When in trouble or in doubt Run in circles, scream and shout.
Anonymous
At this stage, we've already looked at a good deal of the theory behind IPv6. It's now a good time to start thinking about the issues around deploying IPv6 in a wider environment, such as your company, college, or ISP network. In this chapter, we provide recommendations for what to think about and what to do when planning an IPv6 deployment; how to introduce IPv6 to your network, how to interoperate with IPv4, and planning for the growth of IPv6, all with an eye to maintaining stability and manageability on your network. We provide worked examples of IPv6 deployment for networks which are hopefully quite similar to yours, and also highlight under exactly what circumstances our recommendations are applicable. By the end of this chapter you should hopefully have a toolbox of techniques for implementing IPv6, and also the right mental framework for using that toolbox.
Since we will be talking in some detail about the planning process, it's incumbent upon us to outline the important building-blocks and techniques of IPv6 network design before we talk about how we actually put them together. So, ahead of outlining step-by-step plans, we need to tell you about getting connectivity, getting address space, and the intricacies of selecting transition mechanisms, amongst other things. With those under your belt, you'll be in a position to get the most out of the worked examples.
Note that a significant portion of this chapter is about network planning, and planning for larger networks at that. If you are more of a Systems Administrator, rather than a Network Administrator, then you still may want to skim this chapter before moving on to the latter chapters. For those of you staying on, let's get stuck right in to the detail.
Transition mechanisms are so called because they are ostensibly ways you can move your network to IPv6. In reality, IPv4 and IPv6 are likely to be co-operating on most networks for a long while, so they might better be called inter-operating techniques or IPv6 introduction mechanisms. In any event, there are quite a few of them, and they have a wide variety of capabilities. Some allow you to connect to the IPv6 Internet, even if intervening equipment only speaks IPv4 (tunnels, 6to4, Teredo). Some are suitable for providing internal IPv6 connectivity until your infrastructure supports IPv6 (tunnels, 6to4, ISATAP). Others are to help IPv4-only hosts communicate with IPv6-only (NAT-PT, TRT, Proxies). There are even some to help IPv4-only applications (Bump in the Stack/API).
Tip
While there is a plethora of mechanisms available, you will in all probability only need to understand and use a small fraction of them. (We provide a table that gives an overview later.) At a minimum, you'll want to know about dual-stack, configured tunnels and proxies. You may want to browse through the others to see if they'll be useful in your network.
The dual-stack transition mechanism is perhaps not so elegant as others we will discuss, but is common, useful and many of the other mechanisms we'll talk about require at least one dual-stacked host. We expect that dual-stacking a network will be the way most people choose to deploy IPv6, unless they have unusual requirements.
As the name implies, dual stacking involves installing both an IPv4 and an IPv6 stack on a host. This means the host can make decisions about when connections should be made using IPv4 or IPv6; generally this is done based on the availability of IPv6 connectivity and DNS records. The IPv4 and IPv6 stacks can and often are completely independent: logical interfaces may be numbered separately, brought up and down separately and essentially treated as being separate machines.
One problem with the dual-stack method is that the shortage of IPv4 addresses means that you may not have enough to give to every host. There is a proposal called DSTM (Dual Stack Transition Mechanism) that allows for the temporary assignment of IPv4 addresses to nodes while they need them, so a large group of dual-stacked hosts can share a small number of IPv4 addresses, akin to dialup hosts sharing addresses out of a pool.
The fact that these dual-stacked hosts can originate and receive IPv6 and IPv4 packets is extremely powerful, allowing them to form a connection between IPv4 and IPv6 networks. We'll look at ways in which this is possible next.
This is, in many ways, the simplest of transition mechanisms, although it is not as easily maintainable as others because it involves manually configuring some addresses.
The principle behind tunnelling is the encapsulation of IPv6 packets in IPv4 packets. If you haven't encountered this notion before, it might sound rather peculiar at firstâwrap packets in other packets? But it's actually a very powerful technique.
