Chapter 4. Sample Application
In this chapter, we create a complete sample application so we can see how all the parts fit together. We will use various parts of the API to see how to insert data, perform batch updates, and search column families and super column families.
To create the example, we want to use something that is complex enough to show the various data structures and basic API operations, but not something that will bog you down with details. In order to get enough data in the database to make our searches work right (by finding stuff we’re looking for and leaving out stuff we’re not looking for), there’s a little redundancy in the prepopulation of the database. Also, I wanted to use a domain that’s familiar to everyone so we can concentrate on how to work with Cassandra, not on what the application domain is all about.
Note
The code in this chapter has been tested against the 0.7 beta 1 release, and works as shown. It is possible that API changes may necessitate minor tuning on your part, depending on your version.
Data Design
When you set out to build a new data-driven application that will use a relational database, you might start by modeling the domain as a set of properly normalized tables and use foreign keys to reference related data in other tables. Now that we have an understanding of how Cassandra stores data, let’s create a little domain model that is easy to understand in the relational world, and then see how we might map it from a relational to a distributed hashtable model in Cassandra.
Relational modeling, in simple terms, means that you start from the conceptual domain and then represent the nouns in the domain in tables. You then assign primary keys and foreign keys to model relationships. When you have a many-to-many relationship, you create the join tables that represent just those keys. The join tables don’t exist in the real world, and are a necessary side effect of the way relational models work. After you have all your tables laid out, you can start writing queries that pull together disparate data using the relationships defined by the keys. The queries in the relational world are very much secondary. It is assumed that you can always get the data you want as long as you have your tables modeled properly. Even if you have to use several complex subqueries or join statements, this is usually true.
By contrast, in Cassandra you don’t start with the data model; you start with the query model.
For this example, let’s use a domain that is easily understood and that everyone can relate to: a hotel that wants to allow guests to book a reservation.
Our conceptual domain includes hotels, guests that stay in the hotels, a collection of rooms for each hotel, and a record of the reservation, which is a certain guest in a certain room for a certain period of time (called the “stay”). Hotels typically also maintain a collection of “points of interest,” which are parks, museums, shopping galleries, monuments, or other places near the hotel that guests might want to visit during their stay. Both hotels and points of interest need to maintain geolocation data so that they can be found on maps for mashups, and to calculate distances.
Note
Obviously, in the real world there would be many more considerations and much more complexity. For example, hotel rates are notoriously dynamic, and calculating them involves a wide array of factors. Here we’re defining something complex enough to be interesting and touch on the important points, but simple enough to maintain the focus on learning Cassandra.
Here’s how we would start this application design with Cassandra. First, determine your queries. We’ll likely have something like the following:
Find hotels in a given area.
Find information about a given hotel, such as its name and location.
Find points of interest near a given hotel.
Find an available room in a given date range.
Find the rate and amenities for a room.
Book the selected room by entering guest information.
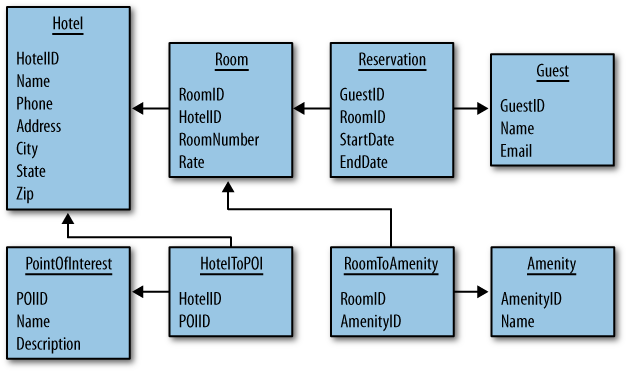
Hotel App RDBMS Design
Figure 4-1 shows how we might represent this simple hotel reservation system using a relational database model. The relational model includes a couple of “join” tables in order to resolve the many-to-many relationships of hotels-to-points of interest, and for rooms-to-amenities.
Hotel App Cassandra Design
Although there are many possible ways to do it, we could represent the same logical data model using a Cassandra physical model such as that shown in Figure 4-2.
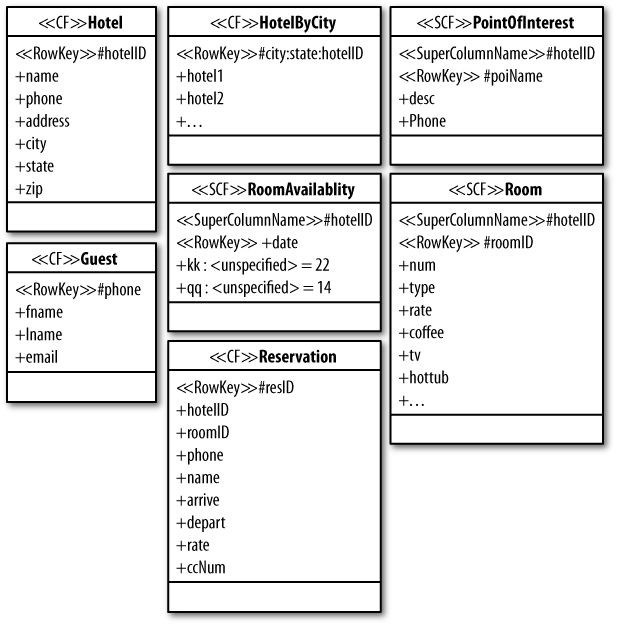
In this design, we’re doing all the same things as in the relational
design. We have transferred some of the tables, such as Hotel
and Guest, to column families. Other tables, such as
PointOfInterest, have been denormalized into a super column
family. In the relational model, you can look up hotels by the city
they’re in using a SQL statement. But because we don’t have SQL in
Cassandra, we’ve created an index in the form of the
HotelByCity column family.
