Chapter 4. Packets and Protocols
In order to understand firewall technology, you need to understand something about the underlying objects that firewalls deal with: packets and protocols. We provide a brief introduction to high-level IP[1] networking concepts (a necessity for understanding firewalls) here, but if you’re not already familiar with the topic, you will probably want to consult a more general reference on TCP/IP (for instance, TCP/IP Network Administration, by Craig Hunt, published by O’Reilly and Associates).
To transfer information across a network, the information has to be broken up into small pieces, each of which is sent separately. Breaking the information into pieces allows many systems to share the network, each sending pieces in turn. In IP networking, those small pieces of data are called packets. All data transfer across IP networks happens in the form of packets.
What Does a Packet Look Like?
To understand packet filtering, you first have to understand packets and how they are layered to build up the TCP/IP protocol stack, which is:
Application layer (e.g., FTP, Telnet, HTTP)
Transport layer (TCP or UDP)
Internet layer (IP)
Network access layer (e.g., Ethernet, FDDI, ATM)
Packets are constructed in such a way that layers for each protocol used for a particular connection are wrapped around the packets, like the layers of skin on an onion.
At each layer (except perhaps at the application layer), a packet has two parts: the header and the body. The header contains protocol information relevant to that layer, while the body contains the data for that layer, which often consists of a whole packet from the next layer in the stack. Each layer treats the information it gets from the layer above it as data, and applies its own header to this data. At each layer, the packet contains all of the information passed from the higher layer; nothing is lost. This process of preserving the data while attaching a new header is known as encapsulation.
At the application layer, the packet consists simply of the data to be transferred (for example, part of a file being transferred during an FTP session). As it moves to the transport layer, the Transmission Control Protocol (TCP) or the User Datagram Protocol (UDP) preserves the data from the previous layer and attaches a header to it. At the next layer, the Internet layer, IP considers the entire packet (consisting now of the TCP or UDP header and the data) to be data and now attaches its own IP header. Finally, at the network access layer, Ethernet or another network protocol considers the entire IP packet passed to it to be data and attaches its own header. Figure 4.1 shows how this works.
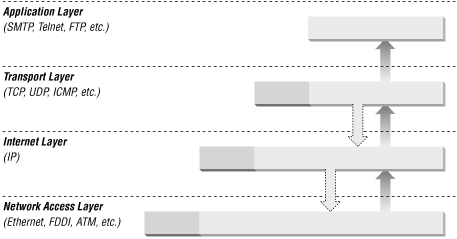
At the other side of the connection, this process is reversed. As the data is passed up from one layer to the next higher layer, each header (each skin of the onion) is stripped off by its respective layer. For example, the Internet layer removes the IP header before passing the encapsulated data up to the transport layer (TCP or UDP).
In trying to understand packet filtering, the most important information from our point of view is in the headers of the various layers. The following sections look at several examples of different types of packets and show the contents of each of the headers that packet filtering routers will be examining. We assume a certain knowledge of TCP/IP fundamentals and concentrate on discussing the particular issues related to packet filtering.
In the following discussion, we start with a simple example demonstrating TCP/IP over Ethernet. From there, we go on to discuss IP’s packet filtering characteristics, then protocols above IP (such as TCP, UDP, and ICMP), protocols below IP (such as Ethernet), and finally non-IP protocols (such as NetBEUI, AppleTalk, and IPX).
TCP/IP/Ethernet Example
Let’s consider an example of a TCP/IP packet (for example, one that is part of a Telnet connection) on an Ethernet.[2] We’re interested in four layers here: the Ethernet layer, the IP layer, the TCP layer, and the data layer. In this section, we’ll consider them from bottom to top and look at the contents of the headers that the packet filtering routers will be examining.
Ethernet layer
At the Ethernet layer, the packet consists of two parts: the Ethernet header and the Ethernet body. In general, you won’t be able to do packet filtering based on information in the Ethernet header. In some situations, you may be interested in Ethernet address information. The Ethernet address is also known as the MAC (Media Access Control) address. Basically, the header tells you:
- What kind of packet this is
We’ll assume in this example that it is an IP packet, as opposed to an AppleTalk packet, a Novell packet, a DECNET packet, or some other kind of packet.
- The Ethernet address of the machine that put the packet onto this particular Ethernet network segment
The original source machine, if it’s attached to this segment; otherwise, the last router in the path from the source machine to here.
- The Ethernet address of the packet’s destination on this particular Ethernet network segment
Perhaps the destination machine, if it’s attached to this segment; otherwise, the next router in the path from here to the destination machine. Occasionally it’s a broadcast address indicating that all machines should read the packet, or a multicast address indicating that a group of subscribing machines should read the packet.
Because we are considering IP packets in this example, we know that the Ethernet body contains an IP packet.
IP layer
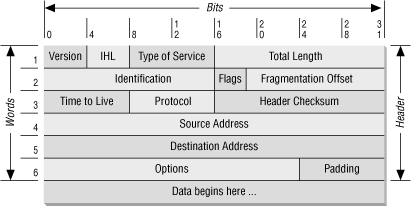
At the IP layer, the IP packet is made up of two parts: the IP header and the IP body, as shown in Figure 4.2. From a packet filtering point of view, the IP header contains four interesting pieces of information:
- The IP source address
Four bytes long and typically written as something like 172.16.244.34.
- The IP destination address
Just like the IP source address.
- The IP protocol type
Identifies the IP body as a TCP packet, as opposed to a UDP packet, an ICMP (Internet Control Message Protocol) packet, or some other type of packet.
- The IP options field
Almost always empty; where options like the IP source route and the IP security options would be specified if they were used for a given packet (see the discussion in Section 4.2.2, later in this chapter).
Most networks have a limit on the maximum length of a packet, which is much shorter than the limit imposed by IP. In order to deal with this conflict, IP may divide a packet that is too large to cross a given network into a series of smaller packets called fragments. Fragmenting a packet doesn’t change its structure at the IP layer (the IP headers are duplicated into each fragment), but it may mean that the body contains only a part of a packet at the next layer. (See the discussion in Section 4.2.3, later in this chapter.)
