Chapter 4. Preparing Your Cloud Foundry Environment
This chapter explores the steps you must perform prior to bootstrapping BOSH and deploying Cloud Foundry. Critically, Cloud Foundry is not a âone size fits allâ technology, and therefore, you must make some decisions at the outset prior to installing the platform. It is important that you understand the key concerns and decision points that define your environment, including:
-
Installation steps
-
Non-technical considerations
-
Cloud Foundry dependencies and integrations
-
IaaS and infrastructure design
-
Networking design and routing
This chapter assumes that you are familiar with the Cloud Foundry components discussed in Chapter 3.
Installation Steps
Following are general steps for deploying Cloud Foundry:
-
Create and configure your IaaS environment, including all the periphery infrastructure that Cloud Foundry requires, such as networks, security groups, blobstores, and load balancers.
-
Set up any additional external enterprise services such as LDAP, syslog endpoints or monitoring, and metrics dashboards.
-
Deploy the BOSH Director.
-
Create an IaaS/infrastructure-specific BOSH configuration such as cloud configuration.
-
Create a deployment manifest to deploy Cloud Foundry.
-
Integrate Cloud Foundry with the required enterprise services (via your deployment manifest).
-
Deploy Cloud Foundry.1
The rest of this chapter explores the necessary considerations for each step. Before we dive into those topics, letâs address the non-technical considerations.
Non-technical Considerations
Before addressing the technical points, it is worth establishing two critical things:
-
The team structure required for installing Cloud Foundry
-
The required deployment topology of Cloud Foundry
These two concerns are especially pertinent when deploying Cloud Foundry for a large enterprise. Both concerns go hand in hand because the âwhere and howâ of deploying Cloud Foundry should always be coupled with the team responsible for operating it.
Team Structure: Platform Operations for the Enterprise
Cloud Foundry is generally deployed either on a team-by-team basis with one installation per business unit, or via a central Platform Operations team who deploy and operate a centralized platform that other DevOps-centric teams can utilize.
Note
In my experience while working with companies helping them to install and run Cloud Foundry, I came across a decentralized deployment model only once. For that one company, it worked well; however, most enterprises choose to establish a centralized Platform Operations team.
Even with a cultural shift toward DevOps, organizations structure teams in a variety of different ways. Choose the team structure that works best for you. Whichever variant you choose, the Platform Operatorâs overall responsibility typically includes the following roles:
-
Networking administrator
-
Storage administrator
-
System administrator
-
IaaS administrator
-
Software development
-
Security
-
QA and performance testing
-
Release management
-
Project management
These are not necessarily nine exclusive roles; individuals might combine a number of the preceding capabilities. For example, an IaaS administrator might also have storage experience. Most of these rolesânetworking and security, for exampleâare more pertinent at the outset when youâre setting up the platform and operational processes. It is often sufficient just to maintain a regular point of contact for ongoing expertise in these areas. A point of contact must still be responsive! If it takes a ticket and three days of waiting to get a network change, your operating model is broken.
If Cloud Foundry is deployed in your data center instead of on a hosted virtual infrastructure, the Platform Operations team will need to work closely with the teams responsible for the physical infrastructure. This is both to help facilitate capacity planning and because an understanding and appreciation of the hardware capabilities underpinning the IaaS layer is required to ensure a sufficient level of availability and scalability. If Cloud Foundry is deployed to a hosted virtual infrastructure such as GCP, Microsoft Azure, or AWS, your Platform Operations team still needs to work closely with the teams responsible for networking so as to establish a direct network connection between the cloud provider and your enterprise.
There is a software development role in the mix because it is necessary to define and understand the application requirements and best practices based on Twelve-Factor applications. Additionally, the Platform Operations team needs to appreciate the application services required to support the cloud-native applications running on the platform. Developers often have specific requirements for choosing a particular technology appropriate for their application. This need can be magnified in a world of microservices in which each service should be free to use an appropriate backing technology so that it can grow and evolve independently from other services. The Platform Operations team should work directly with other business-capability teams to ensure that they offer a rich and defined portfolio of platform services. You can host these services directly on the platform, where it makes sense to do so, instead of being operated and connected adjacent to the platform.
Deployment Topology
How many Cloud Foundry instances should you deploy? There are a number of factors to consider when addressing this question. For example, ask yourself the following:
-
Do you need one instance for the entire company or one instance per organization?
-
Should you have one instance for preproduction workloads and a separate instance for production apps?
-
Do you need to isolate applications or data due to regulatory reasons such as PCI, NIST, or HIPAA compliance?
-
Do you need high availability of Cloud Foundry itself (data center-level redundancy)?
There is no single answer; businesses have different requirements and companies adopt different approaches. However, the decision can be guided by the following considerations:
-
A single instance, or set of instances (e.g., a sandbox; preproduction and production) for the entire company is a conservative and reasonable starting point. As you progress with your Cloud Foundry journey, an additional instance or set of instances per organization might be required if an organization mandates specific customizations (e.g., dedicated internal services that must be isolated from other departments at the network layer).
-
Of primary importance, a sandbox environment is always essential for the Platform Operator to test out new releases without risking developer or production downtime.
