Chapter 1. Continuity
If everyone is moving forward together, then success takes care of itself.
— Henry Ford
The Zen of Prevention
At times it may feel that the universe mischievously conspires to destroy our work. And to some extent this is true: nature doesn’t like order. This entropy manifests itself in many ways: we open a network socket, a router may fail. We write to a file, the disk could fill up. We fail to check for valid inputs, our program could blow up unexpectedly.
Causes of potential failure are both infinite and inevitable. As guardians of our own code quality, we’re armed with two battle tactics: Be reactive, or be proactive.
Reactive Error Handling
Colloquially referred to as “firefighting,” a reactive position calls us to action. In most cases, an undesirable situation has already presented itself, and now we’re charged with fixing:
- The initial cause of the error, if under our control
- The unprotected areas of code that allowed the cause to wreak greater havoc
- Any resultant artifacts that persist after the error is encountered
Anyone who’s rifled through a database’s binary logfile to restore data to a consistent state can attest to the stressful waste of time incurred in handling emergency situations after a breach in expected execution. Dealing with issues as they arise also imposes a sense of immediacy; the activities of a normal workday may be suspended to address more pressing concerns.
Clearly, the reactive model is not our best option if it can be avoided.
Proactive Quality Policies
“Only YOU can prevent … fires” has been the plea of the United States Forest Service since 1947, underscoring the importance of limiting factors that contribute to disaster before they happen.
Related to the prevention of errors is the issue of containment. In the case of failure we’d like to know as soon as possible and handle the problem prior to its leaking into other areas of the system, where it might cause greater harm. Consider this simple bit of code:
publicStringwelcome(Stringname){return"Hello, "+name;}
Assume a user were to accidentally pass null into the welcome(String) method. The String returned would be:
Hello, null
This is because the Java Language Specification Version 7 states in 15.18.1 that concatenation with a single String operand will result in string conversion upon the other operand. The null pointer is therefore represented as the String “null” according to the rules dictated by 5.1.11.
Likely this isn’t the result we’d been expecting, but we’ve put ourselves in this position because we didn’t code defensively. Enhancing the welcome(String) method to perform a precondition check would raise an Exception to the user and prohibit further normal execution flow:
publicStringwelcome(Stringname){if(name==null||name.isEmpty()){thrownewIllegalArgumentException("name must be specified");}return"Hello, "+name;}
This fail-fast policy is equally as important at runtime as it is during development. Knowing how to limit our exposure to error remains a topic of vast research and refinement. Luckily, the study of the software development process provides us with a number of models upon which we may base our own practices.
Software Development Processes
Methodology. Doctrine. Paradigm. Whatever we call it, our process (or absence of one!) is the script we follow on a day-to-day basis that guides our approach to building software. Typically inspired by the central themes we believe contribute to quality and efficiency, a model for development workflow may be a powerful tool in keeping you and your team from heading down an unproductive path. Many well-documented approaches exist, and knowing their motivations can help inform your own decisions in choosing a sensible model for your project.
Serial Models
A serial, or sequential, process follows a linear path from project inception to completion. As each stage in the development lifecycle comes to a close, the next one in turn is started. Prior stages are typically not revisited, and this model is often visualized as a series of steps, as illustrated in Figure 1-1.

Development flows from one stage to the next, forming the basis for the nickname “Waterfall,” often associated with serial models. Also called “Big Design Up Front,” this process relies heavily upon a full understanding of all requirements from the project onset. The general theory supporting Waterfall Design is roughly “measure twice, cut once”: by doing an exhaustive evaluation of all moving parts, the goal is to reduce wasted time by avoiding the need to go back and make corrections. In our opinion, this tack is best applied for projects with a long development cycle targeting a single release.
Though this might fit the retail software mold, the never-go-back mentality of a serial process makes it a particularly brittle approach to building adaptable code; the model is not designed to support changing requirements. For that, we might be better served by looking to a more random-access model where any development phase may be revisited (or many may be in-process at the same time!).
Iterative Models
In stark contrast to the linear workflow prescribed by the Waterfall Model, there exists a suite of well-known iterative designs built to encourage change and promote parallelism. By decomposing a large problem into more manageable components, we grant ourselves the option to solve each piece independently. Additionally, we might opt to take broad swipes on a first pass, further refining our solutions in repeated cycles; this is where “iterative” processes obtain their name.
