Database Management
The trickiest part of managing a cloud infrastructure is the management of your persistent data. Persistent data is essentially any data that needs to survive the destruction of your cloud environment. Because you can easily reconstruct your operating system, software, and simple configuration files, they do not qualify as persistent data. Only the data that cannot be reconstituted qualify. If you are following my recommendations, this data lives in your database engine.
The problem of maintaining database consistency is not unique to the cloud. The cloud simply brings a new challenge to an old problem of backing up your database, because your database server in the cloud will be much less reliable than your database server in a physical infrastructure. The virtual server running your database will fail completely and without warning. Count on it.
Whether physical or virtual, when a database server fails, there is the distinct possibility that the files that comprise the database state will get corrupted. The likelihood of that disaster depends on which database engine you are using, but it can happen with just about any engine out there.
Absent of corruption issues, dealing with a database server in the cloud is very simple. In fact, it is much easier to recover from the failure of a server in a virtualized environment than in the physical world: simply launch a new instance from your database machine image, mount the old block storage device, and you are up and running.
Note
Use block storage devices for database storage. Block storage devices provide the best performance option (better than local storage) and make for more flexible database backup strategies.
Clustering or Replication?
The most effective mechanism for avoiding corruption is leveraging the capabilities of a database engine that supports true clustering. In a clustered database environment, multiple database servers act together as a single logical database server. The mechanics of this process vary from database engine to database engine, but the result is that a transaction committed to the cluster will survive the failure of any one node and maintain full data consistency. In fact, clients of the database will never know that a node went down and will be able to continue operating.
Unfortunately, database clustering is very complicated and generally quite expensive.
Unless you have a skilled DBA on hand, you should not even consider undertaking the deployment of a clustered database environment.
A clustered database vendor often requires you to pay for the most expensive licenses to use the clustering capabilities in the database management system (DBMS). Even if you are using MySQL clustering, you will have to pay for five machine instances to effectively run that cluster.
Clustering comes with significant performance problems. If you are trying to cluster across distinct physical infrastructures—in other words, across availability zones—you will pay a hefty network latency penalty.
Warning
Although there are few challenges in clustering a database in the cloud, one is significant: the I/O challenges inherent in virtualized systems. In particular, write operations in a clustered system are very network intensive. As a result, heavy write applications will perform significantly worse in a clustered virtualized environment than in a standard data center.
The alternative to clustering is replication. A replication-based database infrastructure generally has a main server, referred to as the database master. Client applications execute write transactions against the database master. Successful transactions are then replicated to database slaves.
Replication has two key advantages over clustering:
It is generally much simpler to implement.
It does not require an excessive number of servers or expensive licenses.
Warning
MySQL replication is not a viable solution for anyone who absolutely, positively cannot lose one byte of data as a result of a server failure. If you are in this kind of business, you probably can afford clustering.
Unfortunately, replication is not nearly as reliable as clustering. A database master can, in theory, fail after it has committed a transaction locally but before the database slave has received it. In that event, you would have a database slave that is missing data. In fact, when a database master is under a heavy load, the database slave can actually fall quite far behind the master. If the master is somehow corrupted, it can also begin replicating corrupted data.
Apart from reliability issues, a replicated environment does not failover as seamlessly as a clustered solution. When your database master fails, clients using that master for write transactions cannot function until the master is recovered. On the other hand, when a node in a cluster fails, the clients do not notice the failure because the cluster simply continues processing transactions.
Using database clustering in the cloud
The good news, in general, is that the cloud represents few specific challenges to database clustering. The bad news is that every single database engine has a different clustering mechanism (or even multiple approaches to clustering) and thus an in-depth coverage of cloud-based clustering is beyond the scope of this book. I can, however, provide a few guidelines:
A few cluster architectures exist purely for performance and not for availability. Under these architectures, single points of failure may still exist. In fact, the complexity of clustering may introduce additional points of failure.
Clusters designed for high availability are often slower at processing individual write transactions, but they can handle much higher loads than standalone databases. In particular, they can scale to meet your read volume requirements.
Some solutions—such as MySQL—may require a large number of servers to operate effectively. Even if the licensing costs for such a configuration are negligible, the cloud costs will add up.
The dynamic nature of IP address assignment within a cloud environment may add new challenges in terms of configuring clusters and their failover rules.
