entries in /etc/security/time.conf.
Restrict Users to SCP and SFTP
Provide restricted file-transfer services to your users without resorting to FTP.
Sometimes, you’d like to provide file-transfer services to your users without setting up an FTP server. This leaves the option of letting them transfer files to and from your server using SCP or SFTP. However, because of the way OpenSSH’s sshd implements these subsystems, it’s usually impossible to do this without also giving the user shell access to the system. When an SCP or SFTP session is started, the daemon executes another executable to handle the request using the user’s shell, which means the user needs a valid shell.
One way to get around this problem is to use a custom shell that is capable of executing only the SCP and SFTP subsystems. One such program is
rssh (http://www.pizzashack.org/rssh/), which has the added benefit of being able to chroot(), enabling you to limit access to the server’s filesystem as well.
Setting Up rssh
To set up rssh, first download the compressed archive from program’s web site and unpack it. Then, run the standard ./configure and make:
$tar xfz rssh-2.3.2.tar.gz$cd rssh-2.3.2$./configure && make
Once rssh has finished compiling, become root and run make install. You can now create an account and set its shell to rssh. Try logging into it via SSH. You’ll notice that the connection is closed before you’re able to completely log in. You should also see this before the connection is closed:
This account is restricted by rssh. This user is locked out. If you believe this is in error, please contact your system administrator.
You should get similar results if you try to access the account with scp or sftp, because rssh’s default configuration locks out everything. To enable SFTP and SCP, add the following lines to your rssh.conf file (the file should be located in /usr/local/etc or somewhere similar):
allowsftp allowscp
Now, try accessing the account with sftp:
$ sftp rssh_test@freebsd5-vm1
Connecting to freebsd5-vm1...
Password:
sftp> Configuring chroot()
This has been easy so far. Now comes the hard part: configuring chroot(). Here you have two options: you can specify a common environment for all users that have been configured to use rssh, or you can create user-specific chroot() environments.
To create a global environment, you just need to specify the directory to chroot() by using the chrootpath configuration directive. For instance, to have rssh
chroot() to /var/rssh_chroot, set up a proper environment there and add the following line to your rssh.conf file:
chrootpath=/var/rssh_chroot
Setting up rssh to use chroot() has one major caveat, though. Supporting chroot() requires the use of an SUID helper binary to perform the chroot() call for the user that has logged in. This is because only the root user can issue a chroot() call. This binary is extremely limited; all it does is perform the chroot() and take steps to ensure that it can only be executed by rssh. However, it’s something to keep in mind if you consider this a risk.
For a user-specific chroot() environment, you can add a line like this:
user=rssh_test:077:00011:/var/rssh_chroot
The first set of numbers after the username is the umask. The second set of digits is actually a bit-vector specifying the allowed means of access. From left to right, these are Rsync, Rdist, CVS, SFTP, and SCP. In the previous example, only SFTP and SCP are allowed.
Finally, the last portion of the line specifies which directory to chroot() to. One thing allowed by this configuration syntax that isn’t immediately obvious is the ability to specify per-user configurations without a directory to chroot() to: simply omit the directory. So, if you just want to allow one user to use only SCP but not SFTP (so they can’t browse the filesystem), you can add a line similar to this one:
user=rssh_test:077:00001
Now, all you need to do is set up the sandbox environment. Create a bin directory within the root directory of your sandbox and copy /bin/sh into it. Then, copy all of the requisite libraries for it to their proper places:
#cd /var/rssh_chroot#mkdir bin && cp /bin/sh bin#ldd bin/shbin/sh: libedit.so.4 => /lib/libedit.so.4 (0x2808e000) libncurses.so.5 => /lib/libncurses.so.5 (0x280a1000) libc.so.5 => /lib/libc.so.5 (0x280e0000) #mkdir lib#cp /lib/libedit.so.4 /lib/libncurses.so.5 /lib/libc.so.5 lib