Extreme Programming
Also known simply as “XP,” Extreme Programming is a discipline that introduces a feedback loop into each phase of the development process. A practice that rose to popularity especially in the late ’90s and early 2000s, XP lauds communication and other social aspects as centrally important themes. Figure 1-2 illustrates a typical workflow.
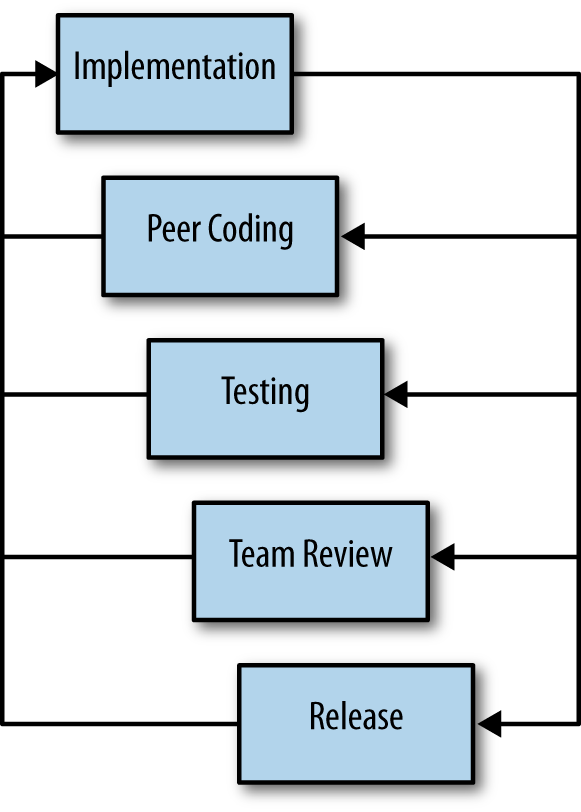
While the full reasoning behind XP is detailed by Kent Beck’s Extreme Programming Explained: Embrace Change, Second Edition (Addison-Wesley, 2004), some of its primary tenets can be boiled down to:
- Short development cycles
- Daily, brief meetings
- Pair Programming, Team Ownership, and Accountability
- Doing only what needs to be done now, deferring nonessential work until later
- Garnering feedback from all stakeholders, not only programmers, early and often
Test-Driven Development
- The approach of first writing automated tests, then correcting/augmenting main code until it passes
In fact, XP, along with other models, has both inspired and acts as an implementation of a larger collection of iterative policies as outlined by the Manifesto for Agile Software Development.
Testing Is Development
Move testing from the caboose to the engine.
— Tim Ottinger Senior Consultant
No matter the development method your team prescribes, and no matter how rigidly you adhere to its principles, eventually you’re going to need to assert that your code works. Of course you could handle this manually by deploying the application and letting a human user follow a scripted test plan, but wherever possible it’s much more efficient and fail-proof to automate the test execution. So you’re going to need to write some tests.
But it’s our opinion that testing is not simply about making sure your code works as expected.
When you write tests, you’re a user of your API. You’ll see how intuitive it is to use, and you’ll discover gaps in documentation. You might discover that it’s too verbose or ugly, and most importantly: you can reevaluate your design before it’s too late. You’re putting yourself in the shoes of your target audience.
What’s more, if you write tests alongside the development of your business logic, you might find your work to be more enjoyable. You’ll know when a feature is completed; you’ll have the satisfaction of seeing concrete feedback in real time. Proponents of Test-Driven Development even make the case for writing tests before implementation. In our experience, testing may be done alongside construction of the primary code such that the experience from one end of the tunnel can inform the other.
Automated testing can take many forms, and we’ll categorize a few for use throughout this text.
Levels of Testing
Proponents of test-oriented software development processes may qualify tests in one or more flavors:
- Acceptance
- Asserts that code meets business requirements
- Black-box
- Asserts the contract of an API is working without respect to its internals
- Compatibility
- Asserts that code plays nicely with one or more outside components; for instance, a web application may need to display correctly on Internet Explorer, Chrome, Firefox, Safari, and mobile devices
- Functional
- Asserts that code meets the technical requirements derived from business requirements (i.e., that all functions are working as expected)
- Load/stress/performance
- Asserts and measures how a system handles input under load, and how gracefully it degrades with increased traffic
- Regression
- Asserts that previously identified errors have been corrected or that existing features continue to function
- Smoke
- A subset of a full test suite, intended to run quickly and provide feedback that the system is generally intact from a simplistic level
- White-box
- Asserts that an API is working as contracted, taking into consideration implementation-specific data structures and constructs
A well-tested application may have tests covering many of these areas, and we can further organize these types according to scope.
