The spirit of HTML5 is simplicity. HTML5 has made it easy to implement web standards that in the past have been difficult to implement. Instead of trying to reinvent the Web, visionary consortiums such as the WHATWG (Web Hypertext Application Technology Working Group) and the W3C (World Wide Web Consortium) looked at the web standards that had evolved and built upon them.
In essence, HTML5 is primarily an update to the HyperText Markup Language (HTML). In this chapter we will start with the basic building blocks of HTML, the semantic elements, to provide a foundation for the simple yet powerful new web browser technologies exposed within this book.
So, open up your favorite code editor, brew a pot of coffee, and get ready to code in the most powerful language the Web has ever seen: HTML5!
If thereâs an emblem representing the simplicity HTML5 brings to the
markup world, itâs the <DOCTYPE>
tag. The HTML5 <doctype> tag is
easy to use.
When you open an XHTML document the first thing you see, the first line of the document, is a mess:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
The <DOCTYPE> tag of HTML
past, inherited from its SGML foundations, consisted of three main
components: the tag name, the public identifier string, and the DTD
(Document Type Definition) URL. Itâs a strange mix of uppercase and
lowercase letters, quote marks and slashes, and a URL that brings up an
even less readable file. To make it even stranger, the <DOCTYPE> tag is unique, as it is the only
HTML tag since HTML 4.01 that is in all caps.
HTML5 says farewell to all that, and keeps it simple:
<!doctype html>The browser uses the <doctype> to know how to render the web
page. Most browsers didnât download the DTD from the URL, but they did
change their behavior based on the <DOCTYPE>. If a browser encountered the
preceding code, it would switch to standards mode (as opposed to quirks
mode) and apply XHTML transitional formatting.
Given all that, how can HTML5 get away with a basic <doctype> such as html? The simple answer is that the new <doctype> is a âsimple answer.â The new
<doctype> was made to trigger a
simplified approach to document rendering, not to meet old expectations.
Browser makers reached a consensus on how browser-specific functionality
should be handled, so there is no need for âquirks modeâ page rendering.
If all browsers render in a standard manner, the DTD is unnecessary; thus
a simple declaration of html states
that the browser should set aside any DTD and simply render the
page.
HTML5 is a simplified version of HTML. The tags are less complex, the features are less complex, and most importantly, the rules are less complex.
However, in most applications you write, you will not yet be
servicing a user base that
consistently supports HTML5. So how can you switch between
<doctype>s when the <doctype> is supposed to be the first line
of the document? This doesnât leave much room for JavaScript trickery or
fancy hacks. Well, good news; there is a backward-compatible HTML5
<doctype> as well:
<!DOCTYPE html>âBut wait,â you say. âIsnât that the same simple <doctype> presented earlier?â Yes, it is!
The only key difference is that âdoctypeâ is now in all caps. The HTML5
specification states that the <doctype> is case-insensitive; however,
previous versions of HTML require an all-caps version of the <doctype>. You will find that much of
HTML5 is backward-compatible with earlier versions. The vast majority of
browsers on the market today will see the new <doctype> and recognize it as simply being
âstandards modeâ for page rendering.
Using the backward-compatible version of the <doctype> will allow you to start using
HTML5 today, while continuing to support browsers of the past!
Many web documents have similar structures. Take advantage of markup that makes it easier to share styles and expectations.
Web designers and developers have long conformed to structural components on a page. A common high-level page structure may look something like the following:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html><head><metahttp-equiv="content-type"content="text/html;charset=UTF-8"/><title>...</title></head><body><divid="header">...</div><divid="nav">...</div><divid="article">...</div><divid="footer">...</div></body></html>
Take note of the âstructuralâ ids in the page. This reflects well-organized
content and a clean structure for the page. The problem with the preceding
code is that almost every element in the markup is a div. Divs are
great, but they are of little use in page definition without associating
them with an id. The problem with using
ids for role association is that when
you want to use them for another purposeâsay, to identify a doc treeâyou
run into problems: as soon as you add a tool such as YUI Grids or
WordPress to a page that actually uses the id of a div,
it conflicts with your div âroles,â and
the next thing you know you are adding layers of divs just to satisfy your structural needs. As a
result, the clean page shown earlier may now look something like
this:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html><head><metahttp-equiv="content-type"content="text/html;charset=UTF-8"/><title>...</title></head><body><divid="header"><divid="nav"><divid="doc2"><divid="wordpress-org-2833893">...</div></div></div><divid="article"><divid="doc2"><divid="wordpress-org-887478">...</div></div></div><divid="footer">...</div></body>
You can see pretty quickly where this gets messy, yet we donât want to abandon the idea of structural elements that declare page segmentsâmany code readers, such as screen readers and search bots, have come to rely on structural conventions. As with many parts of HTML5, the new structural tags have provided a simple solution to the problem of added complexity. Letâs build our page with structural elements:
<!DOCTYPE html><html><head><metacharset="UTF-8"><title>...</title></head><body><header>...</header><nav>...</nav><article>...</article><footer>...</footer></body></html>
Once again we have a simple, clean HTML5 solution that keeps our page easy to work with, and easy to consume by screen readers and search bots. This same code can meet the needs of our third-party products as well, as shown in the following solution:
<!DOCTYPE html><html><head><metacharset="UTF-8"><title>...</title></head><body><headerdata-yuigrid="doc2"data-wordpress="2833893">...</header><nav>...</nav><articledata-yuigrid="doc2"data-wordpress="887478">...</article><footer>...</footer></body></html>
Weâll get into the data-
attributes later in this chapter, but for now you just need to understand
that this solution allows you to keep the structural elements of the page
and let third-party components apply identifiers to the nodes, while
freeing up the id attributes for the
page author to control. Take note, third-party developers: never assume
that the id of an element is yours to
consume!
HTML5 didnât stop at the new tags discussed in the preceding section. Hereâs a partial list of some of the new HTML5 markup tags to take note of:
| | | | | | |
| | | | | | |
A lot of these tags grew out of common use by web developers. The W3C smartly decided to âpave the cow pathsâ instead of trying to change the behavior of web developers. This way, the tags are generally useful for immediate adoption.
In most cases each tagâs intent is pretty obvious. The <header> and <footer> tags do exactly what they say:
they outline the header and footer of the page (or app). You use
<nav> to wrap your navigation.
The <section> and <article> tags give you options to the
overused <div> tag; use these
to break up your page according to the content (e.g., wrap your articles
in the <article> tag). The
<aside> tag acts in a similar
way to the <article> tag, but
groups the content aside the main page content. The <figure> tag refers to a self-contained
piece of content, and so on and so on. Note that this list is not
conclusive and is always changing. Visit the w3schools website for
the most
complete list I could find.
Donât wait for full HTML5 adoption across the Web. Make HTML5 structural tags render properly in all browsers.
So, now you have this whole new world of HTML5 elements that will
let you be both expressive and semantic with your markup. Youâve been
freed from the shackles of divs and can
show your face at parties again!
Semantic markup is the use of markup in a meaningful way. Separation of structure and presentation leads us to define our presentation (look and feel) with CSS, and our content with meaningful or semantic markup.
Youâre feeling pretty good about yourself until you remember that some of your visitors are not using HTML5 browsers, and being the web standards elitist that you are, your page has to be backward-compatible. Donât throw those HTML5 tags out the window just yet. This hack will teach you how to write your code once, and use it on all the browsers out there.
Any browser made in the past 10 years will see your HTML5 tags in one of 3 ways:
See the HTML5 tag and render it appropriately (congratulations, you support HTML5!).
See the HTML5 tag, not recognize it, and consider it an unstyled (which defaults to inline) DOM (Document Object Model) element.
See the HTML5 tag, not recognize it, and ignore it completely, building the DOM without it.
Option 1 is a no-brainer: youâre in an HTML5 browser. Option 2 is
likewise pretty easy to address, as you simply have to set your default
display parameters in your CSS. Keep in mind that with option 2, you have
no functional DOM APIs for these new tags, so this is not true support for
the tags. In other words, using this method to create a meter element does not create a functional
meter. For our use case of semantic markup elements, however, this should
not be an issue.
So, focusing on option 3, youâre using IE 6, 7, or 8 and youâre loading a page that contains new HTML5 semantic tags. The code will look something like this:
<!DOCTYPE html><html><head><metacharset="UTF-8"><title>My New Page with Nav</title></head><body><div><navclass="nav"><p>this is nav text</p></nav></div></body></html>
There are basically two different ways to handle this lack of support.
In the preceding code sample, the nav element is not recognized and is passed
over at render time. Since the DOM does not recognize these elements,
option 1 uses a fallback element that the browser does recognize, and
wraps each unrecognized element in
it. The following code should make this easier to understand:
<!DOCTYPE html><html><head><metacharset="UTF-8"><title>My New Page with Nav</title></head><body><div><navclass="nav"><divclass="nav-div"><p>this is nav text</p></div></nav></div></body></html>
Voilà ! We can now style the element with the
nav-div class instead of the element
with the nav class, and our DOM will
be complete in all common browsers. Our page will style correctly, and
we will have our new HTML5 tags in place for screen readers and search
engines that will benefit from the semantic tags.
This method will work, but there are some downsides to this
solution. For starters, having duplicate tags negates the benefit in
many ways, as we are still using divs
for every structural element of the page. The biggest problem with this
solution, though, is how it corrupts the DOM tree. We no longer have a
consistent parentâchild relationship from browser to browser. The
browsers that do recognize the HTML5 element will have an extra âparentâ
to the contents of the element, so the trees will differ from one
browser to the next. You may think you donât need to care about this,
but as soon as you start accessing the DOM with JavaScript (especially
if youâre using a JavaScript library such as YUI or jQuery) you will run
into cross-browser issues.
Iâm happy to say there is a second, and in my opinion better,
solution to our problem. I believe this âfeatureâ was first discovered
by Sjoerd Visscher in 2002 when he switched from createElement to innerHTML and realized he lost the ability to
style unrecognized elements. Fast-forward to 2008, when John Resig
realized he could exploit the same bug to make HTML5 elements
recognizable in IE; he named the capability the âHTML5 shiv,â although
it is technically a shim. Here are the details.
Old versions of IE donât recognize HTML5 elements
naturally, but as soon as you use document.createElement() in the head of the
document passing in an unrecognized element, IE will add the element to
its tag library and it can be styled with CSS. Letâs go back to the
markup:
<!DOCTYPE html><html><head><metacharset="UTF-8"><title>My New Page with Nav</title><style>.nav{color:red}nav{display:block;background-color:blue}</style></head><body><div><navclass="nav"><p>this is nav text</p></nav></div></body></html>
Figure 1-1 shows how the preceding markup will appear in IE versions 6 through 8.