The central idea to understand is that just like Ethernet headers surround IP packets, which surround TCP and UDP headers, which surround protocols such as SMTP, you can just as easily insert another packet where a TCP packet would go and rely on the routing system to get it to the right place. As long as the receiving and transmitting ends have an agreed convention for how to treat these packets, everything can be decoded correctly and life is easy.
Static tunnelling is meant to link isolated islands of IPv6 connectivity, where the networks are well-known and unlikely to change without notice. One example would obviously be branch officesâthe Galway division of X Corp. has a dial-on-demand link to the Dublin branch with both IPv6 and IPv4 connectivity, say. The way it works is as follows: the egress points of the linked networks are configured to encapsulate IPv6 packets to specified IPv6 destinations through statically configured IPv4 gateways. The packets proceed over the normal IPv4 routing system and are decapsulated at the other end, with the IPv6 packet then being forwarded to the correct host by the IPv6 routing system. If a packet is lost or dropped in the IPv4 part of the forwarding system, the usual TCP or application retransmission mechanisms come into play, just as if the packet had been lost due to, e.g., an Ethernet glitch. The intention is that the IPv4 section of the journey happens in as transparent a fashion as possible to the IPv6 stacks and applications.
It's important to note that this IPv4 forwarding is not happening over any kind of TCP or UDP "port"âit's another protocol commonly referred to as IPv6 over IPv4.
So, where are you likely to see configured tunnels in practice? There seem to be three common situations, all used to work around pieces of IPv4-only infrastructure.
- ISP to customer
Here, possibly because a border router does not support IPv6, an ISP provides IPv6 connectivity to a customer by providing a tunnel to some dual-stacked host or router within the customer network.
- Tunnel broker
Here your ISP may not be providing IPv6 support and instead you get an IPv6 connection via a third party, who are known as tunnel brokers.[1] There are many people who provide tunnels as a public service such as http://www.freenet6.net/ and http://www.sixxs.net/.
- Linking internal sites
In some cases, sites within an organization may be joined by sections of network that aren't IPv6 capable, and until they are upgraded tunnels are necessary to join up the sites. In these cases you have the option of putting the tunnel endpoints on either side of the IPv4-only blockage, or bringing all the tunnels back to a central point. Deciding which is appropriate probably depends on if you have centralized or autonomous IT management.
Example 4-1 shows an example of how a configured tunnel is set up on a Cisco router. We'll leave the ins and outs of this until the Section 4.1.2 later in this chapter, but you can see that it isn't a complex configuration and only involves specifying the IPv4 and IPv6 addresses of the tunnel end points.
Example 4-1. Example static tunnel configuration on a Cisco
! interface Loopback0 ip address 192.0.2.1 255.255.255.255 ! interface Tunnel1 description Tunnel for customer BIGCUST no ip address ipv6 address 2001:db8:8:6::1/64 tunnel source Loopback0 tunnel destination 192.168.200.2 tunnel mode ipv6ip ! ipv6 route 2001:db8:70::/48 Tunnel1 !
RFC 2893 describes the encapsulation used for IPv6-in-IPv4 tunnels, and the notion of
configured tunnels. It also describes the notion of an automatic
tunnelling. In this situation, the prefix ::/96 is set aside for things called
IPv4 compatible addresses, where the rightmost
32 bits of the IPv6 address is considered to be an IPv4 address.
IPv6 packets addressed to these addresses could be automatically
encapsulated in an IPv4 packet addressed to the corresponding IPv4
address and tunnelled to its destination.
This means that two hosts that both speak IPv4 and IPv6 could talk IPv6 to one another, even if neither had a connection to the IPv6 Internet. While initially this might seem useful, the real question is why wouldn't they just speak IPv4? In fact, automatic tunnelling has some security implications; for example, a host that replies to a compatible address may generate IPv4 packets, which may not be expected on the network. As a result compatible addresses are not usually assigned to interfaces, but are used as a way of indicating that IPv6 should be tunnelled. For example, setting the default IPv6 route to the IPv4 compatible address of a dual-stacked router would result in packets being tunnelled to that router.[2]
In general, automatic tunnelling isn't something that you will need to consider at a planning stage as anything more than a configuration device. Its close relative, 6to4, is something considerably more relevant, as we will see.
