The first step is to create XML data to be unmarshalled into Java. You’ll find that you spend as much time creating XML documents as you do in any other aspect of data binding, as it provides the data for your application. Additionally, it’s often easier to open up an editor like notepad or vi than it is to code a program to populate Java objects and then marshal them (although I’ll talk about that approach in the next chapter, which focuses on marshalling Java to XML). So let’s talk XML.
I’ve spent a lot of time talking about constraint models, setting up your data structure, and other conceptual type ideas. In this section, you get to move a little closer to the practical. Once you’ve got your constraint model set up (as shown in Chapter 3), you need to model your actual data. In this case, the modeling part of that task is done, and all that is left is filling a document with data. With the emerging XML editor scene, this becomes a piece of cake. For example, Figure 4-3 shows a screenshot of XML Spy, which allows a simple filling of constraints with data; as you can see, this is a trivial task.
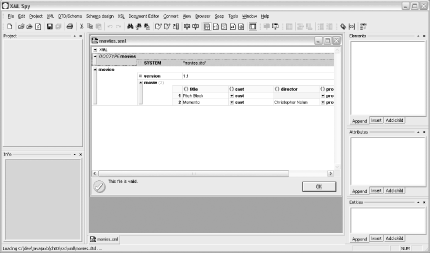
Many of you will use simpler editors, but the principle is the same: take a DTD, figure out what data goes in the elements and attributes as defined by that DTD, and create an XML document.
One issue that comes up
often
is the handling of whitespace. Will the level of indention you use
change the data-bound data? What about using tabs versus spaces or
single versus double quotes? These issues are important in low-level
APIs like SAX because those APIs are intended to give you direct
control over the data. However, in higher-level APIs like data
binding, these choices become pretty inconsequential. For example,
the whitespace between the root and
child elements in this document fragment is
completely irrelevant when using data binding:
<root> <child>Here is some text</child> </root>
Because the root element has no actual textual value,[8] there is no problem with whitespace used in indenting; it’s tossed out when the data is unmarshalled.
The only issue left is that of whitespace within a textual element, like that shown here:
<root> <child> Here is some text with leading and trailing spaces. </child> </root>
Here, you’re going into a vendor-specific paradigm.
Some data binding frameworks preserve this space, resulting in the
getContent( ) method on the
child object returning a value like
Here
is
some
text
with
leading
and
trailing
spaces. Other
frameworks trim this text automatically, giving you
Here
is
some
text
with
leading
and
trailing
spaces. Some
frameworks give you an option to trim or not to trim this text.
If you know you don’t want leading and trailing whitespace (and you usually don’t), it’s always safe to write code like this:
// Get the object
List childElements = root.getChild( );
// Iterate over the children
for (Iterator i = child.iterator(); i.hasNext( ); ) {
Child child = (Child)i.next( );
// Get its value, trimmed
String childValue = child.getContent( );
if (childValue != null) {
childValue = childValue.trim( );
} else {
childValue = "";
}
// Do something with the value
}Warning
Notice that this code compares the returned value from
getContent( ) to null. While
most data binding implementations will not return
null here and instead return an empty string, it
never hurts to be careful. You may save yourself a lot of frustrating
debugging by using this more cautious approach.
Trimming protects you from extra whitespace despite framework variance in whitespace handling. Other than these minor issues, once an XML document (or documents) is created, you only need to validate them and then unmarshal them into Java.
I want to address the issue of data validity before getting into the semantics of converting XML to Java. Example 4-1 is a reprint of the XML document representing a movie database, which I first showed you in Chapter 3.
Example 4-1. Sample movie database
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE movies SYSTEM "movies.dtd">
<movies version="1.1">
<movie>
<title>Pitch Black</title>
<cast>
<actor headliner="true">Vin Diesel</actor>
<actor headliner="true">Radha Mitchell</actor>
<actor>Vic Wilson</actor>
</cast>
<producer>Tom Engelman</producer>
</movie>
<movie>
<title>Memento</title>
<cast>
<actor headliner="true">Guy Pearce</actor>
<actor headliner="true">Carrie-Anne Moss</actor>
</cast>
<director>Christopher Nolan</director>
<producer>Suzanne Todd</producer>
<producer>Jennifer Todd</producer>
</movie>
</movies>This document uses the elements and attributes defined in the movies.dtd constraint set. Because of that, it’s a valid document. In other words, it uses only elements and attributes defined in the DTD and uses the content model specified by that DTD. It could have been created with XML Spy or by hand; in any case, it fits the constraint model defined in Chapter 3.