Now, copy your scp and sftp binaries and all of their requisite libraries to their proper locations. Here is an example of doing so for scp (sftp should require the same libraries):
#ldd usr/bin/scpusr/bin/scp: libssh.so.2 => /usr/lib/libssh.so.2 (0x2807a000) libcrypt.so.2 => /lib/libcrypt.so.2 (0x280a9000) libcrypto.so.3 => /lib/libcrypto.so.3 (0x280c1000) libz.so.2 => /lib/libz.so.2 (0x281b8000) libc.so.5 => /lib/libc.so.5 (0x281c8000) libgssapi.so.7 => /usr/lib/libgssapi.so.7 (0x282a2000) libkrb5.so.7 => /usr/lib/libkrb5.so.7 (0x282b0000) libasn1.so.7 => /usr/lib/libasn1.so.7 (0x282e8000) libcom_err.so.2 => /usr/lib/libcom_err.so.2 (0x28309000) libmd.so.2 => /lib/libmd.so.2 (0x2830b000) libroken.so.7 => /usr/lib/libroken.so.7 (0x28315000) #cp /lib/libcrypt.so.2 /lib/libcrypto.so.3 /lib/libz.so.2 \/lib/libc.so.5 /lib/libmd.so.2 lib#mkdir -p usr/lib#cp /usr/lib/libssh.so.2 /usr/lib/libgssapi.so.7 /usr/lib/libkrb5.so.7 \/usr/lib/libasn1.so.7 /usr/lib/libcom_err.so.2 \/usr/lib/libroken.so.7 usr/lib/
Next, copy rssh_chroot_helper to the proper place and copy your dynamic linker (the program that is responsible for issuing the chroot() call):
#mkdir -p usr/local/libexec#cp /usr/local/libexec/rssh_chroot_helper usr/local/libexec#mkdir libexec && cp /libexec/ld-elf.so.1 libexec/
Tip
This example is for FreeBSD. For Linux, you’ll likely want to use /lib/ld-linux.so.2.
Then, recreate /dev/null in your chroot() environment:
#ls -la /dev/nullcrw-rw-rw- 1 root wheel 2, 2 Apr 10 16:22 /dev/null #mkdir dev && mknod dev/null c 2 2 && chmod a+w dev/null
Now create a dummy password file:
# mkdir etc && cp /etc/passwd etc
Edit the password file to remove all the entries for other accounts, leaving only the accounts that will be used in the jail.
Now, try connecting with sftp:
$sftp rssh_test@freebsd5-vm1Connecting to freebsd5-vm1... Password: sftp>ls /etc/etc/. /etc/.. /etc/passwd
All that’s left to do is to create a /dev/log and change your syslogd startup options to listen for log messages on the /dev/log in your chroot() environment. Using the -a option and specifying additional log sockets will usually take care of this:
# /sbin/syslogd -a /home/rssh_test/dev/log
rssh is an incredibly useful tool that can remove the need for insecure legacy services. In addition to supporting SCP and SFTP, it supports CVS, Rdist, and Rsync. Check out the rssh(1) and rssh.conf(5) manual pages for more information on setting those up.
Use Single-Use Passwords for Authentication
Use one-time passwords to access servers from possibly untrustworthy computers and to limit access to accounts.
Generally, it’s best not to use untrusted computers to access a server. The pitfalls are plentiful. However, you can mitigate some part of the risk by using one-time passwords (OTPs) for authentication. An even more interesting use for them, though, is to limit access to accounts used for file transfer.
That is, if you want to provide a file to someone or allow someone to upload a file only once, you can set up an account to use OTPs. Once the person you’ve given the password to has done her thing (and disconnected), she no longer has access to the account. This works well with rssh [Hack #18], since it prevents the user from accessing the system outside of a specified directory and from generating additional OTPs.
For this purpose, FreeBSD provides One-time Passwords in Everything (OPIE), which is thoroughly supported throughout the system. OpenBSD uses a similar system called S/Key.
OPIE Under FreeBSD
Setting up an account to use OPIE under FreeBSD is fairly simple. First, run opiepasswd to create an entry in /etc/opiepasswd and to seed the OTP generator:
$ opiepasswd -c
Adding andrew:
Only use this method from the console; NEVER from remote. If you are using
telnet, xterm, or a dial-in, type ^C now or exit with no password.
Then run opiepasswd without the -c parameter.
Using MD5 to compute responses.
Enter new secret pass phrase:
Again new secret pass phrase:
ID andrew OTP key is 499 fr8266
HOVE TEE LANG FOAM ALEC THEThe 499 in the output is the OTP sequence, and fr8266 is the seed to use with it in generating the OTP. Once the sequence reaches 0, you’ll need to run opiepasswd again to reseed the system.
The -c option tells it to accept password input directly. Needless to say, you shouldn’t be setting this up over insecure channels; if you do, you’ll defeat the purpose of OTP. Run this from the local console or over an SSH connection only!
