Chunking
The basic technique we will use for entity recognition is chunking, which segments and labels multitoken sequences as illustrated in Figure 7-2. The smaller boxes show the word-level tokenization and part-of-speech tagging, while the large boxes show higher-level chunking. Each of these larger boxes is called a chunk. Like tokenization, which omits whitespace, chunking usually selects a subset of the tokens. Also like tokenization, the pieces produced by a chunker do not overlap in the source text.
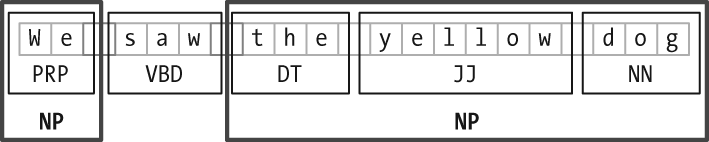
Figure 7-2. Segmentation and labeling at both the Token and Chunk levels.
In this section, we will explore chunking in some depth, beginning with the definition and representation of chunks. We will see regular expression and n-gram approaches to chunking, and will develop and evaluate chunkers using the CoNLL-2000 Chunking Corpus. We will then return in Sections and to the tasks of named entity recognition and relation extraction.
Noun Phrase Chunking
We will begin by considering the task of noun phrase chunking, or NP-chunking, where we search for chunks
corresponding to individual noun phrases. For example, here is some
Wall Street Journal text with NP-chunks marked using brackets:
Example 7-2.
[ The/DT market/NN ] for/IN [ system-management/NN software/NN ] for/IN [ Digital/NNP ] [ ’s/POS hardware/NN ] is/VBZ fragmented/JJ enough/RB that/IN [ a/DT giant/NN ] such/JJ as/IN [ Computer/NNP ...
Get Natural Language Processing with Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