6to4 is a mechanism allowing organizations to experiment with IPv6 without:
An upstream ISP(s) supporting IPv6.
Applying for IPv6 address space.
Arranging a "tunnel" with another IPv6 user.
The only thing a 6to4 user needs is a global IPv4 address, reachable on protocol 41.[3] Again note that this is a protocol number, not a port number.
Here's an example of how it works. Suppose that a 6to4 machine
is using IPv4 address 192.0.2.4
from a public allocation. By virtue of the fact that the machine has
this IPv4 address, by definition, it can also use the entire IPv6
network 2002:c000:0204::/48! You
get this address by taking the 6to4 prefix 2002::/16 and replacing bits 17 to 49 with
the 32 bits of the IPv4 address. Usually, the machine configures a
`'6to4" pseudo-interface which has a selected address from the 6to4
range of its IPv4 address. Other machines within the organization
can then be assigned addresses from the 6to4 range, and outgoing
packets should be routed to the host with the 6to4
pseudo-interface.
So, 6to4 automatically assigns you a range of addresses, but how can we get packets to and from the IPv6 Internet and your network?
Packets from the IPv6 Internet sent to an address in the range
2002:c000:0204::/48 will be
routed to the nearest 6to4 Relay Router. Relay
routers are routers which advertise routes to 2002::/16, into the local or global
routing table, and they're connected to both the IPv4 and IPv6
Internet. The router looks at the 6to4 address, extracts the
embedded IPv4 address, and so encapsulates the IPv6 packet in an
IPv4 packet addressed to 192.0.2.4. When the packet arrives at
192.0.2.4 it will be decapsulated
and routed as a normal IPv6 packet according to the normal IPv6
routing rules within your organization. (The whole strategy might
remind you of the tunnelling mechanism described in Section 4.1.3 earlier in this
chapter.)
To get packets back to the IPv6 Internet from your 6to4
network, we need a relay router for the opposite direction. An IPv4
anycast address, 192.88.99.1, has
been assigned for this job, so the default IPv6 route on 192.0.2.4 can
be set to point to 2002:c058:6301::. This means that packets
going to the IPv6 Internet will be encapsulated and sent to 192.88.99.1, which will be routed by the
normal IPv4 routing system to the nearest 6to4 relay router with
this anycast address. The relay router, which is again connected to
both the IPv4 and IPv6 Internet, will forward the packet to the IPv6
Internet and the packet will then make its way to its
destination.
Figures Figure 4-1 and Figure 4-2 illustrate how packets get from a 6to4 network to the IPv6 Internet and back again. 6to4 also allows for a short-cut for packets between 6to4 networks, where they can be sent directly to the appropriate IPv4 address.
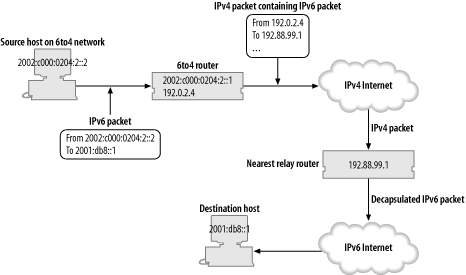
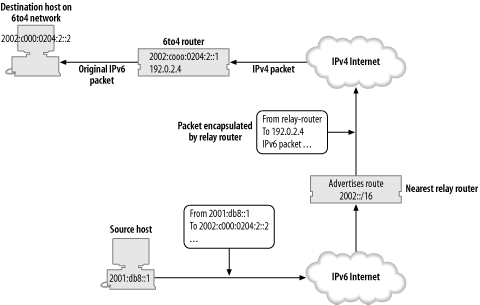
The details of 6to4 are explained in RFC 3056, but it was written before the allocation of the IPv4 anycast address, so RFC 3068 covers the allocation and use of the anycast address. We'll cover the configuration of 6to4 in Section 5.5.2 in Chapter 5.