Using database replication in the cloud
For most nonmission-critical database applications, replication is a “good enough” solution that can save you a lot of money and potentially provide you with opportunities for performance optimization. In fact, a MySQL replication system in the cloud can provide you with a flawless backup and disaster recovery system as well as availability that can almost match that of a cluster. Because the use of replication in the cloud can have such a tremendous impact compared to replication in a traditional data center, we’ll go into a bit more detail on using replication in the cloud than we did with clustering.
Figure 4-9 shows a simple replication environment.
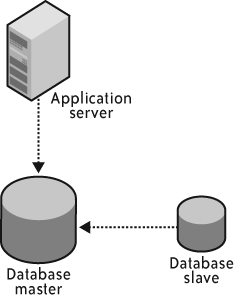
In this structure, you have a single database server of record (the master) replicating to one or more copies (the slaves). In general,[12] the process that performs the replication from the master to the slave is not atomic with respect to the original transaction. In other words, just because a transaction successfully commits on the master does not mean that it successfully replicated to any slaves. The transactions that do make it to the slaves are generally atomic, so although a slave may be out of sync, the database on the slave should always be in an internally consistent state (uncorrupted).
Under a simple setup, your web applications point to the database master. Consequently, your database slave can fail without impacting the web application. To recover, start up a new database slave and point it to the master.
Recovering from the failure of a database master is much more complicated. If your cloud provider is Amazon, it also comes with some extra hurdles you won’t see in a standard replication setup.
Ideally, you will recover your database master by starting a new virtual server that uses your database machine image and then mounting the volume that was formerly mounted by the failed server. The failure of your master, however, may have resulted in the corruption of the files on that volume. At this point, you will turn to the database slave.
A database can recover using a slave in one of two ways:
Promotion of a slave to database master (you will need to launch a replacement slave)
Building a new database master and exporting the current state from a slave to a new master
Promotion is the fastest mechanism for recovery and the approach you almost certainly want to take, unless you have a need for managing distinct database master and database slave machine images. If that’s the case, you may need to take the more complex recovery approach.
Warning
To develop a bulletproof replication architecture, you need to look beyond recovery from the slave. It is possible that your slave process stopped running long before the master failed or, worse, that the slave went down with the master. You should therefore have the capability of restoring from a volume snapshot and, in the worst-case scenario, from a database dump in your cloud storage system. You should also have monitoring slave status as a key part of your cloud monitoring infrastructure.
As with other components in your web application architecture, putting your database in a replication architecture gives it the ability to rapidly recover from a node failure and, as a result, significantly increases overall system availability rating.
For a more detailed discussion of MySQL replication, I recommend reading O’Reilly’s High Performance MySQL, by Baron Schwartz et al.
Replication for performance
Another reason to leverage replication is performance. Without segmenting your data, most database engines allow you to write against only the master, but you can read from the master or any of the slaves. An application heavy on read operations can therefore see significant performance benefits from spreading reads across slaves. Figure 4-10 illustrates the design of an application using replication for performance benefits.
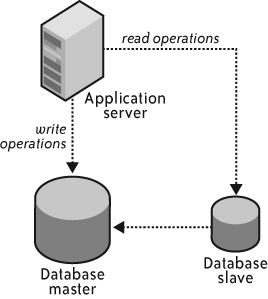
The rewards of using replication for performance are huge, but there are also risks. The primary risk is that you might accidentally execute a write operation against one of the slaves. When you do that, replication falls apart and your master and slaves end up in inconsistent states. Two approaches to solving this problem include:
Clearly separating read logic from write logic in your code and centralizing the acquisition of database connections.
Making your slave nodes read-only.
The second one is the most foolproof, but it complicates the process of promoting a slave to master because you must reconfigure the server out of read-only mode before promoting it.
Primary Key Management
With a web application operating behind a load balancer in which individual nodes within the web application do not share state information with each other, the problem of cross-database primary key generation becomes a challenge. The database engine’s auto-increment functionality is specific to the database you are using and not very flexible; it often is guaranteed to be unique only for a single server.
In Java Database Best Practices (O’Reilly; http://oreilly.com/catalog/9780596005221/index.html), I describe in detail a mechanism for generating keys in memory in an application server that are guaranteed to be unique across any number of application server nodes—even across multiple applications written in different languages. I’ll cover that technique at a high level here and add a new twist: the generation of random identifiers that are guaranteed to be unique across multiple nodes.
How to generate globally unique primary keys
First, you could use standard UUIDs to serve as your primary key mechanism. They have the benefit of an almost nonexistent chance of generating conflicts, and most programming languages have built-in functions for generating them. I don’t use them, however, for three reasons:
They are 128-bit values and thus take more space and have longer lookup times than the 64-bit primary keys I prefer.
