Chapter 7. Merging
Merging is the process of combining the recent changes from several branches into a single new commit that is on all those branches. Most often there are only two branches involved, but in fact, there can be any number; if there are more than two, it is called an âoctopus merge.â When there are only two branches, the current branch is called âourâ side of the merge, while the other branch is called âtheirâ side. Since the octopus merge is unusual, we will generally assume a two-branch merge in this discussion.
We described how Git may start a merge for you as part of git pull (see Pulling), but you can also perform merges explicitly. Hereâs a typical scenario: youâre working on a software project, and you have an idea for a new feature, but you donât want your experimental work on that feature to disturb your main development. So you create a branch named feature to contain the work:
$ git checkout -b feature Switched to a new branch 'feature' (explore brilliant idea...)
When you need to go back to work on the main part of your project, you commit your work on the feature branch and switch back to master (or whichever branch you need to work on):
$ git commit -am "must save brilliant thoughts" [feature c6dbf36e] 0 files changed create mode 100644 effulgent.c create mode 100644 epiphany.h $ git checkout master Switched to branch 'master' (perform mundane chores...)
You continue like this for some time. Eventually, if you decide you donât like your feature idea, you can discard the work by deleting the branch with git branch -D feature. If you decide to keep it, however, at some point youâll want to incorporate it into the main project code, and you do this with a merge:
$ git checkout master Switched to branch 'master' $ git merge feature Auto-merging main.c Merge made by the 'recursive' strategy. effulgent.c | 452 ++++++++++++++++++++++++ epiphany.h | 45 ++++++++++ main.c | 18 ++-- 3 files changed, 507 insertions(+), 9 deletion(-) create mode 100644 effulgent.c create mode 100644 epiphany.h
Warning
Itâs best to have all your work committed before running git merge; that is, git status should show no outstanding changes or untracked files. Backing out of a merge to your initial state may prove difficult otherwise. You can use git stash as a quick way to save working changes and restore them later (see git stash).
This merge was simple. You had added the files effulgent.c and epiphany.h on the feature branch, and they did not exist on master, so Git just added them. You had made minor changes to main.c on both branches, but those changes did not conflict, so Git combined them automatically and committed its merged version. The ASCII graph with filenames on the left is called a âdiffstatâ; it is a summary of the changes made by this commit. The lines of plus and minus signs represent the relative number of line additions (âinsertionsâ) and deletions made in the corresponding file.
Both aspects of merging have occurred here: content and structure. First, Git combined the content of both branches by adding and merging changes to files; then, it recorded the fact of the merge structurally by creating a merge commit tying both branches together in the commit graph. This indicates in the history those commits whose contents were combined to produce the new one, by making them its parents. A âmerge commitâ is defined simply as a commit having more than one parent.
You can continue this process as long as you like, working on the feature branch separately and periodically merging its work into master. If you do, you will probably also need to merge the other way as well, updating the feature branch with the latest work on master, so that youâre not working on outdated code; for this, just do the reverse: switch to feature and run git merge master.
When your new feature is fully incorporated into the main development, and you no longer need to work on it separately, you can delete the feature branch with git branch -d feature; as discussed in Deleting a Branch, Git will complain if you havenât fully merged feature into master, to prevent you from accidentally losing work. Deleting feature doesnât delete any of its content or history; it just removes the name âfeatureâ as a reference point, a place at which you intend to add independent commits later onâsince you no longer need it. You can reuse âfeatureâ as a branch name in the future if you want, and there will be no collision with the earlier usage; in fact, aside from possibly in commit messages or reflogs, once you delete a branch, there is no record in the repository proper that it ever existed! Branch names serve to indicate what parts of the object database are still of interest, and where development is still occurring; if a branchâs content is merged into other branches, and you no longer need a line of development with that name, then you can just delete it, and reuse the name later for something else if you like. Similarly, looking back in the commit graph, it is not possible to know on which branch name a particular commit was made; even in a linear history, the current branch name might have been changed at some point in the past. It might be interesting or useful to know this in some situations, but Git just doesnât keep this information. Git branches are ephemeral in a sense, just tools for building the commit graph, which is what matters.