Unit
The purpose of a unit test is to validate that a single functionality is operating as expected in isolation. Unit tests are characterized as fast, simple, easy-to-run, and fine-grained. They may dig into implementation details for use in white-box testing.
For instance, every Java object inherits the method Object.hashCode() and the value equality test Object.equals(Object). By API contract, calls to hashCode of equal-by-value objects must return equal, that is:
/*** Test bullet 2 of the hashCode contract as defined by:* http://docs.oracle.com/javase/7/docs/api/java/lang/Object.html#hashCode()*/publicvoidtestHashCodeOfEqualObjects(){// Declare some vars that are equal-by-valueMyObjecta=newMyObject("a");MyObjectb=newMyObject("a");// Now ensure hashCode is working for these objects as contractedasserta.equals(b):"The objects should be equal by value";asserta.hashCode()==b.hashCode():"Hash codes of equal objects not equal";}
This test, implemented using the Java assert keyword, is a classic example of a unit test: it checks for the smallest possible invariant (in this case that the equals() and hashCode() implementations of MyObject are working with respect to one another). Many experts will advise that a unit test contains only one assertion; in our experience this is a fantastic guideline, but as the preceding example illustrates, use common sense. If more than one assertion is required to conclude that all participants in an invariant are in expected form, then use what’s necessary.
In cases where a unit test may require inputs from unrelated components, the use of mock objects is a common solution. Mocks supply an alternate implementation used in testing that may help the developer to:
- Simulate an error condition
- Avoid starting up an expensive process or code path
- Avoid dependence upon a third-party system that might not be reliable (or even not available) for testing purposes
Avoid dependence upon a mechanism that supplies nonidempotent (nonrepeatable) values
- For instance, a random-number generator or something that relies on the current time
Although mocks absolutely have their place in the testing arsenal, in the context of Enterprise development it’s our opinion that their use should be limited. The Java Enterprise Edition is based on a POJO (Plain Old Java Object) component model, which enables us to directly instantiate servlets, Enterprise JavaBeans (EJBs), and Context and Dependency Injection (CDI) beans; this is great for validating business logic in simple calls. However, the true power of Java EE is in the loose coupling between components, and mocks do not account for the linkage between these pieces that’s provided by the container. To fully test an application, you must test the whole runtime, not simply the code you’ve written on your own. For that, we need a more comprehensive solution to validation than is allowed by unit tests.
Integration
Imagine we’d like to build a pipe to carry water from a nearby reservoir to a treatment and purification facility. The unit tests we described previously would be responsible for ensuring that each section of the tube was free of leaks and generally of good quality. But the whole is more than the sum of its parts: the opportunity for water escaping between the cracks still exists.
And so it is with software: we must check that our components play nicely with one another. This is especially true for Java EE, where dependency injection is a commonplace tool. It’s great that one bean not be explicitly bound to another, but eventually we rely upon a container to do the wiring for us. If our metadata or configuration is incorrect, our injection points may not be filled as we’re expecting. This could result in a deployment-time exception or worse, making it imperative that we have test coverage for the interaction between components.
When we talk about integration testing in this book, it’s within the context of a container. Historically, interaction with an application server has been notoriously difficult to test. For many, Java EE has become a dirty term as a result. It’s the goal of this text to clearly delineate techniques for building enterprise applications in a testable manner. Though many may view this discussion as related to integration testing, instead we feel that it’s more about development, and integration testing is a valued part of that equation.
Foundation Test Frameworks
As you might imagine, container services really help us to cut down on the complexity in our application code. Dependency injection frees us from manual wiring, while features like declarative security and transaction management keep us from weaving technical concerns into our business logic. Unfortunately, nothing comes for free: the cost of enlisting a framework or an application server’s help is that we’ve now added another integration point. And every integration point must be validated by an integration test.
