Chapter 1. Introduction to Oozie
In this chapter, we cover some of the background and motivations that led to the creation of Oozie, explaining the challenges developers faced as they started building complex applications running on Hadoop.1 We also introduce you to a simple Oozie application. The chapter wraps up by covering the different Oozie releases, their main features, their timeline, compatibility considerations, and some interesting statistics from large Oozie deployments.
Big Data Processing
Within a very short period of time, Apache Hadoop, an open source implementation of Googleâs MapReduce paper and Google File System, has become the de facto platform for processing and storing big data.
Higher-level domain-specific languages (DSL) implemented on top of Hadoopâs MapReduce, such as Pig2 and Hive, quickly followed, making it simpler to write applications running on Hadoop.
A Recurrent Problem
Hadoop, Pig, Hive, and many other projects provide the foundation for storing and processing large amounts of data in an efficient way. Most of the time, it is not possible to perform all required processing with a single MapReduce, Pig, or Hive job. Multiple MapReduce, Pig, or Hive jobs often need to be chained together, producing and consuming intermediate data and coordinating their flow of execution.
Tip
Throughout the book, when referring to a MapReduce, Pig, Hive, or any other type of job that runs one or more MapReduce jobs on a Hadoop cluster, we refer to it as a Hadoop job. We mention the job type explicitly only when there is a need to refer to a particular type of job.
At Yahoo!, as developers started doing more complex processing using Hadoop, multistage Hadoop jobs became common. This led to several ad hoc solutions to manage the execution and interdependency of these multiple Hadoop jobs. Some developers wrote simple shell scripts to start one Hadoop job after the other. Others used Hadoopâs JobControl class, which executes multiple MapReduce jobs using topological sorting. One development team resorted to Ant with a custom Ant task to specify their MapReduce and Pig jobs as dependencies of each otherâalso a topological sorting mechanism. Another team implemented a server-based solution that ran multiple Hadoop jobs using one thread to execute each job.
As these solutions started to be widely used, several issues emerged. It was hard to track errors and it was difficult to recover from failures. It was not easy to monitor progress. It complicated the life of administrators, who not only had to monitor the health of the cluster but also of different systems running multistage jobs from client machines. Developers moved from one project to another and they had to learn the specifics of the custom framework used by the project they were joining. Different organizations within Yahoo! were using significant resources to develop and support multiple frameworks for accomplishing basically the same task.
A Common Solution: Oozie
It was clear that there was a need for a general-purpose system to run multistage Hadoop jobs with the following requirements:
It should use an adequate and well-understood programming model to facilitate its adoption and to reduce developer ramp-up time.
It should be easy to troubleshot and recover jobs when something goes wrong.
It should be extensible to support new types of jobs.
It should scale to support several thousand concurrent jobs.
Jobs should run in a server to increase reliability.
It should be a multitenant service to reduce the cost of operation.
Toward the end of 2008, Alejandro Abdelnur and a few engineers from Yahoo! Bangalore took over a conference room with the goal of implementing such a system. Within a month, the first functional version of Oozie was running. It was able to run multistage jobs consisting of MapReduce, Pig, and SSH jobs. This team successfully leveraged the experience gained from developing PacMan, which was one of the ad hoc systems developed for running multistage Hadoop jobs to process large amounts of data feeds.
Yahoo! open sourced Oozie in 2010. In 2011, Oozie was submitted to the Apache Incubator. A year later, Oozie became a top-level project, Apache Oozie.
Oozieâs role in the Hadoop Ecosystem
In this section, we briefly discuss where Oozie fits in the larger Hadoop ecosystem. Figure 1-1 captures a high-level view of Oozieâs place in the ecosystem. Oozie can drive the core Hadoop componentsânamely, MapReduce jobs and Hadoop Distributed File System (HDFS) operations. In addition, Oozie can orchestrate most of the common higher-level tools such as Pig, Hive, Sqoop, and DistCp. More importantly, Oozie can be extended to support any custom Hadoop job written in any language. Although Oozie is primarily designed to handle Hadoop components, Oozie can also manage the execution of any other non-Hadoop job like a Java class, or a shell script.
