We have been exploring language bottom-up, with the help of texts and the Python programming language. However, we’re also interested in exploiting our knowledge of language and computation by building useful language technologies. We’ll take the opportunity now to step back from the nitty-gritty of code in order to paint a bigger picture of natural language processing.
At a purely practical level, we all need help to navigate the universe of information locked up in text on the Web. Search engines have been crucial to the growth and popularity of the Web, but have some shortcomings. It takes skill, knowledge, and some luck, to extract answers to such questions as: What tourist sites can I visit between Philadelphia and Pittsburgh on a limited budget? What do experts say about digital SLR cameras? What predictions about the steel market were made by credible commentators in the past week? Getting a computer to answer them automatically involves a range of language processing tasks, including information extraction, inference, and summarization, and would need to be carried out on a scale and with a level of robustness that is still beyond our current capabilities.
On a more philosophical level, a long-standing challenge within artificial intelligence has been to build intelligent machines, and a major part of intelligent behavior is understanding language. For many years this goal has been seen as too difficult. However, as NLP technologies become more mature, and robust methods for analyzing unrestricted text become more widespread, the prospect of natural language understanding has re-emerged as a plausible goal.
In this section we describe some language understanding technologies, to give you a sense of the interesting challenges that are waiting for you.
In word sense disambiguation we want to work out which sense of a word was intended in a given context. Consider the ambiguous words serve and dish:
Example 1-2.
serve: help with food or drink; hold an office; put ball into play
dish: plate; course of a meal; communications device
In a sentence containing the phrase: he served the dish, you can detect that both serve and dish are being used with their food meanings. It’s unlikely that the topic of discussion shifted from sports to crockery in the space of three words. This would force you to invent bizarre images, like a tennis pro taking out his frustrations on a china tea-set laid out beside the court. In other words, we automatically disambiguate words using context, exploiting the simple fact that nearby words have closely related meanings. As another example of this contextual effect, consider the word by, which has several meanings, for example, the book by Chesterton (agentive—Chesterton was the author of the book); the cup by the stove (locative—the stove is where the cup is); and submit by Friday (temporal—Friday is the time of the submitting). Observe in Example 1-3 that the meaning of the italicized word helps us interpret the meaning of by.
A deeper kind of language understanding is to work out “who did what to whom,” i.e., to detect the subjects and objects of verbs. You learned to do this in elementary school, but it’s harder than you might think. In the sentence the thieves stole the paintings, it is easy to tell who performed the stealing action. Consider three possible following sentences in Example 1-4, and try to determine what was sold, caught, and found (one case is ambiguous).
Example 1-4.
The thieves stole the paintings. They were subsequently sold.
The thieves stole the paintings. They were subsequently caught.
The thieves stole the paintings. They were subsequently found.
Answering this question involves finding the antecedent of the pronoun they, either thieves or paintings. Computational techniques for tackling this problem include anaphora resolution—identifying what a pronoun or noun phrase refers to—and semantic role labeling—identifying how a noun phrase relates to the verb (as agent, patient, instrument, and so on).
If we can automatically solve such problems of language understanding, we will be able to move on to tasks that involve generating language output, such as question answering and machine translation. In the first case, a machine should be able to answer a user’s questions relating to collection of texts:
Example 1-5.
Text: ... The thieves stole the paintings. They were subsequently sold. ...
Human: Who or what was sold?
Machine: The paintings.
The machine’s answer demonstrates that it has correctly worked out that they refers to paintings and not to thieves. In the second case, the machine should be able to translate the text into another language, accurately conveying the meaning of the original text. In translating the example text into French, we are forced to choose the gender of the pronoun in the second sentence: ils (masculine) if the thieves are sold, and elles (feminine) if the paintings are sold. Correct translation actually depends on correct understanding of the pronoun.
Example 1-6.
The thieves stole the paintings. They were subsequently found.
Les voleurs ont volé les peintures. Ils ont été trouvés plus tard. (the thieves)
Les voleurs ont volé les peintures. Elles ont été trouvées plus tard. (the paintings)
In all of these examples, working out the sense of a word, the subject of a verb, and the antecedent of a pronoun are steps in establishing the meaning of a sentence, things we would expect a language understanding system to be able to do.