Merge Conflicts
The previous merge went smoothly, but what if you had made changes in the two branches that Git could not combine on its own? These are called âmerge conflicts,â and Git would stop and ask you to resolve them before committing. This process can range from simple to very complex, depending on the content and changes involved; fortunately, there are tools available to help, both in Git itself and with which Git can work. Letâs walk through a simple example. Suppose you have a file moebius with the following contents:
hello doctor name continue yesterday tomorrow
and you make commits on branches chandra and floyd changing it thus:
| chandra | floyd |
|
|
|
|
|
|
|
|
|
|
|
|
You have changed the same two lines on each side in different ways, and Gitâs line-oriented merge approach will not attempt to guess at your intent or combine the lines (e.g., form a single line dolphin monoliths, interesting as those might be); it will signal a merge conflict:
$ git checkout chandra Switched to branch 'chandra' $ git merge floyd Auto-merging moebius CONFLICT (content): Merge conflict in moebius Automatic merge failed; fix conflicts and then commit the result.
The phrase CONFLICT (content) indicates that the conflict is due to irreconcilable content changes in this file. Git might indicate other reasons as well, such as an add/add conflict, in which the same filename is added to both branches but with different contents.
Tip
If you start a merge and then want to cancel itâperhaps you werenât expecting so many conflicts and you donât have time to deal with them nowâjust use git merge --abort.
To get an overview of the merge state, use git status. Any changes Git resolved on its own will be shown as already staged for commit, and there is a separate section at the end for merge conflicts:
$ git status
...
# Unmerged paths:
# (use "git add <file>..." to mark resolution)
#
# both modified: moebiusâUnmerged pathsâ are files with conflicts Git could not resolve. To find out what went wrong in detail, use git diff. This command not only shows the differences between various combinations of working tree, index, and commits; it also has a special mode for helping with merge conflicts:
$ git diff
diff --cc moebius
index 1fcbe134,08dbe186..00000000
--- a/moebius
+++ b/moebius
@@@ -1,6 -1,6 +1,11 @@@
hello
doctor
++<<<<<<< ours
+Jupiter
+dolphin
++=======
+ Europa
+ monoliths
++>>>>>>> theirs
yesterday
tomorrowThis display shows the alternative versions of the section in conflict, separated by ======= and marked with the corresponding branch: ours (the current branch) and theirs (in this case floyd, the branch we are merging into ours). As usual, git diff shows differences between the working tree and the index, which in this case are the conflicts yet to be resolved; changes already made and staged are not shown. You can use git diff --staged to see those; add --stat for an overview. Youâll find that Git has updated the working file with similar markup:
hello doctor <<<<<<< ours Jupiter dolphin ======= Europa monoliths >>>>>>> theirs yesterday tomorrow
Once youâve edited the file to resolve the conflict, use git add to stage your fixed version for commit and remove it from the list of conflicted paths (if the resolution is actually to delete the file, use git rm). Once youâve addressed all the conflicts and git status no longer reports any unmerged paths, you can use git commit to complete the merge. Git will present a commit message containing details about this merge including its branches and conflicts, which you can edit as you see fit; in this case:
Merge branch 'floyd' into chandra
Conflicts:
moebiusand you can see youâve created a âmerge commitâ having more than one parent:
$ git log --graph --oneline --decorate
* aeba9d85 (HEAD, chandra) Merge branch 'floyd' inâ¦
|\
| * a5374035 (floyd) back in black
* | e355785d thanks for all the fish!
|/
* 50769fc9 star child
The other branch, floyd, has stayed where it was, while the current branch, chandra, has advanced one commit from e355785d to aeba9d85, and that last commit unifies the two branches. A new commit on floyd will cause them to diverge again, and you can merge again in the future if you need to (in either direction). Note that at this point, a simple git log will show commits from both branches, not just those made while on chandra:
$ git log --oneline --decorate
aeba9d85 (HEAD, chandra) Merge branch 'floyd' into châ¦
a5374035 (floyd) back in black
e355785d thanks for all the fish!
