Chapter 1. Understanding Git
In this initial chapter, we discuss how Git operates, defining important terms and concepts you should understand in order to use Git effectively.
Some tools and technologies lend themselves to a âblack-boxâ approach, in which new users donât pay too much attention to how a tool works under the hood. You concentrate first on learning to manipulate the tool; the âwhyâ and âhowâ can come later. Gitâs particular design, however, is better served by the opposite approach, in that a number of fundamental internal design decisions are reflected directly in how you use it. By understanding up front and in reasonable detail several key points about its operation, you will be able to come up to speed with Git more quickly and confidently, and be better prepared to continue learning on your own.
Thus, I encourage you to take the time to read this chapter first, rather than just jump over it to the more tutorial, hands-on chapters that follow (most of which assume a basic grasp of the material presented here, in any case). You will probably find that your understanding and command of Git will grow more easily if you do.
Overview
We start by introducing some basic terms and ideas, the general notion of branching, and the usual mechanism by which you share your work with others in Git.
Terminology
A Git project is represented by a ârepository,â which contains the complete history of the project from its inception. A repository in turn consists of a set of individual snapshots of project contentâcollections of files and directoriesâcalled âcommits.â A single commit comprises the following:
- A project content snapshot, called a âtreeâ
- A structure of nested files and directories representing a complete state of the project
- The âauthorâ identification
- Name, email address, and date/time (or âtimestampâ) indicating who made the changes that resulted in this project state and when
- The âcommitterâ identification
- The same information about the person who added this commit to the repository (which may be different from the author)
- A âcommit messageâ
- Text used to comment on the changes made by this commit
- A list of zero or more âparent commitsâ
- References to other commits in the same repository, indicating immediately preceding states of the project content
The set of all commits in a repository, connected by lines indicating their parent commits, forms a picture called the repository âcommit graph,â shown in Figure 1-1.
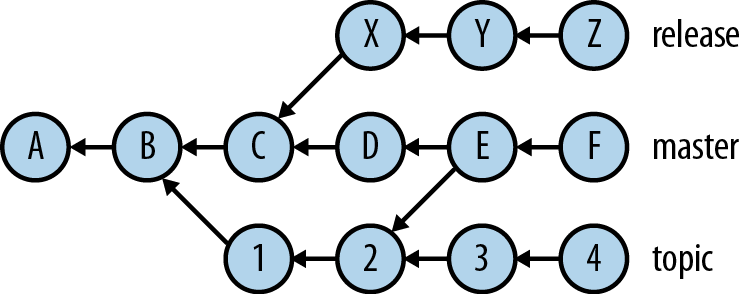
The letters and numbers here represent commits, and arrows point from a commit to its parents. Commit A has no parents and is called a âroot commitâ; it was the initial commit in this repositoryâs history. Most commits have a single parent, indicating that they evolved in a straightforward way from a single previous state of the project, usually incorporating a set of related changes made by one person. Some commits, here just the one labeled E, have multiple parents and are called âmerge commits.â This indicates that the commit reconciles the changes made on distinct branches of the commit graph, often combining contributions made separately by different people.
Since it is normally clear from context in which direction the history proceedsâusually, as here, parent commits appear to the left of their childrenâwe will omit the arrow heads in such diagrams from now on.
Branches
The labels on the right side of this pictureâmaster, topic, and releaseâdenote âbranches.â The branch name refers to the latest commit on that branch; here, commits F, 4, and Z, respectively, are called the âtipâ of the branch. The branch itself is defined as the collection of all commits in the graph that are reachable from the tip by following the parent arrows backward along the history. Here, the branches are:
- release = {A, B, C, X, Y, Z}
- master = {A, B, C, D, E, F, 1, 2}
- topic = {A, B, 1, 2, 3, 4}
Note that branches can overlap; here, commits 1 and 2 are on both the master and topic branches, and commits A and B are on all three branches. Usually, you are âonâ a branch, looking at the content corresponding to the tip commit on that branch. When you change some files and add a new commit containing the changes (called âcommitting to the repositoryâ), the branch name advances to the new commit, which in turn points to the old commit as its sole parent; this is the way branches move forward. From time to time, you will tell Git to âmergeâ several branches (most often two, but there can be more), tying them together as at commit E in Figure 1-1. The same branches can be merged repeatedly over time, showing that they continued to progress separately while you periodically combined their contents.
The first branch in a new repository is named master by default, and itâs customary to use that name if there is only one branch in the repository, or for the branch that contains the main line of development (if that makes sense for your project). You are not required to do so, however, and there is nothing special about the name âmasterâ apart from convention, and its use as a default by some commands.
Sharing Work
There are two contexts in which version control is useful: private and public. When working on your own, itâs useful to commit âearly and often,â so that you can explore different ideas and make changes freely without worrying about recovering earlier work. Such commits are likely to be somewhat disorganized and have cryptic commit messages, which is fine because they need to be intelligible only to you, and for a short period of time. Once a portion of your work is finished and youâre ready to share it with others, though, you may want to reorganize those commits, to make them well-factored with regard to reusability of the changes being made (especially with software), and to give them meaningful, well-written commit messages.
