In Chapter 3, we examined the basics of creating documents in a CouchDB database. Documents are where you store the data, but the only way to get the information back out from your documents is to know the document ID you used to store the document. There are a few different issues with the document structure that you may want to consider, such as enforcing document structure, handling document validation, and searching and querying the document data.
The key to all of these different types of information, and many others, is the design document. Aside from the core document storage, the design document is probably the most important component of your CouchDB database. Design documents contain all of the database logic about the document you are storing. Think of the design document as the glue that turns each of your documents into the format or structure that you need for your application.
The different components of your design document are written using JavaScript and they are executed within the CouchDB application. Because they are code, you can perform almost any action that would perform with JavaScript on an object. This means that you can select fields and components, perform test, reformat, calculate, and many other operations. This is useful as the different components of the design document work together to support the different formatting, indexing, and other procedures.
To be more specific, a design document provides the following:
- Views
Views are functions that take your document data and produce searchable lists of information based on the documentâs contents. Views are incredibly simple yet also very powerful and provide the main route of entry into your data for information for which you donât know the document ID.
- Shows
A show converts a single document into another format, usually HTML, although you can output the document in any format, including JSON or XML, to suit your application. Shows can also be used to simplify the JSON content of a document into a simpler or reduced format.
- Lists
A list is to a view (or collection of documents) as a show is to a single document. You can use a list to format the view as an HTML table, or a page of information or as XML of your document collection. In this way, a list acts as a transform on the entire content on the view into another format.
- Document validation
Because you can store any JSON document in your database, one of the issues is maintaining consistency. This is what the document validation functions solve. When you save a document into CouchDB, the validation function is called, and it can either check or even reformat the incoming document to meet your requirements and standards for different documents.
- Update handlers
Update handlers can be used to perform an action on a document when the document is updated. Unlike document validation, update handlers are explicitly called, but they can be used to make changes to a document within the server without having to retrieve the document, change it, and save it back (as would be required for a client process). For example, you can use update handlers to increment values in a document, or add and update timestamps.
- Filters
When exchanging information between CouchDB databases when using replication or the changes feed, you may want to filter the content of the database. For example, if you store information about your CD and DVD collection in a single database, you may want to exchange only the CD records with another database. This is what a filter function is for: when called, it examines the list of supplied documents from the replication or changes feed and then either returns the document or null.
Design documents are basically just like any other document within a
CouchDB database; that is, a JSON structure that you can create and update
using the same PUT and POST HTTP operations. The difference is that they
are located within a special area of each database (_design), and they are processed and accessed
differently when you want to actually execute the functional
components.
Itâs also worth pointing out at this stage that any database can have zero or more design documents. There are no limits to the number of design documents that you have, although from a practical perspective itâs unlikely that youâll have more than 10 for most databases, especially since for many of the design document components you can have more than one definition in each design document.
For the moment, we will examine how to create and update design documents, followed by the three main areas of design document functionality, shows, views, and lists.
For some of the examples in this chapter weâre going to be working with a database of recipes. The document data contains recipe data, cooking times, ingredient lists, method lists, and keywords. An example of the recipe document for Beef In Red Wine is shown below:
{
"_id": "Beefinredwine",
"_rev": "1-7098492ad814129ea8f026267a12650b",
"preptime": "15",
"servings": "4",
"keywords": [
"diet@peanut-free",
"main ingredient@meat.beef",
"special collections@cheffy recommended",
"diet@corn-free",
"special collections@weekend meal",
"occasion@entertaining",
"diet@citrus-free",
"special collections@very easy",
"diet@shellfish-free",
"meal type@main.stews, casseroles, curries",
"cuisine@european.french",
"cook method.hob, oven, grill@hob / oven",
"special collections@basic cooking",
"diet@egg-free",
"occasion@prepare-ahead entertaining"
],
"subtitle": "Beef and mushrooms in a rich and warming casserole.",
"totaltime": "144",
"cooktime": "129",
"ingredients": [
{
"ingredient": "red wine",
"measure": "450 ml"
},
{
"ingredient": "pickling onions",
"measure": "225 g"
},
{
"ingredient": "garlic",
"measure": "1"
},
{
"ingredient": "bay leaf",
"measure": "1"
},
{
"ingredient": "beef braising steak",
"measure": "450 g"
},
{
"ingredient": "rindless streaky bacon",
"measure": "4 rashers"
},
{
"ingredient": "plain flour",
"measure": "25 g"
},
{
"ingredient": "vegetable oil",
"measure": "3 tsp"
},
{
"ingredient": "button mushrooms",
"measure": "225 g"
},
{
"ingredient": "butter",
"measure": "15 g"
},
{
"ingredient": "seasoning",
"measure": ""
}
],
"method": [
{
"step": "1",
"text": "Preheat oven to 180°C."
},
{
"step": "2",
"text": "Melt the butter and oil in a large heatproof ovenproof casserole. Add the onions. Fry for 2-3 min or until well browned. Remove from pan with a slotted spoon. Set aside. Keep warm."
},
{
"step": "3",
"text": "Add the garlic, braising steak and bacon to the pan. Fry for 5 min, stirring frequently until well browned. Remove from the pan with a slotted spoon. Set aside with the onions."
},
{
"step": "4",
"text": "Add the flour to the pan. Cook, stirring, for 1 min. Gradually add the red wine, stirring frequently until all is incorporated. Bring to the boil."
},
{
"step": "5",
"text": "Return the onion and meats to the pan with the mushrooms, bay leaf and seasoning. Return to the boil. "
},
{
"step": "6",
"text": "Place in oven and cook for 1 hour 30 min until beef is tender."
