Chapter 4. Architecture
In this chapter we look in detail at how eXist is constructed and how it processes your XML documents and executes your XQueries. This information should be considered advanced, so if you are a beginner you may want to skip to another chapter. However, for those wishing to master eXist, this information can be invaluable in helping you understand how to use it efficiently.
eXist is a large software project that has evolved over the last 13 years, and is written predominantly in the Java programming language. Although extensions and add-ons to eXist are often written in pure XQuery and/or XSLT, the main body of eXist is written in Java.
Regardless of how you decide to deploy and use eXist, its architecture (see Figure 4-1) predominately remains the same, with various optional components depending on your use.
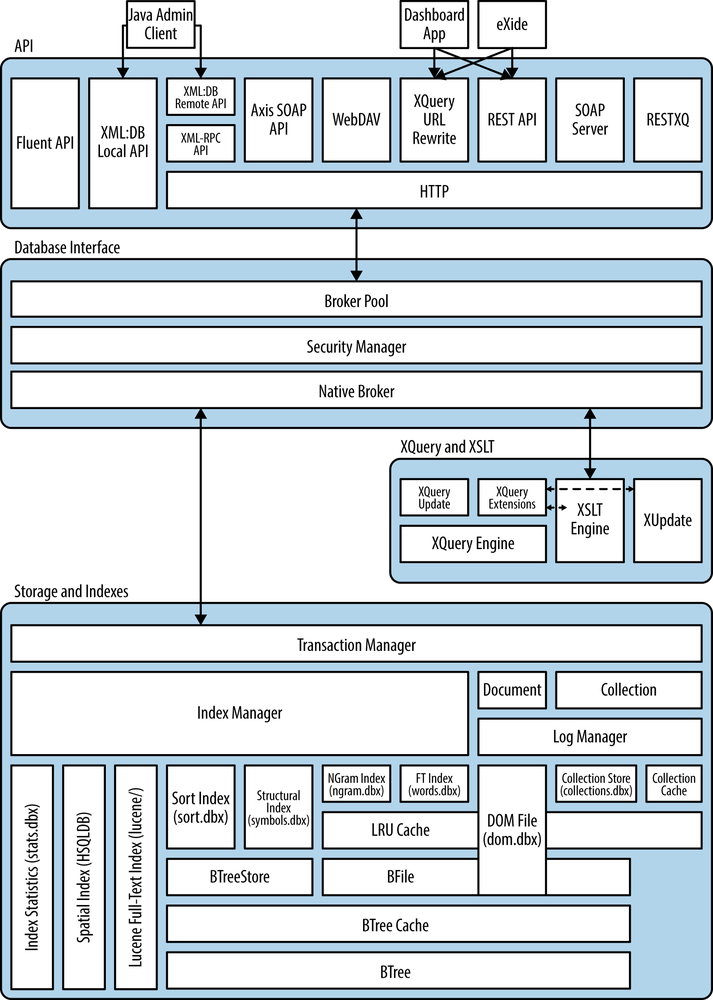
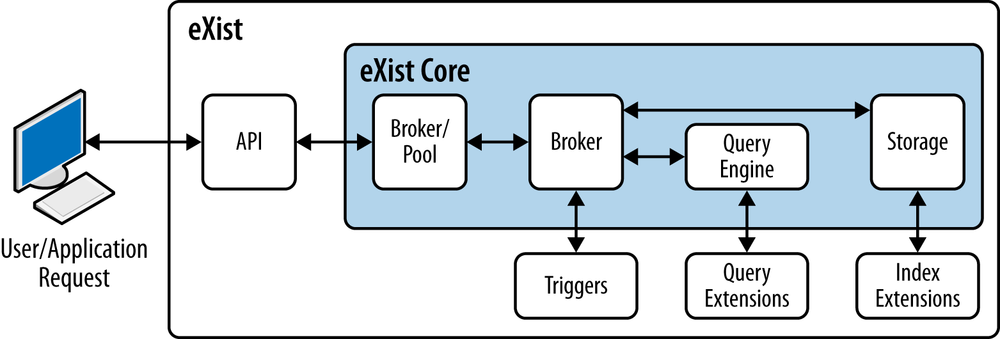
Each connection from an API to eXist is a single thread that interacts with the broker pool, which is configured with a number of brokers (20 by default). Each broker is a thread that interacts with the database, and represents a database request; this might be a database update operation (add/delete/store/update) or a query operation (XPath, XQuery, or XSLT). Should you connect to eXist and all the brokers are busy, your request will pause until a broker becomes available to service your request. Figure 4-2 shows this broker architecture.
Tip
If you are using eXist directly embedded within your own application, then you are responsible for deciding the threading model for interacting with the broker pool.
You can configure the number of brokers available in the broker pool
is configurable in $EXIST_HOME/conf.xml
in the attribute located by the XPath /*:exist/*:db-connection/*:pool/@max. You should
configure the number of brokers be configured to be slightly higher than
the expected number of concurrent connections to
eXist from your users.
Deployment Architectures
eXist offers many options for deployment. These options have informed the architecture of eXist, and depending on your deployment scenario, this will determine how much or how little of eXist you use and how the components of eXist are interconnected. eXist has three main faces—the first you may see only if your interaction with eXist is as a software developer, while the second two you may also see if you are an eXist user:
- An embedded native XML database library
eXist can be compiled as a set of libraries that can be directly embedded into your own application running on a JVM (Java Virtual Machine). In this instance you talk directly to eXist via Java function calls. See XML:DB Local API and Fluent API.
- A native XML database server
eXist can be deployed as a native XML database server, allowing you to store and manage both XML and binary documents and perform queries upon these documents across a network. This approach is similar to a classic client/server networked database architecture.
