The object orientation topic hasn’t been touched yet because you must first know COM before we can really speak about COM object orientation. Thus far, you have gained all the basics of COM. You’ve learned how to wrap up a component from a number of classes, objects, and interfaces. You’ve also learned how to use the services exposed by these COM objects, and you’ve worked very hard to get to here. Everything you’ve learned so far involves classic notions of traditional systems programming: interfaces, objects, and classes. In this section, we will examine the object-oriented aspect of COM. Remember that COM is a model. The model supports the traditional object-oriented notions which include encapsulation, polymorphism, and reuse (or inheritance). In all these cases, COM surpasses the traditional notions, because it ratifies and strengthens them. We’ll first briefly examine these notions in the following sections, and then you’ll learn to write code that allows you to dynamically reuse binary components.
COM not only supports the notion of encapsulation, but it strongly enforces it. The basis of COM is the distinct separation of interface from implementation. All COM objects are built from interfaces and all interfaces must be specified. Interfaces contain specification of methods, but don’t contain specification of states or implementations. In other words, an interface groups together a number of methods that a COM object supports, but it doesn’t specify the states of the object, which are totally implementation details. In addition to the fact that interfaces carry no implementation details, they must never be changed once they are published. With this support, any object may implement a published interface, but how the object implements the interface is its own business. In this respect, an object’s implementation details are all hidden or encapsulated behind exposed interfaces.
A COM object is a black box with a bunch of lollipops. In order to eat a particular lollipop, you have to ask the object whether it’s got that lollipop. A COM object is so well encapsulated that you can’t use it until you actually query for a particular interface that it supports. This support raises encapsulation to a higher level, allowing clients to dynamically and robustly discover an object’s exposed services. If a client asks for a particular interface that an object doesn’t support, the sky won’t fall, since the object returns a negative response, indicating to the client that it should take appropriate action to gracefully recover.
Compared to traditional object-oriented paradigm, polymorphism is better supported in COM. Traditional support for polymorphism allows only methods to be polymorphic, but COM extends polymorphism to a COM interface. For example, the IUnknown interface is polymorphic across all COM objects. Any COM client can talk to any other COM object in cyberspace, since every COM object must implement IUnknown. At the method level, QueryInterface (and company) is polymorphic across all interfaces. This allows anyone to get from one COM interface to another. It is the polymorphic aspects of IUnknown that uphold the COM philosophy.
IUnknown is not the only interface that is polymorphic in COM, though; every interface in COM is polymorphic across all COM objects that implement it. Since an interface is like an application-level communications protocol, you are essentially creating a colloquial dialect that can be potentially turned into standard speech. And once it turns into a well-known interface, such a standard interfaces provided by Microsoft, everyone will be able to speak your colloquial dialect. This is an extremely powerful idea.
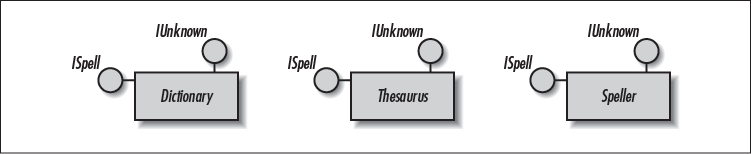
Knowing a particular interface specification, a client can use the services exposed by any COM object that implements and supports that interface. This is true regardless of how the interface is implemented. As shown in Figure 4-4, if three different objects correctly implement an ISpell interface, everyone who knows how to talk the ISpell protocol can use all three objects, despite drastic implementation differences among them. Therefore, specified interfaces are polymorphic across all COM objects.
Traditional object-oriented techniques support reuse via the notion of implementation inheritance, which can be potentially risky, as presented in Chapter 2. Even though COM doesn’t support implementation inheritance, it doesn’t mean that you can’t use traditional implementation inheritance for the internal implementations of your COM objects. Remember that COM is language independent, so theoretically, you can use any language you want to develop component software. If you happen to use C++ to develop COM objects, by all means, be as skillful as you want in exploiting C++ inheritance. Whatever you do inside the object will not affect the outside world, because everything you do internally is implementation detail that clients need not care about.
However, reuse in COM doesn’t mean reusing source code because it means much more than that. In COM, you reuse a binary COM object. For example, consider a CoOuter COM object that reuses the binary CoInner COM object. With binary reusability, when the implementation of the CoInner object changes, no implementation changes to the CoOuter are required. Hence, binary reusability removes the coupling between the CoOuter and CoInner objects. There are two ways to implement binary reuse in COM: containment and aggregation.