The IP body in this example contains an unfragmented TCP packet, although it could just as well contain the first fragment of a fragmented TCP packet.
TCP layer
At the TCP layer, the packet again contains two parts: the TCP header and the TCP body. From a packet filtering point of view, the TCP header contains three interesting pieces of information:
- The TCP source port
A two-byte number that specifies what client or server process the packet is coming from on the source machine.
- The TCP destination port
A two-byte number that specifies what client or server process the packet is going to on the destination machine.
- The TCP flags field
This field contains various flags that are used to indicate special kinds of packets, particularly during the process of setting up and tearing down TCP connections. These flags are discussed further in the sections that follow.
The TCP body contains the actual “data” being transmitted — for example, for Telnet the keystrokes or screen displays that are part of a Telnet session, or for FTP the data being transferred or commands being issued as part of an FTP session.
IP
IP serves as a common middle ground for the Internet. It can have many different layers below it, such as Ethernet, token ring, FDDI, PPP, or carrier pigeon.[3] IP can have many other protocols layered on top of it, with TCP, UDP, and ICMP being by far the most common, at least outside of research environments. In this section, we discuss the special characteristics of IP relevant to packet filtering.
IP Multicast and Broadcast
Most IP packets are what are called unicast; they are sent to an individual destination host. IP packets may also be multicast (sent to a group of hosts) or broadcast (intended for every host that can receive them). Multicast packets are like memos, which are sent to a group of people (“Employees in the purchasing department” or “People working on the Ishkabibble project” or “Potential softball players”); their destination is a group of hosts that ought to be interested in the information. Broadcast packets are like announcements made on overhead speakers; they are used when everybody needs the information (“The building is on fire, evacuate now”) or when the message’s sender can’t determine which particular destination should get the message, but believes that the destination will be able to figure it out (“The green Honda with license plate 4DZM362 has its lights on”).
The purpose of multicasting is to create efficiency. Unlike a memo, a multicast packet is a single object. If 7, or 17, or 70 hosts want the same information, a multicast packet allows you to get it to them by sending just one packet, instead of one packet each. A broadcast packet would give you the same savings in network resources, but it would waste computing time on the uninterested machines that would have to process the packet in order to decide it was irrelevant and reject it.
Note that multicast and broadcast addresses are meant as destination addresses, not as source addresses. A machine may use a broadcast address as a source address only if it does not have a legitimate source address and is trying to get one (see Chapter 22, for more information about DHCP, which may use this mechanism). Otherwise, multicast and broadcast source addresses are generally signs of an attacker who is using a destination machine as an amplifier. If a packet has a broadcast source address and a unicast destination address, any reply to it will have a unicast source address and a broadcast destination; thus, an attacker who uses a broadcast source can cause another machine to do the broadcasting.
This is a good deal for the attacker because it’s rare that packets with a broadcast destination are allowed to cross a firewall (or, in fact, any router). The attacker probably wouldn’t be able to get at a large number of hosts without using this kind of dirty trick. You don’t want broadcast information from other networks; it’s not relevant to your life, and it may be dangerous (either because it’s incorrect for your network, or because it allows attackers to gather information about your network). Routers are sometimes configured to pass some or all broadcasts between networks that are part of the same organization, because some protocols rely on broadcasts to distribute information. This is tricky to get right and tends to result in overloaded networks and hosts, but it is more acceptable than passing broadcasts to or from the Internet.
Your firewall should therefore refuse to pass packets with broadcast destinations and packets with multicast or broadcast source addresses.
IP Options
As we saw in the previous discussion of the IP layer, IP headers include an options field, which is usually empty. In its design, the IP options field was intended as a place for special information or handling instructions that didn’t have a specific field of their own in the header. However, TCP/IP’s designers did such a good job of providing fields for everything necessary that the options field is almost always empty. In practice, IP options are very seldom used except for break-in attempts and (very rarely) for network debugging.
The most common IP option a firewall would be confronted with is the IP source route option. Source routing lets the source of a packet specify the route the packet is supposed to take to its destination, rather than letting each router along the way use its routing tables to decide where to send the packet next. Source routing is supposed to override the instructions in the routing tables. In theory, the source routing option is useful for working around routers with broken or incorrect routing tables; if you know the route that the packet should take, but the routing tables are broken, you can override the bad information in the routing tables by specifying appropriate IP source route options on all your packets. In practice though, source routing is commonly used only by attackers who are attempting to circumvent security measures by causing packets to follow unexpected paths.
This is in fact a circular problem; several researchers have proposed interesting uses of source routing, which are impossible to use widely because source routing is commonly disabled—because it’s useful for nothing but attacks. This situation interferes considerably with widespread use of most solutions for mobile IP (allowing machines to move from place to place while keeping a fixed IP address).
Some packet filtering systems take the approach of dropping any packet that has any IP option set, without even trying to figure out what the option is or what it means; this doesn’t usually cause significant problems.
IP Fragmentation
Another IP-level consideration for packet filtering is fragmentation. One of the features of IP is its ability to divide a large packet that otherwise couldn’t traverse some network link (because of limitations on packet size along that link) into smaller packets, called fragments, which can traverse that link. The fragments are then reassembled into the full packet by the destination machine (not by the machine at the other end of the limited link; once a packet is fragmented, it normally stays fragmented until it reaches its destination).
Normally, any router can decide to fragment a packet. A flag in the IP header can be used to prevent routers from fragmenting packets. Originally, this wasn’t much used, because a router that needs to fragment a packet but is forbidden to do so will have to reject the packet, and communication will fail, which is generally less desirable than having the packet fragmented. However, there is now a system called path maximum transmission unit (MTU) discovery that uses the flag that prevents fragmentation.
