Chapter 1. Node.js: Up and Running
Node.js is a server-side technology thatâs based on Googleâs V8 JavaScript engine. Itâs a highly scalable system that uses asynchronous, event-driven I/O (input/output), rather than threads or separate processes. Itâs ideal for web applications that are frequently accessed but computationally simple.
If youâre using a traditional web server, such as Apache, each time a web resource is requested, Apache creates a separate thread or invokes a new process in order to handle the request. Even though Apache responds quickly to requests, and cleans up after the request has been satisfied, this approach can still tie up a lot of resources. A popular web application is going to have serious performance issues.
Node, on the other hand, doesnât create a new thread or process for every request. Instead, it listens for specific events, and when the event happens, responds accordingly. Node doesnât block any other request while waiting for the event functionality to complete, and events are handledâfirst come, first servedâin a relatively uncomplicated event loop.
Node applications are created with JavaScript (or an alternative language that compiles to JavaScript). The JavaScript is the same as youâd use in your client-side applications. However, unlike JavaScript in a browser, with Node you have to set up a development environment.
Node can be installed in a Unix/Linux, Mac OS, or Windows environment. This chapter will walk you through setting up a development environment for Node in Windows 7 and Linux (Ubuntu). Installation on a Mac should be similar to installation on Linux. Iâll also cover any requirements or preparation you need to take before installing the application.
Once your development environment is operational, Iâll demonstrate a basic Node application and walk you through the important bitâthe event loop I mentioned earlier.
Setting Up a Node Development Environment
There is more than one way to install Node in most environments. Which approach you use is dependent on your existing development environment, your comfort level working with source code, or how you plan to use Node in your existing applications.
Package installers are provided for both Windows and Mac OS, but you can install Node by grabbing a copy of the source and compiling the application. You can also use Git to clone (check out) the Node repo (repository) in all three environments.
In this section Iâm going to demonstrate how to get Node working in a Linux system (an Ubuntu 10.04 VPS, or virtual private server), by retrieving and compiling the source directly. Iâll also demonstrate how to install Node so that you can use it with Microsoftâs WebMatrix on a Windows 7 PC.
Note
Download source and basic package installers for Node from http://nodejs.org/#download. Thereâs a wiki page providing some basic instruction for installing Node in various environments at https://github.com/joyent/node/wiki/Installing-Node-via-package-manager. I also encourage you to search for the newest tutorials for installing Node in your environment, as Node is very dynamic.
Installing Node on Linux (Ubuntu)
Before installing Node in Linux, you need to prepare your environment. As noted in the documentation provided in the Node wiki, first make sure Python is installed, and then install libssl-dev if you plan to use SSL/TLS (Secure Sockets Layer/Transport Layer Security). Depending on your Linux installation, Python may already be installed. If not, you can use your systems package installer to install the most stable version of Python available for your system, as long as itâs version 2.6 or 2.7 (required for the most recent version of Node).
Note
This book assumes only that you have previous experience with JavaScript and traditional web development. Given that, Iâm erring on the side of caution and being verbose in descriptions of what you need to do to install Node.
For both Ubuntu and Debian, youâll also need to install other libraries. Using the Advanced Packaging Tool (APT) available in most Debian GNU/Linux systems, you can ensure the libraries you need are installed with the following commands:
sudo apt-get update sudo apt-get upgrade sudo apt-get install build-essential openssl libssl-dev pkg-config
The update command just ensures
the package index on your system is up to date, and the upgrade command upgrades any existing outdated
packages. The third command line is the one that installs all of the
necessary packages. Any existing package dependencies are pulled in by
the package manager.
Once your system is prepared, download the Node
tarball (the compressed, archived file of the
source) to your system. I use wget to
access tarballs, though you can also use curl. At the time Iâm writing this, the most
recent source for Node is version 0.8.2:
wget http://nodejs.org/dist/v0.8.2/node-v0.8.2.tar.gz
Once youâve downloaded it, unzip and untar the file:
tar -zxf node-v0.8.2.tar.gz
You now have a directory labeled node-v0.6.18. Change into the directory and issue the following commands to compile and install Node:
./configure make sudo make install
If youâve not used the make
utility in Unix before, these three commands set up the
makefile based on your system environment and
installation, run a preliminary make
to check for dependencies, and then perform a final make with installation. After processing these
commands, Node should now be installed and accessible globally via the
command line.