Cleanly representing a 128-bit value in Java and some other programming languages is painful. In fact, the best way to represent such a value is through two separate values representing the 64 high bits and the 64 low bits, respectively.
The possibility of collisions, although not realistic, does exist.
In order to generate identifiers at the application server
level that are guaranteed to be unique in the target database,
traditionally I rely on the database to manage key generation. I
accomplish this through the creation of a sequencer table that hands out a key with
a safe key space. The application server is then free to generate
keys in that key space until the key space is exhausted.
Note
I prefer to use 64-bit integers for primary keys in databases. 64 bits provide a large key space with fast lookups. The technique I talk about here works with alphanumeric key generation as well.
The sequencer table looks
like this:
CREATE TABLE sequencer (
name VARCHAR(20) NOT NULL,
next_key BIGINT UNSIGNED NOT NULL,
last_update BIGINT UNSIGNED NOT NULL,
spacing INT UNSIGNED NOT NULL;
PRIMARY KEY ( name, last_update ),
UNIQUE INDEX ( name )
);The first thing of note here is that there is nothing specific to any database in this table structure and your keys are not tied to a particular table. If necessary, multiple tables can share the same primary key space. Similarly, you can generate unique identifiers that have nothing to do with a particular table in your database.
To generate a unique person_id for your person table:
Set up a
next_keyvalue in memory and initialize it to0.Grab the next
spacingandlast_updatefor thesequencerrecord with thename = 'person.person_id'.Add
1to the retrievednext_keyand update thesequencertable with thenameand retrievedlast_updatevalue in theWHEREclause.If no rows are updated (because another server beat you to the punch), repeat steps 2 and 3.
Set the next person ID to
next_key.Increment the
next_keyvalue by 1.The next time you need a unique person ID, simply execute steps 5 and 6 as long as
next_key < next_key + spacing. Otherwise, setnext_keyto0and repeat the entire process.
Within the application server, this entire process must be locked against multithreaded access.
Support for globally unique random keys
The technique for unique key generation just described generates (more or less) sequential identifiers. In some cases, it is important to remove reasonable predictability from identifier generation. You therefore need to introduce some level of randomness into the equation.
Warning
This technique is not truly random, but pseudorandom. There is no source of entropy in use for the randomly generated values, and the range of random values is sufficiently small for a determined guesser to break.
To get a random identifier, you need to multiply your next_key value by some power of 10 and
then add a random number generated through the random number
generator of your language of choice. The larger the random number
possibility, the smaller your overall key space is likely to be. On
the other hand, the smaller the random number possibility, the
easier your keys will be to guess.
The following Python example illustrates how to generate a pseudorandom unique person ID:
import thread
import random
nextKey = −1;
spacing = 100;
lock = thread.allocate_lock();
def next():
try:
lock.acquire(); # make sure only one thread at a time can access
if nextKey == −1 or nextKey > spacing:
loadKey();
nextId = (nextKey * 100000);
nextKey = nextKey + 1;
finally:
lock.release();
rnd = random.randint(0,99999);
nextId = nextId + rnd;
return nextId;You can minimize the wasting of key space by tracking the
allocation of random numbers and incrementing the nextKey value only after the random space
has been sufficiently exhausted. The further down that road you go,
however, the more likely you are to encounter the following
challenges:
The generation of unique keys will take longer.
Your application will take up more memory.
The randomness of your ID generation is reduced.
Database Backups
Throughout this book, I have hinted at the challenge of database backup management and its relationship to disaster recovery. I discuss the complete disaster recovery picture in the cloud in Chapter 6, but for now, I will deal with the specific problem of performing secure database backups in the cloud.
A good database backup strategy is hard, regardless of whether or not you are in the cloud. In the cloud, however, it is even more important to have a working database backup strategy.
Types of database backups
Most database engines provide multiple mechanisms for executing database backups. The rationale behind having different backup strategies is to provide a trade-off between the impact that executing a backup has on the production environment and the integrity of the data in the backup. Typically, your database engine will offer at least these backup options (in order of reliability):
Database export/dump backup
Filesystem backup
Transaction log backup
Note
Your database engine almost certainly provides other options. It may be valuable to tailor your backup processes to take advantage of those capabilities.
The most solid backup you can execute is the database export/dump. When you perform a database export, you dump the entire schema of the database and all of its data to one or more export files. You can then store the export files as the backup. During recovery, you can leverage the export files to restore into a pristine install of your database engine.