In centralized version control systems, the acts of committing a change and publishing it for others to see are one and the same: the unit of publication is the commit, and committing requires publishing (applying the change to the central repository where others can immediately see it). This makes it difficult to use version control in both private and public contexts. By separating committing and publishing, and giving you tools with which to edit and reorganize existing commits, Git encourages better use of version control overall.
With Git, sharing work between repositories happens via operations called âpushâ and âpullâ: you pull changes from a remote repository and push changes to it. To work on a project, you âcloneâ it from an existing repository, possibly over a network via protocols such as HTTP and SSH. Your clone is a full copy of the original, including all project history, completely functional on its own. In particular, you do not need to contact the first repository again in order to examine the history of your clone or commit to itâhowever, your new repository does retain a reference to the original one, called a âremote.â This reference includes the state of the branches in the remote as of the last time you pulled from it; these are called âremote trackingâ branches. If the original repository contains two branches named master and topic, their remote-tracking branches in your clone appear qualified with the name of the remote (by default called âoriginâ): origin/master and origin/topic.
Most often, the master branch will be automatically checked out for you when you first clone the repository; Git initially checks out whatever the current branch is in the remote repository. If you later ask to check out the topic branch, Git sees that there isnât yet a local branch with that nameâbut since there is a remote-tracking branch named origin/topic, it automatically creates a branch named topic and sets origin/topic as its âupstreamâ branch. This relationship causes the push/pull mechanism to keep the changes made to these branches in sync as they evolve in both your repository and in the remote.
When you pull, Git updates the remote-tracking branches with the current state of the origin repository; conversely, when you push, it updates the remote with any changes youâve made to corresponding local branches. If these changes conflict, Git prompts you to merge the changes before accepting or sending them, so that neither side loses any history in the process.
If youâre familiar with CVS or Subversion, a useful conceptual shift is to consider that a âcommitâ in those systems is analogous to a Git âpush.â You still commit in Git, of course, but that affects only your repository and is not visible to anyone else until you push those commitsâand you are free to edit, reorganize, or delete your commits until you do so.
The Object Store
Now, we discuss the ideas just introduced in more detail, starting with the heart of a Git repository: its object store. This is a database that holds just four kinds of items: blobs, trees, commits, and tags.
Blob
A blob is an opaque chunk of data, a string of bytes with no further internal structure as far as Git is concerned. The content of a file under version control is represented as a blob. This does not mean the implementation of blobs is naive; Git uses sophisticated compression and transmission techniques to handle blobs efficiently.
Every version of a file in Git is represented as a whole, with its own blob containing the fileâs complete contents. This stands in contrast to some other systems, in which file versions are represented as a series of differences from one revision to the next, starting with a base version. Various trade-offs stem from this design point. One is that Git may use more storage space; on the other hand, it does not have to reconstruct files to retrieve them by applying layers of differences, so it can be faster. This design increases reliability by increasing redundancy: corruption of one blob affects only that file version, whereas corruption of a difference affects all versions coming after that one.
Tree
A Git tree, by itself, is actually what one might usually think of as one level of a tree: it represents a single level of directory structure in the repository content. It contains a list of items, each of which has:
- A filename and associated information that Git tracks, such as its Unix permissions (âmode bitsâ) and file type; Git can handle Unix âsymbolic linksâ as well as regular files.
- A pointer to another object. If that object is a blob, then this item represents a file; if itâs another tree, a directory.
There is an ambiguity here: when we say âtree,â do we mean a single object as just described, or the collection of all such objects reachable from it by following the pointers recursively until we reach the terminal blobsâthat is, a âtreeâ in the more usual sense? It is the latter notion of tree that this data structure is used to represent, of course, and fortunately, it is seldom necessary in practice to make the distinction. When we say âtree,â we will normally mean the entire hierarchy of tree and blob objects; when necessary, we will use the phrase âtree objectâ to refer to the specific, individual data structure component.
A Git tree, then, represents a portion of the repository content at one point in time: a snapshot of a particular directoryâs content, including that of all directories beneath it.
Note
Originally, Git saved and restored the full permissions on files (all the mode bits). Later, however, this was deemed to cause more trouble than it was worth, so the interpretation of the mode bits in the index was changed. Now, the only valid values for the low 12 bits of the mode as stored in Git are octal 755 and 644, and these simply indicate that the file should be executable or not. Git sets the execute bits on a file on checkout according to this, but the actual mode value may be different depending on your umask setting; for example, if your umask is 0077, then a file stored with Git mode 755 will end up with mode 700.
Commit
A version control system manages content changes, and the commit is the fundamental unit of change in Git. A commit is a snapshot of the entire repository content, together with identifying information, and the relationship of this historical repository state to other recorded states as the content has evolved over time. Specifically, a commit consists of:
- A pointer to a tree containing the complete state of the repository content at one point in time.