}
],
"title": "Beef in red wine"
}The basic format of the design document is a JSON document with a field for each of the major content types (view, list, shows). Depending on the type, the definition then contains one or more further definitions. For example, you can define more than one view in a single design document. Letâs have a look at a sample design document to make that clearer:
{
"language": "javascript",
"views": {
"all": {
"map": "function(doc) { emit(doc.title, doc) }",
},
"by_title": {
"map": "function(doc) { if (doc.title != null) emit(doc.title, doc) }",
},
"by_keyword": {
"map": "function(doc) { for(i=0;i<doc.keywords.lenghth();i++) { emit(doc.keywords[i], doc); } }",
},
},
"shows": {
"recipe": "function(doc, req) { return '<h1>' + doc.title + '</h1>' }"
}The above example provides a simple design document that defines
three views (more in a moment) and a single show. You can see the
structure here with the views collected together, with a single view,
such as by_title, being defined
individually. Similarly, the one show, recipe, is part of the shows block.
Note
Technically, CouchDB supports design documents written in languages other than the default embedded JavaScript. You can, for example, use Erlang (the native language used to build CouchDB itself), or indeed any language providing CouchDB is configured correctly. For simplicity, weâll use JavaScript for our examples.
You can save this document into a file and then upload this to the
CouchDB design documents area of the recipe database using the same
methods as you would for a typical document. The difference is in the
document ID. All design documents are located within the _design section of the database. They must
also have a fixed name; unlike standard documents, you cannot let
CouchDB name the design document for you. That means that when creating
the document, you must use a PUT request. For example, using curl, you
would use:
curl -X PUT -d @recipes_view.js 'http://localhost:5984/recipes/_design/recipes'
The @ tells curl to load the
data from a file (recipes_view.js).
The URL used specifies the design document area of the database recipes, here calling the design document
itself recipes, too.
Now that the design document has been created, you could access all of the different operations (views and shows in this case). Thereâs nothing you need to do to enable or start the functions from working. Once the design document has been uploaded, CouchDB can start making use of it.
The remainder of the interaction with the design document definition is the same as with a standard document. You can retrieve the design document definition by doing a GET on the design document URL:
curl -X GET 'http://localhost:5984/recipes/_design/recipes'
{
"views" : {
"by_keyword" : {
"map" : "function(doc) { for(i=0;i<doc.keywords.lenghth();i++) { emit(doc.keywords[i], doc); } }"
},
"by_title" : {
"map" : "function(doc) { if (doc.title != null) emit(doc.title, doc) }"
},
"all" : {
"map" : "function(doc) { emit(doc.title, doc) }"
}
},
"language" : "javascript",
"_id" : "_design/recipes",
"_rev" : "1-b41a673ce62351a2c629734d4dc220f9",
"shows" : {
"recipe" : "function(doc, req) { return '<h1>' + doc.title + '</h1>' }"
}
}The JSON returned here is formatted for clarity, but you can see
that we get the entire document definition back again, plus the
_id and _rev fields automatically
added by CouchDB. Note here that the _id field is
_design/recipes, the URL path of the
design document as it was stored into the system.
The _rev parameter should be familiar. If we
want to update the definition of the design document, we need to supply
that parameter just as we did when updating a typical document. Updates
use PUT, and you must put the current revision into the
_rev field of the submitted update. For
example:
/usr/bin/curl -X PUT -H 'Content-type: application/json' \
-d '{"_rev":"1-b41a673ce62351a2c629734d4dc220f9"}' \
'http://localhost:5984/recipes/_design/recipes'This deliberately inserts an empty design document with no definitions just to demonstrate.
Finally, you can delete the design document using the HTTP DELETE operation:
curl -X DELETE -H 'Content-type: application/json' \
'http://localhost:5984/recipes/_design/curlrecipes?rev=3-2d1bca110ccd7263a9f10c79e0de74a7'As you can see, the main operations are the same as for any other document. The only difference is that the content has some functional basis. Letâs start by looking at how shows operate.
Beyond the basic operations of adding and updating records in the database, the most likely operation on a single stored document is that you will want to display the contents. This is the role of a show. A show takes the content of a document and formats it for output.
Notice the word I used wasnât for âdisplayâ. Although you can use a show for that, shows can be used to output information in any format you want from the document content. You can choose to output some of the document, all of it, or even restructure the document entirely. Because the output is just a text string, that means you can reformat the content as XML, a tab delimited string, even as a UUencoded string if that is what you need.
As you saw in the earlier examples, a show is just a JavaScript function. The function itself is supplied two arguments, the document requested to be processed by the show, and the request object (part of standard JavaScript) that generated the request.
In reality, that means that a basic definition looks like this:
function(doc,req) {
}Anything that the function returns is treated as the output that will be returned to the client. Letâs look back at the earlier example recipe, now just looking at the one show:
{
"shows": {
"recipe" : "function (doc,req) { return '<h1>' + doc.title + '</h1>'}"
}
}The above will output the title field from the supplied document
enclosed in the HTML H1 tag. If you upload this to the server as the
design document recipes/_design/detail then you can access the
show (that is, process a document created in the last chapter, Lasagne,
using the show definition) using the following URL:
GET http://localhost:5984/recipes/_design/detail/_show/recipe/Lasagne
The URL bears some scrutiny. The first part is the name of the database, ârecipesâ. The second part states that are access a design document, and the third the name of the design document is detail. Then we specify that we are accessing a show called recipe, and that the document ID of the document that we want to process is called Lasagne.