Path MTU discovery is a way for systems to determine what is the largest packet that can be sent to another machine without getting fragmented. Large unfragmented packets are more efficient than small packets, but if packets have to be broken up later in the process, this will significantly decrease transfer speed. Therefore, maximum efficiency depends on knowing how big to make the packets, but that depends on all the network links between the machines. Neither machine has any way to know what the answer is (and, in fact, it may vary from moment to moment). In order to discover the limit, systems can send out packets with “don’t fragment” set and look for the error response that says that the packet has been dropped because it was too big but could not be fragmented. If there’s an error, the machine reduces the packet size; if there’s no error, it increases it. This adds some extra expense at the beginning of a connection, but for a connection that transmits a significant amount of data across a network that includes a limited link, the overall transmission time will probably be improved despite the intentionally lost packets. However, path MTU discovery will fail catastrophically if the error messages (which are ICMP messages, discussed later in this chapter) are not correctly returned (for instance, if your firewall drops them).
IP fragmentation is illustrated in Figure 4.3.
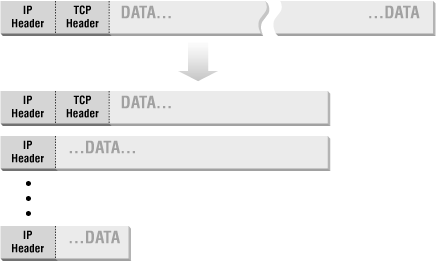
From a packet filtering point of view, the problem with fragmentation is that only the first fragment will contain the header information from higher-level protocols, like TCP, that the packet filtering system needs in order to decide whether or not to allow the full packet. Originally, the common packet filtering approach to dealing with fragmentation was to allow any non-first fragments through and to do packet filtering only on the first fragment of a packet. This was considered safe because if the packet filtering decides to drop the first fragment, the destination system will not be able to reassemble the rest of the fragments into the original packet, regardless of how many of the rest of the fragments it receives. If it can’t reconstruct the original packet, the partially reassembled packet will not be accepted.
However, there are still problems with fragmented packets. If you pass all non-first fragments, the destination host will hold the fragments in memory for a while, waiting to see if it gets the missing piece; this makes it possible for attackers to use fragmented packets in a denial of service attack. When the destination host gives up on reassembling the packet, it will send an ICMP “packet reassembly time expired” message back to the source host, which will tell an attacker that the host exists and why the connection didn’t succeed.
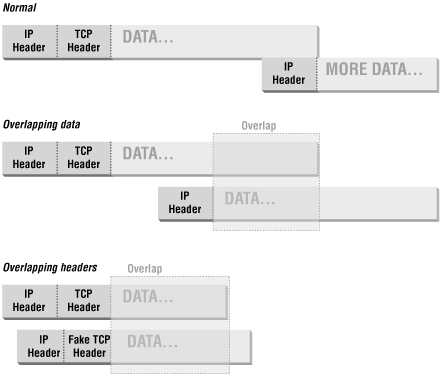
In addition, attackers can use specially fragmented packets to conceal data. Each fragment contains information about where the data it contains starts and ends. Normally, each one starts after the last one ended. However, an attacker can construct packets where fragments actually overlap, and contain the same data addresses. This does not happen in normal operation; it can happen only when bugs or attackers are involved, and attackers are by far the most likely cause.
Operating systems differ in their response to overlapping fragments. Because overlapping fragments are abnormal, many operating systems respond very badly to them and may reassemble them into invalid packets, with the expected sorts of unfortunate results up to and including operating system crashes. When they are reassembled, there are differences in whether the first or second fragment’s data is kept; these differences can be increased by sending the fragments out of order. Some machines prefer the first version received, others the most recent version received, others the numerically first, and still others the numerically last. This makes it nearly impossible for packet filtering or intrusion detection systems to figure out what data the receiving system will actually see if and when the fragments are reassembled.
Three kinds of attacks are made possible by overlapping fragments:
Simple denial of service attacks against hosts with poor responses to overlapping fragments.
Information-hiding attacks. If an attacker knows that virus detectors, intrusion detection systems, or other systems that pay attention to the content of packets are in use and can determine what assembly method the systems use for overlapping fragments, the attacker can construct overlapping fragments that will obscure content from the watching systems.
Attacks that get information to otherwise blocked ports. An attacker can construct a packet with acceptable headers in the first fragment but then overlap the next fragment so that it also has headers in it. Since packet filters don’t expect TCP headers in non-first fragments, they won’t filter on them, and the headers don’t need to be acceptable. Figure 4.4 shows overlapped fragments.
There are other, special problems with passing outbound fragments. Outbound fragments could conceivably contain data you don’t want to release to the world. For example, an outbound NFS packet would almost certainly be fragmented, and if the file were confidential, that information would be released. If this happens by accident, it’s unlikely to be a problem; people do not generally hang around looking at the data in random packets going by just in case there’s something interesting in them. You could wait a very long time for somebody to accidentally send a fragment out with interesting data in it.
If somebody inside intentionally uses fragmentation to transmit data, you have hostile users within the firewall, and no firewall can deal successfully with insiders. (They probably aren’t very clever hostile users, though, because there are easier ways to get data out.)
However, there is one other situation in which outbound fragments could carry data: if you have decided to deal with some vulnerability by blocking outbound responses to something (instead of attempting to block the original request on the incoming side, which would be a better idea), and the reply is fragmented. In this situation, non-first fragments of the reply will get out, and the attacker has reason to expect them and look for them. You can deal with this by being careful to filter out requests and by not relying on filtering out the replies.
Because of these many and varied problems with fragmentation, you should look for a packet filter that does fragment reassembly; rather than either permitting or denying fragments, the packet filter should reassemble the packet locally (and, if necessary, refragment it before sending it on). This will increase the load on the firewall somewhat, but it protects against all fragmentation-based risks and attacks, except those the firewall itself is vulnerable to (for instance, denial of service attacks based on sending non-first fragments until the firewall runs out of memory).
