Preface
We live in a world increasingly filled with digital assistants that allow us to connect with other people as well as vast information resources. Part of the appeal of these smart devices is that they do not simply convey information; to a limited extent, they also understand it—facilitating human interaction at a high level by aggregating, filtering, and summarizing troves of data into an easily digestible form. Applications such as machine translation, question-and-answer systems, voice transcription, text summarization, and chatbots are becoming an integral part of our computing lives.
If you have picked up this book, it is likely that you are as excited as we are by the possibilities of including natural language understanding components into a wider array of applications and software. Language understanding components are built on a modern framework of text analysis: a toolkit of techniques and methods that combine string manipulation, lexical resources, computation linguistics, and machine learning algorithms that convert language data to a machine understandable form and back again. Before we get started discussing these methods and techniques, however, it is important to identify the challenges and opportunities of this framework and address the question of why this is happening now.
The typical American high school graduate has memorized around 60,000 words and thousands of grammatical concepts, enough to communicate in a professional context. While this may seem like a lot, consider how trivial it would be to write a short Python script to rapidly access the definition, etymology, and usage of any term from an online dictionary. In fact, the variety of linguistic concepts an average American uses in daily practice represents merely one-tenth the number captured in the Oxford dictionary, and only 5% of those currently recognized by Google.
And yet, instantaneous access to rules and definitions is clearly not sufficient for text analysis. If it were, Siri and Alexa would understand us perfectly, Google would return only a handful of search results, and we could instantly chat with anyone in the world in any language. Why is there such a disparity between computational versions of tasks humans can perform fluidly from a very early age—long before they’ve accumulated a fraction of the vocabulary they will possess as adults? Clearly, natural language requires more than mere rote memorization; as a result, deterministic computing techniques are not sufficient.
Computational Challenges of Natural Language
Rather than being defined by rules, natural languages are defined by use and must be reverse-engineered to be computed on. To a large degree, we are able to decide what the words we use mean, though this meaning-making is necessarily collaborative. Extending “crab” from a marine animal to a person with a sour disposition or a specific sidewise form of movement requires both the speaker/author and the listener/reader to agree on meaning for communication to occur. Language is therefore usually constrained by community and region—converging on meaning is often much easier with people who inhabit similar lived experiences to our own.
Unlike formal languages, which are necessarily domain specific, natural languages are general purpose and universal. We use the same word to order seafood for lunch, write a poem about a malcontent, and discuss astronomic nebulae. In order to capture the extent of expression across a variety of discourse, language must be redundant. Redundancy presents a challenge—since we cannot (and do not) specify a literal symbol for every association, every symbol is ambiguous by default. Lexical and structural ambiguity is the primary achievement of human language; not only does ambiguity give us the ability to create new ideas, it also allows people with diverse experiences to communicate, across borders and cultures, in spite of the near certainty of occasional misunderstandings.
Linguistic Data: Tokens and Words
In order to fully leverage the data encoded in language, we must retrain our minds to think of language not as intuitive and natural but as arbitrary and ambiguous. The unit of text analysis is the token, a string of encoded bytes that represent text. By contrast, words are symbols that are representative of meaning, and which map a textual or verbal construct to a sound and sight component. Tokens are not words (though it is hard for us to look at tokens and not see words). Consider the token "crab", shown in Figure P-1. This token represents the word sense crab-n1—the first definition of the noun use of the token, a crustacean that can be food, lives near an ocean, and has claws that can pinch.
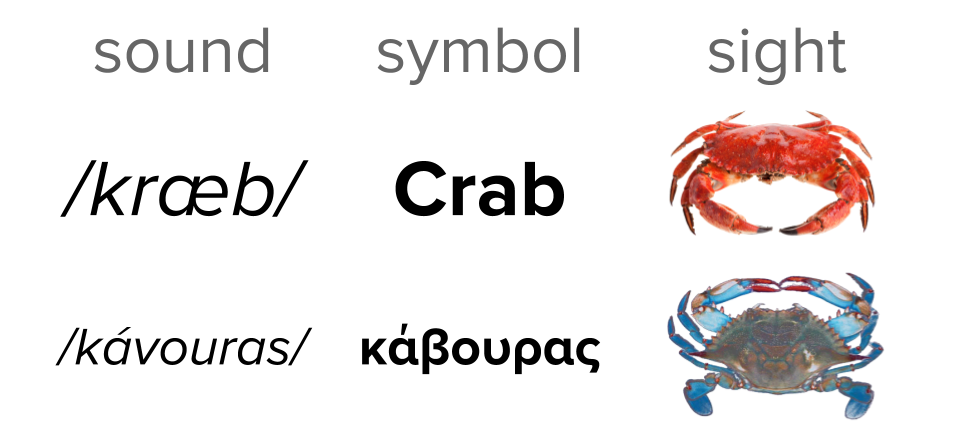
Figure P-1. Words map symbols to ideas
All of these other ideas are somehow attached to this symbol, and yet the symbol is entirely arbitrary; a similar mapping to a Greek reader will have slightly different connotations yet maintain the same meaning. This is because words do not have a fixed, universal meaning independent of contexts such as culture and language. Readers of English are used to adaptive word forms that can be prefixed and suffixed to change tense, gender, etc. Chinese readers, on the other hand, recognize many pictographic characters whose order decides meaning.