- Ancillary information about this change: who was responsible for the content (the âauthorâ); who introduced the change into the repository (the âcommitterâ); and the time and date for both those things. The act of adding a commit object to the repository is called âmaking a commit,â or âcommitting (to the repository).â
- A list of zero or more other commit objects, called the âparentsâ of this commit. The parent relationship has no intrinsic meaning; however, the normal ways of making a commit are meant to indicate that the commitâs repository state was derived by the author from those of its parents in some meaningful way (e.g., by adding a feature or fixing a bug). A chain of commits, each having a single parent, indicates a simple evolution of repository state by discrete steps (and as weâll see, this constitutes a branch). When a commit has more than one parent, this indicates a âmerge,â in which the committer has incorporated the changes from multiple lines of development into a single commit. Weâll define branches and merges more precisely in a moment.
Of course, at least one commit in the repository must have zero parents, or else the repository would either be infinitely large or have loops in the commit graph, which is not allowed (see the description of a âDAGâ next). This is called a âroot commit,â and most often, there is only one root commit in a repositoryâthe initial one created when the repository was started. However, you can introduce multiple root commits if you want; the command git checkout --orphan does this. This incorporates multiple independent histories into a repository, perhaps in order to collect the contents of previously separate projects (see Importing Disconnected History).
Author versus Committer
The separate author and committer informationâname, email address, and timestampâreflect the creation of the commit content and its addition to the repository, respectively. These are initially the same, but may later become distinct with the use of certain Git commands. For example, git cherry-pick replicates an existing commit by reapplying the changes introduced by that commit in another context. Cherry-picking carries forward the author information from the original commit, while adding new committer information. This preserves the identification and origin date of the changes, while indicating that they were applied at another point in the repository at a later date, possibly by a different person. A bugfix cherry-picked from one repository to another might look like this:
$ git log --format=fuller
commit d404534d
Author: Eustace Maushaven <eustace@qoxp.net>
AuthorDate: Thu Nov 29 01:58:13 2012 -0500
Commit: Richard E. Silverman <res@mlitg.com>
CommitDate: Tue Feb 26 17:01:33 2013 -0500
Fix spin-loop bug in k5_sendto_kdc
In the second part of the first pass over the
server list, we passed the wrong list pointer to
service_fds, causing it to see only a subset of
the server entries corresponding to sel_state.
This could cause service_fds to spin if an event
is reported on an fd not in the subset.
---
cherry-picked from upstream by res
upstream commit 2b06a22f7fd8ec01fb27a7335125290b8â¦
Other operations that do this are git rebase and git filter-branch; like git cherry-pick, they too create new commits based on existing ones.
Cryptographic Signature
A commit may also be signed using GnuPG, with:
$ git commit --gpg-sign[=keyid]See Cryptographic Keys regarding Gitâs selection of a key identifier.
A cryptographic signature binds the commit to a particular real-world personal identity attached to the key used for signing; it verifies that the commitâs contents are the same now as they were when that person signed it. The meaning of the signature, though, is a matter of interpretation. If I sign a commit, it might mean that I glanced at the diff; verified that the software builds; ran a test suite; prayed to Cthulhu for a bug-free release; or did none of these. Aside from being a convention among the users of the repository, I can also put the intention of my signature in the commit message; presumably, I will not sign a commit without at least reading its message.
Tag
A tag serves to distinguish a particular commit by giving it a human-readable name in a namespace reserved for this purpose. Otherwise, commits are in a sense anonymous, normally referred to only by their position along some branch, which changes with time as the branch evolves (and may even disappear if the branch is later deleted). The tag content consists of the name of the person making the tag, a timestamp, a reference to the commit being tagged, and free-form text similar to a commit message.
A tag can have any meaning you like; often, it identifies a particular software release, with a name like coolutil-1.0-rc2 and a suitable message. You can cryptographically sign a tag just as you can a commit, in order to verify the tagâs authenticity.
Note
There are actually two kinds of tags in Git: âlightweightâ and âannotated.â This section refers to annotated tags, which are represented as a separate kind of object in the repository database. A lightweight tag is entirely different; it is simply a name pointing directly to a commit (see the upcoming section on refs to understand how such names work generally).
Object IDs and SHA-1
A fundamental design element of Git is that the object store uses content-based addressing. Some other systems assign identifiers to their equivalent of commits that are relative to one another in some way, and reflect the order in which commits were made. For example, file revisions in CVS are dotted strings of numbers such as 2.17.1.3, in which (usually) the numbers are simply counters: they increment as you make changes or add branches. This means that there is no instrinsic relationship between a revision and its identifier; revision 2.17.1.3 in someone elseâs CVS repository, if it exists, will almost certainly be different from yours.
Git, on the other hand, assigns object identifiers based on an objectâs contents, rather than on its relationship to other objects, using a mathematical technique called a hash function. A hash function takes an arbitrary block of data and produces a sort of fingerprint for it. The particular hash function Git uses, called SHA-1, produces a 160-bit fixed-length value for any data object you feed it, no matter how large.
The usefulness of hash-based object identifiers in Git depends on treating the SHA-1 hash of an object as unique; we assume that if two objects have the same SHA-1 fingerprint, then they are in fact the same object. From this property flow a number of key points:
- Single-instance store
- Git never stores more than one copy of a file. It canâtâif you add a second copy of the file, it will hash the file contents to find its SHA-1 object ID, look in the database, and find that itâs already there. This is also a consequence of the separation of a fileâs contents from its name. Trees map filenames onto blobs in a separate step, to determine the contents of a particular filename at any given commit, but Git does not consider the name or other properties of a file when storing it, only its contents.