If you cannot do fragment reassembly, your safest option is to reject all non-first fragments. This may destroy connections that otherwise would have succeeded, but it is the lesser of two evils. Denying fragments will cause some connections to fail mysteriously, which is extremely unpleasant to debug. On the other hand, allowing them will open you to a variety of attacks that are widely exploited on the Internet. Fortunately, fragmented packets are becoming rarer as the use of path MTU discovery increases.
Protocols Above IP
IP serves as the base for a number of different protocols; by far the most common are TCP, UDP, and ICMP. In addition, we briefly discuss IP over IP (i.e., an IP packet encapsulated within another IP packet), which is used primarily for tunneling protocols over ordinary IP networks. This technique has been used in the past to tunnel multicast IP packets over nonmulticast IP networks, and more recently for a variety of virtual private networking systems, IPv6, and some systems for supporting mobile IP. These are the only IP-based protocols that you’re likely to see being routed between networks outside a research environment.[4]
TCP
TCP is the protocol most commonly used for services on the Internet. For example, Telnet, FTP, SMTP, NNTP, and HTTP are all TCP-based services. TCP provides a reliable, bidirectional connection between two endpoints. Opening a TCP connection is like making a phone call: you dial the number, and after a short setup period, a reliable connection is established between you and whomever you’re calling.
TCP is reliable in that it makes three guarantees to the application layer:
The destination will receive the application data in the order it was sent.
The destination will receive all the application data.
The destination will not receive duplicates of any of the application data.
TCP will kill a connection rather than violate one of these guarantees. For example, if TCP packets from the middle of a session are lost in transit to the destination, the TCP layer will arrange for those packets to be retransmitted before handing the data up to the application layer. It won’t hand up the data following the missing data until it has the missing data. If some of the data cannot be recovered, despite repeated attempts, the TCP layer will kill the connection and report this to the application layer, rather than hand up the data to the application layer with a gap in it.
These guarantees incur certain costs in both setup time (the two sides of a connection have to exchange startup information before they can actually begin moving data) and ongoing performance (the two sides of a connection have to keep track of the status of the connection, to determine what data needs to be resent to the other side to fill in gaps in the conversation).
TCP is bidirectional in that once a connection is established, a server can reply to a client over the same connection. You don’t have to establish one connection from a client to a server for queries or commands and another from the server back to the client for answers.
If you’re trying to block a TCP connection, it is sufficient to simply block the first packet of the connection. Without that first packet (and, more importantly, the connection startup information it contains), any further packets in that connection won’t be reassembled into a data stream by the receiver, and the connection will never be made. That first packet is recognizable because the ACK bit in its TCP header is not set; all other packets in the connection, regardless of which direction they’re going in, will have the ACK bit set. (As we will discuss later, another bit, called the SYN bit, also plays a part in connection negotiation; it must be on in the first packet, but it can’t be used to identify the first packet because it is also on in the second packet.)
Recognizing these “start-of-connection” TCP packets lets you enforce a policy that allows internal clients to connect to external servers but prevents external clients from connecting to internal servers. You do this by allowing start-of-connection TCP packets (those without the ACK bit set) only outbound and not inbound. Start-of-connection packets would be allowed out from internal clients to external servers but would not be allowed in from external clients to internal servers. Attackers cannot subvert this approach simply by turning on the ACK bit in their start-of-connection packets, because the absence of the ACK bit is what identifies these packets as start-of-connection packets.
Packet filtering implementations vary in how they treat and let you handle the ACK bit. Some packet filtering implementations give direct access to the ACK bit — for example, by letting you include “ack” as a keyword in a packet filtering rule. Some other implementations give indirect access to the ACK bit. For example, the Cisco “established” keyword works by examining this bit (established is “true” if the ACK bit is set, and “false” if the ACK bit is not set). Finally, some implementations don’t let you examine the ACK bit at all.
TCP options
The ACK bit is only one of the options that can be set; the whole list, in the order they appear in the header, is:
URG (urgent)
ACK (acknowledgment)
PSH (push)
RST (reset)
SYN (synchronize)
FIN (finish)
URG and PSH are supposed to be used to identify particularly critical data; PSH tells the receiver to stop buffering and let some program have the data, while URG more generally marks data that the sender thinks is particularly important (sometimes incorrectly called “out of band” data). In practice, neither of these is reliably implemented, and for most purposes, firewalls do not need to take special action based on them. It can be useful for firewalls to drop packets with URG or PSH set when dealing with protocols that are known not to use these features.
ACK and SYN together make up the famed TCP three-way handshake (so-called because it takes three packets to set up a connection). Figure 4.5 shows what ACK and SYN are set to on packets that are part of a TCP connection.
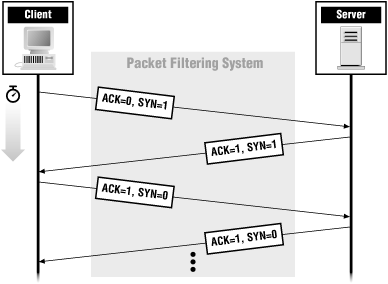
SYN is turned on for the first two packets of a connection (one in each direction), in order to set up sequence numbers. The first packet of a connection must have ACK off (since it isn’t in response to anything) but SYN on (to give the next packet a number to acknowledge). Sequence numbers are discussed further in the section that follows.
RST and FIN are ways of closing a connection. RST is an ungraceful close, sent to indicate that something has gone wrong (for instance, there’s no process listening on the port, or there seems to be something nasty about the packet that came in). FIN is part of a graceful shutdown, where both ends send FIN to each other to say goodbye.
Of this entire laundry list, ACK and RST are the only two of interest to a firewall in normal operation (ACK because it is a reliable way to identify the first packet of connections, and RST because it’s a useful way to shut people up without returning a helpful error message). However, there are a number of attacks that involve setting options that don’t normally get set. Many TCP/IP implementations respond badly to eccentric combinations of options (for instance, they crash the machine). Others respond but don’t log the fact, allowing attackers to scan networks without being noticed. These attacks are discussed further in the section that follows.
