Service providers have deployed and enterprises have used IP networks for a couple of decades now, routing IP packets over a core network. The core network in these deployments consists of a series of IP routers. Recently, the trend has been to deploy a Layer 2 technology (Ethernet) in place of, or to augment, the Layer 3 networks. In this engagement, our tribe of network warriors assisted an enterprise (wishing to become a limited service provider) in deploying a Layer 2 virtual private network (L2VPN) service in one of the most inhospitable environments possible: Alaska.
This network warrior is a Vermonter, and we consider our state to be rugged and, for the most part, sparsely populated. I can now say we are mistaken. Alaska is wilderness; it has a similar population to Vermont (~730,000 versus ~630,000) but almost 70 times the land mass (663,000 sq. mi. versus 9,600 sq. mi.). The old Vermont saying, “Ya can’t get thar from here,” applies in Alaska as well, because for the most part there are no roads to get where you want to go. I heard an ad specify that one in five of the Alaskan population holds a pilot’s license, and now I understand why. A traveler in Alaska uses every available means to get from point A to point B: cars, planes, trains, quad bikes, 4x4s, and yes, sleds (although powered by gas, not dog food).
Deploying a network in such an environment likewise requires the use of every available transmission technology: fiber, terrestrial microwave, wire (DS1s and DS3s), and even satellite links. Links are rented, owned, and shared by service providers, universities, the state, and other companies. Combining these links into an IP network is not a gigantic challenge: IP is self-policing as far as link changes are concerned. Fragmentation happens at the low-speed links and reassembly happens at the end points. IP packets flow between the routers on a per-hop basis, stitching a path between end stations one router at a time. The paths are dynamic in nature and are determined by routing protocols and the “costs” of the links between them. The enterprise went into this project with a high confidence level because the IP network it had stitched together in the past had performed to expectations.
When an L2VPN is deployed, the network becomes an area-wide Ethernet bridge. Sites are interconnected by an Ethernet broadcast domain, not by IP hops. Routers are not needed in this environment—their only function is to interconnect the different broadcast domains that might be deployed. This may sound to the typical IT person like a simpler, easier, more efficient solution to interconnectivity than all the bother of IP networks. There are two different L2VPN technologies that are being deployed today. The first is a point-to-point technology that provides Ethernet links between sites. This virtual private wire service (VPWS) creates pseudowires between sites to transport Layer 2 frames. Switches or routers are used to terminate the pseudowires and determine where traffic can and should flow. VPWS connectivity is depicted in Figure 4-1, where each user site is connected to the L2VPN service by an Ethernet switch.
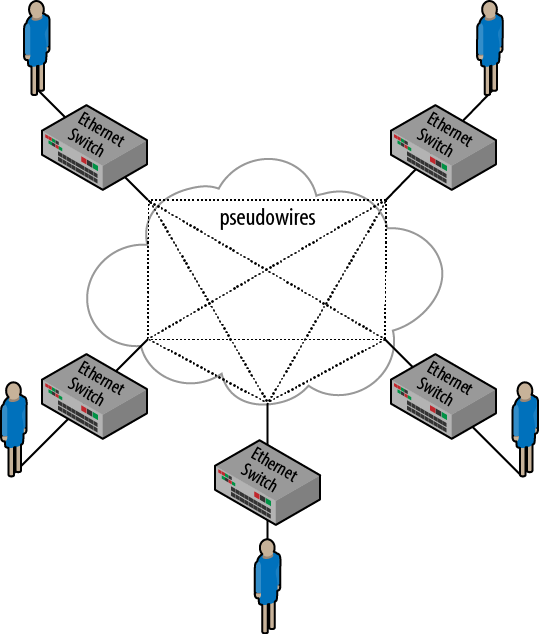
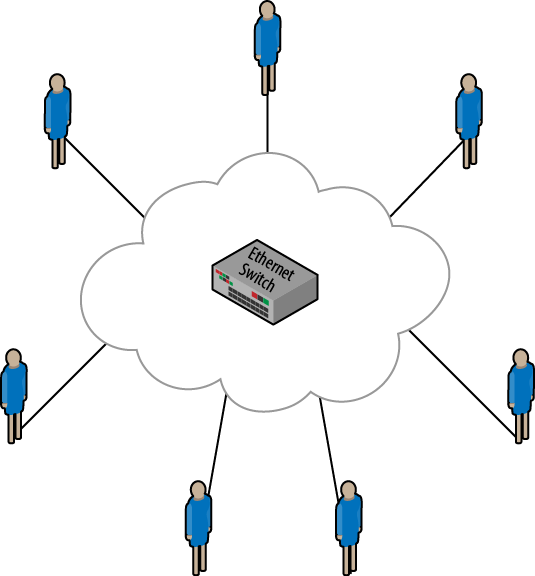
The second technology is called virtual private LAN service (VPLS). While it’s based on a similar technology to VPWS, VPLS offers any-to-any connectivity between sites in an enterprise. The core network looks like a gigantic switch rather than a series of point-to-point links. For this engagement, the VPLS technology was chosen. Each site was to be interconnected to the cloud, and the cloud provided Ethernet switching (MAC learning bridging, using the old-school terminology), as shown in Figure 4-2.
L2VPN technologies are not new; they have been deployed in various environments and for different applications for a number of years. The issue with L2VPNs in general, and specifically VPLS L2VPN implementations, is that there is no concept of fragmentation in the network. In a classical IP network, routers do the fragmentation. In a classical bridged network, the theory is that this is a local area network and maximum transmission unit (MTU) changes should not be seen. However, when you add interconnecting links to the bridge network, you might have a problem. If the MTU is the same on all the links, all is well, but when there are links with differing MTUs, this is where network warriors start to earn their pay.
As traffic enters the VPLS network, the ingress device (PC or router) can fragment the traffic to the specified MTU of the local link. If the frame then encounters a link that cannot handle that MTU, the frame is dropped (ouch), and no ICMP message is returned to indicate that an issue was experienced (ouch again). In most VPLS networks, there are no means for fragmenting an Ethernet frame and no routers to fragment the IP packets—remember, the network looks like a big Ethernet switch.
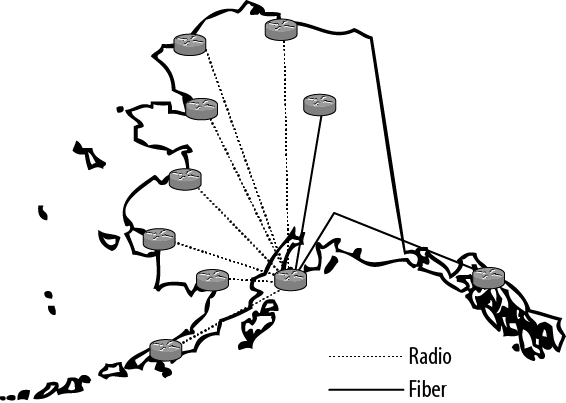
A bunch of Juniper Networks warriors were brought in to deploy an L2VPN based on VPLS technology in a network with multiple remote locations reached by various transmission means. The warrior tribe for this assignment was a trimmed-down group of professional service engineers, like me, and the client’s networking engineers. Added to this mix were radio and satellite engineers who were called in for certain skirmishes. The client owns, rents, borrows, and shares transmission media from various providers. There are local exchange carrier links (T1s and DSL), long-distance provider links (T1s and DS3s), fiber channels (OC3 and OC12s), and radio links from any number of sources, including terrestrial microwave and satellite microwave (Ethernet and T1). Due to this arrangement, the client did not have direct control over the transmission system. However, they did own the routed network, which consisted of a mixture of Juniper Networks M-series and MX-series routers and EX-series switches. Because of the cost of transmission facilities and the geographic realities of Alaska, the network was a giant star, as shown in Figure 4-3. Many of the remote locations had names that us folks in the lower 48 find hard to pronounce (Emmonak, Kotlik, or Unalakleet), yet some were familiar from a historical or romantic perspective (Nome, Fairbanks, and Barrow).