Note
I’m using a stereotype notation here, so
<<CF>> refers to a column family,
<<SCF>> refers to a super column family, and so
on.
We have combined room and amenities into a single column family,
Room. The columns such as type and rate will have
corresponding values; other columns, such as hot tub, will just use the presence of the
column name itself as the value, and be otherwise empty.
Hotel Application Code
In this section we walk through the code and show how to implement the given design. This is useful because it illustrates several different API functions in action.
Warning
The purpose of this sample application is to show how different ideas in Cassandra can be combined. It is by no means the only way to transfer the relational design into this model. There is a lot of low-level plumbing here that uses the Thrift API. Thrift is (probably) changing to Avro, so although the basic ideas here work, you don’t want to follow this example in a real application. Instead, check out Chapter 8 and use one of the many available third-party clients for Cassandra, depending on the language that your application uses and other needs that you have.
The application we’re building will do the following things:
Create the database structure.
Prepopulate the database with hotel and point of interest data. The hotels are stored in standard column families, and the points of interest are in super column families.
Search for a list of hotels in a given city. This uses a secondary index.
Select one of the hotels returned in the search, and then search for a list of points of interest near the chosen hotel.
Booking the hotel by doing an insert into the
Reservationcolumn family should be straightforward at this point, and is left to the reader.
Space doesn’t permit implementing the entire application. But we’ll walk through the major parts, and finishing the implementation is just a matter of creating a variation of what is shown.
Creating the Database
The first step is creating the schema definition. For this example, we’ll define the schema in YAML and then load it, although you could also use client code to define it.
The YAML file shown in Example 4-1 defines the necessary keyspace and column families.
keyspaces:
- name: Hotelier
replica_placement_strategy: org.apache.cassandra.locator.RackUnawareStrategy
replication_factor: 1
column_families:
- name: Hotel
compare_with: UTF8Type
- name: HotelByCity
compare_with: UTF8Type
- name: Guest
compare_with: BytesType
- name: Reservation
compare_with: TimeUUIDType
- name: PointOfInterest
column_type: Super
compare_with: UTF8Type
compare_subcolumns_with: UTF8Type
- name: Room
column_type: Super
compare_with: BytesType
compare_subcolumns_with: BytesType
- name: RoomAvailability
column_type: Super
compare_with: BytesType
compare_subcolumns_with: BytesTypeThis definition provides all of the column families to run the example, and a couple more that we don’t directly reference in the application code, because it rounds out the design as transferred from RDBMS.
Loading the schema
Once you have the schema defined in YAML, you need to load it.
To do this, open a console, start the jconsole application, and
connect to Cassandra via JMX. Then, execute the operation
loadSchemaFromYAML, which is part of the
org.apache.cassandra.service.StorageService
MBean. Now Cassandra knows about your schema and you
can start using it. You can also use the API itself to create
keyspaces and column families.
Data Structures
The application requires some standard data structures that will
just act as transfer objects for us. These aren’t particularly
interesting, but are required to keep things organized. We’ll use a
Hotel data structure to hold all of the
information about a hotel, shown in Example 4-2.
package com.cassandraguide.hotel;
//data transfer object
public class Hotel {
public String id;
public String name;
public String phone;
public String address;
public String city;
public String state;
public String zip;
}This structure just holds the column information for convenience in the application.
We also have a POI data structure to hold
information about points of interest. This is shown in Example 4-3.
package com.cassandraguide.hotel;
//data transfer object for a Point of Interest
public class POI {
public String name;
public String desc;
public String phone;
}
We also have a Constants class, which keeps
commonly used strings in one easy-to-change place, shown in Example 4-4.
package com.cassandraguide.hotel;
import org.apache.cassandra.thrift.ConsistencyLevel;
public class Constants {
public static final String CAMBRIA_NAME = "Cambria Suites Hayden";
public static final String CLARION_NAME= "Clarion Scottsdale Peak";
public static final String W_NAME = "The W SF";
public static final String WALDORF_NAME = "The Waldorf=Astoria";
public static final String UTF8 = "UTF8";
public static final String KEYSPACE = "Hotelier";
public static final ConsistencyLevel CL = ConsistencyLevel.ONE;
public static final String HOST = "localhost";
public static final int PORT = 9160;
}Holding these commonly used strings make the code clearer and more concise, and you can easily change these values to reflect what makes sense in your environment.
Getting a Connection
For convenience, and to save repeating a bunch of boilerplate
code, let’s put the connection code into one class, called
Connector, shown in Example 4-5.
package com.cassandraguide.hotel;
import static com.cassandraguide.hotel.Constants.KEYSPACE;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.InvalidRequestException;
import org.apache.thrift.TException;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.transport.TTransport;
import org.apache.thrift.transport.TTransportException;
//simple convenience class to wrap connections, just to reduce repeat code
public class Connector {
TTransport tr = new TSocket("localhost", 9160);
// returns a new connection to our keyspace
public Cassandra.Client connect() throws TTransportException,
TException, InvalidRequestException {
TFramedTransport tf = new TFramedTransport(tr);
TProtocol proto = new TBinaryProtocol(tf);
Cassandra.Client client = new Cassandra.Client(proto);
tr.open();
client.set_keyspace(KEYSPACE);
return client;
}
public void close() {
tr.close();
}
}When we need to execute a database operation, we can use this class to open a connection and then close the connection once we’re done.