Note
The fun challenge of programming is that no two systems are alike. This sequence of actions should be successful in most Linux environments, but the operative word here is should.
Notice in the last command that you had to use sudo to install Node. You need root privileges
to install Node this way (see the upcoming note). However, you can
install Node locally by using the following, which installs Node in a
given local subdirectory:
mkdir ~/working
./configure --prefix=~/working
make
make install
echo 'export PATH=~/working/bin:${PATH}' >> ~/.bashrc
. ~/.bashrcSo, as you can see here, setting the prefix configuration
option to a specified path in your home directory installs Node locally.
Youâll need to remember to update your PATH environmental
variable accordingly.
Note
To use sudo, you have to be
granted root, or superuser, privileges, and your
username must be listed in a special file located at /etc/sudoers.
Although you can install Node locally, if youâre thinking of using this approach to use Node in your shared hosting environment, think again. Installing Node is just one part of using Node in an environment. You also need privileges to compile an application, as well as run applications off of certain ports (such as port 80). Most shared hosting environments will not allow you to install your own version of Node.
Unless thereâs a compelling reason, I recommend installing Node
using sudo.
Note
At one time there was a security concern about running the Node package manager (npm), covered in Chapter 4, with root privilege. However, those security issues have since been addressed.
Partnering Node with WebMatrix on Windows 7
You can install Node in Windows using a very basic installation sequence as outlined in the wiki installation page provided earlier. However, chances are that if youâre going to use Node in a Windows environment, youâre going to use it as part of a Windows web development infrastructure.
There are two different Windows infrastructures you can use Node with at this time. One is the new Windows Azure cloud platform, which allows developers to host applications in a remote service (called a cloud). Microsoft provides instructions for installing the Windows Azure SDK for Node, so I wonât be covering that process in this chapter (though I will examine and demonstrate the SDK later in the book).
Note
You can find the Windows Azure SDK for Node and installation instructions at https://www.windowsazure.com/en-us/develop/nodejs/.
The other approach to using Node on Windowsâin this case, Windows 7âis by integrating Node into Microsoftâs WebMatrix, a tool for web developers integrating open source technologies. Here are the steps weâll need to take to get Node up and running with WebMatrix in Windows 7:
You install WebMatrix using the Microsoft Web Platform Installer, as shown in Figure 1-1. The tool also installs IIS Express, which is a developer version of Microsoftâs web server. Download WebMatrix from http://www.microsoft.com/web/webmatrix/.
Once the WebMatrix installation is finished, install the latest
version of Node using the installer provided at the primary Node site
(http://nodejs.org/#download). Installation is
one-click, and once youâre finished you can open a Command window and
type node to check for yourself
that the application is operational, as shown in Figure 1-2.
For Node to work with IIS in Windows, install iisnode, a native IIS 7.x module created and maintained by Tomasz Janczuk. As with Node, installation is a snap using the prebuilt installation package, available at https://github.com/tjanczuk/iisnode. There are x86 and x64 installations, but for x64, youâll need to install both.
During the iisnode installation, a window may pop up telling you that youâre missing the Microsoft Visual C++ 2010 Redistributable Package, as shown in Figure 1-3. If so, youâll need to install this package, making sure you get the one that matches the version of iisnode youâre installingâeither the x86 package (available at http://www.microsoft.com/download/en/details.aspx?id=5555) or the x64 package (available at http://www.microsoft.com/download/en/details.aspx?id=14632), or both. Once youâve installed the requisite package, run the iisnode installation again.
If you want to install the iisnode samples, open a Command window with administrator privileges, go to the directory where iisnode is installedâeither Program Files for 64-bit, or Program Files (x86)âand run the setupsamples.bat file.
To complete the WebMatrix/Node setup, download and install the Node templates for WebMatrix, created by Steve Sanderson and found at https://github.com/SteveSanderson/Node-Site-Templates-for-WebMatrix.
