Chapter 4. Oozie Workflow Actions
The previous chapter took us through the Oozie installation in detail. In this chapter, we will start looking at building full-fledged Oozie applications. The first step is to learn about Oozie workflows. Many users still use Oozie primarily as a workflow manager, and Oozieâs advanced features (e.g., the coordinator) are built on top of the workflow. This chapter will delve into how to define and deploy the individual action nodes that make up Oozie workflows. The individual action nodes are the heart and soul of a workflow because they do the actual processing and we will look at all the details around workflow actions in this chapter.
Workflow
As explained earlier in âA Recurrent Problemâ, most Hadoop projects start simple, but quickly become complex. Letâs look at how a Hadoop data pipeline typically evolves in an enterprise. The first step in many big data analytic platforms is usually data ingestion from some upstream data source into Hadoop. This could be a weblog collection system or some data store in the cloud (e.g., Amazon S3). Hadoop DistCp, for example, is a common tool used to pull data from S3. Once the data is available, the next step is to run a simple analytic query, perhaps in the form of a Hive query, to get answers to some business question. This system will grow over time with more queries and different kinds of jobs. At some point soon, there will be a need to make this a recurring pipeline, typically a daily pipeline. The first inclination of many users is to schedule this using a Unix cron job running a script to invoke the pipeline jobs in some sequence.
As new requirements and varied datasets start flowing into this Hadoop system, this processing pipeline quickly becomes unwieldy and complicated. It canât be managed in a cron job anymore. This is when people start exploring Oozie and they start by implementing an Oozie workflow.
âA Simple Oozie Jobâ showed a simple workflow
and âOozie Workflowsâ defined it as a collection of
action and control nodes arranged in a directed acyclic graph (DAG) that
captures control dependency where each action typically is a Hadoop job.
Workflows are defined in an XML file, typically named workflow.xml.
Each job, like the DistCp or the
subsequent Hive query in the previous example, ends up as an action node
in this workflow XML. They can be chained together using the workflow
definition language. If you want a recurring pipeline you can also make
this a daily coordinator job, but we wonât cover the coordinator until
later in the book (for more information, refer to 6). The first and the most important part of
writing such pipelines is to learn to write workflows and to learn how to
define and package the individual actions that make up these
workflows.
Actions
Action nodes define the jobs, which are the individual units of work that are chained together to make up the Oozie workflow. Actions do the actual processing in the workflow. An action node can run a variety of jobs: MapReduce, Pig, Hive, and more.
Actions in a workflow can either be Hadoop actions or general-purpose actions that allow execution of arbitrary code. Not all of the required processing fits into specific Hadoop action types, so the general-purpose action types come in handy for a lot of real-life use cases. We will cover them both in this chapter.
Action Execution Model
Before we get into the details of the Oozie actions, letâs look at how Oozie actually runs these actions. A clear understanding of Oozieâs execution model will help us to design, build, run, and troubleshoot workflows.
When a user runs a Hadoop job from the command line, the client
executable (e.g., Hadoop, Pig, or Hive) runs on the node where the
command is invoked. This node is usually called the
gateway, or an edge node
that sits outside the Hadoop cluster but can talk to the
cluster. Itâs the responsibility of the client program to run the
underlying MapReduce jobs on the Hadoop cluster and return the results.
The Hadoop environment and configuration on the edge node tell the
client programs how to reach the NameNode, JobTracker, and others. The
execution model is slightly different if you decide to run the same job
through an Oozie action.
Oozie runs the actual actions through a launcher job, which itself is a Hadoop MapReduce job that
runs on the Hadoop cluster. The launcher is a map-only job that runs
only one mapper. Letâs assume the Oozie job is launched by the oozie CLI. The
oozie CLI client will submit the job to the Oozie server, which may or may
not be on the same machine as the client. But the Oozie server does not
launch the Pig or Hive client locally on its machine. The server first
launches a job for the aforementioned launcher job on the Hadoop
cluster, which in turn invokes the appropriate client libraries (e.g.,
Hadoop, Pig, or Hive).
Users new to Oozie usually have questions about the need for a launcher job and wonder about the choice of this architecture. Letâs see how and why the launcher job helps. Delegating the client responsibilities to the launcher job makes sure that the execution of that code will not overload or overwhelm the Oozie server machine. A fundamental design principle in Oozie is that the Oozie server never runs user code other than the execution of the workflow itself. This ensures better service stability by isolating user code away from Oozieâs code. The Oozie server is also stateless and the launcher job makes it possible for it to stay that way. By leveraging Hadoop for running the launcher, handling job failures and recoverability becomes easier for the stateless Oozie server. Hadoop is built to handle all those issues, and itâs not smart to reinvent the wheel on the Oozie server.
This architecture also means that the action code and
configuration have to be packaged as a self-contained application and
must reside on HDFS for access across the cluster. This is because Hadoop
will schedule the launcher job on any cluster node. In most cases, the
launcher job waits for the actual Hadoop job running the action to
finish before exiting. This means that the launcher job actually
occupies a Hadoop task slot on the cluster for the entire duration of
the action. Figure 4-1 captures how Oozie
executes a Hive action in a workflow. The Hive action also redirects the
output to the Hive launcher jobâs stdout/stderr and the output is accessible
through the Oozie console. These patterns are consistent across most
asynchronous action types (covered in âSynchronous Versus Asynchronous Actionsâ), except the <map-reduce>
action. The <map-reduce>
launcher is the exception and it exits right after launching the actual
job instead of waiting for it to complete.
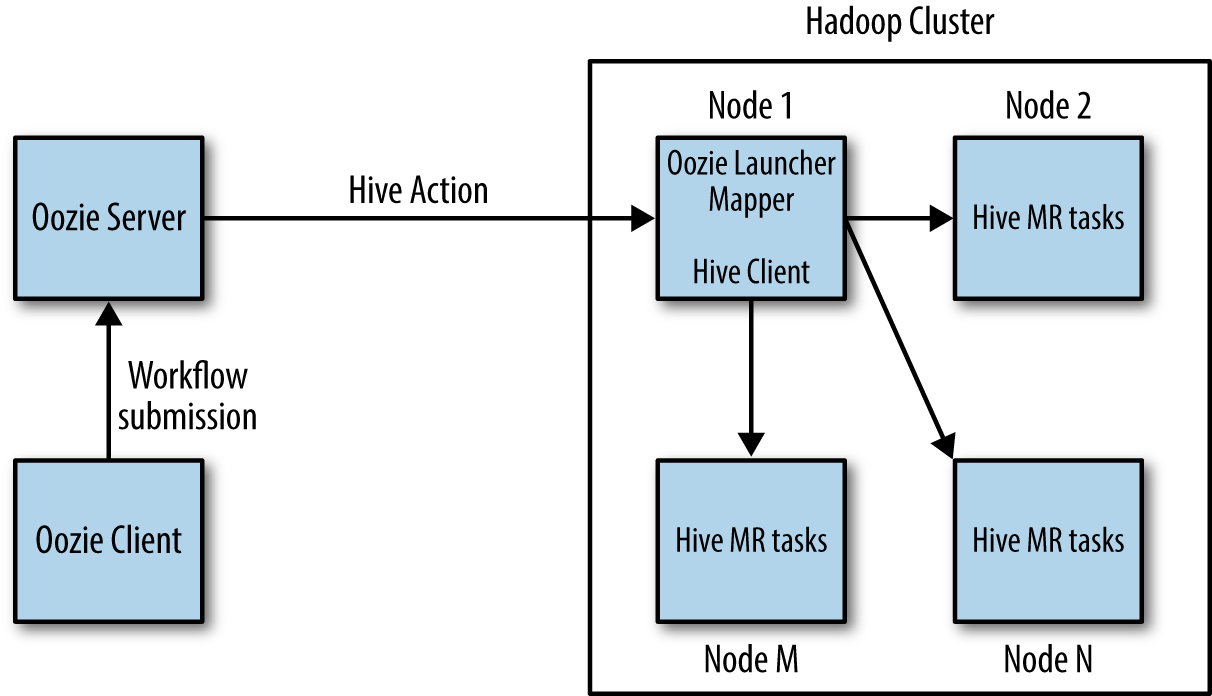
Figure 4-1. Action execution model
If many Oozie actions are submitted simultaneously on a small Hadoop cluster, all the task slots could be occupied by the launcher jobs. These launchers will then be waiting forever to run the actionâs Hadoop jobs that canât be scheduled due to unavailability of slots, causing a messy deadlock. This deadlock can be solved by configuring the launcher and the actual action to run on different Hadoop queues and by making sure the launcher queue cannot fill up the entire cluster. The topic of launcher configuration is covered in detail in âLauncher Configurationâ.