50769fc9 star child
You might have expected to see only commits aeba9d85, e355785d, and 50769fc9. This presentation may seem odd at first, but itâs just a different way of looking at the notion of âbranch.â A Git branch is defined as the set of all commits reachable in the commit graph from the branch tip; think of it as all commits that contributed content to the tip commit (which, after a merge, includes all commits prior to that one on both branches).
Tip
In simple cases, you may get what you think of as the history of âthis branchâ with git log --first-parent, which just follows the first parent of merge commits rather than all of them. However, this isnât guaranteed, and in more complex histories it wonât mean much. Since Git allows nonlinear history, a simple list of commits is often not very useful, and you need visualization tools to help you interpret it (see Visual Tools).
Resolving Merge Conflicts
Git doesnât have built-in tools to interactively address merge conflicts directly; thatâs what external merge tools are for, which weâll consider shortly in Merge Tools. However, here are some tips for use in simple cases.
-
git log -p --mergeshows all commits containing changes relevant to any unmerged files, on either branch, together with their diffs. This can help you identify the changes in the history that led to the conflicts. -
If you want to discard all the changes from one side of the merge, use
git checkout --{ours,theirs}to update the working file with the copy from the current or other branch, followed byfilegit addto stage the change and mark the conflict as resolved.file -
Having done that, if you would like to apply some of the changes from the opposite side, use
git checkout -p. This starts an interactive loop that allows you to selectively apply or edit differing sections (see the âpatchâ item in the âInteractive Modeâ section of git-add(1) for details).branch file
In our example, if you decided to keep your version as a default, but selectively apply changes from the other branch, you could do:
$ git checkout --ours moebius $ git add moebius $ git checkout -p floyd moebius diff --git b/moebius a/moebius index 1fcbe134..08dbe186 100644 --- b/moebius +++ a/moebius @@ -1,6 +1,6 @@ hello doctor -Jupiter -dolphin +Europa +monoliths yesterday tomorrow Apply this hunk to index and worktree [y,n,q,a,d,/,e,⦠y - apply this hunk to index and worktree n - do not apply this hunk to index and worktree q - quit; do not apply this hunk nor any of the remai⦠a - apply this hunk and all later hunks in the file ... $ git add moebius
Notes
-
If the current branch is already contained in the other (that is, HEAD is an ancestor of the other branch tip), then
git mergewill just move the current branch up to meet the other in a âfast-forwardâ update, and not make a new commit at all. You can force a merge commit anyway withgit merge --no-ff(âno fast-forwardâ), if you have some reason to do so. - If the converse is true, and the other branch is already contained in this one, then Git will simply say that the current branch is âalready up-to-date,â and do nothing. The goal of the merge is to incorporate into the current branch any changes on the other branch since the two divergedâbut they havenât diverged.
-
If you want to use Gitâs content-merging and conflict-resolution machinery, but do not want to create a merge commit, use
git merge --squash. This operates like a normal merge with regard to content, but the commit it creates is just on the current branch (that is, has a single parent and does not connect to the other branch in the commit graph). -
You can use
git merge -mto specify a commit message just as withgit commit, although remember that Git provides useful information in its supplied message, which you may prefer to start with and edit instead (which happens by default). -
Use
git merge --no-committo stop Git from committing when an automatic merge succeeds, in case you want to have a look first. This isnât strictly necessary, since you could always abort the commit by giving a blank commit message, or make any changes you want afterward and usegit commit --amend. -
Git records that a merge is in progress by setting the ref
MERGE_HEADto point to the other branch; this is how it knows to make a merge commit (as opposed to a simple commit on the current branch) even when there are intervening commands while you resolve conflicts.
Details on Merging
When merging, Git considers the changes that have occurred on the branches in question since they last diverged. In the previous example, the branches chandra and floyd last diverged at commit 50769fc9, so the changes to be reconciled were those in commits e355785d and a5374035. These branches might have diverged and been merged several times previously, but you will only be asked to deal with new changes since that last happened. Some other version control systems do not have this feature, so that merging branches repeatedly is a problem: you end up resolving the same conflicts over and over.