We can describe that more clearly by using a placeholder URL:
http://localhost:5984/DBNAME/_design/DESIGNDOCID/_show/SHOWNAME/DOCID
The output from the request should be the document title (Lasagne) embedded in the H1 tags:
<h1>Lasagne</h1>
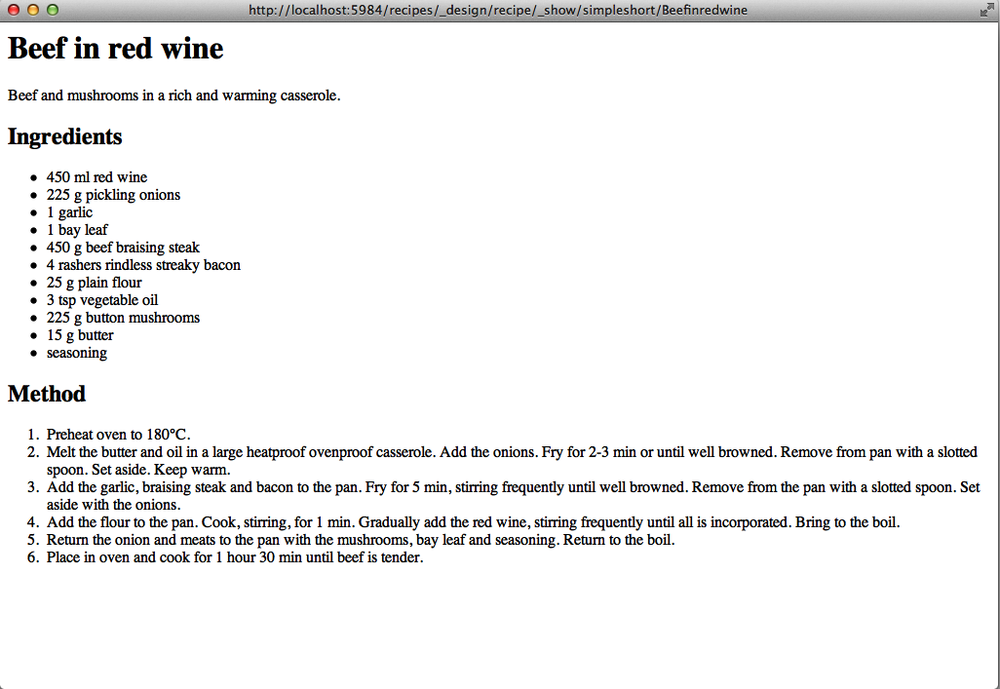
This is pretty boring, but this is a JavaScript function, so we can actually output something more detailed. Letâs try generating a more traditional looking recipe with an updated function:
function(doc, req) {
var output;
output = '<h1>' + doc.title + '</h1>';
output += '<p>' + doc.subtitle + '</p>';
output += '<h2>Ingredients</h2><ul>';
for(i=0;i<doc.ingredients.length;i++) {
output += '<li>' + doc.ingredients[i].measure + ' ' +
doc.ingredients[i].ingredient + '</li>';
}
output += '</ul><h2>Method</h2><ol>';
for(i=0;i<doc.method.length;i++) {
output += '<li>' + doc.method[i].text;
}
output += '</ol>';
return output;
}This will generate a recipe, with the subtitle, and then iterate over the ingredients and method steps to produce a fully displayed recipe, as shown in Figure 4-1.
In this case, the output is assumed by CouchDB to be HTML (i.e.,
with a content type of text/html) and
UTF-8 formatting.
This native HTML output is useful, but you can be more explicit. The return can just be a string, but you can also return a JSON object that contains both the returned data and other meta information, such as the HTTP header information so that you can specify the content type. This can be useful if you want to ensure that a document formatted as XML through the show function is correctly reported to the client.
To achieve this, rather than returning a string, you return a JSON structure containing the body and header information:
function(doc, req) {
return {
'body':'<recipe><title>' + doc.title + '</title></recipe>',
'headers' : {
'Content-type': 'application/xml'
}
}
}
We can put that into the design document as another show:
{
"shows": {
"recipe": "function(doc, req) { var output; output = '<h1>' + doc.title + '</h1>'; output += '<p>' + doc.subtitle + '</p>'; output += '<h2>Ingredients</h2><ul>'; for(i=0;i<doc.ingredients.length;i++) { output += '<li>' + doc.ingredients[i].measure + ' ' + doc.ingredient\
s[i].ingredient + '</li>';} output += '</ul><h2>Method</h2><ol>'; for(i=0;i<doc.method.length;i++) { output += '<li>' + doc.method[i].text } output += '</ol'; return output; }",
"asxml": "function(doc, req) { return { 'body':'<recipe><title>' + doc.title + '</title></recipe>', 'headers' : {'Content-type': 'application/xml'}}}"
}
}From a client, you can access the XML version of the document by
using the asxml show. For
example:
GET http://127.0.0.1:5984/recipes/_design/detail/_show/asxml/Beefinredwine <recipe><title>Beef in red wine</title></recipe>
Now you can see how different design documents and their functionality can be grouped together to produce different sets of functionality and information.
The final part of the show functionality is the ability to process the request information. This is the second argument supplied to the show function. The request object contains all of the information about the original request that accessed the show of the document. This includes any HTTP headers, client addresses, and query arguments to the URL request. You can use this information to make decisions about the format or content of the show function. Thatâs beyond the scope of this discussion.
Once you have started using shows, the most common question is how you get another document so that it can be included in the output. You canât. However, you can access multiple documents and then produce multiple outputs of this information. To start doing that, you need to understand views.
Up to now weâve made some assumptions about how you want to use the information in your database. Primarily, weâve discussed how to store information in the database using a document ID, how to update and manipulate that document, and how to use shows.
To search and aggregate information stored within your CouchDB database, you need to write a view. Views convert the individual documents in your database into a list of information. From that list, you can query and select information from the view, and search and find groups and individual documents.
A view does exactly what the name suggests: it creates a view on your data. That makes it sound incredibly simple, and in fact it really is, but the simplicity also gives the whole process a lot of power.
In fact, views form the basis of a number of key elements of the way CouchDB displays, sorts, and searches information. The main uses of views are:
Indexing and querying information stored in your documents
Producing lists of data on specific elements of a document
Producing tables and lists of information summarizing document data
Extracting or filtering information from your documents
Calculating, summarizing, or reducing large numbers of documents
Views are designed within the views section of your design document. You can create multiple views and multiple design documents to create different views and summaries of your information.
The first thing you need to know about views is that creating a view also creates an index. The contents of the index are made up of the information that the view generates. The index is in the form of a B-Tree index, which in turn makes the process of retrieving information very quick. How the information in the index is created is determined by the view definition.
The view definition consists of two Javascript functions, the map function, and the reduce function. Therefore, CouchDB supports map/reduce. Map/reduce systems have become popular recently because they allow for very large quantities of information to be processed (and reduced) very quickly and efficiently into the information you need. For the moment, letâs concentrate on the map function.