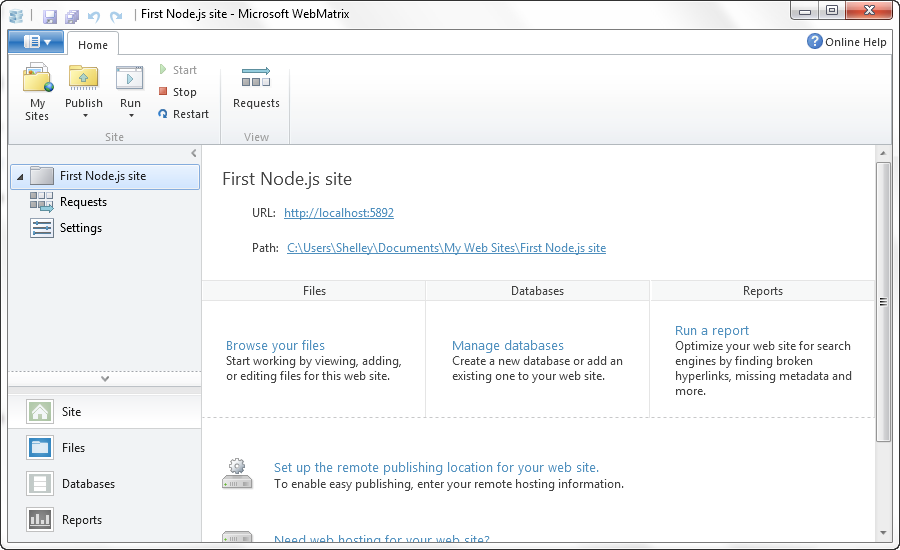
You can test that everything works by running WebMatrix, and in the opening pages, select the âSite from Templateâ option. In the page that opens, shown in Figure 1-4, youâll see two Node template options: one for Express (introduced in Chapter 7) and one for creating a basic, empty site configured for Node. Choose the latter option, giving the site a name of First Node Site, or whatever you want to use.
Figure 1-5 shows WebMatrix once the site has been generated. Click the Run button, located in the top left of the page, and a browser page should open with the ubiquitous âHello, world!â message displayed.
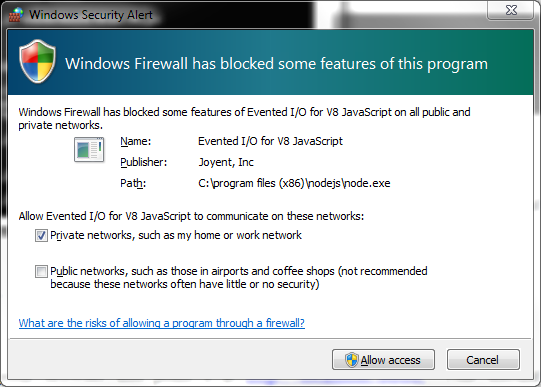
If youâre running the Windows Firewall, the first time you run a Node application, you may get a warning like that shown in Figure 1-6. You need to let the Firewall know this application is acceptable by checking the âPrivate networksâ option and then the âAllow accessâ button. You want to restrict communication to just your private network on your development machine.
If you look at the generated files for your new WebMatrix Node project, youâll see one named app.js. This is the Node file, and it contains the following code:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, { 'Content-Type': 'text/html' });
res.end('Hello, world!');
}).listen(process.env.PORT || 8080);What this all means, Iâll get into in the second part of this chapter. The important item to take away from this code right now is that we can run this same application in any operating system where Node is installed and get the exact same functionality: a service that returns a simple message to the user.
Updating Node
Node stable releases are even numbered, such as the current 0.8.x, while the development releases are odd numbered (currently 0.9.x). I recommend sticking with stable releases onlyâat least until you have some experience with Node.
Updating your Node installation isnât complicated. If you used the
package installer, using it for the new version should just override the
old installation. If youâre working directly with the source, you can
always uninstall the old source and install the new if youâre concerned
about potential clutter or file corruption. In the Node source
directory, just issue the uninstall
make option:
make uninstall
Download the new source, compile it, and install it, and youâre ready to go again.
The challenge with updating Node is determining whether a specific environment, module, or other application works with the new version. In most cases, you shouldnât have version troubles. However, if you do, there is an application you can use to âswitchâ Node versions. The application is the Node Version Manager (Nvm).