Action Definition
Oozieâs XML specification for each action is designed to define and deploy these jobs as self-contained applications. The key to mastering Oozie is to understand how to define, configure, and parameterize the individual actions in a workflow. In this section, we will cover all of the different action types and cover the details of their specification.
Actions are defined in the workflow XML using a set of elements
that are specific and relevant to that action type. Some of these
elements are common across many action types. For example, all Hadoop
actions need the <name-node> and <job-tracker> elements. But some of the
other XML elements are specific to particular actions. For example, the
Pig action needs a <script>
element, but the Java action does not. As a workflow system custom
built for Hadoop, Oozie makes it really easy and intuitive for users to
define all these actions meant for executing various Hadoop tools and
processing paradigms. Before looking at all the actions and their
associated elements, letâs look at an example action again in Example 4-1.
Example 4-1. Action node
<action name="identity-MR">
<map-reduce>
<job-tracker>localhost:8032</job-tracker>
<name-node>hdfs://localhost:8020</name-node>
<prepare>
<delete path="/user/joe/data/output"/>
</prepare>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.hadoop.mapred.lib.IdentityMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.hadoop.mapred.lib.IdentityReducer</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/joe/data/input</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/joe/data/input</value>
</property>
</configuration>
</map-reduce>
<ok to="success"/>
<error to="fail"/>
</action>All action nodes start with an <action>
element with a name attribute that
indicates the action name. Action nodes have three subelements:
the <
encapsulating the definition and all of the configuration for the
action, action-type><ok>, and
the <error> subelements that
indicate the transitions to follow depending on the exit status of the
action. We will now dig further into the various action types required
for building workflows.
Note
As explained in âApplication Deployment Modelâ,
the workflow.xml
file and all the required binaries, scripts, archives, files, and
configuration are packaged and deployed in an HDFS
directory. The workflow.xml file
is under the workflow application root directory on HDFS (oozie.wf.application.path).
Action Types
This section will cover all Oozie action types, but we will first look at a couple of
actions in great detail and the other action types will fall in place
rather easily after that. We will focus on the <map-reduce> Hadoop action and the general-purpose <java> action at first.
Tip
We encourage you to read through these two action types (<map-reduce> and <java>) closely even if they are not of
interest to you, as we will cover all of the common XML elements in the
context of these two actions. The usage and meaning of most elements
repeat across the other action types and can just be borrowed and
replicated. There is a lot of boilerplate XML content explained here
that wonât need further explanation in other action types.
MapReduce Action
We already saw a sample Oozie <map-reduce> action in Example 4-1. We will analyze it in more detail in this
section. This action type supports all three variations of a Hadoop
MapReduce job: Java, streaming, and pipes. The Java MapReduce job is the
most typical of the three and you can think of the other two as special
cases. Letâs look at the different XML elements needed to configure and
define a <map-reduce> action through Oozie. The following is an ordered
sequence of XML elements; you must specify them in order when writing
the action definition in your workflows (elements can be omitted, but if
present, they should be in sequence):
job-tracker(required)name-node(required)preparestreamingorpipesjob-xmlconfigurationfilearchive
Tip
The Oozie XML has a well-defined schema definition (XSD), as most XMLs do. These schema definitions are verbose and can be found in the Oozie documentation. One way to understand the action definition is to look at the schema definition. Itâs not always easy to read but can come in handy sometimes as the source of truth for the list of elements supported and their sequence.
The action needs to know the JobTracker (JT) and the NameNode (NN) of the underlying Hadoop cluster where Oozie has to run the
MapReduce job. The first two elements in the previous list are meant for
specifying them. These are required elements for this action:
...
<job-tracker>localhost:8032</job-tracker>
<name-node>hdfs://localhost:8020</name-node>
...Tip
As already explained in âA Simple Oozie Jobâ, the <job-tracker> element can refer to
either the JobTracker or the ResourceManager
based on the Hadoop version in use. Also, there are ways to globally
specify common elements like the JT and NN to be shared among multiple
actions in a workflow. We cover this in âGlobal Configurationâ.
Caution
You should not use the Hadoop configuration properties <mapred.job.tracker> (JobTracker)
and <fs.default.name> (NameNode)
as part of an Oozie workflow action definition. Oozie
will throw an error on those because it expects the <job-tracker> and <name-node> elements instead. This is
true for all Hadoop action types, including the <map-reduce> action.
The <prepare> section is
optional and is typically used as a preprocessor to delete
output directories or HCatalog
table partitions or to create some directories required for the
action. This delete helps make the action repeatable and enables retries
after failure. Without this cleanup, retries of Hadoop jobs will fail
because Hadoop checks for nonexistence of the output directories and tries to
create them for the job. So deleting them before running the action is a
common use case for this element. Using <prepare> to create directories is also
supported, but not as common as the delete
in usage:
...
<prepare>
<delete path="hdfs://localhost:8020/user/joe/output"/>
</prepare>
...The <job-xml> element(s)
and/or the <configuration> section can be used to capture all of the Hadoop job configuration
properties. The worker code for the MapReduce action is specified as
part of this configuration using the mapred.mapper.class
and the mapred.reducer.class
properties. These properties specify the actual Java classes to be run
as map and reduce as part of this action:
...
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.FirstJob.Map</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.myorg.FirstJob.Reduce</value>
</property>
</configuration>
...Tip
Hadoop supports two distinct API packages, commonly referred to as the mapred and mapreduce APIs. The old org.apache.hadoop.mapred package
and the newer org.apache.hadoop.mapreduce package
are functionally very similar, but the newer mapreduce API has cleaner abstractions and
is better organized though less mature and stable at this point. Refer
to the Hadoop documentation for more details. By default, Oozie
supports only the older mapred API.
There is a way to use the new API with Oozie (covered in âSupporting New API in MapReduce Actionâ).
When you write a Hadoop Java MapReduce
program, you need to write a main driver class that specifies the job
configuration, mapper class, reducer class, and so on. Oozie simplifies
things by handling this responsibility for you. You can just write the
mapper and reducer classes, package them as a JAR, and submit the JAR to
the Oozie action. Oozie takes care of the Hadoop driver code internally
and uses the older mapred API to do
so. However, you must be careful not to mix the new Hadoop APIs in their
mapper/reducer class with the old API in Oozieâs driver code. This is
one of the reasons why Oozie only supports the older mapred API out of the box. Refer to the Hadoop
examples to learn more about the MapReduce driver code.
