In a three-tier environment such as the one shown in Figure 1-4, software developers distributed responsibility among each participant. They took away some intelligence from the clients, in a way that clients would act only as a front-end. In other words, clients were responsible for simply displaying, capturing, and validating user data. From this, a new terminology came into existence. The term “thin client” was used to represent the first tier in a three-tier system. PCs that ran these clients did not need to be high-end. These first-tier clients would communicate with the middle-tier servers via a remoting standard, remote procedure calls (RPC), to be discussed in a moment.
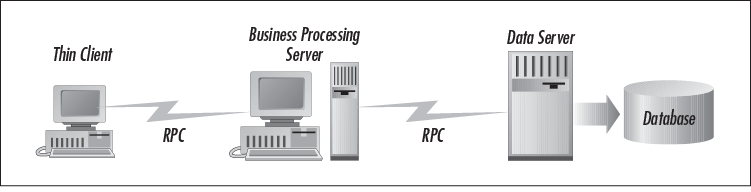
The middle tier was a server tier that supported complex business processing (e.g., calculate expense and calculate factorials) for its clients. Most of the performance problems found on the client end in the client/server scenario had now been relocated to this second tier. Therefore, the middle tier had to be powerful and smart. It had to be a high-end computer, running operating systems such as Windows NT or Solaris, with multiple CPUs to take advantage of symmetric multiprocessing. These middle-tier servers would communicate with the back-end third tier, again using the RPC standard.[1] The third-tier, back-end servers managed persistent business data, and usually exchanged information directly with a database. This tier was also placed on high-end computers.
As you can see, a three-tier architecture allows separation of responsibility, thereby permitting each participant to perform only what is suited to it. To assist in distributing responsibility, software developers use some form of RPC—either the version developed by Sun Microsystems (ONC RPC) or the Distributed Computing Environment (DCE RPC).
RPC is a well-known standard that supports the idea of calling functions remotely. For example, assume you have a function called CalculateExpense, which is implemented on a remote server. To invoke this function, a client would make a normal function call. However, the function is actually executed on the server machine that could be anywhere. This is what we call location transparency, since the called function can be implemented locally or remotely. In other words, the caller is oblivious to the location of the target function.
How is this possible? It is possible through the basic principle of separating interface from implementation. Before you can take advantage of RPC, you must specify an interface using the Interface Definition Language (IDL). Think of an interface as an application level communications protocol that includes a number of functions (intelligent verbs) that clients and servers can use to collaborate. The interface, which is identified by a Universally Unique Identifier (UUID), describes a group of function prototypes that can potentially be called remotely. Once you have specified your interface, you would then use an IDL compiler to automatically generate marshaling code called client and server stubs. After linking these stubs into your client and server applications, you can easily make remote function calls. It is the job of the client stub to marshal the data and send it to the server stub. The server stub executes the target function and returns data to the client stub, which then returns the data to the caller.
RPC brings dramatic value to the software world. Since the marshaling code is automatically generated, software developers can now totally eliminate the arduous hours they have previously wasted in developing customized marshaling software. Put differently, RPC allows developers to concentrate their efforts on the functionality of their application, not on communications and network protocols.
The obvious advantage that RPC brings is location transparency. Thanks to the seamless support for location transparency, developers can easily extend the idea of three-tier systems into multi-tier systems. In fact, this notion allows commercial vendors to introduce brokers into distributed systems to manage server location, naming, and load balancing. Besides the location transparency benefit, RPC comes with built-in support for security, thereby allowing software developers to remove themselves from building nonstandard security functionality into their systems. Moreover, RPC supports the notions of multithreading and network protocol independence. With the advent of RPC, it becomes easy to distribute functionality and services across the entire enterprise, and as a result this popularized the term distributed computing.
[1] Or some other form of communication might be used. For consistency, the example shown here uses RPC as the mechanism for second- to third-tier communications. Other three-tier systems may choose another mechanism for second- to third-tier communications.
Get Learning DCOM now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

