Chapter 4. Generic Servers
Having broken up the radio frequency allocator into generic and
specific modules and investigated some of the corner cases that can occur
when dealing with concurrency, you will have figured out there is no need to
go through this process every time you have to implement a client-server
behavior. In this chapter, we introduce the gen_server OTP behavior, a library module that
contains all of the generic client-server functionality while handling a
large number of corner cases. Generic servers are the most commonly used
behavior pattern, setting the foundations for other behaviors, all of which
can be (and in the early days of OTP were) implemented using this
module.
Generic Servers
The gen_server module implements the client-server behavior we extracted in the
previous chapter. It is part of the standard library application and
available as part of the Erlang/OTP distribution. It contains the generic
code that interfaces with the callback module through a set of callback functions. The
callback module, in our example containing the code specific to the frequency server, is
implemented by the programmer. The callback module has to export a series
of functions that follow naming and typing conventions, so that their
inputs and return values conform to the protocol required by the
behavior.
As seen in Figure 4-1, the functions of both the behavior and callback module execute within the scope the same server process. In other words, a process loops in the generic server module, invoking the callback functions in the callback module as needed.
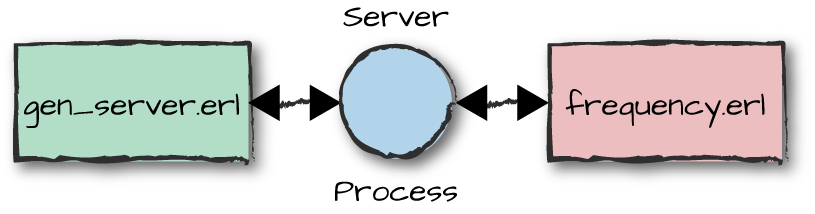
Figure 4-1. The callback and behavior modules
The gen_server library module provides functions to
start and stop the server. You supply callback code to initialize the
system, and in the case of either normal or abnormal process termination,
it is possible to call a function from your callback module to clean up
the state prior to termination. In particular, you no longer need to send
messages to your process. Generic servers encapsulate all message passing
in two functionsâone for sending synchronous messages and one for sending
asynchronous messages. These handle all of the borderline cases we
discussed in the previous chapter, and many others we probably hadnât even
realized could be an issue or cause a race condition. There is also
built-in functionality for software upgrades, where you are able to
suspend your process and migrate data from one version of your system to
the next. Generic servers also provide timeouts, both on the client side
when sending requests, and on the server side when no messages are
received in a predetermined time interval.
We now cover all of the callback functions required when using generic servers. They include:
The
init/1callback function initializes a server process created by thegen_server:start_link/4call.The
handle_call/3callback function handles synchronous requests sent to the server bygen_server:call/2. When the request has been handled,call/2returns a value computed byhandle_call/3.Asynchronous requests are taken care of in the
handle_cast/2callback function. The requests originate in thegen_server:cast/2call, which sends a message to a server process and immediately returns.Termination is handled when any of the server callback functions return a stop message, resulting in the
terminate/2callback function being called.
We look at these functions in more detail including all of their arguments, return values, and associated callbacks as soon as weâve covered the module directives.
Behavior Directives
When we are implementing an OTP behavior, we need to include behavior directives in our module declarations.
-module(frequency).-behavior(gen_server).-export([start_link/1,init/1,...]).start_link(...)->...
The behavior directive is used by the compiler to issue warnings about callback
functions that are not defined, not exported, or defined with the wrong
arity. The dialyzer tool also uses these declarations for checking type
discrepancies. An even more important use of the behavior directive is for
the poor souls1 who have to support, maintain, and debug your code long
after youâve moved on to other exciting and stimulating projects. They
will see these directives and immediately know you have been using the
generic server patterns. If they want to see the initialization of the
server, they go to the init/1 function. If they want to see how
the server cleans up after itself, they jump to terminate/3. This is a great improvement
over a situation in which every company, project, or developer reinvents
their own, possibly buggy, client-server implementations. No time is
wasted understanding this framework, allowing whoever is reading the code
to concentrate on the specifics.
In our example code, compiler warnings come as a result of the -behavior(gen_server). directive because we
omit the code_change/3 function, a callback we cover
in Chapter 12 when discussing release upgrades.
In addition to this directive, we sometimes use a second, optional
directive, -vsn(Version), to keep track of
module versions during code upgrade (and downgrade). We cover versions in
more detail in Chapter 12.
Starting a Server
With the knowledge of our module directives, letâs start a server. Generic servers and other OTP behaviors are started not with the spawn BIFs, but with dedicated functions that do more behind the scenes than just spawn a process:
gen_server:start_link({local,Name},Mod,Args,Opts)->{ok,Pid}|ignore|{error,Reason}
The start_link/4 function takes four arguments. The first tells the gen_server
module to register the process locally with the alias Name.
Mod is the name of the callback module, where the
server-specific code and the callback functions will be found.
Args is an Erlang term passed to the callback function that
initializes the server state. Opts is a list of process and
debugging options we cover in Chapter 5. For the time being, letâs
keep it simple and pass the empty list for Opts. If a process
is already registered with the Name alias, {error,
{already_started, Pid}} is returned. Keep a vigilant eye on which
process executes which functions. You can note them in Figure 4-2, where the server bound to the process
Pid is started by the supervisor. The supervisor is denoted
by a double ring as it is trapping exits.
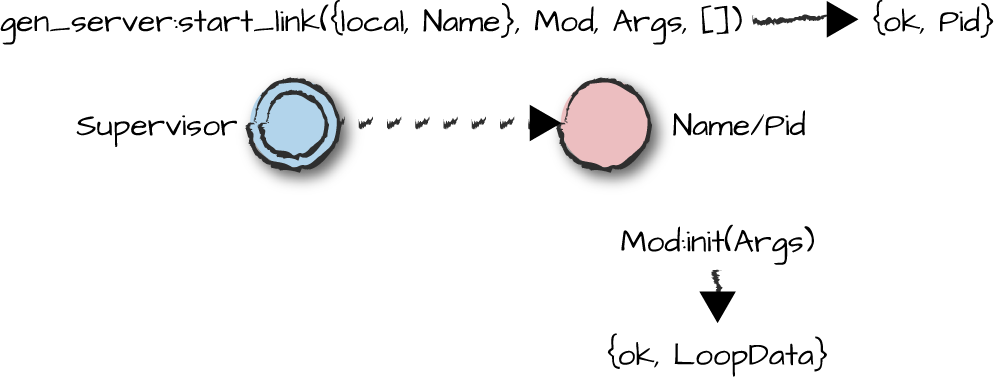
Figure 4-2. Starting a generic server
When the gen_server process has been spawned, it is
registered with the alias Name, subsequently calling the
init/1 function in the callback module Mod. The
init/1 function takes Args, the third parameter
to the start_link call, as an argument, irrespective of
whether it is needed. If no arguments are needed, the init/1
function can ignore it with the donât care variable. Keep in mind that
Args can be any valid Erlang term; you are not bound to using
lists.