Then, try logging into the system remotely:
$ ssh freebsd5-vm1
otp-md5 497 fr8266 ext
Password: The first line of output is the arguments to supply to opiekey, which is used to generate the proper OTP to use. otp-md5 specifies the hashing algorithm that has been used. As before, 497 specifies the OTP sequence, and fr8266 is the seed.
Now, generate the password:
$ opiekey 497 fr8266
Using the MD5 algorithm to compute response.
Reminder: Don't use opiekey from telnet or dial-in sessions.
Enter secret pass phrase:
DUET SHAW TWIT SKY EM CITETo log in, enter the passphrase that was generated. Once you’ve logged in, you can run opieinfo and see that the sequence number has been decremented:
$ opieinfo
496 fr8266It’s also possible to generate multiple passwords at the same time with opiekey:
$ opiekey -n 5 496 fr8266
Using the MD5 algorithm to compute response.
Reminder: Don't use opiekey from telnet or dial-in sessions.
Enter secret pass phrase:
492: EVIL AMID EVEN CRAB FRAU NULL
493: GEM SURF LONG TOOK NAN FOUL
494: OWN SOB AUK RAIL SEED HUGE
495: GAP THAT LORD LIES BOMB ROUT
496: RON ABEL LIE GWYN TRAY ROARYou might want to do this before traveling, so you can print out the passwords and carry them with you.
Warning
Be sure not to include the hostname on the same sheet of paper. If you do and you lose it, anyone who finds it can easily gain access to your system.
If you have a PDA, another option is to use PilOTP (http://astro.uchicago.edu/home/web/valdes/pilot/pilOTP/), an OTP generator for Palm OS devices, which supports both OPIE and S/Key systems.
S/Key Under OpenBSD
Setting up
S/Key under OpenBSD is similar to setting up OPIE. First, the superuser needs to enable it by running skeyinit -E. Then, as a normal user, run skeyinit again. It will prompt you for your system password and then ask you for a password to initialize the S/Key system:
$ skeyinit
Reminder - Only use this method if you are directly connected
or have an encrypted channel. If you are using telnet,
hit return now and use skeyinit -s.
Password:
[Adding andrew with md5]
Enter new secret passphrase:
Again secret passphrase:
ID andrew skey is otp-md5 100 open66823
Next login password: DOLE WALE MAKE COAT BALE AVIDTo log in, you need to append :skey to your username:
$ ssh andrew:skey@puffy
otp-md5 99 open66823
S/Key Password:Then, in another terminal, run skey and enter the password you entered when you ran skeyinit:
$ skey -md5 99 open66823
Reminder - Do not use this program while logged in via telnet.
Enter secret passphrase:
SOME VENT BUDD GONG TEAR SALTHere’s the output of skeyinfo after logging in:
$ skeyinfo
98 open66823Although it’s not wise to use untrusted computers to access your systems, you can see that one-time passwords can help mitigate the possible ill effects. Additionally, they can have other uses, such as combining them with other components to allow a user to access a protected resource only a limited number of times. With a little ingenuity, you can come up with some other uses, too.
Restrict Shell Environments
Keep your users from shooting themselves (and you) in the foot.
Sometimes a sandboxed environment [Hack #10] is overkill for your needs. But if you want to set up a restricted environment for a group of users that allows them to run only a few particular commands, you’ll have to duplicate all of the libraries and binaries for those commands for each user. This is where restricted shells come in handy. Many shells include such a feature, which is usually invoked by running the shell with the -r switch. While not as secure as a system-call-based sandboxed environment, a restricted shell can work well if you trust your users not to be malicious (but worry that some might be curious to an unhealthy degree).
Some common features of restricted shells are the abilities to prevent a program from changing directories, to allow the execution of commands only using absolute pathnames, and to prohibit executing commands in other subdirectories. In addition to these restrictions, all of the command-line redirection operators are disabled. With these features, restricting the commands a user can execute is as simple as picking and choosing which commands should be available and making symbolic links to them inside the user’s home directory. If a sequence of commands needs to be executed, you can also create shell scripts owned by another user. These scripts will execute in an unrestricted environment and can’t be edited within the restricted environment by the user.