TCP sequence numbers
TCP provides a guarantee to applications that they will always receive data in the correct order, but nothing provides a guarantee to TCP that packets will always arrive in the correct order. In order to get the packets back into the correct order, TCP uses a number on each packet, called a sequence number. At the beginning of a connection, each end picks a number to start off with, and this number is what’s communicated when SYN is set. There are two packets with SYN set (one in each direction), because the two ends maintain separate sequence numbers, chosen independently. After the SYN, for each packet, the number is simply incremented by the number of data bytes in the packet. If the first sequence number is 200, and the first data packet has 80 bytes of data on it, it will have a sequence number of 280.[5] The ACK is accompanied by the number of the next expected piece of data (the sequence number plus one, or 281 in this case).
In order for an attacker to take over a TCP connection, the attacker needs to get the sequence numbers correct. Since sequence numbers are just incremented during a connection, this is easy for an attacker who can see the traffic. On the other hand, it’s much more difficult if you can’t see the initial negotiation; the initial sequence number is supposed to be randomly chosen. However, on many operating systems, initial sequence numbers are not actually random. In some TCP/IP implementations, initial sequence numbers are predictable; if you know what initial sequence number one connection uses, you can figure out what initial sequence number the next one will use, because the numbers are simply incremented, either based on number of connections (the number gets bigger by some fixed amount on each connection) or based on time (the number gets bigger by some fixed amount each microsecond).
This may seem like it’s not worth worrying about. After all, in order to hijack a connection by predicting sequence numbers, an attacker needs:
The ability to forge TCP/IP packets.
The initial sequence number for one connection.
The knowledge that somebody else has started up a desirable connection (but not the ability to actually see that connection—if the attacker can see the connection, there’s no need to predict the sequence number).
Precise information about when the desirable connection started up.
Either the ability to redirect traffic so that you receive responses, or the ability to continue the conversation and achieve something without ever getting any of the responses.
In fact, for years this was considered a purely hypothetical attack, something that paranoid minds came up with but that presented no danger in reality. However, it was eventually implemented, and programs are now available that simplify the process. It’s still not a technique that’s used routinely by casual attackers, but it’s available to determined attackers, even if they aren’t technically extremely advanced. You should be sure that security-critical hosts have truly random initial sequence numbers by installing an appropriate version of the operating system.
UDP
The body of an IP packet might contain a UDP packet instead of a TCP packet. UDP is a low-overhead alternative to TCP.
UDP is low overhead in that it doesn’t make any of the reliability guarantees (delivery, ordering, and nonduplication) that TCP does, and, therefore, it doesn’t need the mechanism to make those guarantees. Every UDP packet is independent; UDP packets aren’t part of a “virtual circuit” as TCP packets are. Sending UDP packets is like dropping postcards in the mail: if you drop 100 postcards in the mail, even if they’re all addressed to the same place, you can’t be absolutely sure that they’re all going to get there, and those that do get there probably won’t be in exactly the same order they were in when you sent them. (As it turns out, UDP packets are far less likely to arrive than postcards—but they are far more likely to arrive in the same order.)
Unlike postcards, UDP packets can actually arrive intact more than once. Multiple copies are possible because the packet might be duplicated by the underlying network. For example, on an Ethernet, a packet would be duplicated if a router thought that it might have been the victim of an Ethernet collision. If the router was wrong, and the original packet had not been the victim of a collision, both the original and the duplicate would eventually arrive at the destination. (An application may also decide to send the same data twice, perhaps because it didn’t get an expected response to the first one, or maybe just because it’s confused.)
All of these things can happen to TCP packets, too, but they will be corrected before the data is passed to the application. With UDP, the application is responsible for dealing with the data exactly as it arrives in packets, not corrected by the underlying protocol.
UDP packets are very similar to TCP packets in structure. A UDP header contains UDP source and destination port numbers, just like the TCP source and destination port numbers. However, a UDP header does not contain any of the flags or sequence numbers that TCP uses. In particular, it doesn’t contain anything resembling an ACK bit. The ACK bit is part of TCP’s mechanism for guaranteeing reliable delivery of data. Because UDP makes no such guarantees, it has no need for an ACK bit. There is no way for a packet filtering router to determine, simply by examining the header of an incoming UDP packet, whether that packet is a first packet from an external client to an internal server, or a response from an external server back to an internal client.
ICMP
ICMP is used for IP status and control messages. ICMP packets are carried in the body of IP packets, just as TCP and UDP packets are. Examples of ICMP messages include:
- Echo request
What a host sends when you run ping.
- Echo response
What a host responds to an “echo request” with.
- Time exceeded
What a router returns when it determines that a packet appears to be looping. A more intuitive name might be maximum hopcount exceeded because it’s based on the number of routers a packet has passed through, not a period of time.
- Destination unreachable
What a router returns when the destination of a packet can’t be reached for some reason (e.g., because a network link is down).
- Redirect
What a router sends a host in response to a packet the host should have sent to a different router. The router handles the original packet anyway (forwarding it to the router it should have gone to in the first place), and the redirect tells the host about the more efficient path for next time.
Unlike TCP or UDP, ICMP has no source or destination ports, and no other protocols layered on top of it. Instead, there is a set of defined ICMP message types; the particular type used dictates the interpretation of the rest of the ICMP packet. Some types also have individual codes that convey extra information (for instance, the “Destination unreachable” type has codes for different conditions that caused the destination to be unreachable, one of which is the “Fragmentation needed and Don’t Fragment set” code used for path MTU discovery).
Many packet filtering systems let you filter ICMP packets based on the ICMP message type field, much as they allow you to filter TCP or UDP packets based on the TCP or UDP source and destination port fields. Relatively few of them allow you to filter on codes within a type. This is a problem because you will probably want to allow “Fragmentation needed and Don’t Fragment set” (for path MTU discovery) but not any of the other codes under “Destination unreachable”, all of which can be used to scan networks to see what hosts are attackable.
Most ICMP packets have little or no meaningful information in the body of the packet, and therefore should be quite small. However, various people have discovered denial of service attacks using oversized ICMP packets (particularly echo packets, otherwise known as “ping” packets after the Unix command normally used to send them). It is a good idea to put a size limit on any ICMP packet types you allow through your filters.