So, when is it a good idea to use 6to4? Well, 6to4 has advantages over configured tunnels for people who don't have a fixed IP address. Specifically, your tunnel broker or ISP needs to know your IPv4 address if they are to route packets for a fixed IPv6 address space to you. If your IPv4 address keeps changing, then you need to keep updating their configuration. With 6to4, when your IPv4 address changes, so do your IPv6 addresses, and they implicitly have your new IPv4 address embedded in them. This makes them good for most kinds of dial-up and certain kinds of DSL user.
6to4 could also be used by an organization with fixed IPv4 addresses in the absence of an IPv6-capable ISP or nearby tunnel broker. Unfortunately, there are two disadvantages to using the technique here. First, you don't know where the nearest relay router will be, and second, you may find it tricky to get reverse DNS for your 6to4 prefix. However, it does mean you don't have to depend on a single tunnel broker.
An organization with a large IPv4 infrastructure might consider deploying separate 6to4 prefixes internally and using it to provide islands of IPv6 connectivity internally. They could also provide their own relay router to control the egress of IPv6 from the organization. See the Section 6.6.1 section in Chapter 6 for some advice on running a 6to4 relay router.
One peculiarity of IPv6 is that it is neither forward nor backward-compatible. In other words, IPv4-only hosts cannot communicate with IPv6-only hosts, and vice versa. Even on a globally reachable IPv4 host with a working IPv6 stack, the machine still cannot communicate with IPv6-only hosts unless you configure one of the transition mechanisms or provide native connectivity.
Various people are eager to fix this problem, and 6to4 and
Teredo go a long way to provide IPv6 client hosts with automatic
connectivity to the IPv6 Internet. Dan Bernstein suggested a
mechanism to try to extend this to servers. The idea is that each
IPv4 server with an IPv6 stack automatically configures a
well-known 6to4 address, say 2002:WWXX:YYZZ::c0de. Then when an
IPv6-only client tries to connect to a server that only had an
IPv4 DNS record, it then could generate the corresponding
well-known 6to4 address and try to connect to that.
Dan's argument was that as people gradually upgraded the software on their servers to a version including AutoIPv6, more of the IPv4 Internet would become available over IPv6 without any further effort being expended. To make AutoIPv6 happen would require a tweak in the DNS libraries on IPv6-only hosts and for vendors to arrange automatic configuration of 6to4 and the well-known address: a simple matter of tweaking boot-up scripts.
AutoIPv6 hasn't been taken further than the idea stage yet. Some consideration probably needs to be given to how it would interact with firewalls, load balancers and other complex network hardware, as well as how it would impact native IPv6 deployment. However, it would seem that it could only improve the situation for IPv6-only hosts. We mention AutoIPv6 here mainly to highlight the problem of how to connect IPv6-only and IPv4-only hosts. We'll see other possible solutions to this problem later in this section when we consider mechanisms like SIIT.
We know that there are many hosts that are stuck behind NAT devices, which can usually only deal with TCP, UDP and limited kinds of ICMP. As we have noted, configured tunnels and 6to4 make use of IPv4's protocol 41, which is neither TCP nor UDP. This means that it may not be possible for NATed hosts to use tunnels, 6to4 or indeed any other mechanisms using odd protocol numbers.
Teredo is a mechanism that tunnels IPv6 through UDP in a way that should allow it to pass through most NAT devices. It is a remarkably cunning design, intended as a "last-ditch" attempt to allow IPv6 connectivity from within an organization where end hosts may not have any other suitable networking available.
The operation of Teredo is somewhat similar to 6to4 as it requires a certain amount of infrastructure, namely Teredo servers and Teredo relays. Servers are stateless and are not usually required to forward data packets. The main function of Teredo servers is facilitate the addressing of and communication between Teredo clients and Teredo relays, so they must be on the public IPv4 Internet. They also occasionally have to send packets to the IPv6 Internet, and so need to be connected to it.