-
An instance for pre-production and a separate instance for production might be required if strict network segregation to backed services (such as a production database) is mandated.2
-
Separate instances for non-regulated and regulated apps might be required if dealing with industry regulations such as PCI or HIPPA compliance. A new feature known as isolation segments might alleviate this requirement over time, as discussed further in âIsolation Segmentsâ.
-
Two instances, one in each data center, might be required to allow for data-center failover or activeâactive geodispersed application deployments.
Taking the aforementioned points into consideration, for a scenario in which Cloud Foundry is centrally managed, I tend to see five deployments for a company that has data centers in two locations (e.g., East and West regions):
-
Two environments in a West data centerâpre-production and production instances
-
Two environments in an East data centerâpre-production and production instances
-
A sandbox environment for the Platform Operator
The importance of the sandbox environment should not be underestimated. Changes to the Cloud Foundry environment can occur from several aspects, such as the following:
-
Changing or upgrading the network architecture
-
Upgrading the IaaS and networking layer
-
Upgrading Cloud Foundry
-
Upgrading application services
When applying updates across the stack, there is always the potential, no matter how small, of breaking the underlying infrastructure, the platform itself, or the apps or services running on the platform. From the Platform Operatorâs perspective, both production and preproduction environments are essentially production systems requiring 100 percent uptime. Companies strive to avoid both application and developer downtime and there is a financial impact if any downtime occurs to either group. Therefore, it is vital for the Platform Operator to have a safe environment that can potentially be broken as new changes are tested, without taking developers or production applications offline. It is worth pointing out that although there is always a risk when updating software, Cloud Foundry and BOSH impose a unique set of factors, such as instance group canaries and rolling deployments, that all help mitigate risks and deliver exceptionally reliable updates.
Cloud Foundry Dependencies and Integrations
Before you can deploy and operate Cloud Foundry, you must ensure that all prerequisite dependencies are in place. These dependencies include concerns such as provisioning the IaaS and configuring a load balancer. Additionally, you can integrate Cloud Foundry with other enterprise services such as syslog endpoints, SSO solutions, and metrics dashboards.
Following are the minimum external dependencies:
-
Configured IaaS and infrastructure environment with available administrator credentials
-
Configured networking (subnets and security groups)
-
Defined storage policy and an additional NFS- or Amazon S3âcompatible blobstore (for both the BOSH blobstore and Cloud Foundry blobstore)
-
External load balancers set up to point to GoRouter IP addresses
-
DNS records set up, including defining appropriate system, app, and any other required wildcard domains along with SSL certificates
Additional integration considerations based on enterprise services may require the following:
-
SAML, LDAP, or SSO configured for use with Cloud Foundry where required.
-
A syslog endpoint such as Splunk or ELK (Elasticsearch, Logstash, and Kibana) is available to receive component syslog information.
-
System monitoring and metrics dashboards such as DataDog set up to receive system metrics.
-
An application performance management (APM) tool such as Dynatrace, NewRelic, or AppDynamics set up for receiving application metrics.
Tip
This section focuses only on the dependencies and integration points required for getting started with Cloud Foundry. However, before installing BOSH and Cloud Foundry, it is still worth considering any services and external dependencies with which Cloud Foundry might need to integrate. This is important because if, for example, Cloud Foundry requires access to an external production database, additional considerations such as network access and the latency of roundtrip requests might arise. Ultimately, where your vital backing services reside might be the key deciding factor in where you deploy Cloud Foundry.
IaaS and Infrastructure Design
Before installing Cloud Foundry, you must correctly configure the underpinning infrastructure.
The first technical decision to make is what IaaS or infrastructure you should use to underpin Cloud Foundry. Through the use of the BOSH release tool chain, Cloud Foundry is designed to run on any IaaS provider that has a supported CPI. Refer to the BOSH documentation for an up-to-date list of supported CPIs. As of this writing, there are BOSH CPIs for the following infrastructures:
-
Google Compute Platform
-
AWS
-
Azure
-
OpenStack
-
vSphereâs vCenter
-
vSphereâs vCloudAir
-
Photon
-
RackHD
-
Your local machine (for deploying BOSH Lite)
Your infrastructure decision is often made based on the following three factors:
-
Does your company desire to have an on-premises (vSphere or OpenStack) or a cloud-based (AWS, Azure, GCP) infrastructure? What on-premises infrastructure management exists today, and what is your desired future state?
-
How long will it take to provision new infrastructure (if managed internally)?
-
What is the long-term cost model (both capital and operational expenditure)?
With regard to the time to provision new infrastructure, public cloud providers such as AWS, GCP, or Azure become appealing for many companies because you can quickly spin up new infrastructure and then scale on demand. I have been on six-week engagements for which installing the hardware into the companyâs data centers required four weeks. Time lags such as these are painful; thus utilizing public clouds can accelerate your startup experience. Some companies choose to adopt both a public and private model to provide resiliency through dual deployments.3
From this point on, as a reference architecture, this chapter explores a Cloud Foundry installation on AWS. I selected AWS as the target IaaS for this book because it is accessible both to corporations and individuals who might not have access to other supported IaaS environments.