You can download Nvm from GitHub, at https://github.com/creationix/nvm. Like Node, Nvm must be compiled and installed on your system.
To install a specific version of Node, install it with Nvm:
nvm install v0.4.1
To switch to a specific version, use the following:
nvm run v0.4.1
To see which versions are available, use:
nvm ls
Node: Jumping In
Now that you have Node installed, itâs time to jump into your first application.
Hello, World in Node
As is typical for testing out any new development environment, language, or tool, the first application weâll create is âHello, Worldââa simple application that prints out a greeting to whomever accesses it.
Example 1-1 shows all the text needed to create Hello, World in Node.
// load http module
var http = require('http');
// create http server
http.createServer(function (req, res) {
// content header
res.writeHead(200, {'content-type': 'text/plain'});
// write message and signal communication is complete
res.end("Hello, World!\n");
}).listen(8124);
console.log('Server running on 8124');The code is saved in a file named helloworld.js. As server-side functionality goes, this Node application is neither too verbose, nor too cryptic; one can intuit whatâs happening, even without knowing Node. Best of all, itâs familiar since itâs written in a language we know well: JavaScript.
To run the application, from the command line in Linux, the Terminal window in Mac OS, or the Command window in Windows, type:
node helloworld.js
The following is printed to the command line once the program has successfully started:
Server running at 8124
Now, access the site using any browser. If the application is running on your local machine, youâll use localhost:8124. If itâs running remotely, use the URL of the remote site, with the 8124 port. A web page with the words âHello, World!â is displayed. Youâve now created your first complete and working Node application.
Warning
If youâre installing Node in a Fedora system, be aware that Node is renamed due to name conflicts with existing functionality. Thereâs more on this at http://nodejs.tchol.org/.
Since we didnât use an ampersand (&) following the
node commandâtelling
the application to run in the backgroundâthe application starts and
doesnât return you to the command line. You can continue accessing the
application, and the same words get displayed. The application continues
until you type Ctrl-C to cancel it, or otherwise kill the
process.
If you want to run the application in the background within a Linux system, use the following:
node helloworld.js &
However, youâll then have to find the process identifier using
ps -ef, and manually kill the right
processâin this case, the one with the process identifier 3747âusing
kill:
ps -ef | grep node kill 3747
Exiting the terminal window will also kill the process.
Note
In Chapter 16, I cover how to create a persistent Node application installation.
You wonât be able to start another Node application listening at the same port: you can run only one Node application against one port at a time. If youâre running Apache at port 80, you wonât be able to run the Node application at this port, either. You must use a different port for each application.
You can also add helloworld.js as a new file to the existing WebMatrix website you created earlier, if youâre using WebMatrix. Just open the site, choose the âNew File...â option from the menu bar, and add the text shown in Example 1-1 to the file. Then click the Run button.
Hello, World from the Top
Iâll get more in depth on the anatomy of Node applications in the next couple of chapters, but for now, letâs take a closer look at the Hello, World application.
Returning to the text in Example 1-1, the first line of code is:
var http = require('http');Most Node functionality is provided through external applications and libraries called modules. This line of JavaScript loads the HTTP module, assigning it to a local variable. The HTTP module provides basic HTTP functionality, enabling network access of the application.
The next line of code is:
http.createServer(function (req, res) { ...In this line of code, a new server is created with createServer, and an
anonymous function is passed as the parameter to the function call. This
anonymous function is the requestListener
function, and has two parameters: a server request (http.ServerRequest) and a server response
(http.ServerResponse).
Within the anonymous function, we have the following line:
res.writeHead(200, {'content-Type': 'text/plain'});The http.ServerResponse
object has a method, writeHead, that sends a
response header with the response status code (200), as well as provides
the content-type of the
response. You can also include other response header information within
the headers object, such as
content-length or
connection:
{ 'content-length': '123',
'content-type': 'text/plain',
'connection': 'keep-alive',
'accept': '*/*' }A second, optional parameter to writeHead is a
reasonPhrase, which is
a textual description of the status code.
Following the code to create the header is the command to write the âHello, World!â message:
res.end("Hello, World!\n");The http.ServerResponse.end
method signals that the communication is finished; all headers and the
response body have been sent. This method must be
used with every http.ServerResponse
object.