Note
If Args is a (possibly empty) list, the list will
be passed to init/1 as a list, and not result in an
init of a different arity being called. For example, if
you pass [foo, bar], init([foo,bar]) will be
called, not init(foo, bar). This is a common mistake
developers make when transitioning from Erlang to OTP, as they confuse
the properties of spawn and spawn_link with
those of the behavior start and start_link
functions.
The init/1 callback function is responsible for
initializing the server state. In our example, this entails creating the
variable containing the lists of available and allocated
frequencies:
start()->% frequency.erlgen_server:start_link({local,frequency},frequency,[],[]).init(_Args)->Frequencies={get_frequencies(),[]},{ok,Frequencies}.get_frequencies()->[10,11,12,13,14,15].
If successful, init/1 callback function returns
{ok, LoopData}. If the startup fails but you do not want to
affect other processes started by the same supervisor, return ignore. If you want to affect other processes,
return {stop, Reason}. We cover ignore in Chapter 8
and stop in âTerminationâ.
In our example, start_link/4 passes the empty list
[] to init/1, which in turn uses the
_Args donât care variable to ignore it. We could have passed
any other Erlang term, as long as we make it clear to anyone reading the
code that no arguments are needed. The atom undefined or the
empty tuple {} are other favorites.
By passing {timeout, Ms} as an option in the
Opts list, we allow our generic server Ms
milliseconds to start up. If it takes longer, start_link/4
returns the tuple {error, timeout} and the behavior process
is not started. No exception is raised. We cover options in more detail in
Chapter 5.
Starting a generic server behavior process is a synchronous
operation. Only when init/1 callback function returns {ok,
LoopData} to the server loop does the
gen_server:start_link/4 function return {ok,
Pid}. Itâs important to understand the synchronous nature of
start_link and its importance to a repeatable startup
sequence. The ability to deterministically reproduce an error is important
when troubleshooting issues that occur at startup. You could
asynchronously start all of the processes, checking each afterward to make
sure they all started correctly. But as a result of changing scheduler
implementations and configuration values running on multi-core
architectures, deploying to different hardware or operating systems, or
even the state of the network connectivity, the processes would not
necessarily always initialize their state and complete the startup
sequence in the same order. If all goes well, you wonât have an issue with
the variability inherent in an asynchronous startup approach, but if race
conditions manifest themselves, trying to figure out what went wrong and
when, especially in production environments, is not for the faint of
heart. The synchronous startup approach implemented in
start_link clearly ensures through its simplicity that each
process has started correctly before moving on to the next one, providing
determinism and reproducible startup errors on a single node. If startup
errors are influenced by external factors such as networks, external
databases, or the state of the underlying hardware or OS, try to contain
them. In the cases where determinism does not help, a controlled startup
procedure removes any element of doubt as to where the issue might be.
Message Passing
Having started our generic server and initialized its loop data, we
now look at how communication works. As you might have understood from the
previous chapter, sending messages using the ! operator is
out of fashion. OTP uses functional interfaces that provide a higher level
of abstraction. The gen_server module exports functions that
allow us to send both synchronous and asynchronous messages, hiding the
complexity of concurrent programming and error handling from the
programmer.
Synchronous Message Passing
While Erlang has asynchronous message passing built in as part of the language, there is
nothing stopping us from implementing synchronous calls using existing
primitives. This is what the gen_server:call/2 function does. It sends
a synchronous Message to the server and waits for a
Reply while the server handles the request in a callback
function. The Reply is passed as the return value to the
call. The message and reply follow a specific protocol and contain a
unique tag (or reference), matching the message and the response. Letâs
have a look at the gen_server:call/2 function in more
detail:
gen_server:call(Name,Message)->Reply
Name is either the server pid or the registered name
of the server process. The Message is an Erlang term that
gets forwarded as part of the request to the server. Requests are
received as Erlang messages, stored in the mailbox, and handled
sequentially. Upon receiving a synchronous request, the handle_call(Message, _From,
LoopData) callback function is invoked in the callback module.
The first argument is the Message passed to
gen_server:call/2. The second argument, _From,
contains a unique request identifier and information about the client.
We will ignore it for the time being, binding it to a donât care
variable. The third argument is the LoopData originally
returned by the init/1 callback function. You should be
able to follow the call flow in Figure 4-3.
