Domain Decomposition Data Structure Needs
Data decomposition is a technique frequently used for very scalable computations. There are two points of definition: tasks that communicate most frequently are in the same domain; and the amount of work in a domain is fairly balanced. For scalability, the first point assumes that most communication occurs local to each domain; in other words, local to a single thread and requiring no synchronization. A smaller amount between domains should impact speedup less. Communication cost should include the cache effects of moving a cache line from one core to another, as well as synchronization.
There is a natural tendency to associate the term domain with a spatial domain. That may not be the case. It is possible, and demonstrated in the example, that spatially close objects may execute in different threads because the memory is still shared. It is also possible that a domain—a group of objects—may move (by task stealing) to a different thread even though its spatial-domain neighbors stay.
In this example, one root task creates a task for each domain in a k-d tree (see Figure 11-27). It starts by creating the root:
*new(tbb::task::allocate_root()) InteractTask(m_bh, 0, m_bh, m_universeRadius, m_DummyCount);
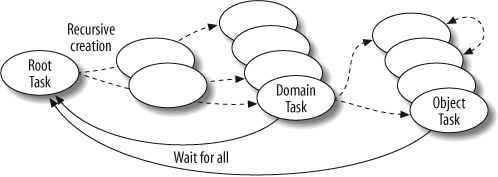
Figure 11-27. Task creation structure
A task tree of all the domain tasks is built recursively descending the k-d tree structure. See InteractTask ...
Get Intel Threading Building Blocks now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