More precisely, when merging several branches, Git seeks a âmerge baseâ: a recent common ancestor of all the branch tips, to use as a reference point for arbitrating changes. Although in complicated situations there might be multiple possibilities for a merge base (see git-merge-base(1)), in the common case of our example, there is a single obvious choice, which Git finds automatically. Since our merge now involves three commitsâtwo branch tips and the merge baseâit is called a âthree-way merge.â
Recall that git status showed our conflicts, the âunmerged paths.â Where does it keep this information? There are conflict markers in the working files, but it would be slow to read all the files for this purpose, and in any case that wouldnât help for a modify/delete conflict. The answer demonstrates yet again the usefulness of the index. When there is a merge conflict for a file, Git simply stores not one version of the file in the index, but three: those belonging to the merge base and to the current and âotherâ branches, numbered 1, 2, and 3, respectively. The number is called the âstageâ of the file and is a distinct property of an index entry along with the filename, mode bits, and so on. In fact, there is a third stage, 0, which is the usual state of an entry that has no associated merge conflict. We can see this using git ls-files, which shows the contents of the index. Prior to the merge, we see:
$ git ls-files -s --abbrev
100644 1fcbe134 0 moebiusThe fields here are the mode bits, ID of the blob object holding the fileâs contents, the stage number, and the filename. After running git merge floyd and getting a conflict for this file, we see something very different (using -u instead of -s would show only unmerged paths; here we have only one file anyway):
$ git ls-files -s --abbrev
100644 30b7cdab 1 moebius
100644 1fcbe134 2 moebius
100644 08dbe186 3 moebiusNote that the ID of stage 2 matches what was previously stage 0 earlier, since stage 2 is the version on the current branch. You can use git cat-file to see the contents of the different stages, here the stage 1 merge-base version:
$ git cat-file -p 30b7cdab
hello
doctor
name
continue
yesterday
tomorrowYou can refer to a specific stage of a file with the syntax :n:path; so git show :1:moebius is an easier equivalent for this.
Git records the three commits into the index in this way at the start of the merge. It then follows a set of simple rules to quickly resolve the easy cases; for example:
- If all three stages match, reduce to a single stage 0.
- If stage 1 matches stage 2, then reduce to a single stage 0 matching stage 3 (or vice versa): one side made a change while the other did nothing.
- If stage 1 matches stage 2, but there is no stage 3, then remove the file: we made no change, while the other branch deleted it, so accept the other branchâs deletion.
- If stages 1 and 2 differ, and there is no stage 3, then report a âmodify/deleteâ conflict: we changed the file, while the other branch deleted it; the user must decide what to do.
â¦and so forth. Note that for matching, Git doesnât need to fetch the actual files; it can just compare the blob object IDs already in the index, since they are hashes of the filesâ contents. This is very fast; content-based addressing wins again. You can read about this process in more detail in git-read-tree(1). Any files that canât be easily resolved this way must then actually be examined to attempt merging their contents.
Merge Tools
Merging can be a complex job, with you staring at scores of conflicting sections of source code changes from yourself and other people, and trying to combine them into a single working whole. There are tools available that go far beyond the simple text output of git diff in helping you to visualize and resolve such conflicts. Git integrates smoothly with these external âmerge tools,â to help you get the job done more easily. Git supports over a dozen free and commercial merge tools out of the box, including araxis, emerge, opendiff, kdiff3, and gvimdiff. It also defines an interface with which you can use most any such tool, usually requiring only a simple wrapper script to connect it to Git.
We canât delve into the details of the individual merge tools; many of them are complex programs in their own right and would require another small book each to describe. Here, weâll just describe how they work with Git generally.
The driver for using a merge tool is git mergetool. Once invoked, this command runs over all the files with merge conflicts, asking for each if you want to invoke the selected merge tool on the file. The default merge tool is opendiff, but you can set a different default with the merge.tool Git configuration variable. The tool will usually present you with a view of the âoursâ and âtheirsâ versions of the file, along with the merge base, and provide ways to move from one change or conflict to the next, select which sideâs change to use (or combine them), etc. When you quit the merge tool indicating success, Git will add your merged version to the index (thus marking this conflict as resolved), and go on to the next unmerged file.