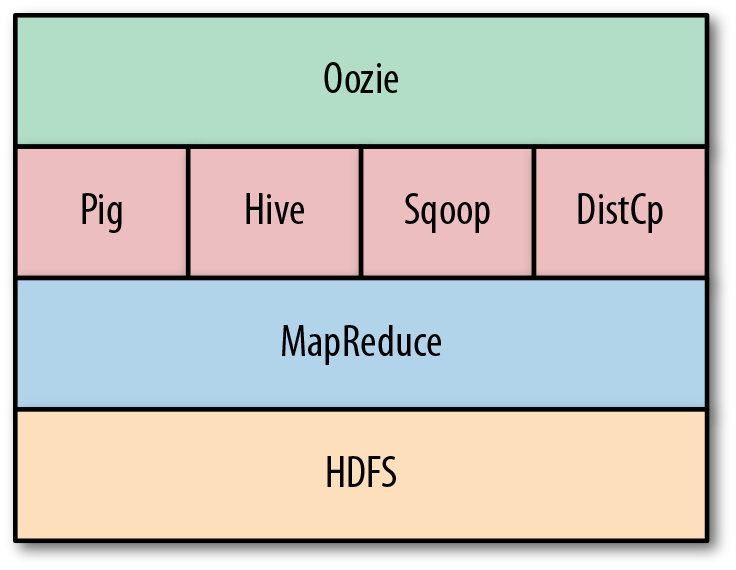
Figure 1-1. Oozie in the Hadoop ecosystem
What exactly is Oozie?
Oozie is an orchestration system for Hadoop jobs. Oozie is designed to run multistage Hadoop jobs as a single job: an Oozie job. Oozie jobs can be configured to run on demand or periodically. Oozie jobs running on demand are called workflow jobs. Oozie jobs running periodically are called coordinator jobs. There is also a third type of Oozie job called bundle jobs. A bundle job is a collection of coordinator jobs managed as a single job.
The name âOozieâ
Alejandro and the engineers were looking for a name that would convey what the system doesâmanaging Hadoop jobs. Something along the lines of an elephant keeper sounded ideal given that Hadoop was named after a stuffed toy elephant. Alejandro was in India at that time, and it seemed appropriate to use the Hindi name for elephant keeper, mahout. But the name was already taken by the Apache Mahout project. After more searching, oozie (the Burmese word for elephant keeper) popped up and it stuck.
A Simple Oozie Job
To get started with writing an Oozie application and running an Oozie job, weâll
create an Oozie workflow application named
identity-WF that runs an identity MapReduce job. The
identity MapReduce job just echoes its input as output and does nothing
else. Hadoop bundles the IdentityMapper class and
IdentityReducer class, so we can use those
classes for the example.
Tip
The source code for all the examples in the book is available on GitHub.
For details on how to build the examples, refer to the README.txt file in the GitHub repository.
Refer to âOozie Applicationsâ for a quick definition of the terms Oozie application and Oozie job.
In this example, after starting the identity-WF workflow, Oozie runs a MapReduce job called identity-MR. If the MapReduce job completes
successfully, the workflow job ends normally. If the MapReduce job fails to
execute correctly, Oozie kills the workflow. Figure 1-2 captures this workflow.
The example Oozie application is built from the examples/chapter-01/identity-wf/ directory using the Maven command:
$ cd examples/chapter-01/identity-wf/ $ mvn package assembly:single ... [INFO] BUILD SUCCESS ...
The identity-WF Oozie workflow
application consists of a single file, the workflow.xml file.
The Map and Reduce classes are already available in Hadoopâs classpath
and we donât need to include them in the Oozie workflow application
package.