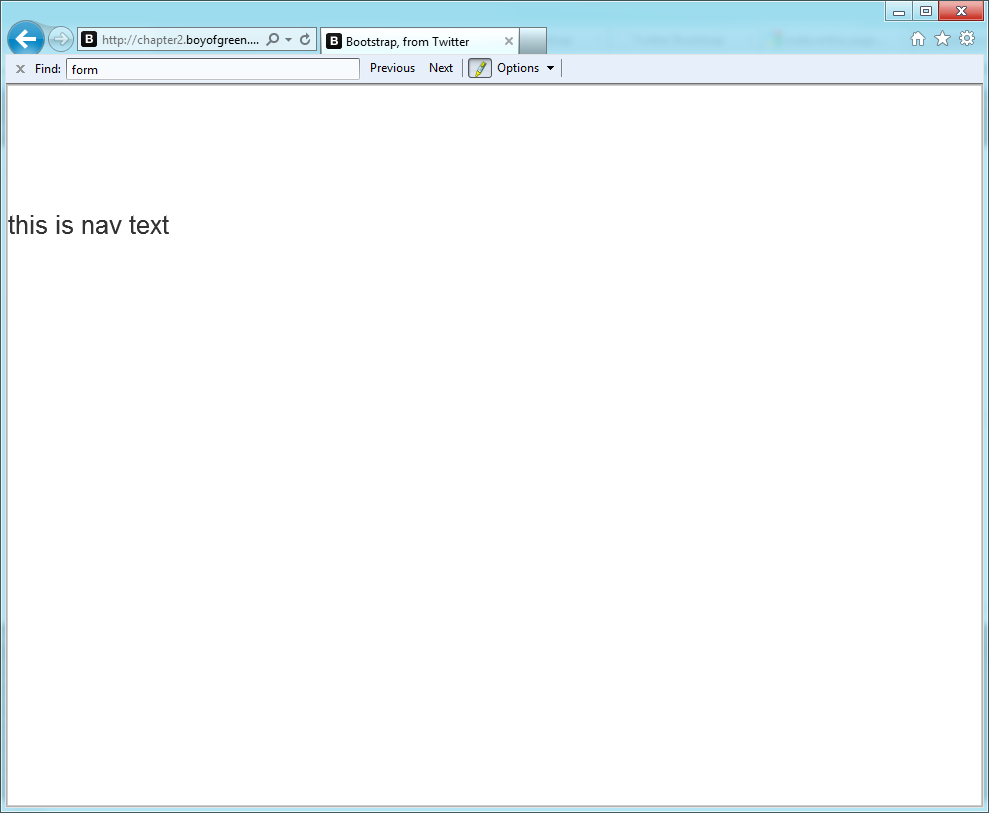
Notice that the element didnât pick up the color from the tag name or the CSS class assigned to the tag; it simply ignored it. Now letâs throw in our JavaScript and try it again:
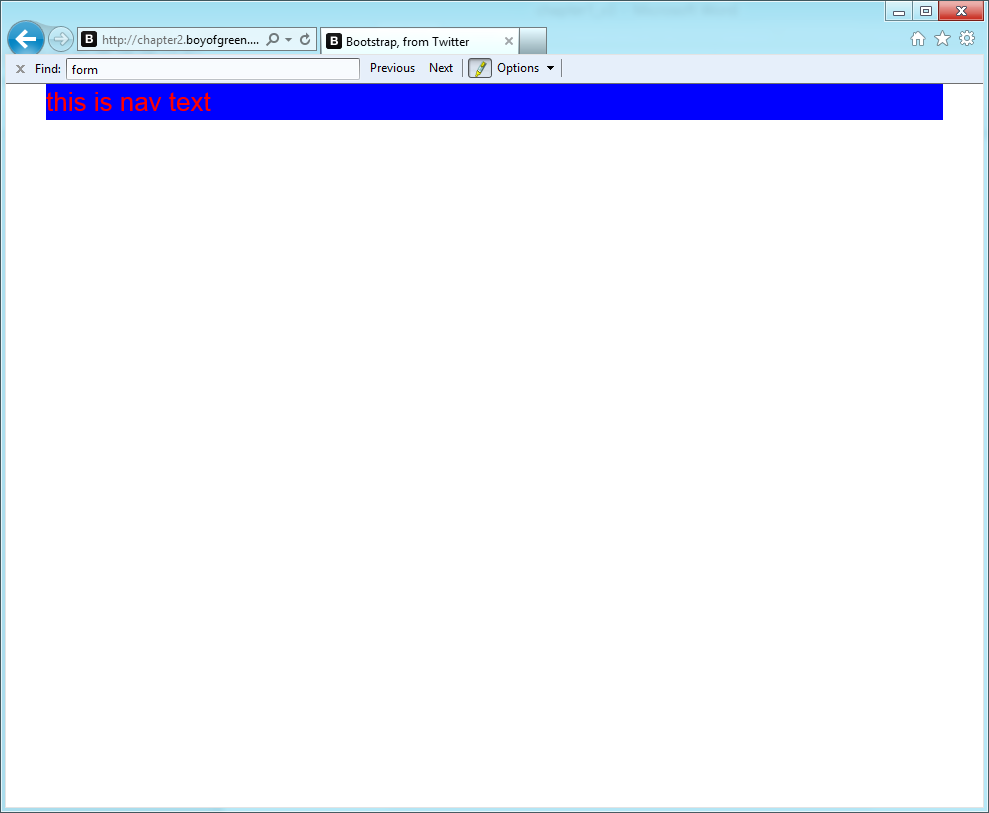
<!DOCTYPE html><html><head><metacharset="UTF-8"><title>My New Page with Nav</title><style>.nav{color:red}nav{display:block;background-color:blue}</style><script>document.createElement('nav');</script></head><body><div><navclass="nav"><p>this is nav text</p></nav></div></body></html>
Now our markup will pick up the blue background from the tag styles and the red text from the class name; the result will look something like Figure 1-2.
HTML5 has breathed new life into the <input> tag. Itâs time to get excited once
again about this âage-oldâ tag.
I have to admit that I was getting a little bored with the <input> tag. Before HTML5, any real
interaction had to be done outside the tag: whether the interaction
involved validation, formatting, or graphical presentation, JavaScript was
a necessary polyfill. Well, HTML5 has given us a reason to be excited
about the <input> tag
again.
The <input> tag is not
truly an HTML5 tag, per se. Itâs the same <input> tag we have had in every previous
version of HTML, but HTML5 has added a slew of new features. The good
thing about updating an existing tag is that itâs naturally
backward-compatible. You may code your tag like this:
<inputtype="date"/>
and non-HTML5 browsers will simply see this:
<input/>
In this hack weâll look at a few new, common features of this wonder of a tag.
There are a few basic (but powerful) new features in the HTML5
<input> tag that are accessible
on almost any input type. Weâll start by looking at some of the simple
attributes and then move on to some of the more complex ones.
First on the list is the placeholder text, which is a
string assigned to the placeholder
attribute that provides a hint for the input box. Placeholder text is
quite useful and quickly becoming commonplace. The text appears when the
input value is empty and disappears once the input receives focus. Then
it reappears when it loses focus (providing the input box is still
empty).
Another common attribute is autofocus, which, as you can guess by the
name, brings focus to an element
once the document is loaded. Simply set autofocus="autofocus" (or just add autofocus as an attribute) and this will be
the default focus element once the page is loaded (as opposed to
focusing on the first element of the page).
The required attribute
is another one of those patterns that has been accomplished through
JavaScript for years, but has finally made it into DOM functionality.
Simply add the attribute required="required" (or simply required) to your input and the DOM will not
submit the form while the requirements of that field are not satisfied.
Letâs look at a quick example:
<!DOCTYPE html><html><body><form>Add your telephone:<inputtype="tel"name="phone"required/><br/><inputtype="submit"/></form></body></html>
If you try hitting the Submit button without putting a value in the field, your browser will throw up a default message along the lines of âPlease fill out this field.â Itâs not perfect, but itâs a start.
The form attribute is a
feature that has been a long time coming. Have you ever wanted to have a
form on your page, but without constraining the form elements to one
section of your DOM? Maybe you are on a mobile device and you would like
your Submit button to pop up from the bottom of the screen instead of
residing in your form area. The form
attribute lets you create a form
element for a form, even when it is not a child node of the form. Simply
set the form attribute to the
id of the form (it canât be the form
name or another attribute, something the W3C needs to address). With
this attribute, the preceding example would look something like
this:
<!DOCTYPE html><html><body><formid="myForm">Add your telephone:<inputtype="tel"name="phone"required/><br/></form><inputtype="submit"form="myForm"/></body></html>
Now that weâve covered the basics of the <input> tag, letâs move on to some of
the tagâs more interesting features.
The Web definitely has a fascination with autocomplete. Since we
all hate to type, we love it when the form element knows what we want to type and
just does it for us. So HTML5 comes along and introduces autocomplete as
a simple attribute. You set autocomplete to on or off
(itâs on by default) and your work is
done! The code would look something like this:
<!DOCTYPE html><html><body><formid="myForm">Add your telephone:<inputtype="tel"name="phone"autocomplete="on"/><br/></form><inputtype="submit"form="myForm"/></body></html>
Now, what sucks about autocomplete is where it gets its data. To
explain this Iâll cite the boring old spec from the W3C:
The user agent may store the value entered by the user so that if the user returns to the page, the UA can prefill the form.[2]
So, the autocomplete value
comes from the user agent. But who is the user agent? Itâs not the page
developer, or JavaScript, or HTML: itâs the
browser. If I fill out a few forms and always enter
the string email@mail.com into the input field designated
for an email address, the browser remembers that and prefills it for me.
So itâs great for form elements such as email address and telephone
number, but itâs not incredibly useful for a developer. The key thing to
take away from this discussion is that you can turn off the autocomplete
feature when you need to.
Fortunately, all is not lost. HTML5 didnât forget about the other
use case. Itâs actually there in the spec as well, itâs just poorly
named and even more poorly supported. Itâs the list attribute; at the time of this writing,
the only browsers that support this attribute are Firefox 10 and Opera
10.
Think of the list attribute as
being a version of autocomplete for
developers. The list attribute is
tied to an id of a datalist (yes, once again this is not a name
or any other type of identifier, it has to be an id). It will look something like
this:
<!DOCTYPE html><html><body><formaction="demo_form.asp"autocomplete="on">First name:<inputtype="text"name="fname"/><br/>Last name:<inputtype="text"name="lname"/><br/>E-mail:<inputtype="email"name="email"/><br/>Favorite Animal:<inputtype="text"name="animal"list="animals"/><br/><datalistid="animals"><optionvalue="Dog"><optionvalue="Dolphin"><optionvalue="Duck"><optionvalue="Cat"><optionvalue="Bird"><optionvalue="mouse"></datalist><inputtype="submit"/></form></body></html>
The level of interaction is what you would expect from an
autocomplete feature: press the âDâ key on your keyboard and it should
offer you the options from the list of animals that start with
D (see Figure 1-3). Once again, donât
be surprised if your favorite HTML5 browser doesnât support this; it
will in time. Keep in mind that the datalist is not visible to the user; itâs
purely a reference.
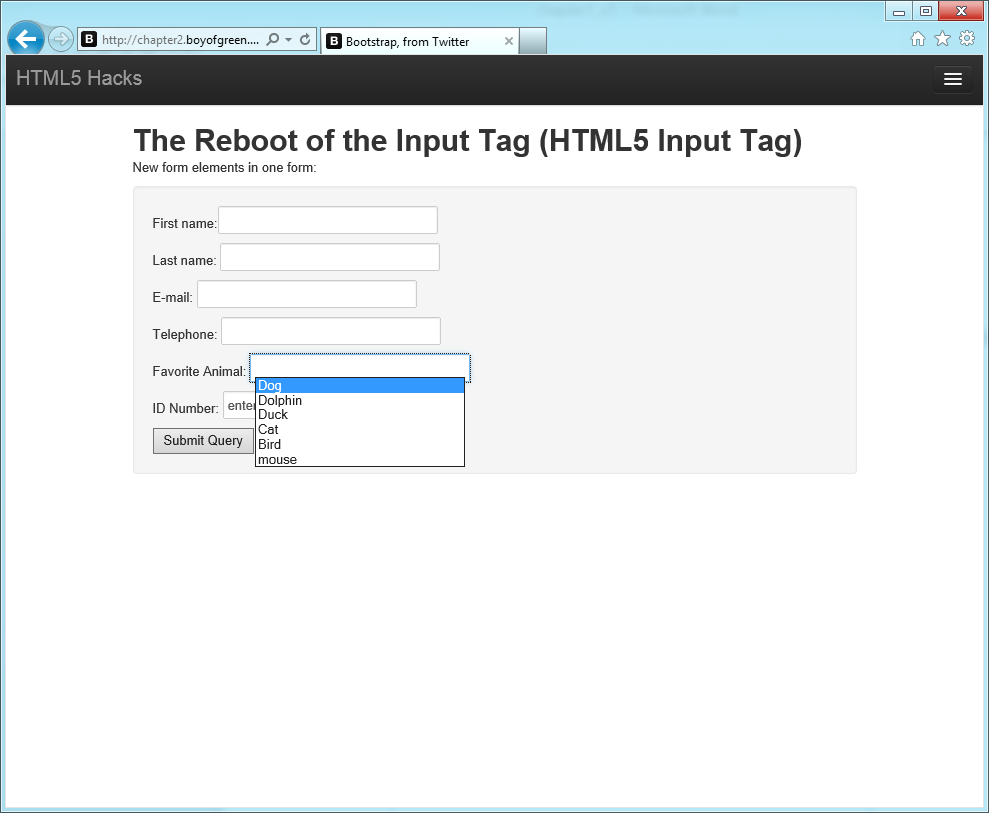
One of the bad things about both list and autocomplete is that you canât style them.