Oozie also supports the <file> and <archive> elements for actions that need them. This is the native, Hadoop way
of packaging libraries, archives, scripts, and other data files that
jobs need, and Oozie provides the syntax to handle them. Refer to the
Hadoop
documentation for more information on files and archives. Users can specify symbolic links to
files and archives using the # symbol
in the workflow, as the following code fragment will show. The links themselves canât have slashes
(/) in them. Oozie creates these symlinks in the workflow root directory, and
other files in the application can refer to and access them using
relative paths.
Caution
Oozie does not support the libjars option available as part of the
Hadoop command line. But Oozie does provide several ways to handle
JARs and shared libraries, which are covered in âManaging Libraries in Oozieâ.
In the following example, the myFile.txt file referred to by the <file> element needs to be deployed in
the myDir1 subdirectory under the
wf/ root directory on HDFS. A
symlink named file1 will
be created in the workflow root directory. The archive file mytar.tgz also needs to be copied to the
workflow root directory on HDFS and Oozie will unarchive it into a
subdirectory called mygzdir/ in the current execution
directory on the Hadoop compute nodes. This is how Hadoop generally
distributes files and archives using the distributed cache. Archives
(TARs) are packaged and deployed, and the specified directory (mygzdir/) is the path where your MapReduce
code can find the files in the archive:
...
<file>hdfs://localhost:8020/user/myUser/wf/myDir1/myFile.txt#file1</file>
<archive>hdfs://localhost:8020/user/myUser/wf/mytar.tgz#mygzdir</archive>
...Now, putting all the pieces together, a sample <map-reduce> action
is shown here:
...
<action name="myMapReduceAction">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${myMapReduceActionOutput}"/>
</prepare>
<job-xml>/myfirstjob.xml</job-xml>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.FirstJob.Map</value>
</property>
<property>
<name>mapred.reducer.class</name
<value>org.myorg.FirstJob.Reduce</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${myMapReduceActionInput}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${myMapReduceActionOutput}</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>${JobNumReducers}</value>
</property>
</configuration>
<file>myDir1/myFile.txt#file1</file>
<archive>mytar.tgz#mygzdir</archive>
</map-reduce>
</action>
...Note
The preceding example uses typical conventions for variable substitution and parameterization (we will look at this in detail in âParameterizationâ). This example illustrates some of the best practices in writing an action definition.
Streaming and pipes are special kinds of MapReduce jobs, and this action supports both. They are both mechanisms that Hadoop supports to help run non-Java code as MapReduce jobs. This is to help users who might have to port existing code written in other languages like Python or C++ to Hadoopâs MapReduce framework in Java. Also, some users might just prefer other programming languages.
Depending on whether you want to execute streaming or pipes, you
can have either of those elements or neither. But you cannot specify
both <streaming> and <pipes> as part of a single <map-reduce>
action. Also, if they are present, they require some special subelements
specific to those execution modes.
Streaming
Streaming jobs support the following elements in addition to the
<map-reduce> elements we saw previously (these are subelements
under the <streaming> element):
mapperreducerrecord-readerrecord-reader-mappingenv
Streaming jobs run binaries or scripts and obviously need a
mapper and reducer executable. These are packaged through the <file> and <archive> elements as explained in the
previous section. If the <file> element is missing for a
streaming job, the executables are assumed to be available in the
specified path on the local Hadoop nodes. If itâs a relative path,
itâs assumed to be relative to the workflow root directory.
Caution
You might have noticed that the mapred.mapper.class and/or mapred.reducer.class properties can be
defined as part of the configuration section for the action as well.
If present, those will have higher priority over the <mapper> and <reducer> elements in the streaming section and will override the values
in the streaming section.
You can optionally give a <record-reader> and <record-reader-mapping> through those
elements to the streaming MapReduce job. Refer to the
Hadoop documentation for more information on those properties.
The <env> element comes in handy to set some environment variables
required by the scripts. Here is an example of a streaming
section:
...
<streaming>
<mapper>python MyCustomMapper.py</mapper>
<reducer>python MyCustomReducer.py</reducer>
<record-reader>StreamXmlRecordReader</record-reader>
<env>output_dir=/tmp/output</env>
</streaming>
...Pipes
While streaming is a generic framework to run any non-Java code in Hadoop, pipes are
a special way to run C++ programs more elegantly. Though not very
popular, Oozieâs <map-reduce> action does support a <pipes> section for defining pipes
jobs and it includes the following subelements:
mapreduceinputformatpartitionerwriterprogram
The <program> element
is the most important in the list and it points to the C++
executable to be run. This executable needs to be packaged with the
workflow application and deployed on HDFS. You can also optionally
specify the <map> class, <reduce> class, <inputformat>, <partitioner>, and <writer> elements. Refer to the Hadoop
documentation on pipes
for more details. Here is an example of a pipes section in the Oozie
action:
...
<pipes>
<program>hdfs://localhost:8020/user/myUser/wf/bin/
wordcount-simple#wordcount-simple</program>
</pipes>
...Note
As a general rule in Oozie, the exit status of the Hadoop MapReduce job and the job counters must be available to the workflow job after the Hadoop job completes. Without this, the workflow may not be able to decide on the next course of action. Oozie obviously needs to know if the job succeeded or failed, but it is also common for the workflow to make decisions based on the exit status and the counters.
MapReduce example
Now, letâs look at a specific example of how a Hadoop MapReduce job is run on the command line and convert it into an Oozie action definition. Youâre likely already familiar with running basic Hadoop jobs from the command line. Using that as a starting point and converting it to an action definition in Oozie will make it easier for you to become familiar with the workflow syntax. Hereâs an example:
$ hadoop jar /user/joe/myApp.jar myAppClass -Dmapred.job.reduce.memory.mb=8192 /hdfs/user/joe/input /hdfs/user/joe/output prod
The command just shown runs a Java MapReduce job to implement
some business logic. The myApp.jar file packages the code that runs
the mapper and the reducer class. The job requires 8 GB memory for its
reducers (and that is) defined in the command line above using the
-D option). The job also takes
three command-line arguments. The first one is the input directory on
HDFS (/hdfs/user/joe/input), the
second argument is the output directory (/hdfs/user/joe/output), and the last one is
the execution type (prod), which is some application-specific
argument. The arguments and the directory paths themselves are just
examples; it could be anything in reality.
In âAction Typesâ, we covered how a
typical Java MapReduce program has a main driver class that is not
needed in Oozie. You just need to specify the mapper and reducer class
in the action definition. But this also requires knowing the actual
mapper and reducer class in the JAR to be able to write the Oozie
<map-reduce> action. In the command line above,
myAppClass is the main driver class. This is part
of the main driver code for the preceding Hadoop example:
...
/**
* The main driver for the map/reduce program.
* Invoke this method to submit the map/reduce job.