Prepopulating the Database
The
Prepopulate class, shown in Example 4-6, does a bunch of
inserts and
batch_mutates in order to
prepopulate the database with the hotel information and points of
interest information that users will search for.
package com.cassandraguide.hotel;
import static com.cassandraguide.hotel.Constants.CAMBRIA_NAME;
import static com.cassandraguide.hotel.Constants.CL;
import static com.cassandraguide.hotel.Constants.CLARION_NAME;
import static com.cassandraguide.hotel.Constants.UTF8;
import static com.cassandraguide.hotel.Constants.WALDORF_NAME;
import static com.cassandraguide.hotel.Constants.W_NAME;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.Clock;
import org.apache.cassandra.thrift.Column;
import org.apache.cassandra.thrift.ColumnOrSuperColumn;
import org.apache.cassandra.thrift.ColumnParent;
import org.apache.cassandra.thrift.ColumnPath;
import org.apache.cassandra.thrift.Mutation;
import org.apache.cassandra.thrift.SuperColumn;
import org.apache.log4j.Logger;
/**
* Performs the initial population of the database.
* Fills the CFs and SCFs with Hotel, Point of Interest, and index data.
* Shows batch_mutate and insert for Column Families and Super Column Families.
*
* I am totally ignoring exceptions to save space.
*/
public class Prepopulate {
private static final Logger LOG = Logger.getLogger(Prepopulate.class);
private Cassandra.Client client;
private Connector connector;
//constructor opens a connection so we don't have to
//constantly recreate it
public Prepopulate() throws Exception {
connector = new Connector();
client = connector.connect();
}
void prepopulate() throws Exception {
//pre-populate the DB with Hotels
insertAllHotels();
//also add all hotels to index to help searches
insertByCityIndexes();
//pre-populate the DB with POIs
insertAllPointsOfInterest();
connector.close();
}
//also add hotels to lookup by city index
public void insertByCityIndexes() throws Exception {
String scottsdaleKey = "Scottsdale:AZ";
String sfKey = "San Francisco:CA";
String newYorkKey = "New York:NY";
insertByCityIndex(scottsdaleKey, CAMBRIA_NAME);
insertByCityIndex(scottsdaleKey, CLARION_NAME);
insertByCityIndex(sfKey, W_NAME);
insertByCityIndex(newYorkKey, WALDORF_NAME);
}
//use Valueless Column pattern
private void insertByCityIndex(String rowKey, String hotelName)
throws Exception {
Clock clock = new Clock(System.nanoTime());
Column nameCol = new Column(hotelName.getBytes(UTF8),
new byte[0], clock);
ColumnOrSuperColumn nameCosc = new ColumnOrSuperColumn();
nameCosc.column = nameCol;
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc;
//set up the batch
Map<String, Map<String, List<Mutation>>> mutationMap =
new HashMap<String, Map<String, List<Mutation>>>();
Map<String, List<Mutation>> muts =
new HashMap<String, List<Mutation>>();
List<Mutation> cols = new ArrayList<Mutation>();
cols.add(nameMut);
String columnFamily = "HotelByCity";
muts.put(columnFamily, cols);
//outer map key is a row key
//inner map key is the column family name
mutationMap.put(rowKey, muts);
//create representation of the column
ColumnPath cp = new ColumnPath(columnFamily);
cp.setColumn(hotelName.getBytes(UTF8));
ColumnParent parent = new ColumnParent(columnFamily);
//here, the column name IS the value (there's no value)
Column col = new Column(hotelName.getBytes(UTF8), new byte[0], clock);
client.insert(rowKey.getBytes(), parent, col, CL);
LOG.debug("Inserted HotelByCity index for " + hotelName);
} //end inserting ByCity index
//POI
public void insertAllPointsOfInterest() throws Exception {
LOG.debug("Inserting POIs.");
insertPOIEmpireState();
insertPOICentralPark();
insertPOIPhoenixZoo();
insertPOISpringTraining();
LOG.debug("Done inserting POIs.");
}
private void insertPOISpringTraining() throws Exception {
//Map<byte[],Map<String,List<Mutation>>>
Map<byte[], Map<String, List<Mutation>>> outerMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
List<Mutation> columnsToAdd = new ArrayList<Mutation>();
Clock clock = new Clock(System.nanoTime());
String keyName = "Spring Training";
Column descCol = new Column("desc".getBytes(UTF8),
"Fun for baseball fans.".getBytes("UTF-8"), clock);
Column phoneCol = new Column("phone".getBytes(UTF8),
"623-333-3333".getBytes(UTF8), clock);
List<Column> cols = new ArrayList<Column>();
cols.add(descCol);
cols.add(phoneCol);
Map<String, List<Mutation>> innerMap =
new HashMap<String, List<Mutation>>();
Mutation columns = new Mutation();
ColumnOrSuperColumn descCosc = new ColumnOrSuperColumn();
SuperColumn sc = new SuperColumn();
sc.name = CAMBRIA_NAME.getBytes();
sc.columns = cols;
descCosc.super_column = sc;
columns.setColumn_or_supercolumn(descCosc);
columnsToAdd.add(columns);
String superCFName = "PointOfInterest";
ColumnPath cp = new ColumnPath();
cp.column_family = superCFName;
cp.setSuper_column(CAMBRIA_NAME.getBytes());
cp.setSuper_columnIsSet(true);
innerMap.put(superCFName, columnsToAdd);