- A web application platform
This really builds upon the preceding item, but eXist provides so many web-oriented features and capabilities that it deserves a mention of its own. You can build entire web applications by writing very simple and powerful high-level web application code in XQuery, XForms, and XSLT, while eXist provides the HTTP glue and is able to serve these up as complete web applications.
Embedded Architecture
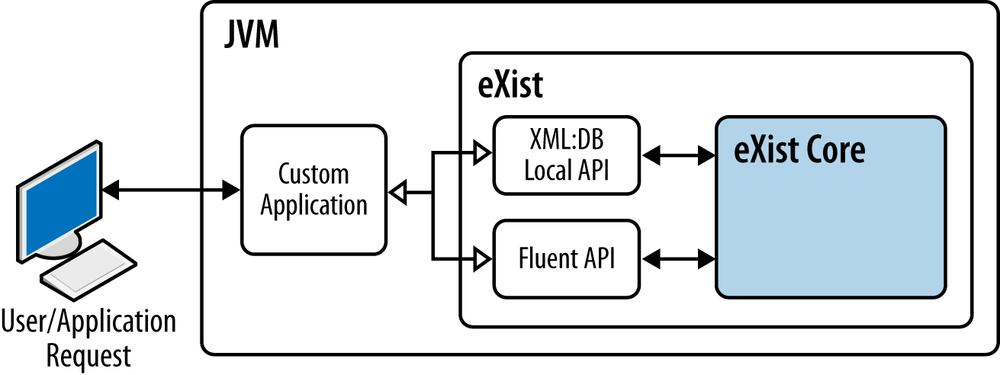
If you choose to embed eXist directly in your own application (see Local APIs), eXist operates as any other third-party library would; that is, you make function calls in your application upon the classes that make up eXist in order to perform various operations. When eXist is embedded in your application, you have two local APIs to choose from—either the XML:DB Local API (see XML:DB Local API) or the Fluent API (see Fluent API).
Warning
It is also possible to directly call eXist’s internal API functions; however, this is strongly discouraged, as you are then responsible for the correct locking and transaction management of resources, which is nontrivial to achieve correctly. In addition, these API functions are subject to change at any time.
Embedding eXist within your application (as shown in Figure 4-3) can be a suitable choice if you wish to release a convenient standalone application to your users that has advanced XML processing and query facilities.
Warning
The downside to embedding eXist within your own application rather than connecting to it as a server is a lack of isolated concerns. When eXist is embedded in a developer application, it runs within the same JVM instance, and thus the memory and resources available to the JVM are shared between both eXist and the developer application. Should a fault or design error exist within the developer application, this could potentially easily exhaust the resources or memory available to the JVM instance. This results in a lockup of the application and unpredictable behavior that is beyond the control of eXist. Such unpredictable behavior is not desirable when you’re operating a database system, as it can lead to stability issues and possibly data corruptions.
Client/Server Database Architecture
There is no fixed pattern for running eXist as a database server, as eXist offers many different options, but for the purposes of illustration we will assume that the database server architecture is akin to a classic client/server networked database. In the client/server networked database, users typically connect to a database server with a fat client application and/or communicate with the database server from custom applications by opening connections to the database across the network. In this architecture we will exclude the more web-oriented aspects of eXist, as they are more applicable to the next section, Web Application Platform Architecture.
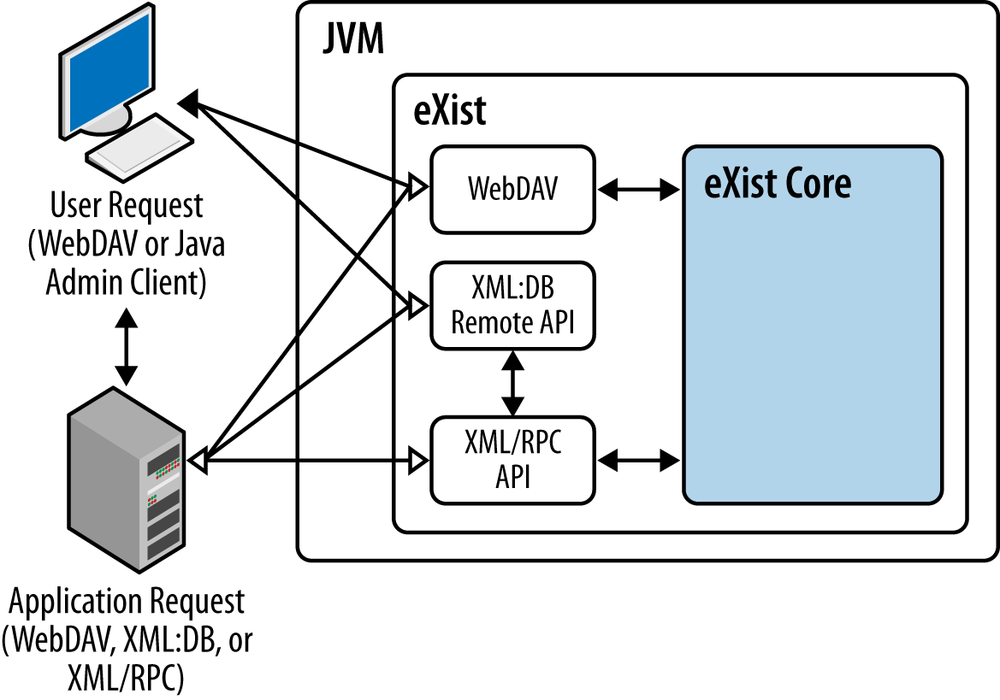
In the client/server database architecture eXist is deployed to a central server, and users are given access to the database by both the WebDAV and XML:DB Remote APIs (Figure 4-4). The WebDAV API allows users to directly manipulate documents in the database from their operating system’s file explorer just as if the files were in a local folder on their computer (see WebDAV). The XML:DB Remote API, on the other hand, allows users to connect to eXist from the Java Admin Client GUI (see XML:DB Remote API), from which they can manage the database and perform queries upon it. If you enable the XML:DB Remote API, XML-RPC (see XML-RPC API) also has to be enabled as a prerequisite, so application developers are free to develop applications that can talk to the database programatically using one or a combination of the WebDAV, XML:DB, or XML-RPC protocols.