Containment is the traditional technique for reuse, which C++ developers have grown to know and trust. In classical object-oriented programming, you use containment to build a larger object that is composed of many smaller ones. For example, a car (the outer object) contains an engine (the inner object) and delegates engine-related functionality to its engine. A car cannot accelerate without an engine; therefore, it has to delegate this responsibility to its contained engine. For this reason, containment is also called delegation. This is a simple idea that’s been in use for years.
We can apply the same technique in reusing binary COM objects. Recall that you’ve developed a COM object, called CoOcrEngine, which exposes two interfaces (IOcr and ISpell). If you were to develop a CoDictionary COM object, you might want to support an IDictionary and an ISpell interface, but since you’ve already written the code for ISpell in the CoOcrEngine object, it’d be nice to reuse that particular implementation. You can easily do this using COM containment.
You’ve seen a simple picture of COM containment in Chapter 2, but Figure 4-5 more accurately depicts COM containment. This simple reuse mechanism allows the outer object (CoDictionary) to delegate method invocations to the inner object (CoOcrEngine), effectively reusing the inner object’s implementation. The CoDictionary object will pass all ISpell calls to its contained object’s ISpell interface. In this sense, all ISpell methods in the CoDictionary (outer object) object are stubs that automatically forward their calls to the corresponding methods implemented by CoOcrEngine (inner object). For this reason, the CoDictionary’s ISpell interface is often called a pass-through interface, because it doesn’t do anything. It simply forwards the calls to the target destination.
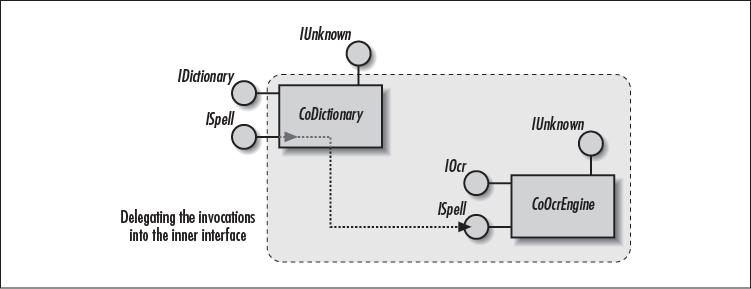
The dotted rectangle represents the CoDictionary object as seen by a client. You may have realized that CoDictionary may be a server to other clients, but it is simply a client to CoOcrEngine. Thus, the CoOcrEngine that is reused could live on a totally different machine, proving that you’re getting both binary and distributed component reuse.
Here’s how you would use containment to gain binary reusability. As shown in the code following, CoDictionary implements IDictionary and ISpell. CoDictionary is implemented exactly like any other COM object; however, it is also a client to the CoOcrEngine COM object. Therefore, it keeps a reference to CoOcrEngine’s ISpell interface as a member variable. It creates the CoOcrEngine object in the constructor, by calling a private helper function, CreateInnerObject, which will be discussed in a moment. The destructor simply releases the interface.
class CoDictionary : public IDictionary, public ISpell {
LONG m_lRefCount;
// We specifically want to reuse the ISpell interface that belongs to
// the inner object — using the containment technique
// we're keeping a reference to the inner,
// reused object (CoOcrEngine).
ISpell *m_pISpell ;
public:
CoDictionary() : m_lRefCount(0), m_pISpell(0)
{
ComponentAddRef();
// Create the inner object.
CreateInnerObject();
}
~CoDictionary()
{
// Release the interface of the inner object
// that we've been keeping for inner method delegation.
if (m_pISpell) { m_pISpell->Release(); }
ComponentRelease();
}
// The factory will call this method to actually
// create this object.
static HRESULT CreateObject(LPUNKNOWN pUnkOuter, REFIID riid, void** ppv);
public:
// IUnknown Methods
STDMETHODIMP QueryInterface(REFIID riid, void **ppv);
STDMETHODIMP_(ULONG) AddRef(void);
STDMETHODIMP_(ULONG) Release(void);
// IDictionary
STDMETHODIMP LookUp()
{ wprintf(TEXT("Lookup success...\n")); return S_OK; }
// ISpell methods
// We're reusing the implementation of an inner
// binary object. Simply forward the calls...