The problem that we were facing was that the transmission systems had different maximum frame sizes, and we had no way of adjusting the frames automatically. An experienced reader would pipe in at this point and say, “Hey Peter, it’s all Ethernet, the standard has been around forever and everybody supports it.” And you would be right, except that we were transmitting not only Ethernet, but Ethernet encapsulated in multiprotocol label switching (MPLS).
The problem definition has to start with some networking basics.
Note
Sorry for the Networking 101 stuff, folks, but this is where a warrior has to go when the head scratching begins and it’s time to start counting bytes.
When a ping is generated from a PC connected to an Ethernet segment, Figure 4-4 is what’s seen at the command prompt.
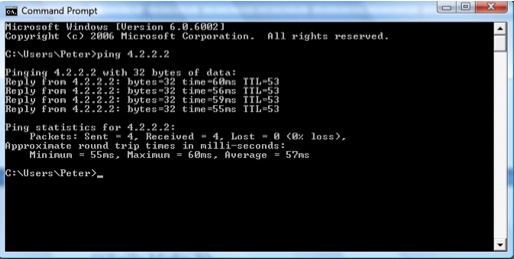
The basic ping is sending 32 bytes of data (abcdefg...) and receiving the same from the destination (in this case, 4.2.2.2). The basic frame format for a ping on an Ethernet is:
An ICMP header (8 bytes) is added to the data to form a message.
An IP header (20 bytes) is added to the ICMP header to form a packet.
The IP packet is encapsulated in an Ethernet frame that has a header (14 bytes) and a trailer (4 bytes).
Other Ethernet stuff (preamble bits) is added to the frame and the frame is transmitted on the wire.
So, our 32 bytes of data are surrounded by (8 + 20 + 14 + 4 = 46) 46 bytes of protocol overhead, plus the preamble bits. If you discount the preamble, the frame that is transmitted on the wire is 78 bytes long and looks like Figure 4-5.

If the network were a series of interconnected links pushing Ethernet frames, we’d be able to end the Networking 101 review at this point. But sadly, that is not the case—we have two more pieces to add to this networking warrior puzzle.
Because the client had many different departments that needed connectivity, and they also thought that once this beast was up and running they might be able to sell service to other companies in the area, they decided to use virtual LAN (VLAN) tagging to differentiate the departments and to differentiate between companies. This double tagging for Ethernet frames is called Q-in-Q tagging and is defined in IEEE standard 802.1Q. The dual VLAN tags (4 octets each) are installed in the Ethernet header and expand the header from 14 octets to 22 octets. The Q-in-Q-enhanced Ethernet header now looks like Figure 4-6.

The first and second tags each contain a type field that says that a tag is being carried. The final EtherType field defines the actual payload that is being carried (an IP packet). The addition of the Q-in-Q headers increases the ping packet size from 78 octets to 86 octets. This increase happens not at the PC, but at the first switch that is encountered. This is an important detail because of where fragmentation is occurring in the system. The PC is fragmenting the initial message to fit into packets that can go on the wire using a default MTU (1,518 bytes) for that fragmentation decision. If a switch then adds information to that frame, increasing the total size by 8 bytes, the 1,518-byte maximum-sized frame is now 1,526 bytes.
The second piece of this puzzle is that the Ethernet frames (really Q-in-Q frames) are not being placed on the wire for transport to the destination, but are being carried over an MPLS infrastructure. As stated previously, the client deployed a VPLS infrastructure to transport the Ethernet traffic between locations. The use of VPLS again adds to the overhead of the information being carried.
When we consider VPLS, the overhead calculation for our initial ping starts as it did initially:
An ICMP header (8 bytes) is added to the data to form a message.
An IP header (20 bytes) is added to the ICMP header to form a packet.
The IP packet is encapsulated in an Ethernet frame that has a header (14 bytes) and a trailer (4 bytes).
The Ethernet frame then encounters the first VPLS provider edge router. At this point:
The Ethernet frame is stripped off the trailer (−4 bytes).
A VPLS (customer) label is added to the Ethernet frame (4 bytes).
An MPLS (transport) label is added to the VPLS label (4 bytes).
The MPLS frame is encapsulated in the transport medium framing, which in this case is Ethernet (14 bytes header and 4 bytes trailer).
For those who have not battled with VPLS or MPLS before, the concepts of labels and label stacking might have just raised some serious flags (like, “Whoa there, where did that crap come from?” types of flags). MPLS is a switching technology very similar to frame relay (FR) and asynchronous transfer mode (ATM) from the old schools. The payload is given a header that identifies a path through the network. The header is the label. The difference between FR/ATM and MPLS is that MPLS exists on the same IP infrastructure as normal IP traffic. The payload and the MPLS headers are sent between routers over the same links as normal IP traffic. In our example, the Ethernet header identifies the payload as MPLS rather than IP—it’s a pretty slick technology.
An MPLS network supports multiple service types (Layer 3 VPNs and L2VPNs being two of them). Another header (label) is added to differentiate between these services and the customers on these services. The labels exist above the Ethernet header and below the payload headers in the protocol stack. The OSI purists call MPLS a Layer 2.5 protocol or a shim protocol because it does not line up neatly in the OSI stack of definitions.
Note
From a warrior’s point of view any weapon that gets the job done is just as good as any other, so it’s a great thing that Juniper Networks is known to stick to the standards, unlike other vendors who tend to make their own standards. With Juniper Networks gear, interoperability and stability between (most) vendors is a given.
In our implementation, VPLS uses two labels for passing traffic over the network: the transport label identifies the path that the traffic is to use between the edge devices, and the customer label identifies the traffic as VPLS and belonging to a specific customer. For us, the mapping of VLAN tags and VPLS labels provides that one-to-one correspondence between customers and VPLS labels. In a default Juniper Networks MPLS network, the transport label is “popped” (extracted) by the second-to-last router in the MPLS path. This process, called penultimate-hop popping, is used to reduce the processing on the last (ultimate) router.
Figure 4-7 follows a frame in this environment that arrives at the edge router (called a provider edge or PE router). Two labels, transport and customer, are added (pushed) onto the packet. The transport label will be swapped at each internal router (called a provider or P router) until the frame hits the second-to-last (penultimate) router. At the penultimate router, the transport label is popped and the frame with the customer label is delivered to the destination PE router. The destination PE pops the customer label, maps the traffic to the correct outgoing interface, and sends the frame on its way. The label identifiers that are commonly found in Juniper Networks routers are between 250000 and 300000.
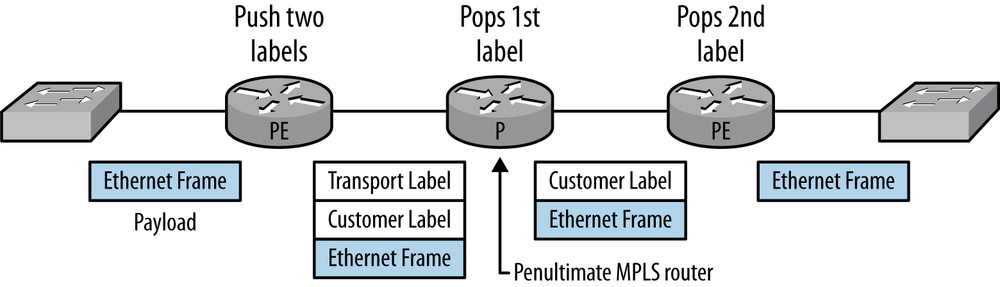
There is one additional note to be added here: the MPLS labels cannot transport traffic between routers without a true data link and physical layer protocol (this is a difference from FR and ATM networks). Our MPLS label, etc. are wrapped in whatever data link protocol is running between the routers. In our example, this happens to be Ethernet.