- Efficient comparisons
- As part of managing change, Git is constantly comparing things: files against other files, changed files against existing commits, as well as one commit against another. It compares whole repository states, which might encompass hundreds or thousands of files, but it does so with great efficiency because of hashing. When comparing two trees, for example, if it finds that two subtrees have the same ID, it can immediately stop comparing those portions of the trees, no matter how many layers of directories and files might remain. Why? We said earlier that a tree object contains âpointersâ to its child objects, either blobs or other trees. Well, those pointers are the objectsâ SHA-1 IDs. If two trees have the same ID, then they have the same contents, which means they must contain the same child object IDs, which means that in turn those objects must also be the same! Inductively, we see immediately that in fact, the entire contents of the two trees must be identical, if the uniqueness property assumed previously holds.
- Database sharing
- Git repositories can share their object databases at any level with impunity because there can be no aliasing; the binding between an ID and the content to which it refers is immutable. One repository cannot mess up anotherâs object store by changing the data out from under it; in that sense, an object store can only be expanded, not changed. We do still have to worry about removing objects that another database is using, but thatâs a much easier problem to solve.
Much of the power of Git stems from content-based addressingâbut if you think for a moment, itâs based on a lie! We are claiming that the SHA-1 hash of a data object is unique, but thatâs mathematically impossible: because the hash function output has a fixed length of 160 bits, there are exactly 2160 IDsâbut infinitely many potential data objects to hash. There have to be duplications, called âhash collisions.â The whole system appears fatally flawed.
The solution to this problem lies in what constitutes a âgoodâ hash function, and the odd-sounding notion that while SHA-1 cannot be mathematically collision-free, it is what we might call effectively so. For the practical purposes of Git, Iâm not necessarily concerned if there are in fact other files that might have the same ID as one of mine; what really matters is whether any of those files are at all likely to ever appear in my project, or in anyone elseâs. Maybe all the other files are over 10 trillion bytes long, or will never match any program or text in any programming, object, or natural language ever invented by humanity. This is exactly a property (among others) that researchers endeavor to build into hash functions: the relationship between changes in the input and output is extremely sensitive and wildly unpredictable. Changing a single bit in a file causes its SHA-1 hash to change radically, and flipping a different bit in that file, or the same bit in a different file, will scramble the hash in a way that has no recognizable relationship to the other changes. Thus, it is not that SHA-1 hash collisions cannot happenâit is just that we believe them to be so astronomically unlikely in practice that we simply donât care.
Of course, discussing precise mathematical topics in general terms is fraught with hazard; this description is intended to communicate the essence of why we rely upon SHA-1 to do its job, not to prove anything rigorously or even to give justification for these claims.
Security
SHA-1 stands for âSecure Hash Algorithm 1,â and its name reflects the fact that it was designed for use in cryptography. âHashingâ is a basic technique in computer science, with applications to many areas besides security, including signal processing, searching and sorting algorithms, and networking hardware. A âcryptographically secureâ hash function like SHA-1 has related but distinct properties to those already mentioned with respect to Git; it is not just extraordinarily unlikely that two distinct trees arising in practice will produce the same commit ID, but it should also be effectively impossible for someone to deliberately find two such trees, or to find a second tree with the same ID as a given one. These features make a hash function useful in security as well as for more general purposes, since with them it can defend against deliberate tampering as well as ordinary or accidental changes to data.
Because SHA-1 is a cryptographic hash function, Git inherits certain security properties from its use of SHA-1 as well as operational ones. If I tag a particular commit of security-sensitive software, it is not feasible for an attacker to substitute a commit with the same ID in which he has embedded a backdoor; as long as I record the commit ID securely and compare it correctly, the repository is tamper proof in this regard. As explained earlier, the chained use of SHA-1 causes the tagâs ID to cover the entire content of the tagged commitâs tree. The addition of GnuPG digital signatures allows individuals to vouch for the contents of entire repository states and history, in a way that is impractical to forge.
Cryptographic research is always ongoing, though, and computing power increases every year; other hash functions such as MD5 that were once considered secure have been deprecated due to such advances. We have developed more secure versions of SHA itself, in fact, and as of this writing in early 2013, serious weaknesses in SHA-1 have recently been discovered. The criteria used to appraise hash functions for cryptographic use are very conservative, so these weaknesses are more theoretical than practical at the moment, but they are meaningful nonetheless. The good news is that further cryptographic breaks of SHA-1 will not affect the usefulness of Git as a version control system per se; that is, make it more likely in practice that Git will treat distinct commits as identical (that would be disastrous). They will affect the security properties Git enjoys as a result of using SHA-1, but those, while important, are critical to a smaller number of people (and those security goals can mostly be met in other ways if need be). In any case, it will be possible to switch Git to using a different hash function when it becomes necessaryâand given the current state of research, it would probably be wise to do that sooner rather than later.