Relays are the gateways between the IPv6 Internet and the Teredo clients. They forward the data packets, contacting the Teredo servers if necessary. They must be on the IPv4 and the IPv6 Internet.
Much of the complication of Teredo involves sending packets to create state on the NAT device. These packets are given the name Teredo bubbles. Clients initially contact the Teredo server, allowing two way conversation with it. The client forms an address that is a combination of the server's IPv4 address and the IPv4 and port number allocated to the NAT device by this initial communication.
From then on, if a Teredo relay wants to forward packets to a Teredo client, it can contact the server to ask it to ask the client to send a packet to the relay. This packet will establish the necessary state on the NAT device to allow direct communication between the relay and the client.
Provision is also made for direct client-to-client operation and other optimizations, depending on the specifics of the NAT device you are behind. (There is a process a Teredo client can go through to determine what kind of NAT it is behind.)
Teredo uses the prefix 3FFE:831F::/32 and UDP port 3544. Since
the IPv6 address assigned to a client depends on the server's
address and the NAT's address, there is a possibility that it will
change frequently, especially if the NAT's IPv4 address is
dynamically assigned.
Christian Huitema from Microsoft is an important driving force behind Teredo. His draft describing the current state of Teredo's development is available at http://www.ietf.org/internet-drafts/draft-huitema-v6ops-teredo-03.txt. Microsoft is very interested in technology like Teredo because many Windows machines are stuck behind NAT devices and Microsoft would like to be able to offer new technology and services to these machines and their users. Teredo is available as part of the peer-to-peer update for Windows XP, and though other vendors have not yet implemented it, it looks likely to become widely used. You can also get access to a preview of the server-relay technology component of Teredoâemail ipv6-fb@microsoft.com for more details. (Although Teredo is currently at a somewhat experimental stage. some code is already shipping.)
While Teredo is likely to become widely used in unmanaged networks as a way for a computer to connect itself to the IPv6 network, Teredo is the sort of technology that you don't want to include in a deployment plan. Teredo is intended to be a last resort, used before any IPv6 infrastructure is available and when you have no access to a public IPv4 address. Your deployment should put infrastructure in place that eliminates the need for Teredo. However, if you are just trying to deploy IPv6 on your desktop and you're stuck behind a NAT, then Teredo may be your only choice.
In the same way as you can have "IPv6 over Ethernet" or "IPv6 over token ring," there is a mechanism to run an IPv6 network using IPv4 as the layer 2 transport, and this mechanism is called 6over4. This is different from tunnels and 6to4, because it aims to allow full neighbor discovery with the IPv4 network acting as a LAN. Remember, IPv6 makes use of layer 2 multicast, so 6over4 achieves this by using IPv4 multicast.
In the same way that Ethernet uses the EUI-64 interface IDs,
6over4 needs a way to form interface IDs so it uses the IPv4
address: a node with address 10.0.0.1 will end up with link-local
address fe80::0a00:0001.
Similarly, there is a mapping between IPv6 multicast addresses and
IPv4 multicast addresses, so FF02::1 becomes 239.192.0.1. All this is explained in
detail in RFC 2529.
In a way, 6over4 is a little like carrying IPv6 over MPLS, in that MPLS encapsulates IPv6 such that the internal details of the routing become invisible to the IPv6 layer 3 devices.
Since 6over4 is just another medium type that you can run IPv6 over, it doesn't have any special prefix associated with it. (If you want to use 6over4 you have to get your address space and external connectivity from some other source.)
6over4 doesn't really seem to have a lot of momentum, probably as a result of it requiring working IPv4 multicast infrastructure and the work on ISATAP, which provides many of the features 6over4 would have provided. It is also not widely implemented, so you probably do not need to consider it while planning your use of IPv6.
ISATAP is a rather funky acronym standing for Intra-Site Automatic Tunnel Addressing Protocol. The idea is very similar to 6over4, in that it aims to use an IPv4 network as a virtual link layer for IPv6. Probably the most important difference is that it avoids the use of IPv4 multicast.