Web Application Platform Architecture
When developing a web application, you typically have two domains of code, server-side and client-side. Server-side code is executed on the web application server itself (in this case eXist), while client-side code is executed by the client (typically a web browser).
eXist can serve as a complete web application platform whereby your applications are developed in one or more of the following server-side XML languages: XQuery, XSLT, XProc and XForms.
Upon receiving a web request from a client, eXist processes your server-side code and generates a response containing the results of processing (which may even include further client-side code) for the client. The response sent to the client could be anything, but typically will be in one or more of these formats: HTML5, XHTML, XML, JSON, XForms, CSS, or a variety of binary formats (e.g., images for display in a page).
To understand how to develop web applications with eXist, see Chapter 9. When eXist is deployed as a web application platform there are many components that you may or may not wish to use depending on your web application; however, it is recommended (as described in Reducing the Attack Surface ) that you disable those that you are not using. Regardless of your application, if you wish to use eXist as a web application platform, it will require the use of a Java web application server, and here you have two main choices for deployment:
- Jetty™ (default)
eXist ships with the Jetty Java web application server. This can be used with very little effort and is the recommended approach, as it is well understood and supported by the eXist community and developers. See Starting and Stopping eXist with a GUI.
- WAR file and third-party Java web application server
eXist can be built and deployed as a WAR file to your choice of Java web application server (e.g., Apache Tomcat, GlassFish, JBoss Application Server, etc.). This can work well if your organization is already heavily invested in particular technology. However, it is recommended that you run eXist solely in its own web application server; otherwise, it is potentially competing for resources with other applications in the same server. See Building eXist from Source.
Either way—whether you use the built-in Jetty or a third-party Java web application server—the web application platform architecture of eXist remains much the same (see Figure 4-5).
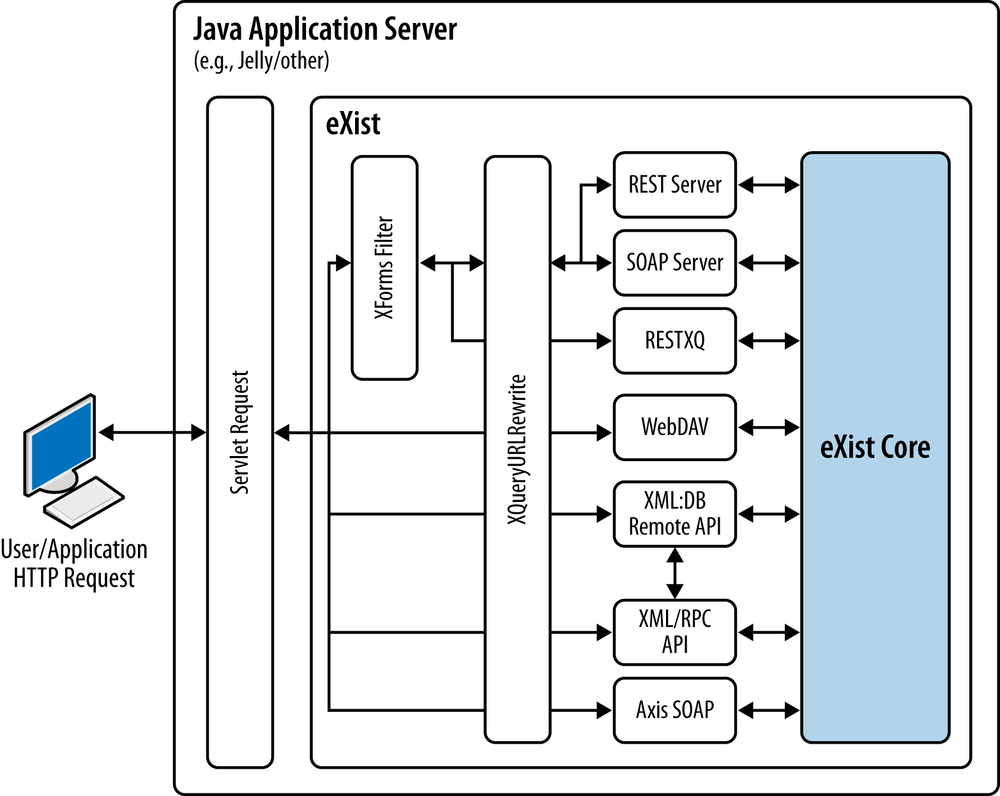
Note
Figure 4-5 should be interpreted as depicting that only the REST Server and SOAP Server services of eXist are directly manipulatable by the XQuery URL Rewrite facility (see URL Mapping Using URL Rewriting). However, it also shows that RESTXQ can be coupled with the XForms Filter, and while this is indeed the case and may be desirable, it is not enabled by default in eXist but may be configured easily.
Storage Architecture
So far we have mostly been looking at the high-level architecture of eXist depending on the type of application you wish to build with it. You should at least have a cursory understanding of how eXist structures its resources into Collections from reading Chapter 3 We will now look much more closely at the Storage Architecture of eXist, as you may be wondering: what happens when I actually store a document into eXist?