*/
public static void main(String[] args) throws IOException {
JobConf conf = new JobConf(myAppClass.class);
conf.setJobName("myAppClass");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(MyMapClass.class);
conf.setReducerClass(MyRedClass.class);
...Given this, the command line for the preceding Hadoop job submission can be specified in an Oozie workflow action as shown here:
<map-reduce>
<job-tracker>jt.mycompany.com:8032</job-tracker>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<prepare>
<delete path="hdfs://nn.mycompany.com:8020/hdfs/user/joe/output"/>
</prepare>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>com.myBiz.mr.MyMapClass</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>com.myBiz.mr.MyRedClass</value>
</property>
<property>
<name>mapred.job.reduce.memory.mb</name>
<value>8192</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/hdfs/user/joe/input</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/hdfs/user/joe/output</value>
</property>
</configuration>
</map-reduce>
<ok to="success"/>
<error to="fail"/>
</action>You might notice that the preceding Oozie action definition does not have any reference to the main JAR (/user/joe/myApp.jar) that you saw in the Hadoop command line. This is because of the way Oozie workflows are packaged and deployed. Oozie knows where to look for and find this JAR. The JAR has to be copied to the lib/ subdirectory under the workflow application root directory on HDFS.
Due to the implicit handling of the main driver code in Oozie,
some users who are new to Hadoop are likely to be confused when they
try to switch between the Hadoop command line and the Oozie <map-reduce> action. This is a little
subtle and tricky, but the translation to an Oozie action is a lot
more straightforward with all the other action types that we cover
later in this chapter.
Tip
For the sake of clarity, the example discussed in this section specifically skips variable substitution and parameterization. It would be a good exercise for readers to parameterize this example using variables (âEL Variablesâ provides insight on how to do this).
Streaming example
Letâs look at a Python streaming job invoked using the Hadoop client:
$ hadoop jar /opt/hadoop/share/hadoop/tools/lib/hadoop-*streaming*.jar -file /home/joe/mapper.py -mapper /home/joe/mapper.py -file /home/joe/reducer.py -reducer /home/joe/reducer.py -input hdfs://nn.mycompany.com:8020/hdfs/user/joe/input/ -output hdfs://nn.mycompany.com:8020/hdfs/user/joe/output/
This command-line example runs a Python streaming job to implement a Hadoop MapReduce application. The Python script mapper.py is the code it runs for the mapper, and reducer.py is the Python script it runs for the reducer. The job reads its input from the /hdfs/user/joe/input/ directory on HDFS and writes the output to /hdfs/user/joe/output/. The previous example can be specified in Oozie as shown in Example 4-2.
Example 4-2. MapReduce streaming action
<action name="myStreamingMRAction">
<map-reduce>
<job-tracker>jt.mycompany.com:8032</job-tracker>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<prepare>
<delete path="hdfs://nn.mycompany.com:8020/hdfs/user/joe/output"/>
</prepare>
<streaming>
<mapper>python mapper.py</mapper>
<reducer>python reducer.py</reducer>
</streaming>
<configuration>
<property>
<name>mapred.input.dir</name>
<value>/hdfs/user/joe/input</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/hdfs/user/joe/output</value>
</property>
</configuration>
<file>wfDir/mapper.py#mapper.py</file>
<file>wfDir/redcer.py#reducer.py</file>
</map-reduce>
<ok to="success"/>
<error to="fail"/>
</action>Java Action
Oozieâs Java action is a great way to run custom Java code on the Hadoop cluster.
The Java action will execute the public static
void main(String[] args) method of the specified Java main class. It is technically considered a non-Hadoop action. This action
runs as a single mapper job, which means it will run on an arbitrary
Hadoop worker node.
While itâs not recommended, Java action can be used to run Hadoop
MapReduce jobs because MapReduce jobs are nothing but Java programs
after all. The main class invoked can be a Hadoop MapReduce driver and
can call Hadoop APIs to run a MapReduce job. In that mode, Hadoop spawns
more mappers and reducers as required and runs them on the cluster. The
reason this approach is not ideal is because Oozie does not know about
or manage the MapReduce job spawned by the Java action, whereas it does
manage the job run by the <map-reduce> action we saw in the
previous section. There are distinct advantages to being tightly
integrated as a <map-reduce> action in Oozie instead of being just another
Java program:
Because Oozie knows that the
<map-reduce>action runs a Hadoop job, it provides easy access to Hadoop counters for this job. We will learn more about these counters in âEL Variablesâ. Itâs a lot harder to save and access the counters of a Hadoop job if it is invoked as a<java>action.The launcher map task that launches the
<map-reduce>action completes immediately and Oozie directly manages the MapReduce job. This frees up a Hadoop slot for a MapReduce task that would have otherwise been occupied by the launcher task in the case of a<java>action.
Tip
We saw in âMapReduce Actionâ that Oozie
supports only the older, mapred
Java API of Hadoop. However, the Java class invoked via the <java> action could use the newer mapreduce API of Hadoop. This is not
recommended, but is still a potential workaround for people committed
to using the newer Hadoop API.
The Java action is made up of the following elements:
job-tracker(required)name-node(required)prepareconfigurationmain-class(required)java-optsargfilearchivecapture-output
We have seen the <job-tracker>, <name-node>, <prepare>, <configuration>, <file>, and <archive> elements in the context of a <map-reduce> action, which work exactly the
same with the <java> action or
any other action for that matter. Letâs look at the elements specific to
the <java> action.
The key driver for this action is the Java main class to be run
plus any arguments and/or JVM options it requires. This is captured
in the <main-class>, <arg>, and <java-opts> elements, respectively. Each <arg> element corresponds to one
argument and will be passed in the same order, as specified in the
workflow XML to the main class by Oozie.
The <capture-output>
element, if present, can be used to pass the output back to the
Oozie context. The Java program has to write the output in Java
properties file format and the default maximum size allowed is 2 KB.
Instead of stdout, the Java program should write to a file path defined
by the system and accessible via the system property oozie.action.output.properties. Other
actions in the workflow can then access this data through
the EL function wf:actionData(String
java-node-name), which returns a map (EL functions are covered in âEL Functionsâ). The following piece of code in the Java
action generates some output shareable with Oozie:
{
File outputFile = new File(System.getProperty(
"oozie.action.output.properties"));
Properties outputProp = new Properties();
outputProp.setProperty("OUTPUT_1", "007");
OutputStream oStream = new FileOutputStream(outputFile);
outputProp.store(oStream, "");
oStream.close();
System.out.println(outputFile.getAbsolutePath());
}Tip
The oozie.action.max.output.data property
defined in oozie-site.xml
on the Oozie server node controls the maximum size of the output data.
It is set to 2,048 by default, but users can modify it to suit their
needs. This change will require a restart of the Oozie server
process.
The Java main class has to exit gracefully to help the Oozie
workflow successfully transition to the next action, or throw an
exception to indicate failure and enable the error transition. The Java
main class must not call System.exit(int
n), not even exit(0). This
is because of Oozieâs execution model and the launcher mapper process.
It is this mapper that invokes the Java main class to run the Java
action. An exit() call will force the
launcher mapper process to quit prematurely and Oozie will consider that
a failed action.
The Java action also builds a file named oozie-action.conf.xml and puts it in the running directory of the Java class for it to access. Here is an example of a Java action:
...
<action>
<java>
<job-tracker>localhost:8032</job-tracker>
<name-node>hdfs://localhost:8020</name-node>
<prepare>
<delete path="${myJavaActionOutput}"/>
</prepare>
<configuration>
<property>
<name>mapred.queue.name</name>
<value>default</value>
</property>
</configuration>
<main-class>org.apache.oozie.MyJavaMainClass</main-class>
<java-opts>-DmyOpts</java-opts>
<arg>argument1</arg>
<arg>argument2</arg>
<capture-output/>
</java>
</action>
...Tip
You will see that a lot of the XML elements become repetitive
across actions now that we have seen the <map-reduce> and <java> action. Settings like <name-node>, <job-tracker>, and <queue> are required by most actions and are typically the same
across a workflow or even many workflows. You can just cut and paste
them across actions or centralize them using some approaches that we
will see in the next chapter.
