Chapter 4. T-Shaped Data Scientists
We feel that a defining feature of data scientists is the breadth of their skills — their ability to single-handedly do at least prototype-level versions of all the steps needed to derive new insights or build data products (Mason & Wiggins, 2010). We also feel that the most successful data scientists are those with substantial, deep expertise in at least one aspect of data science, be it statistics, big data, or business communication.
In many ways, this pattern matches the “T-shaped skills” idea that has been promoted since at least the early 1990s (see citations here). The “T” represents breadth of skills, across the top, with depth in one area represented by the vertical bar. T-shaped professionals can more easily work in interdisciplinary teams than those with less breadth and can be more effective than those without depth. Data science is an inherently collaborative and creative field, where the successful professional can work with database administrators, business people, and others with overlapping skill sets to get data projects completed in innovative ways.
For data scientists, we feel this notion can help address the communications issues we’ve described. By clarifying your areas of depth, perhaps using our Skills terminology, others can more quickly understand where your expertise lies. We also suggest that our Skills terminology can suggest areas of career development. For instance, a data scientist with an Operations Research background and deep skills in Simulation, Optimization, Algorithms, and Math might find value in learning some of the new Bayesian/Monte Carlo Statistics methods that also fall under our Math/OR Skills Group. That same data scientist might also want to make sure they have enough broad programming, big data, and business skills to be able to intelligently collaborate with (or lead) others on a data science team.
Others have made this point as well. Stanton et al. (2012), in a writeup of a recent workshop, reviewed the state of data science in a primarily academic/"eScience” context. Interestingly, they emphasized a role performing data archival and preservation, which is not currently a focus of data scientists, although perhaps it should be. Their workshop participants recommended that the breadth of T-shaped data scientists should fall into three categories: data curation, analytics and visualization, and networks and infrastructure. They also mention the intriguing idea that data scientists should have (serif) “I"-shaped skills, with domain knowledge along the bottom (see also The Data Science Venn Diagram, Conway, 2010).
Evidence for T-Shaped Data Scientists
Our survey data can be used to indicate how T-shaped data scientists already are, at least directionally. As we used rankings rather than an absolute measure of skills, our data only lets us approximate skill depth.
What would our results have to look like to support the idea that data scientists are T-shaped? In general, most respondents would have a Skill Group (e.g., Math/OR or Statistics) that they are strong in, and relatively uniform rankings in the other Skill Groups. In contrast, if the rankings (and thus groupings) were idiosyncratic, with different people having different patterns of skills, we wouldn’t see that pattern.
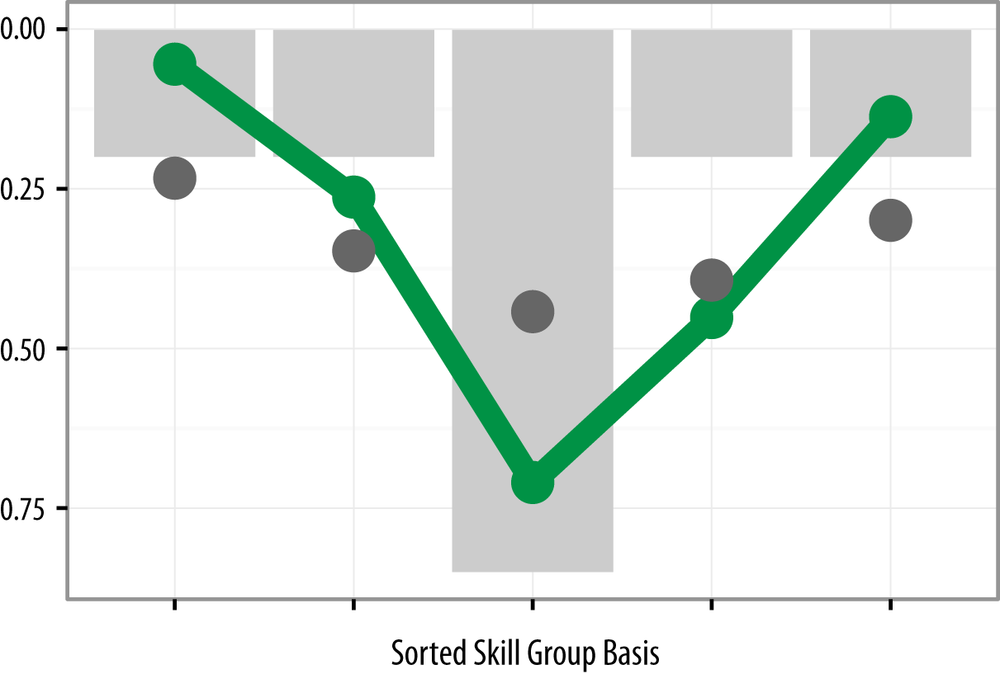
Figure 4-1 shows that our respondents did trend toward T-shapes in their skills. Each respondent has a numerical “loading” representing the strength of their responses to the five Skill Groups. Instead of plotting the same Skill Group in the same place, we instead plot the strongest Skill Group for an individual in the center, the next strongest to the right, then to the left, and so forth. The grey bars show a subjectively created “ideal” T-shaped pattern. The grey circles illustrate a simulated null hypothesis: that our respondents were not T-shaped in their skills. (The process of sorting random ranks will naturally cause some skill groups to be stronger than others.) The green circles show the results from our respondents. They were substantially more T-shaped than you would expect from random rankings and tended to have one strongest Skill Group, perhaps a secondary Skill Group, and weaker skills elsewhere. (See Appendix: Non-negative Matrix Factorization for technical details.)