XML Document Storage and Indexing
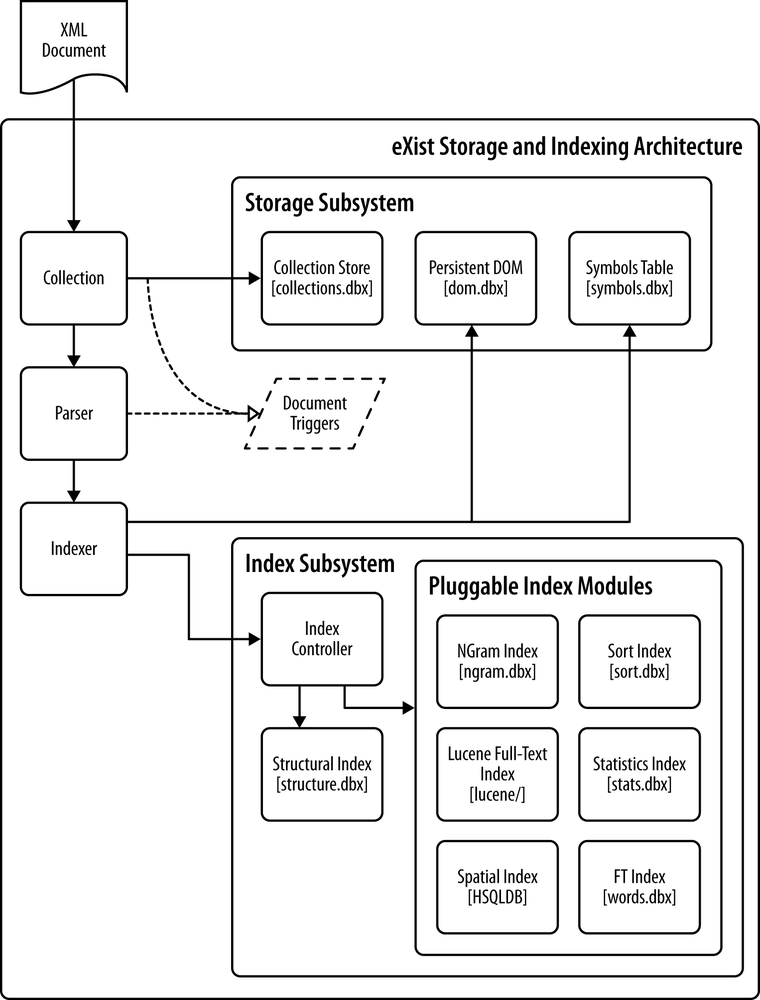
When given an XML document, eXist firstly takes this document and parses it (whilst validating it if requested), and then extracts all of the document information from this document and stores it while also indexing the document’s key features (see Figure 4-6).
Note
eXist does not store your XML documents as a series of XML files on disk, as this is not an efficient storage format for database operations.
eXist stores an XML document by taking the information making up the document and separating it into distinct parts that are then stored in a series of optimized binary files on disk. This process is transparent to users; they can always ask eXist for the XML document they originally stored, and the complete document will be re-constituted and presented to them as it was.
The indexes that eXist builds from your XML document during storage enable you to later perform fast and efficient queries against the documents in the database. The structural index employed by eXist is fixed, but additional indexes are configurable by the user depending on their query requirements; see Configuring Indexes for index configuration details.
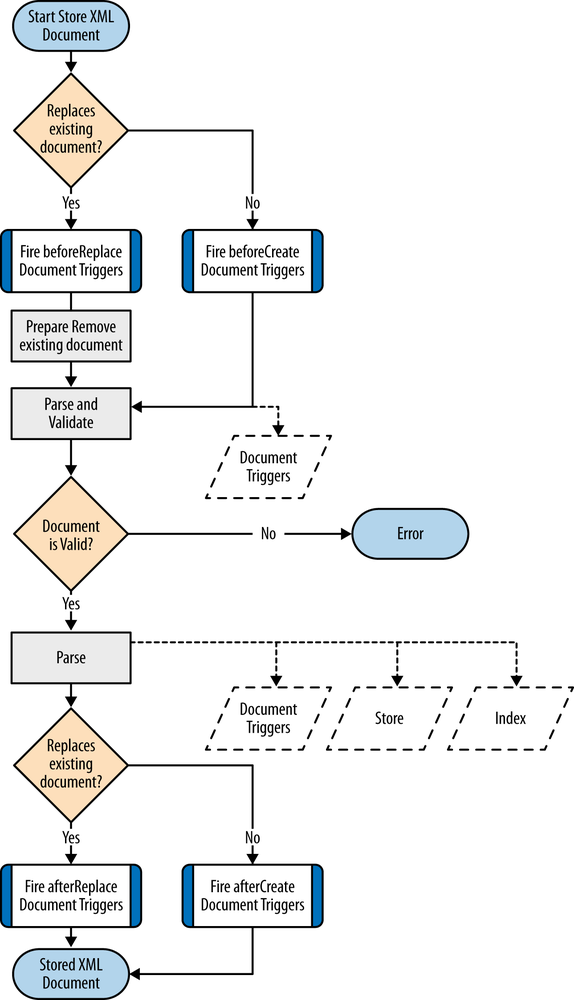
The following steps occur when eXist stores an XML document into a collection in the database (see Figure 4-7):
Either a
beforeCreateDocumentorbeforeUpdateDocumentevent is raised with each document trigger configured on the target collection.Validation phase begins. The parser begins parsing the XML document with validation (if requested) and dispatches events as it moves through the document.
If any document triggers are configured on the target collection, each of these will receive the events from the parser in turn. This effectively allows the document triggers to interrupt the parse and hence fail the validation phase, which will abort storing the document.