Java example
Letâs look at an example of how a Hadoop job is converted into a custom Oozie Java action. The
example below is the same MapReduce job that we saw in âMapReduce exampleâ, but we will convert it into a <java> action here instead of the
<map-reduce> action:
$ hadoop jar /user/joe/myApp.jar myAppClass -Dmapred.job.reduce.memory.mb=8192 /hdfs/user/joe/input /hdfs/user/joe/output prod
The complete Java action definition is shown here:
<action name="myJavaAction">
<java>
<job-tracker>jt.mycompany.com:8032</job-tracker>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<prepare>
<delete path="hdfs://nn.mycompany.com:8020/hdfs/user/joe/output"/>
</prepare>
<main-class>myAppClass</main-class>
<arg>-D</arg>
<arg>mapreduce.reduce.memory.mb=8192</arg>
<arg>hdfs://nn.mycompany.com:8020/hdfs/user/joe/input</arg>
<arg>hdfs://nn.mycompany.com:8020/hdfs/user/joe/output</arg>
<arg>prod</arg>
<file>myApp.jar#myApp.jar</file>
<capture-output/>
</java>
<ok to="success"/>
<error to="fail"/>
</action>Tip
Itâs customary and useful to set oozie.use.system.libpath=true in the job.properties file for a lot of the actions to find the required jars and work seamlessly. We cover library management in detail in âManaging Libraries in Oozieâ.
Pig Action
Oozieâs Pig action runs a Pig job in Hadoop. Pig is a popular tool to run Hadoop jobs via a procedural language interface called Pig Latin. The Pig framework translates the Pig scripts into MapReduce jobs for Hadoop (refer to the Apache Pig documentation for more details). Pig action requires you to bundle the Pig script with all the necessary parameters. Hereâs the full list of XML elements:
scrjob-tracker(required)name-node(required)preparejob-xmlconfigurationscript(required)paramargumentfilearchive
The following is an example of a Pig action with the Pig script,
parameters, and arguments. We will look at Oozieâs variable substitution in detail in âParameterizationâ, but the script can be parameterized
in Pig itself because Pig supports variable substitution as well. The
values for these variables can be defined as <argument> in the action. Oozie does its
parameterization before submitting the script to Pig, and this is
different from the parameterization support inside Pig. Itâs important
to understand the two levels of parameterization. Letâs look at an
example:
...
<action name=" myPigAction">
<pig>
...
<script>/mypigscript.pig</script>
<argument>-param</argument>
<argument>TempDir=${tempJobDir}</argument>
<argument>-param</argument>
<argument>INPUT=${inputDir}</argument>
<argument>-param</argument>
<argument>OUTPUT=${outputDir}/my-pig-output</argument>
</pig>
</action>
...Oozie will replace ${tempJobDir}, ${inputDir}, and ${outputDir} before submission to Pig. And
then Pig will do its variable substitution for TempDir, INPUT, and OUTPUT which will be referred inside the Pig
script as $TempDir, $INPUT, and $OUTPUT respectively (refer to the parameterization
section in the Apache Pig documentation for more
details).
Note
The argument in the example above, -param INPUT=${inputDir}, tells Pig to
replace $INPUT in the Pig script
and could have also been expressed as <param>INPUT=${inputDir}</param>
in the action. Oozieâs Pig action supports a <param> element, but itâs an older
style of writing Pig actions and is not recommended in newer versions,
though it is still supported.
Pig example
Letâs look at a specific example of how a real-life Pig job is run on the command line and convert it into an Oozie action definition. Hereâs an example of a simple Pig script:
REGISTER myudfs.jar;
data = LOAD '/user/joe/pig/input/data.txt' USING PigStorage(',') AS
(user, age, salary);
filtered_data = FILTER data BY age > $age;
ordered_data = ORDER filtered_data BY salary;
final_data = FOREACH ordered_data GENERATE (user, age,
myudfs.multiply_salary(salary));
STORE final_data INTO '$output' USING PigStorage();It is common for Pig scripts to use user-defined functions (UDFs) through custom JARs. In
the preceding example, there is a Java UDF JAR file (myudfs.jar) on the local filesystem. The
JAR is first registered using the REGISTER
statement in Pig before using the UDF multiply_salary() (refer to the Pig documentation
on how to write, build, and package the UDFs; we will only
cover how to use it via Oozie here).
This Pig script is also parameterized using variablesâ$age and $ouput. This is typically run in Pig using
the following command (this invocation substitutes these two variables
using the -param option to
Pig):
$ pig -Dmapreduce.job.queuename=research -f pig.script -param age=30 -param output=hdfs://nn.mycompany.com:8020/hdfs/user/joe/pig/output
We will now see an example Oozie Pig action to run this Pig
script. The easiest way to use the UDF in Oozie is to copy the
myudfs.jar file to the lib/ subdirectory under the workflow root
directory on HDFS. You can then remove the REGISTER statement in the Pig script before
copying it to HDFS for the Oozie action to run it. Oozie will
automatically add the JAR to the classpath and the Pig action will
have no problem finding the JAR or the UDF even without the REGISTER
statement:
<action name="myPigAction">
<pig>
<job-tracker>jt.mycompany.com:8032</job-tracker>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<prepare>
<delete path="hdfs://nn.mycompany.com:8020/hdfs/user/
joe/pig/output"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>research</value>
</property>
</configuration>
<script>pig.script</script>
<argument>-param</argument>
<argument>age=30</argument>
<argument>-param</argument>
<argument>output=hdfs://nn.mycompany.com:8020/hdfs/user/
joe/pig/output</argument>
</pig>
<ok to="end"/>
<error to="fail"/>
</action>Tip
There are multiple ways to use UDFs and custom JARs in Pig
through Oozie. The UDF code can be distributed via the <archive> and <file> elements, as always, but
copying it to the lib/
subdirectory is the easiest and most straightforward
approach.
FS Action
Users can run HDFS commands using Oozieâs FS action. Not all HDFS commands
are supported, but the following common operations are allowed: delete, mkdir, move, chmod, <touchz>, chgrp. The elements that make up the FS action are as follows:
name-node(required)job-xmlconfigurationdeletemkdirmovechmodtouchzchgrp
Tip
FS action commands are launched by Oozie on its server instead
of the launcher. This is something to keep in mind, because a
long-running, resource-intensive FS action can affect the performance
of the Oozie server and impact other Oozie applications. This is also
the reason why not all HDFS commands (e.g., copy) are supported through this
action.
Hereâs an example of an FS action in a real workflow:
...
<action name="myFSAction">
<fs>
<delete path='hdfs://foo:8020/usr/joe/temp-data'/>
<mkdir path='myDir/${wf:id()}'/>
<move source='${jobInput}' target='myDir/${wf:id()}/input'/>
<chmod path='${jobOutput}' permissions='-rwxrw-rw-'
dir-files='true'/>
</fs>
</action>
...Depending on the operation, Oozie will check to make sure source directories exist and target directories donât to reduce the chance of failure of the HDFS commands. To be more specific, Oozie checks for the following:
The nonexistence of the target file path for the
<move>(existence of a directory path is fine).
Both move and chmod use the same conventions as typical Unix
operations. For move, the existence
of the target path is fine if itâs a directory because the move will drop the source files or the source
directory underneath this target directory. However, the target canât be
a path of an existing file. The parent of the target path must exist.