To execute a database export on SQL Server, for example, use the following command:
BACKUP DATABASE website to disk = 'D:\db\website.dump'The result is an export file you can move from one SQL Server environment to another SQL Server environment.
The downside of the database export is that your database server must be locked against writes in order to get a complete export that is guaranteed to be in an internally consistent state. Unfortunately, the export of a large database takes a long time to execute. As a result, full database exports against a production database generally are not practical.
Most databases provide the option to export parts of the database individually. For example, you could
dump just your access_log table
every night. In MySQL:
$ mysqldump website access_log > /backups/db/website.dumpIf the table has any dependencies on other tables in the system, however, you can end up with inconsistent data when exporting on a table-by-table basis. Partial exports are therefore most useful on data from a data warehouse.
Filesystem backups involve backing up all of the underlying files that support the database. For some database engines, the database is stored in one big file. For others, the tables and their schemas are stored across multiple files. Either way, a backup simply requires copying the database files to backup media.
Though a filesystem backup requires you to lock the database against updates, the lock time is typically shorter. In fact, the snapshotting capabilities of block storage devices generally reduce the lock time to under a second, no matter how large the database is.
The following SQL will freeze MySQL and allow you to snapshot the filesystem on which the database is stored:
FLUSH TABLES WITH READ LOCK
With the database locked, take a snapshot of the volume, and then release the lock.
The least disruptive kind of backup is the transaction log backup. As a database commits transactions, it writes those transactions to a transaction logfile. Because the transaction log contains only committed transactions, you can back up these transaction logfiles without locking the database or stopping. They are also smaller files and thus back up quickly. Using this strategy, you will create a full database backup on a nightly or weekly basis and then back up the transaction logs on a more regular basis.
Restoring from transaction logs involves restoring from the most recent full database backup and then applying the transaction logs. This approach is a more complex backup scheme than the other two because you have a number of files created at different times that must be managed together. Furthermore, restoring from transaction logs is the longest of the three restore options.
Applying a backup strategy for the cloud
The best backup strategy for the cloud is a file-based backup solution. You lock the database against writes, take a snapshot, and unlock it. It is elegant, quick, and reliable. The key cloud feature that makes this approach possible is the cloud’s ability to take snapshots of your block storage volumes. Without snapshot capabilities, this backup strategy would simply take too long.
Your backup strategy cannot, however, end with a file-based backup. Snapshots work beautifully within a single cloud, but they cannot be leveraged outside your cloud provider. In other words, an Amazon EC2 elastic block volume snapshot cannot be leveraged in a cloud deployment. To make sure your application is portable between clouds, you need to execute full database exports regularly.
How regularly you perform your database exports depends on how much data you can use. The underlying question you need to ask is, “If my cloud provider suddenly goes down for an extended period of time, how much data can I afford to lose when launching in a new environment?”
For a content management system, it may be OK in such an extreme situation to lose a week of data. An e-commerce application, however, cannot really afford to lose any data—even under such extreme circumstances.
My approach is to regularly execute full database exports against a MySQL slave, as shown in Figure 4-11.
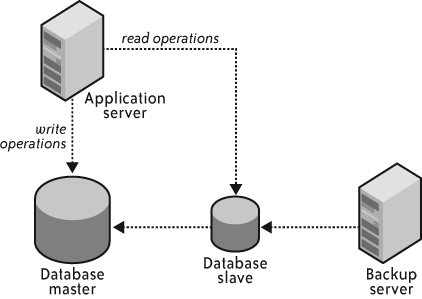
For the purposes of a backup, it does not matter if your database slave is a little bit behind the master. What matters is that the slave represents the consistent state of the entire database at a relatively reasonable point in time. You can therefore execute a very long backup against the slave and not worry about the impact on the performance of your production environment. Because you can execute long backups, you can also execute numerous backups bounded mostly by your data storage appetite.
If your database backups truly take such a long time to execute that you risk having your slaves falling very far behind the master, it makes sense to configure multiple slaves and rotate backups among the slaves. This rotation policy will give a slave sufficient time to catch up with the master after it has executed a backup and before it needs to perform its next backup.
Once the backup is complete, you should move it over to S3 and regularly copy those backups out of S3 to another cloud provider or your own internal file server.
Your application architecture should now be well structured to operate not only in the Amazon cloud, but in other clouds as well.
[12] This situation may not be the case for every configuration of every database engine in a replication architecture. Unless you know your replication is atomic with respect to the original transaction, however, assume your slave can be out of sync with the master at times.
Get Cloud Application Architectures now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