Let’s try running a restricted shell and see what happens:
$bash -rbash: SHELL: readonly variable bash: PATH: readonly variable bash-2.05b$lsbash: ls: No such file or directory bash-2.05b$/bin/lsbash: /sbin/ls: restricted: cannot specify \Q/' in command names bash-2.05b$exit$ln -s /bin/ls .$bash -rbash-2.05b$ls -latotal 24 drwx------ 2 andrew andrew 4096 Oct 20 08:01 . drwxr-xr-x 4 root root 4096 Oct 20 14:16 .. -rw------- 1 andrew andrew 18 Oct 20 08:00 .bash_history -rw-r--r-- 1 andrew andrew 24 Oct 20 14:16 .bash_logout -rw-r--r-- 1 andrew andrew 197 Oct 20 07:59 .bash_profile -rw-r--r-- 1 andrew andrew 127 Oct 20 07:57 .bashrc lrwxrwxrwx 1 andrew andrew 7 Oct 20 08:01 ls -> /bin/ls
Restricted ksh is a little different in that it will allow you to run scripts and binaries that are in your PATH, which can be set before entering the shell:
$rksh$ls -latotal 24 drwx------ 2 andrew andrew 4096 Oct 20 08:01 . drwxr-xr-x 4 root root 4096 Oct 20 14:16 .. -rw------- 1 andrew andrew 18 Oct 20 08:00 .bash_history -rw-r--r-- 1 andrew andrew 24 Oct 20 14:16 .bash_logout -rw-r--r-- 1 andrew andrew 197 Oct 20 07:59 .bash_profile -rw-r--r-- 1 andrew andrew 127 Oct 20 07:57 .bashrc lrwxrwxrwx 1 andrew andrew 7 Oct 20 08:01 ls -> /bin/ls $which ls/bin/ls $exit
This worked because /bin was in the PATH before we invoked ksh. Now let’s change the PATH and run rksh again:
$export PATH=.$/bin/rksh$/bin/ls/bin/rksh: /bin/ls: restricted $exit$ln -s /bin/ls .$ls -latotal 24 drwx------ 2 andrew andrew 4096 Oct 20 08:01 . drwxr-xr-x 4 root root 4096 Oct 20 14:16 .. -rw------- 1 andrew andrew 18 Oct 20 08:00 .bash_history -rw-r--r-- 1 andrew andrew 24 Oct 20 14:16 .bash_logout -rw-r--r-- 1 andrew andrew 197 Oct 20 07:59 .bash_profile -rw-r--r-- 1 andrew andrew 127 Oct 20 07:57 .bashrc lrwxrwxrwx 1 andrew andrew 7 Oct 20 08:01 ls -> /bin/ls
Restricted shells are incredibly easy to set up and can provide minimal restricted access. They might not be able to keep out determined attackers, but they certainly make a hostile user’s job much more difficult.
Enforce User and Group Resource Limits
Make sure resource-hungry users don’t bring down your entire system.
Whether it’s
through malicious intent or an unintentional slip, having a user bring your system down to a slow crawl by using too much memory or CPU time is no fun at all. One popular way of limiting resource usage is to use the ulimit
command. This method relies on a shell to limit its child processes, and it is difficult to use when you want to give different levels of usage to different users and groups. Another, more flexible way of limiting resource usage is with the PAM module pam_limits.
pam_limits is preconfigured on most systems that have PAM [Hack #17] installed. All you should need to do is edit /etc/security/limits.conf to configure specific limits for users and groups.
The limits.conf configuration file consists of single-line entries describing a single type of limit for a user or group of users. The general format for an entry is:
domain type resource value
The domain portion specifies to whom the limit applies. You can specify single users here by name, and groups can be specified by prefixing the group name with an @. In addition, you can use the wildcard character * to apply the limit globally to all users except for root. The type portion of the entry specifies whether it is a soft or hard resource limit. The user can increase soft limits, whereas hard limits can be changed only by root.
You can specify many types of resources for the resource portion of the entry. Some of the more useful ones are cpu, memlock, nproc, and fsize. These allow you to limit CPU time, total locked-in memory, number of processes, and file size, respectively. CPU time is expressed in minutes, and sizes are in kilobytes. Another useful limit is maxlogins, which allows you to specify the maximum number of concurrent logins that are permitted.
One nice feature of pam_limits is that it can work together with ulimit to allow the user to raise her limit from the soft limit to the imposed hard limit.
Let’s try a quick test to see how it works. First, we’ll limit the number of open files for the guest user by adding these entries to limits.conf:
guest soft nofile 1000 guest hard nofile 2000
Now the guest account has a soft limit of 1,000 concurrently open files and a hard limit of 2,000. Let’s test it out:
#su - guest$ulimit -acore file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited file size (blocks, -f) unlimited max locked memory (kbytes, -l) unlimited max memory size (kbytes, -m) unlimited open files (-n) 1000 pipe size (512 bytes, -p) 8 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes (-u) 1024 virtual memory (kbytes, -v) unlimited $ulimit -n 2000$ulimit -n2000 $ulimit -n 2001-bash: ulimit: open files: cannot modify limit: Operation not permitted
There you have it. In addition to open files, you can create resource limits for any number of other resources and apply them to specific users or entire groups. As you can see, pam_limits is quite powerful and useful in that it doesn’t rely upon the shell for enforcement.