Redundancy, ambiguity, and perspective mean that natural languages are dynamic, quickly evolving to encompass current human experience. Today we don’t bat an eye at the notion that there could be a linguistic study of emoticons sufficiently complete to translate Moby Dick!1 Even if we could systematically come up with a grammar that defines how emoticons work, by the time we finish, language will have moved on—even the language of emoticons! For example, since we started writing this book, the emoji symbol for a pistol (🔫) has evolved from a weapon to a toy (at least when rendered on a smartphone), reflecting a cultural shift in how we perceive the use of that symbol.
It’s not just the inclusion of new symbols and structures that adapt language, but also the inclusion of new definitions, contexts, and usages. The token “battery” has shifted in meaning as a result of the electronic age to mean a repository for converting chemical energy to electricity. However, according to the Google Books Ngram Viewer2 “battery” enjoyed far more usage, meaning also a connected array of machines or a fortified emplacement for heavy guns during the last part of the 19th century and beginning of the 20th. Language is understood in context, which goes beyond just the surrounding text to include also the time period. Clearly identifying and recognizing the meaning of words requires more computation than simply looking up an entry in a dictionary.
Enter Machine Learning
The same qualities that make natural language such a rich tool for human communication also make it difficult to parse using deterministic rules. The flexibility that humans employ in interpretation is why, with a meager 60,000 symbolic representations, we can far outperform computers when it comes to instant understanding of language. Therefore in a software environment, we need computing techniques that are just as fuzzy and flexible, and so the current state-of-the-art for text analysis is statistical machine learning techniques. While applications that perform natural language processing have been around for several decades, the addition of machine learning enables a degree of flexibility and responsiveness that would not otherwise be possible.
The goal of machine learning is to fit existing data to some model, creating a representation of the real world that is able to make decisions or generate predictions on new data based on discovered patterns. In practice, this is done by selecting a model family that determines the relationship between the target data and the input, specifying a form that includes parameters and features, then using some optimization procedure to minimize the error of the model on the training data. The fitted model can now be introduced to new data on which it will make a prediction—returning labels, probabilities, membership, or values based on the model form. The challenge is to strike a balance between being able to precisely learn the patterns in the known data and being able to generalize so the model performs well on examples it has never seen before.
Many language-aware software applications are comprised of not just a single machine-trained model but a rich tapestry of models that interact and influence each other. Models can also be retrained on new data, target new decision spaces, and even be customized per user so that they can continue to develop as they encounter new information and as different aspects of the application change over time. Under the hood of the application, competing models can be ranked, age, and eventually perish. This means that machine learning applications implement life cycles that can keep up with dynamism and regionality associated with language with a routine maintenance and monitoring workflow.
Tools for Text Analysis
Because text analysis techniques are primarily applied machine learning, a language that has rich scientific and numeric computing libraries is necessary. When it comes to tools for performing machine learning on text, Python has a powerhouse suite that includes Scikit-Learn, NLTK, Gensim, spaCy, NetworkX, and Yellowbrick.
-
Scikit-Learn is an extension of SciPy (Scientific Python) that provides an API for generalized machine learning. Built on top of Cython to include high-performance C-libraries such as LAPACK, LibSVM, Boost, and others, Scikit-Learn combines high performance with ease of use to analyze small- to medium-sized datasets. Open source and commercially usable, it provides a single interface to many regression, classification, clustering, and dimensionality reduction models along with utilities for cross-validation and hyperparameter tuning.