For a long time now, machine translation (MT) has been the holy grail of language understanding, ultimately seeking to provide high-quality, idiomatic translation between any pair of languages. Its roots go back to the early days of the Cold War, when the promise of automatic translation led to substantial government sponsorship, and with it, the genesis of NLP itself.
Today, practical translation systems exist for particular pairs
of languages, and some are integrated into web search engines.
However, these systems have some serious shortcomings. We can explore
them with the help of NLTK’s “babelizer” (which is automatically
loaded when you import this chapter’s materials using from nltk.book import *). This program
submits a sentence for translation into a specified language, then
submits the resulting sentence for translation back into English. It
stops after 12 iterations, or if it receives a translation that was
produced already (indicating a loop):
>>> babelize_shell() NLTK Babelizer: type 'help' for a list of commands. Babel> how long before the next flight to Alice Springs? Babel> german Babel> run 0> how long before the next flight to Alice Springs? 1> wie lang vor dem folgenden Flug zu Alice Springs? 2> how long before the following flight to Alice jump? 3> wie lang vor dem folgenden Flug zu Alice springen Sie? 4> how long before the following flight to Alice do you jump? 5> wie lang, bevor der folgende Flug zu Alice tun, Sie springen? 6> how long, before the following flight to Alice does, do you jump? 7> wie lang bevor der folgende Flug zu Alice tut, tun Sie springen? 8> how long before the following flight to Alice does, do you jump? 9> wie lang, bevor der folgende Flug zu Alice tut, tun Sie springen? 10> how long, before the following flight does to Alice, do do you jump? 11> wie lang bevor der folgende Flug zu Alice tut, Sie tun Sprung? 12> how long before the following flight does leap to Alice, does you?
Observe that the system correctly translates Alice
Springs from English to German (in the line starting
1>), but on the way back to
English, this ends up as Alice jump (line 2). The preposition
before is initially translated into the
corresponding German preposition vor, but later
into the conjunction bevor (line 5). After line
5 the sentences become non-sensical
(but notice the various phrasings indicated by the commas, and the
change from jump to leap).
The translation system did not recognize when a word was part of a
proper name, and it misinterpreted the grammatical structure. The
grammatical problems are more obvious in the following example. Did
John find the pig, or did the pig find John?
>>> babelize_shell() Babel> The pig that John found looked happy Babel> german Babel> run 0> The pig that John found looked happy 1> Das Schwein, das John fand, schaute gl?cklich 2> The pig, which found John, looked happy
Machine translation is difficult because a given word could have several possible translations (depending on its meaning), and because word order must be changed in keeping with the grammatical structure of the target language. Today these difficulties are being faced by collecting massive quantities of parallel texts from news and government websites that publish documents in two or more languages. Given a document in German and English, and possibly a bilingual dictionary, we can automatically pair up the sentences, a process called text alignment. Once we have a million or more sentence pairs, we can detect corresponding words and phrases, and build a model that can be used for translating new text.
In the history of artificial intelligence, the chief measure of intelligence has been a linguistic one, namely the Turing Test: can a dialogue system, responding to a user’s text input, perform so naturally that we cannot distinguish it from a human-generated response? In contrast, today’s commercial dialogue systems are very limited, but still perform useful functions in narrowly defined domains, as we see here:
| S: How may I help you? |
| U: When is Saving Private Ryan playing? |
| S: For what theater? |
| U: The Paramount theater. |
| S: Saving Private Ryan is not playing at the Paramount theater, but |
| it’s playing at the Madison theater at 3:00, 5:30, 8:00, and 10:30. |
You could not ask this system to provide driving instructions or details of nearby restaurants unless the required information had already been stored and suitable question-answer pairs had been incorporated into the language processing system.
Observe that this system seems to understand the user’s goals: the user asks when a movie is showing and the system correctly determines from this that the user wants to see the movie. This inference seems so obvious that you probably didn’t notice it was made, yet a natural language system needs to be endowed with this capability in order to interact naturally. Without it, when asked, Do you know when Saving Private Ryan is playing?, a system might unhelpfully respond with a cold Yes. However, the developers of commercial dialogue systems use contextual assumptions and business logic to ensure that the different ways in which a user might express requests or provide information are handled in a way that makes sense for the particular application. So, if you type When is ..., or I want to know when ..., or Can you tell me when ..., simple rules will always yield screening times. This is enough for the system to provide a useful service.