The end method has two
parameters:
A chunk of data, which can be either a string or a buffer.
If the chunk of data is a string, the second parameter specifies the encoding.
Both parameters are optional, and the second parameter is required
only if the encoding of the string is anything other than utf8, which is the default.
Instead of passing the text in the end function, I could have used another
method, write:
res.write("Hello, World!\n");and then:
res.end();
The anonymous function and the createServer function
are both finished on the next line in the code:
}).listen(8124);
The http.Server.listen method
chained at the end of the createServer method
listens for incoming connections on a given portâin this case, port
8124. Optional parameters are a hostname and a callback function. If a hostname
isnât provided, the server accepts connections to web addresses, such as
http://oreilly.com or http://examples.burningbird.net.
Note
More on the callback function later in this chapter.
The listen method is asynchronous, which means the
application doesnât block program execution, waiting for the connection
to be established. Whatever code following the listen call is processed, and the listen callback function is invoked when the
listening event is
firedâwhen the port connection is established.
The last line of code is:
console.log('Server running on 8124/');The console object is one
of the objects from the browser world that is incorporated into Node.
Itâs a familiar construct for most JavaScript developers, and provides a
way to output text to the command line (or development environment),
rather than to the client.
Asynchronous Functions and the Node Event Loop
The fundamental design behind Node is that an application is executed on a single thread (or process), and all events are handled asynchronously.
Consider how the typical web server, such as Apache, works. Apache has two different approaches to how it handles incoming requests. The first is to assign each request to a separate process until the request is satisfied; the second is to spawn a separate thread for each request.
The first approach (known as the prefork multiprocessing model, or prefork MPM) can create as many child processes as specified in an Apache configuration file. The advantage to creating a separate process is that applications accessed via the request, such as a PHP application, donât have to be thread-safe. The disadvantage is that each process is memory intensive and doesnât scale very well.
The second approach (known as the worker MPM), implements a hybrid process-thread approach. Each incoming request is handled via a new thread. Itâs more efficient from a memory perspective, but also requires that all applications be thread-safe. Though the popular web language PHP is now thread-safe, thereâs no guarantee that the many different libraries used with it are also thread-safe.
Regardless of the approach used, both types respond to requests in parallel. If five people access a web application at the exact same time, and the server is set up accordingly, the web server handles all five requests simultaneously.
Node does things differently. When you start a Node application, itâs created on a single thread of execution. It sits there, waiting for an application to come along and make a request. When Node gets a request, no other request can be processed until itâs finished processing the code for the current one.
You might be thinking that this doesnât sound very efficient, and it wouldnât be except for one thing: Node operates asynchronously, via an event loop and callback functions. An event loop is nothing more than functionality that basically polls for specific events and invokes event handlers at the proper time. In Node, a callback function is this event handler.
Unlike with other single-threaded applications, when you make a request to a Node application and it must, in turn, make some request of resources (such as a database request or file access), Node initiates the request, but doesnât wait around until the request receives a response. Instead, it attaches a callback function to the request. When whatever has been requested is ready (or finished), an event is emitted to that effect, triggering the associated callback function to do something with either the results of the requested action or the resources requested.
If five people access a Node application at the exact same time, and the application needs to access a resource from a file, Node attaches a callback function to a response event for each request. As the resource becomes available for each, the callback function is called, and each personâs request is satisfied in turn. In the meantime, the Node application can be handling other requests, either for the same applications or a different application.
Though the application doesnât process the requests in parallel, depending on how busy it is and how itâs designed, most people usually wonât perceive any delay in the response. Best of all, the application is very frugal with memory and other limited resources.
Reading a File Asynchronously
To demonstrate Nodeâs asynchronous nature, Example 1-2 modifies the Hello, World application from earlier in the chapter. Instead of just typing out âHello, World!â it actually opens up the previously created helloworld.js and outputs the contents to the client.