If the parse succeeded, the validation phase is complete. If the parse failed, the process of storing the document is aborted and an error is reported.
The parser begins parsing the XML document and dispatches events as it moves through the document.
If any document triggers are configured on the target collection, each of these will receive the events from the parser in turn before they are then passed on to the indexer. This effectively allows the document triggers to dynamically modify the document should they wish.
The indexer receives the events from the parser (or document triggers if configured) and performs a number of steps:
It extracts symbols from the event (e.g., the qualified name of an element) and places them in the symbols table if they are not already present. The symbols table file is $EXIST_HOME/webapp/WEB-INF/data/symbols.dbx.
For each node from the event, it substitutes names for symbols, and then stores the node details into the persistent DOM. Elements and attributes are placed into a B+-tree index, while other nodes are stored into pages in a persistent DOM. The B+-tree index maps nodes to their values located in the pages. The persistent DOM file is $EXIST_HOME/webapp/WEB-INF/data/dom.dbx.
It forwards each event to the index controller.
The index controller passes each event through an indexing pipeline. The indexing pipeline always starts with the structural index (which is mandatory in eXist), then follows any pluggable index modules that a user has configured on the target collection (see Configuring Indexes and Configuring Full-Text Indexes). The structural index file is $EXIST_HOME/webapp/WEB-INF/data/structure.dbx.
The target collection adds an entry for the newly stored XML document to itself in the collection store. The collection store file is $EXIST_HOME/webapp/WEB-INF/data/collections.dbx.
Either an
afterCreateDocumentorafterUpdateDocumentevent is raised with each document trigger configured on the target collection.
Binary Document Storage
When given a binary document (i.e., any document that is not XML), eXist stores a copy of it in a shadow of its collection hierarchy on disk under the folder $EXIST_HOME/webapp/WEB-INF/data/fs; it also stores a copy of the document metadata (e.g., database permissions, owner, group, and created date) into the collection store for the target collection. See Figure 4-8.
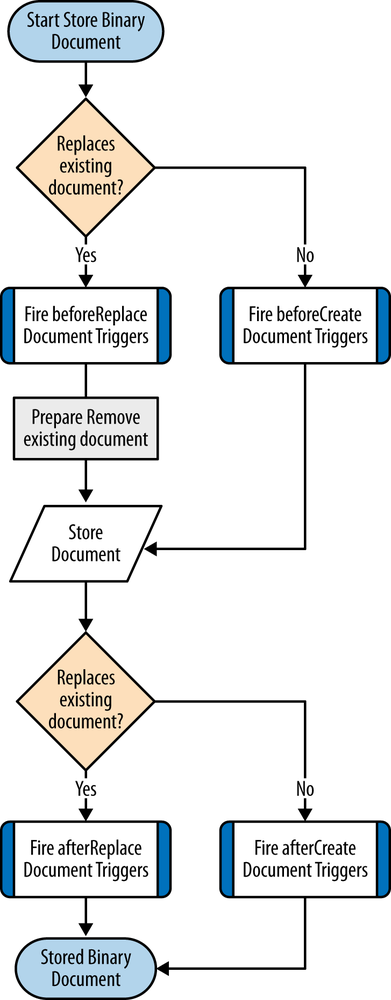
Tip
Whilst eXist does indeed store the content of your binary documents as a series of files on disk, you should not manually change the files in the $EXIST_HOME/webapp/WEB-INF/data/fs folder, as eXist will be unaware of the changes that you have made. Any changes to this folder could cause the database to lose integrity for binary resources and could lead to stability issues.
While the storage of binary documents into eXist is relatively simple (i.e., the content is maintained in files on disk and additional metadata is maintained in eXist’s collection store), you can go further by making use of eXist’s binary content extraction facilities (see contentextraction) to enable indexing and search of binary documents.
Efficient XML Processing Architecture
There are several cross-cutting concerns of eXist’s architecture that focus on efficient XML processing and storage; we will take a look at a couple of the more significant ones next. These topics are certainly advanced and may be skipped if you are not interested in eXist’s internals.
There are three levels of granularity that eXist is concerned with:
- Collection
An arbitrary grouping of XML and binary documents.
- Document
Either an XML document or binary document.
- Node
The nodes within XML documents (i.e., elements, attributes, and text, etc.).
Collections
A collection in eXist is very similar to a folder on a filesystem. It groups a number of related XML and/or binary documents together. Each collection in eXist has a name and is identified by a URI. A collection stores its own metadata, and also all of the metadata of all of the documents present in that collection, as you can see in Table 4-1.
| Metadata property | Description | |
URI | The URI of the Collection in the database | |
Created Date | The date and time the collection was created | |
Permissions | ||
Owner | The owner user of the collection | |
Group | The owner group of the collection | |
Mode | The security mode of the collection (e.g., | |
Access Control List | The access control list for the collection | |
In eXist collections are identified by a hierarchical URI scheme, and are in fact hierarchical containers (Figure 4-9). That is to say, a collection inherits all documents from any subcollections, and that configuration on a collection is applied to all subcollections, unless it is explicitly overridden by a subcollection. If you request a collection in eXist, you receive all of the documents in that collection, but if that collection has subcollections, you also receive all of the documents from all of the subcollections of that collection, and so on.
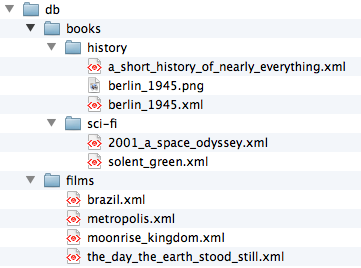
Collections in eXist always start from the root collection named
db with the corresponding
URI /db. In the example hierarchy shown in
Figure 4-9 we can see the following
collections.
| Name | URI |
db |
|
books |
|
history |
|
sci-fi |
|
films |
|
Careful organization of your documents into collections in eXist can vastly improve query performance. It is sensible to organize your documents into collections based on the queries that you will want to make of them; typically this is also the way that your organization logically thinks about documents and their meaning.