outerMap.put(keyName.getBytes(), innerMap);
client.batch_mutate(outerMap, CL);
LOG.debug("Done inserting Spring Training.");
}
private void insertPOIPhoenixZoo() throws Exception {
Map<byte[], Map<String, List<Mutation>>> outerMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
List<Mutation> columnsToAdd = new ArrayList<Mutation>();
long ts = System.currentTimeMillis();
String keyName = "Phoenix Zoo";
Column descCol = new Column("desc".getBytes(UTF8),
"They have animals here.".getBytes("UTF-8"), new Clock(ts));
Column phoneCol = new Column("phone".getBytes(UTF8),
"480-555-9999".getBytes(UTF8), new Clock(ts));
List<Column> cols = new ArrayList<Column>();
cols.add(descCol);
cols.add(phoneCol);
Map<String, List<Mutation>> innerMap =
new HashMap<String, List<Mutation>>();
String cambriaName = "Cambria Suites Hayden";
Mutation columns = new Mutation();
ColumnOrSuperColumn descCosc = new ColumnOrSuperColumn();
SuperColumn sc = new SuperColumn();
sc.name = cambriaName.getBytes();
sc.columns = cols;
descCosc.super_column = sc;
columns.setColumn_or_supercolumn(descCosc);
columnsToAdd.add(columns);
String superCFName = "PointOfInterest";
ColumnPath cp = new ColumnPath();
cp.column_family = superCFName;
cp.setSuper_column(cambriaName.getBytes());
cp.setSuper_columnIsSet(true);
innerMap.put(superCFName, columnsToAdd);
outerMap.put(keyName.getBytes(), innerMap);
client.batch_mutate(outerMap, CL);
LOG.debug("Done inserting Phoenix Zoo.");
}
private void insertPOICentralPark() throws Exception {
Map<byte[], Map<String, List<Mutation>>> outerMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
List<Mutation> columnsToAdd = new ArrayList<Mutation>();
Clock clock = new Clock(System.nanoTime());
String keyName = "Central Park";
Column descCol = new Column("desc".getBytes(UTF8),
"Walk around in the park. It's pretty.".getBytes("UTF-8"), clock);
//no phone column for park
List<Column> cols = new ArrayList<Column>();
cols.add(descCol);
Map<String, List<Mutation>> innerMap =
new HashMap<String, List<Mutation>>();
Mutation columns = new Mutation();
ColumnOrSuperColumn descCosc = new ColumnOrSuperColumn();
SuperColumn waldorfSC = new SuperColumn();
waldorfSC.name = WALDORF_NAME.getBytes();
waldorfSC.columns = cols;
descCosc.super_column = waldorfSC;
columns.setColumn_or_supercolumn(descCosc);
columnsToAdd.add(columns);
String superCFName = "PointOfInterest";
ColumnPath cp = new ColumnPath();
cp.column_family = superCFName;
cp.setSuper_column(WALDORF_NAME.getBytes());
cp.setSuper_columnIsSet(true);
innerMap.put(superCFName, columnsToAdd);
outerMap.put(keyName.getBytes(), innerMap);
client.batch_mutate(outerMap, CL);
LOG.debug("Done inserting Central Park.");
}
private void insertPOIEmpireState() throws Exception {
Map<byte[], Map<String, List<Mutation>>> outerMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
List<Mutation> columnsToAdd = new ArrayList<Mutation>();
Clock clock = new Clock(System.nanoTime());
String esbName = "Empire State Building";
Column descCol = new Column("desc".getBytes(UTF8),
"Great view from 102nd floor.".getBytes("UTF-8"), clock);
Column phoneCol = new Column("phone".getBytes(UTF8),
"212-777-7777".getBytes(UTF8), clock);
List<Column> esbCols = new ArrayList<Column>();
esbCols.add(descCol);
esbCols.add(phoneCol);
Map<String, List<Mutation>> innerMap = new HashMap<String, List<Mutation>>();
Mutation columns = new Mutation();
ColumnOrSuperColumn descCosc = new ColumnOrSuperColumn();
SuperColumn waldorfSC = new SuperColumn();
waldorfSC.name = WALDORF_NAME.getBytes();
waldorfSC.columns = esbCols;
descCosc.super_column = waldorfSC;
columns.setColumn_or_supercolumn(descCosc);
columnsToAdd.add(columns);
String superCFName = "PointOfInterest";
ColumnPath cp = new ColumnPath();
cp.column_family = superCFName;
cp.setSuper_column(WALDORF_NAME.getBytes());
cp.setSuper_columnIsSet(true);
innerMap.put(superCFName, columnsToAdd);
outerMap.put(esbName.getBytes(), innerMap);
client.batch_mutate(outerMap, CL);
LOG.debug("Done inserting Empire State.");
}
//convenience method runs all of the individual inserts
public void insertAllHotels() throws Exception {
String columnFamily = "Hotel";
//row keys
String cambriaKey = "AZC_043";
String clarionKey = "AZS_011";
String wKey = "CAS_021";
String waldorfKey = "NYN_042";
//conveniences
Map<byte[], Map<String, List<Mutation>>> cambriaMutationMap =
createCambriaMutation(columnFamily, cambriaKey);
Map<byte[], Map<String, List<Mutation>>> clarionMutationMap =
createClarionMutation(columnFamily, clarionKey);
Map<byte[], Map<String, List<Mutation>>> waldorfMutationMap =
createWaldorfMutation(columnFamily, waldorfKey);
Map<byte[], Map<String, List<Mutation>>> wMutationMap =
createWMutation(columnFamily, wKey);
client.batch_mutate(cambriaMutationMap, CL);
LOG.debug("Inserted " + cambriaKey);
client.batch_mutate(clarionMutationMap, CL);
LOG.debug("Inserted " + clarionKey);