Given this last piece of information, our 32-byte ping data now has a whopping 72-byte header attached:
| 8 – ICMP header |
| +20 – IP header |
| +4 – 802.1Q tag#1 |
| +4 – 802.1Q tag#2 |
| +14 – Ethernet header (original) |
| −4 – Ethernet trailer (original, stripped) |
| +4 – MPLS label, customer |
| +4 – MPLS label, transport |
| +14 – Ethernet header (new) |
| +4 – Ethernet trailer (new) |
| = 72 total overhead bytes |
The additional overhead makes the packet on the wire 104 bytes long!
During testing, the warriors captured traffic that showed all these levels of overhead. The ping was a 1,000-byte ping from a Juniper Networks router, not the 32-byte ping that we have been using for the preceding analysis, but the overhead showed the full protocol stack:
Ethernet II, Destination: JuniperN_db:ba:00 (00:24:dc:db:ba:00) Source: JuniperN_03:be:01 (00:1d:b5:03:be:01) Type: MPLS label switched packet (0x8847)MultiProtocol Label Switching Header, Label: 262152, Exp: 0, S: 1, TTL: 255MultiProtocol Label Switching Header, Label: 301152, Exp: 0, S: 0, TTL: 255Ethernet II, Destination: JuniperN_db:9b:80 (00:24:dc:db:9b:80) Source: JuniperN_db:9b:81 (00:24:dc:db:9b:81) Type: 802.1Q Virtual LAN (0x8100)802.1Q Virtual LAN, PRI: 0, CFI: 0, ID: 488 Type: 802.1Q Virtual LAN (0x8100)802.1Q Virtual LAN, PRI: 0, CFI: 0, ID: 516 Type: IP (0x0800)Internet Protocol, Src: 1.1.2.1 (1.1.2.1), Dst: 1.1.2.2 (1.1.2.2) Version: 4 Header length: 20 bytes Differentiated Services Field: 0x00 (DSCP 0x00: Default; ECN: 0x00) Total Length: 1028 Identification: 0xbad3 (47827) Flags: 0x00 Fragment offset: 0 Time to live: 64 Protocol: ICMP (0x01)Internet Control Message ProtocolType: 8 (Echo (ping) request) Code: 0 () Checksum: 0xbdd8 [correct] Identifier: 0xef03 Sequence number: 9488 (0x2510) Data (1000 bytes)
Note
In today’s environment of Ethernet switches, it is all but impossible to find a shared-bandwidth hub. These old devices allowed a protocol sniffer (packet analyzer) to monitor traffic between any two devices. Each port saw all the traffic on the hub. To gather the same traffic for a sniffer, Ethernet switches have to be configured to allow a monitor port. For Juniper Networks EX switches, the configuration for this function is call port mirroring. The configuration is:
[edit ethernet-switching-options]
analyzer vpls {
input {
ingress {
interface ge-0/0/23.0;
interface ge-0/0/21.0;
}
}
output {
interface {
ge-0/0/22.0;
}
}
}In this configuration, the ports ge-0/0/23 and ge-0/0/21 are the traffic-carrying ports. The traffic is mirrored to port ge-0/0/22, where the sniffer is attached. There are all sorts of restrictions on port mirroring on the devices, so check out the Juniper techpubs for all the details.
All of this warrior protocol analysis stuff showed that there was a lot of overhead on our network. While this is not an issue in itself, there are many more complex protocol stacks in use in the industry today. In this case, the overhead added by the network after the packet was put on the wire caused our initial 78 bytes of traffic from the PC to grow to 102 bytes. This 24-octet growth could take a full-size Ethernet frame (1,518 bytes) and make it bigger than the default MTU of a link. If the device terminating that link is unable to fragment the packet, it will discard this traffic.
This is the crux of our problem. The devices in the network do not fragment the traffic once the PC has transmitted it. All of the devices on the network are supposedly working at the Ethernet layer and do not support fragmentation. If a network link supports less than the required (1,518 + 24 = 1,542) MTU, then VPLS over that link will fail.
RFC 4448 defines the encapsulation of Ethernet frames in an MPLS/VPLS network. The applicable paragraph from the RFC states the issue:
6. PSN MTU Requirements
The MPLS PSN MUST be configured with an MTU that is large enough to transport a maximum-sized Ethernet frame that has been encapsulated with a control word, a pseudowire demultiplexer, and a tunnel encapsulation. With MPLS used as the tunneling protocol, for example, this is likely to be 8 or more bytes greater than the largest frame size. The methodology described in [FRAG] MAY be used to fragment encapsulated frames that exceed the PSN MTU. However, if [FRAG] is not used and if the ingress router determines that an encapsulated Layer 2 PDU exceeds the MTU of the PSN tunnel through which it must be sent, the PDU MUST be dropped.
The failures are interesting to note. A normal ping will work, and an extended ping will work up to a limit (1,472 seems to be the limit), while larger pings will simply time out. An FTP over the link will work most of the time but will have a very slow response time. HTTP pages do not load. What this means to the casual observer is that the link is good, VPLS connections are good, MAC addresses are being learned, and pings are OK over the link. Only when traffic is actually tried between the edge devices is the link determined to be defective (often by the customer).
The first obvious solution to this problem was that all links must support MTUs greater than 1,542. If the client was in an East Coast city or a Midwest area, the MTU would be a design specification on the order form. A setting would be made on the fiber multiplexer, and all would be happy. But considering that we were not in any of those areas, and the transmission facilities were in some cases 20-year-old technologies, the option to “just change the MTU” was not possible. Other alternatives had to be explored. The warriors had to put their heads together.
RFC 4623, Pseudowire Emulation Edge-to-Edge (PWE3) Fragmentation and Reassembly, defines a mechanism for fragmenting traffic on a VPLS network. The RFC is interesting in that it states that other means should be used instead of fragmentation by the network devices to solve this issue. The list includes:
Proper configuration and management of MTU sizes between the customer edge (CE) router and provider edge (PE) router and across the VPLS/MPLS network.
Adaptive measures that operate with the originating host to reduce the packet sizes at the source. Path MTU and TCP MSS are two measures that are in common use.
The ability to recognize an oversized packet and fragment it at the PE router. The PE may be able to fragment an IP version 4 (IPv4) packet before it enters a VPLS/MPLS path.
Number one is the obvious answer that we already discussed. Number two is interesting in that it does work, but only for very specific applications: some standard web browsers (IE and Firefox) do not use these methods, so this option is not useful to us.
Number three is interesting, and we explored the possibility of using this as a solution. This issue here is that the solution is not scalable. We had to terminate each of the VLANs, create a routed interface for them, and adjust the default gateway of the devices on the customer’s LANs. These restrictions obviated the benefits of VPLS.
We looked into the fragmentation capabilities defined in the RFC, approached Juniper Networks for their take on the options, and were told that the Junos OS did not yet support VPLS/MPLS fragmentation (it may by the time you are reading this).
After a few more warrior sessions, two solutions to the problem were suggested.
The first solution was setting the MTU at the customer locations to a value less than 1,518 bytes. If the sending PC or the last router in the network set its MTU to a lower value, these devices would fragment the larger packets and solve our problem.
By reducing the MTU at the customer edge from 1,518 bytes (the default) to 1,494 bytes, we could ensure that the maximum frame size with all the additional overhead would remain below the 1,518-byte default that the transmission links can handle.
This solution worked for our client for their internal divisions, because they owned the infrastructure and managed the PCs and routers that connect to this network.
However, the solution did not work for the client’s long-range plans. They wanted to be able to recoup some of the cost of the network by selling interconnectivity services to other local companies. In these cases, they would not have control over the PCs and internal devices. An option for the proposed customers was to offer a “managed” router to interconnect with the customer and to set the MTU on the router’s outgoing interface. The solution, while not elegant, gave the client a means to move forward on the project.
The other solution was the deployment strategy for the MPLS VPLS service. The use of Q-in-Q VLAN tagging provides a separation between the client’s traffic from different departments and possible third-party traffic. The links that have the lower MTUs are the spoke links to the remote locations. Rather than deploying a router at the end of these spoke links and pushing MPLS to the remote locations, we thought, why not leave the links as Ethernet, deploy a switch to the remote locations, and install MPLS/VPLS at the core locations?