Organizing documents into collections and querying only those collections that are relevant reduces the amount of documents that eXist must interrogate during a query, and hence this approach lends itself to more efficient processing. In Figure 4-9, you might want to answer queries about all history books, so by querying just the /db/books/history collection, you are not querying any documents that you already know are irrelevant. Indeed, you can also answer queries about all books by querying the /db/books collection, as this would also query each of its subcollections recursively.
Documents
Documents are the basic unit that you work with in eXist, and they come in two forms: XML documents and binary documents. eXist is not particularly fussy about how you organize your information into documents; whether you choose to use several large documents or many smaller documents, eXist will happily store your data. However, your data architecture is an important concern for your business and applications, so here are some concerns that you should consider when deciding on document granularity:
- Locking
When a document is being read, it is read locked, which means that any incoming updates to the document will be blocked. If you have a few large documents and your system is not mostly concerned with reads, this can introduce contention for the document. If you have several smaller documents, they can be read and updated independently. Likewise, when you are updating a document, it is write locked. If you have several smaller documents rather than a few large documents, several updates can take place independently.
In addition, your own application may also require you to lock documents—for example, to stop two users in an XForms application from simultaneously editing the same document.
- Retrieval
Users retrieving documents directly by URI may not wish to retrieve an entire, large document if they are concerned only with a small portion of its information. To a certain extent, you can mitigate this by placing a virtual URI space over the database by using XQuery with URL Rewriting or RESTXQ, which then just returns a specific portion of the document. However, using URI Rewriting or RESTXQ adds complexity, so if your data architecture doesn’t require it, things will be much simpler for you without them.
All that being said, we advise you to make decisions about document granularity based on your domain model. Most importantly, ask yourself, “What do we think of as a document?.” Typically the technology concerns can be solved later.
Each document in eXist has a filename and a URI, the latter of which is made up of the collection URI and the filename of the document. Documents, like collections, also maintain a small set of metadata, as Table 4-2 shows.
| Metadata property | Description | |
Name | The filename of the document in the database | |
Created Date | The date and time the document was created | |
Last Modified Date | The date and time the document was last modified | |
Internet Media Type | The Internet media type of the document | |
Permissions | ||
Owner | The owner user of the document | |
Group | The owner group of the document | |
Mode | The security mode of the document (e.g., rwxr-xr-x) | |
Access Control List | The access control list for the document | |
Dynamic Level Numbering of Nodes
You have already seen in XML Document Storage and Indexing that while, as a user of eXist, you are working with XML documents (and the nodes from those documents), eXist itself does not work with the textual XML document you provided it, but rather a machine-optimized model of that document.
XML documents themselves are constructed from nodes, and at the very core of everything that eXist does with nodes is DLN (dynamic level numbering). DLN enables eXist to efficiently identify both a node and its structural relationship to other nodes.
Each node from an XML document is given a DLN identifier. DLN identifiers are hierarchical in nature and borrow concepts from the Dewey Decimal Classification system. Each DLN identifier assigned to a node starts with the identifier of the parent node, and then concludes with a number for the node under consideration, which indicates its position among its siblings.
DLN identifiers are unique within a document, which allows for easy identification of a node. They also encode some additional structural properties that are very useful:
The ID of the parent node.
By virtue of the IDs being hierarchical, you also have the ID of every ancestor node.
The ability given two DLN IDs to determine the structural relationship between two nodes.
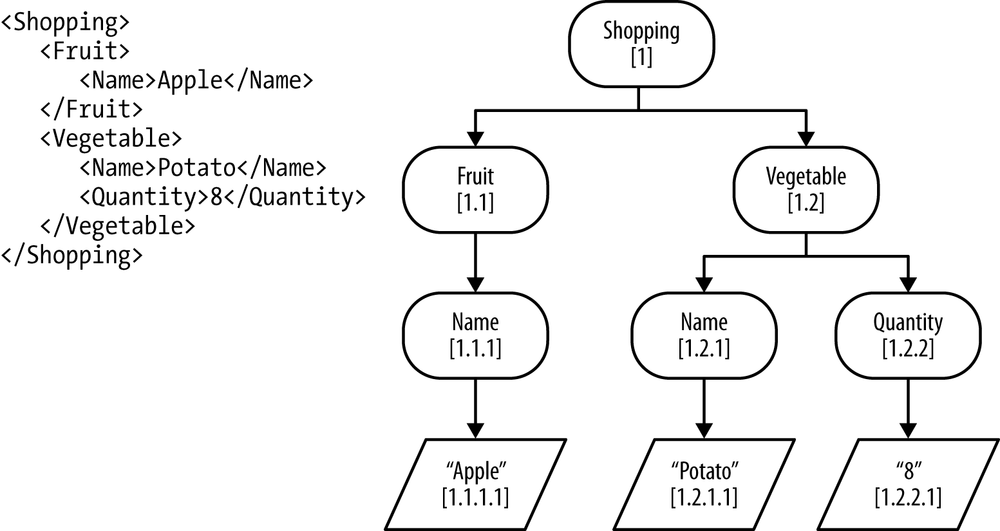
Here are some examples of how the DLN identifiers on the nodes shown in Figure 4-10 can easily be used to perform structural joins in eXist and answer queries without needing to examine the nodes and traverse node relationships themselves:
- Root
By looking at the first level of any node identifier, we find its root node. For example, if you take the node identifier for the text node “Apple,” which is
1.1.1.1, and look at the first number before the first period, then the root identifier is1, and the node with the identifier1is the element “Shopping.”- Ancestors
By looking at all parts of a node identifier from left to right, excluding the last part, we can find all ancestors of that node. For example, if you take the node identifier for the text node “Apple,” which is