STDMETHODIMP Check(wchar_t *pszWord, PossibleWords *pWords)
{ return m_pISpell->Check(pszWord, pWords); }
private:
// Helper member function to create the inner object for reuse.
void CreateInnerObject();
};As just shown, you provide a simple implementation of LookUp (IDictionary’s method). In the simple implementation of Check (ISpell’s method), you simply pass the buck to m_pISpell, which is a pointer to CoOcrEngine’s ISpell interface. This interface pointer is obtained in the private helper function, CreateInnerObject:
void CoDictionary::CreateInnerObject() { MULTI_QI mqi[] = { {&IID_ISpell, NULL, S_OK} }; // Create the inner object for reuse by containment HRESULT hr = CoCreateInstanceEx(CLSID_OcrEngine, NULL, CLSCTX_SERVER, NULL, sizeof(mqi)/sizeof(mqi[0]), mqi); if (SUCCEEDED(hr) && SUCCEEDED(mqi[0].hr)) { // Save the interface pointer as a member variable m_pISpell = static_cast<ISpell *>(mqi[0].pItf); } else { assert(false); } }
You shouldn’t be surprised that CoCreateInstanceEx is used to create the inner COM object, because after all, the CoDictionary COM object is simply a client to CoOcrEngine. Notice that you request the ISpell interface, because that’s the interface you want to save, and to which you’ll later forward method invocations. CoCreateInstanceEx also allows you to get an array of interfaces at one time, so if needed, you can take advantage of this feature.
Here’s one place that you shouldn’t specify a server destination (the fourth parameter of CoCreateInstanceEx), but instead allow the server name to be derived from the RemoteServerName named value registry entry, which can be easily configured using dcomcnfg.exe or oleview.exe. Remember that the outer and inner objects can be located anywhere after you’ve deployed your components. If you hard code the inner object’s server name, there’s no way to configure the destination of the inner object. Put differently, you wouldn’t want to change the code of your outer object each time you relocate the inner object to a different machine. Thus, don’t specify a hard-coded server destination when you are writing a COM object that internally uses another object. If you don’t heed this advice, you may encounter the infamous RPC_S_SERVER_UNAVAILABLE return code.
The advantage of COM containment is simplicity, because the outer object simply acts as a client to the inner object. This implies that the inner object can exist anywhere in cyberspace, and reuse is still possible. Another advantage is that any COM object can be reused by virtue of containment. These are the reasons why containment is preferred over aggregation.
Aggregation is another technique for binary reuse in COM, which allows a number of COM objects to be aggregated together into one single entity. When you use this technique, your outer object can expose an inner object’s interfaces as if the outer object implemented them. Furthermore, you can selectively choose the inner interfaces that you want to expose. A client that uses the your outer object will not know that you have indeed reused one or more binary components. A client sees only one single entity, the outer object.
For instance, if you were to develop a CoThesaurus (outer) COM object, you might like to support an ISpell interface, in addition to possibly supporting an IThesaurus interface. Since CoOcrEngine (inner object) has already implemented the ISpell, it would be wise to reuse the implementation. If you were to use aggregation, we would aggregate the ISpell (and maybe even the IOcr) interface of the CoOcrEngine object into your CoThesaurus object. Aggregation allows you to hallucinate clients into thinking that the CoThesaurus COM object implements the ISpell interface, when in fact the ISpell interface is actually implemented by the inner object. As seen in Figure 4-6, the ISpell and IOcr interface have been extended to clients of the CoThesaurus object. Note that you can selectively expose the inner interfaces to your clients. For example, the CoThesaurus object shown in Figure 4-6 supports the IOcr interface, but it doesn’t have to support this functionality.
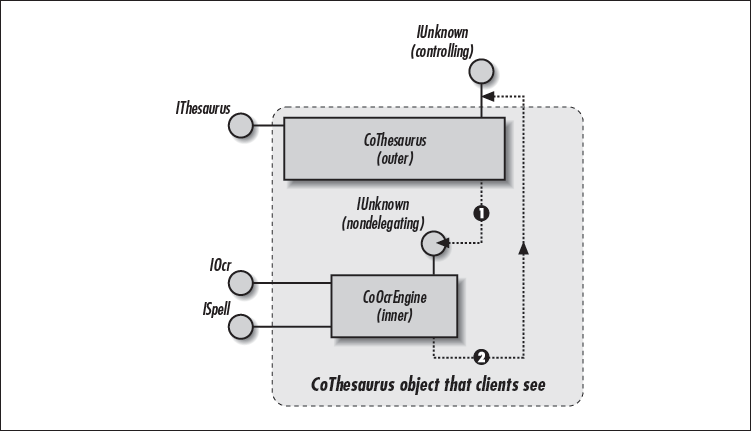
Though you’ve seen a simple picture of COM aggregation in Chapter 2, Figure 4-6 more accurately depicts COM aggregation. COM Aggregation allows the outer object (CoThesaurus) to aggregate the inner object’s (CoOcrEngine) interfaces, so that clients see all inner interfaces as part of the outer object. There are two requirements needed to preserve the outer object’s identity.
