This section discusses more advanced concepts, which you may prefer to skip on the first time through this chapter.
A major part of algorithmic problem solving is selecting or adapting an appropriate algorithm for the problem at hand. Sometimes there are several alternatives, and choosing the best one depends on knowledge about how each alternative performs as the size of the data grows. Whole books are written on this topic, and we only have space to introduce some key concepts and elaborate on the approaches that are most prevalent in natural language processing.
The best-known strategy is known as divide-and-conquer. We attack a problem of size n by dividing it into two problems of size n/2, solve these problems, and combine their results into a solution of the original problem. For example, suppose that we had a pile of cards with a single word written on each card. We could sort this pile by splitting it in half and giving it to two other people to sort (they could do the same in turn). Then, when two sorted piles come back, it is an easy task to merge them into a single sorted pile. See Figure 4-3 for an illustration of this process.
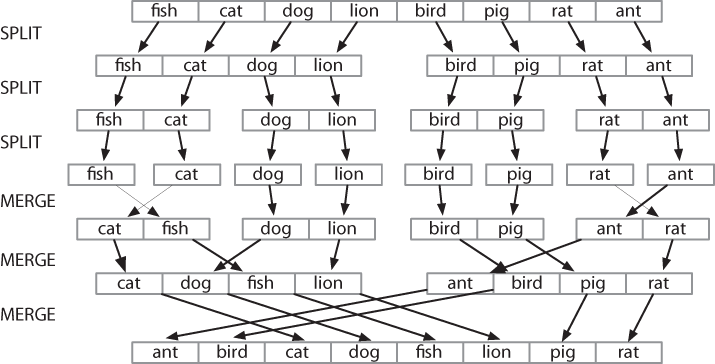
Figure 4-3. Sorting by divide-and-conquer: To sort an array, we split it in half and sort each half (recursively); we merge each sorted half back into a whole list (again recursively); this algorithm is known as “Merge Sort.”
Another example is the process of looking up a word in a dictionary. We open the book somewhere around the middle and compare our word with the current page. If it’s earlier in the dictionary, we repeat the process on the first half; if it’s later, we use the second half. This search method is called binary search since it splits the problem in half at every step.
In another approach to algorithm design, we attack a problem by transforming it into an instance of a problem we already know how to solve. For example, in order to detect duplicate entries in a list, we can pre-sort the list, then scan through it once to check whether any adjacent pairs of elements are identical.
The earlier examples of sorting and searching have a striking property: to solve a problem of size n, we have to break it in half and then work on one or more problems of size n/2. A common way to implement such methods uses recursion. We define a function f, which simplifies the problem, and calls itself to solve one or more easier instances of the same problem. It then combines the results into a solution for the original problem.
For example, suppose we have a set of n words, and want to calculate how many different ways they can be combined to make a sequence of words. If we have only one word (n=1), there is just one way to make it into a sequence. If we have a set of two words, there are two ways to put them into a sequence. For three words there are six possibilities. In general, for n words, there are n × n-1 × … × 2 × 1 ways (i.e., the factorial of n). We can code this up as follows:
>>> def factorial1(n): ... result = 1 ... for i in range(n): ... result *= (i+1) ... return result
However, there is also a recursive algorithm for solving this problem, based on the following observation. Suppose we have a way to construct all orderings for n-1 distinct words. Then for each such ordering, there are n places where we can insert a new word: at the start, the end, or any of the n-2 boundaries between the words. Thus we simply multiply the number of solutions found for n-1 by the value of n. We also need the base case, to say that if we have a single word, there’s just one ordering. We can code this up as follows:
>>> def factorial2(n): ... if n == 1: ... return 1 ... else: ... return n * factorial2(n-1)
These two algorithms solve the same problem. One uses iteration
while the other uses recursion. We can use recursion to navigate a
deeply nested object, such as the WordNet hypernym hierarchy. Let’s
count the size of the hypernym hierarchy rooted at a given synset
s. We’ll do this by finding the size of each
hyponym of s, then adding these together (we will
also add 1 for the synset itself). The following function size1() does this work; notice that the body
of the function includes a recursive call to size1():
>>> def size1(s): ... return 1 + sum(size1(child) for child in s.hyponyms())
We can also design an iterative solution to this problem which
processes the hierarchy in layers. The first layer is the synset
itself ![]() , then all the hyponyms of
the synset, then all the hyponyms of the hyponyms. Each time through
the loop it computes the next layer by finding the hyponyms of
everything in the last layer
, then all the hyponyms of
the synset, then all the hyponyms of the hyponyms. Each time through
the loop it computes the next layer by finding the hyponyms of
everything in the last layer ![]() . It
also maintains a total of the number of synsets encountered so far
. It
also maintains a total of the number of synsets encountered so far
![]() .
.