Automate System Updates
Patch security holes in a timely manner to prevent intrusions.
Updating and patching your systems in a timely manner is one of the most important things you can do to help protect them from the deluge of newly discovered security vulnerabilities. Unfortunately, this task often gets pushed to the wayside in favor of “more pressing” issues, such as performance tuning, hardware maintenance, and software debugging. In some circles, it’s viewed as a waste of time and overhead that doesn’t contribute to the primary function of a system. Coupled with management demands to maximize production, the task of keeping a system up-to-date is often pushed even further down on the to-do list.
Updating a system can be very repetitive and time-consuming if you’re not using scripting to automate it. Fortunately, most Linux distributions make their updated packages available for download from a standard online location, and you can monitor that location for changes and automatically detect and download the new updates when they’re made available. To demonstrate how to do this on an RPM-based distribution, we’ll use AutoRPM (http://www.autorpm.org).
AutoRPM is a powerful Perl script that allows you to monitor multiple FTP sites for changes. It will automatically download new or changed packages and either install them automatically or alert you so that you may do so. In addition to monitoring single FTP sites, you can also monitor a pool of mirror sites, to ensure that you still get your updates if the FTP server is busy. AutoRPM will monitor busy FTP servers and keep track of how many times connections to them have been attempted. Using this information, it assigns internal scores to each of the FTP sites configured within a given pool, with the outcome that the server in the pool that is available most often will be checked first.
To use AutoRPM, download the latest package and install it like this:
# rpm -ivh autorpm-3.3.3-1.noarch.rpm
Although a tarball is also available, installation is a little trickier than the typical make; make install, so it is recommended that you stick to installing from the RPM package.
By default AutoRPM is configured to monitor for updated packages for Red Hat’s Linux distribution, but you’ll probably want to change this to use Fedora or another RPM-based distribution. To do this, open the AutoRPM configuration file, /etc/autorpm.d/autorpm.conf, and find the following section:
######################## BEGIN Red Hat Linux #################################
# This automatically determines the version of Red Hat Linux
# You have... you can comment this out and define it yourself
# if you want to
Eval_Var("RHVersion", "sed 's/\(Red Hat Linux \)\?release \([^ ]*\) (.*)/\2/' /etc/redhat-release");
#Set_Var("RHVersion", "9.0");
# Look for official Red Hat updates
# (won't automatically install anything unless you edit the file)
Config_File("/etc/autorpm.d/redhat-updates.conf");
########################## END Red Hat Linux #################################Comment out the Eval_var, Set_Var, and Config_File lines. In the next section, uncomment the Eval_Var and Config_File lines to make it like this:
######################## BEGIN Fedora Linux #################################
# This automatically determines your version of Fedora Linux
Eval_Var("FedoraVersion", "rpm -q fedora-release | awk -F'-' {'print $3'}");
# Look for official Fedora updates
# (won't automatically install anything unless you edit the file)
Config_File("/etc/autorpm.d/fedora-updates.conf");
########################## END Fedora Linux #################################After you’ve done that, you can add a crontab entry for /etc/autorpm.d/autorpm.cron to schedule AutoRPM to run at a regular interval. When it runs, it will automatically download any pending updates.
Another way to perform automatic updates is to use the
yum program. By default, yum both downloads and installs updates, but you can change this behavior by installing the
downloadonly plug-in (http://linux.duke.edu/projects/yum/download/yum-utils/), causing yum to skip the installation step. You can then use the following command to download any updates that are available:
# yum --downloadonly -y update
Put this command in a crontab entry so that it will run at a regular interval. Then, when you’ve reviewed the updates that you’ve downloaded, you can use the usual yum update command to install them.
You can achieve similar results on Debian-based systems with apt-get -d -y
upgrade. This command downloads any pending updates to packages that you have installed. When you’ve decided to install them, you can do so by running apt-get upgrade.
As you can see, there are many ways that you can keep a system updated with the latest fixed packages. Whatever you decide to do, it’s important to stay current with operating system patches because of the security fixes they contain. If you fall behind, you’re a much easier target for an attacker.
Get Network Security Hacks, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