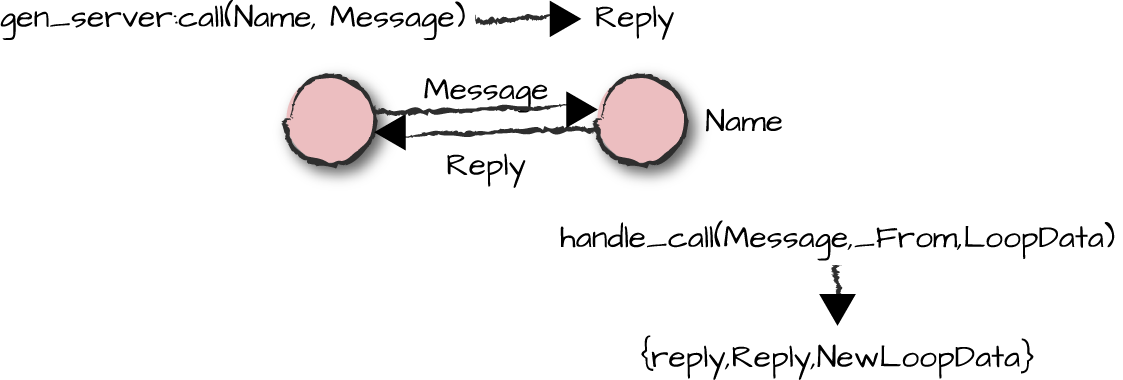
Figure 4-3. Synchronous message passing
The handle_call/3 callback function contains all the
code required to handle the request. It is good practice to have a
separate handle_call/3 clause for every request and to use
pattern matching to pick the right one, instead of using a
case statement to single out the individual messages. In
the function clause, we would execute all of the code for that
particular request and, when done, return a tuple of the format
{reply, Reply, NewLoopData}. A callback module uses the
atom reply to tell the gen_server that the
second element, Reply, has to be sent back to the client
process, becoming the return value of the gen_server:call/2
request. The third element, NewLoopData, is the callback
moduleâs new state, which the gen_server passes into the
next iteration of its tail-recursive receive-evaluate loop. If
LoopData does not change in the body of the function, we
just return the original value in the reply tuple. The
gen_server merely stores it without inspecting it or
manipulating its contents. Once it sends the reply tuple back to the
client, the server is then ready to handle the next request. If no
messages are queued up in the process mailbox, the server is suspended
waiting for a new request to arrive.
In our frequency server example, allocating a frequency needs a synchronous
call because the reply to the call must contain the allocated frequency.
To handle the request, we call the internal function
allocate/2, which you might recall returns
{NewFrequencies, Reply}. NewFrequencies is the
tuple containing the lists of allocated and available frequencies, while
the Reply is the tuple {ok, Frequency} or
{error, no_frequency}:
allocate()->% frequency.erlgen_server:call(frequency,{allocate,self()}).handle_call({allocate,Pid},_From,Frequencies)->{NewFrequencies,Reply}=allocate(Frequencies,Pid),{reply,Reply,NewFrequencies}.
Once completed, the allocate/0 function called by the
client process returns {ok, Frequency} or {error,
no_frequency}. The updated loop data containing available and
allocated frequencies is stored in the generic server receive-evaluate
loop awaiting the next request.
Asynchronous Message Passing
If the client needs to send a message to the server but does not expect a reply, it can
use asynchronous requests. This is done using the gen_server:cast/2 library
function:
gen_server:cast(Name,Message)->ok
Name is the pid or the locally registered alias of
the server process. Message is the term the client wants to
send to the server. As soon as the cast/2 call has sent its
request, it returns the atom ok. On the server side, the
request is stored in the process mailbox and handled sequentially. When
it is received, the Message is passed on to the handle_cast/2 callback function,
implemented by the developer in the callback module.
The handle_cast/2 callback function takes two
arguments. The first is the Message sent by the client,
while the second is the LoopData previously returned by the
init/1, handle_call/3, or
handle_cast/2 callbacks. This can be seen in Figure 4-4.
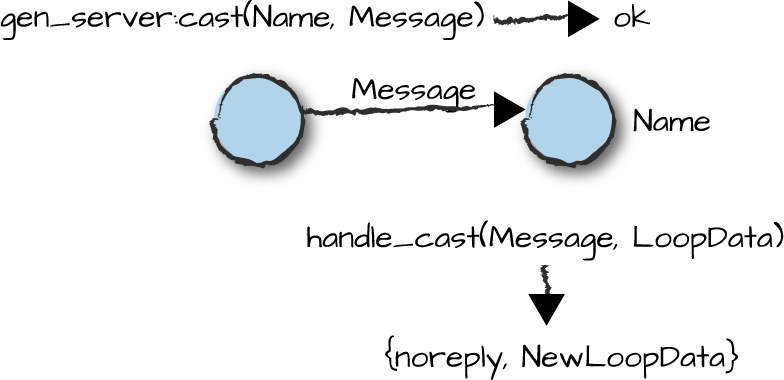
Figure 4-4. Asynchronous message passing
The handle_cast/2 callback function has to return a
tuple of the format {noreply, NewLoopData}. The
NewLoopData will be passed as an argument to the next call
or cast request.
In some applications, client functions return a hardcoded value,
often the atom ok, relying on side effects executed in the
callback module. Such functions could be implemented as asynchronous
calls. In our frequency example, did you notice that
frequency:deallocate(Freq) always returns the atom
ok? We donât really care if handling the request is delayed
because the server is busy with other calls, making it a perfect
candidate for an example using a generic server cast:
deallocate(Frequency)->% frequency.erlgen_server:cast(frequency,{deallocate,Frequency}).handle_cast({deallocate,Freq},Frequencies)->NewFrequencies=deallocate(Frequencies,Freq),{noreply,NewFrequencies};
The client function deallocate/1 sends an
asynchronous request to the generic server and immediately returns the
atom ok. This request is picked up by the
handle_cast/2 function, which pattern matches the
{deallocate, Frequency} message in the first argument and
binds the loop data to Frequencies in the second. In the
function body, it calls the helper function deallocate/2,
moving Frequency from the list of allocated frequencies to
the list of available ones. The return value of
deallocate/2 is bound to the variable
NewFrequencies, returned as the new loop data in the
noreply control tuple.
Note that we said that only in some applications do client
functions ignore return values from server functions with side effects.
Pinging a server to make sure it is alive, for example, would rely on
gen_server:call/2 raising an exception if the server had
terminated or if there were a delay, possibly as a result of heavy load,
in handling the request and sending the response. Another example where
synchronous calls are used is when there is a need to throttle requests
and control the rate at which messages are sent to the server. We
discuss the need to throttle messages in Chapter 15.
As with pure Erlang, calls and casts should be abstracted in a functional API if used from outside the module. This gives you greater flexibility to change your protocol and hide private implementation-related information from the caller of the function. Place the client functions in the same module as the process, as this makes it easier to follow the message flow without jumping between modules.