client.batch_mutate(wMutationMap, CL);
LOG.debug("Inserted " + wKey);
client.batch_mutate(waldorfMutationMap, CL);
LOG.debug("Inserted " + waldorfKey);
LOG.debug("Done inserting at " + System.nanoTime());
}
//set up columns to insert for W
private Map<byte[], Map<String, List<Mutation>>> createWMutation(
String columnFamily, String rowKey)
throws UnsupportedEncodingException {
Clock clock = new Clock(System.nanoTime());
Column nameCol = new Column("name".getBytes(UTF8),
W_NAME.getBytes("UTF-8"), clock);
Column phoneCol = new Column("phone".getBytes(UTF8),
"415-222-2222".getBytes(UTF8), clock);
Column addressCol = new Column("address".getBytes(UTF8),
"181 3rd Street".getBytes(UTF8), clock);
Column cityCol = new Column("city".getBytes(UTF8),
"San Francisco".getBytes(UTF8), clock);
Column stateCol = new Column("state".getBytes(UTF8),
"CA".getBytes("UTF-8"), clock);
Column zipCol = new Column("zip".getBytes(UTF8),
"94103".getBytes(UTF8), clock);
ColumnOrSuperColumn nameCosc = new ColumnOrSuperColumn();
nameCosc.column = nameCol;
ColumnOrSuperColumn phoneCosc = new ColumnOrSuperColumn();
phoneCosc.column = phoneCol;
ColumnOrSuperColumn addressCosc = new ColumnOrSuperColumn();
addressCosc.column = addressCol;
ColumnOrSuperColumn cityCosc = new ColumnOrSuperColumn();
cityCosc.column = cityCol;
ColumnOrSuperColumn stateCosc = new ColumnOrSuperColumn();
stateCosc.column = stateCol;
ColumnOrSuperColumn zipCosc = new ColumnOrSuperColumn();
zipCosc.column = zipCol;
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc;
Mutation phoneMut = new Mutation();
phoneMut.column_or_supercolumn = phoneCosc;
Mutation addressMut = new Mutation();
addressMut.column_or_supercolumn = addressCosc;
Mutation cityMut = new Mutation();
cityMut.column_or_supercolumn = cityCosc;
Mutation stateMut = new Mutation();
stateMut.column_or_supercolumn = stateCosc;
Mutation zipMut = new Mutation();
zipMut.column_or_supercolumn = zipCosc;
//set up the batch
Map<byte[], Map<String, List<Mutation>>> mutationMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
Map<String, List<Mutation>> muts =
new HashMap<String, List<Mutation>>();
List<Mutation> cols = new ArrayList<Mutation>();
cols.add(nameMut);
cols.add(phoneMut);
cols.add(addressMut);
cols.add(cityMut);
cols.add(stateMut);
cols.add(zipMut);
muts.put(columnFamily, cols);
//outer map key is a row key
//inner map key is the column family name
mutationMap.put(rowKey.getBytes(), muts);
return mutationMap;
}
//add Waldorf hotel to Hotel CF
private Map<byte[], Map<String, List<Mutation>>> createWaldorfMutation(
String columnFamily, String rowKey)
throws UnsupportedEncodingException {
Clock clock = new Clock(System.nanoTime());
Column nameCol = new Column("name".getBytes(UTF8),
WALDORF_NAME.getBytes("UTF-8"), clock);
Column phoneCol = new Column("phone".getBytes(UTF8),
"212-555-5555".getBytes(UTF8), clock);
Column addressCol = new Column("address".getBytes(UTF8),
"301 Park Ave".getBytes(UTF8), clock);
Column cityCol = new Column("city".getBytes(UTF8),
"New York".getBytes(UTF8), clock);
Column stateCol = new Column("state".getBytes(UTF8),
"NY".getBytes("UTF-8"), clock);
Column zipCol = new Column("zip".getBytes(UTF8),
"10019".getBytes(UTF8), clock);
ColumnOrSuperColumn nameCosc = new ColumnOrSuperColumn();
nameCosc.column = nameCol;
ColumnOrSuperColumn phoneCosc = new ColumnOrSuperColumn();
phoneCosc.column = phoneCol;
ColumnOrSuperColumn addressCosc = new ColumnOrSuperColumn();
addressCosc.column = addressCol;
ColumnOrSuperColumn cityCosc = new ColumnOrSuperColumn();
cityCosc.column = cityCol;
ColumnOrSuperColumn stateCosc = new ColumnOrSuperColumn();
stateCosc.column = stateCol;
ColumnOrSuperColumn zipCosc = new ColumnOrSuperColumn();
zipCosc.column = zipCol;
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc;
Mutation phoneMut = new Mutation();
phoneMut.column_or_supercolumn = phoneCosc;
Mutation addressMut = new Mutation();
addressMut.column_or_supercolumn = addressCosc;
Mutation cityMut = new Mutation();
cityMut.column_or_supercolumn = cityCosc;
Mutation stateMut = new Mutation();
stateMut.column_or_supercolumn = stateCosc;
Mutation zipMut = new Mutation();
zipMut.column_or_supercolumn = zipCosc;
//set up the batch
Map<byte[], Map<String, List<Mutation>>> mutationMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
Map<String, List<Mutation>> muts =
new HashMap<String, List<Mutation>>();
List<Mutation> cols = new ArrayList<Mutation>();
cols.add(nameMut);
cols.add(phoneMut);
cols.add(addressMut);
cols.add(cityMut);
cols.add(stateMut);
cols.add(zipMut);
muts.put(columnFamily, cols);
//outer map key is a row key
//inner map key is the column family name
mutationMap.put(rowKey.getBytes(), muts);
return mutationMap;
}
//set up columns to insert for Clarion
private Map<byte[], Map<String, List<Mutation>>> createClarionMutation(
String columnFamily, String rowKey)
throws UnsupportedEncodingException {