Designing for Resilience
As discussed in âBuilt-In Resilience and Fault Toleranceâ, Cloud Foundry promotes different levels of built-in resilience and fault tolerance. The lowest layer of resilience within a single installation is achieved through the use of AZs to drive antiaffinity of components and applications to physical servers.
Cloud Foundry AZs (assuming they have been configured correctly) ensure that multiple instances of Cloud Foundry components and the subsequent apps running on Cloud Foundry all end up on different physical hosts. An important point here is that if you desire to use AZs for high availability (HA), you will need a minimum of three AZs (due to the need to maintain quorum for components that are based on the Raft consensus algorithm). Chapter 16 offers more information on designing for resilience.
Tip
The Cloud Foundry deployment example discussed in Chapter 5 uses bosh-bootloader and cf-deployment. bosh-bootloader will configure the infrastructure on your behalf and will try and configure three AZs by default (assuming the IaaS you deploy to can support three distinct regions).
Sizing and Scoping the Infrastructure
Correctly sizing infrastructure for a specific Cloud Foundry installation can be challenging, especially if you cannot accurately forecast how many apps are going to be deployed to the platform. Whatâs more, this challenge becomes compounded because a single application might require several instances due to a combination of the following:
-
Running multiple instances for resilience
-
Running multiple instances over different spaces throughout the application life cycle
-
Running multiple instances for concurrency performance
For example, as depicted in Figure 4-1, a single AI can often require a minimum of seven instances when running in an activeâactive setting:
-
Two instances in development (blue and green versions)
-
One instance in the test or the CI/CD pipeline
-
Four instances in production (two instances in each activeâactive data center)
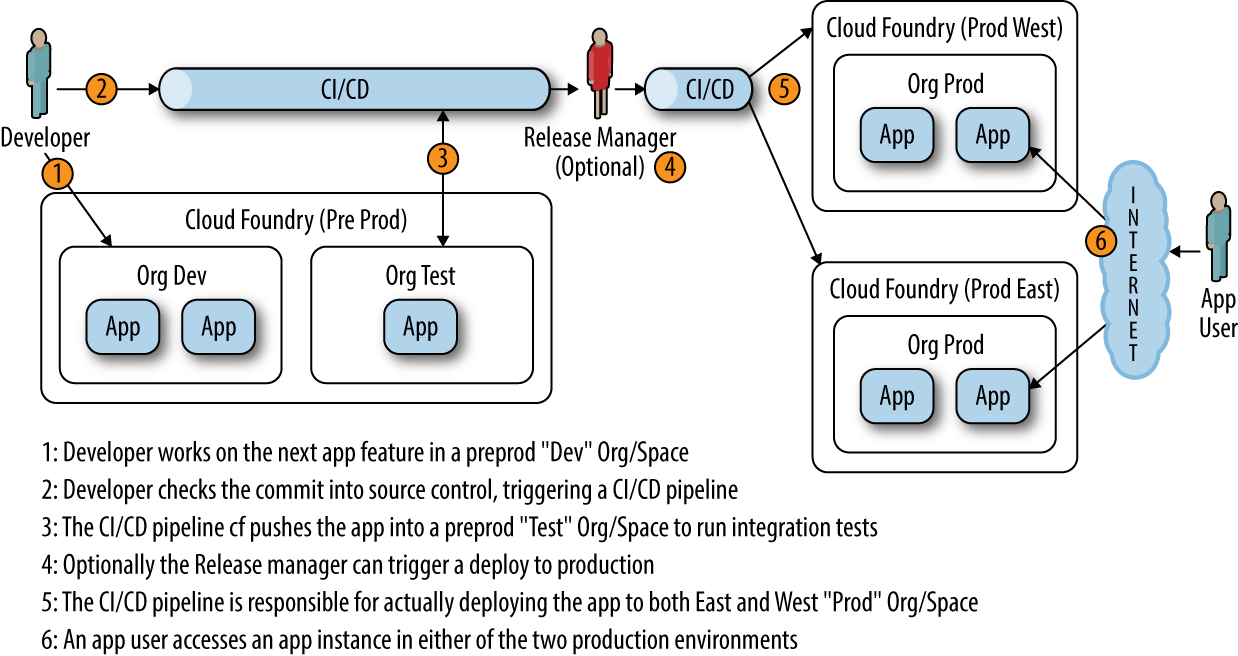
Figure 4-1. Typical multiregion, multi-instance deployment with user-interaction flow
In addition, a typical application involves more than one process; for example, it might have a UI layer, controller/model layer, a service layer, and data layer. You can quickly begin to see that accurate upfront sizing can become complex as the number of running instances starts to scale.
Therefore, sizing and capacity planning is generally considered to be a âday twoâ concern that should be informed, driven, and actioned via metrics and real data, as opposed to hypothesis prior to deploying Cloud Foundry. A key advantage is that Cloud Foundry scales well at every layer, from deploying more AIs to deploying more Cloud Foundry resources, right down to upgrading the IaaS and the physical infrastructure underpinning the IaaS.