Notes
-
The
-yswitch togit mergetooltells it to run the tool on all unmerged files, without pausing to prompt yes or no for each one. -
git mergetoolleaves a backup foo.orig for each file foo it processes, since you might have modified it yourself before running the merge tool. You can setmergetool.keepBackup noto turn off this feature. Actually, Git still makes the backup; it just deletes it when the merge tool exits successfully, so that the backup is still there in case the tool were to crash. If a merge tool exits unexpectedly or doesnât work properly, you may see files like these left behind (for the file main.c):
main.c.BACKUP.62981.c main.c.BASE.62981.c main.c.LOCAL.62981.c main.c.REMOTE.62981.c
These are the temporary files that Git uses to pass the various file versions to the merge tool.
Custom Merge Tools
If you want to use a merge tool not directly supported by Git, it need only obey some simple conventions; usually, youâll write a glue script to accommodate them. Git passes four filenames to the tool as environment variables:
-
LOCAL - The version from the current branch
-
REMOTE - The version from the other branch
-
BASE - The version from the merge base (common ancestor)
-
MERGED - File to which the merged version should be written
The tool should exit with a code of zero to indicate that the user is happy with the merged version, saved to the filename in the MERGED environment variable. A nonzero exit code means that Git should ignore that file and not mark this conflict resolved. To define a new Git merge tool named âfooâ with your own program named newtool:
[mergetool "foo"]
cmd = newtool $LOCAL $REMOTE $MERGED $BASE
trustExitCode = trueThis shows the files being passed on the command line to newtool; if your program reads the environment variables itself, then of course thatâs not required. The trustExitCode setting means that Git will interpret the toolâs exit code as previously described; if this setting is false, Git will prompt the user for what to do anyway.
Merge Strategies
Git has a number of approaches it can take to automatically merge files that have been changed by both sides of a merge; that is to say, exactly what it does in analyzing text to determine the boundaries of changed blocks, when blocks have been moved, when changes can be safely merged, and when they should be punted to the user. These approaches are called âmerge strategies,â and each may in turn have various options; Git can even be extended with new strategies by writing custom âmerge drivers,â without having to touch Git proper.
The built-in merge strategies are described in git-merge(1). The many options are quite technical and involved, and Gitâs default choice of strategy is usually sufficient; we will not cover them in depth here. However, here are a few tips involving merge strategies that are generally useful:
-
git merge -s ours -
The
oursstrategy is simple: it discards all changes from the other branch. This leaves the content on your branch unchanged, and when you next merge from the other branch, Git will only consider changes made from this point forward. You might use this to retain the history of a branch, without incorporating its effects. (This strategy works with more than two branches as well.) -
git merge -s recursive -X ours -
This is the
oursoption to therecursivestrategy, not to be confused with theoursstrategy. Therecursivestrategy is often the default, and so you might not have to use-s, but weâll be explicit here. This option directs Git to resolve conflicting changes in favor of the current branch. This is different from theoursstrategy, in that nonconflicting changes can still be resolved in favor of either branch. You can use-X theirsas well, to resolve in favor of the other branch instead. -
ignore-space-change,ignore-all-space,ignore-space-at-eol -
These options to the
recursivestrategy automatically resolve conflicts differing only in certain types of whitespace; see git-merge(1) for details. -
merge.verbosity -
This configuration variable (or the
GIT_MERGE_VERBOSITYenvironment variable, which takes precedence), holds a natural number indicating the level of information printed by therecursivestrategy. Zero prints only a final error message on conflict, 2 is the default, and 5 and above show debugging information. - The âoctopusâ strategy
-
The octopus strategy can merge any number of branches, but only if all changes can be resolved automatically. If not, the strategy will abort in the middle of the merge attempt, possibly leaving your index and working tree in a not terribly meaningful state. Unlike when merging two branches,
git merge --abortdoesnât work in this case (it says no merge is in progress); this may be a limitation that will be addressed in future versions of Git. You can usegit resetto discard the index changes, adding--hardto reset the working tree as well, if you had no uncommitted changes to lose. âOctopusâ is the default strategy when merging more than two branches, e.g.,git merge bert ernie oscar.