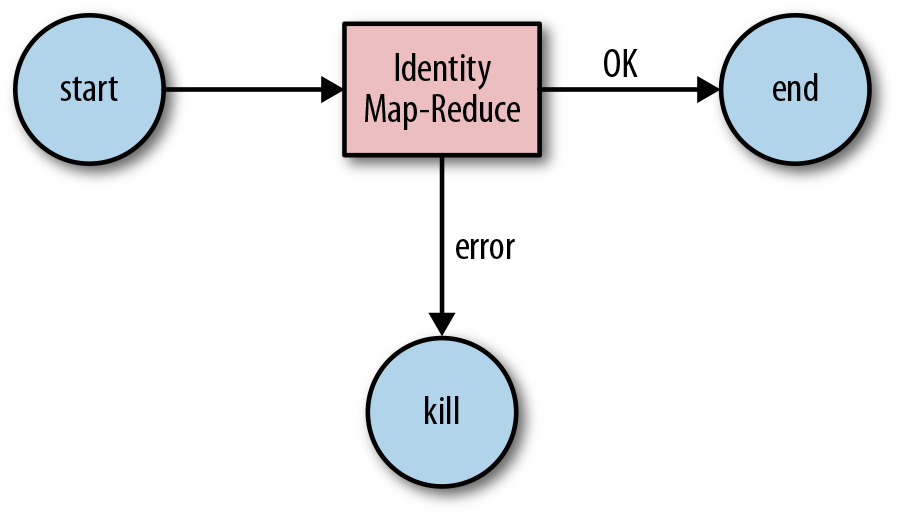
Figure 1-2. identity-WF Oozie workflow example
The workflow.xml file in Example 1-1 contains the workflow definition of the application, an XML representation of Figure 1-2 together with additional information such as the input and output directories for the MapReduce job.
Note
A common question people starting with Oozie ask is Why was XML chosen to write Oozie applications? By using XML, Oozie application developers can use any XML editor tool to author their Oozie application. The Oozie server uses XML libraries to parse and validate the correctness of an Oozie application before attempting to use it, significantly simplifying the logic that processes the Oozie application definition. The same holds true for systems creating Oozie applications on the fly.
Example 1-1. identity-WF Oozie workflow XML (workflow.xml)
<workflow-app xmlns="uri:oozie:workflow:0.4" name="identity-WF">
<start to="identity-MR"/>
<action name="identity-MR">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${exampleDir}/data/output"/>
</prepare>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.hadoop.mapred.lib.IdentityMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.hadoop.mapred.lib.IdentityReducer</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${exampleDir}/data/input</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${exampleDir}/data/output</value>
</property>
</configuration>
</map-reduce>
<ok to="success"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>The Identity Map-Reduce job failed!</message>
</kill>
<end name="success"/>
</workflow-app>The workflow application shown in Example 1-1 expects three parameters: jobTracker, nameNode, and exampleDir. At runtime, these variables will
be replaced with the actual values of these parameters.
Note
In Hadoop 1.0, JobTracker
(JT) is the service that manages MapReduce jobs. This execution
framework has been overhauled in Hadoop 2.0, or YARN; the details of YARN are
beyond the scope of this book. You can think of the YARN ResourceManager (RM) as the new JT, though the RM is vastly different from JT in
many ways. So the <job-tracker> element in Oozie can be used to pass in either the JT or the RM,
even though it is still called as the <job-tracker>. In this book, we will
use this parameter to refer to either the JT or the RM depending on
the version of Hadoop in play.
When running the workflow job, Oozie begins with the start node and follows the specified
transition to identity-MR. The
identity-MR node is a <map-reduce> action. The <map-reduce> action indicates where the MapReduce job should run via the job-tracker and name-node elements (which define the URI of the JobTracker
and the NameNode, respectively). The prepare element is used to delete the output directory that will be
created by the MapReduce job. If we donât delete the output directory
and try to run the workflow job more than once, the MapReduce job will
fail because the output directory already exists. The configuration section defines the Mapper class, the Reducer class, the
input directory, and the output directory for the MapReduce job. If the
MapReduce job completes successfully, Oozie follows the transition
defined in the ok element named
success. If the MapReduce job fails,
Oozie follows the transition specified in the error element named
fail. The success transition takes the job to the
end node, completing the Oozie job
successfully. The fail transition
takes the job to the kill node,
killing the Oozie job.