// load http module
var http = require('http');
var fs = require('fs');
// create http server
http.createServer(function (req, res) {
// open and read in helloworld.js
fs.readFile('helloworld.js', 'utf8', function(err, data) {
res.writeHead(200, {'Content-Type': 'text/plain'});
if (err)
res.write('Could not find or open file for reading\n');
else
// if no error, write JS file to client
res.write(data);
res.end();
});
}).listen(8124, function() { console.log('bound to port 8124');});
console.log('Server running on 8124/');A new module, File System (fs), is used in this example. The File System
module wraps standard POSIX file functionality, including opening up and
accessing the contents from a file. The method used is readFile. In Example 1-2, itâs passed the
name of the file to open, the encoding, and an anonymous
function.
The two instances of asynchronous behavior I want to point out in
Example 1-2 are the
callback function thatâs attached to the readFile method, and
the callback function attached to the listen method.
As discussed earlier, the listen method tells the
HTTP server object to begin listening for connections on the given port.
Node doesnât block, waiting for the connection to be established, so if
we need to do something once the connection is established, we provide a
callback function, as shown in Example 1-2.
When the connection is established, a listening event is
emitted, which then invokes the callback function, outputting a message
to the console.
The second, more important callback instance is the one attached
to readFile. Accessing a
file is a time-consuming operation, relatively speaking, and a
single-threaded application
accessed by multiple clients that blocked on file access would soon bog
down and be unusable.
Instead, the file is opened and the contents are read
asynchronously. Only when the contents have been read into the data
bufferâor an error occurs during the processâis the callback function
passed to the readFile method called.
Itâs passed the error (if any), and the data if no error occurs.
In the callback function, the error is checked, and if there is no error, the data is then written out to the response back to the client.
Taking a Closer Look at Asynchronous Program Flow
Most people who have developed with JavaScript have done so in client applications, meant to be run by one person at a time in a browser. Using JavaScript in the server may seem odd. Creating a JavaScript application accessed by multiple people at the same time may seem even odder.
Our job is made easier because of the Node event loop and being able to put our trust in asynchronous function calls. However, weâre no longer in Kansas, Dorothyâwe are developing for a different environment.
To demonstrate the differences in this new environment, I created two new applications: one as a service, and one to test the new service. Example 1-3 shows the code for the service application.
In the code, a function is called, synchronously, to write out numbers from 1 to 100. Then a file is opened, similar to what happened in Example 1-2, but this time the name of the file is passed in as a query string parameter. In addition, the file is opened only after a timer event.
var http = require('http');
var fs = require('fs');
// write out numbers
function writeNumbers(res) {
var counter = 0;
// increment global, write to client
for (var i = 0; i<100; i++) {
counter++;
res.write(counter.toString() + '\n');
}
}
// create http server
http.createServer(function (req, res) {
var query = require('url').parse(req.url).query;
var app = require('querystring').parse(query).file + ".txt";
// content header
res.writeHead(200, {'Content-Type': 'text/plain'});
// write out numbers
writeNumbers(res);
// timer to open file and read contents
setTimeout(function() {
console.log('opening ' + app);
// open and read in file contents
fs.readFile(app, 'utf8', function(err, data) {
if (err)
res.write('Could not find or open file for reading\n');
else {
res.write(data);
}
// response is done
res.end();
});
},2000);
}).listen(8124);
console.log('Server running at 8124');The loop to print out the numbers is used to delay the
application, similar to what could happen if you performed a
computationally intensive process and then blocked until the process was
finished. The setTimeout function is
another asynchronous function, which in turn invokes a second
asynchronous function: readFile. The
application combines both asynchronous and synchronous processes.
Create a text file named main.txt, containing any text you want.
Running the application and accessing the page from Chrome with a query
string of file=main generates the
following console output:
Server running at 8124/ opening main.txt opening undefined.txt
The first two lines are expected. The first is the result of
running console.log at the end of the
application, and the second is a printout of the file being opened. But
whatâs undefined.txt in the third
line?
When processing a web request from a browser, be aware that browsers may send more than one request. For instance, a browser may also send a second request, looking for a favicon.ico. Because of this, when youâre processing the query string, you must check to see if the data you need is being provided, and ignore requests without the data.
Warning
The browser sending multiple requests can impact your application if youâre expecting values via a query string. You must adjust your application accordingly. And yes, youâll still need to test your application with several different browsers.
So far, all weâve done is test our Node applications from a browser. This isnât really putting much stress on the asynchronous nature of the Node application.