Why the Octopus?
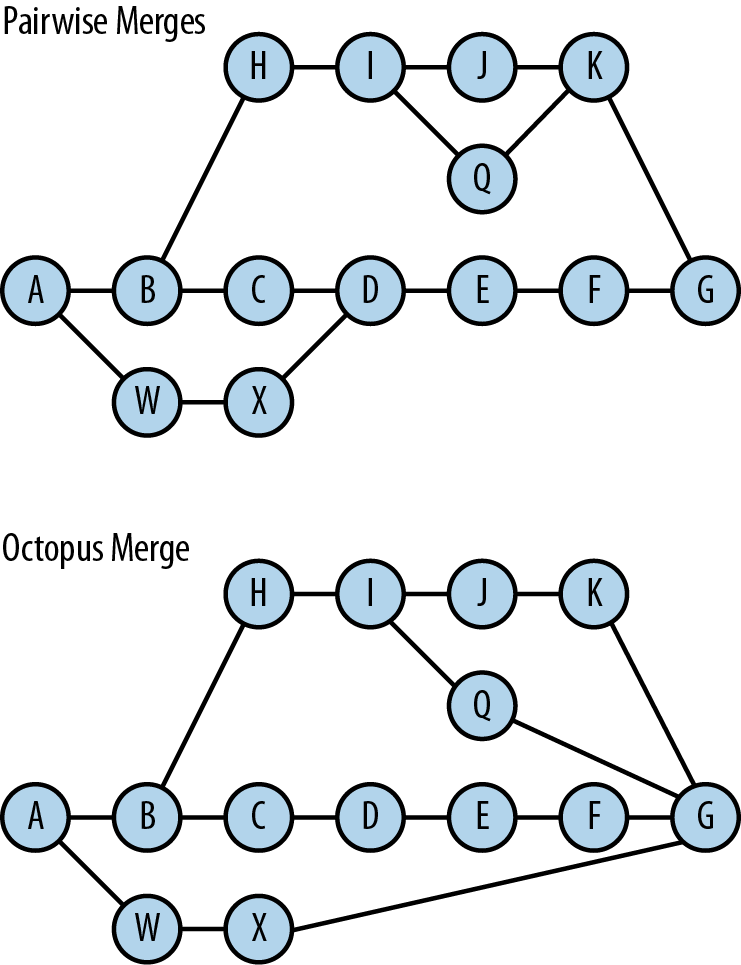
An octopus merge is generally used to tie together several topic branches with the master branch in preparation for a new release of a project, bringing in all their separate contributions. The individual branches should already have been reconciled with the master and have no conflicts amongst them, or else as mentioned, the octopus merge will not work. The octopus merge does not have any inherent advantage over simply merging all the topic branches into the master pairwise and reconciling the conflicts there; it accomplishes the same goal and incorporates the same history. However, with a large number of branches, it can make for a cleaner and more easily understood commit graph, and so some people prefer it. See Figure 7-1.
Reusing Previous Merge Decisions
Git can remember merge conflict resolutions you made in the past, and reuse them automatically if you run into similar conflicts later. This feature goes by the name git rerere, for âreuse recorded resolution.â This is useful if youâre working on a particularly difficult merge. You may abort a merge and retry it in various ways, but having resolved some conflicts in the meantime, this feature can remember and reapply those decisions. It can also be helpful if youâre rewriting repository history, or in maintaining branches on which you end up resolving the same conflicts repeatedly until the branchâs content can finally be merged appropriately.
Setting rerere.enabled in a repository turns on the feature, which is then automatically used by both git merge and git rebase. Since this is an advanced feature, we just note its existence here and refer the reader to git-rerere(1) for details.
Get Git Pocket Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