The outer object keeps a reference to the inner object’s implicit (or nondelegating) unknown.
The inner object knows (holds onto) the outer object’s unknown, so that it can delegate all delegating IUnknown methods out to the outer object’s unknown (called the controlling unknown). The dotted rectangle in Figure 4-6 represents the CoThesaurus object as seen by a client.
Figure 4-6 looks fairly straightforward, but you need to provide special support in both the inner and outer objects to successfully take advantage of aggregation. A COM object can be aggregated only if it supports the aggregation guidelines set forth by the COM Specification, so naturally not every COM object can be aggregated. The good thing is COM doesn’t mandate that objects support aggregation, but if you want to use aggregation, here are five requirements for both the outer and inner objects.
When being aggregated, the inner object must provide special support for the outer object’s identity and lifetime management. This requires the inner object to provide two sets of implementations for IUnknown (one called the delegating unknown and the other called the nondelegating or implicit unknown).
The outer object’s clients will use the inner object’s delegating unknown, even though they have no idea that they’re actually doing this. In order to maintain the outer object’s identity, the inner object’s delegating unknown routes all its method invocations (QueryInterface, AddRef, and Release) outward to the outer object’s IUnknown, the controlling unknown.
The outer object will use the inner object’s nondelegating or implicit IUnknown. This inner object’s implicit IUnknown must not delegate to the outer object, in order to prevent infinite recursion.
When an outer object aggregates an inner object, the outer object must tell the inner object that it is aggregating the inner object. The outer object does this by passing its controlling unknown (a pointer to its own IUnknown) into the inner object when it creates the inner object.
When the outer object creates the inner object, it can ask only for the inner object’s implicit IUnknown interface, nothing else. This is required to prevent infinite recursion, as only the implicit unknown of the inner object prevents outward delegation.
That’s quite a bit of work. So before you go on to the code that’s required to fulfill these requirements, first examine some advantages and disadvantages of aggregation. After the explanation of these advantages and disadvantages, you can decide whether you would want your COM objects to support aggregation.
If your COM objects support aggregation, here are two benefits:
Other objects can reuse your object by aggregation or containment.
If your object supports an interface with 100 methods, other objects can use aggregation so that they don’t have to implement 100 passthrough methods when reusing this particular interface.
However, here are two notable drawbacks of aggregation:
COM objects that support aggregation are harder to implement than simple COM objects. For example, you must write special code for your object to support aggregation.[45]
Aggregation doesn’t work across apartments (execution contexts), which is a drawback that prevents distributed reuse. This also means that in order for an object to be aggregated, it must be packaged into an in-process server.[46]
Now that you’ve examined the obvious advantages and disadvantages of aggregation, look at what’s needed to aggregate an inner object that supports aggregation. Consider a CoThesaurus COM object that implements the IThesaurus interface. It also aggregates the CoOcrEngine object to expose the IOcr and ISpell interfaces to its clients as if these interfaces were its own. To do this, it needs to keep a pointer to an implicit IUnknown interface of the inner object, shown in the following code as m_pUnkAggregate. Like containment, you create the inner object in the constructor by calling the helper function CreateInnerObject, and you release m_pUnkAggregate in the destructor. Unlike containment, you don’t implement any pass-through interface methods for ISpell and IOcr.
class CoThesaurus : public IThesaurus {
LONG m_lRefCount;
// To support aggregation, keep a pointer to the
// implicit (nondelegating) unknown
// of the object we're aggregating (the inner object)
IUnknown *m_pUnkAggregate;
public:
CoThesaurus() : m_lRefCount(0), m_pUnkAggregate(0)
{
ComponentAddRef();
// Create the inner, reused object
CreateInnerObject();
}
~CoThesaurus()
{
if (m_pUnkAggregate) { m_pUnkAggregate->Release(); }
ComponentRelease();
}
// The factory will call this method to actually
// create this object.