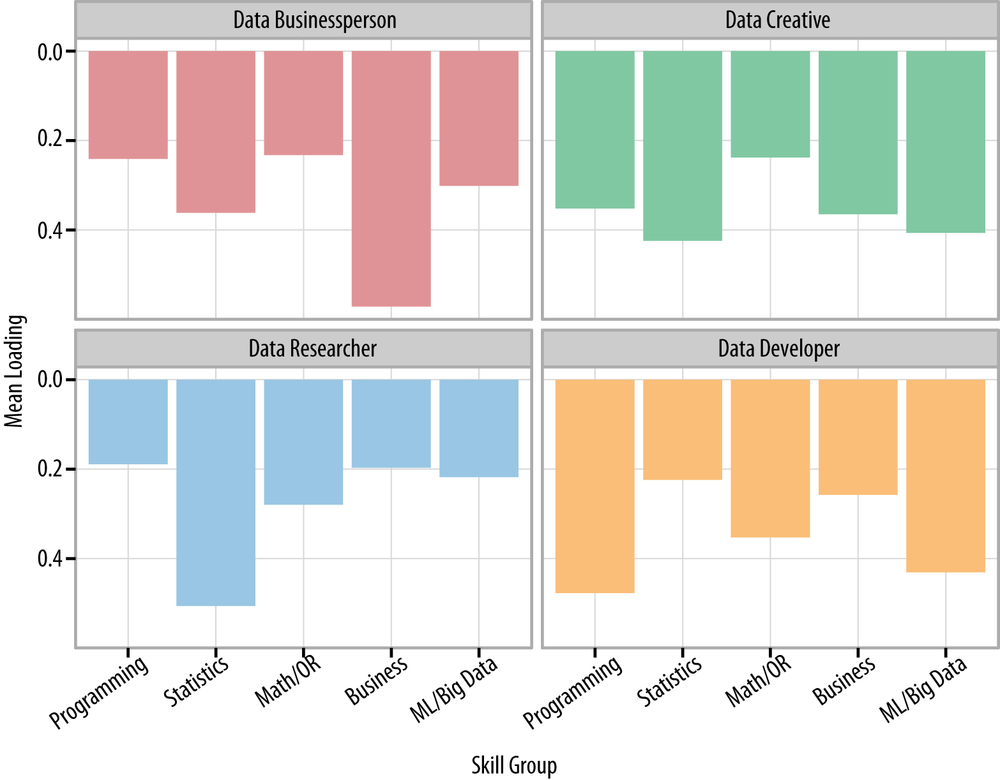
We can look at the T-shaped nature of the four Self-ID Groups as well. Figure 4-2 shows how strongly, on average, people in each Self-ID Group were associated with our five Skills Groups. Data Businesspeople were quite T-shaped, with top skills in Business, and moderate skills elsewhere. Data Researchers tended to be very deep in Statistics (and related skills), but somewhat less broad. On average, they ranked all of the ML/Big Data, Business, and Programming skills fairly low. Data Developers had a pattern that might be called “Pi-shaped,” with strong Programming skills and relatively strong ML/Big Data skills, along with moderate skills in the other three skill groups. And finally, Data Creatives tended to be the least T-shaped of our respondents. Interestingly, Data Creatives were, on average, neither ranked the strongest nor the weakest in any skill group.
Get Analyzing the Analyzers now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