The example application consists of a single file, workflow.xml. We need to package and deploy the application on HDFS before we can run a job. The Oozie application package is stored in a directory containing all the files for the application. The workflow.xml file must be located in the application root directory:
app/ | |-- workflow.xml
We first need to create the workflow application package in our local filesystem. Then, to deploy it, we must copy the workflow application package directory to HDFS. Hereâs how to do it:
$ hdfs dfs -put target/example/ch01-identity ch01-identity $ hdfs dfs -ls -R ch01-identity /user/joe/ch01-identity/app /user/joe/ch01-identity/app/workflow.xml /user/joe/ch01-identity/data /user/joe/ch01-identity/data/input /user/joe/ch01-identity/data/input/input.txt
Tip
To access HDFS from the command line in newer Hadoop versions,
the hdfs dfs commands
are used. Longtime users of Hadoop may be familiar with the hadoop fs commands. Either interface will
work today, but users are encouraged to move to the hdfs dfs commands.
The Oozie workflow application is now deployed in the ch01-identity/app/ directory under the userâs HDFS home directory. We have also copied the necessary input data required to run the Oozie job to the ch01-identity/data/input directory.
Before we can run the Oozie job, we need a job.properties file in our local filesystem that specifies the required parameters for the job and the location of the application package in HDFS:
nameNode=hdfs://localhost:8020
jobTracker=localhost:8032
exampleDir=${nameNode}/user/${user.name}/ch01-identity
oozie.wf.application.path=${exampleDir}/appThe parameters needed for this example are jobTracker, nameNode, and exampleDir. The oozie.wf.application.path indicates the
location of the application package in HDFS.
Caution
Users should be careful with the JobTracker and NameNode URI, especially the port
numbers. These are cluster-specific Hadoop configurations. A common
problem we see with new users is that their Oozie job submission will
fail after waiting for a long time. One possible reason for this is
incorrect port specification for the JobTracker.
Users need to find the correct JobTracker RPC port
from the administrator or Hadoop site XML file. Users often get this
port and the JobTracker UI port mixed up.
We are now ready to submit the job to Oozie. We will use the
oozie command-line tool for
this:
$ export OOZIE_URL=http://localhost:11000/oozie $ oozie job -run -config target/example/job.properties job: 0000006-130606115200591-oozie-joe-W
We will cover Oozieâs command-line tool and its different
parameters in detail later in âOozie CLI Toolâ. For now, we
just need to know that we can run an Oozie job using the -run option. And using the -config option, we can specify the location of
the job.properties file.
We can also monitor the progress of the job using the oozie
command-line tool:
$ oozie job -info 0000006-130606115200591-oozie-joe-W Job ID : 0000006-130606115200591-oozie-joe-W ----------------------------------------------------------------- Workflow Name : identity-WF App Path : hdfs://localhost:8020/user/joe/ch01-identity/app Status : RUNNING Run : 0 User : joe Group : - Created : 2013-06-06 20:35 GMT Started : 2013-06-06 20:35 GMT Last Modified : 2013-06-06 20:35 GMT Ended : - CoordAction ID: - Actions ----------------------------------------------------------------- ID Status ----------------------------------------------------------------- 0000006-130606115200591-oozie-joe-W@:start: OK ----------------------------------------------------------------- 0000006-130606115200591-oozie-joe-W@identity-MR RUNNING -----------------------------------------------------------------
When the job completes, the oozie command-line tool reports the completion state:
$ oozie job -info 0000006-130606115200591-oozie-joe-W Job ID : 0000006-130606115200591-oozie-joe-W ----------------------------------------------------------------- Workflow Name : identity-WF App Path : hdfs://localhost:8020/user/joe/ch01-identity/app Status : SUCCEEDED Run : 0 User : joe Group : - Created : 2013-06-06 20:35 GMT Started : 2013-06-06 20:35 GMT Last Modified : 2013-06-06 20:35 GMT Ended : 2013-06-06 20:35 GMT CoordAction ID: - Actions ----------------------------------------------------------------- ID Status ----------------------------------------------------------------- 0000006-130606115200591-oozie-joe-W@:start: OK ----------------------------------------------------------------- 0000006-130606115200591-oozie-joe-W@identity-MR OK ----------------------------------------------------------------- 0000006-130606115200591-oozie-joe-W@success OK -----------------------------------------------------------------
The output of our first Oozie workflow job can be found in the ch01-identity/data/output directory under the userâs HDFS home directory:
$ hdfs dfs -ls -R ch01-identity/data/output /user/joe/ch01-identity/data/output/_SUCCESS /user/joe/ch01-identity/data/output/part-00000
The output of this Oozie job is the output of the MapReduce job run by the workflow job. We can also see the job status and detailed job information on the Oozie web interface, as shown in Figure 1-3.