static HRESULT CreateObject(LPUNKNOWN pUnkOuter, REFIID riid,
void** ppv);
public:
// IUnknown Methods
STDMETHODIMP QueryInterface(REFIID riid, void **ppv);
STDMETHODIMP_(ULONG) AddRef(void);
STDMETHODIMP_(ULONG) Release(void);
// IThesaurus
STDMETHODIMP LookUp()
{ wprintf(TEXT("Lookup success...\n")); return S_OK; }
private:
// Helper member function to create the inner object for reuse.
void CreateInnerObject();
};So far, everything’s fairly simple. Now look at the private CreateInnerObject function, which creates and aggregates the inner object. As seen in the following code, you query only for the inner IUnknown when creating the inner COM object, as this is a requirement stipulated by COM. If you request for any other interface at this moment, you won’t be able to create the inner object for aggregation. Also, notice that when you create the inner object (CoOcrEngine represented by CLSID_OcrEngine) using the CoCreateInstanceEx API function, you pass the this pointer as the second parameter, which represents the outer (controlling) IUnknown. As another requirement mandated by COM, this allows the inner object to detect that it is being aggregated, so that it will provide the correct support for the COM identity of the outer object.
void CoThesaurus::CreateInnerObject()
{
// Only request for inner IUnknown when aggregating.
MULTI_QI mqi[] = { {&IID_IUnknown, NULL, S_OK} };
// Prevent possible premature self-destruction.
InterlockedIncrement(&m_lRefCount);
// Create the inner object, notifying it that we're aggregating it.
HRESULT hr = CoCreateInstanceEx(CLSID_OcrEngine,
this, // Outer unknown, tells the inner object it's being aggregated.
CLSCTX_SERVER, NULL, sizeof(mqi)/sizeof(mqi[0]), mqi);
InterlockedDecrement(&m_lRefCount);
if (SUCCEEDED(hr) && SUCCEEDED(mqi[0].hr)) {
// Save the inner unknown as a member variable.
m_pUnkAggregate = reinterpret_cast<IUnknown *>(mqi[0].pItf);
} else {
assert(false);
}
}Notice that a pair of InterlockedIncrement/InterlockedDecrement calls wraps the CoCreateInstanceEx invocation. This is a technique that protects the outer object from premature self-destruction. Recall that the constructor of CoThresaurus calls this function, which means that, at this moment, the reference count (m_lRefCount) of this object is zero.
Assume in the earlier code that you don’t have the pair of InterlockedIncrement/InterlockedDecrement wrapping the CoCreateInstanceEx call. When you call CoCreateInstanceEx, the inner object will be created. During its creation, assume for some weird reason that the inner object queries the outer object for an IThesaurus interface, which increments the outer object’s m_lRefCount to one. Assume also that it then releases the interface, sending the outer object’s m_lRefCount back to zero. Then recall that in the Release method, an object deletes itself when it detects that its reference count has fallen to zero, which means that the call to Release will trigger the untimely destruction of the outer object. To prevent this problem, you can temporarily bump up the outer object’s reference count before creating the inner object. Now, if the inner object queries for an outer interface (outer m_lRefCount=2) and immediately releases (outer m_lRefCount=1) it, the reference count of your object will be one, which fixes the premature self-destruction problem. Be advised that you’re calling InterlockedDecrement instead of calling your own Release method. If you had called Release, you would face the same problem of premature self-destruction. Since we use InterlockedDecrement, you’ll need to be consistent and also use InterlockedIncrement.
Finally, you need to add simple code to the outer object’s QueryInterface method. As seen in the following, you forward all the QueryInterface calls for IOcr and ISpell to the inner object, using the implicit IUnknown pointer (m_pUnkAggregate) that you’ve saved earlier.
STDMETHODIMP
CoThesaurus::QueryInterface(REFIID riid, void** ppv)
{
if (ppv==NULL) { return E_INVALIDARG; }
if (riid==IID_IUnknown) {
*ppv= static_cast<IThesaurus *>(this);
} else if (riid==IID_IThesaurus) {
*ppv= static_cast<IThesaurus *>(this);
} else if (riid==IID_IOcr||riid==IID_ISpell) {
// Support Aggregation...