When sizing infrastructure for Cloud Foundry, I strongly suggest leaving sufficient headroom for growth. However, there is a danger that by doing this you can end up with an initial IaaS capacity that drastically exceeds what you actually require. For this reason, I tend to move away from explicit sizing and focus on general scoping. Scoping is based on a set of predefined concerns. Through scoping, it is possible to define the underlying infrastructure, and it becomes easier to be more explicit as to what resources will be required.
Scoping deployments on AWS is relatively straightforward because you can pick your desired AWS region, create and configure a new virtual private cloud (VPC) [along with subnets, security groups, etc.], and then map your Cloud Foundry AZs to the AWS region AZs. When deploying Cloud Foundry to physical infrastructure, you need to size your infrastructure in advance. For example, most vSphere customers have a minimum vSphere cluster configuration of three hosts. Two-host clusters are not ideal if 50% of the cluster is taken up via vCenter HA demands, and a single-host cluster is meaningless from a vSphere perspective. vSphere hosts sizes usually contain 256 GB, 384 GB, or 512 GB of RAM. Taking into account the requirement of three AZs based on three vSphere clusters, this implies that the total provisioned RAM is 2.25 to 4.5 TB, which is often drastically more than the initial requirement. The same logic holds true for CPU cores.
Tip
For an excellent reference point, the Pivotal Professional Services team has put together two fantastic resources to help structure and size your infrastructure:4
-
For establishing the base architectural design, you can review the reference architecture.
-
For sizing your base architecture for the required workload, there is a sizing toolâthe PCF sizing toolâbased on some fundamental scoping questions.
After you define your architectural footprint and then size the infrastructure based on your anticipated workload, the next key requirement is to understand the implications of your applications operating under peak load. For example, a retail app on a critical sale day might require more instances to deal with concurrency concerns. Additional instances might require additional Cell resources. Throughput of traffic to the additional apps might require additional GoRouters to handle the extra concurrent connections. When designing your routing tier to handle the required load, you can review the Cloud Foundry routing performance page.
Cell sizing
Cell sizing is of particular importance because Cells run your applications. This is where most of your expansion will be when your AIs begin to increase. Table 4-1 lists typical sizing for a Cell.
| Resource | Sizing |
|---|---|
AI average RAM |
1.5 GB |
AI average storage |
2 GB |
Cell instance type |
AWS m3.2xlarge (or vSphere eight, 4-core vCPUs) |
Cell mem size |
64 GB |
Cell ephemeral storage size |
64 GB |
Overcommitting Memory
Overcommitting memory is configurable in BOSH. However, you need to have a crystal-clear profile of your workloads if you overcommit memory because you can run out of memory in catastrophic ways if you calculate this wrong. Memory is relatively inexpensive, so it is best to avoid this.
A typical three-AZ deployment is often initially set up with six Cells in total: two Cells per AZ. You can always increase the size of your Cells or add additional Cells at a later date.
A key consideration when choosing Cell size is that if the Cells are too small and the average app size too high, you risk wasting space. For example, imagine an 8 GB Cell, with 2 GB apps. When you take into account headroom for the host OS, you will be able to fit only three 2 GB apps on a single Cell. This means that you are wasting well over 1 GB of RAM per Cell; as you replicate this pattern over several Cells, the wasted RAM begins to accumulate to a significant amount.
Conversely, if your Cells are too large, you risk unnecessary churn if a Cell fails. For example, imagine a 128 GB Cell hosting two hundred fifty-five 512 MB apps. Although the app density is great, if for some reason the Cell fails, Cloud Foundry5 will need to subsequently replace 255 apps in one go, in addition to any other workload coming onto the platform. Although this volume of replacement most likely will be fine, replicating this pattern across several concurrent Cell failuresâfor example, due to an AZ failureâcan cause unnecessary churn. Even though Cloud Foundry can cope with a huge amount of churn in replacing applications, but if all of the Cells are running at maximum capacity (as in the scenario stated), rescheduling the apps will not work until you add additional Cells. However, Cloud Foundry is eventually consistent. Even for a situation in which Cloud Foundry fails to place the apps, it will eventually fix itself and reach a consistent state when additional resources are added.
Based on the preceding two illustrations, 32 GB to 64 GB Cells (for an average app size of between 512 MB and 2 GB) is a good sweet spot to work with.
Tip
cf-deploymentâs manifest generation capability provides default Cell sizes that can be reconfigured after you generate the deployment manifest.
Instance group replication
HA requirements are discussed in detail in âHigh Availability Considerationsâ. For deployment of a single Cloud Foundry foundation, you are generally concerned with defining three AZs and removing single points of failure through instance group replication.
When using AZs, you can ensure that there are very few (or zero) single points of failure. In addition to running a multiple Cell instance group as previously described, you should also run multiple instances of the following:
-
MySQL (for BBS, UAA, and CCDBs)
-
NATS
-
Diego (BBS, Brain, AccessVM, CC-Bridge, Cells)
-
Routing (GoRouter, Consul, RouteEmitter)
-
Cloud Controller (including the CC-Worker)
-
UAA
-
Doppler server and Loggregator traffic controller
Tip
Strictly speaking, most of the aforementioned instance groups require only two AZs. Clustered components such as MySQL, Consul, and etcd require quorum and thus require three AZs. For simplicity, I recommend replicating all components across three AZs if you have enough IaaS capacity.