The target for the move can also skip
the filesystem URI (e.g., hdfs://{nameNode}) because the source and the
target Hadoop cluster must be the same.
Permissions for chmod are
specified using the Unix symbolic representation (e.g., -rwxrw-rw-) or an octal representation (755). When doing a chmod command on a directory, by default the
command is applied to the directory and the files one level within the
directory. To apply the chmod command
to the directory, without affecting the files within it, the dir-files attribute must be set to false. You can also optionally add a <recursive>
element to chmod to change the
permissions recursively in the given directory.
Filesystem example
This is the easiest example to illustrate among all the Oozie actions. Imagine that we
want to do the following three simple filesystem tasks on HDFS:
delete, mkdir, and chmod. Letâs first see the command-line way
of doing this (the example uses both the hadoop and hdfs CLI tools, but they support the same
functionality and are equivalent; the hdfs CLI is the
recommended tool moving forward):
$ hadoop fs -rm -r /hdfs/user/joe/logs $ hdfs dfs -mkdir /hdfs/user/joe/logs $ hdfs dfs -chmod -R 755 /hdfs/user/joe/
This can be implemented using an Oozie FS action as shown here:
<action name="myFSAction">
<fs>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<delete path='/hdfs/user/joe/logs'/>
<mkdir path='/hdfs/user/joe/logs'/>
<chmod path='/hdfs/user/joe/' permissions='755' dir-files='true'>
<recursive/></chmod>
</fs>
<ok to="success"/>
<error to="fail"/>
</action>Caution
The entire action is not atomic. This means that if the
<chmod> command fails in
this example, the action does not rollback the <delete> and <mkdir> commands that happened just
prior to that. So itâs important to handle the cleanup and reset if
you want to rerun the action in its entirety.
Sub-Workflow Action
The sub-workflow action runs a child workflow as part of the parent workflow. You can think of it as an embedded workflow. From a parentâs perspective, this is a single action and it will proceed to the next action in its workflow if and only if the sub-workflow is done in its entirety. The child and the parent have to run in the same Oozie system and the child workflow application has to be deployed in that Oozie system:
app-path(required)propagate-configurationconfiguration
The properties for the sub-workflow are defined in the <configuration> section. The <propagate_configuration> element can also be optionally used to tell Oozie to pass the parentâs job configuration to the sub-workflow. Note that this is to propagate the job configuration (job.properties file). The following is an example of a simple but complete <sub-workflow> action:
<action name="mySubWorkflow">
<sub-workflow>
<app-path>hdfs://nn.mycompany.com:8020/hdfs/user/joe/
sub_workflow</app-path>
<propagate-configuration/>
</sub-workflow>
<ok to="success"/>
<error to="fail"/>
</action>Hive Action
Hive actions run a Hive query on the cluster and are not very different from the Pig actions as far as Oozie is concerned. Hive is a SQL-like interface for Hadoop and is probably the most popular tool to interact with the data on Hadoop today (refer to the Apache Hive documentation for more information). The Hive query and the required configuration, libraries, and code for user-defined functions have to be packaged as part of the workflow bundle and deployed to HDFS:
job-tracker(required)name-node(required)preparejob-xmlconfigurationscript(required)paramargumentfilearchive
Hive requires certain key configuration properties, like the
location of its metastore (hive.metastore.uris), which are typically part of the hive-site.xml. These properties have to be
passed in as configuration to Oozieâs Hive action.
Tip
One common shortcut people take for Hive actions is to pass in a
copy of the hive-site.xml from
the Hive client node (edge node) as the <job-xml> element. This way, the
hive-site.xml is just reused in
its entirety and no additional configuration settings or special files
are necessary. This is an overkill and considered a little lazy, but
it works most of the time.
Be careful with any directory and file path settings copied or borrowed from the hive-site.xml file, because the directory layout on the edge node and the Hadoop worker nodes may not be the same and you might hit some filesystem and permission errors.
The script element points to the actual Hive script to be run with the <param>
elements used to pass the parameters to the script. Hive supports
variable substitution similar to Pig, as explained in âPig Actionâ. The same rules from the Pig action apply
here as far as using the <argument>
element instead of the old-style <param> element and also understanding
the two levels of parameterization with Oozie and Hive. Hereâs a simple
example:
...
<action name=" myHiveAction ">
<hive>
...
<script>myscript.sql</script>
<argument>-hivevar</argument>
<argument>InputDir=/home/joe/input-data</argument>
<argument>-hivevar</argument>
<argument>OutputDir=${jobOutput}</argument>
</hive>
</action>
...Hive example
Letâs look at an example of how a real-life Hive job is run on
the command line. The following is a simple Hive query saved in a file
called hive.hql. This query also
uses a UDF from the JAR file /tmp/HiveSwarm-1.0-SNAPSHOT.jar on the
local filesystem. The Hive statement ADD JAR is
invoked before using the UDF dayofweek() (refer to the Hive
documentation for information on Hive UDFs; we will just see
how to run it in Oozie here):
ADD JAR /tmp/HiveSwarm-1.0-SNAPSHOT.jar;
create temporary function dayofweek as 'com.livingsocial.hive.udf.DayOfWeek';
select *, dayofweek(to_date('2014-05-02')) from test_table
where age>${age} order by name;This Hive query is also parameterized using the variable
$age. This is typically run in Hive
using the following command line (this invocation substitutes the
variable using the -hivevar
option):
$ hive -hivevar age=30 -f hive.hql
We will now see a Hive action to operationalize this example in
Oozie. As with Pig UDFs, copy the JAR file (HiveSwarm-1.0-SNAPSHOT.jar) to the
lib/ subdirectory under the
workflow root directory on HDFS. You can then remove the ADD JAR statement in the Hive query before
copying it to HDFS for the Oozie action to run it. Oozie will
automatically add the JAR to the classpath and the Hive action will
have no problem finding the JAR or the UDF even without the ADD JAR statement. Alternatively, the UDF
code can be distributed via the <archive> and <file> elements as well, but that will
involve more work:
<action name="myHiveAction">
<hive xmlns="uri:oozie:hive-action:0.5">
<job-tracker>jt.mycompany.com:8032</job-tracker>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<job-xml>hive-config.xml</job-xml>
<script>hive.hql</script>
<argument>-hivevar</argument>
<argument>age=30</argument>
</hive>
<ok to="success"/>
<error to="fail"/>
</action>The hive-config.xml file in the example needs to be on HDFS in the workflow root directory along with the Oozie workflow XML and the hive.hql file. The config file can be a simple copy of the entire hive-site.xml or a file with a subset of the Hive configuration handcrafted for the specific query.
Caution
In older versions of Oozie and Hive, we could use the oozie.hive.defaults configuration
property to pass in the default settings for Hive.
This setting no longer works with newer versions of Oozie (as of
Oozie 3.4) and will be ignored even if present in the workflow XML
file. You should use the <job-xml> element instead to pass
the settings.
DistCp Action
DistCp action supports the Hadoop distributed copy tool, which is typically used to copy data across Hadoop clusters. Users can use it to copy data within the same cluster as well, and to move data between Amazon S3 and Hadoop clusters (refer to the Hadoop DistCp documentation for more details).
Here are the elements required to define this action:
job-tracker(required)name-node(required)prepareconfigurationjava-optsarg
Here is an example of a DistCp action:
<action name=" myDistCpAction ">
<distcp>
...