Clock clock = new Clock(System.nanoTime());
Column nameCol = new Column("name".getBytes(UTF8),
CLARION_NAME.getBytes("UTF-8"), clock);
Column phoneCol = new Column("phone".getBytes(UTF8),
"480-333-3333".getBytes(UTF8), clock);
Column addressCol = new Column("address".getBytes(UTF8),
"3000 N. Scottsdale Rd".getBytes(UTF8), clock);
Column cityCol = new Column("city".getBytes(UTF8),
"Scottsdale".getBytes(UTF8), clock);
Column stateCol = new Column("state".getBytes(UTF8),
"AZ".getBytes("UTF-8"), clock);
Column zipCol = new Column("zip".getBytes(UTF8),
"85255".getBytes(UTF8), clock);
ColumnOrSuperColumn nameCosc = new ColumnOrSuperColumn();
nameCosc.column = nameCol;
ColumnOrSuperColumn phoneCosc = new ColumnOrSuperColumn();
phoneCosc.column = phoneCol;
ColumnOrSuperColumn addressCosc = new ColumnOrSuperColumn();
addressCosc.column = addressCol;
ColumnOrSuperColumn cityCosc = new ColumnOrSuperColumn();
cityCosc.column = cityCol;
ColumnOrSuperColumn stateCosc = new ColumnOrSuperColumn();
stateCosc.column = stateCol;
ColumnOrSuperColumn zipCosc = new ColumnOrSuperColumn();
zipCosc.column = zipCol;
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc;
Mutation phoneMut = new Mutation();
phoneMut.column_or_supercolumn = phoneCosc;
Mutation addressMut = new Mutation();
addressMut.column_or_supercolumn = addressCosc;
Mutation cityMut = new Mutation();
cityMut.column_or_supercolumn = cityCosc;
Mutation stateMut = new Mutation();
stateMut.column_or_supercolumn = stateCosc;
Mutation zipMut = new Mutation();
zipMut.column_or_supercolumn = zipCosc;
//set up the batch
Map<byte[], Map<String, List<Mutation>>> mutationMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
Map<String, List<Mutation>> muts =
new HashMap<String, List<Mutation>>();
List<Mutation> cols = new ArrayList<Mutation>();
cols.add(nameMut);
cols.add(phoneMut);
cols.add(addressMut);
cols.add(cityMut);
cols.add(stateMut);
cols.add(zipMut);
muts.put(columnFamily, cols);
//outer map key is a row key
//inner map key is the column family name
mutationMap.put(rowKey.getBytes(), muts);
return mutationMap;
}
//set up columns to insert for Cambria
private Map<byte[], Map<String, List<Mutation>>> createCambriaMutation(
String columnFamily, String cambriaKey)
throws UnsupportedEncodingException {
//set up columns for Cambria
Clock clock = new Clock(System.nanoTime());
Column cambriaNameCol = new Column("name".getBytes(UTF8),
"Cambria Suites Hayden".getBytes("UTF-8"), clock);
Column cambriaPhoneCol = new Column("phone".getBytes(UTF8),
"480-444-4444".getBytes(UTF8), clock);
Column cambriaAddressCol = new Column("address".getBytes(UTF8),
"400 N. Hayden".getBytes(UTF8), clock);
Column cambriaCityCol = new Column("city".getBytes(UTF8),
"Scottsdale".getBytes(UTF8), clock);
Column cambriaStateCol = new Column("state".getBytes(UTF8),
"AZ".getBytes("UTF-8"), clock);
Column cambriaZipCol = new Column("zip".getBytes(UTF8),
"85255".getBytes(UTF8), clock);
ColumnOrSuperColumn nameCosc = new ColumnOrSuperColumn();
nameCosc.column = cambriaNameCol;
ColumnOrSuperColumn phoneCosc = new ColumnOrSuperColumn();
phoneCosc.column = cambriaPhoneCol;
ColumnOrSuperColumn addressCosc = new ColumnOrSuperColumn();
addressCosc.column = cambriaAddressCol;
ColumnOrSuperColumn cityCosc = new ColumnOrSuperColumn();
cityCosc.column = cambriaCityCol;
ColumnOrSuperColumn stateCosc = new ColumnOrSuperColumn();
stateCosc.column = cambriaStateCol;
ColumnOrSuperColumn zipCosc = new ColumnOrSuperColumn();
zipCosc.column = cambriaZipCol;
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc;
Mutation phoneMut = new Mutation();
phoneMut.column_or_supercolumn = phoneCosc;
Mutation addressMut = new Mutation();
addressMut.column_or_supercolumn = addressCosc;
Mutation cityMut = new Mutation();
cityMut.column_or_supercolumn = cityCosc;
Mutation stateMut = new Mutation();
stateMut.column_or_supercolumn = stateCosc;
Mutation zipMut = new Mutation();
zipMut.column_or_supercolumn = zipCosc;
//set up the batch
Map<byte[], Map<String, List<Mutation>>> cambriaMutationMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
Map<String, List<Mutation>> cambriaMuts =
new HashMap<String, List<Mutation>>();
List<Mutation> cambriaCols = new ArrayList<Mutation>();
cambriaCols.add(nameMut);
cambriaCols.add(phoneMut);
cambriaCols.add(addressMut);
cambriaCols.add(cityMut);
cambriaCols.add(stateMut);
cambriaCols.add(zipMut);
cambriaMuts.put(columnFamily, cambriaCols);
//outer map key is a row key
//inner map key is the column family name
cambriaMutationMap.put(cambriaKey.getBytes(), cambriaMuts);
return cambriaMutationMap;
}
}
This is a rather long example, but it attempts to show something
more than “hello, world”—there are a number of
insert and
batch_mutate operations shown with standard column families and super column
families. I have also included multiple rows for each type so that more
sophisticated queries are required.