Therefore, a single Cloud Foundry deployment spanning three AZs should have at least two of the aforementioned components that do not require quorum. As discussed previously, any component that uses the Raft consensus algorithm (MySQL, Consul, etcd) should have three instances to maintain a quorum. These instance groups always need an odd number of instances deployed, but you get no additional benefit from having more than three instances. For the other instance groups in the list, at least two instances are required to ensure HA and to allow for rolling upgrades. However, you might want a higher number of instances in order to handle additional capacity and concurrency.
For example, because the GoRouter is on the critical path for application traffic, it might be considered necessary to have two GoRouters per AZ to ensure that you can handle peak traffic if an AZ goes offline. Because the GoRouters load-balance between all the backend instances, the GoRouter is able to span AZs to reach the desired AI. Therefore, if two GoRouters can handle peak workload, adding an additional instance per AZ is not necessary.
Clock Global remains the only singleton. It is not a critical job. It is used for Cloud Controller cleanup and BOSH resurrection should be sufficient for this instance. Beyond that, the only single jobs remaining would be the internal NFS. The NFS can and should be replaced by an external blobstore such as Amazon S3. Additionally, the HAProxy and MySQL proxy are singletons by default. Again, you can and should use an enterprise load balancer, in which case the MySQL proxy can have multiple instances (e.g., one per AZ) when used in conjunction with an external load balancer. If youâre using more than one Cloud Foundry AZ, any singleton instance group must be placed into a specific AZ. Other components that can run with several instances can and should be balanced across multiple AZs.
Setting Up an AWS VPC
Each IaaS that you use will have its own unique set of dependencies and configuration steps. For example, before setting up an AWS VPC, you will need the following:
-
An AWS account that can accommodate the minimum resource requirements for a Cloud Foundry installation.
-
The appropriate region selected within your AWS account (this example uses US-west).
-
The AWS CLI installed on your operator machine, configured with user credentials that have administrative access to your AWS account.
-
Sufficiently high instance limits (or no instance limits) on your AWS account. Installing Cloud Foundry might require more than the default 20 concurrent instances.
-
A key-pair to use with your Cloud Foundry deployment. This key-pair allows you to configure SSH access to your instances. The key-pair name should be uploaded to the NAT instance upon VPC creation.6
-
A certificate for your chosen default domain.
Tip
If you are deploying a highly distributed Cloud Foundry on AWS, built for HA, you will need to file a ticket with Amazon to ensure that your account can launch more than the default 20 instances. In the ticket, ask for a limit of 50 t2.micro instances and 20 c4.large instances in the region you are using. You can check the limits on your account by visiting the EC2 Dashboard on the AWS console; in the Navigation pane on the left, click Limits.
You can bootstrap VPC setup via bosh-bootloader, as described in âInstalling Cloud Foundryâ. Table 4-2 lists the external IaaS-related dependencies that you should take into consideration when manually setting up an AWS VPC.
| Item |
|---|
Access key ID |
AWS secret key |
VPC ID |
AWS security group name |
Region |
Key-pair name (used for VM-to-VM communication and SSH) |
DNS IP(s) |
NTP IP(s) |
SSH password (if applicable) |
VPC to data center connection |
If you are not using bosh-bootloader, there are some excellent instructions on setting up an AWS IaaS environment ready to install Cloud Foundry at prepare-aws. Figure 4-2 presents an example of a typical direct VPC setup.
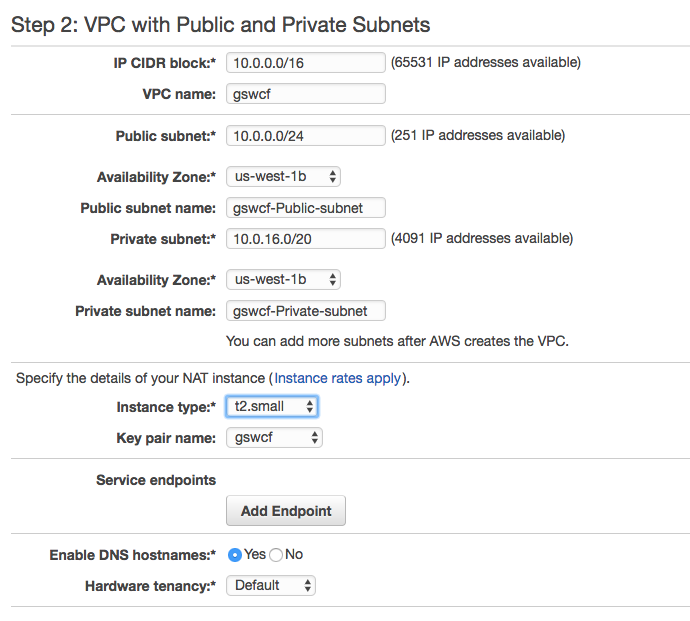
Figure 4-2. Setting up the VPC
Warning
A strong word of caution. The Identity and Access Management (IAM) policy offered by BOSH.io is sufficient to get you started, but for corporate or production environments, it is highly recommended you set a very restrictive policy to limit unnecessary user access. In addition, when setting up the AWS security group (egress and ingress network rules), it is highly insecure to run any production environment with 0.0.0.0/0 as the source or to make any BOSH management ports publicly accessible.