To get this to work, ISATAP needs to specify a way to avoid
the link-local multicast used by neighbor solicitation and router
solicitation. To avoid the need for neighbor solicitation, ISATAP
uses addresses with an interface ID of ::0:5EFE:a.b.c.d which are assumed to
correspond to an IPv4 "link-layer" address of a.b.c.d. Thus link-layer addresses on
ISATAP interfaces are calculated as opposed to solicited.
Avoiding multicast for router solicitations requires some sort of jump-start process
that provides you with the IPv4 addresses of potential routers. It
is suggested that these might be got from a DHCPv4 request or by
looking up a hostname like isatap.example.com using IPv4
connectivity. Once the node has the IPv4 addresses of potential
ISATAP routers it can then send router solicitations to each,
encapsulated in an IPv4 packet. The routers can reply and the nodes
can configure addresses based on the advertised prefixes and their
ISATAP interface IDs.
So, what does ISATAP buy us? Without an ISATAP router, it acts
like automatic tunnelling, but using link-local ISATAP
addresses[4] of the form fe80::5EFE:a.b.c.d rather than IPv4
compatible addresses like ::a.b.c.d, allowing communication between
a group of hosts that can speak IPv4 protocol 41 to one another.
This could be a group of hosts behind a NAT, or a group of hosts on
the public Internet.
With an ISATAP router you can assign a prefix to this group of hosts and the router can provide connectivity to the IPv6 Internet via some other means (either a native connection, a tunnel, 6to4 or whatever). So, the thing that defines which group of hosts are on the same virtual subnet is the ISATAP router they have been configured to use.
ISATAP has some nice features, especially if you are doing a sparse IPv6 deployment in a large IPv4 network. You may not want to manually configure tunnels or deploy IPv6 routers for each subnet that you are deploying an IPv6 node on. ISATAP lets you deploy a number of centrally located ISATAP routers which can then be accessed from anywhere in the IPv4 network without further configuration.
Note that you can achieve something quite similar to this with
6to4, where 192.88.99.1 takes the
place of the ISATAP router. However, with 6to4 the prefixes you use
are derived from the IPv4 addresses, so if you are stuck behind a
NAT you get bad 6to4 addresses. With ISATAP the interface ID is
derived from the IPv4 address and the prefix comes from the ISATAP
router, so you can give out real addresses IPv6 inside the NATed
network.
The draft describing ISATAP can be found at http://www.ietf.org/internet-drafts/draft-ietf-ngtrans-isatap-22.txt. Unfortunately, ISATAP implementations are a bit thin on the ground at the moment: Windows XP supports ISATAP, and KAME and USAGI snapshots used to include ISATAP support, but its development is being hindered by intellectual property concerns.
The previous techniques we have discussed allow us to use IPv4 infrastructure to enable IPv6 hosts to talk to one another, or to the IPv6 Internet at large. SIIT is the first technique we'll mention that's intended to allow IPv4-only hosts to talk to IPv6-only hosts.
SIIT is Stateless IP/ICMP Translation. The idea is that it allows you to take an IPv4 packet and rewrite the headers to form an IPv6 packet and vice versa. The IP level translations are relatively simple: TTL is copied to Hop Limit, ToS bits to traffic class, payload lengths are recalculated and fragmentation fields can be copied to a fragmentation header if needed.
Since TCP and UDP haven't really changed, they can be passed through relatively unscathed. However the differences between ICMPv4 and ICMPv6 are more significant, so SIIT specifies how to do these translations too.
There is one other tricky issue, which is how to translate addresses between IPv4 and IPv6. Getting an IPv4 address into an IPv6 address is straightforward, just embed it in the low 32 bits. Since IPv6 addresses are much larger, there's not a lot of point trying to encode them in an IPv4 address, so some mapping must be done. NAT-PT and NAPT-PT are ways of doing this, which we'll discuss in a moment.
Note that while SIIT involves copying lots of header fields around it doesn't actually require any state to be kept on the translating box, other than the rule to map IPv4 address back to IPv6 addresses.