Other Messages
OTP behaviors are implemented as Erlang processes. So while communication
should ideally occur through the protocols defined in the
gen_server:call/2 and gen_server:cast/2
functions, that is not always the case. As long as the pid or registered
name is known, there is nothing stopping a user from sending a message
using the Name ! Message construct. In some cases, Erlang
messages are the only way to get information across to the generic
server. For example, if the server is linked to other processes or ports
but has called the process_flag(trap_exit, true) BIF to
trap exits from those processes or ports, it might receive
EXIT signal messages. Also, communication between processes and ports
or sockets is based on message passing. And finally, what if we are
using a process monitor, monitoring distributed nodes or communicating
with legacy, non-OTP-compliant code?
These examples all result in our server receiving Erlang messages
that do not comply with the internal OTP messaging protocol of the
server. Compliant or not, if you are using features that can generate
messages to your server, then your server code has to be capable of
handling them. Generic servers provide a callback function that takes
care of all of these messages. It is the handle_info(_Msg,
LoopData) callback. When called, it has to return either the
tuple {noreply, NewLoopData} or, when stopping,
{stop, Reason, NewLoopData}:
handle_info(_Msg,LoopData)->% frequency.erl{noreply,LoopData}.
It is common practice, even if you are not expecting any messages,
to include this callback function. Not doing so and sending the server a
non-OTP-compliant message (they arrive when you least expect them!)
would result in a runtime error and the server terminating, as the
handle_info/2 function would be called in the callback
module, resulting in an undefined function error.
Weâve kept our frequency server example simple. We ignore any
message coming in, returning the unchanged LoopData in the
noreply tuple. If you are certain you should not be
receiving non-OTP messages, you could log such messages as errors. If we
wanted to print an error message every time a process the server was
linked to terminated abnormally, the code would look like this (we are
assuming that the server in question is trapping exits):
handle_info({'EXIT',_Pid,normal},LoopData)->{noreply,LoopData};handle_info({'EXIT',Pid,Reason},LoopData)->io:format("Process:~pexited with reason:~p~n",[Pid,Reason]),{noreply,LoopData};handle_info(_Msg,LoopData)->{noreply,LoopData}.
Warning
One of the downsides of OTP is the overhead resulting from the
layering of the various behavior modules and the data overhead
required by the communication protocol. Both will affect performance.
In an attempt to shave a few microseconds from their calls, developers
have been known to bypass the gen_server:cast function
and use the Pid ! Msg construct instead, or, even worse,
embed receive statements in their callback functions to
receive these messages. Donât do this! You will make your code hard to
debug, support, and maintain, lose many of the advantages OTP brings
to the table, and get the authors of this book to stop liking you. If
you need to shave off microseconds, optimize only when you know from
actual performance measurements that your program is not fast
enough.
Unhandled Messages
Erlang uses selective receives when retrieving messages from the process mailbox. But allowing us to extract certain messages while leaving others unhandled comes with the risk of memory leakages. What happens if a message type is never read? Using Erlang without OTP, the message queue would get longer and longer, increasing the number of messages to be traversed before one is successfully pattern matched. This message queue growth will manifest itself in the Erlang VM through high CPU usage as a result of the traversal of the mailbox, and by the VM eventually running out of memory and possibly being restarted through heart, which we cover in Chapter 11.
All of this is valid if we are using pure Erlang, but OTP behaviors take a different approach. Messages are handled in the same order in which they are received. Start your frequency server, and try sending yourself a message you are not handling:
1>frequency:start().{ok,<0.33.0>} 2>gen_server:call(frequency, foobar).=ERROR REPORT==== 29-Nov-2015::18:27:45 === ** Generic server frequency terminating ** Last message in was foobar ** When Server state == {data,[{"State", {{available,[10,11,12,13,14,15]}, {allocated,[]}}}]} ** Reason for termination == ** {function_clause,[{frequency,handle_call, [foobar, {<0.44.0>,#Ref<0.0.4.112>}, {[10,11,12,13,14,15],[]}], [{file,"frequency.erl"},{line,63}]}, {gen_server,try_handle_call,4, [{file,"gen_server.erl"},{line,629}]}, {gen_server,handle_msg,5, [{file,"gen_server.erl"},{line,661}]}, {proc_lib,init_p_do_apply,3, [{file,"proc_lib.erl"},{line,240}]}]}
This is probably not what you were expecting. The frequency server terminated with a
function_clause runtime error, printing an error
report.2 When you call a function, one of the clauses always has to
match. Failure to do so results in a runtime error. When doing a
gen_server call or cast, the message is always retrieved
from the mailbox in the generic server loop, and the
handle_call/3 or handle_cast/2 callback
function is invoked. In our example, handle_call(foobar, _From,
LoopData) doesnât match any of the clauses, causing the function
clause error weâve just viewed. The same would happen with a
cast.
How do we avoid such errors? One option is to have a catch-all,
where unknown messages are pattern matched to a donât care variable and
ignored. This is specific to the application, and may or may not be the
answer. A catch-all might be the norm with the
handle_info/2 callback when dealing with ports, sockets,
links, monitors, and monitoring of distributed nodes where there is a
risk of forgetting to handle a particular message not needed by the
application. When dealing with calls and casts, however, all requests
should originate from the behavior callback module and any unknown
messages should be caught in the early stages of testing.
If in doubt, donât be defensive, and instead make your server terminate when receiving unknown messages. Treat these terminations as bugs, and either handle the messages or correct them at the source. If you do decide to ignore unknown messages, donât forget to log them.
Synchronizing Clients
What happens in a situation where two clients each send a synchronous request to a server, but instead of immediately responding to each individually, the server has to wait for both requests before responding to the first? We demonstrate this in Figure 4-5. This could be done for synchronization purposes or because the server needs the data from both requests.