Jumpbox
A jumpbox VM (or Bastian VM) provides layered security because it acts as a single access point for your control plane. It is the jumpbox that accesses the BOSH Director and subsequent deployed VMs. For operator resilience, there should be more than one jumpbox. Allowing access through the firewall only to the jumpboxes and disabling direct access to the other VMs is a common security measure.
Using a jumpbox from your VPC to deploy BOSH and Cloud Foundry can help navigate past network connectivity issues, given that most corporate networks will have firewall rules preventing SSH connections from a VPC to a local machine.
Instead of using SSH to connect to the jumpbox to run commands, newer CLIs respect the SOCKS5 protocol. SOCKS5 routes packets between a server and a client using a proxy server. This means that you can set up an SSH tunnel from your laptop to the jumpbox, forwarded to a local port. By setting an environment variable prior to executing the CLI, the CLI will then run through the jumpbox on your workstation. This provides the advantage that you do not need to install anything on the jumpbox, but you have access to the jumpboxâs network space.
You can create a jumpbox by using $bosh create env. There are also tools in the Cloud Foundry community to help manage, instantiate, and configure your jumpbox. One such tool is Jumpbox.
Networking Design and Routing
As with all networking, many configurations are possible. The key concern with networking is to design a network topology that suits your business while factoring in any specific security requirements. The most appropriate network configuration for Cloud Foundry is established by treating the Cloud Foundry ecosystem as a virtual appliance. Doing so establishes the expectation that all Cloud Foundry components are allowed to talk among themselves. Adopting this virtual appliance mindset will help articulate and shape the networking strategy that could stand in contrast to more traditional networking policies. Security and networking policies should be in place and adhered to for sound reasons, not because âthatâs the way weâve always done it.â
The principal networking best practice is to deploy Cloud Foundry to run on a trusted, isolated network, typically only accessible via an external SSL terminating load balancer that fronts Cloud Foundry. Although it is possible to run Cloud Foundry on any networkâfor example, where every deployed VM is accessible via its own IPânearly all of the projects that I have worked on are deployed into a private network utilizing NAT for outbound traffic.
Before setting up your VPC, you need to consider the VPC-to-data center connection. If you are running your VPC in an isolated manner in which all external calls use NAT to reach out to your corporate network, the VPC to data center connection is not important. However, the VPC to data center connection becomes important if you are treating the VPC as an extension of your corporate network (through capabilities such as directconnect) because the available network range can have a bearing on your VPC classless interdomain routings (CIDRs). The important concern in this scenario is to avoid IP collision with existing resources on the network by defining a portion of the existing network that is free and can be strictly reserved for Cloud Foundry. There are arguments for and against using NAT from the VPC because some companies desire the components within the Cloud Foundry network to remain explicitly routable. However, it is worth noting that if you consider the network as a single address space, you still can use NAT when required, but you cannot âunNATâ a VPC if your VPC has overlapping addresses with the corporate network.
For each AWS subnet used, you should gather and document the information listed in Table 4-3. You will use this information in your deployment manifest if you are creating it from scratch.
| Network dependencies |
|---|
AWS network name |
VPC subnet ID |
Subnet (CIDR range) |
Excluded IP ranges |
DNS IP(s) |
Gateway |
A best practice is to co-locate the services in a separate network from Cloud Foundry and allow a full range of communication (bidirectionally) between the two segments (the services and Cloud Foundry). You also might choose to have one network per service and do the same. However, white-listing ports can make the process very painful, and, for most companies, this extra precaution is regarded as unnecessary. The general recommendation is to allow full communication among all Cloud Foundryâmanaged components at the network-segment level. There is no reason to white-list ports if you trust all components. This approach is often regarded as entirely reasonable given that all of the components are under the same management domain.
For a simple installation, the Cloud Foundry documentation provides recommendations on basic security group egress and ingress rules.
Using Static IPs
The following Cloud Foundry components (referred to in BOSH parlance as instance groups) and IaaS components require static IPs or resolution via external DNS:
-
Load balancer (static IP for HAProxy, VIP for F5, etc.)
-
GoRouter (depending on the IaaS, some CPIs will resolve this for you)
-
NATS
-
Consul/etcd
-
Database such as a MySQL cluster (relational databse service [RDS] referenced by DNS)
Static IPs are required for the aforementioned components because they are used by other downstream instance groups. For example, Consul and etcd, being apex instance groups, require static IPs; all other instance groups can then be resolved through external DNS, or internally through Consulâs internal DNS resolution. For example, the following Cloud Foundry instance groups can have IP resolution via internal DNS:
-
Diego components (BBS, Brain, etc.)