When you create a view, every document in your database is sent to the map function, which is primarily responsible for mapping the information stored within each document into the generated view content. This is composed of three parts: the document ID from which the row of output was generated, the key (which we can use to query and retrieve information), and the value. All of this information is stored in the index, allowing you to very quickly retrieve specific information stored in your database without having to individually load documents.
Letâs have a look at a sample map function to process our recipe content:
function(doc) {
if (doc.title != null)
emit(doc.title, null)
}Letâs dissect that function just a little. The function takes a single argument, the document being supplied. Remember, a view is generated by CouchDB, sending each document in the database to the view.
The embedded if checks to
ensure that we have a valid document. In this case, weâre ensuring
that the document has a title since this view outputs the recipe by
its title.
The emit() function is
built-in; it generates one row of information from the map function
consisting of the key and the value. The key in this case is the
document title, and the value null (empty).
Views are defined within the views section of your design document. For example:
{
"views": {
"by_title": {
"map": "function(doc) { if (doc.title != null) emit(doc.title, null) }"
},
}Here our view is called by_title. If the design document is called
simple then we can access the view
using the following URL:
http://127.0.0.1:5984/recipes/_design/simple/_view/by_title
The view information generated by this will look similar to the following:
{D
"total_rows" : 2667,
"rows" : [
{
"value" : null,
"id" : "Aberffrawcake",
"key" : "Aberffraw cake"
},
{
"value" : null,
"id" : "Adukiandorangecasserole-microwave",
"key" : "Aduki and orange casserole - microwave"
},
{
"value" : null,
"id" : "Aioli-garlicmayonnaise",
"key" : "Aioli - garlic mayonnaise"
}
],
"offset" : 0
}The output has been trimmed in this example. You can see that
each call to the emit() function
has created a single row, containing the implied document ID, key
(first argument), and value (second argument).
Accessing a view is significant within CouchDB. To keep the speed of the database when creating and writing documents, the index for a view is not updated when the document is written. This is because, in real terms, this is not the point at which indexing is really useful. The update doesnât need or use the update. Instead, when you access a view, the view is generated and the index is updated.
The first time you access a new view on a database, the entire contents of the database are processed through the view. If you then update, delete, and add new records and access the view again, only the changed documents are updated in the generated index. Obviously if you have a lot of documents in your database then the first time you hit the view, it will take some time to create the index. But the update process is comparatively small.
Itâs also worth noting that the B-Tree created from a view, and view creation in detail, is tied to the design document. If you define 10 views in your design document then CouchDB will supply each updated document to all 10 views in your design document and update the index, even though you only accessed a single view.
The main benefit of the indexing and B-Tree used for storing the information is that B-Trees are incredibly efficient at pulling out an item based on a single key, or a range of keys, for example, all the recipes from Casserole to Granola.
The information generated by the view can be queried because the generated view has a few properties that may not be immediately obvious. First and foremost, the information output by the view is automatically sorted by its UTF-8 value. You can also specify in the URL that all the view return outputs everything starting from a specific UTF-8 string.
For example, if you wanted to output all of the recipes that have a title starting with âApricotâ then you can use the following URL:
http://127.0.0.1:5984/recipes/_design/simple/_view/by_title?startkey=%22Apricot%22
Note that the startkey value has to be a JSON value, in this case a quoted string. The generated information is shown below:
{"total_rows":2667,"offset":54,"rows":[
{"id":"Apricotandcranberrystuffedlambroll","key":"Apricot and cranberry stuffed lamb roll","value":null},
{"id":"Apricotandoatcakes","key":"Apricot and oat cakes","value":null},
{"id":"Apricotandoatmealteabread","key":"Apricot and oatmeal tea bread","value":null},
{"id":"Apricotandprunestreuselcake","key":"Apricot and prune streusel cake","value":null},
{"id":"Apricotcheesecake","key":"Apricot cheesecake","value":null},
{"id":"ApricotChelseabuns","key":"Apricot Chelsea buns","value":null},
{"id":"Apricotcoconuttart","key":"Apricot coconut tart","value":null},
{"id":"ApricotEvespudding","key":"Apricot Eve's pudding","value":null},
{"id":"Apricotfreezerjam","key":"Apricot freezer jam","value":null},
{"id":"Arcticroll","key":"Arctic roll","value":null},
{"id":"Arcticsurprise","key":"Arctic surprise","value":null},
{"id":"Aromaticroastchicken","key":"Aromatic roast chicken","value":null},
...Well, weâve found a lot of Apricot recipes, but also some that obviously donât start with Apricot. The reason is that we havenât given a range. Weâve only specified that the output starts with the specified JSON string.
To do a range we need to specify the endkey. Because in this example we know that
the endkey is âArcticrollâ, we
could specify this in the URL, but we arenât always going to know what
the endkey is. If we want to
restrict it to those starting with Apricot, we can use the UTF-8
sorting to our advantage. If we add the UTF-8 character 007F to
âApricotâ, the range will only include recipes with the title starting
with Apricot, even if the document ID contains other characters. Letâs
see that in action:
http://127.0.0.1:5984/recipes/_design/simple/_view/by_title?startkey=%22Apricot%22&endkey=%22Apricot%007F%22
The resulting output contains exactly what we need:
{"total_rows":2667,"offset":54,"rows":[
{"id":"Apricotandcranberrystuffedlambroll","key":"Apricot and cranberry stuffed lamb roll","value":null},
{"id":"Apricotandoatcakes","key":"Apricot and oat cakes","value":null},
{"id":"Apricotandoatmealteabread","key":"Apricot and oatmeal tea bread","value":null},
{"id":"Apricotandprunestreuselcake","key":"Apricot and prune streusel cake","value":null},
{"id":"Apricotcheesecake","key":"Apricot cheesecake","value":null},
{"id":"ApricotChelseabuns","key":"Apricot Chelsea buns","value":null},
{"id":"Apricotcoconuttart","key":"Apricot coconut tart","value":null},
{"id":"ApricotEvespudding","key":"Apricot Eve's pudding","value":null},
{"id":"Apricotfreezerjam","key":"Apricot freezer jam","value":null}
]}Because you define the parameters and content of the view, you can use this to produce and support different methods of accessing and sharing the information. For example, what if you wanted to support accessing recipe information by using the ingredients from the recipe?