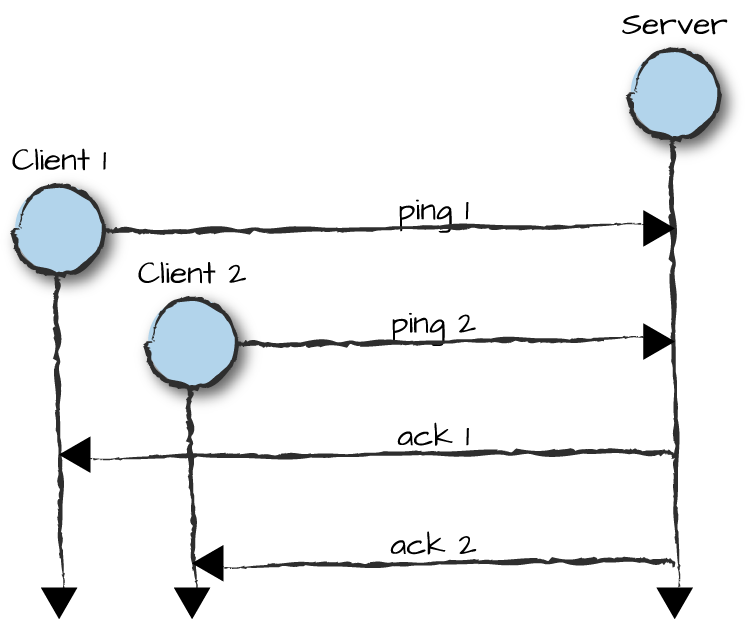
Figure 4-5. Rendezvous with generic servers
The solution to this problem is simple. Do you remember the
From field in the handle_call(Message, From, State)
callback function? Instead of returning a reply back to the behavior
loop, we return {noreply, NewState}. We then use the
From attribute and the function:
gen_server:reply(From,Reply)
to later send back the reply to the client when it suits us. In
the case of having to synchronize two clients, it could be in the second
handle_call/3 callback, where the From value
for the first client is stored between the calls either as part of the
NewState or in a table or database.
You can also use reply/2 if a synchronous request
triggers a time-consuming computation and the only response the client
is interested in is an acknowledgment that the request has been received
and is in the process of being fulfilled, without having to wait for the
whole computation to be completed. To send an immediate acknowledgment,
the gen_server:reply/2 call can be used in
the callback itself:
handle_call({add,Data},From,Sum)->gen_server:reply(From,ok),timer:sleep(1000),NewSum=add(Data,Sum),io:format("From:~p, Sum:~p~n",[From,NewSum]),{noreply,NewSum}.
Letâs run this code, assuming it is a generic server implemented
in the from callback module. The call
timer:sleep/1 will suspend the process, allowing the shell process to handle
the response from gen_server:reply/2 before the io:format/2 call:
1>gen_server:start({local, from}, from, 0, []).{ok,<0.53.0>} 2>gen_server:call(from, {add, 10}).ok From:{<0.55.0>,#Ref<0.0.3.248>}, Sum:10
Note the value and format of the From argument we are
printing in the shell. It is a tuple containing the client pid and a
unique reference. This reference is used in a tag with the reply sent
back to the client, ensuring that it is in fact the intended reply, and
not a message conforming to the protocol sent from another process.
Always use From as an opaque data type; donât assume it is
a tuple, as its representation might change in future releases.
Termination
What if we want to stop a generic server? So far, weâve seen the callback
functions init/1, handle_call/3, and
handle_cast/2 return {ok, LoopData},
{reply, Reply, LoopData}, and {noreply,
LoopData}, respectively. Stopping the server requires the callbacks
to return different tuples:
init/1can return{stop, Reason}handle_call/3can return{stop, Reason, Reply, LoopData}handle_cast/2can return{stop, Reason, LoopData}handle_info/2can return{stop, Reason, LoopData}
These return values terminate with the same behavior as
if exit(Reason) were called. In the case of calls and casts,
before exiting, the callback function terminate(Reason, LoopData) is called.
It allows the server to clean up after itself before being shut down. Any
value returned by terminate/2 is ignored. In the case of
init, stop should be
returned if something fails when initializing the state. As a result,
terminate/2 will not be called. If we return {stop,
Reason} in the init/1 callback, the
start_link function returns {error,
Reason}.
In our frequency server example, the stop/0 client
function sends an asynchronous message to the server. Upon receiving it,
the handle_cast/2 callback returns the tuple with the
stop control atom, which in turn results in the
terminate/2 call being invoked. Have a look at the
code:
stop()->gen_server:cast(frequency,stop).% frequency.erlhandle_cast(stop,LoopData)->{stop,normal,LoopData}.terminate(_Reason,_LoopData)->ok.
To keep the example simple, weâve left terminate empty.
In an ideal world, we would probably have killed all of the client
processes that were allocated a frequency, thereby terminating their tasks
using those frequencies and ensuring that upon a restart, all frequencies
are available.
Look at the message gen_server:cast/2 sends to the
frequency server. Youâll notice it is the atom stop, pattern
matched in the first argument of the handle_cast/2 call. The
message has no meaning other than the one we give to it in our code. We
could have sent any atom, like gen_server:cast(frequency,
donald_duck). Pattern matching donald_duck in the
handle_cast/2 would have given us the same result. The only
stop that has special meaning is the one that occurs in the
first element of the tuple returned by handle_cast/2, as it
is interpreted in the receive-evaluate loop of the generic server.
If you are shutting down your server as part of your normal workflow
(e.g., the socket it is handling has been closed, or the hardware it
controls and monitors is shutting down), it is good practice to set your
Reason to normal. A non-normal
reason, while perfectly acceptable, will result in error reports being
logged by the SASL logger. These entries might overshadow those of real
crashes. (The SASL logger is another freebie you get when using OTP. We
cover it in Chapter 9.)
Although servers can be stopped normally by returning the
stop tuple, there might be cases when they terminate as the
result of a runtime error. In these cases, if the generic server is
trapping exits (by having called the process_flag(trap_exit,
true) BIF), terminate/2 will also be called, as shown
in Figure 4-6. If you are not
trapping exits, the process will just terminate without calling terminate/2.
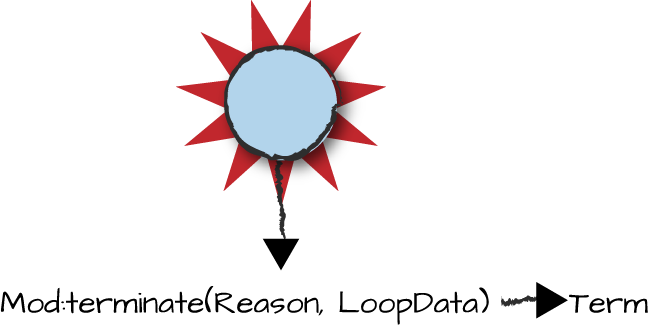
Figure 4-6. Abnormal server termination
If you want the terminate/2 function to execute after
abnormal terminations, you have to set the trap_exit flag. If it is not set, a supervisor
or linked process might bring the server down without allowing it to clean
up.