Example 1-4 contains the code for a very simple test application. All it does is use the HTTP module to request the example server several times in a loop. The requests arenât asynchronous. However, weâll also be accessing the service using the browser as we run the test program. Both, combined, asynchronously test the application.
Note
Iâll cover creating asynchronous testing applications in Chapter 14.
var http = require('http');
//The url we want, plus the path and options we need
var options = {
host: 'localhost',
port: 8124,
path: '/?file=secondary',
method: 'GET'
};
var processPublicTimeline = function(response) {
// finished? ok, write the data to a file
console.log('finished request');
};
for (var i = 0; i < 2000; i++) {
// make the request, and then end it, to close the connection
http.request(options, processPublicTimeline).end();
}Create the second text file, named secondary.txt. Put whatever you wish in it, but make the contents obviously different from main.txt.
After making sure the Node application is running, start the test application:
node test.js
As the test application is running, access the application using your browser. If you look at the console messages being output by the application, youâll see it process both your manual and the test applicationâs automated requests. Yet the results are consistent with what we would expect, a web page with:
The numbers 1 through 100 printed out
The contents of the text fileâin this case, main.txt
Now, letâs mix things up a bit. In Example 1-3, make the counter global rather than local to the loop
function, and start the application again. Then run the test program and
access the page in the browser.
The results have definitely changed. Rather than the numbers starting at 1 and going to 100, they start at numbers like 2,601 and 26,301. They still print out the next sequential 99 numbers, but the starting value is different.
The reason is, of course, the use of the global counter. Since youâre accessing the same
application in the browser manually as the test program is doing
automatically, youâre both updating counter. Both the manual and automated
application requests are processed, in turn, so thereâs no contention
for the shared data (a major problem with thread safety in a
multithreaded environment), but if youâre expecting a consistent
beginning value, you might be surprised.
Now change the application again, but this time remove the
var keyword in front of
the app variableââaccidentallyâ
making it a global variable. We all have, from time to time, forgotten
the var keyword with our
client-side JavaScript applications. The only time we get bit by this
mistake is if any libraries weâre using are using the same variable
name.
Run the test application and access the Node service in your
browser a couple of times. Chances are, youâll end up with the text from
the secondary.txt file in your
browser window, rather than the requested main.txt file. The reason is that in the time
between when you processed the query for the filename and when you
actually opened the file, the automatic application modified the
app variable. The test application is
able to do so because you made an asynchronous function request,
basically ceding program control to another request while your request
was still mid-process.
Benefits of Node
By now you have a working Node installationâpossibly even more than one.
Youâve also had a chance to create a couple of Node applications and
test out the differences between synchronous and asynchronous code (and
what happens if you accidentally forget the var keyword).
Node isnât all asynchronous function calls. Some objects may provide both synchronous and asynchronous versions of the same function. However, Node works best when you use asynchronous coding as much as possible.
The Node event loop and callback functions have two major benefits.
First, the application can easily scale, since a single thread of execution doesnât have an enormous amount of overhead. If we were to create a PHP application similar to the Node application in Example 1-3, the user would see the same pageâbut your system would definitely notice the difference. If you ran the PHP application in Apache with the default prefork MPM, each time the application was requested, it would have to be handled in a separate child process. Chances are, unless you have a significantly loaded system, youâll only be able to runâat mostâa couple of hundred child processes in parallel. More than that number of requests means that a client needs to wait for a response.
A second benefit to Node is that you minimize resource usage, but without having to resort to multithreaded development. In other words, you donât have to create a thread-safe application. If youâve ever developed a thread-safe application previously, youâre probably feeling profoundly glad at this statement.
However, as was demonstrated in the last example application, you
arenât developing JavaScript applications for single users to run in the
browser, either. When you work with asynchronous applications, you need to
make sure that you donât build in dependencies on one asynchronous
function call finishing ahead of another, because there are no
guaranteesânot unless you call the second function call within the code of
the first. In addition, global variables are extremely hazardous in Node,
as is forgetting the var keyword.
Still, these are issues we can work withâespecially considering the benefits of Nodeâs low resource requirements and not having to worry about threads.
Get Learning Node now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