The emit() function we used in the original
view can be called multiple times within your map function, each
time outputting a row. Because each generated row contains the
attached value and the document ID that generated the row, we can
use this to query the recipe data by the ingredient, and get the
recipe information in return.
The view definition below shows a new view that emits a row of data based on the ingredient text by iterating over the ingredient list from each recipe document, and emitting each ingredient name.
function(doc) {
if (doc.ingredients) {
for(i=0;i<doc.ingredients.length;i++) {
emit(doc.ingredients[i].ingredient, null);
}
}
}Querying this using the same query values as last time, but
using the view by_ingredient, we get the
following list of recipes:
{
"total_rows" : 26468,
"rows" : [
{
"value" : null,
"id" : "Jamaicandelightcocktail",
"key" : "apricot brandy"
},
{
"value" : null,
"id" : "Appleandcinnamonpuffs",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Apricotcoconuttart",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Coffeeandgrapecheesecake",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Continentalmueslitorte",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Frenchappleflan",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Fruitybakedparcels",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "LastminuteChristmascake",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Normandybreadandbutterpudding",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Sachertorte",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Sultanacitrustruffles",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Trufflecake",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Welshgingercake",
"key" : "apricot jam"
},
{
"value" : null,
"id" : "Tropicaljuicecocktail",
"key" : "apricot juice"
}
],
"offset" : 1371
}Now we have all the recipes that contain some kind of apricot ingredient.
For a view like this, the chances are we are really looking
for a specific single value, such as Lemon Sole. In this case, we
can use the key argument to the
query:
http://127.0.0.1:5984/recipes/_design/simple/_view/by_ingredient?key=%22lemon%20sole%22
Which in turn outputs the recipes that contain Lemon Sole:
{
"total_rows" : 26468,
"rows" : [
{
"value" : null,
"id" : "Lemonsoleenpapillote",
"key" : "lemon sole"
},
{
"value" : null,
"id" : "Soleandsalmonfling",
"key" : "lemon sole"
},
{
"value" : null,
"id" : "Soleandsalmonroulade",
"key" : "lemon sole"
},
{
"value" : null,
"id" : "Soleduxelles",
"key" : "lemon sole"
}
],
"offset" : 14323
}So far weâve looked at single data points (Lemon Sole) and ranges (Apricots). But if you wanted to search by more complex means, such as all the recipes with Trout that take less than 10 minutes, then you need to construct a different view.
Although this sounds complicated, the reality is that for the vast majority of database queries, the actual query structure is the same, only the values differ. Once you have created your database, and then your views, you will eventually have developed the suite of views necessary to support the different query and list information that you need.
CouchDB supports this by allowing you to output a compound
type as the key generated by the emit() call. In
this case, letâs output an array containing the ingredient and the
recipe cooking time:
function(doc) {
if (doc.ingredients) {
for(i=0;i<doc.ingredients.length;i++) {
if (doc.ingredients[i].ingredient !== null)
emit([doc.ingredients[i].ingredient, parseInt(doc.cooktime)], null);
}
}
}This will output an array that contains the ingredient text and the cooking time. To query it, we need to provide a JSON value to the key parameters. So to perform our original query we might use:
http://127.0.0.1:5984/recipes/_design/recipe/_view/by_ingredient_time?startkey=%5B%22trout%22,0%5D&endkey=%5B%22trout%22,150%5D
This generates a list of all the recipes using trout that can be cooked in fewer than 10 minutes:
{
"total_rows" : 25215,
"rows" : [
{
"value" : null,
"id" : "Searedtroutbruschettawithhorseradish",
"key" : [
"trout",
3
]
},
{
"value" : null,
"id" : "Barbecuedtroutwithfennelbutter",
"key" : [
"trout",
6
]
},
...
],
"offset" : 23299
}Often the information that you are searching or reporting on needs to be summarized or reduced. There are a number of different occasions when this can be useful, for example, if you want to obtain a count of all the items of a particular type, such as comments, recipes matching an ingredient, or blog entries against a keyword.
Alternatively, views can be used for performing sums, such as totaling all of the invoice values for a single client, or totaling up the preparation and cooking times in a recipe.
In each of the above cases, the raw data is the information from
one or more rows of information produced by a call to emit(). The input data, each record
generated by the emit() call, is
reduced and grouped together to produce a new record in the
output.
A good example of reduction functions in action with our recipe
example is the sort of display typical when browsing recipes. Here you
might want to show recipes by their keyword, then provide a count of
the number of recipes by the keyword. The view uses the built-in
_count function:
"by_keyword": {
"map": "function(doc) { if (doc.keywords) { for(i=0;i<doc.keywords.length;i++) { emit(doc.keywords[i], null); } } }",
"reduce": "_count"
},When querying, we have to specify the group level (the default
is 0, which would provide a count of all the rows generated by
emit()). The query looks like this:
http://localhost:5984/recipes/_design/simple/_view/by_keyword?group_level=1
Note
The reduce function within a view is optional, but if defined,
the reduce function is automatically applied to the view output. You
can switch this off by adding the reduce=false option to the query.
The resulting view result looks like this:
{"rows":[
{"key":"convenience@add bread for complete meal","value":234},
{"key":"convenience@add jacket potato for a complete meal","value":110},
{"key":"convenience@add pasta for a complete meal","value":44},
{"key":"convenience@add rice for a complete meal","value":133},
{"key":"convenience@serve with salad for complete meal","value":214},
{"key":"cook method.hob, oven, grill@grill","value":135},
{"key":"cook method.hob, oven, grill@grill / oven","value":8},
{"key":"cook method.hob, oven, grill@hob","value":1036},
{"key":"cook method.hob, oven, grill@hob / grill","value":98},
{"key":"cook method.hob, oven, grill@hob / grill / oven","value":8},
{"key":"cook method.hob, oven, grill@hob / oven","value":469},
{"key":"cook method.hob, oven, grill@oven","value":361},
...The output is trimmed here, but you can see the recipe information has been grouped together by the keyword text, with the value showing a count of the recipes that include that keyword.