Iâll rant about that some more as we get into a few of the more
functional input types, such as date,
but I would expect to be able to style the results with CSS, just as I
do any form element.
How many times have you run a regex (or regular expression)
against the value of input to see if
it meets certain criteria? If youâre like me, youâve done this more
times than you can count. This was the inspiration for the pattern attribute in HTML5. According to the
W3C spec, the pattern should âcontrolâ the input value. As you would
expect, you utilize this value with the pattern attribute set to a JavaScript format
regular expression. Letâs take a look:
<!DOCTYPE html><html><body><formaction="demo_form.asp"autocomplete="on">First name:<inputtype="text"name="fname"/><br/>Last name:<inputtype="text"name="lname"/><br/>E-mail:<inputtype="email"name="email"/><br/>ID Number:<inputplaceholder="enter your 5 digit id number"type="text"name="idNumber"pattern="[0-9]{5}"/><br/><inputtype="submit"/></form></body></html>
If you donât meet the pattern criteria the form cannot be submitted, and instead you get a user agent message that says something like âPlease match the requested format.â One of the big problems with this implementation is its lack of adherence to modern web patterns.
Back in the day (2005 or so) we used to wait until a form was submitted to validate each input field, and if one or more of the fields didnât pass we would return an error message to the user. The W3Câs implementation is so HTML 4.01. In HTML5 I would have expected the validation to be on a specified keystroke or on a blur of the field.
Luckily HTML5 has a backup plan for some of these validation shortcomings. The next hack discusses form validation to see how to make it all work for you!
HTML5 includes powerful form validation that works seamlessly with the slew of new input types.
Form validation is fun again. Well, maybe not fun, but more fun than it ever was before. OK, letâs just admit it, form validation sucks. Itâs not fun, but it is necessary. In the past you would write a form and then run some very custom code to make sure all your inputs contained what they were supposed to contain. This was done in one of two ways: on the server or on the client. For server-side validation you would submit your form and run server-side code to make sure all your requirements were met, and if they werenât you would reload the page with an error or two on it telling the user where the problem was. Client-side validation worked in pretty much the same way, except you would run some JavaScript before the form was submitted to make sure all your conditions were met. For the record, the best kind of validation is when you do both. You should start with validation on the client to give the user an immediate response, and then revalidate on the server to make sure your response wasnât being hacked.
HTML5 isnât going to help you with server-side validation, but it sure will make it easier on the client. HTML5 once again takes a tried-and-true web standard and reinvents it as native browser functionality. Letâs dive in!
In HTML5 every input has the ability to have validation engaged,
and a form cannot be submitted if it doesnât validate. In order for the
form to validate, every input needs to have its validation criteria met.
Itâs pretty simple: every input has a method you can call to see if it
will meet a validation test. Letâs look at a form containing an input of type number:
<!DOCTYPE html><html><body><formname="myForm">Quantity (between 1 and 5):<inputtype="number"name="quantity"min="1"max="5"value="11"/><inputtype="submit"/></form></body></html>
Now letâs check it with JavaScript:
<script>if(document.myForm.quantity.checkValidity()===false){alert('fail');}</script>
When the value of quantity is
greater than 5 the alert will be
fired. Now letâs try something a little different. Instead of checking
the input itself, letâs just check the form. Here is the new
JavaScript:
<script>//myForm is the name of the form elementif(document.myForm.checkValidity()===false){alert('fail');}</script>
Notice that the validity state rolled up to the form. If any one
of the inputs within the form doesnât meet the criteria for validation,
the form rule will return false as
well. This is a key feature when you have long forms. For instance, if I
have a form with 25 input fields that need to be validated, I donât want
to have to go through the form with JavaScript and check each input
fieldâthis would require 25 different DOM hits. Instead, Iâd rather
check the form and have it determine whether all the necessary input
criteria are met on each of the 25 inputs.
So, we know how we can check to see if a form is valid or not, but how do we set the criteria we want to validate against? Well, there are really three ways to do this in HTML5.
First, we can simply add the required attribute to an input, and the input will return a true state for its validity value only if the element has a
value and the value matches the required input criteria. In the
following example, the input has to
be a number between one and five:
<inputtype="number"name="quantity"min="1"max="5"/>
The new pattern attribute is
pretty slick, especially for people who like to write regular
expressions. In this case you set a regular expression to the pattern attribute, and your input will
validate against that pattern in order to have the validity value return true:
<inputtype="text"name="quantity"pattern="[0-5]{1}"/>
Notice that the type was
changed to text in order for the
pattern to make the input invalid; we need to remove the number type, as that will supersede the
validation criteria. If the type and pattern conflict (by requiring
results that exclude each other), the validation criteria will never
be met, and the form will never validate.
Some input types have
comparative criteria such as email,
which require a strict input pattern. Other input types have attributes such as min and max that must be satisfied before the input
can be considered valid. Letâs look at our first input example
again:
<formname="myForm">Quantity (between 1 and 5):<inputtype="number"name="quantity"min="1"max="5"/><inputtype="submit"/></form>
In this case the number that is input must meet the min and max criteria in order to be considered
valid. For example, the number 11 would not validate but the number 4
would validate. In a similar manner we have the email type:
<formname="myForm">Enter Your Email:<inputtype="email"name="myEmail"/><inputtype="submit"/></form>
The email type looks for a
value that meets traditional email criteria that would match a regular
expression such as this:
var emailTest = /^[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}$/;If the value of the input doesnât have a username, an at sign (@), and a domain, itâs considered invalid.
Sometimes you may want to skip validation. A few HTML5 validations
allow you to do this. The first is the formnovalidate attribute. As you can guess, if
you apply this attribute to a button or an input whose type is submit, the validation does not stop the form
from submitting. This attribute can be placed as follows:
<formname="myForm">Quantity (between 1 and 5):<inputtype="number"name="quantity"min="1"max="5"/>Enter Your Email:<inputtype="email"name="myEmail"/><inputtype="submit"/><buttontype="submit"formnovalidate>save</button</form>
Note that the form is still invalid. If you call the checkValidity() method on this form, it will
still return false. In the case of
the formnovalidate attribute, you
simply ignore whether the form is valid or not when you submit.
The second way to escape validation is with the novalidate attribute. In a similar manner, the
novalidate attribute is added to the
form element itself, and every button
and input whose type is submit will skip the validation stem and
submit the form directly:
<formname="myForm"novalidate> Quantity (between 1 and 5):<inputtype="number"name="quantity"min="1"max="5"/>Enter Your Email:<inputtype="email"name="myEmail"/><inputtype="submit"/><buttontype="submit">save</button></form>
The HTML5 spec makes allowances for us to be more specific with
our validation errors. In the previous example form, the user must enter
a number between one and five to not receive an error. If we wanted to
update the error message to be a little more suitable, we would add a
custom message with the setCustomValidity() method:
<formname="myForm">Quantity(between1and5):<inputtype="number"name="quantity"min="1"max="5"oninput="updateMessage(this)"/>EnterYour:<inputtype="email"name="myEmail"formnovalidate/><inputtype="submit"/></form><script>myForm.quantity.setCustomValidity('looks like your numbers ... between oneand five')functionupdateMessage(input){if(input.value==""){}input.setCustomValidity('');}</script>
Our form will now give us an option for a friendlier, more helpful
user error. Notice that we had another method in the <script> tag and set it to the oninput of the input. When you use setCustomValidity() you automatically trigger
the other portion of your Constraint Validation API to return false when you call the checkValidity() method. In order to use a
custom method and still have the form be considered valid when the
criteria are met, you need to throw in some JavaScript to clear out the
setCustomValidity() method once the
validation criteria are met (in this case, once the form is not blank).
I still think the W3C has some room to make this even easier for web
developers in upcoming versions of the spec. This is functionality you
should be able to access without JavaScript.
Developers arenât the only ones using the Constraint Validation
API. The user agent uses the same API when it sets up the pseudoclasses
for its CSS. With CSS3 we can change visual cues based on the âstateâ of
a validation field. We have access to two pseudoclasses (more on this
later) to use for visualizing cues: :required, for elements that are marked as
required; and :invalid, for elements
that are marked as invalid. Unlike the form-level validation that occurs
when the page submits, the pseudoclasses are based on the current state.
This will give users strong visual cues. Letâs look at an example with a
contact form where the name is required, and the phone number and email
address are not required:
//ourcss<!DOCTYPEhtml><html><body><style>input{display:block;border:1pxsolid#ccc;}:invalid{border-color:#DB729C;-webkit-box-shadow:005pxrgba(27,0,97,.5);}:required{border-color:#1BE032;-webkit-box-shadow:005pxrgba(57,237,78,.5);}</style>//ourform<formname="myForm">EnterYourName:<inputtype="text"name="myName"required>EnterYourPhoneNumber:<inputtype="tel"name="myPhone"pattern="\d\d\d-\d\d\d-\d\d\d\d"/>EnterYour:<inputtype="email"name="myEmail"/><inputtype="submit"/></form>
Figure 1-4 shows our rendered view.
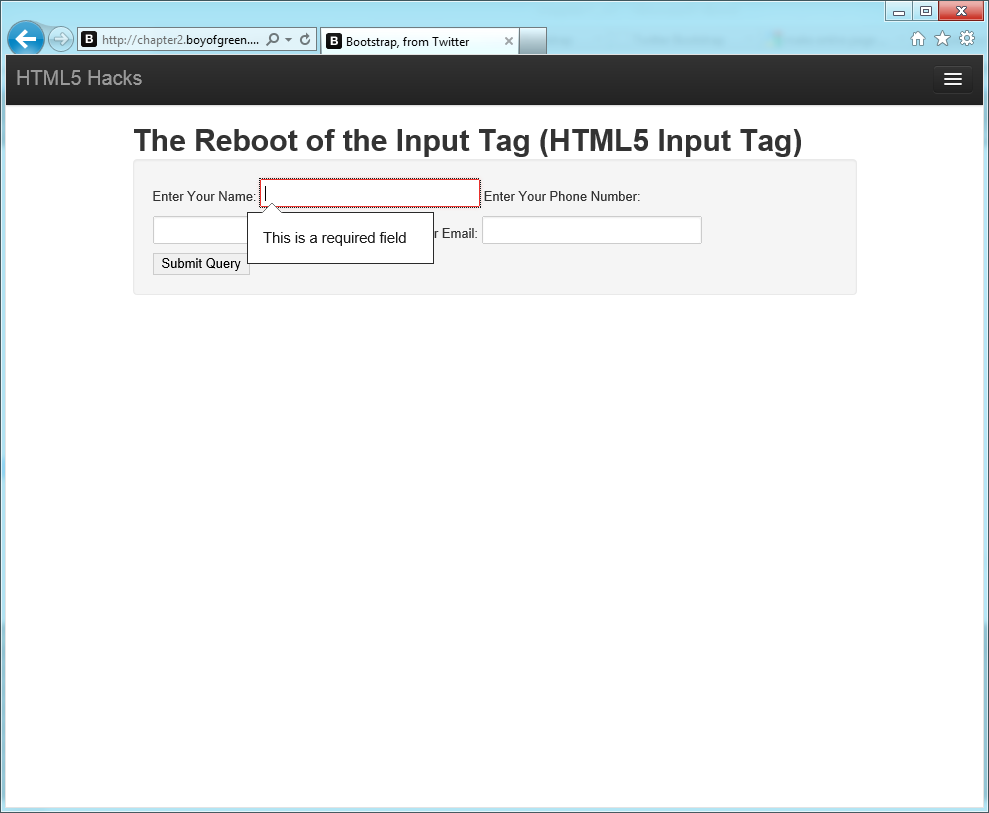
The CSS in the preceding code snippet adds a red border around the invalid field. The red border will remain until the proper content is entered.