Java has built-in support for the java.lang.Assertion error and the assert keyword, and these are fine tools when used in the right context. Because assertions using assert are only analyzed in the presence of the -ea switch at launch of the Java runtime, you need not worry about the performance implications of running extra checks in a production environment with this support disabled. For that reason, it makes sense to use assert for testing internal code. For instance:
privateStringwelcome(Stringname){assertname!=null&&!name.isEmpty():"name must be specified";return"Hello, "+name;}
Because the visibility of this code is private, we do not need to worry about doing precondition checks on end-user input; the parameter username must be supplied by something we have written. Therefore, this need not be tested in production.
Of course, assertions may help us along the way, but they’re not tests. Tests exercise a code path and validate one or more post-conditions. For instance, we might write the following client to validate that the public welcome(String) example from Proactive Quality Policies is working as we’d expect:
publicclassWelcomeJDKTest{/** WelcomeBean instance to be tested **/privateWelcomeBeanwelcomer;privateWelcomeJDKTest(WelcomeBeanwelcomer){this.welcomer=welcomer;}publicstaticvoidmain(String...args){/** Make a test client, then execute its tests **/WelcomeJDKTesttester=newWelcomeJDKTest(newWelcomeBean());tester.testWelcome();tester.testWelcomeRequiresInput();}privatevoidtestWelcome(){Stringname="ALR";StringexpectedResult="Hello, "+name;StringreceivedResult=welcomer.welcome(name);if(!expectedResult.equals(receivedResult)){thrownewAssertionError("Did not welcome "+name+" correctly");}}privatevoidtestWelcomeRequiresInput(){booleangotExpectedException=false;try{welcomer.welcome(null);}catch(finalIllegalArgumentExceptioniae){gotExpectedException=true;}if(!gotExpectedException){thrownewAssertionError("Should not accept null input");}}}
Not too terrible as far as code coverage goes; we’ve ensured that the welcome method functions as we’d expect, and we even check that it bans null input at the right place, before that null pointer has a chance to make things more complicated later.
But our signal-to-noise ratio is way off when we write our own main(String[])-based test clients. Look at all the boilerplate involved just to get the execution running, as compared with the test code itself! Just as we use frameworks and component models to cut the redundant, rote bits in our business logic, we can take advantage of some popular libraries to help us slim our tests.
JUnit
The JUnit Test Framework is one of the most widely known testing frameworks for Java. Initially ported from Kent Beck’s work in testing the Smalltalk programming language, JUnit is the most-downloaded artifact in the Maven Central Repository outside of libraries used to run Maven itself (as of August 2012).
Refactoring our WelcomeJDKTest to use JUnit might look a little like this:
publicclassWelcomeJUnitTest{/** To be set by the {@link Before} lifecycle method **/privateWelcomeBeanwelcomer;/** Called by JUnit before each {@link Test} method **/@BeforepublicvoidmakeWelcomer(){this.welcomer=newWelcomeBean();}@Testpublicvoidwelcome(){finalStringname="ALR";finalStringexpectedResult="Hello, "+name;finalStringreceivedResult=welcomer.welcome(name);Assert.assertEquals("Did not welcome "+name+" correctly",expectedResult,receivedResult);}@TestpublicvoidwelcomeRequiresInput(){booleangotExpectedException=false;try{welcomer.welcome(null);}catch(finalIllegalArgumentExceptioniae){gotExpectedException=true;}Assert.assertTrue("Should not accept null input",gotExpectedException);}}
The first benefit we get is that we don’t need a main(String[]) method, and we don’t need to manually call upon our test methods. Instead, JUnit will dutifully execute for us any lifecycle (i.e., @Before) or test (annotated with @Test) methods and report the results back to its initial runner. Secondly, we’re given access to the JUnit library (for instance, a set of convenience methods in org.junit.Assert) to help us reduce the amount of code we’ll need to write assertions.
JUnit also has widespread IDE support, making test execution during development much easier. For instance, consider the context menu available in Eclipse, as shown in Figure 1-3.
As opposed to our homebrewed main(String[]) test client, JUnit supports reporting. In the IDE this may appear graphically, as shown in Figure 1-4.