Dialogue systems give us an opportunity to mention the commonly assumed pipeline for NLP. Figure 1-5 shows the architecture of a simple dialogue system. Along the top of the diagram, moving from left to right, is a “pipeline” of some language understanding components. These map from speech input via syntactic parsing to some kind of meaning representation. Along the middle, moving from right to left, is the reverse pipeline of components for converting concepts to speech. These components make up the dynamic aspects of the system. At the bottom of the diagram are some representative bodies of static information: the repositories of language-related data that the processing components draw on to do their work.
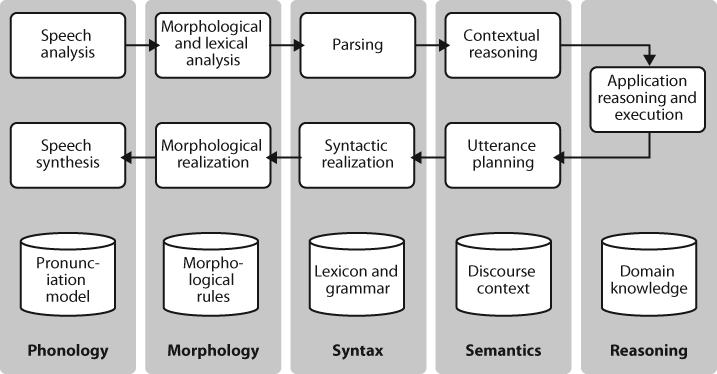
Figure 1-5. Simple pipeline architecture for a spoken dialogue system: Spoken input (top left) is analyzed, words are recognized, sentences are parsed and interpreted in context, application-specific actions take place (top right); a response is planned, realized as a syntactic structure, then to suitably inflected words, and finally to spoken output; different types of linguistic knowledge inform each stage of the process.
The challenge of language understanding has been brought into focus in recent years by a public “shared task” called Recognizing Textual Entailment (RTE). The basic scenario is simple. Suppose you want to find evidence to support the hypothesis: Sandra Goudie was defeated by Max Purnell, and that you have another short text that seems to be relevant, for example, Sandra Goudie was first elected to Parliament in the 2002 elections, narrowly winning the seat of Coromandel by defeating Labour candidate Max Purnell and pushing incumbent Green MP Jeanette Fitzsimons into third place. Does the text provide enough evidence for you to accept the hypothesis? In this particular case, the answer will be “No.” You can draw this conclusion easily, but it is very hard to come up with automated methods for making the right decision. The RTE Challenges provide data that allow competitors to develop their systems, but not enough data for “brute force” machine learning techniques (a topic we will cover in Chapter 6). Consequently, some linguistic analysis is crucial. In the previous example, it is important for the system to note that Sandra Goudie names the person being defeated in the hypothesis, not the person doing the defeating in the text. As another illustration of the difficulty of the task, consider the following text-hypothesis pair:
Example 1-7.
Text: David Golinkin is the editor or author of 18 books, and over 150 responsa, articles, sermons and books
Hypothesis: Golinkin has written 18 books
In order to determine whether the hypothesis is supported by the text, the system needs the following background knowledge: (i) if someone is an author of a book, then he/she has written that book; (ii) if someone is an editor of a book, then he/she has not written (all of) that book; (iii) if someone is editor or author of 18 books, then one cannot conclude that he/she is author of 18 books.
Despite the research-led advances in tasks such as RTE, natural language systems that have been deployed for real-world applications still cannot perform common-sense reasoning or draw on world knowledge in a general and robust manner. We can wait for these difficult artificial intelligence problems to be solved, but in the meantime it is necessary to live with some severe limitations on the reasoning and knowledge capabilities of natural language systems. Accordingly, right from the beginning, an important goal of NLP research has been to make progress on the difficult task of building technologies that “understand language,” using superficial yet powerful techniques instead of unrestricted knowledge and reasoning capabilities. Indeed, this is one of the goals of this book, and we hope to equip you with the knowledge and skills to build useful NLP systems, and to contribute to the long-term aspiration of building intelligent machines.
Get Natural Language Processing with Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