-
Cloud Controller
-
Cell
-
GoRouter (depending on the IaaS, some CPIs will resolve this for you)
-
Routing API
-
Loggregator
-
WebDAV, nfs_server (or S3 blobstore referenced by DNS)
-
etcd
Subnets
Network design is dependent on a number of factors. As a minimum, it is recommended that you create one with a public and private subnet. With a public subnet, you get an internet GW with no NAT, thus every VM that needs internet access will require a public IP. With the private network, you can use an NAT gateway or NAT instance. By default, using bosh-bootloader will provision a management subnet and then a separate subnet per AZ. This is a basic configuration to get you started. However, there is a typical pattern of subnetting your network that has emerged as a common practice for production environments (see also Figure 4-3):
-
A management subnet for the BOSH Director and or jumpbox
-
A dedicated subnet for the core Cloud Foundry components (which also could contain the BOSH Director)
-
A dedicated subnet for the Diego Cells (so as to scale independently as apps scale)
-
A dedicated internet protocol security (IPsec) subnet for services that require the use of IPSec
-
A dedicated subnet for services that do not use IPSec
The first three networks can be on an IPSec-enabled network if required, but it is important to ensure that you have a non-IPSec subnet for services that do not or cannot use IPSec.
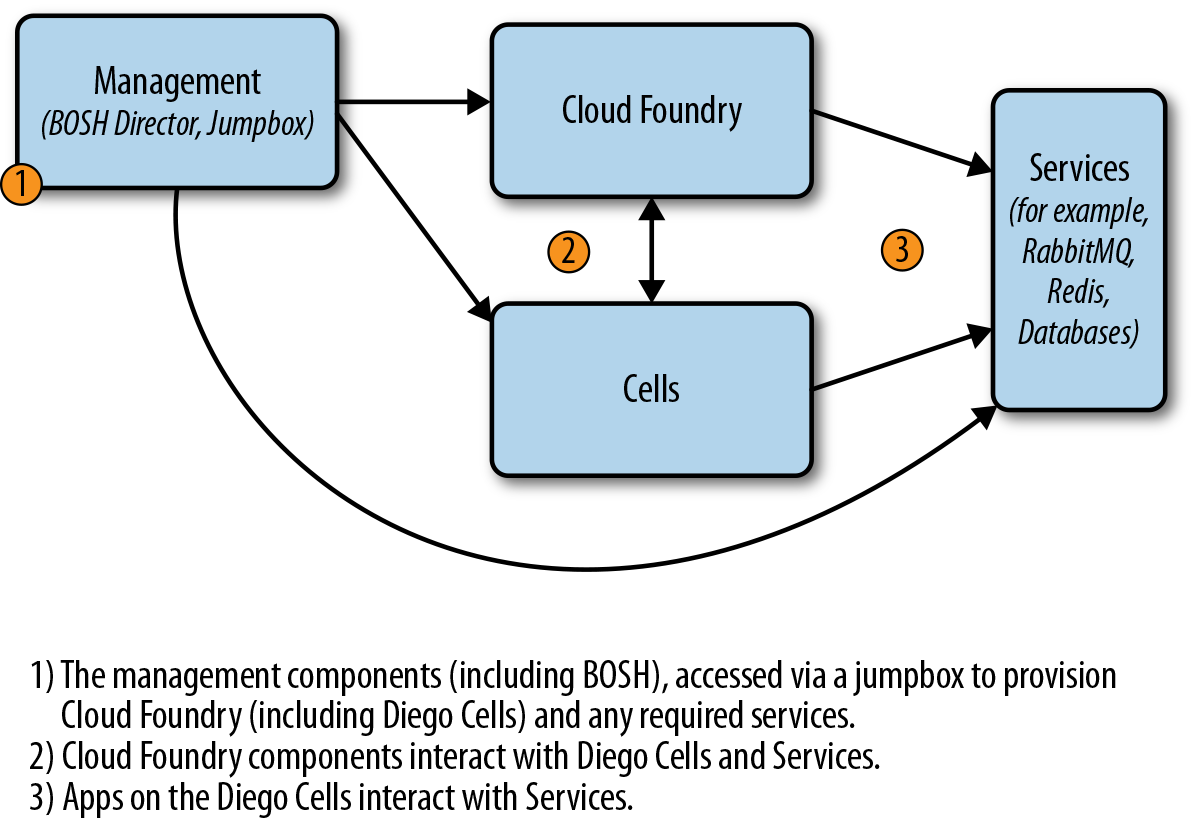
Figure 4-3. Subnet architecture example
Security Groups
Security group requirementsâwith respect to egress and ingress rulesâare defined in the Cloud Foundry documentation. It is worth noting that, when setting up the security group inbound rules, you will define SSH from your current IP. If you are on a corporate network, your IP will change as you hop on and off it. Therefore, if you are trying to use $ bosh create-env to update your environment, and you have a previously created security group policy, you might not have authority to connect to the Director VM as you try to establish a new connection. After the VM is fully set up, you can remove the âconnect from MyIPâ rules for SSH because they are no longer required.
Tip
bosh-bootloader will establish and configure the networking requirements (static IPs, subnets, security groups) on your behalf, across your VPC AZs.