We had to do this in two different ways due to browser support.
The easy way was the method we used for the email address. The input knows what a valid input address looks
like (i.e., the pattern of the address, not whether it works). So once a
valid string is set to the proper value, the field will no longer appear
with a red border.
The method we used for the telephone number was a little more
difficult. Most modern browsers âpartiallyâ support the tel input type for HTML5. One thing that isnât
supported is whether what is entered is indeed a valid telephone number.
I could easily type my name into that field and it would validate. Here,
we needed to go back to the pattern
attribute and use a regex to determine whether it was a phone number.
This particular regex isnât very useful, as it only checks to see if
there is a digit string that matches this pattern: xxx-xxx-xxxx. It
doesnât satisfy the use of brackets around an area code, nor does it
support any numbers in a format other than that used in the United
States. Weâd need a more robust regular expression for that.
It would appear that our form is complete and ready to throw onto
our website, but there are a few final details to point out. We assigned
a required state to the name, as we desired, but note that a partially
filled input will stop the form from
submitting as well (the form field is invalid but not required, but this
form must validate before it can be submitted). Adding novalidate to the form allows not only the
invalid inputs to submit, but also the required ones as well. There is
no clear solution for avoiding this, so letâs move forward and address
the issue with the user if it becomes a problem.
Before we try this form again, letâs go back and update the Enter Your Name field to display a more user-friendly error message:
<style>input{display:block;border:1pxsolid#ccc;}:invalid{border-color:#DB729C;-webkit-box-shadow:005pxrgba(27,0,97,.5);}:required{border-color:#1BE032;-webkit-box-shadow:005pxrgba(57,237,78,.5);}</style>//ourform<formname="myForm">EnterYourName:<inputtype="text"name="myName"placeholder="Enter Your Name"oninput="updateMessage(this)"required>EnterYourPhoneNumber:<inputtype="tel"name="myPhone"pattern="\d\d\d-\d\d\d-\d\d\d\d"/>EnterYour:<inputtype="email"name="myEmail"/><inputtype="submit"/></form><script>document.myForm.myName.setCustomValidity("To join our list..., please enterit here")functionupdateMessage(input){if(input.value==""){}input.setCustomValidity('');}</script>
There we have it. In the past, such validation would have required a good amount of custom JavaScript. Now it can be done with the simplicity of HTML5!
Your forms just got easier to use. HTML5 browsers include new
controls such as the date input type,
the <range> tag, and
others.
Weâve been talking about form elements for the past few hacks now, and they all have a common thread when it comes to reasoning. Many of these simple, easy-to-implement specifications actually replace standards that web developers have been coding to for years. This has made life easier for developers, made pages perform more quickly (browser code instead of JavaScript), and brought uniformity across web applications.
Letâs focus on uniformity for a bit. For example, letâs look at the
date input type. In the past, web
developers have developed a date picker standard similar to the one shown
in Figure 1-5, which is
from the popular YUI library.
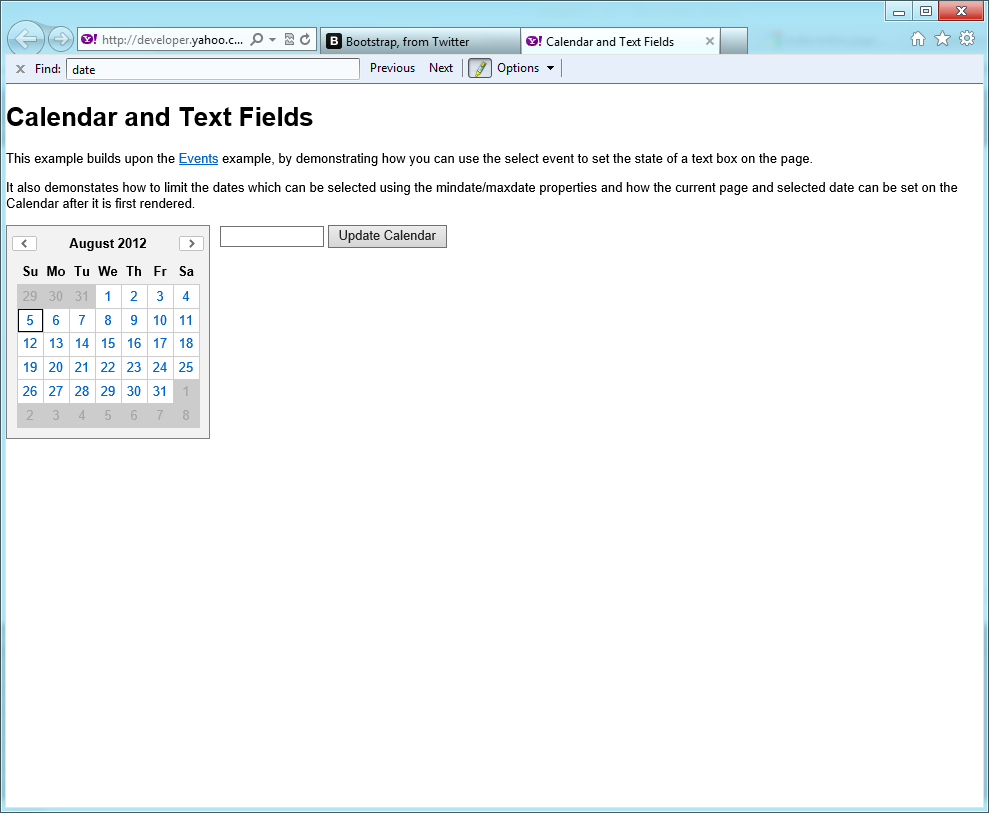
This is a huge improvement over having the user enter the date into an input field and hoping that it meets the required format. With the YUI date picker, we can stylize the component with CSS and make it look like it blends right in with our app. This has served our purposes for years. Whether we are using the Internet Explorer browser or the Firefox browser, our date picker will look the same and the user will always know what to expect.
Along comes mobile. Mobile browsers, for the most part, surf the same Web as our desktops. If you come across this same date picker on an iPhone, this previously great experience becomes difficult. Since the component has no awareness of the native content (it has a small screen in this scenario), it canât adapt to its context. Many keen JavaScript Ninjas have already started to think about how they can use the User Agent Declaration (part of the request) to customize this date picker for the context of each known user agent. This is a great idea, and many of our polyfill libraries, such as YUI, are a step ahead and provide concessions for small screens. Unfortunately, the only way to do this without HTML5 is to add more code. And more JavaScript, more markup, and more CSS equals page bloat and additional memory usage. Letâs use that extra code and memory for something spectacular and leave the basic input functionality to the browser. Each of the following form features takes something that used to be hard to do in JavaScript and makes it easy, light, and context-aware.
The date input type is one of
my favorites. As in the previous date picker example, a lot of work has
gone into creating a successful date selection tool. I canât tell you
how many times Iâve been frustrated with parts of the Web that use date
selection tools that are slow and buggy (yes, I mean you, airline and
car rental sites).
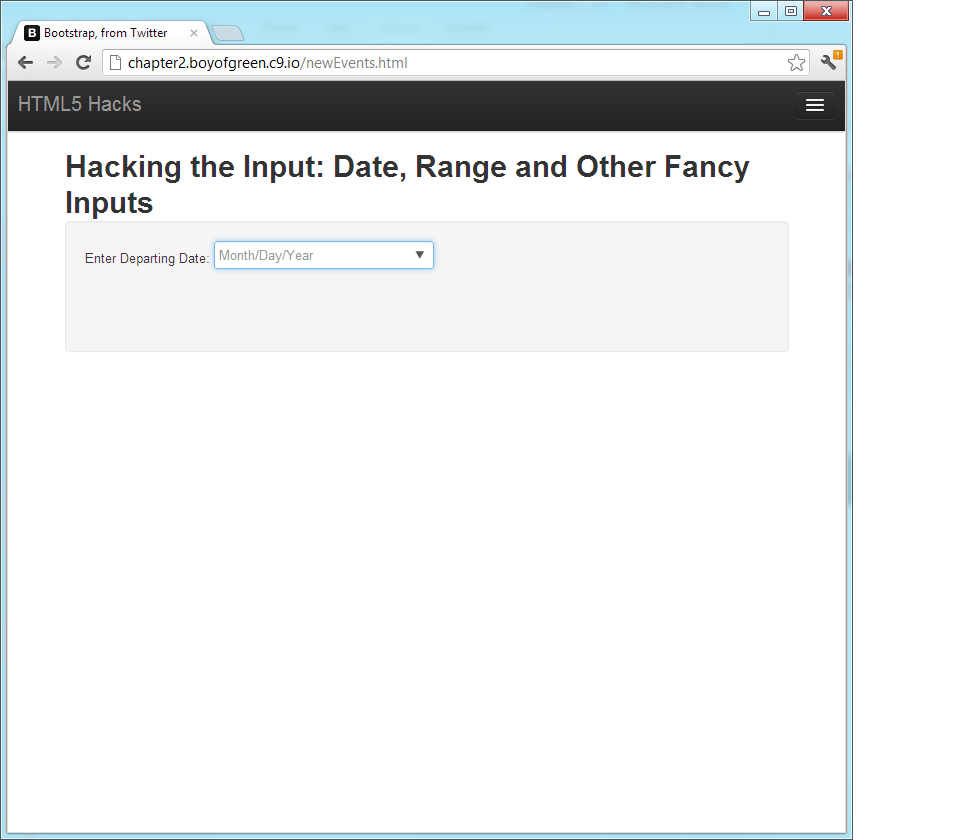
The HTML5 date input type is
fairly simple to implement. Out of the box it looks something like
this:
<formname="dateSelection">Enter Departing Date:<inputtype="date"name="departingDate"/></form>
The preceding code results in the simple pull-down box shown in Figure 1-6.
In terms of context, hereâs the great thing about the preceding example. As it stands, the date selector will be pretty tough to use on my iPhone; not only is it hard to see, but also my fingers are pretty fat and those tap zones are pretty small. So in iOS 5 and later, Apple has kindly implemented the date input field shown in Figure 1-7.