Where Objects Live
In a Git repository, objects are stored under .git/objects. They may be stored individually as âlooseâ objects, one per file with pathnames built from their object IDs:
$ find .git/objects -type f
.git/objects/08/5cf6be546e0b950e0cf7c530bdc78a6d5a78db
.git/objects/0d/55bed3a35cf47eefff69beadce1213b1f64c39
.git/objects/19/38cbe70ea103d7185a3831fd1f12db8c3ae2d3
.git/objects/1a/473cac853e6fc917724dfc6cbdf5a7479c1728
.git/objects/20/5f6b799e7d5c2524468ca006a0131aa57ecce7
...
They may also be collected into more compact data structures called âpacks,â which appear as paired .idx and .pack files:
$ ls .git/objects/pack/
pack-a18ec63201e3a5ac58704460b0dc7b30e4c05418.idx
pack-a18ec63201e3a5ac58704460b0dc7b30e4c05418.packGit automatically rearranges the object store over time to improve performance; for example, when it sees that there are many loose objects, it automatically coalesces them into packs (though you can do this by hand; see git-repack(1)). Donât assume that objects will be represented in any particular way; always use Git commands to access the object database, rather than digging around in .git yourself.
The Commit Graph
The collection of all commits in a repository forms what in mathematics is called a graph: visually, a set of objects with lines drawn between some pairs of them. In Git, the lines represent the commit parent relationship previously explained, and this structure is called the âcommit graphâ of the repository.
Because of the way Git works, there is some extra structure to this graph: the lines can be drawn with arrows pointing in one direction because a commit refers to its parent, but not the other way around (weâll see later the necessity and significance of this). Again using a mathematical term, this makes the graph âdirected.â The commit graph might be a simple linear history, as shown in Figure 1-2.

Or a complex picture involving many branches and merges, as shown in Figure 1-3.
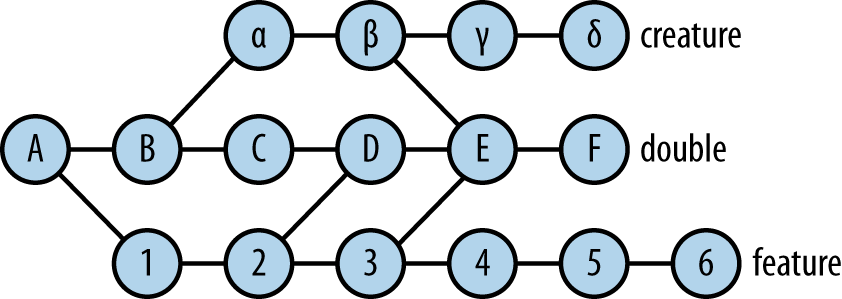
Those are the next topics weâll touch on.
Refs
Git defines two kinds of references, or named pointers, which it calls ârefsâ:
- A simple ref, which points directly to an object ID (usually a commit or tag)
- A symbolic ref (or symref), which points to another ref (either simple or symbolic)
These are analogous to âhard linksâ and âsymbolic linksâ in a Unix filesystem.
Git uses refs to name things, including commits, branches, and tags. Refs inhabit a hierarchical namespace separated by slashes (as with Unix filenames), starting at refs/. A new repository has at least refs/tags/ and refs/heads/, to hold the names of tags and local branches, respectively. There is also refs/remotes/, holding names referring to other repositories; these contain beneath them the ref namespaces of those repositories, and are used in push and pull operations. For example, when you clone a repository, Git creates a âremoteâ named origin referring to the source repository.
There are various defaults, which means that you donât often have to refer to a ref by its full name; for example, in branch operations, Git implicitly looks in refs/heads/ for the name you give.
Related Commands
These are low-level commands that directly display, change, or delete refs. You donât ordinarily need these, as Git usually handles refs automatically as part of dealing with the objects they represent, such as branches and tags. If you change refs directly, be sure you know what youâre doing!
-
git show-ref - Display refs and the objects to which they refer
-
git symbolic-ref - Deals with symbolic refs specifically
-
git update-ref - Change the value of a ref
-
git for-each-ref - Apply an action to a set of refs
Warning
Refs often live in corresponding files and directories under .git/refs; however, donât get in the habit of looking for or changing them directly there, since there are cases in which they are stored elsewhere (in âpacks,â in fact, as with objects), and changing one might involve other operations you donât know about. Always use Git commands to manipulate refs.
Branches
A Git branch is the simplest thing possible: a pointer to a commit, as a ref. Or rather, that is its implementation; the branch itself is defined as all points reachable in the commit graph from the named commit (the âtipâ of the branch). The special ref HEAD determines what branch you are on; if HEAD is a symbolic ref for an existing branch, then you are âonâ that branch. If, on the other hand, HEAD is a simple ref directly naming a commit by its SHA-1 ID, then you are not âonâ any branch, but rather in âdetached HEADâ mode, which happens when you check out some earlier commit to examine. Letâs see:
# HEAD points to the master branch $ git symbolic-ref HEAD refs/heads/master # Git agrees; Iâm on the master branch. $ git branch * master # Check out a tagged commit, not at a branch tip. $ git checkout mytag Note: checking out 'mytag'. You are in 'detached HEAD' state... # Confirmed: HEAD is no longer a symbolic ref. $ git symbolic-ref HEAD fatal: ref HEAD is not a symbolic ref # What is it? A commit ID... $ git rev-parse HEAD 1c7ed724236402d7426606b03ee38f34c662be27 # ... which matches the commit referred to by the # tag. $ git rev-parse mytag^{commit} 1c7ed724236402d7426606b03ee38f34c662be27 # Git agrees; weâre not on any branch. $ git branch * (no branch) master
The HEAD commit is also often referred to as the âcurrentâ commit. If you are on a branch, it may also be called the âlastâ or âtipâ commit of the branch.