There have also been attacks that use ICMP as a covert channel, a way of smuggling information. As we mentioned previously, most ICMP packet bodies contain little or no meaningful information. However, they may contain padding, the content of which is undefined. For instance, if you use ICMP echo for timing or testing reasons, you will want to be able to vary the length of the packets and possibly the patterns of the data in them (some transmission mechanisms are quite sensitive to bit patterns, and speeds may vary depending on how compressible the data is, for instance). You are therefore allowed to put arbitrary data into the body of ICMP echo packets, and that data is normally ignored; it’s not filtered, logged, or examined by anybody. For someone who wants to smuggle data through a firewall that allows ICMP echo, these bodies are a very tempting place to put it. They may even be able to smuggle data into a site that allows only outbound echo requests by sending echo responses even when they haven’t seen a request. This will be useful only if the machine that the responses are being sent to is configured to receive them; it won’t help anyone break into a site, but it’s a way for people to maintain connections to compromised sites.
IP over IP and GRE
In some circumstances, IP packets are encapsulated within other IP packets for transmission, yielding so-called IP over IP. IP over IP is used for various purposes, including:
Encapsulating encrypted network traffic; for instance, using the IPsec standard or PPTP, which are described in Chapter 14.
Carrying multicast IP packets (that is, packets with multicast destination addresses) between networks that do support multicasting over intermediate networks that don’t
Mobile IP (allowing a machine to move between networks while keeping a fixed IP address)
Carrying IPv6 traffic over IPv4 networks
Multiple different protocols are used for IP over IP, including protocols named Generic Routing Encapsulation (GRE), IP in IP, IP within IP, and swIPe. Currently, GRE appears to be the most popular. The general principle is the same in all cases; a machine somewhere picks up a packet, encapsulates it into a new IP packet, and sends it on to a machine that will unwrap it and process it appropriately.
In some cases (for instance, for multicast and IPv6 traffic), the encapsulation and de-encapsulation is done by special routers. The sending and receiving machines send out their multicast or IPv6 traffic without knowing anything about the network in between, and when they get to a point where the network will not handle the special type, a router does the encapsulation. In this case, the encapsulated packet will be addressed to another router, which will unwrap it. The encapsulation may also be done by the sending machine or the de-encapsulation by the receiving machine.
IP over IP is also a common technique used for creating virtual private networks, which are discussed further in Chapter 5. It is the basis for a number of higher-level protocols, including IPsec and PPTP, which are discussed further in Chapter 14.
IP over IP presents a problem for firewalls because the firewall sees the IP header information of the external packet, not the original information. In some cases, it is possible but difficult for the firewall to read the original headers; in other cases, the original packet information is encrypted, preventing it from being read by snoopers, but also by the firewall. This means that the firewall cannot make decisions about the internal packet, and there is a risk that it will pass traffic that should be denied. IP over IP should be permitted only when the destination of the external packet is a trusted host that will drop the de-encapsulated packet if it is not expected and permitted.
Protocols Below IP
It’s theoretically possible to filter on information from below the IP level — for example, the Ethernet hardware address. However, doing so is very rarely useful because in most cases, all packets from the outside are coming from the same hardware address (the address of the router that handles your Internet connection). Furthermore, many routers have multiple connections with different lower-level protocols. As a result, doing filtering at lower levels would require configuring different interfaces with different kinds of rules for the different lower-level protocols. You couldn’t write one rule to apply to all interfaces on a router that had two Ethernet connections and two FDDI connections because the headers of Ethernet and FDDI packets, while similar, are not identical. In practice, IP is the lowest level protocol at which people choose to do packet filtering.
However, if you are dealing with a network with a small, fixed number of machines on it, filtering based on hardware addresses is a useful technique for detecting and disabling machines that have been added inappropriately. (It is also a useful technique for making yourself look like an idiot when you exchange network boards, and an important machine suddenly and mysteriously stops working—better document it very carefully.) Even on relatively large networks, setting alarms based on hardware addresses will notify you when machines are changed or added. This may not be obvious based on IP address alone, since people who add new machines will often reuse an existing IP address.
Filtering based on hardware addresses is not a reliable security mechanism against hostile insiders. It is trivial to reset the apparent hardware address on most machines, so an attacker can simply choose to use the hardware address of a legitimate machine.
Application Layer Protocols
In most cases, there is a further protocol on top of any or all of the above protocols, specific to the application. These protocols differ widely in their specificity, and there are hundreds, if not thousands, of them (almost as many as there are network-based applications). Much of the rest of this book is about network applications and their protocols.
IP Version 6
The current version of IP (as we write) is officially known as IP Version 4; throughout this book, whenever we talk about IP with no further qualification, that’s what we’re talking about. There is, however, a new version of IP in the works right now, known as IP Version 6 (IPv6 for short). Why do we need a new version of IP, and how will IPv6 affect you?
The impetus to create IPv6 was one simple problem: the Internet is running out of IP addresses. The Internet has become so popular that there just won’t be enough IP network numbers (particularly Class B network numbers, which have proven to be what most sites need) to go around; by some estimates, if nothing had been done, the Internet would have run out of addresses in 1995 or 1996. Fortunately, the problem was recognized, and something was done. Two things, actually — first, the implementation of a set of temporary measures and guidelines to make best possible use of the remaining unassigned addresses, and second, the design and implementation of a new version of IP that would permanently deal with the address exhaustion issue.
If you’re going to create a new version of IP in order to deal with address-space exhaustion, you might as well take advantage of the opportunity to deal with a whole raft of other problems or limitations in IP as well, such as encryption, authentication, source routing, and dynamic configuration. (For many people, these limitations are the primary reasons for IPv6, and the addressing problem is merely a handy reason for other people to accept it.) This produces a number of implications for firewalls. According to Steve Bellovin of AT&T Bell Laboratories, a well-known firewalls expert and a participant in the IPv6 design process:[6]
IPv6 is based on the concept of nested headers. That’s how encryption and authentication are done; the “next protocol” field after the IPv6 header specifies an encryption or an authentication header. In turn, their next protocol fields would generally indicate either IPv6 or one of the usual transport protocols, such as TCP or UDP.