-
NLTK, the Natural Language Tool-Kit, is a “batteries included” resource for NLP written in Python by experts in academia. Originally a pedagogical tool for teaching NLP, it contains corpora, lexical resources, grammars, language processing algorithms, and pretrained models that allow Python programmers to quickly get started processing text data in a variety of languages.
-
Gensim is a robust, efficient, and hassle-free library that focuses on unsupervised semantic modeling of text. Originally designed to find similarity between documents (generate similarity), it now exposes topic modeling methods for latent semantic techniques, and includes other unsupervised libraries such as word2vec.
-
spaCy provides production-grade language processing by implementing the academic state-of-the-art into a simple and easy-to-use API. In particular, spaCy focuses on preprocessing text for deep learning or to build information extraction or natural language understanding systems on large volumes of text.
-
NetworkX is a comprehensive graph analytics package for generating, serializing, analyzing, and manipulating complex networks. Although not specifically a machine learning or text analysis library, graph data structures are able to encode complex relationships that graph algorithms can traverse or find meaning in, and is therefore a critical part of the text analysis toolkit.
-
Yellowbrick is a suite of visual diagnostic tools for the analysis and interpretation of machine learning workflows. By extending the Scikit-Learn API, Yellowbrick provides intuitive and understandable visualizations of feature selection, modeling, and hyperparameter tuning, steering the model selection process to find the most effective models of text data.
What to Expect from This Book
In this book, we focus on applied machine learning for text analysis using the Python libraries just described. The applied nature of the book means that we focus not on the academic nature of linguistics or statistical models, but instead on how to be effective at deploying models trained on text inside of a software application.
The model for text analysis we propose is directly related to the machine learning workflow—a search process to find a model composed of features, an algorithm, and hyperparameters that best operates on training data to produce estimations on unknown data. This workflow starts with the construction and management of a training dataset, called a corpus in text analysis. We will then explore feature extraction and preprocessing methodologies to compose text as numeric data that machine learning can understand. With some basic features in hand, we explore techniques for classification and clustering on text, concluding the first few chapters of the book.
The latter chapters focus on extending models with richer features to create text-aware applications. We begin by exploring how context can be embedded as features, then move on to a visual interpretation of text to steering the model selection process. Next, we examine how to analyze complex relationships extracted from text using graph analysis techniques. We then change focus to explore conversational agents and deepen our understanding of syntactic and semantic analysis of text. We conclude the book with a practical discussion of scaling text analysis with multiprocessing and Spark, and finally, we explore the next phase of text analytics: deep learning.
Who This Book Is For
This book is for Python programmers who are interested in applying natural language processing and machine learning to their software development toolkit. We don’t assume any special academic background or mathematical knowledge from our readers, and instead focus on tools and techniques rather than lengthy explanations. We do primarily analyze the English language in this book, so basic grammatical knowledge such as how nouns, verbs, adverbs, and adjectives are related to each other is helpful. Readers who are completely new to machine learning and linguistics but have a solid understanding of Python programming will not feel overwhelmed by the concepts we present.
Code Examples and GitHub Repository
The code examples found in this book are meant to be descriptive of how to implement Python code to execute particular tasks. Because they are targeted toward readers, they are concise, often omitting key statements required during execution; for example, import statements from the standard library. Additionally they often build on code from other parts of the book or the chapter and occasionally pieces of code that must be modified slightly in order to work in the new context. For example, we may define a class as follows:
classThing(object):def__init__(self,arg):self.property=arg
This class definition serves to describe the basic properties of the class and sets up the structure of a larger conversation about implementation details. Later we may add methods to the class as follows:
...defmethod(self,*args,**kwargs):returnself.property
Note the ellipsis at the top of the snippet, indicating that this is a continuation from the class definition in the previous snippet. This means that simply copying and pasting example snippets may not work. Importantly, the code also is designed to operate on data that must be stored on disk in a location readable by the executing Python program. We have attempted to be as general as possible, but cannot account for all operating systems or data sources.
In order to support our readers who may want to run the examples found in this book, we have implemented complete, executable examples on our GitHub repository. These examples may vary slightly from the text but should be easily runnable with Python 3 on any system. Also note that the repository is kept up-to-date; check the README to find any changes that have occurred. You can of course fork the repository and modify the code for execution in your own environment—which we strongly encourage you to do!
Conventions Used in This Book
The following typographical conventions are used in this book:
- Italic
-
Indicates new terms, URLs, email addresses, filenames, and file extensions.