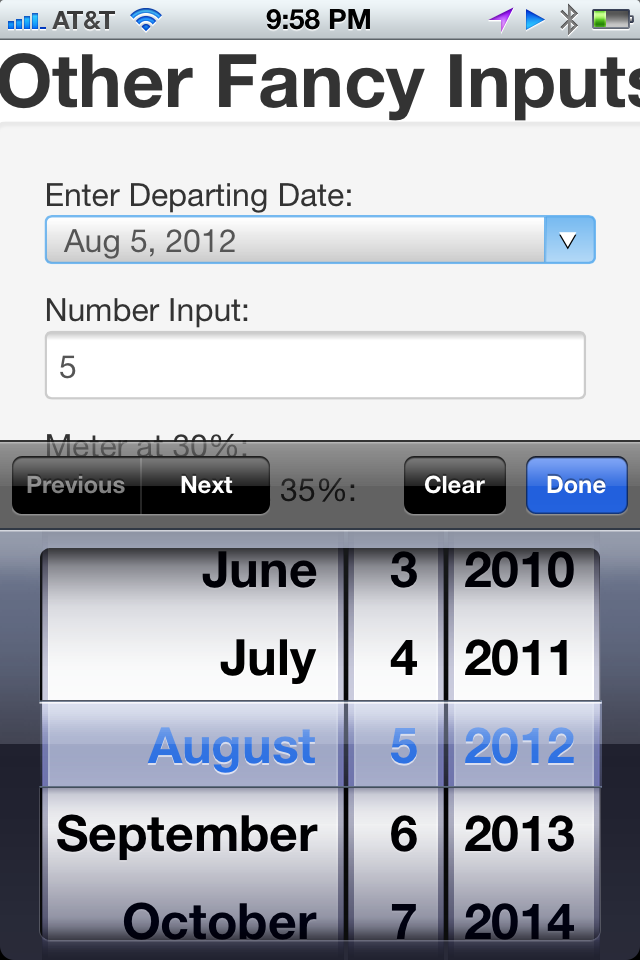
Nice job, Apple! Now letâs look at some of the other attributes we can add to give this application a functionality similar to those great little polyfill date pickers. Hereâs the code:
<formname="dateSelection">Enter Departing Date:<inputtype="date"min="2012-03-12"step="1"max="2012-05-12"name="departingDate"/><inputtype="submit"/></form>
Letâs look at some of these in more detail:
stepIncrement at which a date can be selected. The spec doesnât clarify all the increment types that a user agent must adhere to, but day, week, month, and year are obvious implementations.
minA date value that represents the minimum date the input will consider valid. Itâs not clear whether the controller will allow you to choose dates below the
mindate, or whether it limits selection to the valid date range. Implementations differ among browser makers at this point.maxA date value that represents the maximum date the input will consider valid.
As is the case with all changes that are powerful, a new set of DOM methods has been added as well:
stepUp()/stepDown()Can be called to increment the date that is input to either the next date or the preceding date in the series.
stepUp()calls the next day;stepDown()calls the preceding day.valueAsDate()Returns a JavaScript date object, not just a date string.
This might not sound exciting, but you can replace this polyfill:
<formname="myForm">Birthday:<inputtype="text"name="bday"value="03/12/2012"/><inputtype="submit"/></form><script>varmyInput=document.myForm.bday.value;varmyDate=newDate(myInput);</script>
with this:
<formname="myForm">Birthday:<inputtype="date"name="bday"value="2012-03-12"/><inputtype="submit"/></form><script>varmyInput=document.myForm.bday.valueAsDate();</script>
Itâs also interesting to note that there are a few variations on
the input type of date, and each
provides noteworthy interface challenges, especially on mobile and touch
devices. Here are some similar types to keep your eye on:
datetimemonthweektimedatetime-local
Once again, letâs look at one of our great polyfill libraries to get an idea of what the problem is. Figure 1-8 shows a screen capture of the YUI slider utility.
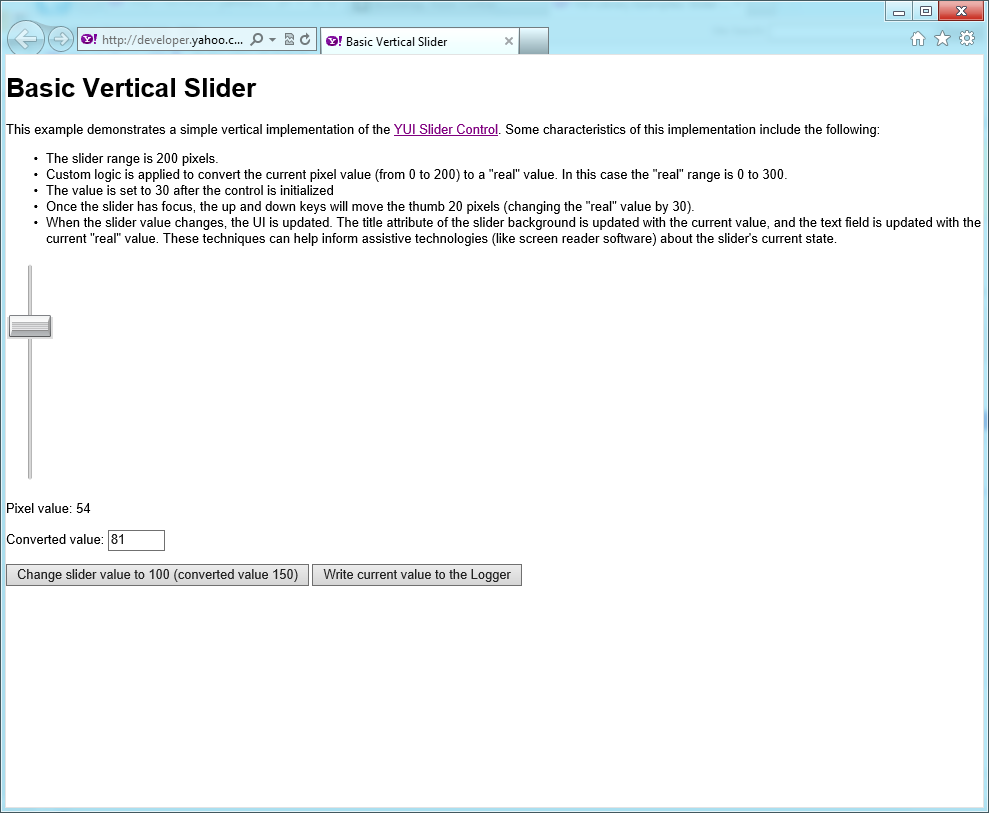
When youâre selecting ranges, nothing is worse than typing in values, especially when youâre âexploringâ what will happen when those ranges change. The slider has become a standard tool on both web and desktop devices. You generally have a bar representing something like numeric values or colors, and a handle that you drag from one end of the bar to the other. Again, letâs consider how difficult it may be to make selections on the YUI slider if youâre on a mobile device. The handle is small, and what feels like a short amount of movement on a mobile device could be a sizable amount to the slider.
The HTML5 type of range allows
browser makers to provide a range selection tool with an experience that
best fits the context of the device. The pattern for desktop browsers
appears to be a slider. Letâs jump into the implementation:
<formname="myForm">Shoe size:<inputtype="range"name="shoeSize"min="0"max="15"step=".5"value="3"/><inputtype="submit"/></form>
All that, with no JavaScriptâthis polyfill would be hundreds of kilobytesâ worth of code. Now letâs look at some of the attributes we added to the input:
min/maxOnce again we see the ability to set a
minand amaxfor the range. These are a bit more profound in therangeinput type because they define the first step (the bottom of the slider) and the top (the top of the slider). If nominandmaxare set, the user agent (again, the browser) will assume the range is 0 to 100.stepIn the preceding example we are selecting shoe sizes that come in half or whole sizes. Therefore, we set the
stepto.5so that whole or half sizes can be chosen. This can come in handy in very large ranges as well. Say you are applying for a loan and youâre using a range tool to choose your loan amount. For an improved user experience, you may want to round up to the nearest $10,000. Setting thestepto10,000will allow you to do just that.valueWeâve seen
valuehundreds of times when it comes to input: it allows us to set the initial value of that input. Itâs of particular interest on therangeinput type, because there is no ânullâ value. Since it is a slider, there is no point at which the value would be undefined, so the user agent will choose a reasonable default value for youâsomething in the middle of the range. In our example, we chose ourvalueto be3since the most popular shoe size in our little store is size 3. (Yes, we do cater to elves, leprechauns, and small children.) Thevalueallows you to choose the âdefaultâ value that makes the most sense, not just whatâs in the middle.
The HTML5 version of the sliders also has the added benefit of being able to match the other browser controls, as shown in Figure 1-9.
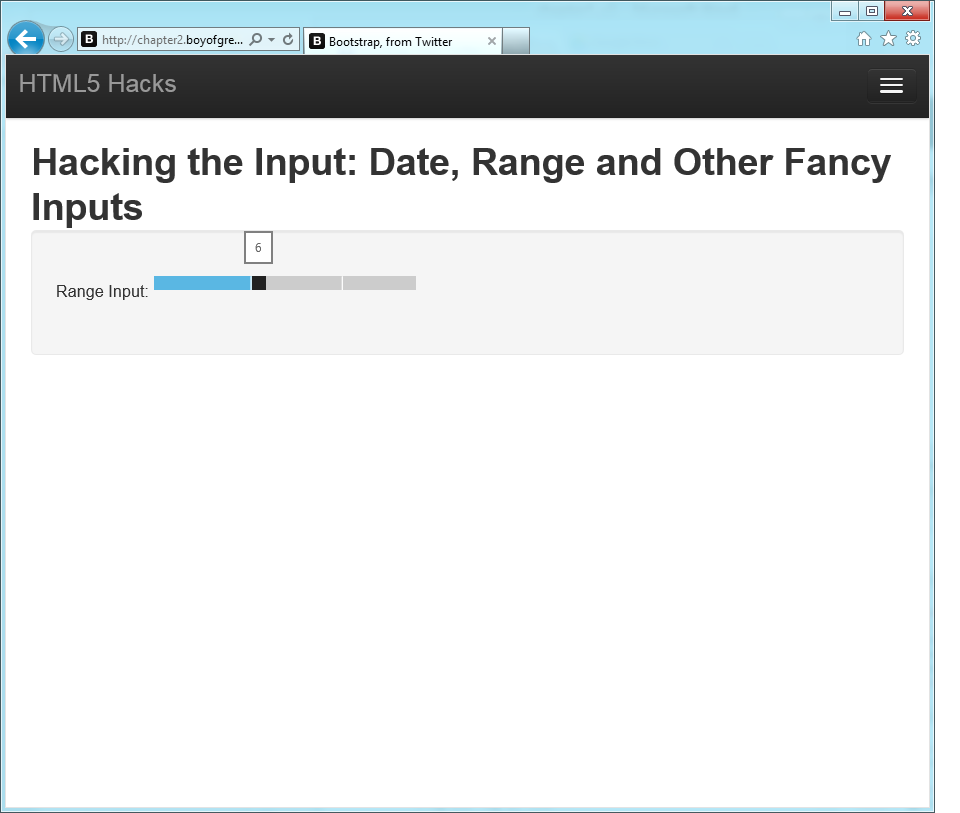
Figure 1-9. HTML5 range input type from Internet Explorer 10 that matches other form elements on the page
Itâs also interesting to note that the range tool can be tied to a
datalist (we discussed this briefly
in [Hack #4]). The datalist could include non-numeric values or
unequal numeric values that can be selected within the range. I havenât
seen any browser makers implement this yet, but it will be interesting
to see some possibilities.
You may not have thought of a color picker as being essential to a
userâs web experience, but as the Web becomes more of an application
environment, complex activities such as picking colors need to be
responsive and adaptive. The color
input type allows you to select a color value from within the
input.
Support for this input type is still nascent, and at the time of
this writing no user agent supports it. As with all of the other
unsupported input types, browsers that do not (or do not yet) support
the color input type will simply see
an input tag as it would appear for an input with the type equal to text.