Nested IP over IP can be done even without encryption or authentication; that can be used as a form of source routing. A more efficient way is to use the source routing header — which is more useful than the corresponding IPv4 option, and is likely to be used much more, especially for mobile IP.
Some of the implications for firewalls are already apparent. A packet filter must follow down the full chain of headers, understanding and processing each one in turn. (And yes, this can make looking at port numbers more expensive.) A suitably cautious stance dictates that a packet with an unknown header be bounced, whether inbound or outbound. Also, the ease and prevalence of source routing means that cryptographic authentication is absolutely necessary. On the other hand, it is intended that such authentication be a standard, mandatory feature. Encrypted packets are opaque, and hence can’t be examined; this is true today, of course, but there aren’t very many encryptors in use now. That will change. Also note that encryption can be done host-to-host, host-to-gateway, or gateway-to-gateway, complicating the analysis still more.
Address-based filtering will also be affected, to some extent, by the new autoconfiguration mechanisms. It’s vital that any host whose address is mentioned in a filter receive the same address each time. While this is the intent of the standard mechanisms, one needs to be careful about proprietary schemes, dial-up servers, etc. Also, high-order address bits can change, to accommodate the combination of provider-based addressing and easy switching among carriers.
Finally, IPv6 incorporates “flows.” Flows are essentially virtual circuits at the IP level; they’re intended to be used for things like video, intermediate-hop ATM circuit selection, etc. But they can also be used for firewalls, given appropriate authentication: the UDP reply problem might go away if the query had a flow id that was referenced by the response. This, by the way, is a vague idea of mine; there are no standards for how this should be done. The regular flow setup protocol won’t work; it’s too expensive. But a firewall traversal header might do the job.
As you can see, IPv6 could have a major impact on firewalls, especially with respect to packet filtering. However, IPv6 is not being deployed rapidly. The address exhaustion problem doesn’t seem to be as bad as people had feared (under many estimates, the address space ought to have been gone before this edition made it to press). On the other hand, the problem of converting networks from IPv4 to IPv6 has turned out to be worse. The end result is that while IPv6 is still a viable technology that is gaining ground, it’s not going to take over from IPv4 in the immediate future; you’re going to need an IPv4 firewall for quite some time.
Non-IP Protocols
Other protocols at the same level as IP (e.g., AppleTalk and IPX) provide similar kinds of information as IP, although the headers and operations for these protocols, and therefore their packet filtering characteristics, vary radically. Most packet filtering implementations support IP filtering only and simply drop non-IP packets. Some packages provide limited packet filtering support for non-IP protocols, but this support is usually far less flexible and capable than the router’s IP filtering capability.
At this time, packet filtering as a tool isn’t as popular and well developed for non-IP protocols, presumably because these protocols are rarely used to communicate outside a single organization over the Internet. (The Internet is, by definition, a network of IP networks.) If you are putting a firewall between parts of your network, you may find that you need to pass non-IP protocols.
In this situation, you should be careful to evaluate what level of security you are actually getting from the filtering. Many packages that claim to support packet filtering on non-IP protocols simply mean that they can recognize non-IP packets as legal packets and allow them through, with minimal logging. For reasonable support of non-IP protocols, you should look for a package developed by people with expertise in the protocol, and you should make sure that it provides features appropriate to the protocol you’re trying to filter. Products that were designed as IP routers but claim to support five or six other protocols are probably just trying to meet purchasing requirements, not to actually meet operational requirements well.
Across the Internet, non-IP protocols are handled by encapsulating them within IP protocols. In most cases, you will be limited to permitting or denying encapsulated protocols in their entirety; you can accept all AppleTalk-in-UDP connections, or reject them all. A few packages that support non-IP protocols can recognize these connections when encapsulated and filter on fields in them.
Attacks Based on Low-Level Protocol Details
As we’ve discussed protocols, we’ve also mentioned some of the attacks against them. You will often see attacks discussed using the names given to them by the people who wrote the original exploit programs, which are eye-catching but not informative. These names multiply daily, and there’s no way for us to document them all here, but we can tell you about a few of the most popular. In fact, although there are dozens and dozens of different attacks, they are pretty much all variations on the same few themes, and knowing the name of the day isn’t very important.
Port Scanning
Port scanning is the process of looking for open ports on a machine, in order to figure out what might be attackable. Straightforward port scanning is quite easy to detect, so attackers use a number of methods to disguise port scans. For instance, many machines don’t log connections until they’re fully made, so an attacker can send an initial packet, with a SYN but no ACK, get back the response (another SYN if the port is open, a RST if it is not), and then stop there. (This is often called a SYN scan or a half open scan.) Although this won’t get logged, it may have other unfortunate effects, particularly if the scanner fails to send a RST when it stops (for instance, it may end up being a denial of service attack against the host or some intermediate device that’s trying to keep track of open connections, like a firewall).
Attackers may also send other packets, counting a port as closed if they get a RST and open if they get no response, or any other error. Almost any combination of flags other than SYN by itself can be used for this purpose, although the most common options are FIN by itself, all options on, and all options off. The last two possibilities, sometimes called Christmas tree (some network devices show the options with lights, and it makes them all light up like a Christmas tree) and null, tend to have unfortunate side effects on weak TCP/IP stacks. Many devices will either crash or disable TCP/IP.
Implementation Weaknesses
Many of the attacks that work at this level are denial of service attacks that exploit weaknesses in TCP/IP implementations to crash machines. For instance, teardrop and its relatives send overlapping fragments; there are also attacks that send invalid combinations of options, set invalid length fields, or mark data as urgent when no application would (winnuke).