This class is the first to execute in our sample application, and
once the prepopulate method is complete, your database will
have all the data that the search functions need to work with.
The Search Application
Example 4-7 is the Java class with the
main method that you should execute. It relies
on Log4J, so you’ll want to point to your
log4j.properties file when you run it. All you have
to do is run this class, and the database gets prepopulated with all of
the hotel and point of interest information; then, it allows the user to
search for hotels in a given city. The user picks one hotel, and the
application fetches the nearby points of interest. You can then
implement the remaining parts of the application to book a reservation
if you like.
package com.cassandraguide.hotel;
import static com.cassandraguide.hotel.Constants.CL;
import static com.cassandraguide.hotel.Constants.UTF8;
import java.util.ArrayList;
import java.util.List;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.Column;
import org.apache.cassandra.thrift.ColumnOrSuperColumn;
import org.apache.cassandra.thrift.ColumnParent;
import org.apache.cassandra.thrift.KeyRange;
import org.apache.cassandra.thrift.KeySlice;
import org.apache.cassandra.thrift.SlicePredicate;
import org.apache.cassandra.thrift.SliceRange;
import org.apache.cassandra.thrift.SuperColumn;
import org.apache.log4j.Logger;
/**
* Runs the hotel application. After the database is pre-populated,
* this class mocks a user interaction to perform a hotel search based on
* city, selects one, then looks at some surrounding points of interest for
* that hotel.
*
* Shows using Materialized View pattern, get, get_range_slices, key slices.
*
* These exceptions are thrown out of main to reduce code size:
* UnsupportedEncodingException,
InvalidRequestException, UnavailableException, TimedOutException,
TException, NotFoundException, InterruptedException
Uses the Constants class for some commonly used strings.
*/
public class HotelApp {
private static final Logger LOG = Logger.getLogger(HotelApp.class);
public static void main(String[] args) throws Exception {
//first put all of the data in the database
new Prepopulate().prepopulate();
LOG.debug("** Database filled. **");
//now run our client
LOG.debug("** Starting hotel reservation app. **");
HotelApp app = new HotelApp();
//find a hotel by city--try Scottsdale or New York...
List<Hotel> hotels = app.findHotelByCity("Scottsdale", "AZ");
//List<Hotel> hotels = app.findHotelByCity("New York", "NY");
LOG.debug("Found hotels in city. Results: " + hotels.size());
//choose one
Hotel h = hotels.get(0);
LOG.debug("You picked " + h.name);
//find Points of Interest for selected hotel
LOG.debug("Finding Points of Interest near " + h.name);
List<POI> points = app.findPOIByHotel(h.name);
//choose one
POI poi = points.get(0);
LOG.debug("Hm... " + poi.name + ". " + poi.desc + "--Sounds fun!");
LOG.debug("Now to book a room...");
//show availability for a date
//left as an exercise...
//create reservation
//left as an exercise...