Moving slightly out of the input space but staying within the
HTML5 form, we see two new form components that will quickly become
basic building blocks for web applications. The first of the two is the
<meter> tag. For a clear
definition, letâs go right to the spec:
The meter element represents a scalar measurement within a known range, or a fractional value; for example disk usage, the relevance of a query result, or the fraction of a voting population to have selected a particular candidate.
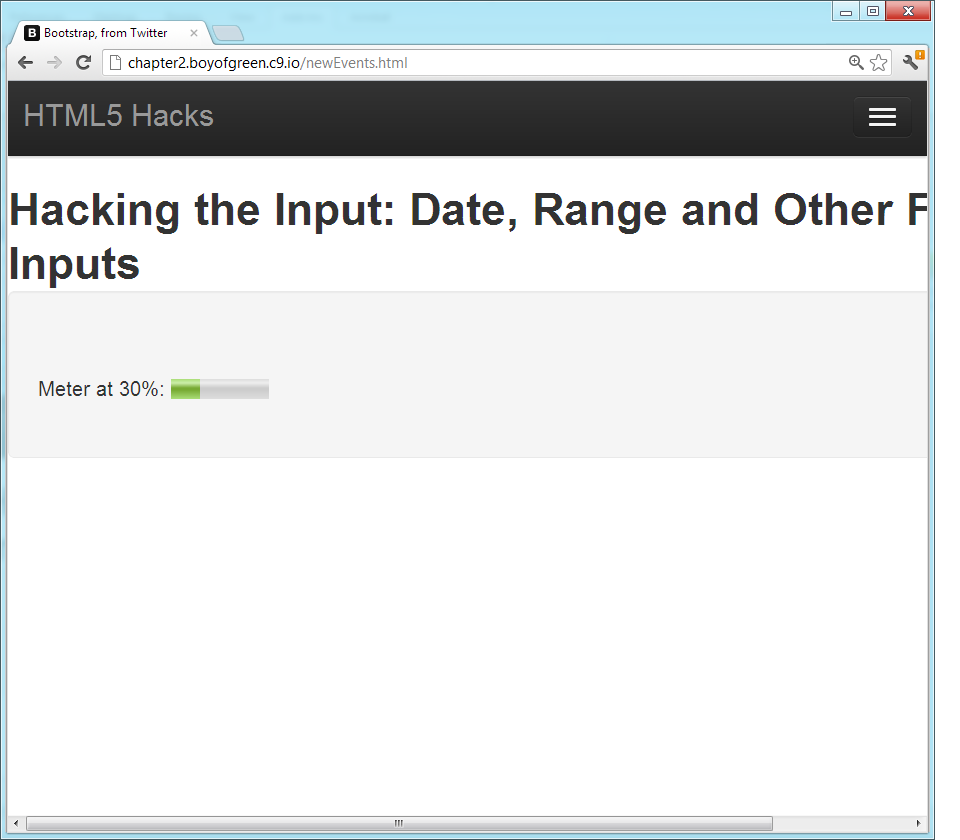
Think of a meter as a bar from a bar chart. Itâs a graphical representation of one number as part of a greater number. Letâs look at a code example:
<formname="myForm">30%:<metervalue="3"min="0"max="10"></meter><br/>30%:<metervalue="0.3"low="0.4">30%</meter></form>
The preceding code would result in something like Figure 1-10.
This particular form element has some interesting UI controls. You
can see from the preceding example that the meter needs to have a value
set, as well as a range, to be effective. The min and max
attributes will set the range (the meter is completely empty and the
meter is completely full, respectively), and the value will specify the current fill level. If
either of the attributes is missing, the form will assume the valueâfor
example, an undefined value will probably be considered zero by most
user agents.
Additionally, three other attributes can be added to the meter to
control the interface. The optimum
value would display a graphical representation of what the ideal value
would be. The low and high attributes are for setting thresholds
when your meter is below or above the optimal range. The interface
should respond accordingly; current browser implementations turn the
meter color to yellow for âlowâ and red for âhigh.â
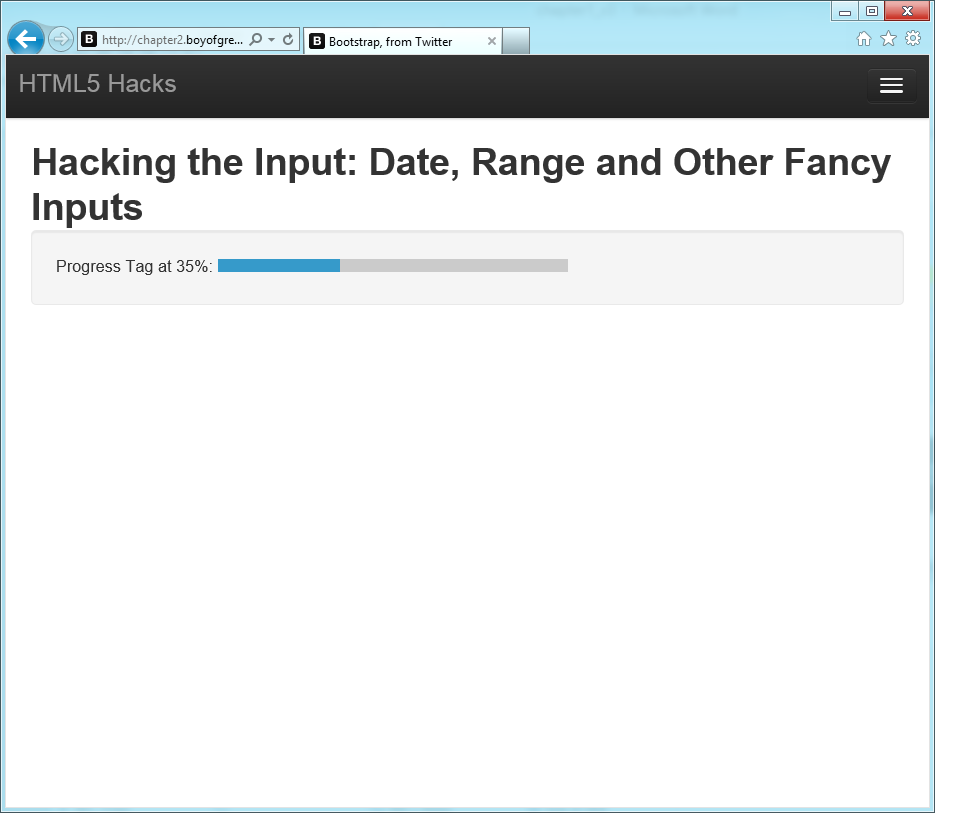
The <progress>
tag is also new for HTML5 forms. Think of the <progress> tag as the bar that pops up
when youâre downloading a file to tell you how much longer you have to
wait. It might look something like Figure 1-11.
The code implementation would be as follows:
<formname="myForm">Downloading progress:<progressvalue="35"max="100"></progress></form>
The <progress> tag has
only a few configuration attributes, and both are shown in the preceding
code. The first is the max attribute
that tells you what your progress âgoalâ is. The max value will be the top of your meter; the
bottom will always be zero. Your value will then specify the progress, and
thus, how much of the progress bar is filled.
Once again, these two new tags are examples of web standards that traditionally were implemented with JavaScript and CSS but can now be accomplished directly through HTML5. Each tag should look appropriate for the context of the application.
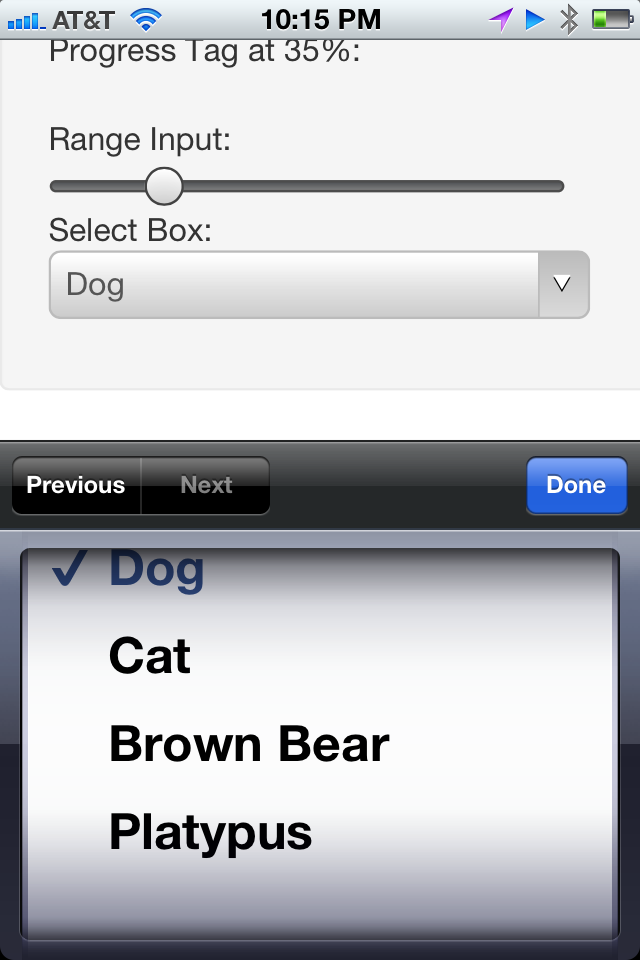
One thing all form elements have in common is that they look bad. Since I first started working with forms nearly 15 years ago, Iâve been trying to find ways to make them look better. A perfect example of this is the drop-down menu. Drop-downs look pretty simple. However, itâs difficult to do anything special with them, such as adding help text to the options or controlling the width of the menu while it has options with a lot of text in them.
HTML5 and CSS3 bring us some good news and some bad news. The good news is that we can use CSS to control a lot of the treatments weâve looked at in this hack. The bad news is that we canât control all of them. Letâs look at a few examples.
<formname="myForm"><inputtype="number"value="5"/><inputtype="submit"/></form>//css<style>input[type=number]::-webkit-inner-spin-button,input[type=number]::-webkit-outer-spin-button{-webkit-appearance:none;margin:0;}</style>
In the preceding example, we have a number input type with some funky spinner
buttons on it to increment and decrement the number. We
donât want the funky buttons, so
in CSS we specify (with browser prefixes) the subcomponents we want to alter. In this
case they are -webkit-inner-spin-button and -webkit-outer-spin-button. We are simply
hiding them in this example.
Browser makers are adding flexibility for many form controls.
Most browser makers allow you to alter the look of the validation
error pop-up windows as well. Some components, such as the date and color input types, may not have CSS
subcomponent controls.
Keep in mind that this control is both good and bad. Itâs good when you just donât like the experience presented by the user agent and you need to update the look and feel on your own. In contrast, itâs bad to makes changes to these elements because they then lack the ability to adapt to the context in which they are being used. Remember the drop-down menu I complained about earlier? Well, iOS has found a way to turn it into a brilliant user input on the iPad and iPhone. On the iPhone it becomes a spinner input at the bottom of the screen (see Figure 1-12). On the iPad it becomes a drop-down window in the context of the Select Box. In both cases, the input is well suited to its context. If you had CSS overrides on these components, who knows what the experience would be like for the end user on an iOS device.
HTML5 provides a slew of new events for you to latch on to. The world has moved beyond mouse clicks and keyboards. Now the Web has, too.
DOM events havenât changed much in the past 15 years. I think the
last new DOM event we got was the mouse scroll (thatâs what you call that
little spinner in the center of your mouse). Even touch events are not
officially supported DOM events, although they are much more prevalent
(and supported) than DOMMouseScroll.
With HTML5 we have tons of new input types to work with. As JavaScript is an event-driven language, it helps to work with a DOM that also natively fires events when actions take place. Some of these actions are directly related to a user interaction (such as the traditional DOM events), whereas others are related to events triggered by the user agent (such as going offline and coming back online). Letâs start with a look at some form events.