The solution is shown in Figure 4-8, and it moves the MPLS labels to the core of the network rather than the spokes of the network. The use of Q-in-Q on the links drops the requirement for the MTU from 1,542 to 1,526 bytes, an MTU that we found most vendors could support.
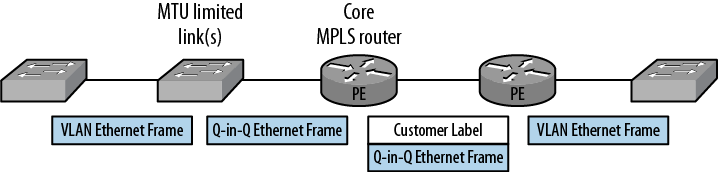
Our initial deployment used a combination of solutions. Where the client had routers that connected the traffic to the VPLS/MPLS network, the router’s outgoing interface MTU was adjusted to be 1,494 bytes. Where the client only had Ethernet equipment at the remote location, the redesign was used to limit the overhead at these locations. Finally, when the service is resold, a managed router will be used at the customer-facing interface to provide fragmentation.
At some point Juniper Networks will include fragmentation in the VPLS code, but this customer did not have the time to wait for that eventuality.
Once the design issues were resolved and the design could be rolled out, the actual configuration of the devices took place. The client allowed the devices to be staged prior to deployment into the nether regions of Alaska (the warriors were spared the pleasure of doing battle with the native warriors of that great state, although from what I hear, they would have kicked our butts all the way back to the lower 48).
Note
While not trying to make this sound like a travelogue, while in Alaska, I was introduced to many of the different native peoples of the region. The native lore includes tales of many impressive warriors. We hear many stories of the Wild West and those Native Americans, but very few of the Wilder Far Northwest and these fierce Native Americans.
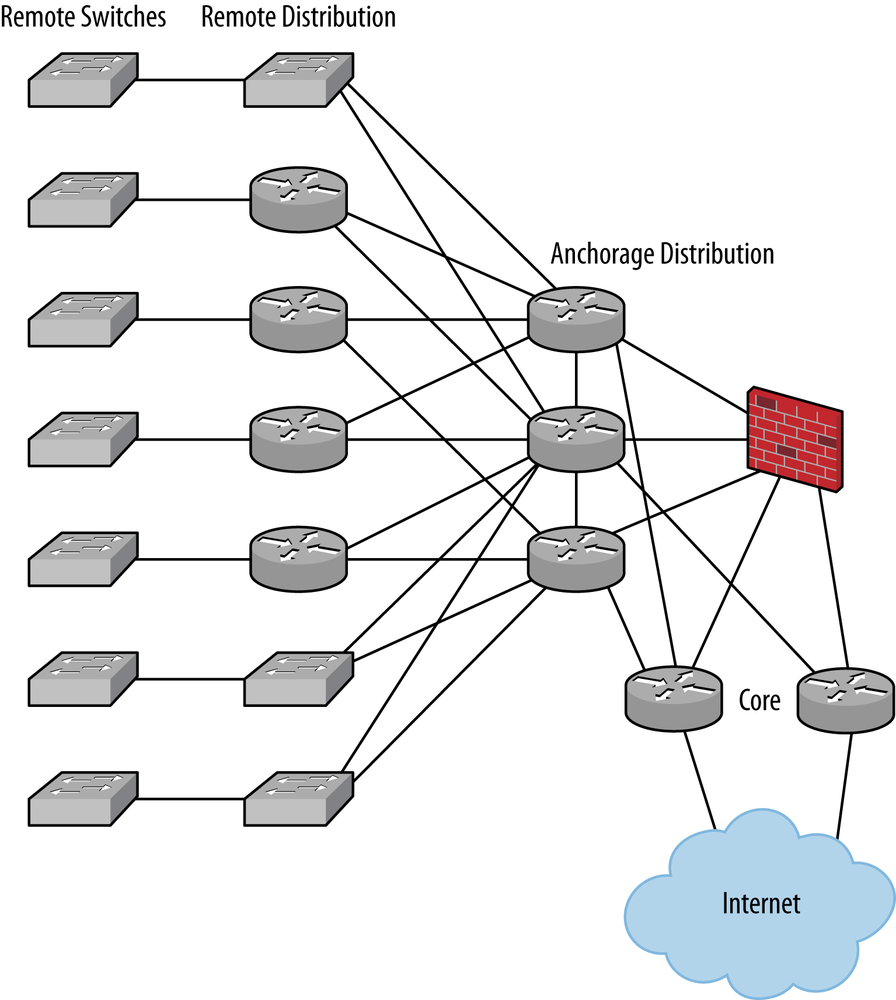
We initially deployed 20 devices in the staging area:
The core routers that were to be our primary Internet access devices and the router reflectors for the rest of the network
The primary distribution routers that served the local users and supported the firewalls to the Internet
The remote distribution routers where transmission facilities could handle the MTU of a full VPLS frame
The remote distribution switches where the transmission facilities were less than ideal
The remote managed switches for the customers
The network as staged looked like Figure 4-9.
Presented here are the configurations from one of each type of the devices. The configurations cover:
- The management aspects of the network
These were all in-band as there were no facilities for out-of-band management (except for dial-up modems).
- Router security
These configurations protected the routers from hackers and local threats.
- BGP connectivity
A dual route reflector topology was used for BGP and also offered Internet access.
- VPLS overlay
The VPLS overlay includes the label distribution protocol (LDP) and MPLS protocols where possible and Ethernet Q-in-Q where necessary.
Note
The addresses used here have been sanitized for all the configurations. This client had a rather large legacy IP address space for its internal network. The addressing used that public address space for all aspects of the network. In my representation of the configurations, the address space has been replaced by the ubiquitous 10.0.0.0. I am aware that address translation would have to take place for the configurations to actually work in the real world.
The first aspect of the configuration was common across all of the Juniper Networks platforms and provided a common means to access and monitor the devices. The management traffic was carried in-band, on the same transmission facilities as the working traffic. Where possible, the management traffic was carried on a separate VLAN. The management traffic was not carried on a VPLS instance.
The management configuration was composed of multiple parts—syslog settings, firewall settings, prefix lists, and access settings, reviewed here one at a time.