This section has illustrated the full lifecycle of a simple Oozie workflow application and the typical ways to monitor it.
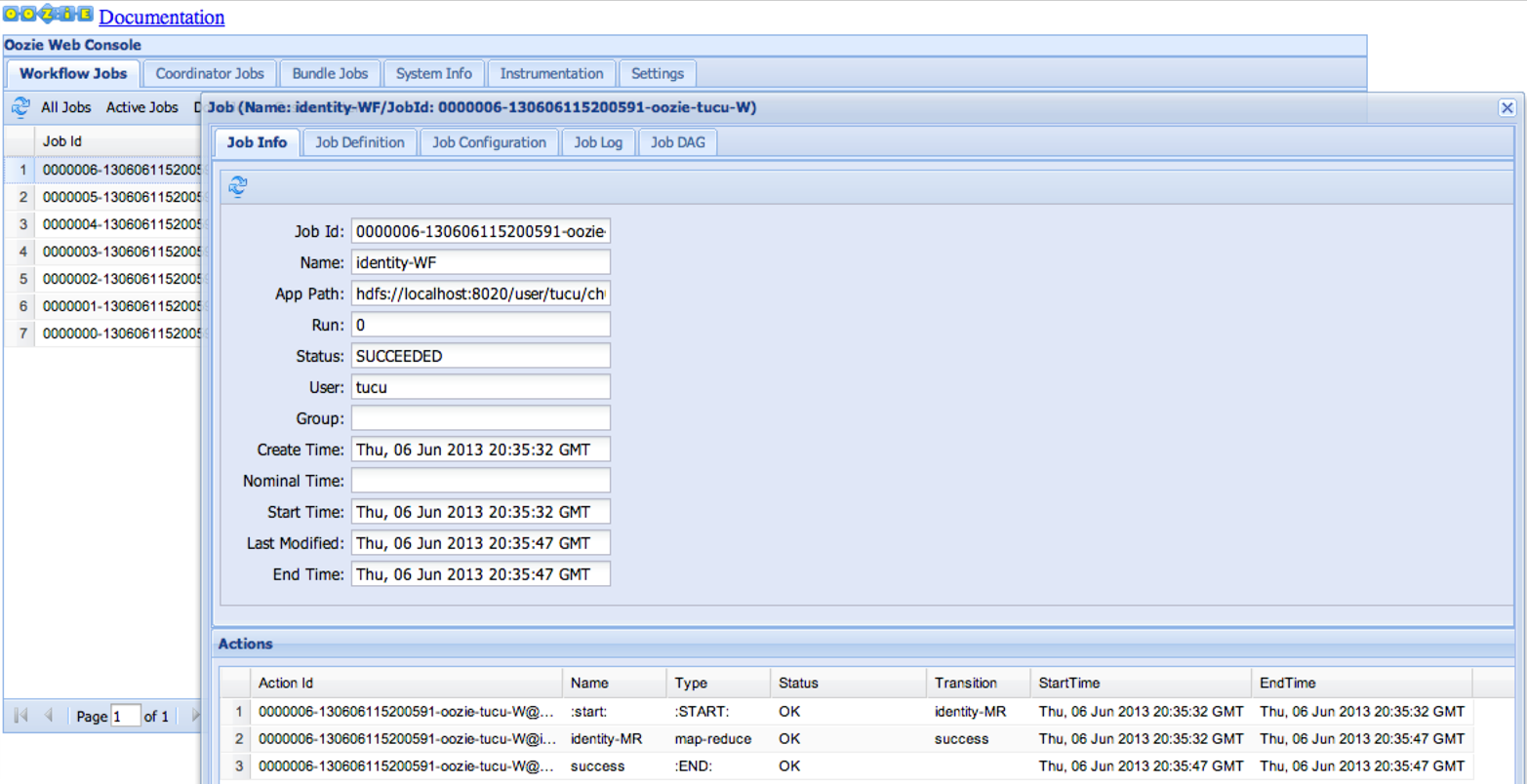
Figure 1-3. Oozie workflow job on the Oozie web interface
Oozie Releases
Oozie has gone through four major releases so far. The salient features of each of these major releases are listed here:
- 1.x
- 2.x
- 3.x
- 4.x
Hive/HCatalog integration, Oozie server high availability, and support for service-level agreement (SLA) notifications
Several other features, bug fixes, and improvements have also been released as part of the various major, minor, and micro releases. Support for additional types of Hadoop and non-Hadoop jobs (SSH, Hive, Sqoop, DistCp, Java, Shell, email), support for different database vendors for the Oozie database (Derby, MySQL, PostgreSQL, Oracle), and scalability improvements are some of the more interesting enhancements and updates that have made it to the product over the years.