A branch evolves over time; thus, if you are on the branch master and make a commit, Git does the following:
- Creates a new commit with your changes to the repository content
- Makes the commit at the current tip of the master branch the parent of the new commit
- Adds the new commit to the object store
-
Changes the master branch (specifically, the ref
refs/heads/master) to point to the new commit
In other words, Git adds the new commit to the end of the branch using the commitâs parent pointer, and advances the branch ref to the new commit.
Note a few consequences of this model:
- Considered individually, a commit is not intrinsically a part of any branch. There is nothing in the commit itself to tell you by name which branches it is or may once have been on; branch membership is a consequence of the commit graph and the current branch pointers.
-
âDeletingâ a branch means simply deleting the corresponding ref; it has no immediate effect on the object store. In particular, deleting a branch does not delete any commits. What it may do, however, is make certain commits uninteresting, in that they are no longer on any branch (that is, no longer reachable in the commit graph from any branch tip or tag). If this state persists, Git will eventually remove such commits from the object store as part of garbage collection. Until that happens, though, if you have an abandoned commitâs ID you can still directly access it perfectly well by its SHA-1 name; the Git reflog (
git log -g) is useful in this regard. - By this definition, a branch can include more than just commits made while on that branch; it also contains commits from branches that flow into this one via an earlier merge. For example: here, the branch topic was merged into master at commit C, then both branches continued to evolve separately, as shown in Figure 1-4.
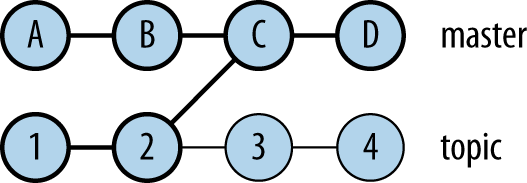
At this point, git log on the master branch shows not only commits A through D as you would expect, but also commits 1 and 2, since they are also reachable from D via C. This may be surprising, but itâs just a different way of defining the idea of a branch: as the set of all commits that contributed content to the latest commit. You can generally get the effect of looking âonly at the history of this branchââeven though thatâs not really well definedâwith git log --first-parent.
The Index
The Git âindexâ often seems a bit mysterious to people: some invisible, ineffable place where changes are âstagedâ until theyâre committed. The talk about âstaging changesâ in the index also suggests that it holds only changes, as if it were a collection of diffs waiting to be applied. The truth is different and quite simple, and critical to grasp in order to understand Git well. The index is an independent data structure, separate from both your working tree and from any commit. It is simply a list of file pathnames together with associated attributes, usually including the ID of a blob in the object database holding the data for a version of that file. You can see the current contents of the index with git ls-files:
$ git ls-files --abbrev --stage
100644 2830ea0b 0 TODO
100644 a4d2acee 0 VERSION
100644 ce30ff91 0 acinclude.m4
100644 236d5f93 0 configure.ac
...
The --stage option means to show just the index; git ls-files can show various combinations and subsets of the index and your working tree, generally. If you were to delete or change any of the listed files in your working tree, this would not affect the output of this command at all; itâs not looking at them. Key facts about the index:
-
The index is the implicit source of the content for a normal commit. When you use
git commit(without supplying specific pathnames), you might think that it creates the new commit based on your working files. It does not; instead, it simply realizes the current index as a new tree object, and makes the new commit from that. This is why you need to âstageâ a changed file in the index withgit addin order for it to be part of the next commit. -
The index does not just contain changes to be made on the next commit; it is the next commit, a complete catalog of the files that will be included in the tree of the next commit (recall that each commit refers to a tree object that is a complete snapshot of the repository content). When you check out a branch, Git resets the index to match the tip commit of that branch; you then modify the index with commands such as
git add/mv/rmto indicate changes to be part of the next commit. git adddoes not just note in the index that a file has changed; it actually adds the current file content to the object database as a new blob, and updates the index entry for that file to refer to that blob. This is whygit commitis always fast, even if youâre making lots of changes: all the actual data has already been stored by precedinggit addcommands.An implication of this behavior that occasionally confuses people is that if you change a file,
git addit, then change it again, it is the version you last added to the index, not the one in your working tree, that is part of the next commit.git statusshows this explicitly, by listing the same file as having both âchanges to be committedâ and âchanges not staged for commit.â-
Similar to
git commit,git diffwithout arguments also has the index as an implicit operand; it shows the differences between your working tree and the index, rather than the current commit. Initially these are the same, as the index matches the last commit after a clean checkout or commit. As you make changes to your working files, these show up in the output ofgit diff, then disappear as you add the corresponding files. The idea is thatgit diffshows changes not yet staged for commit, so you can see what you have yet to deal with (or have deliberately not included) as you prepare the next commit.git diff--stagedshows the opposite: the differences between the index and the current commit (that is, the changes that are about to be committed).