// Let the inner object handle this request,
// since both interfaces belong to the inner object.
return m_pUnkAggregate->QueryInterface(riid, ppv) ;
} else {
*ppv=NULL; return E_NOINTERFACE ;
}
reinterpret_cast<IUnknown *>(*ppv)->AddRef();
return S_OK;
}As you can see, it’s easy to reuse a COM object that supports aggregation. However, developing COM objects that support aggregation requires much more effort.
So far, we’ve gone over the code that’s necessary for an outer object to aggregate an inner object, but you haven’t learned about what’s needed for an inner object to support aggregation. This is what you’re about to embark upon. First, an inner object that supports aggregation must be packaged in an in-process server, since aggregation doesn’t work across apartment boundaries. An in-process server will likely meet this criteria, since it runs in the same process as the outer object.[47]
Besides this requirement, you need to provide two different implementations of IUnknown, as mandated by the COM Specification. Figure 4-7 shows two instances of the CoOcrEngine object that can be aggregated. The instance on the left is a normal CoOcrEngine object, and the one on the right is a CoOcrEngine object that is being aggregated by an outer entity. Each of these objects has a group of finely dotted lines along with an arrow.
To provide two different implementations of IUnknown, you need to perform a few C++ tricks. The tricks you perform must point this arrow to the correct unknown that manages the resulting object’s identity. Depending on whether this object is being aggregated, this can be either the inner object’s implicit unknown or the outer object’s controlling unknown. Specifically, when the inner object is not being aggregated, you must point this arrow to the implicit unknown. In this case, no outward delegation happens. However, if the inner object is being aggregated, you must point this arrow to the controlling unknown, which is owned by the outer object. This allows the inner object to delegate outward. Imagine Figure 4-7 as you implement the two unknowns.
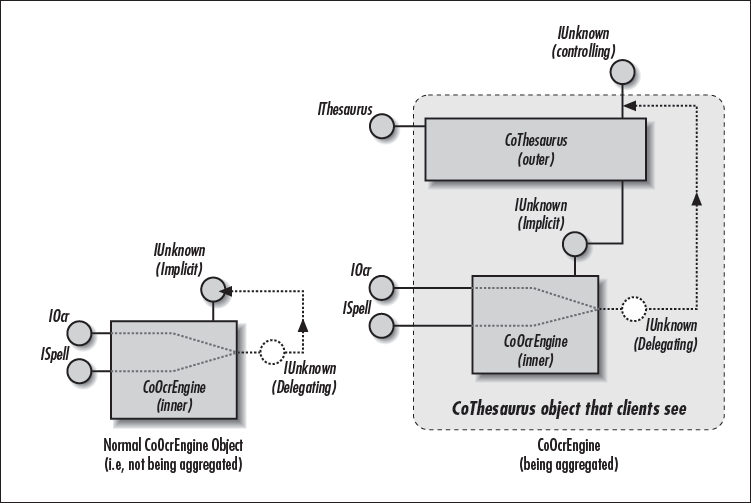
The first IUnknown is the implicit unknown, which is clearly labeled in Figure 4-7. This is the unknown that is normally used when the inner object is not being aggregated. Shown below is a generic and templatized implementation of the implicit unknown (See the C++ Templates sidebar found later if you’re not familiar with C++ templates). The implicit unknown simply implements the IUnknown interface. The Bkptr function is used to set the back pointer to the object (CoOcrEngine) that implements the nondelegating methods of the implicit unknown, which include InternalQueryInterface, InternalAddRef, and InternalRelease (to be discussed in a moment).
// IMPLITCIT UNKNOWN // Works with three special, private methods to implement // the nondelegating unknown. template<class T> class CImplicitUnknown : public IUnknown { public: // m_pbkptr points to the object implementing the // nondelegating IUnknown methods. void Bkptr(T *p) { m_pbkptr=p; } STDMETHODIMP QueryInterface(REFIID iid, void **ppv) { return m_pbkptr->InternalQueryInterface(iid, ppv); } STDMETHODIMP_(ULONG) AddRef(void) { return m_pbkptr->InternalAddRef(); } STDMETHODIMP_(ULONG) Release(void) { return m_pbkptr->InternalAddRef(); } private: T *m_pbkptr; };
Since CImplicitUnknown is a template class, T represents the class that implements these internal methods. Even though CImplicitUnknown is generic, it assumes that the nondelegation IUnknown methods are named InternalQueryInterface, InternalAddRef, and InternalRelease. As shown in the earlier code snippet, the QueryInterface, AddRef, and Release methods simply forward to m_pbkptr’s InternalQueryInterface, InternalAddRef, and InternalRelease respectively. This will be clear in a moment when you implement CoOcrEngine, but here’s a hint: m_pbkptr will be pointing to a CoOcrEngine object. Thus, CoOcrEngine must implement the nondelegating InternalQueryInterface, InternalAddRef, and InternalRelease methods.