Timeline and status of the releases
The 1.x release series was developed by Yahoo! internally. There were two open source code drops on GitHub in May 2010 (versions 1.5.6 and 1.6.2).
The 2.x release series was developed in Yahoo!âs Oozie repository on GitHub. There are nine releases of the 2.x series, the last one being 2.3.2 in August 2011.
The 3.x release series had eight releases. The first three were developed in Yahoo!âs Oozie repository on GitHub and the rest in Apache Oozie, the last one being 3.3.2 in March 2013.
4.x is the newest series and the latest version (4.1.0) was released in December 2014.
The 1.x and 2.x series are are no longer under development, the 3.x series is under maintenance development, and the 4.x series is under active development.
The 3.x release series is considered stable.
Current and previous releases are available for download from Apache Oozie, as well as a part of Cloudera, Hortonworks, and MapR Hadoop distributions.
Compatibility
Oozie has done a very good job of preserving backward compatibility between releases. Upgrading from one Oozie version to a newer one is a simple process and should not affect existing Oozie applications or the integration of other systems with Oozie.
As we discussed in âA Simple Oozie Jobâ, Oozie applications must be written in XML. It is common for Oozie releases to introduce changes and enhancements to the XML syntax used to write applications. Even when this happens, newer Oozie versions always support the XML syntax of older versions. However, the reverse is not true, and the Oozie server will reject jobs of applications written against a later version.
As for the Oozie server, depending on the scope of the upgrade, the Oozie administrator might need to suspend all jobs or let all running jobs complete before upgrading. The administrator might also need to use an upgrade tool or modify some of the configuration settings of the Oozie server.
The oozie command-line tool,
Oozie client Java API, and the Oozie HTTP REST API have all evolved
maintaining backward compatibility with previous releases.3
Some Oozie Usage Numbers
Oozie is widely used in several large production clusters across major enterprises to schedule Hadoop jobs. For instance, Yahoo! is a major user of Oozie and it periodically discloses usage statistics. In this section, we present some of these numbers just to give readers an idea about Oozieâs scalability and stability.
Yahoo! has one of the largest deployments of Hadoop, with more than 40,000 nodes across several clusters. Oozie is the primary workflow engine for Hadoop clusters at Yahoo! and is responsible for launching almost 72% of 28.9 million monthly Hadoop jobs as of January 2015. The largest Hadoop cluster processes 60 bundles and 1,600 coordinators, amounting to 80,000 daily workflows with 3 million workflow nodes. About 25% of the coordinators execute at frequencies of either 5, 10, or 15 minutes. The remaining 75% of the coordinator jobs are mostly hourly or daily jobs with some weekly and monthly jobs. Yahooâs Oozie team runs and supports several complex jobs. Interesting examples include a single bundle with 200 coordinators and a workflow with 85 fork/join pairs.
Now that we have covered the basics of Oozie, including the problem it solves and how it fits into the Hadoop ecosystem, itâs time to learn more about the concepts of Oozie. We will do that in the next chapter.
1 Tom White, Hadoop: The Definitive Guide, 4th Edition (Sebastopol, CA: OâReilly 2015).
2 Olga Natkovich, "Pig - The Road to an Efficient High-level language for Hadoop,â Yahoo! Developer Network Blog, October 28, 2008.
3 Roy Thomas Fielding, "REST: Representational State Transfer" (PhD dissertation, University of California, Irvine, 2000)
Get Apache Oozie now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