Constant width-
Used for program listings, as well as within paragraphs to refer to program elements such as variable or function names, databases, data types, environment variables, statements, and keywords.
Constant width bold-
Shows commands or other text that should be typed literally by the user.
Constant width italic-
Shows text that should be replaced with user-supplied values or by values determined by context.
Tip
This element signifies a tip or suggestion.
Note
This element signifies a general note.
Warning
This element indicates a warning or caution.
Using Code Examples
Supplemental material (code examples, exercises, etc.) is available for download at https://github.com/foxbook/atap.
This book is here to help you get your job done. In general, if example code is offered with this book, you may use it in your programs and documentation. You do not need to contact us for permission unless you’re reproducing a significant portion of the code. For example, writing a program that uses several chunks of code from this book does not require permission. Selling or distributing a CD-ROM of examples from O’Reilly books does require permission. Answering a question by citing this book and quoting example code does not require permission. Incorporating a significant amount of example code from this book into your product’s documentation does require permission.
We appreciate, but do not require, attribution. An attribution usually includes the title, author, publisher, and ISBN. For example: “Applied Text Analysis with Python by Benjamin Bengfort, Rebecca Bilbro, and Tony Ojeda (O’Reilly). 978-1-491-96304-3.”
The BibTex for this book is as follows:
@book{title ={Applied{{Text Analysis}}with{{Python}}}, subtitle ={Enabling Language Aware{{Data Products}}}, shorttitle ={Applied{{Text Analysis}}with{{Python}}}, publisher ={{O'Reilly Media, Inc.}}, author ={Bengfort, Benjamin and Bilbro, Rebecca and Ojeda, Tony}, month = jun, year ={2018}}
If you feel your use of code examples falls outside fair use or the permission given above, feel free to contact us at permissions@oreilly.com.
O’Reilly Safari
Note
Safari (formerly Safari Books Online) is a membership-based training and reference platform for enterprise, government, educators, and individuals.
Members have access to thousands of books, training videos, Learning Paths, interactive tutorials, and curated playlists from over 250 publishers, including O’Reilly Media, Harvard Business Review, Prentice Hall Professional, Addison-Wesley Professional, Microsoft Press, Sams, Que, Peachpit Press, Adobe, Focal Press, Cisco Press, John Wiley & Sons, Syngress, Morgan Kaufmann, IBM Redbooks, Packt, Adobe Press, FT Press, Apress, Manning, New Riders, McGraw-Hill, Jones & Bartlett, and Course Technology, among others.
For more information, please visit http://oreilly.com/safari.
How to Contact Us
Please address comments and questions concerning this book to the publisher:
- O’Reilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (in the United States or Canada)
- 707-829-0515 (international or local)
- 707-829-0104 (fax)
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at http://bit.ly/applied-text-analysis-with-python.
To comment or ask technical questions about this book, send email to bookquestions@oreilly.com.
For more information about our books, courses, conferences, and news, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
Acknowledgments
We would like to thank our technical reviewers for the time and commitment they spent on our first drafts and for the feedback they provided, which dramatically shaped the book. Dan Chudnov and Darren Cook provided excellent technical feedback that helped us stay on track, and Nicole Donnelly provided a perspective that allowed us to tailor our content to our readers. We would also like to thank Lev Konstantinovskiy and Kostas Xirogiannopoulos who provided academic feedback to ensure that our discussion was the state-of-the-art.
To our ever-smiling and unfailingly encouraging editor, Nicole Tache, we can’t say enough nice things. She shepherded this project from the very beginning and believed in us even as the finish line seemed to get further away. Her commitment to us and our writing process, her invaluable feedback and advice, and her timely suggestions are the reasons this book exists.
To our friends and families, we could not do our work without your support and encouragement. To our parents, Randy and Lily, Carla and Griff, and Tony and Teresa; you have instilled in us the creative minds, work ethic, technical ability, and love of learning that made this book possible. To our spouses, Jacquelyn, Jeff, and Nikki; your steadfast resolve even in the face of missed deadlines and late nights and weekends writing means the world to us. And finally, to our children, Irena, Henry, Oscar, and Baby Ojeda, we hope that you will someday find this book and think “Wow, our parents wrote books about when computers couldn’t talk like a normal person…how old are they?”
1 Fred Benenson, Emoji Dick, (2013) http://bit.ly/2GKft1n
2 Google, Google Books Ngram Viewer, (2013) http://bit.ly/2GNlKtk
Get Applied Text Analysis with Python now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