The loopback interface was the management portal to the devices. All devices had a loopback interface defined, rather than the more traditional fxp0 management port. The source addresses for the other management functions (syslog and snmp) used the loopback port for a source address. The loopback interface was protected by a firewall filter that limited the traffic to the interface. A common configuration for the loopback interface was:
lo0 {
unit 0 {
family inet {
filter {
input LOCKDOWN;
}
address 10.102.191.21/32;
}
}
}The firewall filter referenced in the loopback configuration provided access to the device from a select set of management resources. The firewall configuration used prefix lists to manage these resources. The firewall filter and the prefix list configuration were:
policy-options {
prefix-list SECURE-SSH {
10.102.74.0/26;
10.102.18.192/27;
192.168.141.0/24;
}
prefix-list SECURE-RADIUS {
192.168.141.0/24;
}
prefix-list SECURE-DNS {
192.168.141.0/24;
}
prefix-list SECURE-SYSLOG {
192.168.141.0/24;
}
prefix-list SECURE-SNMP {
192.168.141.0/24;
}
prefix-list SECURE-SNMPTRAP {
192.168.141.0/24;
}
prefix-list SECURE-FTP {
192.168.141.0/24;
}
prefix-list SECURE-NTP {
10.102.72.1/32;
192.168.141.0/24;
}
prefix-list SECURE-DHCP {
10.102.84.1/32;
192.168.7.1/32;
192.168.141.2/32;
192.168.141.3/32;
}
prefix-list SECURE-ICMP {
10.102.1.100/32;
192.168.141.0/24;
}
prefix-list SECURE-BGP {
10.102.0.1/32;
10.102.0.2/32;
}
}The use of prefix lists provided a better means of controlling the access points of the network. The prefix lists could be updated more easily than the actual firewall terms. The firewall configurations remained generic and referenced the prefix lists. This also allowed portions of the network to be managed by different engineering groups, while keeping a standardized protection in place. The components of the firewall filter were:
firewall {
family inet {
filter LOCKDOWN {
term ICMP-NO-POLICER {
from {
prefix-list {
SECURE-ICMP;
}
protocol icmp;
icmp-type [ echo-reply echo-request time-exceeded
unreachable ];
}
then accept;
}
term ICMP {
from {
protocol icmp;
icmp-type [ echo-reply echo-request time-exceeded
unreachable ];
}
then {
policer DOS-PROTECTION;
accept;
}
}
term TRACEROUTE {
from {
packet-length [ 82 40 ];
protocol udp;
port 33435-33523;
}
then {
policer DOS-PROTECTION;
accept;
}
}The first couple of terms limited what ICMP traffic could get to the routing engine and the amount of ICMP traffic. Note that the policer referenced looked only at the ICMP traffic. There is an overall traffic limiter built into Junos that blocks storms of traffic to the RE. This rate limiter is applied by default and affects all traffic:
term SSH {
from {
prefix-list {
SECURE-SSH;
}
protocol tcp;
port ssh;
}
then accept;
}
term RADIUS {
from {
prefix-list {
SECURE-RADIUS;
}
protocol [ tcp udp ];
port radius;
}
then accept;
}
term DNS {
from {
prefix-list {
SECURE-DNS;
}
protocol udp;
port domain;
}
then accept;
}
term SYSLOG {
from {
prefix-list {
SECURE-SYSLOG;
}
protocol udp;
port syslog;
}
then accept;
}
term SNMP {
from {
prefix-list {
SECURE-SNMP;
}
protocol [ udp tcp ];
port snmp;
}
then accept;
}
term SNMPTRAP {
from {
prefix-list {
SECURE-SNMPTRAP;
}
protocol [ udp tcp ];
port snmptrap;
}
then accept;
}
term FTP {
from {
prefix-list {
SECURE-FTP;
}
protocol tcp;
port [ ftp ftp-data ];
}
then accept;
}
term NTP {
from {
prefix-list {
SECURE-NTP;
}
protocol udp;
port ntp;
}
then accept;
}The next set of terms allowed management traffic from secured sources to the routing engine. Because of these protections, more services were allowed on the device (ftp, for instance). There was a trade-off between services and security here, but because a firewall filter was used to protect the services, this was considered a good design decision:
term OSPF {
from {
protocol [ ospf igmp ];
}
then accept;
}
term BGP {
from {
prefix-list {
SECURE-BGP;
}
protocol tcp;
port bgp;
}
then accept;
}
term LDP {
from {
protocol [ udp tcp ];
port ldp;
}
then accept;
}
term DISCARD-ALL {
then {
count COUNTER;
discard;
}
}
}
}
}The remaining terms permitted the routing protocols that allow the network to operate. An astute reader might recognize the use of route reflectors in the BGP prefix lists. This network feature reduces change management when new devices are added to the network. For the same reason, LDP and OSPF do not have prefix lists associated with them.
The remaining portion of the loopback configuration was the policer for the DOS protection. This policer was specific for 32 kbps of ICMP traffic:
firewall {
policer DOS-PROTECTION {
if-exceeding {
bandwidth-limit 32k;
burst-size-limit 2k;
}
then discard;
}
}Access to the routers was controlled by a series of configuration items that were defined in the system stanza. The login users, authentication servers, and services were set to secure access to the device. The relevant portions of the system stanza begin with the authentication mechanisms:
system {
authentication-order [ radius password ];
root-authentication {
encrypted-password "$1$EPfhIHHCedikf443ds.";
}
radius-server {
192.168.141.5 {
secret "$9$/.rItpBleWdVYLxjeonljkhnlhfks;la33/CuBEM87";
source-address 10.102.191.21;
}
login {
class FULL-ACCESS {
idle-timeout 30;
login-alarms;
permissions all;
}
class READ-ACCESS {
idle-timeout 30;
login-alarms;
permissions [ firewall interface network routing system
view view-configuration ];
allow-commands "show log|clear interfaces statistics";
deny-commands "(ssh)|(telnet)";
}
user fullaccess {
authentication {
encrypted-password "$1$aedfkiko3dsm_ka /";
}
}
user localadmin {
class super-user;
authentication {
encrypted-password "$1$cyMbsb/764YRg1";
}
}
user readonly {
class READ-ACCESS;
}
}
}Additional components were used to secure the device: RADIUS, restricted services, a login banner, event logging, and archiving. The authentication order specified that a RADIUS server would provide the initial authentication verification. If this system failed, a local database was present to support local authentication. The login users fullaccess and readonly were RADIUS user aliases (these aliases are mapped to real usernames in the RADIUS server). The login user localadmin is a local user that allows access to the device in the event that RADIUS is not responding correctly. (If RADIUS is down, the fullaccess user will also work, but if RADIUS is misbehaving rather than failing to respond, the fullaccess user might still not be able to access the device.) The final piece of the access puzzle is the root login. This allows local access to the full device capabilities:
system {
services {
ssh {
root-login deny;
protocol-version v2;
connection-limit 10;
rate-limit 10;
ftp;
}
}
}The services that were allowed to be supported on the devices were ssh and ftp. These are both protected by the LOCKDOWN filter and the prefix lists associated with authorized source addresses. Although ftp is considered a nonsecure protocol, the configuration as shown provides a sufficient level of protection for the services offered (gathering troubleshooting files from the device).
While no login banner will actually stop a hacker from breaking into a system, they are a required component if the owners of the system wish to press charges against the hacker.
Note
For some reason, locking the door to your house is not a legal deterrent; you must post a sign that says that only permitted personnel are allowed in the house, and all others are subject to prosecution. I must be missing something—if a hacker is caught in a system that was locked down, why isn’t that breaking and entering just like breaking a window and barging into a private home?
There are banners that are the standard, and there are banners that stand above the standard. This client actually went so far as to grab ASCII art and add it to the standard security banner. The results looked really strange in the configuration, but pretty spectacular from the login screen. The configuration for this banner was:
login {
message "\n db `7MMF' `YMM' .g8"""bgd .g8""8q.
`7MMM. ,MMF'\n\n ;MM: MM .M' .dP' `M .dP'
`YM. MMMb dPMM \n\n ,V^MM. MM .d" dM' ` dM'
`MM M YM ,M MM \n\n ,M `MM MMMMM. MM MM
MM M Mb M' MM \n\n AbmmmqMA MM VMA mmmmm MM. MM.
,MP M YM.P' MM \n\n A' VML MM `MM. `Mb. ,' `Mb.
,dP' M `YM' MM \n\n.AMA. .AMMA..JMML. MMb. `"bmmmd'
`"bmmd"' .JML. `' .JMML.
\n\n*************************** Warning Notice ***************************\n\n
This system is restricted solely to AK-COM authorized users for\n
legitimate business purposes only. The actual or attempted\n unauthorized
access, use, or modification of this system is strictly\n prohibited by
AK-COM. Unauthorized users are subject to Company\n disciplinary
proceedings and/or criminal and civil penalties under\n state, federal,
or other applicable domestic and foreign laws. The\n use of this system
may be monitored and recorded for administrative\n and security reasons.
Anyone accessing this system expressly consents\n to such monitoring and
is advised that if monitoring reveals possible\n evidence of criminal activity,
AK-COM may provide the evidence of\n such activity to law enforcement officials.
All users must comply\n with AK-COM company policies regarding the
protection of AK-COM\n information assets.
\n\n *************************** Warning Notice ***************************\n\n";
}When a user logged into the devices, here’s what she saw:
db `7MMF' `YMM' .g8"""bgd .g8""8q. `7MMM. ,MMF'
;MM: MM .M' .dP' `M .dP' `YM. MMMb dPMM
,V^MM. MM .d" dM' ` dM' `MM M YM ,M MM
,M `MM MMMMM. MM MM MM M Mb M' MM
AbmmmqMA MM VMA mmmmm MM. MM. ,MP M YM.P' MM
A' VML MM `MM. `Mb. ,' `Mb. ,dP' M `YM' MM
.AMA. .AMMA..JMML. MMb. `"bmmmd' `"bmmd"' .JML. `' .JMML.