Letâs take a closer look at the internal workings, but simplify our data set slightly so that the process and calculations are easier. Weâll use this sample data:
{
"city" : "Paris",
"sales" : 13000,
"name" : "James",
},
{
"city" : "Tokyo",
"sales" : 20000,
"name" : "James",
},
{
"city" : "Paris",
"sales" : 5000,
"name" : "James",
},
{
"city" : "Paris",
"sales" : 22000,
"name" : "John",
},
{
"city" : "London",
"sales" : 3000,
"name" : "John",
},
{
"city" : "London",
"sales" : 7000,
"name" : "John",
},
{
"city" : "London",
"sales" : 7000,
"name" : "Adam",
},
{
"city" : "Paris",
"sales" : 19000,
"name" : "Adam",
},
{
"city" : "Tokyo",
"sales" : 17000,
"name" : "Adam",
}When using a reduce function the reduction is applied as follows:
For each record of input, the corresponding reduce function is applied on the row generated from the
emit()call in the map function. For example, using the following design document:{ "language": "javascript", "views": { "bynamecity": { "map": "function(doc) { emit([doc.name,doc.city],doc.sales)}", "reduce": "_sum" } } }The key is output using an array of both the name and the city for the sales. The reduce function uses the built-in
_sumfunction. Outputting the view without the reduce function produces the following information:{ "total_rows" : 9, "rows" : [ { "value" : 7000, "id" : "64f4057ad37fdd9bc2ccd808ca01c717", "key" : [ "Adam", "London" ] }, { "value" : 19000, "id" : "64f4057ad37fdd9bc2ccd808ca01d629", "key" : [ "Adam", "Paris" ] }, ... ], "offset" : 0 }Calling the view with reduction enabled, we receive a sum of all the records from the view:
{ "rows" : [ { "value" : 113000, "key" : null } ] }Results are grouped on the key from the call to
emit(). As shown in the previous example, the reduction operates by taking the key as the group value and using this as the basis of the reduction.By using an array as the key, you can group to multiple levels. There are times you may want to perform a reduction on a compound value. For example, on both the name of the salesman and the city in which they did their business. You can achieve this by using an array as your key and specifying the
group_levelparameter. Group level 1 uses the first element of the key array as the group value:{ "rows" : [ { "value" : 43000, "key" : [ "Adam" ] }, { "value" : 38000, "key" : [ "James" ] }, { "value" : 32000, "key" : [ "John" ] } ] }Group level 2 uses the first and second elements of the key array as the group value:
{ "rows" : [ { "value" : 18000, "id" : "James", "key" : ["James", "Paris"] }, { "value" : 20000, "id" : "James", "key" : ["James", "Tokyo"], }, ... ] }In this case, because the group level of 2 was specified, the first two elements of the array provided in the key have been used as the collation key.
You can also output null values within your
mapfunction, which can be used in combination with yourreducefunction to provide summary and grouping information to combine different information types into the output.
Whenever the reduce function is called, the generated view content contains the same key and value fields for each row, but the key is the selected group (or an array of the group elements according to the group level) and the value is the computed reduction value.
CouchDB includes three built-in reduce functions: _count, _sum, and _stats.
Reduce functions have one final trick up their sleeves: the results of the reduction are stored in the index along with the rest of the view information. This means that when accessing the result of a reduce function in your view is only accessing the index content, and therefore is very low impact compared to calculating the values live when the view is accessed.
The _count function
provides a simple count of the input rows from the map function, using the keys and group
level to provide to provide a count of the correlated items. The
values generated during the map()
stage are ignored.
Enabling the reduce()
function and using a group level of 1 would produce:
{
"rows" : [
{
"value" : 3,
"key" : [
"Adam"
]
},
{
"value" : 3,
"key" : [
"James"
]
},
{
"value" : 3,
"key" : [
"John"
]
}
]
}The reduction has produced a new result set with the key as an array based on the first element of the array from the map output. The value is the count of the number of records collated by the first element.
Using a group level of 2 would generate the following:
{
"rows" : [
{
"value" : 1,
"key" : [
"Adam",
"London"
]
},
{
"value" : 1,
"key" : [
"Adam",
"Paris"
]
},
{
"value" : 1,
"key" : [
"Adam",
"Tokyo"
]
},
{
"value" : 2,
"key" : [
"James",
"Paris"
]
},
{
"value" : 1,
"key" : [
"James",
"Tokyo"
]
},
{
"value" : 2,
"key" : [
"John",
"London"
]
},
{
"value" : 1,
"key" : [
"John",
"Paris"
]
}
]
}Now the counts are for the keys matching both the first two elements of the map output.
The built-in _sum functions
collates the output from the map
function call, this time summing up the information in the value for
each row. The information can either be a single number or an array
of numbers.
Note
The input values must be a number, not a
string-representation of a number. The entire Map/Reduce will fail
if the reduce input is not in the correct format. You should use
the parseInt() or parseFloat() function calls within your
map() function stage to ensure
that the input data is a number.
For example, using the same sales source data, accessing the group level 1 view would produce the total sales for each salesman:
{
"rows" : [
{
"value" : 43000,
"key" : [
"Adam"
]
},
{
"value" : 38000,
"key" : [
"James"
]
},
{
"value" : 32000,
"key" : [
"John"
]
}
]
}Using a group level of 2, you get the information summarized by salesman and city:
{
"rows" : [
{
"value" : 7000,
"key" : [
"Adam",
"London"
]
},
{
"value" : 19000,
"key" : [
"Adam",
"Paris"
]
},
{
"value" : 17000,
"key" : [
"Adam",
"Tokyo"
]
},
{
"value" : 18000,
"key" : [
"James",
"Paris"
]
},
{
"value" : 20000,
"key" : [
"James",
"Tokyo"
]
},
{
"value" : 10000,
"key" : [
"John",
"London"
]
},
{
"value" : 22000,
"key" : [
"John",
"Paris"
]
}
]
}The _stats built-in
produces statistical calculations for the input data. Like the
_sum call, the source information
should be a number. The generated statistics include the sum, count,
minimum (min), maximum (max), and sum squared (sumsqr) of the input rows.