In the past we have relied on keydown and keyup events quite often to determine whatâs
going on within form elements. The bad thing about key events is that
they donât specifically apply to the input element itself, as
technically itâs the document, not the input, which is receiving the
keystrokes. This led us to trick the DOM, by temporarily adding key
events after an input receives focus and removing the key listeners once
the blur event of an input is fired. This has been terribly
inefficient.
With the oninput event, a
listener can be placed directly on an input tag (or bubbled up from one)
and be associated with the actions of that input only. Letâs look at a
traditional listener with an oninput
event instead of an onkeypress
event:
<inputid="myInput"type="text"placeholder="enter text"><script>document.getElementById('myInput').addEventListener('input',function(e){console.log("I just changed an input on:",e.target);},false);</script>
Once you begin typing in the input field, the log will be fired.
As you can see, the input event is attached to the myInput field, so input into any other input
field will not trigger this event.
Similarly, we have two additional events that can be attached to
the input field: onchange and
oninvalid. The onchange event fires once the value attribute is updated. You may not
immediately see the need for an onchange event, since we do have oninput and numerous other events that can be
triggered on an input change. But letâs think about some of the new
HTML5 elements, such as the input with type set to range. The range input or slider has no input
mechanism; it simply changes. When I drag the handle from one position
to another it doesnât fire an oninput
event, only an onchange event.
Similar events are required for other input mechanisms, such as date
pickers, number wheels, and color pickers. These new input types make
the onchange event not just handy,
but essential.
The oninvalid event is a
similar new event that is fired when a form element is deemed invalid.
Unlike many of our other validity checks, current implementations do not
work on the form element itself, but rather on the individual inputs.
Remember a few hacks back when I was complaining about how the form
elements werenât validated in real time (such as when you enter data
into the input rather than at form submit) and that only the CSS state
change was in real time? Letâs look at an example of how we can put some
of these events together to make the solution to my pet peeve a
reality!
In order to validate an input field while the user is entering
data into it, we need an event which fires as the user changes the value
of the input. In the past we would have to follow troublesome
keystrokes, but with the oninput
event we can easily attach a listener to the input in question, and
react to the change.
Once we catch that event we need to do some ad hoc validation
checking, so for this we will go back to the checkValidity() method (see [Hack #6]) to get the input
to self-validate. This can easily be fired from the oninput event. At this point, if the input is
deemed invalid the oninvalid event
will be fired alongside it.
The last thing we need to do is to attach an event listener to the
oninvalid event, and have it fire a
function that will indicate to the user that the value she entered is
invalid. Weâll follow this up with some CSS to reinforce the state of
the input.
Letâs take a look at the code:
<!DOCTYPEhtml><html><body><style>input[type=number]{border:2pxsolidgreen}input:invalid{border:2pxsolidred}</style><formname="myForm">Pickanumber,anynumberbetween1and5:<inputtype="number"name="quantity"min="1"max="5"/><br/><inputtype="submit"name="mySubmit"/></form><script>document.myForm.quantity.addEventListener('input',function(e){this.checkValidity()},false);document.myForm.quantity.addEventListener('invalid',function(e){alert('Your Number needs to be between 1 and five, you chose '+this.value+'.')},false);</script></body></html>
Endless fun, right? We now have the best of both worlds: built-in validation with real-time responsiveness.
While we are on the subject of events, HTML5 is proposing the adoption of a slew of new events similar to the ones mentioned in the preceding section. Most of these events focus on a user action, and they fire before, after, and during the event. Hereâs a list of events that had not been adopted at the time of this writing, but are likely forthcoming:
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | Â |
HTML5 formalizes the ability to store data directly in the page element. The data is simple to add, and just as simple to access.
Custom data attributes give us the ability to add more richness and
depth to our markup than weâve ever been able to before. Custom data
attributes, often called the data-*
attributes, are an easy way to add contextual data to HTML5 markup. Just
come up with an attribute name, prefix it with âdata-â, and add it to any
HTML markup tag:
<ulid="carInventory"><liclass="auto"data-make="toyota"data-bodytype="sedan"data-year="2005">Light blue Toyota Prism</li></ul>
In the preceding example, we have information we want to present to
the user that we include as text inside the tag. We also have contextual
information that our app will want to use to provide additional
functionality to the user. Before HTML5, this additional data would have
been stored in one of two ways. Either we would have hacked up another
attribute (such as the class attribute
or the id) with a string that encoded
all this information, or we would have kept a separate data source in
JavaScript that had a reference to this tag linked to it. Neither of these
options is very fun, and both require quite a few lines of JavaScript to
become useful.
Being able to place this data in the element itself not only is convenient for access purposes, but also provides rich context. According to the HTML5 spec from the W3C, a custom data attribute is defined as the following:
A custom data attribute is an attribute in no namespace whose name starts with the string âdata-â, has at least one character after the hyphen, is XML-compatible, and contains no characters in the range U+0041 to U+005A (LATIN CAPITAL LETTER A to LATIN CAPITAL LETTER Z).[3]
In summary, itâs an attribute that starts with âdata-â and is in all lowercase letters. Now, letâs be clear about the purpose of this data. Weâll start with how we donât want to use it (letâs get all that negative stuff out of the way!).
First, the data attribute shouldnât be used to replace an existing
HTML attribute such as class name id.
For example, if you want to add a unique identifier to an element of which
there will only be one on the page, just use the id, because that is exactly what it is designed for. Having a data-id on all your elements will probably get
you a healthy number of complaints from your friends and coworkers.
Second, donât use the data element to make your code more
âmachine-readable.â This is what microformatting is for, which we will
discuss in depth in a few hacks. Your custom data attribute is intended to
provide information that is relevant for your application, not for an
external page reader (whether it is human or machine).
Now, on to the fun part! How should you use custom data attributes? Simply put, you should use them for âanything you need,â with emphasis on the words anything and you. Anytime you need access to data about a DOM element or to data related to the information that element represents, store it in the custom data attribute.
In the following example we have a table that was built out dynamically in JavaScript from a database. The database has a local key that identifies each row of data, but that key only means something to our application; it doesnât have any value to the user. Before custom data attributes, we had to do something like this:
<tablewidth="100%"border="1"><tr><thclass="key">key row</th><th>Title</th><th>Price</th></tr><tr><tdclass="key">323</td><td>Google Hacks</td><td>FREE</td></tr><tr><tdclass="key">324</td><td>Ajax Hacks</td><td>FREE</td></tr><tr><tdclass="key">325</td><td>HTML5 Hacks</td><td>FREE</td></tr></table>
Then we had to use CSS to hide the first row (with a class name of
key):
.key{
display: none
}Another really bad solution involved using one of the existing
attributes to store this data. In the following example the data is stored
in the id attribute:
<tablewidth="100%"border="1"><tr><th>Title</th><th>Price</th></tr><trid="323"><td>Google Hacks</td><td>FREE</td></tr><trid="324"><td>Ajax Hacks</td><td>FREE</td></tr><trid="325"><td>HTML5 Hacks</td><td>FREE</td></tr></table>
There are so many problems with this solution that itâs hard to know
where to start. First, itâs a horrible idea to store data in the id attribute. The id attribute is meant to be a unique identifier
for HTML elements. Since itâs associated with our database key, the key
will change when the data changes, making it impossible to use that
id to reference the element, as itâs
subject to change. Storing the key as a class name is equally bad, for
similar reasons.
Now letâs turn it around and put that essential data into a custom data attribute:
<tablewidth="100%"border="1"><tr><th>Title</th><th>Price</th></tr><trdata-key="323"><td>Google Hacks</td><td>FREE</td></tr><trdata-key="324"><td>Ajax Hacks</td><td>FREE</td></tr><trdata-key="325"><td>HTML5 Hacks</td><td>FREE</td></tr></table>
Here we have simple markup that contains a reference to our database
key, without unnecessary markup or prostitution of the id or class
attribute. We didnât even have to write any CSS to make this work.
Another important piece of the puzzle concerns accessing the data.
The W3C HTML5 spec has a clear
method for collecting data in JavaScript. A dataset object is available on the HTML5
element that allows you to access your custom values by name:
<divid="myNode"data-myvalue="true">my node</div>//javascript access to value var nodeValue = document.getElementById('myNode').dataset.myvalue //nodeValue = 'true'
Notice that we donât need the âdata-â in front of our value; we
just call our value name directly. This access method is great and meets
the spec, but like many of our HTML5 features, it only works in HTML5
browsers. Interestingly enough, putting a custom data attribute of
sort onto an element has worked in
browsers for some time (it may not have validated, but it worked), all
the way back to IE 6. However, note that the JavaScript access method is
introduced with the HTML5 spec, but donât fretâwe have a hack for
that:
<divid="myNode"data-myvalue="true">mynode</div>//javascript access to value where nodeValue = 'true'varnodeValue=document.getElementById('myNode').getAttribute('data-myvalue')
Before, HTML5 browsers simply recognized the value as an attribute
of the element, so a simple getAttribute method of the element would
retrieve the data. Note that in this method, the âdata-â part of the
value is required to retrieve the data.
There is one more way to access this data, but it comes with a warning. Most current browsers support a CSS3 pseudoproperty (see Chapter 3 for more about pseudoclasses) on which you can base a style declaration. It looks something like this:
<divid='myNode'data-myvalue='true'>my node</div>/*css declaration */ #myNode[data-myvalue]{ color: red; }
or this:
#myNode[data-myvalue='true']{
color: red;
}Now your CSS can style the element based on the presence of the custom data attribute, or by the value of the custom data. Hereâs your warning: donât use custom data in place of CSS classes. Class names are still the definitive way to declare reusable style rules. Remember, custom data is not intended to represent something to the user, but rather to provide context data for your application, which means that, in general, you donât want to use the previously demonstrated pseudoclasses.
Tracking user events can be difficult on highly dynamic pages with JavaScript alone. It usually requires that you add and remove multiple listeners. With HTML5 custom data, you can have that same rich interaction on dynamic pages with a single listener.
One of the most difficult things about generating HTML markup with JavaScript is managing behaviors. Anyone who has worked with DOM events on a dynamic app knows that managing behaviors can be quite a hassle. This hack shows you a way to use custom data along with JavaScript event delegation to make an otherwise difficult task easy and lightweight.
Weâre not going to talk too much about event delegation; there are plenty of books and other resources out there that explain the details behind all of that. But it is important to know what event delegation is and why we do it.
Event delegation is the act of passing (or
bubbling, to use a more accurate term) the captured
event from an inner element to an outer element. Think about what happens
when you click a button that is inside a list element (li). Since the button is inside the li, technically you clicked on both elements, so
the browser by default passes or âbubblesâ that click up from the button
to the li. First the button executes
its onclick event, and then the
li executes its own onclick event. Event delegation is when you
allow your event (in this case, the click event) to bubble up to a parent
element (in this case, the li), which
then fires an event based on the fact that you clicked on the
button.
Generally, event delegation allows you to use fewer event listeners on a page, as any one listener can handle an endless number of functions based on the different elements being clicked. Using event delegation generally uses less memory in your page, and makes maintenance of dynamic pages much simpler.
In this hack we will add a tool tip to a list of elements using custom data and only one event listener.
Letâs start with our markup:
<divclass="container"><h1>Choose Your weapon</h1><p>Click on one of the selections below to find out more info about your character:</p><ulid="myList"><lidata-description="Most powerful goblin in entire kingdom">Ludo</li><lidata-description="Ruler over all goblins big and small">Jareth the Goblin King</li><lidata-description="Only person who can put a stop to the GoblinKing">Sarah</li><lidata-description="Unsung hero of the goblin kingdom">Hoggle</li></ul><pid="displayTarg"class="well"></p></div><!-- /container -->
Figure 1-13 shows the results.