*************************** Warning Notice ***************************
This system is restricted solely to AK-COM authorized users for
legitimate business purposes only. The actual or attempted
unauthorized access, use, or modification of this system is strictly
prohibited by AK-COM. Unauthorized users are subject to Company
disciplinary proceedings and/or criminal and civil penalties under
state, federal, or other applicable domestic and foreign laws. The
use of this system may be monitored and recorded for administrative
and security reasons. Anyone accessing this system expressly consents
to such monitoring and is advised that if monitoring reveals possible
evidence of criminal activity, AK-COM may provide the evidence of
such activity to law enforcement officials. All users must comply
with AK-COM company policies regarding the protection of AK-COM
information assets.
************************** Warning Notice ***************************I asked who the ASCII artist was and was told that http://patorjk.com/software/taag/ converted text to any number of ASCII art styles—it’s nice to see someone taking time to play now and then!
The next part of securing the devices was to record the events happening on the devices. The syslog stanza has an equal number of on-device files and remote device files, so when an event was observed, the logging system was unlikely to miss it. The syslog system included default syslog files and also those specific to the issues seen by the client; the use of NTP assured that the logs from all the devices would be synced in time.
Note
Did you know that Alaska has its own time zone, but some of the Aleutian Islands are actually in the next time zone?
The syslog and NTP stanzas looked like this:
system {
syslog {
user * {
any emergency;
}
host syslog.ak-com.net {
any any;
facility-override local7;
}
file auth.log {
authorization any;
archive size 1m files 1;
}
file firewall.log {
firewall any;
archive size 5m files 3;
}
file interfaces.log {
any info;
match .*SNMP_TRAP_LINK.*;
archive size 1m files 3;
}
source-address 10.102.72.1;
}
ntp {
boot-server 192.168.141.2;
server 192.168.141.2;
server 192.168.141.3;
source-address 10.102.72.1;
}
}The final part of securing the devices was recording the configurations to a secure server. The system’s archival capabilities allowed the configurations to be saved on the devices, but now when a commit is performed they are also sent to a server. The configuration for this capability is:
system {
archival {
configuration {
transfer-on-commit ;
archive-sites {
scp://admin@archive.ak-com.com:config/MX/password
admin123;file://config/MX/config;
}
}
}
}To communicate with the company’s network operations center, each device had an SNMP configuration that allowed an SNMP agent to poll the devices for bandwidth measurements and receive traps from the devices in the event of failures. The SNMP stanza was very basic:
snmp {
name Kodiac-1;
location "Kodiac Island";
contact "AK-CON NOC 1-800-123-4567";
community "eert5c$" {
authorization read-only;
}
community "Gfesb765#5" {
authorization read-only;
}
trap-options {
source-address lo0;
}
trap-group 1 {
version v2;
categories {
authentication;
chassis;
link;
remote-operations;
routing;
startup;
rmon-alarm;
vrrp-events;
configuration;
services;
}
targets {
192.168.141.55;
}
}
}Logically the next configuration portion should be the interfaces, but due to the wide range of devices in use, the interface section is instead shown in the device-specific configurations. The next portion of the configuration to cover is device generic—the protocols running on the network’s routers. The network used OSPF area 0 as an IGP, and the limited numbers of routers allowed the network to operate with little convergence delay. BGP was used throughout to support the services. Internal and external BGP peerings were supported in the network. MPLS was supported with LDP on all the routers. This made most of the protocols section very generic. The only differences were the interfaces that were assigned to the routing protocols. In the following examples, a generic set of interfaces (ge-0/0/1 and ge-0/0/2) is used. One part of the configuration that I took particular note of was that traceoptions were set up for each protocol and deactivated—this type of configuration foresight allows quick troubleshooting and keeps a standard operating procedure for tracing issues.
The MPLS configuration identified specific interfaces in the area and used authentication to prohibit rogue routers from being connected to the network. Here’s a configuration example:
protocols {
mpls {
inactive: traceoptions {
file mpls.log size 5m files 2;
flag error;
flag state;
}
interface ge-0/0/0.0;
interface ge-0/0/1.0;
}Also associated with the MPLS protocol was that all interfaces carrying MPLS traffic had to have that protocol enabled in the logical interfaces.
The next protocol in the stack was BGP. In this engagement, BGP was the workhorse protocol for deploying services throughout the network. Managed Internet (family inet unicast), L3VPN (family inet-vpn), and VPLS (family l2vpn-signaling) were all deployed with this protocol. To minimize the configuration tasks for BGP, two route reflectors were used in the core of the network. The use of route reflectors allowed each of the remote devices to have a generic BGP configuration for the internal group. For those with external connections, customer-specific groups were created along with the routing policies.
The BGP routing policies were kept to a minimum. Route filtering was performed at the edges to the network, keeping the internal BGP operation free and open (L3VPN and VPLS policies were also kept to a minimum by the use of the route target commands, as we’ll see later):
bgp {
inactive: traceoptions {
file bgp.log size 1m files 2;
flag state;
}
log-updown;
group iBGP {
type internal;
local-address 10.102.72.1;
neighbor 10.102.0.1 {
description "Peer To Anchorage-1";
family inet {
unicast;
}
family inet-vpn {
unicast;
}
family l2vpn {
signaling;
}
authentication-key "$9$ga-Ysdb G6eer-baZD";
}
neighbor 10.102.0.2 {
description "Peer To Anchorage-2";
family inet {
unicast;
}
family inet-vpn {
unicast;
}
family l2vpn {
signaling;
}
authentication-key "$9$ -YoGUH.eedfa-baZD";
}
}
}An example of an external BGP group with route filtering policies is shown next. In this case, the client used a group configuration to contain all the configuration for the customer. The group configuration allows easy setup and easy cleanup when customers come and go. It contains the BGP configuration for the customer, the interface to the customer, the policies for the customer’s prefixes, and a policer to regulate the amount of traffic the customer has contracted for.
The autonomous system (AS) numbers for the configuration are 1234 for our client (yes, it is made up) and 65432 for the customer. The local AS number was set as part of the routing options:
routing-options {
autonomous-system {
1234;
}
}Without the above stanza, the internal BGP stanza would not commit. Once that was added, the external BGP configuration group was added:
groups {
PETRO {
interfaces {
fe-0/2/0 {
no-traps;
speed 100m;
mtu 4500;
link-mode full-duplex;
unit 0 {
description "Ethernet to 65432 PETRO";
bandwidth 20m;
traps;
family inet {
policer {
input 20M;
output 20M;
}
address 10.102.1.1/30;
}
}
}
}
protocols {
bgp {
group eBGP-1234-PETRO {
type external;
neighbor 10.102.1.2 {
description "Peer To PETRO (AS 65432)";
local-address 10.102.1.1;
import 65432-TO-1234;
authentication-key "$9$l2/M7-V4aUN-wg4oGU";
export 1234-TO-65432-DEFAULT;
peer-as 65432;
}
}
}
}
policy-options {
policy-statement 65432-TO-1234 {
term PRIVATE {
from {
route-filter 10.0.0.0/8 orlonger;
route-filter 192.168.0.0/16 orlonger;
route-filter 172.16.0.0/12 orlonger;
}
then reject;
}
term TOO-LONG {
from {
route-filter 0.0.0.0/0 prefix-length-range
/25-/32;
}
then reject;
}
term FROM-PETRO {
from {
protocol bgp;
neighbor 10.102.1.2;
route-filter 101.101.110.0/22 exact;
}
then {
community add FROM-PETRO;
next-hop self;
accept;
}
}
term REJECT {
then reject;
}
}
policy-statement 1234-TO-65432-DEFAULT {
term DEFAULT {
from {
route-filter 0.0.0.0/0 exact;
}
then accept;
}
term REJECT-ALL {
then reject;
}
}
community FROM-PETRO members 65432:10;
}
}
firewall {
policer 20M {
if-exceeding {
bandwidth-limit 20m;
burst-size-limit 100k;
}
then discard;
}
}
}This generic configuration provides the customer with only a default BGP route—if a full Internet routing table were requested, the 1234-to-65432 policy would be altered to allow the full routing table to be transmitted to the remote router. The import policies protect the client from private addresses and addresses that are too long. These are not important for this client as they only have a single prefix to export, but it is another protection that we installed for the client to prohibit problems from customers. In this case, the import policy included the next-hop self statement. This prevents the loss of prefixes due to OSPF errors for interfaces and/or inclusion of static routes. Finally, each incoming prefix was tagged with a community string that identified the origin of the prefix. These were used at the route reflectors to filter prefixes.