Merging
Merging is the complement of branching in version control: a branch allows you to work simultaneously with others on a particular set of files, whereas a merge allows you to later combine separate work on two or more branches that diverged earlier from a common ancestor commit. Here are two common merge scenarios:
You are working by yourself on a software project. You decide to explore refactoring your code in a certain way, so you make a branch named refactor off of the master branch. You can make any changes you like on the refactor branch without disturbing the main line of development.
After a while, youâre happy with the refactoring youâve done and want to keep it, so you switch to the master branch and run
git merge refactor. Git applies the changes youâve made on both branches since they diverged, asking for your help in resolving any conflicts, then commits the result. You delete the refactor branch, and move on.-
You have been working on the master branch of a cloned repository and have made several commits over a day or two. You then run
git pullto update your clone with the latest work committed to the origin repository. It happens that others have also committed to the origin master branch in the meantime, so Git performs an automatic merge of master and origin/master and commits this to your master branch. You can then continue with your work or push to the origin repository now that you have incorporated its latest changes with your own. See Push and Pull.
There are two aspects to merging in Git: content and history.
Merging Content
What it means to successfully âmergeâ two or more sets of changes to the same file depends on the nature of the contents. Git will try to merge automatically, and often call it a success if the two changesets altered non-overlapping portions of the file. Whether you will call that a success, however, is a different question. If the file is chapter three of your next novel, then perhaps such a merge would be fine if you were making minor grammar and style corrections. If you were reworking the plot line, on the other hand, the results could be less usefulâperhaps you added a paragraph on one branch that depends on details contained in a later paragraph that was deleted on another branch. Even if the contents are programming source code, such a merge is not guaranteed to be useful. You could change two separate subroutines in a way that causes them to fail when actually used; they might now make incompatible assumptions about some shared data structure, for example. Git doesnât even check to see that your code still compiles; thatâs up to you.
Within these limitations, though, Git has very sophisticated mechanisms for presenting merge conflicts and helping you to resolve them. It is optimized for the most common use case: line-oriented textual data, often in computer programming languages. It has different strategies and options for determining âmatchingâ portions of files, which you can use when the defaults donât produce adequate results. You can interactively choose sets of changes to apply, skip, or further edit. To handle complex merges, Git works smoothly with external merge tools such as araxis, emerge, and kdiff, or with custom merge tools you write yourself.
Merging History
When Git has done what it can automatically, and you have resolved any remaining conflicts, itâs time to commit the result. If we just make a commit to the current branch as usual, though, weâve lost critical information: the fact that a merge occurred at all, and which branches were involved. You might remember to include this information in the commit message, but itâs best not to depend on that; more importantly, Git needs to know about the merge in order to do a good job of merging in the future. Otherwise, the next time you merge the same branches (say, to periodically update one with continuing changes on the other), Git wonât know which changes have already been merged and which are new. It may end up flagging as conflicts changes you have already considered and handled, or automatically applying changes you previously decided to discard.
The way Git records the fact of a merge is very simple. Recall from The Object Store that a commit has a list of zero or more âparent commits.â The initial commit in a repository has no parents, and a simple commit to a branch has just one. When you commit as part of a merge, Git lists the tip commits of all branches involved in the merge as the parents of the new commit. This is in fact the definition of a âmerge commitâ: a commit having more than one parent. This information, recorded as part of the commit graph, allows visualization tools to detect and display merges in a helpful and unambiguous way. It also lets Git find an appropriate base version for comparison in later merging of the same or related branches when they have diverged again, avoiding the duplication mentioned earlier; this is called the âmerge base.â
Push and Pull
You use the commands git pull and git push to update the state of one repository from that of another. Usually, one of these repositories was cloned from the other; in this context, git pull updates my clone with recent work added to the original repository, whereas git push contributes my work in the other direction.
There is sometimes confusion over the relationship between a repository and the one from which it was cloned. Weâre told that all repositories are equal, yet there seems to be an asymmetry in the original/clone relationship. Pulling automatically updates this repository from the original, so how interconnected are they? Will the clone still be usable if the original goes away? Are there branches in my repository that are somehow pointers to content in another repository? If so, that doesnât sound as if theyâre truly independent.
Fortunately, as with most things in Git, the situation is actually very simple; we just need to precisely define the terms at hand. The central thing to remember is that with regard to content, a repository consists of two things: an object store and a set of refsâthat is, a commit graph and a set of branch names and tags that call out those commits that are of interest. When you clone a repository, such as with git clone server:dir/repo, hereâs what Git does:
- Creates a new repository.