If you want to know the details of SIIT see RFC 2765. Remember that SIIT is very definitely a translation technology: it takes IPv6 packets and removes all the IPv6 headers and replaces them with IPv4 headers. This is very different to tunnels, Toredo or ISATAP; they encapsulate IPv6 packets, retaining all their IPv6 headers. As we have all seen with IPv4 NAT, translation can cause problems with applications like FTP that transmit addresses internally. Also remember that if remote addresses of connections are logged by applications, then they will be translated addresses.
NAT-PT is an application of SIIT that allows the mapping of a group of IPv6 hosts to a group of IPv4 addresses, in much the same way that IPv4 NAT allows a group of IPv4 hosts using private addresses to use a group of public addresses. The extra PT in NAT-PT stands for protocol translation.
RFC 2766, which describes NAT-PT, also describes a "DNSALG" system for IPv6. DNSALG is a way of rewriting DNS requests and responses as they pass through the NAT system. This, in principle, means that DNS query for an IPv6 host inside the NATed network can be translated to one of the IPv4 addresses in use on the NAT automatically.
We have to admit that we haven't seen any NAT-PT devices in action, though there are both commercial and free implementations available.
TRT, Transport Relay Translation, is described in RFC 3142. It is similar in idea to SIIT, but rather than translate between IPv4 and IPv6 at the IP and ICMP levels, instead we translate at the transport level, i.e., TCP and UDP. A machine doing TRT will have some range of IPv6 addresses that it translates to a range of IPv4 addresses. When a TCP connection is made to one of these addresses the TRT machine will make a TCP connection to the corresponding IPv4 address on the same port. Then as TCP data packets are received the data is forwarded on, and similarly for UDP.
TRT has the disadvantages of translation, mentioned in the previous section; however, it avoids certain issues related to fragmentation. It does also require the storage of state associated with the ongoing TCP and UDP sessions that SIIT does not. It also tends to be deployed on an application-specific basis; in other words, it doesn't try to translate every possible protocol. This may be an advantage or a disadvantage, depending on your setup!
We give an example of a TRT setup in Section 6.6.2 of Chapter 6, using the KAME faith mechanism.
Bump in the stack (BIS) is basically another SIIT variant, but the motivation is slightly different. Suppose you have some piece of software that you want to use over IPv6, but you can't get an IPv6-capable version of it. Even if you have great IPv6 connectivity, this software is pretty useless to you. BIS is a trick to make software like this usable.
Say the software makes tries to make a connection to www.example.com, with address 2001:db8::abcd. When the software looks up
www.example.com the
address mapper component of BIS picks an IPv4
address from a pool configured for BIS, say 192.168.1.1, to represent this host and
returns this IPv4 address to the software. The software then uses
this address normally.
Meanwhile, BIS intercepts packets coming out of the IPv4 stack
that are destined to 192.168.1.1
and uses SIIT to rewrite them as IPv6 packets destined to 2001:db8::abcd. Packets going in the
opposite direction are similarly translated.
There is a variant of BIS called Bump in the API (BIA). It
operates in a similar way: an address mapper intercepts name lookup
calls and returns a fake IPv4 address for IPv6 hosts. The
application uses the address as usual. However, library functions
such as connect, bind and getpeername know about these fake
addresses and actually translate these to/from IPv6 addresses before
proceeding (otherwise) as normal.
Bump in the stack is described in RFC 2767 and Bump in the API is described in RFC 3338.
Both BIS and BIA have the usual drawbacks associated with translation: embedded addresses cause problems and logging of addresses may be inaccurate. They do have some advantages over NAT and TRT though because they distribute the translation task to the end hosts and consequently may scale better.
Proxies are another way to connect IPv6-only networks to IPv4-only networks. Many people are already familiar with web proxies, where a web browser can be configured to make all requests to the proxy rather than directly to the appropriate web server. The web proxy then fetches the web page on behalf of the browser.