The next protocol in the stanza is the IGP OSPF. Area 0 was used for all the routers, as the network was not large enough to bother with multiple areas. Authentication was used to prevent rogue routers. On some routers an export policy was used to advertise static routes that were needed to reach “different” parts of the network, but we tried to keep these to a bare minimum:
ospf {
inactive: traceoptions {
file ospf.log size 1m files 2;
flag state;
flag error;
}
area 0.0.0.0 {
interface ge-0/0/0.0 {
authentication {
md5 1 key "$9$eJ.KXNwssfgCA1Iws24JD";
}
}
interface ge-0/0/1.0 {
authentication {
md5 1 key "$9$eJ.KsdfgsgsgCA1Iws24JD";
}
}
}
}LDP was the MPLS label-switched path (LSP) control protocol of choice for the customer. The star topology had no need for traffic engineering, and convergence times were such that failure recovery was very quick. Running LDP is an easy way to create LSPs across the network. With the use of route reflectors, resource reservation protocol (RSVP) static routes or false LSPs are not needed:
ldp {
inactive: traceoptions {
file ldp.log size 5m files 2;
flag error;
flag state;
}
interface ge-0/0/0.0;
interface ge-0/0/1.0;
}
}With the protocols installed, all the generic portions of the configurations were covered. The next set of configuration options was the device-specific configurations; these were added or merged into the generic configurations on the devices.
The device-specific configurations start with the core routers. These had two position-specific elements: the route reflector configuration, which replaced the generic internal BGP configuration, and the Internet access BGP configurations, which provided Internet service to the entire network. At these locations, OSPF was modified to provide a default route to the network as well. This first portion displays the Internet access BGP configurations:
protocol {
bgp {
traceoptions {
file bgp.log size 1m files 2;
flag state;
}
log-updown;
group EBGP-Internet {
type external;
export 1234-TO-INTERNET
import INTERNET-TO-1234
neighbor 172.16.90.93 {
description "Peer To L3 (AS 77)";
authentication-key "$9$kihgkolknoo^jikfa23d/9";
peer-as 77;
}
neighbor 172.16.83.226 {
description "Peer To AK-COM (AS 70)";
peer-as 70;
}
}The referenced import policies accept all the routes and attach a service-specific community string. The export policies provide the prefixes that are accepted from customers and the local prefix aggregations. The policies and the related aggregates are:
routing-options {
aggregate {
route 192.168.136.0/22;
route 10.102.0.0/20;
route 10.102.16.0/20;
route 10.102.32.0/20;
route 10.102.48.0/20;
route 10.102.64.0/20;
route 10.102.80.0/20;
route 10.102.96.0/20;
route 10.102.112.0/20;
}
}
policy-options {
prefix-list ORIGINATED-ROUTES {
10.102.32.0/20;
10.102.64.0/20;
10.102.80.0/20;
10.102.96.0/20;
192.168.136.0/22;
}
prefix-list ORIGINATED-ROUTES-DEPREF {
10.102.0.0/20;
10.102.16.0/20;
10.102.48.0/20;
10.102.112.0/20;
}
policy-statement 1234-TO-INTERNET {
term ORIGINATED-ROUTES {
from {
protocol aggregate;
prefix-list ORIGINATED-ROUTES;
}
then accept;
}
term ORIGINATED-ROUTES-DEPREF {
from {
protocol aggregate;
prefix-list ORIGINATED-ROUTES-DEPREF;
}
then {
as-path-prepend 1234;
accept;
}
}
term FROM-PETRO {
from {
protocol bgp;
community FROM-PETRO;
}
then {
as-path-prepend 1234;
accept;
}
}
term REJECT {
then reject;
}
}
policy-statement INTERNET-TO-1234 {
term FROM-INTERNET-REJECT {
from {
route-filter 10.102.0.0/20 upto /32;
route-filter 10.102.16.0/20 upto /32;
route-filter 10.102.32.0/20 upto /32;
route-filter 10.102.48.0/20 upto /32;
route-filter 10.102.64.0/20 upto /32;
route-filter 10.102.80.0/20 upto /32;
route-filter 10.102.96.0/20 upto /32;
route-filter 10.102.112.0/20 upto /32;
route-filter 192.168.136.0/22 upto /32;
route-filter 0.0.0.0/0 exact;
}
then reject;
}
term FROM-INTERNET {
from {
protocol bgp;
}
then {
community + FROM-INTERNET;
accept;
}
}
term REJECT {
then {
reject;
}
}
}
community FROM-PETRO members 65432:10;
community FROM-INTERNET members 7077:10;
}A couple of notes about this configuration:
To provide a level of load sharing for incoming traffic, some of the aggregates were prepended with the local AS for this core router. The other core router swapped the group contents.
The use of prepending to similar-level ISPs provided a means for the ISPs to load-share incoming traffic to our client. In the outgoing direction, the client’s traffic went to the closest ISP (core #1 or core #2).
The import policy rejected any prefix that was originated by the client, to protect the client from loops.
This is a single customer prefix being exported; the configuration was repeated for all the customers that were being provided ISP service.
The route reflector BGP configuration listed the remote BGP sites in a single group. Each remote site was adjusted for the services offered at that site. A couple of generic export policies were used for each site, and incoming BGP routes were accepted wholesale:
protocols {
bgp {
deactivated: traceoptions {
file bgp.log size 1m files 2;
flag state;
}
log-updown;
group iBGP-32328 {
type internal;
local-address 10.102.0.2;
authentication-key "$9$t4Khu01EcrML7.gsT-Vk.Pf3eKM8-baZD";
cluster 10.102.0.2;
neighbor 10.102.0.1 {
description "Peer To CoreRtr-1";
family inet {
unicast;
}
family inet-vpn {
unicast;
}
family l2vpn {
signaling;
}
authentication-key "$9$.PfF3eKM8-baZD";
}
neighbor 10.102.0.3 {
description "Peer To DistRtr-1";
export DEFAULT_ONLY
family inet {
unicast;
}
family inet-vpn {
unicast;
}
family l2vpn {
signaling;
}
authentication-key "$9$.PfF3eKM8-baZD";
}
neighbor 10.102.0.4 {
description "Peer To DistRtr-2";
family inet-vpn {
unicast;
}
family l2vpn {
signaling;
}
authentication-key "$9-Vk.PfF3eKM8-baZD";
}
neighbor 10.102.72.1 {
description "Peer To DistRtr-3";
family l2vpn {
signaling;
}
authentication-key "$9Vk.PfF3eKM8-baZD";
}
}
}
}In this configuration example, three of the remote distribution routers are shown. For DistRtr-1, all services (Internet access, L3VPNs, and VPLS) are offered. The Internet access delivers a default route only, so that policy is included at the neighbor level.
Note
We had debates about the restriction of the full routing table and neighbor-specific export policies. On the one hand, when a new service is offered, more than the remote locations need to be touched. But on the other hand, having the bandwidth and local memory being used up for 700,000 routes that are never used seems to be a waste. We ended up with the more conservative approach. As services are added, the route reflectors need to be updated as well as the remote locations.