Adds a remote named âoriginâ to refer to the repository being cloned in .git/config:
[remote "origin"] fetch = +refs/heads/*:refs/remotes/origin/* url = server:dir/repoThe
fetchvalue here, called a refspec, specifies a correspondence between sets of refs in the two repositories: the pattern on the left side of the colon names refs in the remote, and the spec indicates with the pattern on the right side where the corresponding refs should appear in the local repository. In this case, it means: âKeep copies of the branch refs of the remoteoriginin its local namespace in this repository,refs/remotes/origin/.â-
Runs
git fetch origin, which updates our local refs for the remoteâs branches (creating them in this case), and asks the remote to send any objects we need to complete the history for those refs (in the case of this new repository, all of them). -
Finally, Git checks out the remoteâs current branch (its HEAD ref), leaving you with a working tree to look at. You can select a different initial branch to check out with
--branch, or suppress the checkout entirely with-n.
Suppose we know the other repository has two branches, master and beta. Having cloned it, we see:
$ git branch
* master
Very well, weâre on the master branch, but whereâs the beta branch? It appears to be missing until we use the --all switch:
$ git branch --all
* master
remotes/origin/HEAD -> origin/master
remotes/origin/master
remotes/origin/beta
Aha! There it is. This makes some sense: we have copies of the refs for both branches in the origin repository, just where the origin refspec says they should be, and there is also the HEAD ref from the origin, which told Git the default branch to check out. The curious thing now is: what is this duplicate master branch, outside of origin, that is the one weâre actually on? And why did we have to give an extra option to see all these in the first place?
The answer lies in the purpose of the origin refs: theyâre called remote-tracking refs, and they are markers showing us the current state of those branches on the remote (as of the last time we checked in with the remote via fetch or pull). In adding to the master branch, you donât want to actually directly update your tracking branch with a commit of your own; then it would no longer reflect the remote repository state (and on your next pull, it would just discard your additions by resetting the tracking branch to match the remote). So, Git created a new branch with the same name in your local namespace, starting at the same commit as the remote branch:
$ git show-ref --abbrev master
d2e46a81 refs/heads/master
d2e46a81 refs/remotes/origin/master
The abbreviated SHA-1 values on the left are the commit IDs; note that they are the same, and recall that refs/heads/ is the implicit namespace for local branches. Now, as you add to your master branch, it will diverge from the remote master, which reflects the actual state of affairs.
The final piece here is the behavior of your local master branch in regard to the remote. Your intention is presumably to share your work with others as an update to their master branches; also, youâd like to keep abreast of changes made to this branch in the remote while youâre working. To that end, Git has added some configuration for this branch in .git/config:
[branch "master"]
remote = origin
merge = refs/heads/masterThis means that when you use git pull while on this branch, Git will automatically attempt to merge in any changes made to the corresponding remote branch since the last pull. This configuration affects the behavior of other commands as well, including fetch, push, and rebase.
Finally, Git has a special convenience for git checkout if you try to check out a branch that doesnât exist, but a corresponding branch does exist as part of a remote. It will automatically set up a local branch by the same name with the upstream configuration just demonstrated. For example:
$ git checkout beta Branch beta set up to track remote branch beta from origin. Switched to a new branch 'beta' $ git branch --all * beta master remotes/origin/HEAD -> origin/master remotes/origin/beta remotes/origin/master
Having explained remote-tracking branches, we can now say succinctly what the push and pull operations do:
-
git pull Runs
git fetchon the remote for the current branch, updating the remoteâs local tracking refs and obtaining any new objects needed to complete the history of those refs: that is, all commits, tags, trees, and blobs reachable from the new branch tips. Then it tries to update the current local branch to match the corresponding branch in the remote. If only one side has added content to the branch, then this will succeed, and is called a fast-forward update since one ref is simply moved forward along the branch to catch up with the other.If both sides have committed to the branch, however, then Git has to do something to incorporate both versions of the branch history into one shared version. By default, this is a merge: Git merges the remote branch into the local one, producing a new commit that refers to both sides of the history via its parent pointers. Another possibility is to rebase instead, which attempts to rewrite your divergent commits as new ones at the tip of the updated remote branch (see Pull with Rebase).
-
git push - Attempts to update the corresponding branch in the remote with your local state, sending any objects the remote needs to complete the new history. This will fail if the update would be nonâfast-forward as described earlier (i.e., would cause the remote to discard history), and Git will suggest that you first pull in order to resolve the discrepancies and produce an acceptable update.
Notes
-
It should be clear from this description that nothing about the remote-tracking branches ties the operation of your repository to the remote. Each is just a branch in your repository like any other branch, a ref pointing to a particular commit. They are only âremoteâ in their intention: they track the state of corresponding branches in the remote, and they are periodically updated via
git pull. -
It can be momentarily confusing if you clone a repository, use
git logon a branch you know is in the remote, and it failsâbecause you donât have a local branch by that name (yet); itâs only in the remote. You donât have to check it out and set up a local branch just to examine it, though; you can specify the remote-tracking branch by name:git log origin/foo. -
A repository can have any number of remotes, set up at any time; see git-remote(1). If the original repository you cloned from is no longer valid, you can fix the URL by editing .git/config or with
git remote set-url, or remove it entirely withgit remote rm(which will remove the corresponding remote-tracking branches as well).
Get Git Pocket Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