The second IUnknown is the delegating unknown, which delegates all IUnknown methods outward to the controlling unknown of the outer object. The reason for this is to maintain the outer object’s COM identity and lifetime management, since the outer object is the only object of this aggregate that a client sees. Put differently, an outer object’s client will never know that an inner object exists. However, if a client calls QueryInterface on an interface (not including IUnknown) pointer that really belongs to the inner object, the inner object must notify the outer object of the QueryInterface call to allow the outer object to correctly manage its identity. Likewise calls to AddRef and Release must also be delegated to the outer object to allow the outer object to correctly manage its lifetime.
Remember, these outward delegations are shown by the group of dotted lines in Figure 4-7. The lollipop for the delegating unknown is dotted to show that it delegates outward to the controlling unknown only when the inner object is being aggregated. When the inner object is not being aggregated, it delegates to its own implicit unknown.
Following is a rewrite of the CoOcrEngine COM object to support aggregation. Notice that you have a member variable that represents the implicit unknown, m_InnerUnk. Also, you keep a member variable called m_pOuterUnk, which points either to the outer object’s controlling unknown when being aggregated or to this object’s implicit unknown when not being aggregated.
class CoOcrEngine : public IOcr, public ISpell {
LONG m_lRefCount;
friend CImplicitUnknown<CoOcrEngine>;
// Represents the implicit IUnknown of this object.
CImplicitUnknown<CoOcrEngine> m_InnerUnk;
// Points either to the outer object's IUnknown
// or to this object's implicit IUnknown.
IUnknown *m_pOuterUnk;Correctly setting the m_pOuterUnk pointer is the trick to developing objects that support aggregation. Specifically, m_pOuterUnk must point to the unknown that manages the resulting object’s identity. Set this pointer in the constructor of CoOcrEngine.
As shown in the later code snippet, the constructor has a parameter that represents the outer IUnknown pointer. If this pointer is non-NULL, this object is being aggregated. In this case, you make a copy of the outer unknown’s interface pointer (m_pOuterUnk(pOuterUnk)). However, don’t call AddRef on this pointer because the inner object’s lifetime is a subset of the outer object’s lifetime. In other words, the outer object determines the creation and destruction of the inner object.
On the other hand, if the pointer passed into the constructor is NULL, this object is not being aggregated; and therefore, you’ve got no outer object. In other words, you are either being contained or being used as a normal object. In this case, you need to set m_pOuterUnk to point to m_InnerUnk (the implicit unknown). Since there’s no outer object, you delegate to your own implicit unknown to preserve the object’s identity.
public: CoOcrEngine(IUnknown *pOuterUnk) : m_lRefCount(0), m_InnerUnk(), m_pOuterUnk(pOuterUnk) { ComponentAddRef(); // Set the inner unknown back pointer to point to this object, // so that we can later call special internal functions, // which supports the implementation of the implicit unknown. m_InnerUnk.Bkptr(this); if (pOuterUnk==NULL) { // We're not being aggregated; therefore, we've got no outer object. // Set the outer unknown to be the non-delegating or implicit unknown, // since we're either being contained or used as a normal object. m_pOuterUnk = &m_InnerUnk; } } ~CoOcrEngine() { ComponentRelease(); } static HRESULT CreateObject(LPUNKNOWN pOuterUnk, REFIID riid, void **ppv);
As shown in the earlier code snippet (m_InnerUnk.Bkptr(this)), you set the back pointer of the implicit unknown to point to this object regardless of the argument passed into the constructor. You do this so that you can later call the nondelegating InternalQueryInterface, InternalAddRef, and InternalRelease methods. You will write the code for these methods shortly.