<arg> hdfs://localhost:8020/path/to/input.txt</arg>
<arg>${nameNode2}/path/to/output.txt</arg>
</distcp>
</action>The first argument passed in via the <arg> element points to the URI for the full path for the source data
and the second <arg> corresponds to the
full path URI for the target for the distributed copy. Do note the
different NameNodes.
Tip
The following configuration property is required if the DistCp is copying data between two secure Hadoop clusters:
oozie.launcher.mapreduce.job.hdfs-servers
The DistCp action might not work very well if the two clusters are running different Hadoop versions or if they are running secure and nonsecure Hadoop. There are ways to make it work by using the WebHDFS protocol and setting some special configuration settings for Hadoop. Those details about DistCp are beyond the scope of this book, but itâs fairly straightforward to implement them in Oozie if you want to research and incorporate those tricks and tips.
DistCp Example
Letâs look at a specific example of how a real-life DistCp job is run on the command line and convert it into an Oozie action definition. The following is an example of a typical DistCp command:
$ /opt/hadoop/bin/hadoop distcp -m 100 s3n://my-logfiles/2014-04-15/* /hdfs/user/joe/logs/2014-04-15/
This example copies data from an Amazon S3 bucket to the local
Hadoop cluster, which is a common usage pattern. Copying from one
Hadoop cluster to another follows the same concepts. This DistCp is
configured to run 100 mappers through the -m=100 option.
Letâs convert this command line example to an Oozie action:
<action name="myDistcpAction">
<distcp xmlns="uri:oozie:distcp-action:0.1">
<job-tracker>jt.mycompany.com:8032</job-tracker>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<prepare>
<delete path="hdfs://nn.mycompany.com:8020/hdfs/user/joe/
logs/2014-04-15/"/>
</prepare>
<arg>-Dfs.s3n.awsAccessKeyId=XXXX</arg>
<arg>-Dfs.s3n.awsSecretAccessKey=YYYY</arg>
<arg>-m</arg>
<arg>100</arg>
<arg>s3n://my-logfiles/2014-04-15/*</arg>
<arg>/hdfs/user/joe/logs/2014-04-15/</arg>
</distcp>
<ok to="success"/>
<error to="fail"/>
</action>As you can see, the <distcp> action definition in Oozie
has the Amazon (AWS) access key and secret key, while the command-line
example does not. This is because the AWS keys are typically saved as
part of the Hadoop core-site.xml
configuration file on the edge node where the DistCp command line is invoked. But they
need to be defined explicitly in the Oozie action either through the
-D option, the <job-xml> file, or the configuration
section because those keys need to be propagated to the launcher job
running on one of the nodes, which may or may not have the same Hadoop
configuration files as the edge node.
Tip
The DistCp command-line
example shown here assumes the keys are in the Hadoop core-site.xml file. Also, the keys in the
Oozie example are obviously fake. There is another way to pass in the
AWS keys by embedding them in the s3n URI itself using the syntax
s3n://ID:SECRET@BUCKET (refer to
the Hadoop
documentation for more details; Oozie supports this syntax
as well).
Email Action
Sometimes there is a need to send emails from a workflow
application. It might be to notify users about the state of the workflow
or error messages or whatever the business need dictates. Oozieâs email
action provides an easy way to integrate this feature into the workflow.
It takes the usual email parameters: to, cc,
subject, and body. Email IDs of multiple recipients can be
comma separated.
The following elements are part of this action:
to(required)ccsubject(required)body(required)
This is one of the few actions that runs on the Oozie server and not through an Oozie launcher on one of the Hadoop nodes. The assumption here is that the Oozie server node has the necessary SMTP email client installed and configured, and can send emails. In addition, the following SMTP server configuration has to be defined in the oozie-site.xml file for this action to work:
Here is an example of an email action:
...
<action name="myEmailAction">
<email xmlns="uri:oozie:email-action:0.2">
<to>joe@initech.com,the_other_joe@initech.com</to>
<cc>john@initech.com</cc>
<subject>Email notifications for ${wf:id()}</subject>
<body>The wf ${wf:id()} successfully completed.</body>
</email>
</action>
...Shell Action
Oozie provides a convenient way to run any shell
command. This could be Unix commands, Perl/Python scripts, or even Java
programs invoked through the Unix shell. The shell command runs on an arbitrary Hadoop
cluster node and the commands being run have to be available locally on
that node. Itâs important to keep the following limitations and
characteristics in mind while using the <shell> action:
Interactive commands are not allowed.
You canât run
sudoor run as another user.Because the shell command runs on any Hadoop node, you need to be aware of the path of the binary on these nodes. The executable has to be either available on the node or copied by the action via the distributed cache using the
<file>tag. For the binaries on the node that are not copied via the cache, itâs perhaps safer and easier to debug if you always use an absolute path.Itâs not unusual for different nodes in a Hadoop cluster to be running different versions of certain tools or even the operating system. So be aware that the tools on these nodes could have slightly different options, interfaces, and behaviors. While built-in shell commands like
grepandlswill probably work fine in most cases, other binaries could either be missing, be at different locations, or have slightly different behaviors depending on which node they run on.On a nonsecure Hadoop cluster, the shell command will execute as the Unix user who runs the TaskTracker (Hadoop 1) or the YARN container (Hadoop 2). This is typically a system-defined user. On secure Hadoop clusters running Kerberos, the shell commands will run as the Unix user who submitted the workflow containing the
<shell>action.
The elements that make up this action are as follows:
job-tracker(required)name-node(required)preparejob-xmlconfigurationexec(required)argumentenv-varfilearchivecapture-output
The <exec> element
has the actual shell
command with the arguments passed in through the <argument>
elements. If the excutable is a script instead of a standard Unix
command, the script needs to be copied to the workflow root directory on
HDFS and defined via the <file>
element as always. The <shell> action
also includes an <env-var>
element that contains the Unix environment variable, and itâs defined using the standard
Unix syntax (e.g., PATH=$PATH:my_path).
Caution
Be careful not to use the ${VARIABLE} syntax for the environment
variables, as those variables will be replaced by Oozie.
This action also adds a special environment variable called
OOZIE_ACTION_CONF_XML, which has the
path to the Hadoop configuration file that Oozie creates and drops in
the <shell> actionâs running directory.
This environment variable can be used in the script to access the
configuration file if needed.
Just like Java action, if the <capture_output> element is present
here, Oozie will capture the output of the shell command and make it available to the
workflow application. This can then be accessed by the workflow
through the action:output() EL function. The one
difference between the <java>
action and <shell> action is
that Oozie captures the stdout of the <shell> action whereas with the
Java action, the program has to write the output to a file
(oozie.action.output.properties).
Here is a typical <shell> action:
...
<action name=" myShellAction ">
<shell>
...
<exec>${EXEC}</exec>
<argument>A</argument>
<argument>B</argument>
<file>${EXEC}#${EXEC}</file>
</shell>
</action>
...Note
While Oozie does run the shell command on a Hadoop node, it runs it via the launcher job. It does not invoke another MapReduce job to accomplish this task.