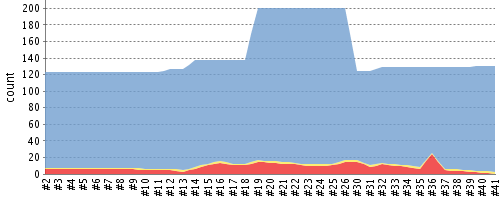
Often we’ll make use of a continuous integration server to handle our builds and provide an auditable view of the codebase over time. During this more formal build process, output may be directed to an XML file for analysis by plug-ins. This can be very helpful in tracking progress of the failing and total number of tests. For instance, we can use the Jenkins Continuous Integration Server shown in Figure 1-5 to track the progress graphically.
Of course, JUnit is not the only kid on the block when it comes to test frameworks.
TestNG
If JUnit sets the standard for simplicity in Java testing, TestNG touts greater flexibility to the developer by offering an arguably greater featureset. Although the differences between the two frameworks are beyond the scope of this text, there’s quite a bit of overlap in concept. Refactoring our test for TestNG should look familiar:
publicclassWelcomeTestNGTest{/** To be set by the {@link @BeforeTest} lifecycle method **/privateWelcomeBeanwelcomer;/** Called by TestNG before each {@link Test} method **/@BeforeTestpublicvoidmakeWelcomer(){this.welcomer=newWelcomeBean();}@Testpublicvoidwelcome(){/// .. Omitting logic for brevityAssert.assertEquals(receivedResult,expectedResult,"Did not welcome "+name+" correctly");}@TestpublicvoidwelcomeRequiresInput(){/// .. Omitting logic for brevityAssert.assertTrue(gotExpectedException,"Should not accept null input");}}
Some of the parameter orders and API names for the annotations have changed, but the concept remains: write less, and let the framework wire up the call stack.
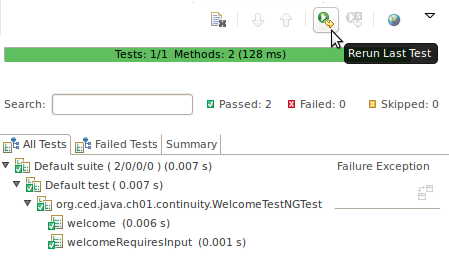
IDE integration, while not standard for Eclipse Juno, is simple enough to install and provides a GUI runner, as we see in Figure 1-6.
Continuous Development
Followers of Extreme Programming and Agile methodologies are likely to be familiar with Continuous Integration, a practice that advocates frequent patching of the upstream development branch in order to catch errors as they’re introduced. Such an approach involves:
- An authoritative source repository (which is not at odds with decentralized version control systems, as we’ll soon see)
- A comprehensive test suite
- An automated build system
- Automated deployment
These general rules are applicable in most any modern language, are tool-agnostic, and are widely accepted throughout the development community.
So why the Continuous Development title of this book?
In addition to the successful ideology and theory espoused by the Agile community, we’ll be looking at concrete tools and projects both within and extending the Java Enterprise platform to best address the real-world concerns of an Enterprise Java developer.
The authoritative Git repository containing the book and example application source for this text is hosted by our friends at GitHub. The accompanying book site is located at http://continuousdev.org, and the official Twitter channel is @ContinuousDev. The authors can be reached at authors@continuousdev.org.
All contents of the book’s repository are licensed under Creative Commons Attribution-ShareAlike 2.0 Generic, and we invite the community at large to contribute work, including feature requests, typographical error corrections, and enhancements, via our GitHub Issue Tracker.
The print release of the book and its example source is set to be given the Git tag of 1.0.0 in the authoritative repository, and development will continue thereafter in the master branch to correct errata and add supplementary material, including new chapters and use cases. The community is welcome to suggest or request topics for additional coverage.
The example application accompanying the use cases raised in this book is called GeekSeek, and it is publicly available at http://geekseek.continuousdev.org. The source is located in this repository under code/application, and instructions for building, testing, and running locally are detailed in Chapter 4. The build jobs for the application are kindly powered by CloudBees at http://bit.ly/1e7wRGN and http://bit.ly/1e7wQ5H.
We welcome your contributions and hope you find the material covered here to be of interest and benefit to your work and career in testable enterprise development.
The first step is to meet some of the key players who will become thematic in this text.
Get Continuous Enterprise Development in Java now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