Setting Up the Load Balancer
Application end users access applications via a generic domain such as myapp.com. A DNS is consulted as part of the path to the application; this is done to route traffic on to the correct Cloud Foundry installation.
Most Cloud Foundry deployments need more than one instance of the GoRouter for HA. However, DNS targets a single IP, often referred to as a VIP (virtual IP). Consequently, you need another device in front of the GoRouter to take requests on that IP and balance them across the available routers. In addition to balancing traffic, the load balancer (ELB in the case of AWS) can be used to terminate SSL or it can pass SSL on to the GoRouter for termination.
Tip
bosh-bootloader will create your AWS elastic load balancer and subsequent security groups.
Setting Up Domains and Certificates
Regardless of the installation approach you choose, your Cloud Foundry installation will need a registered wildcard domain for its default domain. You will need this registered domain when configuring your SSL certificate and Cloud Controller. For more information, read the AWS documentation on Creating a Server Certificate.
When setting up a single Cloud Foundry deployment, it is recommended that you have at least two default wildcard domains: a system domain and a separate application domain, as demonstrated here:
-
*.system.cf.com
-
*.apps.cf.com
The system domain allows Cloud Foundry to know about its internal components because Cloud Foundry itself runs some of its components as applications; for example, the UAA. Developers use the application domain to access their applications.
If Cloud Foundry had only one combined system and app domain, there would be no separation of concerns. A developer could register an app domain name that infers it was a potential system component. This can cause confusion to the Cloud Foundry operator as to what are system applications and what are developer-deployed applications. Even worse, if an app is mapped to an existing system-component route such as api.mycf.com, the Cloud Foundry environment can become unusable. This is discussed in âScenario Five: Route Collisionâ. By enforcing a separation of system and app domains, it is far more likely that you will avoid this scenario. Therefore, it is recommended that you always have at least one default system and default app domain per environment.
It is also recommended that you use unique system and application domain as opposed to deploying Cloud Foundry with a system domain that is in the appâs domain list. For instance, you should use the preceding example; do not use the following:
-
*.system.apps.cf.com
-
*.apps.cf.com
You will need an SSL certificate for your Cloud Foundry domains. This can be a self-signed certificate, but you should use a self-signed certificate only for testing and development. A certificate should be obtained from a certificate authority (CA) for use in production.
A quick and effective way to get started is the AWS Certificate Manager. This allows you to create SSL certificates (multidomain storage-area network [SAN], wildcard, etc.) for free if you are using the AWS ELB. This makes it very easy to get the âgreen padlockâ for Cloud Foundry on AWS environments. After it is authorized, a certificate will be issued and stored on the AWS ELB, allowing for secure HTTPS connections to your ELB.
You can use bosh-bootloader to generate and upload your AWS key and certificate. Alternatively, if you want to generate your certificate manually, you can use openssl as follows:
$ openssl req -sha256 -new -key <YOUR_KEY.pem> -out <YOUR_KEY_csr.pem>
$ openssl x509 -req -days 365 -in <YOUR_KEY_csr.pem> \
-signkey <YOUR_KEY.pem> -out <YOUR_CERT.pem>
If you are not using bosh-bootloader, you will need to add your key manually and upload the certificate to your VPC, as follows:
$ aws iam upload-server-certificate --server-certificate-name <YOUR_CERT_NAME> \
--certificate-body file://<YOUR_CERT.pem> \
--private-key file://<YOUR_KEY.pem>
One final point: be sure to register your chosen domain name in Route53 by creating the appropriate record to point to your ELB.
Summary
Cloud Foundry is a complex distributed system that requires forethought prior to deploying. How you configure and deploy Cloud Foundry becomes even more important if you intend to use your environment for production applications. Appropriate effort and assessment at the outset can help mitigate challenges such as future resource contention or infrastructure and component failure. This chapter explored both the technical and non-technical topics that require upfront consideration prior to deploying Cloud Foundry.
Although upfront sizing and architectural assessment is vital, keep in mind that timely progression toward an end state is always better then stagnation due to indecision. The benefit of Cloud Foundryâs rolling-upgrade capability is that it offers you the freedom to modify your environment at any point in the future.
Now that you are aware of the prerequisites, considerations, and decision points that are required prior to installing Cloud Foundry, Chapter 5 walks you through a Cloud Foundry installation.
1 Deployment and configuration steps are significantly easier to manage if using a CI pipeline such as Concourse.ci.
2 All companies I have worked with have adopted separate preproduction and production instances. From a technical standpoint, if you do not require strict networking segregation, and you size the environment for all workloads, then separate instances between preproduction and production are not required. However, the clean separation of concerns between the two environments is appealing for most companies, especially when considering additional concerns such as performance testing.
3 An example of such a deployment is documented at the Pivotal blog.
4 These reference architectures and tooling are designed for Pivotal Cloud Foundry. The rationale behind these resources holds true for all Cloud Foundry deployments with the exception of AI Packs and the Ops Manager VM, which can be discounted if you are not using Pivotal Cloud Foundry.
5 Diego is the subsystem responsible for app placement and the container life cycle.
6 bosh-bootloader will create this key-pair for you.
Get Cloud Foundry: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