>>> def size2(s): ... layer = [s]... total = 0 ... while layer: ... total += len(layer)
... layer = [h for c in layer for h in c.hyponyms()]
... return total
Not only is the iterative solution much longer, it is harder to
interpret. It forces us to think procedurally, and keep track of what
is happening with the layer and
total variables through time. Let’s
satisfy ourselves that both solutions give the same result. We’ll use
a new form of the import statement, allowing us to abbreviate the name
wordnet to wn:
>>> from nltk.corpus import wordnet as wn >>> dog = wn.synset('dog.n.01') >>> size1(dog) 190 >>> size2(dog) 190
As a final example of recursion, let’s use it to
construct a deeply nested object. A letter trie is a data structure that can be
used for indexing a lexicon, one letter at a time. (The name is based
on the word retrieval.) For example, if trie contained a letter trie, then trie['c'] would be a smaller trie which held
all words starting with c. Example 4-6 demonstrates the recursive process of building
a trie, using Python dictionaries (Mapping Words to Properties Using Python Dictionaries). To insert the word
chien (French for dog), we
split off the c and recursively insert
hien into the sub-trie trie['c']. The recursion continues until
there are no letters remaining in the word, when we store the intended
value (in this case, the word dog).
Example 4-6. Building a letter trie: A recursive function that builds a nested dictionary structure; each level of nesting contains all words with a given prefix, and a sub-trie containing all possible continuations.
def insert(trie, key, value):
if key:
first, rest = key[0], key[1:]
if first not in trie:
trie[first] = {}
insert(trie[first], rest, value)
else:
trie['value'] = value>>> trie = nltk.defaultdict(dict) >>> insert(trie, 'chat', 'cat') >>> insert(trie, 'chien', 'dog') >>> insert(trie, 'chair', 'flesh') >>> insert(trie, 'chic', 'stylish') >>> trie = dict(trie) # for nicer printing >>> trie['c']['h']['a']['t']['value'] 'cat' >>> pprint.pprint(trie) {'c': {'h': {'a': {'t': {'value': 'cat'}}, {'i': {'r': {'value': 'flesh'}}}, 'i': {'e': {'n': {'value': 'dog'}}} {'c': {'value': 'stylish'}}}}}
Caution!
Despite the simplicity of recursive programming, it comes with a cost. Each time a function is called, some state information needs to be pushed on a stack, so that once the function has completed, execution can continue from where it left off. For this reason, iterative solutions are often more efficient than recursive solutions.
We can sometimes significantly speed up the execution of a program by building an auxiliary data structure, such as an index. The listing in Example 4-7 implements a simple text retrieval system for the Movie Reviews Corpus. By indexing the document collection, it provides much faster lookup.
Example 4-7. A simple text retrieval system.
def raw(file):
contents = open(file).read()
contents = re.sub(r'<.*?>', ' ', contents)
contents = re.sub('\s+', ' ', contents)
return contents
def snippet(doc, term): # buggy
text = ' '*30 + raw(doc) + ' '*30
pos = text.index(term)
return text[pos-30:pos+30]
print "Building Index..."
files = nltk.corpus.movie_reviews.abspaths()
idx = nltk.Index((w, f) for f in files for w in raw(f).split())
query = ''
while query != "quit":
query = raw_input("query> ")
if query in idx:
for doc in idx[query]:
print snippet(doc, query)
else:
print "Not found"A more subtle example of a space-time trade-off involves replacing the tokens of a corpus with integer identifiers. We create a vocabulary for the corpus, a list in which each word is stored once, then invert this list so that we can look up any word to find its identifier. Each document is preprocessed, so that a list of words becomes a list of integers. Any language models can now work with integers. See the listing in Example 4-8 for an example of how to do this for a tagged corpus.
Example 4-8. Preprocess tagged corpus data, converting all words and tags to integers.
def preprocess(tagged_corpus):
words = set()
tags = set()
for sent in tagged_corpus:
for word, tag in sent:
words.add(word)
tags.add(tag)
wm = dict((w,i) for (i,w) in enumerate(words))
tm = dict((t,i) for (i,t) in enumerate(tags))
return [[(wm[w], tm[t]) for (w,t) in sent] for sent in tagged_corpus]Another example of a space-time trade-off is maintaining a vocabulary list. If you need to process an input text to check that all words are in an existing vocabulary, the vocabulary should be stored as a set, not a list. The elements of a set are automatically indexed, so testing membership of a large set will be much faster than testing membership of the corresponding list.
We can test this claim using the timeit module. The Timer class has two parameters: a statement
that is executed multiple times, and setup code that is executed once
at the beginning. We will simulate a vocabulary of 100,000 items using
a list ![]() or set
or set ![]() of integers. The test statement will
generate a random item that has a 50% chance of being in the
vocabulary
of integers. The test statement will
generate a random item that has a 50% chance of being in the
vocabulary ![]() .
.
>>> from timeit import Timer >>> vocab_size = 100000 >>> setup_list = "import random; vocab = range(%d)" % vocab_size
Performing 1,000 list membership tests takes a total of 2.8 seconds, whereas the equivalent tests on a set take a mere 0.0037 seconds, or three orders of magnitude faster!