Using the sales data, a slightly truncated output would be:
{
"rows" : [
{
"value" : {
"count" : 3,
"min" : 7000,
"sumsqr" : 699000000,
"max" : 19000,
"sum" : 43000
},
"key" : [
"Adam"
]
},
{
"value" : {
"count" : 3,
"min" : 5000,
"sumsqr" : 594000000,
"max" : 20000,
"sum" : 38000
},
"key" : [
"James"
]
},
{
"value" : {
"count" : 3,
"min" : 3000,
"sumsqr" : 542000000,
"max" : 22000,
"sum" : 32000
},
"key" : [
"John"
]
}
]
}The same fields in the output value are provided for each of the reduced output rows.
You can write your own reduce functions to produce custom reduction operations on your data. Custom reduce functions are easy to write, but you have to know a few of the rules for doing so. Probably the most important aspect to remember is that a reduce function may be called by itself to complete the reduction functionality. This process is called rereduce. The reduce function definition identifies this by using a third argument to the call to the reduce function:
function (key, values, rereduce) {
return sum(values);
}The function should return the values that you want to be returned by the reduction process.
The rereduce is a boolean value that is used to indicate when the reduce function is being called by itself (i.e., in rereduce mode). For a standard reduction (no rereduce, where rereduce is false), the arguments are:
Key will be an array, the elements of which are an array consisting of the key and document ID generated by the
emit()calls within your map functionValues is an array of the values generated from the value argument of your
emit()function call. This is an array of the values from the documents referenced in the keys elements.
For example, when performing the reduce on the sample sales data a reduction function might be provided with:
reduce([ [ "James", "James"], [ "Adam", "Adam" ], [ "John", "John" ] ],[ 13000, 5000, 10000 ], false);
Notice in the above that we have been provided the keys of three items, and the values of each corresponding item. Effectively this is equivalent to:
reduce([ [key1,id1], [key2,id2], [key3,id3] ], [value1,value2,value3], false)
If the function is being called in rereduce mode, then the rereduce value will be true, the keys will be null, and the values will be one or more values returned from the previous calls to the reduce function. For example:
reduce(null, [28000, 40000, 10000], true)
To put this into perspective, we can reproduce the
_sum built-in function like this:
function(keys,values,rereduce)
{
var sum = 0;
for(var idx in values) {
sum = sum + values[idx];
}
return sum;
}Here we just take each of the values in the array of values supplied, sum them together, and return them. In this case, the output information for a rereduce is irrelevant because the values will be in the same format. We return a simple value, which will be supplied as part of an array of values in the event of a rereduce.
However, it is possible to return compound values. For example, say you wanted to produce a view that provided both the count of the items, and the sum of the value. In this case, the reduce would process the raw values (sales), but the output would be the count and the sum of the values supplied. The function in this case would look like the following:
function(keys,values,rereduce) {
var count = 0;
var sum = 0;
if (rereduce) {
for(var idx in values) {
count = count + values[idx][0];
sum = sum + values[idx][1];
}
}
else {
for(var idx in values) {
count = count + 1;
sum = sum + values[idx];
}
}
return [count,sum];
}When the function is called merely as a reduce function, we can just count the entries and add up the values, but we return an array of the count and sum. In rereduce mode, we need to extract the values from the array returned by the reduce stage, hence the two different formats.
CouchDB has been designed to be fairly resilient to problems that you create within the views. In most cases, CouchDB will try to create the view definition even if there are occasional issues in the content and output format. For example, if you create a view that outputs a field where the field is not defined in a document, instead of completely failing to generate your view, CouchDB will output a null value for each document.
Mostly this is a huge help, because it ensures that minor errors donât completely defeat the benefits of defining your view. The downside is that it can sometimes be difficult to determine a problem if you find your view isnât generating the information you expect.
Errors generated by CouchDB are recorded in the CouchDB log, which you can access from within CouchDB using http://127.0.0.1:5984/_log.
If you want to monitor specific values within your views,
unfortunately, you cannot directly debug the progress and output,
but you can call the log() function to output
information in your views. This generates entries in your log file
prefixed by the Log tag:
[Mon, 31 Oct 2011 13:31:34 GMT] [info] [<0.31248.20>] OS Process #Port<0.7491> Log :: Root vegetables baked in cream with garlic [Mon, 31 Oct 2011 13:31:34 GMT] [info] [<0.31248.20>] OS Process #Port<0.7491> Log :: Carrot and thyme roulade with onion and garlic cream [Mon, 31 Oct 2011 13:31:34 GMT] [info] [<0.31248.20>] OS Process #Port<0.7491> Log :: Bacon and pesto pasta salad [Mon, 31 Oct 2011 13:31:34 GMT] [info] [<0.31248.20>] OS Process #Port<0.7491> Log :: Pork balls with tomato sauce and spaghetti
Before we move on, there is one final convenience facility for CouchDB views. Defining and uploading views for the purposes of testing can be a little time consuming and complex. To simplify the process, you can create a temporary view.
To use a temporary view, you submit the view information as
the HTTP body in a request to the _temp_view component for your database.
For example, we can rewrite the recipe by title view as a temporary
view using curl like this:
curl -X POST -H 'Content-type: application/json' \
http://127.0.0.1:5984/recipes/_temp_view \
-d '{"map": "function(doc) {emit(doc.title,null)}"}'Temporary views like this are only good for testing your view definition. The information is not sorted in any way (eliminating many of the benefits of the view) and because this process immediately executes the view on your data, the process is processor intensive.
