In the card game Bridge, each player is dealt 13 cards, all face down. One way to arrange a hand is to pick up the cards one at a time and insert each card into the hand. The invariant to maintain is that the cards in the hand are always sorted by suit and then by rank within the same suit. Start by picking up a single card to form a hand that is (trivially) already sorted. For each card picked up, find the correct place to insert the card into the hand, thus maintaining the invariant that the cards in the hand are sorted. When all the cards are placed, the invariant establishes that the algorithm works. When you hold cards in your hand, it is easy to insert a card into its proper position because the other cards are just pushed aside a bit to accept the new card. When the collection is stored in memory, however, a sorting algorithm must do more work to manually move information, in order to open up space for an element to be inserted.
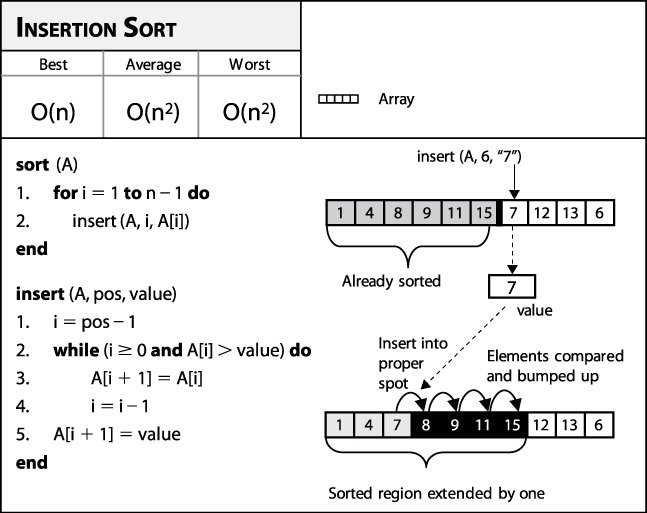
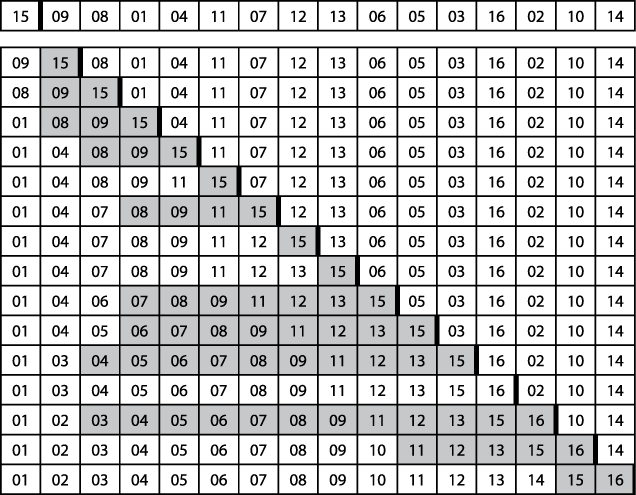
The pseudocode in Figure 4-6 describes how Insertion Sort repeatedly invokes the insert helper function to ensure that A[0,i] is properly sorted; eventually, i reaches the rightmost element, sorting A entirely. Figure 4-7 shows how Insertion Sort operates on a small, unordered collection A of size n=16. The 15 rows that follow depict the state of A after each pass. A is sorted "in place" by incrementing pos=1 up to n−1 and inserting the element A[pos] into its rightful position in the growing sorted region A[0,pos], demarcated on the right by a bold vertical line. The elements shaded in gray were shifted to the right to make way for the inserted element; in total, Insertion Sort executed 60 transpositions (a movement of just one place by an element).
Context
Use Insertion Sort when you have a small number of elements to sort or the elements in the initial collection are already "nearly sorted." Determining when the array is "small enough" varies from one machine to another and by programming language. Indeed, even the type of element being compared may be significant.
Forces
Insertion Sort need only set aside space for a single element to function properly. For a pointer-based representation, this is trivial; for a value-based representation, one need only allocate enough memory to store a value (requiring a fixed s bytes, as described in the earlier section "Representation") for the duration of the sort, after which it can be freed. There are no complicated nested loops to implement, and a generic function can be written to sort many different types of elements simply through the use of a cmp comparator function. For value-based representations, most language libraries offer a block memory move function to make the algorithm more efficient.
Solution
When the information is stored using pointers, the C program in Example 4-1 sorts an array ar with items that can be compared using a provided comparison function, cmp.