Just taking my word for it isn’t such a great idea; you need to be able to verify the document’s validity. Many validation frameworks allow you to validate your XML data as it is read in and unmarshalled. However, this adds processing time, which is probably not desired in your application. In many cases, you want some validation at compile time, but not at runtime.
Warning
While I’m all for making applications as fast as humanly possible, removing validation is a delicate issue. If you know that you are going to use an XML document that you have available at compile time, turning off validation makes a lot of sense.
However, data binding is often used to interpret data that is handed off to an application at runtime; for example, consider an application server that reads in deployment information for applications through data binding. In these cases, you probably want to leave validation on at runtime, despite the performance penalty. You can’t perform the compile-time validation I refer to in this section, so you need assurance that you’re getting valid data and you need to pay whatever price is necessary to get this assurance. Leave validation out, and your data binding may fail with some pretty nasty (and often cryptic!) exceptions.
Because of this, it’s helpful to have available a
simple utility program that will validate a document against the DTD
it specifies through the DOCTYPE declaration, as
seen in Example 4-1. To help you in this endeavor,
Example 4-2 shows a program that uses JAXP to
validate a
document.
Example 4-2. Simple validation program
package javajaxb.util;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.OutputStream;
import java.io.PrintStream;
import java.io.Reader;
// JAXP classes
import javax.xml.parsers.SAXParserFactory;
import javax.xml.parsers.SAXParser;
// SAX classes
import org.xml.sax.InputSource;
import org.xml.sax.helpers.DefaultHandler;
public class XMLValidator {
public XMLValidator( ) {
// Currently, does nothing
}
public void validate(Reader reader, OutputStream errorStream) {
PrintStream printStream = new PrintStream(errorStream);
try {
SAXParserFactory factory = SAXParserFactory.newInstance( );
factory.setValidating(true);
SAXParser parser = factory.newSAXParser( );
parser.parse(new InputSource(reader), new DefaultHandler( ));
// If we got here, no errors occurred
printStream.print("XML document is valid.\n");
} catch (Exception e) {
e.printStackTrace(printStream);
}
}
public static void main(String[] args) {
if (args.length != 1) {
System.out.println("Usage: java javajaxb.util.XMLValidator " +
"[XML filename]");
return;
}
try {
File xmlFile = new File(args[0]);
FileReader reader = new FileReader(xmlFile);
XMLValidator validator = new XMLValidator( );
// Validate, and write errors to system output stream
validator.validate(reader, System.out);
} catch (FileNotFoundException e) {
System.out.println("Could not locate XML document '" +
args[0] + "'");
} catch (IOException e) {
System.out.println("Error processing XML: " + e.getMessage( ));
e.printStackTrace( );
}
}
}You can compile this class and run it on a document like this:
C:\dev\javajaxb\ch04\src\xml>set CLASSPATH=c:\dev\lib\xerces.jar;
c:\dev\javajaxb\build
C:\dev\javajaxb\ch04\src\xml>java javajaxb.util.XMLValidator movies.xml
XML document is valid.On Unix, it would look like this:
bmclaugh@FRODO ~/dev/javajaxb/ch04/src/xml $ export CLASSPATH=~/dev/lib/xerces.jar:~/dev/javajaxb/build bmclaugh@FRODO ~/dev/javajaxb/ch04/src/xml $ java javajaxb.util.XMLValidator movies.xml XML Document is valid.
As you can see here, I’ve ensured that the movies.xml document is valid with respect to the movies database DTD (movies.dtd).
Note
A quick note on using this program: this program assumes that the
DOCTYPE reference is relative to the location that
the program is run within. Since in this case, the reference is
simply movies.dtd, that DTD should be in the
directory that the program is run within. You can use a path like
DTDs/movies.dtd and put the DTD in a
subdirectory called DTDs/, and it
would also work.
You’ll also notice that I ensured that a parser
(like Xerces) with the JAXP classes, as well as the utility program
itself, is included within the classpath. If you forget this step,
you’ll end up with annoying
ClassNotFoundException problems.
Each of your own documents can be run through this simple program to ensure validity at compile time, rather than performing this step repeatedly at runtime. With this step out of the way, you’re now ready to convert your XML data into Java object instances.
[8] I am assuming that this document’s DTD is well
written. In other words, the root element has a
definition like this: <!ELEMENT root (child)+>. This definition removes the chance that
PCDATA slips in and gets turned into a Java object
value.
Get Java & XML Data Binding now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