1.1.1.1, and work backwards from right to left looking at the parent, then the parent of the parent, and so on until you reach the root, you will find the ancestor nodes “Name” (1.1.1), “Fruit” (1.1), and “Shopping” (1).- Parent
By looking at the parent identifier levels of any node identifier, we can find its parent node. For example, if you take the node identifier for the element “Quantity,” which is
1.2.2, and look at the identifier all the way up to the last period, then the parent identifier is1.2, and the node with the identifier1.2is the element “Vegetable.”- Child
By looking at the identifiers of any two nodes, we can determine if one is the child of the other. Given the identifier for the element “Name,” which is
1.2.1, and for the text node “Potato,” which is1.2.1.1, because the identifier for “Potato” has the prefix of the identifier for “Name” and has one extra level in its identifier we can tell that it is a child of “Name.” We can also tell that it is the first child of “Name” from the last level of its identifier.- Siblings
By looking at the identifiers of any two nodes, we can determine if they are siblings. Given the identifier for the element “Name,” which is
1.2.1, and for the element “Quantity,” which is1.2.2, because their identifiers have the same number of levels and have the same prefix we can tell that the node with identifier1.2is their parent. We can also tell that “Name” is the preceding sibling of “Quantity” because its last level has the lower identifier numbering of1, while “Quantity” is numbered2, and therefore must be the following sibling of “Name.”- Common ancestor
By looking at the common prefix of any two node identifiers, we can find their common ancestor node. For example, if you take the node identifier for the text node “Potato.” which is
1.2.1.1, and the node identifier for the text node “8,” which is1.2.2.1, and examine them from left to right, you will find that the common prefix is1.2, and the node with the identifier1.2is the element “Vegetable.”
Note
eXist provides some extensions that allow you to view the
DLN identifiers assigned to nodes, and also to
retrieve nodes by their DLN identifiers. See the
util:node and util:node-by-id functions in util. eXist also provides the add-exist-id serialization option, which
inserts the DLN identifiers into attributes on each
element of a document or node when you retrieve it from eXist; see
Serialization.
DLN helps eXist perform efficient queries of XML documents, as often eXist can calculate the sets of nodes involved in an XPath expression by performing computations using just their DLN identifiers.
Warning
Should you choose to retrieve nodes from eXist using DLN identifiers, you should be aware that DLN identifiers are not guaranteed to be stable. After you update a document by replacing it or using XQuery update extensions or XUpdate, it is likely that some of the nodes in the document will have different identifiers.
Dynamic Level Numbering and Updates
So far we have looked at DLN within a fixed document, but it can also be useful to understand how the DLN identifiers on nodes in a document may change if that document is updated. There are three ways in which an XML document in eXist may be updated:
- Replacement
In this instance the node identifiers are not updated; rather, the original document is deleted and a new document is stored, and they just happen to have the same URI within the database.
- XUpdate
An XUpdate document may be processed against one or more documents; this could lead to the insertion, deletion, or modification of nodes in the documents. These modifications will lead to identifier changes.
- XQuery update extensions
Similarly to XUpdate, XQuery update extensions may be processed against one or more documents, which could lead to the insertion, deletion, or modification of nodes in the documents. These modifications will lead to identifier changes. The difference between this and an XQuery update is that all operations from a single XUpdate document will occur within the same database transaction, while each XQuery update statement will be executed in its own transaction.
When a document is modified, we want to preserve the integrity of the conceptual model of hierarchical identifiers that have previously been assigned to nodes in the document. However, we need only concern ourselves with insertions between existing nodes because:
Insertions as the last following sibling or insertions as new only child can be assigned new DLN identifiers without our needing to change any existing identifiers to maintain our integrity.
Modifications to existing nodes (e.g., renaming) do not change their identifier.
Deletions do not break the integrity of our model. It does not matter if sibling
1.2is followed by sibling1.4because1.3was deleted, as long as higher numbers indicate the order.
If we could not maintain our existing identifiers on insertion, we would have to re-number all of the nodes in the document which would be a very computationally expensive exercise. In fact, this is exactly what eXist used to do before it implemented DLN. Luckily, DLN provides a mechanism whereby we don’t need to renumber existing nodes but can still perform insertions; this is known as subvalue identifiers.
If we consider the case where we have two elements called
“Name” and “Quantity” with the identifiers
1.2.1 and 1.2.2, respectively, we could insert a new
sibling element named “Cost” between them by using
subvalues. The new element “Cost” would have the identifier
1.2.1/1. The /1 indicates the subvalue; that is,
“Cost” follows “Name” (1.2.1) but precedes “Quantity”
(1.2.2).