The policy referenced is the same used in the distribution routers:
policy-options {
policy-statement DEFAULT-ONLY {
term DEFAULT {
from {
route-filter 0.0.0.0/0 exact;
}
then accept;
}
term REJECT-ALL {
then reject;
}
}
}The default route was added to the routing table as a static route, which gave the client more control over the default than having it arrive from the ISPs. It was also exported to OSPF for use in the normal routing of the network. Outgoing load balancing is performed by the use of the static routes and a load-balancing policy:
routing-options {
static {
route 0.0.0.0/0 next-hop {
172.16.90.93;
172.16.83.226;
}
forwarding-table {
export LOAD-BALANCE;
}
}
policy-options {
policy-statement {
policy-statement LOAD-BALANCE {
then {
load-balance per-packet;
}
}
}This policy allows both ISP routes to be installed in the forwarding table, and per-flow load balancing is performed on the outgoing streams.
In the locations that supported low MTU levels, the customer-facing device was a switch rather than the normal distribution router, allowing for the delivery of the services with a link that supported only a lower MTU. The switches were all Juniper Networks EX4200s in a single or dual virtual chassis arrangement. The normal management configurations were used in these devices, with the change being in the customer-facing VLAN configurations. The use of 802.1ad dual VLAN tagging allowed the differentiation between customers and allowed the customers to add VLAN tags to their traffic. The configurations for these switches were:
interfaces {
ge-0/0/0 {
description "To DistRtr-1";
mtu 4500;
ether-options {
no-auto-negotiation;
link-mode full-duplex;
speed {
100m;
}
}
unit 0 {
bandwidth 5m;
family ethernet-switching {
port-mode trunk;
vlan {
members all;
}
}
}
}
ge-0/0/2 {
description "VPLS-Customer-1";
mtu 4500;
ether-options {
no-auto-negotiation;
link-mode full-duplex;
speed {
100m;
}
}
unit 0 {
bandwidth 5m;
no-traps;
family ethernet-switching;
}
}
vlan {
unit 201 {
family inet {
filter {
input LOCKDOWN;
}
address 172.29.64.94/30;
}
}
}
}
routing-options {
static {
route 0.0.0.0/0 next-hop 172.16.64.93;
}
}
ethernet-switching-options {
dot1q-tunneling {
ether-type 0x8100;
}
}
vlans {
CUSTOMER-VPLS {
vlan-id 88;
interface {
ge-0/0/2.0;
}
dot1q-tunneling {
customer-vlans 1-4094;
}
}
MGMT {
vlan-id 201;
l3-interface vlan.201;
}
}Two interfaces are defined, one connecting back to the core of the network and the other to the customer. In this example, the only customer is a VPLS customer. The management traffic for the switch uses a VLAN ID of 201. All VPLS customer traffic arrived at the core with a service provider tag of 88.
The static route was for management traffic. The normal protection firewalls and prefix lists were used too, but were attached to the management VLAN rather than the loopback interface.
The distribution routers were responsible for offering services to the customers. The existing configurations offered L3VPN service. We added the VPLS services to these devices. In the process of the update, we also cleaned up the configurations and modularized the L3VPN customers. All service configurations were created in a group, allowing the administrators to easily add, copy, and delete customers to/from the configurations. The routing instances used the vrf-target statement to eliminate the need for route policies for each customer. This is fine for pure customer installations, but when a customer wants an extranet, or filtering of sites, the policies are necessary. For the existing customers, this was not the case, so the simpler approach was used.
Here’s a generic L3VPN group configuration:
L3VPN {
interfaces {
ge-0/0/2 {
unit 0 {
family inet {
address 172.16.80.49/30;
}
}
}
}
policy-options {
policy-statement DEFAULT {
from {
route-filter 0.0.0.0/0 exact;
}
then accept;
}
}
routing-instances {
L3VPN {
instance-type vrf;
interface ge-0/0/2.0;
route-distinguisher 1234:100;
vrf-target target:1234:100;
routing-options {
protocols {
ospf {
export DEFAULT;
area 0.0.0.10 {
interface ge-0/0/2.0;
}
}
}
}
}
}
set apply-groups L3VPNHere, the customer-facing interface is ge-0/0/2.0. If the remote device were a distribution switch, the interface would be a logical interface with a VLAN identified (for example, ge-0/0/2.88, VLAN ID 88). In this example, the customer is using OSPF as a routing protocol. The prefixes that are received from the customer are readvertised to the rest of the locations, and the default route is advertised back to this customer site.
A VPLS customer group configuration is very similar to the L3VPN. An example of a VPLS configuration is:
groups {
VPLS {
routing-instance {
VPLS-cust {
instance-type vpls;
interface ge-0/3/0.88;
route-distinguisher 1234:200;
vrf-target target:1234:200;
protocols {
vpls {
site-range 10;
mac-table-size {
4096;
}
no-tunnel-services;
site VPLS-1 {
automatic-site-id;
}
}
}
}
}
policy-options {
community FROM-VPLS members target:1234:200;
}
interfaces {
ge-0/3/0 {
unit 88 {
description "Ethernet to VPLS";
encapsulation vlan-vpls;
bandwidth 100m;
traps;
vlan-id 88;
family vpls;
}
}
}
}
apply-groups VPLSWe used a couple of VPLS features here that reduced the bookkeeping for the administrators. The first was automatic site numbering. Each site was given a unique site identifier, and the system figured out the numbering. We also used the vrf-target statement again to reduce the need for route policies.
The L3VPN and VPLS configuration groups were installed at each customer-facing router. The use of the distribution switch did not alter the router’s configuration.
Those customers that were served over the low-bandwidth satellite circuits had an additional configuration in place. The satellite modems were sensitive to being overrun by the network, and when that happened, the traffic loss was unpredictable and often caused outages on the links. To solve this issue, a combination of policers and traffic shapers were used to control the rates of traffic accessing the modems.
The policers were configured facing the customer for incoming traffic. The filters were:
interface {
ge-0/0/0 {
unit 0 {
family inet {
filter input {
10m-POLICER;
}
}
}
}
}
firewall {
family {
inet {
filter {
10m_POLICER {
term 1 {
then {
count 10m;
policer 10m-POLICER;
}
}
}
}
}
}
policer {
10m-POLICER {
if-exceeding {
bandwidth-limit 10m;
burst-size-limit 1m;
}
then {
discard;
}
}
}
}For the shapers that faced the satellite modems, the configurations were very simple:
class-of-service {
interfaces {
ge-0/0/0 {
shaping-rate 10;
}
}
}The combination of the shapers, policers, and flow control on the satellite modems eliminated the buffer overflows and stopped outages for these finicky links.
In some cases, the customer requested that the client provide a managed device onsite. These devices (typically Juniper Networks EX4200s) needed to be managed by the client’s administrative staff. Since the customer was given full use of all the VLANs, the use of a VLAN for management was not supported. The solution to this issue was to move the Q-in-Q to the CPE device. This allowed the use of service provider VLAN tags as well as management VLAN tags on the circuit. The configuration of these devices became the same as that of the distribution switch shown above.
When network warriors enter an engagement, they often arrive at the scene with preconceived notions of what they are about to do for the client. The 12-hour flight from Vermont to Alaska provided me with many opportunities to create preconceived notions. I thought we were going into a simple Layer 2 virtual private network implementation, trading out one set of customer-facing protocols for another. The reality of the engagement was a deep dive into the interworkings of the protocols, their frame structures and operations. We had to dig out the reference materials and reacquaint ourselves with the basics of LANs and data networking. A common theme in this book is that on every engagement, warriors learn. We learn, and we take the results and solve client issues. The solution to this client’s issue included not only creating a set of configurations, but also redesigning the components of the network to allow it to operate in the limiting environment.
A side lesson of this engagement was that the most basic of networking components can necessitate a full redesign of the service. In this case, the MTU limitation of the satellite links caused the redefinition of the edge of the VPLS network. As networking professionals, warriors have to look at all the little details to assure a successful implementation. It is said that the devil is in the details, and this was a great case in point.
Get Juniper Networks Warrior now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