When querying the view results, you can use the query arguments shown in the table below to limit and manipulate your query. Some of the key query parameters are:
descendingBy default, CouchDB sorts the keys and outputs the view in ascending order (i.e., A-Z). By specifying
descending=true, the view results will be output in descending order (i.e., Z-A).One artifact of this process is that if you are searching for a range of items then you must also reverse the startkey and endkey values, because the order in which CouchDB will reach has changed. For example, the query:
/recipes/_design/simple/_view/bytitle?startkey=Lasagne&endkey=Pasta
Should be written as:
/recipes/_design/simple/_view/bytitle?descending=true&endkey=Lasagne&startkey=Pasta
limitLimit the output the specified number of rows. For example, to limit the output to 10 rows:
/recipes/_design/simple/_view/bytitle?limit=10
skipSkip the specified number of rows before starting the output. For example:
/recipes/_design/simple/_view/bytitle?skip=100
CouchDB will process 100 rows of view output, and then only start outputting row values on the 101st row.
You can use this in combination with the
limitparameter to paginate through the output, but this is a relatively expensive operation, as CouchDB still actually accesses the row information.staleAllow stale views. Because CouchDB only rebuilds the view index; when the view is accessed, it can mean that there is a delay between requesting the view information and the output being generated, because the view index must be updated. If you are not worried about updating the view index (or including any records) since the last time the view was updated, you can use
stale=trueto use the existing view index and not update the view data. This is quicker, but may output stale information as it wonât include any of the recent document updates, deletions, and inserts since the view was last updated.
There are some other possible values and query arguments. Check The CouchDB API for more information.
Lists are to views what shows are to individual documents. In a very simple way they perform exactly the same function. They output the results from each row generated by a view, and transform it into any format you want. As with a show, you can use this to output as HTML, XML, formatted JSON, even CSV if that is what you need.
Unlike a show, a list has to deal with the slightly more complex information in the form of one or more rows of generated information, rather than just a single document.
The basics of the list function are similar to the view and show functions we have already seen. You can specify more than one list function in a design document. However, you must specify the list and the view that you are using to output information within the same design document.
The function definition for a list is as follows:
function(head, req) {}The head argument contains core
information about the view being supplied to the list function,
specifically itâs the information beyond the row data (i.e., the total
number of rows and the number of skipped, or offset, rows):
{
total_rows:2667,
offset:0
}The req is a much more complex
structure and contains all of the information about the request,
including any HTTP headers, stored cookie information for the domain,
security data, the request path, a UUID, client and server information,
and even database information for the database being accessed. This is
beyond the scope of this book, but for reference, the structure looks
like this:
{
"info" : {
"compact_running" : false,
"doc_count" : 2671,
"db_name" : "recipes",
"purge_seq" : 0,
"committed_update_seq" : 2719,
"doc_del_count" : 1,
"disk_format_version" : 5,
"update_seq" : 2719,
"instance_start_time" : "1319627005264155",
"disk_size" : 17121380
},
"headers" : {
"Connection" : "keep-alive",
"User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/534.51.22 (KHTML, like Gecko) Version/5.1.1 Safari/534.51.22",
"Cache-Control" : "max-age=0",
"Accept-Encoding" : "gzip, deflate",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language" : "en-us",
"Host" : "localhost:5984"
},
"userCtx" : {
"roles" : [
"_admin"
],
"db" : "recipes",
"name" : null
},
"query" : {
"limit" : "10"
},
"cookie" : {},
"form" : {},
"path" : [
"recipes",
"_design",
"simple",
"_list",
"by_title",
"by_title"
],
"uuid" : "64f4057ad37fdd9bc2ccd808ca01fbae",
"body" : "undefined",
"peer" : "127.0.0.1",
"id" : null,
"method" : "GET"
}Both the head and request information allow you to view and parse the request much more closely. For example, you can extract the query elements from the requested URL or a form to generate and output different information.
The core definition of the remainder of the list function is surprisingly straightforward. The function itself is called only once for the entire group of documents supplied to it. So, unlike a show, we have to manually iterate over the content.
To do that, we use the getRow() function in a
while statement to get each row of the generated
view. For example, to create a bulleted list of the recipes, with a link
to the show that will display them:
function (head,req) {
start({ "headers": {
"Content-type" : "text/html"
}
});
send('<ul>');
var row;
while (row = getRow()) {
send('<li><a href="/recipes/_design/detail/_show/recipe/'
+ row.id + '\">' + row.key + '</a></li>');
}
send('</ul>');
}In the above example, everything before the while is sent before the individual rows of
the view are processed. The start()
function is used to output the HTTP headers, in this case, an HTML
content type so that we can generate an HTML list. Then we output the
opening HTML bullet list tag.
The while block gets each row
of the generated view and puts it into the variable row. Remember that the output of a view is a
row of information in the form of the document ID, key, and value of the
generated information. Once the view data has been processed, we close
the HTML list.
The complete definition as part of a design document is shown below:
{
"language": "javascript",
"views": {
"by_title": {
"map": "function(doc) { if (doc.title != null) emit(doc.title, null) }"
}
},
"lists": {
"by_title": "function (head,req) { start({'headers': { 'Content-type': 'text/html' }}); send('<html><ul>'); var row; while(row = getRow()) { send('<li><a href=\"/recipes/_design/detail/_show/recipe/' + row.id + '\">' + row.key + '</a></li>'); } send('</ul></html>'); }"
},
"shows": {
"simple": "function(doc, req) { var output; output = '<h1>' + doc.title + '</h1>'; output += '<p>' + doc.subtitle + '</p>'; output += '<h2>Ingredients</h2><ul>'; for(i=0;i<doc.ingredients.length;i++) { output += '<li>' + doc.ingredients[i].measure + ' ' + doc.ingredients[i].\
ingredient + '</li>';} output += '</ul><h2>Method</h2><ol>'; for(i=0;i<doc.method.length;i++) { output += '<li>' + doc.method[i].text } output += '</ol'; return output; }"
}
}To access a list you use a URL of the format:
/DBNAME/_design/DESIGNDOC/_list/LISTNAME/VIEWNAME
In the above example we could access the view for the design
document simple:
http://localhost:5984/recipes/_design/simple/_list/by_title/by_title
The above design document becomes a completely self-contained
solution for querying, listing, and viewing recipes from the database.
The view outputs the recipe by their title. The list formats the recipes
as a nice HTML list, with each recipe as a link to the corresponding
show function to display the recipe
content.
Get Getting Started with CouchDB now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