Having said this, always check the context for termination. If a runtime error has occurred, clean up the server state with extreme care, as you might end up corrupting your data and so set your system up for more runtime errors after the server restarts. When restarting, you should aim to recreate the server state from correct (and unique) sources of data, not a copy you stored right before the crash, as it might have been corrupted by the same fault that caused the crash.
Call Timeouts
When sending synchronous messages to your server using a gen_server call, you should expect a response
within milliseconds. But what if there is a delay in sending the response?
Your server might be extremely busy handling thousands of requests, or
there might be bottlenecks in external dependencies such as databases,
authentication servers, IP networks, or any other resource or API taking
its time to respond. OTP behaviors have a built-in timeout of 5 seconds in
their synchronous gen_server:call APIs. This should be enough
to cater to most queries in any soft real-time system, but there are
borderline cases that need to be handled differently. If you are sending a
synchronous request using OTP behaviors and have not received a response
within 5 seconds, the client process will raise an exception. Letâs try it
out in the shell with the following callback module:
-module(timeout).-behavior(gen_server).-export([init/1,handle_call/3]).init(_Args)->{ok,undefined}.handle_call({sleep,Ms},_From,LoopData)->timer:sleep(Ms),{reply,ok,LoopData}.
In the gen_server:call/2 function, we send a message of
the format {sleep, Ms}, where Ms is a value used
in the timer:sleep/1 call executed in the
handle_call/3 callback. Sending a value larger than 5,000 milliseconds should cause
the gen_server:call/2 function to raise an exception, as such
a value exceeds the default timeout. Letâs try it out in the shell. We
assume that the timeout module is already compiled, so as to avoid the
compiler warnings from the callback functions we have omitted:
1>gen_server:start_link({local, timeout}, timeout, [], []).{ok,<0.66.0>} 2>gen_server:call(timeout, {sleep, 1000}).ok 3>catch gen_server:call(timeout, {sleep, 5001}).{'EXIT',{timeout,{gen_server,call,[timeout,{sleep,5001}]}}} 4>flush().Shell got {#Ref<0.0.0.300>,ok} 5>gen_server:call(timeout, {sleep, 5001}).** exception exit: {timeout,{gen_server,call,[timeout,{sleep,5001}]}} in function gen_server:call/2 6>catch gen_server:call(timeout, {sleep, 1000}).{'EXIT',{noproc,{gen_server,call,[timeout,{sleep,1000}]}}}
We start the server, and in shell command 2, we send a synchronous
message telling the server to sleep for 1,000 milliseconds before replying
with the atom ok. As this is within the 5-second default
timeout, we get our response back. But in shell command 3, we raise the
timeout to 5,001 milliseconds, causing the gen_server:call/2
function to raise an exception. In our example, shell command 3 catches
the exception, allowing the client function to handle any special cases
that might arise as a result of the timeout.
If you decide to catch exceptions arising as the result of a
timeout, be warned: if the server is alive but busy, it will send back a
response after the timeout exception has been raised. This response has to
be handled. If the client is itself an OTP behavior, the exception will
result in the handle_info/2 call being invoked. If this call
has not been implemented, the client process will crash.
If the call is from a pure Erlang client, the exception will be stored in the client mailbox and never handled. Having unread messages in your mailbox will consume memory and slow down the process when new messages are received, as the littering messages need to be traversed before new ones will be pattern matched. Not only that, but sending a message to a process with a large number of unread messages will slow down the sender, because the send operation will consume more reductions. This will have a knock-on effect, potentially triggering more timeouts and further growing the number of littering messages in the client mailbox.
The performance penalty when sending messages to a process with a
long message queue does not apply to behaviors synchronously responding to
the process where the request originated. If the client process has a long
message queue, thanks to compiler and virtual machine optimizations, the
receive clause will match the reply without having to
traverse the whole message queue.
We see the proof of this memory leak in shell command 4, where unread messages are flushed. Had we not flushed the message, it would have remained in the shellâs mailbox. Throughout this book, we keep reminding you not to handle corner cases and unexpected errors in your code, as you run the risk of introducing more bugs and errors than you actually solve. This is a typical example where side effects resulting from these timeouts will probably manifest themselves only under extreme load in a live system.
Now have a look at shell command 5 and Figure 4-7. We have a call that causes the client
process to crash, because it is executed outside the scope of a
try-catch statement. In a majority of cases, if your server
is not responding for any (possibly unknown) reason, making the client
process terminate and letting the supervisor deal with it is probably the
best approach. In this example, the shell process terminates and is
immediately restarted. The timeout server sends a response to the old
client (and shell) pid after 5,001 milliseconds. As this process does not
exist anymore, the message is discarded. So why does shell command 6 fail
with reason noproc? Have a look at the sequence of shell
commands and see if you can figure it out before reading on.

Figure 4-7. Server timeouts
When we started the server, we linked it to the shell, making the
shell process act as both the client and the parent. The timeout server
terminated after we executed a gen_server:call/2 call outside
of the scope of a try-catch in shell command 5. Because the
server is not trapping exits, when the shell terminated, the
EXIT signal propagated to the server, causing it to also
terminate. In normal circumstances, the client and the parent of the
server that links to it would not be the same process, so this would not
occur. These issues tend to show up when testing behaviors from the shell,
so keep them in mind when working on your exercises.
So, how do we supply something other than the 5-second default timeout value in behaviors? Easy: we set our own timeout. In generic servers, we do this using the following function call:
gen_server:call(Server,Message,TimeOut)->Reply
where TimeOut is either the desired value in
milliseconds or the atom infinity.
A client call will often consist of a chain of synchronous requests to several, potentially distributed, behavior processes. They might in turn send requests to external resources. More often than not, choosing timeout values becomes tricky, as these processes are accessing services and APIs provided by third parties completely out of your control. Systems that have been known to respond in milliseconds to the majority of the requests can take seconds or even minutes under extreme loads. The throughput of your system counted in operations per second might still be the same, but when there is a higher loadâpossibly many orders of magnitude higherâgoing through it, the latency of the individual requests will be higher.