Shell example
Letâs say there is a Python script that takes todayâs date as
one of the arguments and does some basic processing. Letâs assume it
also requires an environment variable named TZ to set the time zone. This is how you
will run it on the shell command
line:
$ export TZ=PST $ python test.py 07/21/2014
Letâs convert this example to an Oozie <shell>
action:
<action name="myShellAction">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>jt.mycompany.com:8032</job-tracker>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<exec>/usr/bin/python</exec>
<argument>test.py</argument>
<argument>07/21/2014</argument>
<env-var>TZ=PST</env-var>
<file>test.py#test.py</file>
<capture-output/>
</shell>
<ok to="success"/>
<error to="fail"/>
</action>Note
Users often use the Python Virtual Environment and distribute it via the Hadoop distributed cache using the <archive> element. This is a nice and self-contained approach to isolate your Python environment from whatâs available on the node and also to make sure you have access to all the packages your job needs.
SSH Action
The <ssh> action
runs a shell command on
a specific remote host using a secure shell. The
command should be available in the path on the remote machine and it is executed in the userâs home directory on the remote machine. The
shell command can be run as another
user on the remote host from the one running the workflow. We can do
this using typical ssh syntax:
user@host. However, the oozie.action.ssh.allow.user.at.host should be
set to true in oozie-site.xml for
this to be enabled. By default, this variable is false. Here are the elements of an <ssh> action:
host(required)command(required)argsargcapture-output
The <command> element
has the actual command to be run on the remote host and
the <args> element has the
arguments for the command. Either <arg> or
<args> can be used in the
action, but not both. The difference between the two is as follows. If
there is a space in the <args>,
it will be handled as separate arguments, while <arg> will handle each value as one
argument. The <arg> element was
basically introduced to handle arguments with white spaces in them. Here
is an example <ssh> action:
...
<action name="mySSHAction">
<ssh xmlns="uri:oozie:ssh-action:0.2">
<host>foo@bar.com</host>
<command>uploaddata</command>
<args>jdbc:derby://bar.com:1527/myDB</args>
<args>hdfs://foobar.com:8020/usr/joe/myData</args>
</ssh>
</action>
...Note
Itâs important to understand the difference between the <ssh> action and the <shell> action. The <shell> action can be used to run
shell commands or some custom
scripts on one of the Hadoop nodes. The <ssh> action can be used to run
similar commands, but itâs meant to be run on some remote node thatâs
not part of the Hadoop cluster. Also, the <shell> action runs through an Oozie
launcher while the <ssh>
action is initiated from the Oozie server.
Sqoop Action
Apache Sqoop is a Hadoop tool used for importing and exporting data between relational
databases (MySQL, Oracle, etc.) and Hadoop clusters. Sqoop commands are
structured around connecting to and importing or exporting data from
various relational databases. It often uses JDBC to talk to these
external database systems (refer to the documentation on Apache
Sqoop for more details). Oozieâs sqoop action helps users run Sqoop jobs as
part of the workflow.
The following elements are part of the Sqoop action:
job-tracker(required)name-node(required)preparejob-xmlconfigurationcommand(required ifargis not used)arg(required ifcommandis not used)filearchive
The arguments to Sqoop are sent either through the <command> element in one line or broken
down into many <arg> elements.
The following example shows a typical usage:
...
<action name=" mySqoopAction ">
<sqoop>
...
<command>import --connect jdbc:hsqldb:file:db.hsqldb --table
test_table--target-dir hdfs://localhost:8020/user/joe/sqoop_tbl
-m 1</command>
</sqoop>
</action>
...Sqoop example
Letâs look at an example of an import from a MySQL database into HDFS using the Sqoop command line. We are using Sqoop version 1.4.5 here. Also known as Sqoop 1, it is a lot more popular than the newer Sqoop 2 at this time. The command shown here is connecting to a MySQL database called MY_DB and importing all the data from the table test_table. The output is written to the HDFS directory /hdfs/joe/sqoop/output-data and this Sqoop job runs just one mapper on the Hadoop cluster to accomplish this import. Hereâs the actual command line:
$ /opt/sqoop-1.4.5/bin/sqoop import --connect jdbc:mysql://mysqlhost.mycompany .com/MY_DB --table test_table -username mytestsqoop -password password --target-dir /hdfs/joe/sqoop/output-data -m 1
Example 4-3 converts this command line to an Oozie sqoop
action:
Example 4-3. Sqoop import
<action name="sqoop-import">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>jt.mycompany.com:8032</job-tracker>
<name-node>hdfs://nn.mycompany.com:8020</name-node>
<prepare>
<delete path=" hdfs://nn.mycompany.com:8020/hdfs/joe/sqoop/
output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>default</value>
</property>
</configuration>
<command>import --connect jdbc:mysql://mysqlhost.mycompany.com/MY_DB
--table test_table -username mytestsqoop -password password
--target-dir /user/alti-test-01/ara/output-data/sqoop -m 1</command>
</sqoop>
<ok to="end"/>
<error to="fail"/>
</action>
Caution
The Sqoop eval option runs any random and valid SQL statement on the target (relational) DB and returns the results. This command does not run a MapReduce job on the Hadoop side and this caused some issues for Oozie. The eval option via the Oozie <sqoop> action used to fail. This bug has been fixed in Oozie version 4.1.0 and it now supports the eval option as well.
Letâs see another example using the <arg> element instead of the <command> element in the <sqoop> action. Example 4-4 shows how to run a Sqoop eval in Oozie 4.1.0:
Example 4-4. Sqoop eval
<action name="ara_sqoop_eval">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>jt.mycompany.com:8032$lt;/job-tracker>
<name-node>hdfs://nn.mycompany.com:8020$lt;/name-node>
<arg>eval</arg>
<arg>--connect</arg>
<arg>jdbc:mysql://mysqlhost.mycompany.com/MY_DB</arg>
<arg>--username</arg>
<arg>mytestsqoop</arg>
<arg>--password</arg>
<arg>password</arg>
<arg>-e</arg>
<arg>SELECT count(*) FROM test_table</arg>
</sqoop>
<ok to="end"/>
<error to="fail"/>
</action>
Tip
The example shows the username and password in clear text just for convenience. This is not the recommended way to pass them via Oozie. These values are usually parameterized using variables and saved in a secure fashion.
Synchronous Versus Asynchronous Actions
All Hadoop actions and the <shell>
action follow the âAction Execution Modelâ. These are called
asynchronous actions because they are launched via a
launcher as Hadoop jobs. But the filesystem action, email action, SSH
action, and sub-workflow action are executed by the Oozie server itself
and are called synchronous actions. The execution of these synchronous
actions do not require running any user codeâjust access to some
libraries.
Note
As seen earlier, the Oozie filesystem action performs lightweight filesystem operations not involving data transfers and is executed by the Oozie server itself. The email action sends emails; this is done directly by the Oozie server via an SMTP server. The sub-workflow action is executed by the Oozie server also, but it just submits a new workflow. The SSH action makes Oozie invoke a secure shell on a remote machine, though the actual shell command itself does not run on the Oozie server. These actions are all relatively lightweight and hence safe to be run synchronously on the Oozie server machine itself.
Table 4-1 captures the execution modes for the different action types.
| Action | Type |
|---|---|
| MapReduce | Asynchronous |
| Java | Asynchronous |
| Pig | Asynchronous |
| Filesystem | Synchronous |
| Sub-Workflow | Synchronous |
| Hive | Asynchronous |
| DistCp | Asynchronous |
| Synchronous | |
| Shell | Asynchronous |
| SSH | Synchronous |
| Sqoop | Asynchronous |
This wraps up the explanation of all action types that Oozie supports out of the box. In this chapter, we learned about all the details and intricacies of writing and packaging the different kinds of action types that can be used in a workflow. We will cover parameterization and other advanced workflow topics in detail in Chapter 5.
Get Apache Oozie now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

