Chapter 7. MapReduce Integration
One of the great features of HBase is its tight integration with Hadoop’s MapReduce framework. Here you will see how this can be leveraged and how unique traits of HBase can be used advantageously in the process.
Framework
Before going into the application of HBase with MapReduce, we will first have a look at the building blocks.
MapReduce Introduction
MapReduce as a process was designed to solve the problem of processing in excess of terabytes of data in a scalable way. There should be a way to build such a system that increases in performance linearly with the number of physical machines added. That is what MapReduce strives to do. It follows a divide-and-conquer approach by splitting the data located on a distributed filesystem so that the servers (or rather CPUs, or more modern “cores”) available can access these chunks of data and process them as fast as they can. The problem with this approach is that you will have to consolidate the data at the end. Again, MapReduce has this built right into it. Figure 7-1 gives a high-level overview of the process.
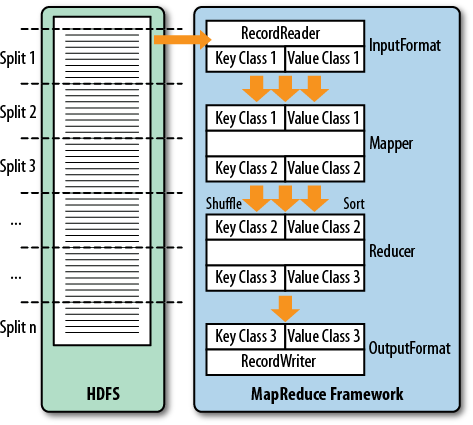
This (rather simplified) figure of the MapReduce process shows you how the data is processed. The first thing that happens is the split, which is responsible for dividing the input data into reasonably sized chunks that are then processed by one server at a time. This ...
Get HBase: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