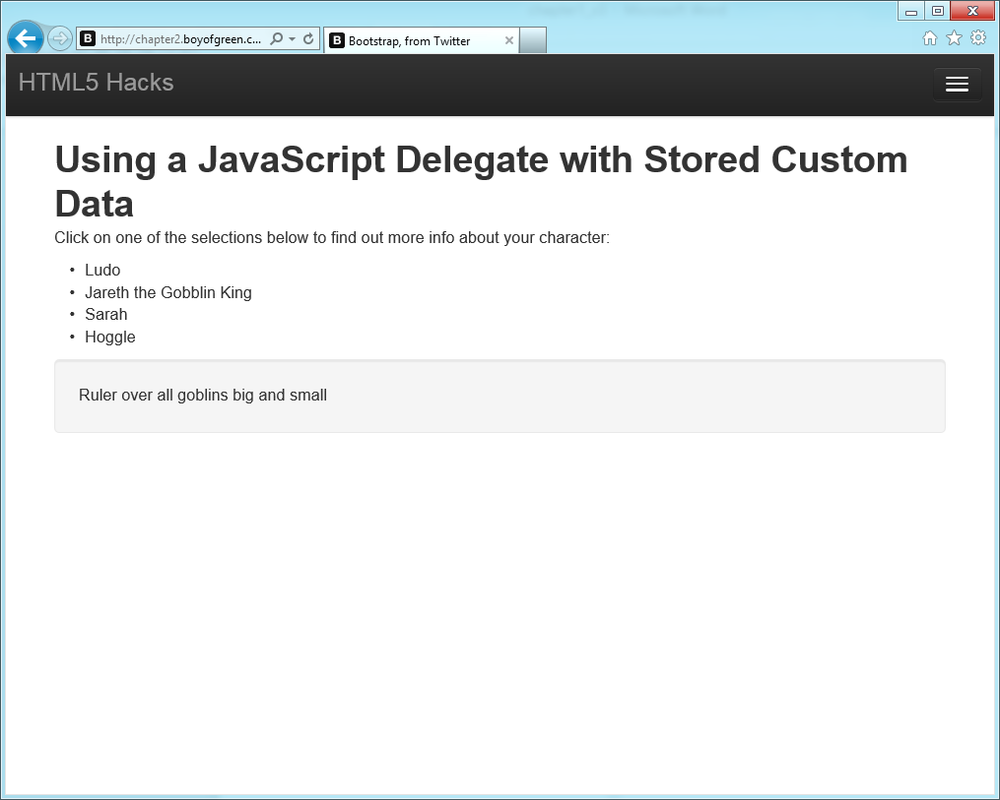
Custom data attributes allow us to âinlineâ data in our elements by
setting a string to the data- attribute
of the element. (For a more in-depth look at custom data, see [Hack #8].)
We are using an HTML5 page âprimerâ (the base page that we edit to
get a quick start on development) called twitter
bootstrap. It provides us with the clean look and feel for our
markup; some of our additional class names come from that framework. Now
letâs add our listener to the unordered list (ul) so that we can take action on any of the
items inside it:
varmainElement=document.getElementById('myList');vardescriptionTarget=document.getElementById('displayTarg');mainElement.addEventListener('click',function(e){vardescription=e.target.getAttribute('data-description');//remember we use getAttribute instead of//dataset.description due to its backwards compatibilitydescriptionTarget.innerHTML=description;});
JavaScript event delegation is so much more powerful when you have access to additional data within the DOM element itself. Now imagine that this data was pulled from a database or JSON (JavaScript Object Notation) object and updated in the DOM. The list and markup can be updated, but the JavaScript does not need to change. The same listener can handle this list of four characters or a list of 400 characters, no matter how many times the list changes.
As markup gets more complex and we start to see elements nested
inside other elements, finding the right target element to pull our description from
can get pretty complicated. We are lucky to have many fine frameworks on
the market that make event delegation easy to manage. Instead of
managing the event target (e.target
in the previous code) to get ahold of the right element, these
frameworks allow us to write a few lines of code to make sure weâre
working with the right elements. Letâs look at a few examples just to
see how easy it is:
Embrace JavaScript event delegation, and make your markup more powerful with custom data attributes. Youâll find yourself writing less code, taking up less memory, and living an overall happier life!
HTML5 microdata provides the mechanism for easily allowing machines to consume the data on your pages, while not affecting the experience for the user.
If youâre like me, you believe that in the future, machines will rule over us humans with an iron fist (provided, of course, that the Zombie Apocalypse doesnât get us first). While there isnât anything we can do to help the zombie masses understand the Internet, HTML5 does offer a feature that prepares us for that machine dictatorship. Itâs called microdata, and itâs supposed to be for machines onlyâno humans allowed.
You can tell by now that HTML5 adds a lot of depth to your data, but up to this point the focus has been on your users. Microdata takes you down a slightly different path when you think about consumers who arenât your users. Microdata is additional context you add to your markup to make it more consumable. When you build your page, you can add these additional attributes to give further context to your markup.
Microdata can be added to any page element to identify that element
as an âitemâ or a high-level chunk of data. The content nested inside that
item can then be labeled as properties. These properties essentially
become nameâvalue pairs when the itemprop becomes the value name and the
human-readable content becomes the value. The relevant code would look
something like this:
<divitemscope><spanitemprop="name">Fred</span></div>
Sometimes item property data isnât in the format that a âmachineâ would like, and additional attributes need to be added to clarify what the human-readable data is saying. In that scenario your data would look like this:
<divitemscope>Hello, my name is<spanitemprop="name">Fred</span>. I was born on<timeitemprop="birthday"datetime="1975-09-29">Sept. 29, 1975</time>.</div>
Now imagine how consumable the Web would be for those machines of the future once microdata is utilized on every page!
In this hack weâll use microdata to make sure our contact list is machine-readable. Each contact entry will be identified as an item, and its contents will be labeled as a property. Our first contact will look like this:
<liitemscope><ul><li>Name:<spanitemprop="name">Fred</span></li><li>Phone:<spanitemprop="telephone">210-555-5555</span></li><li>Email:<spanitemprop="email">thebuffalo@rockandstone.com</span></li></ul></li>
As you can see, we have constructed one data item on our page, and when the markup is machine-read it will see the item as something like this:
Item:{name:'Fred',telephone:'210-555-5555',:'thebuffalo@rockandstone.com'}
Now letâs build ourselves a whole list:
<ul><liitemscope><ul><li>Name:<spanitemprop="name">Fred</span></li><li>Phone:<spanitemprop="telephone">210-555-5555</span></li><li>Email:<spanitemprop="email">thebuffalo@rockandstone.com</span></li></ul></li><liitemscope><ul><li>Name:<spanitemprop="name">Wilma</span></li><li>Phone:<spanitemprop="telephone">210-555-7777</span></li><li>Email:<spanitemprop="email">thewife@rockandstone.com</span></li></ul></li><liitemscope><ul><li>Name:<spanitemprop="name">Betty</span></li><li>Phone:<spanitemprop="telephone">210-555-8888</span></li><li>Email:<spanitemprop="email">theneighbour@rockandstone.com</span></li></ul></li><liitemscope><ul><li>Name:<spanitemprop="name">Barny</span></li><li>Phone:<spanitemprop="telephone">210-555-0000</span></li><li>Email:<spanitemprop="email">thebestfriend@rockandstone.com</span></li></ul></li></ul>
To our human friends, the page looks something like Figure 1-14.
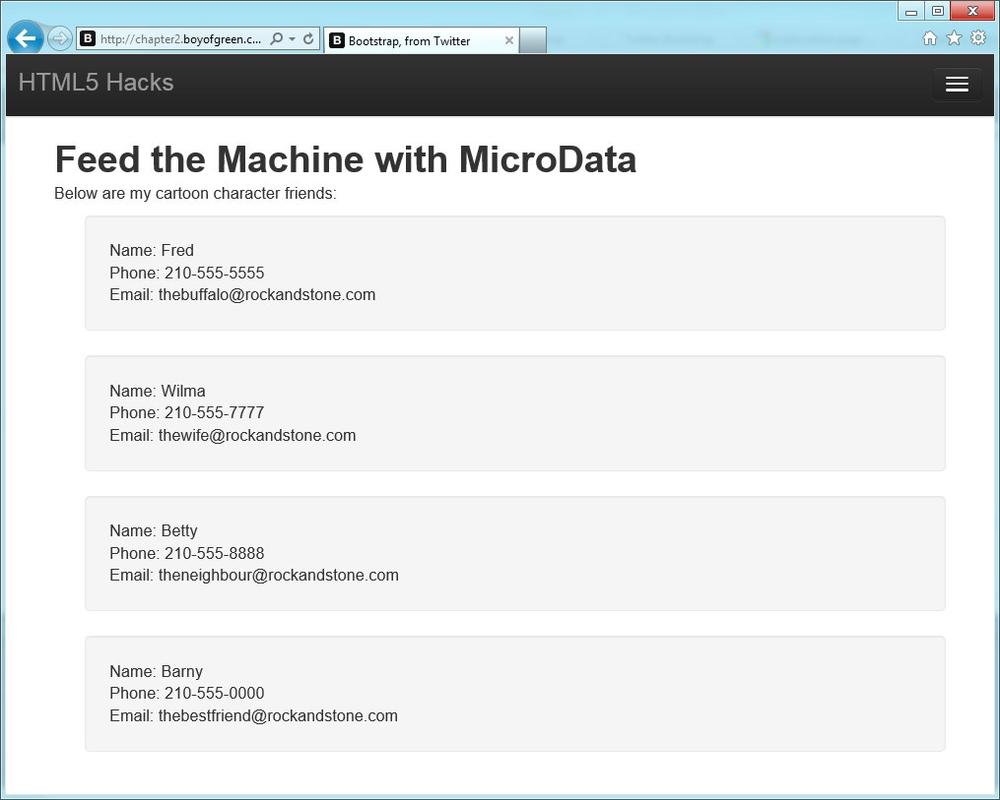
To our machine friends, the code looks something like this:
Item:{name:'Fred',telephone:'210-555-5555',:'thebuffalo@rockandstone.com'},Item:{name:'Wilma',telephone:'210-555-7777',:'thewife@rockandstone.com'},Item:{name:'Betty',telephone:'210-555-8888',:'theneighbor@rockandstone.com'},Item:{name:'Barny,telephone: '210-555-0000',email: 'thebestfriend@rockandstone.com'}
Itâs that easy to add microdata to your page without sacrificing the interface for your human friends.
Microdata is pretty darn easy to implement, and the W3C spec
thinks it should be just as easy to read, which is why the W3C added a
JavaScript API to be able to access the data. Remember, each of your
identified elements was marked with an attribute called itemscope, which means the API considers them
items. To get all these items, you simply call the following:
document.getItems();
Now your items can also be segmented by type, so you can identify
some of your items as people, and others as cats. Microdata allows you
to define your items by adding the itemtype attribute, which will point to a URL,
or have an inline definition. In this case, if we defined our cat type
by referring to the URL http://example.com/feline,
our cat markup would look
something like this:
<liitemscopeitemtype="http://example.com/feline"><ul><li>Name:<spanitemprop="name">Dino</span></li><li>Phone:<spanitemprop="telephone">210-555-4444</span></li><li>Email:<spanitemprop="email">thecat@rockandstone.com</span></li></ul></li>
And if we wanted to get items with only a specific type of cat, we would call:
document.getItems("http://example.com/feline")Thanks to this simple API, your microdata-enriched markup is both easy to produce and easy to consume.
Get HTML5 Hacks now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