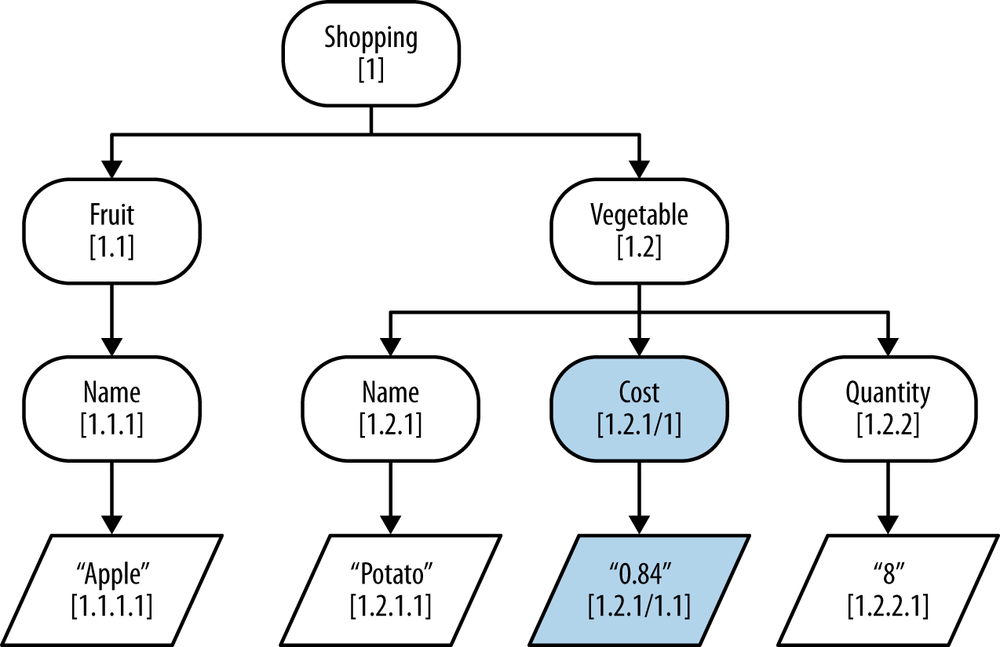
While subvalues give us the ability to perform fast updates and still query documents, comparing subvalue DLN identifiers against non-subvalue DLN identifiers is more costly. For this reason, eXist will occasionally trigger the background defragmentation of a document that has had significant updates made to it. The defragmentation effectively renumbers all of the nodes in the document, removing the subvalues.
Note
The fragmentation of documents occurs when XQuery update or
XUpdate expressions are executed against XML documents. After the
evaluation of an XQuery running XQuery update expressions or XUpdate
document, the updated documents will be checked for fragmentation. If
they exceed the allowed fragmentation limit set in $EXIST_HOME/conf.xml,
then they will be queued for defragmentation. Defragmentation happens
in the background in the database, but during defragmentation a
document is locked against further writes!
Paging and Caching
Several of the core database files (dom.dbx, structure.dbx, and collections.dbx) that are kept on disk are organized into pages of 4 KB. A page is simply a contiguous region that is read or written in an atomic operation. Rather than randomly seeking and reading individual bytes as required, mechanical rotational storage systems (such as hard disks) are much faster at larger linear reads and writes. However, pages themselves are not necessarily always in the order that you need to answer a query, as such good random-access speed is still a requirement of the filesystem and underlying storage system.
Note
The size of a page in eXist is configurable in $EXIST_HOME/conf.xml at the attribute indicated by the XPath /exist/db-connection/@pageSize. This should be aligned with the block size of your filesystem; today 4 KB is typically correct. You can also experiment with setting this to a multiple of the block size when testing for the optimal performance of eXist with your data. However, be aware that you can only change the page size before creating a database (i.e., with no .dbx files in $EXIST_HOME/webapp/WEB-INF/data).
The persistent on-disk DOM (dom.dbx) and collections (collections.dbx) files are split into two parts, a data section and an index section (which is a B+ tree). The data section contains the document or collection metadata, while the index section ensures the quick lookup of collections, documents, and nodes. The structural index (structure.dbx) file is literally just an index and has no data section to its file.
In any database system, aside from network I/O, disk I/O is always the slowest component. For example, reading 1 MB of data from disk takes 32 times as long just to locate the data on the disk as it does to read it from memory. To then actually read the data from disk takes 80 times as long as it does to read it from memory. Therefore, it is highly desirable to optimize any database system to avoid disk I/O as much as possible, and eXist is no exception.
Access to all database files in eXist that make use of paging is performed through specific page caches. The job of the caches is to keep frequently accessed data in memory to avoid having to retrieve it from disk. eXist has separate caches for the data and index sections of its files. The caches in eXist are LRU (least recently used) caches, so pages are evicted from their cache (under various circumstances) based on the time they were last accessed. In particular, the caches for the index sections (B+tree) distinguish between pages that contain internal (nonleaf) nodes or leaf nodes. Since internal nodes are likely to be accessed more frequently, they are assigned a higher priority and are not evicted from the cache before related leaf nodes.
Caches grow (up to a maximum limit) and shrink automatically as required. If a cache is thrashing (i.e., pages are frequently replaced), it will request more memory from the cache manager. Providing the cache manager has it available, extra memory will always be granted to a requesting cache. Exactly how and when a cache grows is specific to each cache implementation. For example, the data section cache of the persistent on-disk DOM will never grow, because it is very unlikely that the same page will be frequently accessed over a short finite duration; therefore, the cache size is fixed to 256 pages (typically 1 MB when you’re using 4 KB pages). Conversely, the collection cache attempts to calculate the memory required by the metadata of each collection, and tries to fill itself with the metadata of the hottest collections. During periods of low database activity, the cache manager may decide to reclaim space from the caches so that it can quickly be reallocated in the future.
Tip
Caches in eXist are configured to use an explicit maximum amount
of memory, which is subtracted from the maximum memory made available
to eXist (the JVM’s -Xmx maximum
memory setting).
All caches (except the collection cache) share a single caching space in memory. The size of this caching space is configurable in $EXIST_HOME/conf.xml at the attribute indicated by the XPath /exist/db-connection/@cacheSize. The collection cache (for collections.dbx) has its own caching space in memory and may likewise be configured in the same file at the XPath /exist/db-connection/@collectionCache.
For information on how to tune eXist’s memory and cache settings for your database, see Cache Tuning.
Get eXist now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