IP Spoofing
In IP spoofing, an attacker sends packets with an incorrect source address. When this happens, replies will be sent to the apparent source address, not to the attacker. This might seem to be a problem, but actually, there are three cases where the attacker doesn’t care:
The attacker can intercept the reply.
The attacker doesn’t need to see the reply.
The attacker doesn’t want the reply; the point of the attack is to make the reply go somewhere else.
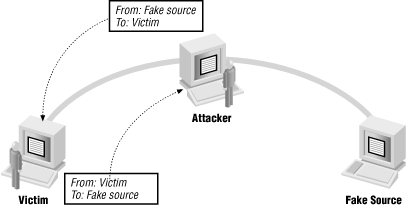
The attacker can intercept the reply
If an attacker is somewhere on the network between the destination and the forged source, the attacker may be able to see the reply and carry on a conversation indefinitely. This is the basis of hijacking attacks, which are discussed in more detail later. Figure 4.6 shows an attacker using a forgery this way.
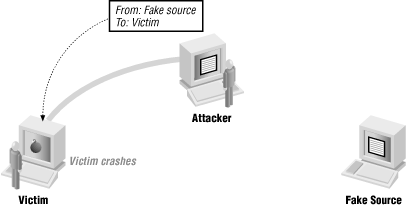
The attacker doesn’t need to see the reply
An attacker doesn’t always care what the reply is. If the attack is a denial of service, the attacked machine probably isn’t going to be able to reply anyway. Even if it isn’t, the attacker may be able to make a desired change without needing to see the response. Figure 4.7 shows this kind of attack.
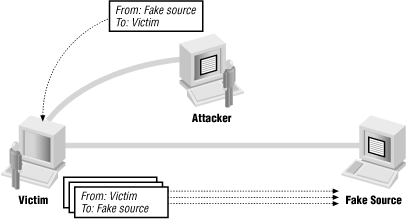
The attacker doesn’t want the reply
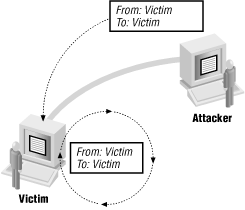
Several attacks rely upon the fact that the reply (or better yet, lots of replies) will go somewhere else. The smurf attack uses forged source addresses to attack the host that’s the apparent source; an attacker sends a forged packet to some host he or she doesn’t like very much (call it “apparentvictim”) with a source address of a host that he or she doesn’t like at all (call it “realvictim”). “apparentvictim” then replies to “realvictim”, tying up network resources at both victim sites but not at the attacker’s actual location. The administrators at “apparentvictim” and “realvictim” then start arguing about who is attacking whom and why. This attack has a number of variants using different protocols and methods for multiplying the replies. The most common protocols are ICMP echo and the UDP-based echo service, both of which are discussed in Chapter 22. The most common method of multiplying the replies is to use a broadcast address as the source address. Figure 4.8 shows this kind of attack.
The land attack sends a packet with a source identical to the destination, which causes many machines to lock up. Figure 4.9 shows this kind of attack.
Packet Interception
Reading packets as they go by, frequently called packet sniffing, is a frequent way of gathering information. If you’re passing around important information unencrypted, it may be all that an attacker needs to do.
In order to read a packet, the attacker needs to get the packet somehow. The easiest way to do that is to control some machine that the traffic is supposed to go through anyway (a router or a firewall, for instance). These machines are usually highly protected, however, and don’t usually provide tools that an attacker might want to use.
Usually, it’s more practical for an attacker to use some less-protected machine, but that means that the attacker needs to be able to read packets that are not addressed to the machine itself. On some networks, that’s very easy. An Ethernet network that uses a bus topology, or that uses 10-base T cabling with unintelligent hubs, will send every packet on the network to every machine. Token-ring networks, including FDDI rings, will send most or all packets to all machines. Machines are supposed to ignore the packets that aren’t addressed to them, but anybody with full control over a machine can override this and read all the packets, no matter what destination they were sent to.
Using a network switch to connect machines is supposed to avoid this problem. A network switch, by definition, is a network device that has multiple ports and sends traffic only to those ports that are supposed to get it. Unfortunately, switches are not an absolute guarantee. Most switches have an administrative function that will allow a port to receive all traffic. Sometimes there’s a single physical port with this property, but sometimes the switch can turn this function on for any port, so that an attacker who can subvert the switch software can get all traffic. Furthermore, switches have to keep track of which addresses belong to which ports, and they only have a finite amount of space to store this information. If that space is exhausted (for instance, because an attacker is sending fake packets from many different addresses), the switch will fail. Some of them will stop sending packets anywhere; others will simply send all packets to all ports; and others provide a configuration parameter to allow you to choose a failure mode.
Some switches offer increased separation of traffic with a facility called a Virtual Local Area Network (VLAN). On a normal switch, all the ports are part of the same network. A switch that supports VLANs will be able to treat different ports as parts of different networks. Traffic is only supposed to go between ports on different VLANs if a router is involved, just as if the ports were on completely separate switches. Normal tricks to confuse switches will compromise only one VLAN. VLANs are a convenient tool in many situations, and they provide a small measure of increased security over a plain switched network. However, you are still running all of the traffic through a single device, which could be compromised. There are known attacks that will move traffic from one VLAN to another in most implementations, and almost any administrative error will compromise the separation. You should not rely on VLANs to provide strong, secure separation between networks.
[1] Unless otherwise noted, we are discussing IP version 4, which is the version currently in common use.
[2] Ethernet is the most popular networking protocol currently at the link layer; 10-base T and 100-base T networks are almost always Ethernet networks.
[3] See RFC 1149, dated 1 April 1990, which defines the Avian Transport Protocol; RFCs dated 1 April are usually worth reading.
[4] You may also see the routing protocols OSPF or IGMP, which are discussed in Chapter 22. However, they are rarely distributed between networks and do not form the basis for other protocols.
[5] The details of how the sequence number is calculated are actually slightly more complex than this, but the end result is as described.
[6] Steve Bellovin, posting to the Firewalls mailing list, 31 December 1994.
Get Building Internet Firewalls, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