The only way to answer the question of what TimeOut you
should set is to start with your external requirements. If a client
specifies a 30-second timeout, start with it and work your way through the
chain of requests. What are the guaranteed response times of your external
dependencies? How will disk access and I/O respond under extreme load?
What about network latency? Spend lots of time stress testing your system
on the target hardware and fine-tune your values accordingly. When youâre
unsure, start with the 5,000-millisecond default value. Use the value
infinity with extreme care, avoiding it altogether unless
thereâs no other alternative.
Deadlocks
Picture two generic servers in a badly designed system.
server1 does a synchronous call to server2.
server2 receives the request, and through a series of calls
in other modules ends up (possibly unknowingly) executing a synchronous
callback to server1. Observing Figure 4-8, this problem is resolved not through
complex deadlock prevention algorithms, but through timeouts.
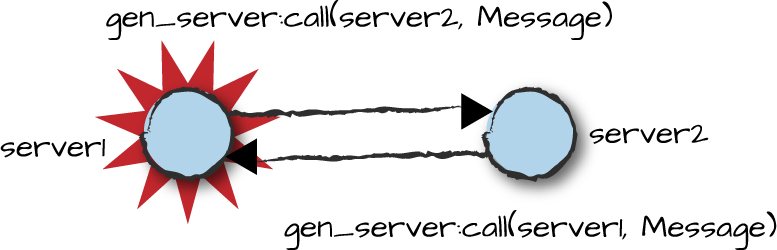
Figure 4-8. Generic server deadlocks
If server1 has not received a response within 5,000
milliseconds, it terminates, causing server2 to terminate
as well. Depending on what gets there first, the termination is
triggered either through the monitor signal or through a timeout of its
own. If more processes are involved in the deadlock, the termination
will propagate to them as well. The supervisor will receive the
EXIT signals and restart the servers accordingly. The
termination is stored in a log file where it is hopefully detected,
resulting in the bug leading to the deadlock being fixed.
In 17 years of working with Erlang, Iâve come across only one
deadlock.3 Process A synchronously called process
B, which in turn did a remote procedure call to another
node that resulted in a synchronous call to process C.
Process C synchronously called process D,
which did another remote procedure call back to the first node. This
call resulted in a synchronous callback to process A, which
was still waiting for a response back from B. We discovered
this deadlock when integrating the two nodes for the first time, and it
took us 5 minutes to solve. Process A should have called
B asynchronously, and process B should have
responded back to A with an asynchronous callback. So while
there is a risk of deadlocks, if you approach the problem right, it is
minimal, as the largest cause of deadlocks occurs when controlling
execution and failure in critical sectionsâsomething for which the
shared-nothing approach in Erlang provides plenty of alternatives.
Generic Server Timeouts
Picture a generic server whose task is to monitor and communicate with a particular hardware device. If the server has not received a message from the device within a predefined timeout, it should send a ping request to ensure the device is alive. These ping requests can be triggered by internal timeouts, created by adding a timeout value in the control tuples sent back as a result of the behavior callback functions:
init/1->{ok,LoopData,Timeout}handle_call/3->{reply,Reply,LoopData,Timeout}handle_cast/2->{noreply,LoopData,Timeout}handle_info/2->{noreply,LoopData,Timeout}
The value Timeout is either an integer in milliseconds
or the atom infinity. If the server does not receive a
message in Timeout milliseconds, it receives a
timeout message in its handle_info/2 callback
function. Returning infinity is the same as not setting a
timeout value. Letâs try it with a simple example where every 5,000
milliseconds, we generate a timeout that retrieves the current time and
prints the seconds. We can pause the timer and restart it by sending the
synchronous messages start and pause:
-module(ping).-behavior(gen_server).-export([init/1,handle_call/3,handle_info/2]).-define(TIMEOUT,5000).init(_Args)->{ok,undefined,?TIMEOUT}.handle_call(start,_From,LoopData)->{reply,started,LoopData,?TIMEOUT};handle_call(pause,_From,LoopData)->{reply,paused,LoopData}.handle_info(timeout,LoopData)->{_Hour,_Min,Sec}=time(),io:format("~2.w~n",[Sec]),{noreply,LoopData,?TIMEOUT}.
Assuming the ping module is compiled, we start it and generate a
timeout every 5 seconds. We can suspend the timeout by sending it the
pause message, which when handled in the second clause of the
handle_call/3 function does not include a timeout in its
return tuple. We turn it back on with the start
message:
1>gen_server:start({local, ping}, ping, [], []).{ok,<0.38.0>} 22 27 2>gen_server:call(ping, pause).paused 3>gen_server:call(ping, start).started 51 56 4>gen_server:call(ping, start).started 4
Because we set a relatively high timeout, we do not generate a timeout message at 5,000-millisecond intervals. We send a timeout message only if a message has not been received by the behavior. If a message is received, as is happening with shell command 4 in our example, the timer is reset.
If you need timers that may not be reset or have to run at regular
intervals irrespective of incoming messages, use functions such as erlang:send_after/3 or those provided by the
timer module, including apply_after/3,
send_after/2, apply_interval/4, and
send_interval/2.
Hibernating Behaviors
If instead of a timeout value or the atom infinity we return
the atom hibernate, the server will reduce its memory
footprint and enter a wait state. You will want to use
hibernate when servers that receive intermittent,
memory-intensive requests are causing the system to run low on memory.
Using hibernate will discard the call stack and run a
full-sweep garbage collection, placing everything in one continuous
heap. The allocated memory is then shrunk to the size of the data on the
heap. The server will remain in this state until it receives a new
message.
Warning
There is a cost associated with hibernating processes, as it involves a full-sweep garbage collection prior to hibernating and one soon after the process wakes up. Use hibernation only if you do not expect the behavior to receive any messages in the foreseeable future and need to economize on memory, not for servers receiving frequent bursts of messages. Using it as a preemptive measure is dangerous, especially if your process is busy, as it might (and probably will) cost more to hibernate the process than to just leave it as is. The only way to know for sure is to benchmark your system under stress and demonstrate a gain in performance along with a substantial reduction in memory usage. Add it as an afterthought only if you know what you are doing. If in doubt, donât do it!