A web proxy running on a dual-stacked host can potentially accept requests over both IPv4 and IPv6 from web browsers and then fetch pages from both IPv4 and IPv6 servers, as required.
Proxying is not limited to HTTP either. A dual-stacked recursive DNS server behaves very similarly, accepting requests over IPv4 and IPv6 and answering those requests by making a sequence of requests to other DNS servers as necessary. Likewise, a dual-stacked SMTP server can receive mail for an IPv6-only domain and forwarded it as needed.
The main advantage of proxying is that it is a technology that is relatively familiar and it does not require any complex translation. The down side is that it can require some application support. Proxies are likely to be an important bridge between IPv4 and IPv6 for the foreseeable future.
We cover HTTP proxying in some detail in Chapter 7 (Section 7.3.4), and the issue of dual-stack DNS servers in Chapter 6, in the Section 6.1.3 section. We also give an example of port forwarding, a form of proxying that can be used to get IPv4-only applications to talk over IPv6, in Section 7.12 of Chapter 7.
Since there are such a large number of transition mechanisms that have been identified as being useful for IPv6 deployment, we offer you Table 4-1. It provides a one sentence description of each. Table 4-2 gives a one-sentence "serving suggestion" for each of the mechanisms.
Table 4-1. One-line summary of IPv6 transition mechanisms
Method | Summary |
|---|---|
Dual-stack | Run IPv4 and IPv6 on nodes. |
DSTM | Dual-stack, but dynamically allocate IPv4 addresses as needed. |
Configured tunnel | Virtual point-to-point IPv6 link between two IPv4 addresses. |
Automatic tunnel | Automatic encapsulation of IPv6 packets using "compatible addresses." |
6to4 | Automatic assignment of |
Teredo | IPv6 in UDP through a NAT. |
6over4 | Using IPv4 as a link layer for IPv6, using IPv4 multicast. |
ISATAP | Using IPv4 as a link layer for IPv6, using a known router. |
SIIT | Rules for translating IPv6 packets straight into IPv4. |
NAT-PT | Using SIIT to do NAT with IPv4 on one side and IPv6 on the other. |
TRT | Translating IPv6 to IPv4 at the UDP/TCP layer. |
BIS | Using SIIT to make IPv4 applications speak IPv6. |
BIA | Using a special library to make IPv4 applications speak IPv6. |
Proxies | Using application level trickery to join IPv4 to IPv6 networks. |
Table 4-2. Possible deployment scenario for IPv6 transition mechanisms
Method | Deployment scenario |
|---|---|
Dual-stack | Dual stack everything, if you have enough IPv4 addresses. |
| Â | Otherwise dual stack a few border devices. |
DSTM | Can be used instead of dual stacking border devices. |
| Â | Not that widely available. |
Configured tunnel | Use to hop over IPv4-only equipment. |
Automatic tunnel | Only used as a configuration device. |
6to4 | Good for isolated IPv6 networks (e.g., home/departmental networks). |
Teredo | A last resort for people stuck behind NAT. |
6over4 | Not widely deployed because of IPv4 multicast requirement. |
ISATAP | Useful for sparse IPv6 deployments within IPv4 networks. |
SIIT | Not deployed by itself. |
NAT-PT | Proxies are probably a cleaner solution, where available. |
TRT | Ditto. |
BIS | Getting software that supports IPv6 would be better. |
BIA | Ditto. |
Proxies | Dual-stack proxies for SMTP, HTTP and DNS will be important for some time. |
[1] Actually, a tunnel broker is someone who finds a tunnel for you and the tunnel may in turn be provided by a fourth party!
[2] More explicitly, if the router had address 10.0.0.1 this might be achieved by
running a command such as route add
-inet6 default ::10.0.0.1. Not all operating systems
support this, but you can see examples of this in Table 5-13.
[3] The protocol number for encapsulated IPv6.
[4] In case you are wondering where 5EFE comes from, it is the Organizationally-Unique Identifier (OUI) assigned by IANA that can be used for forming EUI-64 addresses.
Get IPv6 Network Administration now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