LOG.debug("All done.");
}
//use column slice to get from Super Column
public List<POI> findPOIByHotel(String hotel) throws Exception {
///query
SlicePredicate predicate = new SlicePredicate();
SliceRange sliceRange = new SliceRange();
sliceRange.setStart(hotel.getBytes());
sliceRange.setFinish(hotel.getBytes());
predicate.setSlice_range(sliceRange);
// read all columns in the row
String scFamily = "PointOfInterest";
ColumnParent parent = new ColumnParent(scFamily);
KeyRange keyRange = new KeyRange();
keyRange.start_key = "".getBytes();
keyRange.end_key = "".getBytes();
List<POI> pois = new ArrayList<POI>();
//instead of a simple list, we get a map whose keys are row keys
//and the values the list of columns returned for each
//only row key + first column are indexed
Connector cl = new Connector();
Cassandra.Client client = cl.connect();
List<KeySlice> slices = client.get_range_slices(
parent, predicate, keyRange, CL);
for (KeySlice slice : slices) {
List<ColumnOrSuperColumn> cols = slice.columns;
POI poi = new POI();
poi.name = new String(slice.key);
for (ColumnOrSuperColumn cosc : cols) {
SuperColumn sc = cosc.super_column;
List<Column> colsInSc = sc.columns;
for (Column c : colsInSc) {
String colName = new String(c.name, UTF8);
if (colName.equals("desc")) {
poi.desc = new String(c.value, UTF8);
}
if (colName.equals("phone")) {
poi.phone = new String(c.value, UTF8);
}
}
LOG.debug("Found something neat nearby: " + poi.name +
". \nDesc: " + poi.desc +
". \nPhone: " + poi.phone);
pois.add(poi);
}
}
cl.close();
return pois;
}
//uses key range
public List<Hotel> findHotelByCity(String city, String state)
throws Exception {
LOG.debug("Seaching for hotels in " + city + ", " + state);
String key = city + ":" + state.toUpperCase();
///query
SlicePredicate predicate = new SlicePredicate();
SliceRange sliceRange = new SliceRange();
sliceRange.setStart(new byte[0]);
sliceRange.setFinish(new byte[0]);
predicate.setSlice_range(sliceRange);
// read all columns in the row
String columnFamily = "HotelByCity";
ColumnParent parent = new ColumnParent(columnFamily);
KeyRange keyRange = new KeyRange();
keyRange.setStart_key(key.getBytes());
keyRange.setEnd_key((key+1).getBytes()); //just outside lexical range
keyRange.count = 5;
Connector cl = new Connector();
Cassandra.Client client = cl.connect();
List<KeySlice> keySlices =
client.get_range_slices(parent, predicate, keyRange, CL);
List<Hotel> results = new ArrayList<Hotel>();
for (KeySlice ks : keySlices) {
List<ColumnOrSuperColumn> coscs = ks.columns;
LOG.debug(new String("Using key " + ks.key));
for (ColumnOrSuperColumn cs : coscs) {
Hotel hotel = new Hotel();
hotel.name = new String(cs.column.name, UTF8);
hotel.city = city;
hotel.state = state;
results.add(hotel);
LOG.debug("Found hotel result for " + hotel.name);
}
}
///end query
cl.close();
return results;
}
}
I interspersed the code with comments to illustrate the purpose of the different statements.
The output of running the application is shown in Example 4-8.
DEBUG 09:49:50,858 Inserted AZC_043 DEBUG 09:49:50,861 Inserted AZS_011 DEBUG 09:49:50,863 Inserted CAS_021 DEBUG 09:49:50,864 Inserted NYN_042 DEBUG 09:49:50,864 Done inserting at 6902368219815217 DEBUG 09:49:50,873 Inserted HotelByCity index for Cambria Suites Hayden DEBUG 09:49:50,874 Inserted HotelByCity index for Clarion Scottsdale Peak DEBUG 09:49:50,875 Inserted HotelByCity index for The W SF DEBUG 09:49:50,877 Inserted HotelByCity index for The Waldorf=Astoria DEBUG 09:49:50,877 Inserting POIs. DEBUG 09:49:50,880 Done inserting Empire State. DEBUG 09:49:50,881 Done inserting Central Park. DEBUG 09:49:50,885 Done inserting Phoenix Zoo. DEBUG 09:49:50,887 Done inserting Spring Training. DEBUG 09:49:50,887 Done inserting POIs. DEBUG 09:49:50,887 ** Database filled. ** DEBUG 09:49:50,889 ** Starting hotel reservation app. ** DEBUG 09:49:50,889 Seaching for hotels in Scottsdale, AZ DEBUG 09:49:50,902 Using key [B@15e9756 DEBUG 09:49:50,903 Found hotel result for Cambria Suites Hayden DEBUG 09:49:50,903 Found hotel result for Clarion Scottsdale Peak DEBUG 09:49:50,904 Found hotels in city. Results: 2 DEBUG 09:49:50,904 You picked Cambria Suites Hayden DEBUG 09:49:50,904 Finding Points of Interest near Cambria Suites Hayden DEBUG 09:49:50,911 Found something neat nearby: Phoenix Zoo. Desc: They have animals here.. Phone: 480-555-9999 DEBUG 09:49:50,911 Found something neat nearby: Spring Training. Desc: Fun for baseball fans.. Phone: 623-333-3333 DEBUG 09:49:50,911 Hm... Phoenix Zoo. They have animals here.--Sounds fun! DEBUG 09:49:50,911 Now to book a room... DEBUG 09:49:50,912 All done.
Again, you typically don’t want to write against Thrift or Avro yourself, but instead should use one of the clients listed in Chapter 8. The purpose here is to give you an idea of how the plumbing works, and to show a complete, working application that performs inserts and various searches and that resembles real-world usage.
Twissandra
When you start thinking about how to design for Cassandra, take a look at Twissandra, written by Eric Florenzano. Visit http://www.twissandra.com to see a fully working Twitter clone that you can download and try out. The source is all in Python, and it has a few dependencies on Django and a JSON library to sort out, but it’s a great place to start. You can use what’s likely a familiar data model (Twitter’s) and see how users, time lines, and tweets all fit into a simple Cassandra data model.
There is also a helpful post by Eric Evans explaining how to use Twissandra, which is available at http://www.rackspacecloud.com/blog/2010/05/12/cassandra-by-example.
Get Cassandra: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