For now, examine the code for the delegating IUnknown methods, which are shown in the following code snippet. Remember, the delegating IUnknown methods delegate to the unknown that manages the object’s identity. When this object is being aggregated, these methods (QueryInterface, AddRef, and Release) simply delegate outward to the controlling unknown of the outer object. When this object is not being aggregated, these methods simply forward calls to the implicit unknown, which reroutes the calls to the nondelegating InternalQueryInterface, InternalAddRef, and InternalRelease methods. The resulting behavior depends upon where m_pOuterUnk points. Recall that you make m_pOuterUnk point to either the implicit or the controlling unknown in the constructor of CoOcrEngine.
public: STDMETHODIMP QueryInterface(REFIID iid, void **ppv) { return m_pOuterUnk->QueryInterface(iid, ppv); } STDMETHODIMP_(ULONG) AddRef(void) { return m_pOuterUnk->AddRef(); } STDMETHODIMP_(ULONG) Release(void) { return m_pOuterUnk->Release(); } // IOcr Methods STDMETHODIMP OcrImage(long lImageSize, byte *pbImage, wchar_t **pwszOcrText); STDMETHODIMP OcrZone(long lImageSize, byte *pbImage, Zone zone, wchar_t **pwszOcrText); // ISpell Methods STDMETHODIMP Check(wchar_t *pwszWord, PossibleWords *pWords);
Now for the nondelegating IUnknown methods. These methods are an exact replica of the normal implementation of IUnknown for a simple COM object, except for the following code shown in boldface. Really, only the names have been changed, because you can’t overload functions with the same signature in C++. The boldfaced code within the InternalQueryInterface method is needed, because COM mandates that when anyone queries for the IUnknown interface of your inner object, you always return the implicit unknown pointer. Recall that the implementation of the CImplicitUnknown methods simply forwards to these internal methods.
private: HRESULT InternalQueryInterface(REFIID iid, void **ppv) { if (ppv==NULL) { return E_INVALIDARG; } if (riid==IID_IUnknown) { // Always return the implicit unknown, // when anyone requests for IUnknown. *ppv= static_cast<IUnknown *>(&m_InnerUnk); } else if (riid==IID_IOcr) { *ppv= static_cast<IOcr *>(this); } else if (riid==IID_ISpell) { *ppv= static_cast<ISpell *>(this); } else { *ppv=NULL; return E_NOINTERFACE ; } reinterpret_cast<IUnknown *>(*ppv)->AddRef(); return S_OK; } ULONG InternalAddRef(void) { return InterlockedIncrement(&m_lRefCount); } ULONG InternalRelease(void) { long lCount = InterlockedDecrement(&m_lRefCount); if (lCount == 0) { delete this; } return lCount; } };
There are a few remaining important points before you can complete the support for aggregation. Recall that CreateObject is a static method that is called by a class factory’s CreateInstance method to actually create the COM object. COM mandates that in order for an outer object to aggregate the inner object, it must only request for the inner object’s IUnknown when it creates the inner object. Check this requirement in the first few lines of the following code snippet:
HRESULT CoOcrEngine::CreateObject(LPUNKNOWN pOuterUnk, REFIID riid, void**
ppv)
{
*ppv = NULL;
// If aggregating, must initially request for IID_IUnknown.
if (pOuterUnk != NULL && riid != IID_IUnknown)
return CLASS_E_NOAGGREGATION;You then dynamically allocate the inner object, passing along the outer unknown. If the argument is NULL, this inner object is either being contained or being used normally by a client.
// Create the new object with a possibly valid outer unknown. CoOcrEngine * pEngine = new CoOcrEngine(pOuterUnk); if (pEngine == NULL) { return E_OUTOFMEMORY; }
Finally, you query for the requested interface using InternalQueryInterface, which is a nondelegating method of the inner object’s implicit unknown. We must use the nondelegating InternalQueryInterface method when the object is created. Do not call QueryInterface. If you do, it will delegate outward to the outer object’s QueryInterface method, which will delegate back into the inner QueryInterface method, and so on recursively.
// If aggregating, the first query MUST be sent to the implicit // IUnknown requesting for IUnknown. HRESULT hr = pEngine->InternalQueryInterface(riid, ppv); if (FAILED(hr)) { delete pEngine; } return hr; }
As you have seen, it takes some work on both the outer and inner objects to provide support for aggregation. You know a few major advantages and disadvantages associated with COM aggregation. Be aware that aggregation will not work across apartment boundaries, including processes and machines. Since this is very important for distributed computing, many developers choose containment over aggregation as the binary reuse mechanism.
Get Learning DCOM now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