Dynamic programming is a general technique for designing algorithms which is widely used in natural language processing. The term “programming” is used in a different sense to what you might expect, to mean planning or scheduling. Dynamic programming is used when a problem contains overlapping subproblems. Instead of computing solutions to these subproblems repeatedly, we simply store them in a lookup table. In the remainder of this section, we will introduce dynamic programming, but in a rather different context to syntactic parsing.
Pingala was an Indian author who lived around the 5th century B.C., and wrote a treatise on Sanskrit prosody called the Chandas Shastra. Virahanka extended this work around the 6th century A.D., studying the number of ways of combining short and long syllables to create a meter of length n. Short syllables, marked S, take up one unit of length, while long syllables, marked L, take two. Pingala found, for example, that there are five ways to construct a meter of length 4: V4 = {LL, SSL, SLS, LSS, SSSS}. Observe that we can split V4 into two subsets, those starting with L and those starting with S, as shown in Example 4-9.
Example 4-9.
V4 = LL, LSS i.e. L prefixed to each item of V2 = {L, SS} SSL, SLS, SSSS i.e. S prefixed to each item of V3 = {SL, LS, SSS}
With this observation, we can write a little recursive function
called virahanka1() to compute
these meters, shown in Example 4-10. Notice that,
in order to compute V4 we
first compute V3 and
V2. But to compute
V3, we need to first
compute V2 and
V1. This call structure is depicted in Example 4-11.
Example 4-10. Four ways to compute Sanskrit meter: (i) iterative, (ii) bottom-up dynamic programming, (iii) top-down dynamic programming, and (iv) built-in memoization.
def virahanka1(n):
if n == 0:
return [""]
elif n == 1:
return ["S"]
else:
s = ["S" + prosody for prosody in virahanka1(n-1)]
l = ["L" + prosody for prosody in virahanka1(n-2)]
return s + l
def virahanka2(n):
lookup = [[""], ["S"]]
for i in range(n-1):
s = ["S" + prosody for prosody in lookup[i+1]]
l = ["L" + prosody for prosody in lookup[i]]
lookup.append(s + l)
return lookup[n]
def virahanka3(n, lookup={0:[""], 1:["S"]}):
if n not in lookup:
s = ["S" + prosody for prosody in virahanka3(n-1)]
l = ["L" + prosody for prosody in virahanka3(n-2)]
lookup[n] = s + l
return lookup[n]
from nltk import memoize
@memoize
def virahanka4(n):
if n == 0:
return [""]
elif n == 1:
return ["S"]
else:
s = ["S" + prosody for prosody in virahanka4(n-1)]
l = ["L" + prosody for prosody in virahanka4(n-2)]
return s + l>>> virahanka1(4) ['SSSS', 'SSL', 'SLS', 'LSS', 'LL'] >>> virahanka2(4) ['SSSS', 'SSL', 'SLS', 'LSS', 'LL'] >>> virahanka3(4) ['SSSS', 'SSL', 'SLS', 'LSS', 'LL'] >>> virahanka4(4) ['SSSS', 'SSL', 'SLS', 'LSS', 'LL']
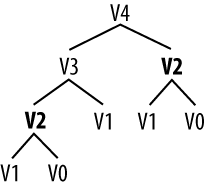
As you can see, V2
is computed twice. This might not seem like a significant problem, but
it turns out to be rather wasteful as n gets
large: to compute V20
using this recursive technique, we would compute
V2 4,181 times; and for
V40 we would compute
V2 63,245,986 times! A
much better alternative is to store the value of
V2 in a table and look it
up whenever we need it. The same goes for other values, such as
V3 and so on. Function
virahanka2() implements a dynamic
programming approach to the problem. It works by filling up a table
(called lookup) with solutions to
all smaller instances of the problem, stopping as
soon as we reach the value we’re interested in. At this point we read
off the value and return it. Crucially, each subproblem is only ever
solved once.
Notice that the approach taken in virahanka2() is to solve smaller problems on
the way to solving larger problems. Accordingly, this is known as the
bottom-up approach to dynamic
programming. Unfortunately it turns out to be quite wasteful for some
applications, since it may compute solutions to sub-problems that are
never required for solving the main problem. This wasted computation
can be avoided using the top-down
approach to dynamic programming, which is illustrated in the function
virahanka3() in Example 4-10. Unlike the bottom-up approach, this
approach is recursive. It avoids the huge wastage of virahanka1() by checking whether it has
previously stored the result. If not, it computes the result
recursively and stores it in the table. The last step is to return the
stored result. The final method, in virahanka4(), is to use a Python “decorator”
called memoize, which takes care of
the housekeeping work done by virahanka3() without cluttering up the
program. This “memoization” process stores the result of each previous
call to the function along with the parameters that were used. If the
function is subsequently called with the same parameters, it returns
the stored result instead of recalculating it. (This aspect of Python
syntax is beyond the scope of this book.)
This concludes our brief introduction to dynamic programming. We will encounter it again in Parsing with Context-Free Grammar.
Get Natural Language Processing with Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