Going Global
Behavior processes can be registered locally or globally. In our examples, they
have all been registered locally using a tuple of the format {local,
ServerName}, where ServerName is an atom denoting the
alias. This is equivalent to registering the process using the register(ServerName, Pid) BIF. But
what if we want location transparency in a distributed cluster?
Globally registered processes piggyback on the global name server,
which makes them transparently accessible in a cluster of (possibly
partitioned) distributed nodes. The name server stores local replicas of
the names on every node and monitors node health and changes in
connectivity, ensuring there is no central point of failure. You register
a server globally by using the {global, Name} tuple as an
argument to the server name field. It is equivalent to registering the
process using the function global:register_name(Name, Pid).
Use the same tuple in your synchronous and asynchronous
calls:
gen_server:start_link({global,Name},Mod,Args,Opts)->{ok,Pid}|ignore|{error,Reason}gen_server:call({global,Name},Message)->Replygen_server:cast({global,Name},Message)->ok
There is an API that allows you to replace the global process
registry with one you have implemented yourself. You can create your own
when the functionality provided by the global module is not enough, or when you
want a different behavior that caters for different network topologies.
You need to provide a callback moduleâsay, Moduleâthat exports the same functions and
return values defined in the global module, namely register_name/2,
unregister_name/1, whereis_name/1, and
send/2. Name registration then uses the tuple {via,
Module, Name}, and starting your process using {via, global,
Name} is the same as registering it globally using {global,
Name}. For globally registered processes, the Name
does not have to be an atom; rather, any Erlang term is valid. Once you
have your callback module, you can start your process and send messages
using:
gen_server:start_link({via,Module,Name},Mod,Args,Opts)->{ok,Pid}gen_server:call({via,Module,Name},Message)->Replygen_server:cast({via,Module,Name},Message)->ok
In the remainder of the book, we aggregate {via, Module,
Name}, {local, Name}, and {global, Name}
using NameScope. Most servers are registered locally, but
depending on the complexity of the system and clustering strategies,
global and via are used as well.
When communicating with behaviors, you can use their pids instead of their registered aliases. Registering behaviors is not mandatory; not registering allows multiple instances of the same behavior to run in parallel. When starting the behaviors, just omit the name field:
gen_server:start_link(Mod,Args,Opts)->{ok,Pid}|ignore|{error,Reason}
If you broadcast a request to all servers within a cluster of nodes,
you can use the generic server multi_call/3 call if you need
results back and abcast/3 if you donât:
gen_server:multi_call(Nodes,Name,Request[,Timeout])->{[{Node,Reply}],BadNodes}gen_server:abcast(Nodes,Name,Request)->abcast
On the servers of the individual nodes, requests are handled in the
handle_call/3 and handle_cast/2 callbacks,
respectively. When broadcasting asynchronously with abcast,
no checks are made to see whether or not the nodes are connected and still
alive. Requests to nodes that cannot be reached are simply thrown
away.
Linking Behaviors
When you start behaviors in the shell, you link the shell process to them.
If the shell process terminates abnormally, its EXIT signal will propagate to the behaviors it started and cause them to
terminate. Generic servers can be started without linking them to their
parent by calling gen_server:start/3 or
gen_server:start/4. Use these functions with care, and
preferably only for development and testing purposes, because behaviors
should always be linked to their parent:
gen_server:start(NameScope,Mod,Args,Opts)gen_server:start(Mod,Args,Opts)->{ok,Pid}|{error,{already_started,Pid}}
Erlang systems will operate for years in the absence of rebooting the computers they run on. They can continue even during software upgrades for bug fixes, feature enhancements, and new functionality, and through behaviors terminating abnormally and being restarted. When shutting down a subsystem, you need to be 100% certain that all processes associated with that subsystem are terminated, and avoid leaving any orphan processes lingering. The only way to do so with certainty is using links. We go into more detail when we cover supervisor behaviors in Chapter 8.
Summing Up
In this chapter, we have introduced the most important concepts and
functionality in the generic server behavior, the behavior behind all
behaviors. You should by now have a good understanding of the advantages
of using the gen_server behavior instead of rolling your own.
We have covered the majority of functions and associated callbacks needed
when using this behavior. Although you do not need to understand
everything that goes on behind the scenes, we hope you now have an idea
and appreciation that there is more than meets the eye. The most important
functions we have covered are listed in Table 4-1.
| gen_server function or action | gen_server callback function |
|---|---|
gen_server:start/3,
gen_server:start/4,
gen_server:start_link/3,
gen_server:start_link/4 | Module:init/1 |
gen_server:call/2,
gen_server:call/3,
gen_server:multi_call/2,
gen_server:multi_call/3 | Module:handle_call/3 |
gen_server:cast/2,
gen_server:abcast/2,
gen_server:abcast/3 | Module:handle_cast/2 |
Pid ! Msg, monitors, exit messages, messages
from ports and sockets, node monitors, and other non-OTP
messages | Module:handle_info/2 |
Triggered by returning {stop, ...} or when
terminating abnormally while trapping exits | Module:terminate/2 |
When compiling behavior modules, you will have seen a warning about
the missing code_change/3 callback. We cover it in Chapter 11 when looking at release handling and
software upgrades. In the next chapter, while using the generic server
behavior as an example, we look at advanced topics and behavior-specific
functionality that comes with OTP.
At this point, you will want to make sure you review the manual
pages for the gen_server module. If you are feeling brave,
read the code in the gen_server.erl
source file, and the source for the gen helper module. Having
read this and the previous chapter and understood the corner cases, you
will discover the code is not as cryptic as it might first appear.
Whatâs Next?
The next chapter contains odds and ends that allow you to dig deeper
into behaviors. We start investigating the built-in tracing and logging
functionality we get from using them. We also introduce you to the
Opts flags in the start functions. The flags allow you to
fine-tune performance and memory usage, as well as start your behavior
with trace flags enabled. So read on, as interesting things are in store
in the next chapter.
1 At the risk of sounding repetitious, be nice to them, as it might be you someday.
2 If you run this example in the shell, you will also get an error report from the shell itself terminating as a result of the exit signal propagating through the link.
3 Iâm the author who in the previous book caused the nationwide data outage in a mobile network.
Get Designing for Scalability with Erlang/OTP now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