Example 4-1. Insertion Sort with pointer-based values
void sortPointers (void **ar, int n,
int(*cmp)(const void *,const void *)) {
int j;
for (j = 1; j < n; j++) {
int i = j-1;
void *value = ar[j];
while (i >= 0 && cmp(ar[i], value)> 0) {
ar[i+1] = ar[i];
i--;
}
ar[i+1] = value;
}
}When A is represented using value-based storage, it is packed into n rows of a fixed element size of s bytes. Manipulating the values requires a comparison function as well as the means to copy values from one location to another. Example 4-2 shows a suitable C program that uses memmove to transfer the underlying bytes efficiently for a set of contiguous entries in A.
Example 4-2. Insertion Sort using value-based information
void sortValues (void *base, int n, int s,
int(*cmp)(const void *, const void *)) {
int j;
void *saved = malloc (s);
for (j = 1; j < n; j++) {
/* start at end, work backward until smaller element or i < 0. */
int i = j-1;
void *value = base + j*s;
while (i >= 0 && cmp(base + i*s, value) > 0) { i--; }/* If already in place, no movement needed. Otherwise save value to be
* inserted and move as a LARGE block intervening values. Then insert
* into proper position. */
if (++i == j) continue;
memmove (saved, value, s);
memmove (base+(i+1)*s, base+i*s, s*(j-i));
memmove (base+i*s, saved, s);
}
free (saved);
}Given the example in Figure 4-7, Insertion Sort needed to transpose 60 elements that were already in sorted order. Since there were 15 passes made over the array, on average four elements were moved during each pass. The optimal performance occurs when the array is already sorted, and arrays sorted in reverse order naturally produce the worst performance for Insertion Sort. If the array is already "mostly sorted," Insertion Sort does well because there is less need to transpose the elements.
Analysis
In the best case, each of the n items is in its proper place and thus Insertion Sort takes linear time, or O(n). This may seem to be a trivial point to raise (how often are you going to sort a set of already sorted elements?), but it is important because Insertion Sort is the only sorting algorithm based on comparisons discussed in this chapter that has this behavior.
Much real-world data is already "partially sorted," so optimism and realism might coincide to make Insertion Sort an effective algorithm for much real-world data. But sadly, if every input permutation is equally likely, then the probability of having optimal data (every item being in its proper position) is only 1/n!; for n=10, the odds are already 3.6 million to one. Note that the efficiency of Insertion Sort increases when duplicate items are present, since there are fewer swaps to perform.
Unfortunately, Insertion Sort suffers from being too conservative for "random data." If all n items are distinct and the array is "random" (all permutations of the data are equally likely), then each item starts on average n/3 positions in the array from its final resting place.[8] So in the average case and worst case, each of the n items must be transposed a linear number of positions, and Insertion Sort will take quadratic time, or O(n2).
Insertion Sort operates inefficiently for value-based data because of the amount of memory that must be shifted to make room for a new value. Table 4-1 contains direct comparisons between a naïve implementation of value-based Insertion Sort and the implementation from Example 4-2. Here 10 random trials of sorting n elements were conducted, and the best and worst results were discarded. This table shows the average of the remaining eight runs. Note how the implementation improves by using a block memory move rather than individual memory swapping. Still, as the array size doubles, the performance time approximately quadruples, validating the O(n2) behavior of Insertion Sort. Even with the bulk move improvement, Insertion Sort still remains quadratic since the performance of Insertion Sort using bulk moves is a fixed multiplicative constant (nearly 1/7) of the naïve Insertion Sort. The problem with Insertion Sort is that it belongs to a conservative class of algorithms (called local transposition sorts) in which each element moves only one position at a time.
Table 4-1. Insertion Sort bulk move versus Insertion Sort (in seconds)
|
n |
Insertion Sort bulk move (Bn) |
Naïve Insertion Sort (Sn) |
Ratio B2n/Bn |
Ratio S2n/Sn |
|---|---|---|---|---|
|
1,024 |
0.0055 |
0.0258 | ||
|
2,048 |
0.0249 |
0.0965 |
4.5273 |
3.7403 |
|
4,096 |
0.0932 |
0.3845 |
3.7430 |
3.9845 |
|
8,192 |
0.3864 |
1.305 |
4.1459 |
3.3940 |
|
16,384 |
1.3582 |
3.4932 |
3.5150 |
2.6768 |
|
32,768 |
3.4676 |
12.062 |
2.5531 |
3.4530 |
|
65,536 |
15.5357 |
48.3826 |
4.4802 |
4.0112 |
|
131,072 |
106.2702 |
200.5416 |
6.8404 |
4.1449 |
When Insertion Sort operates over pointer-based input, swapping elements is more efficient; the compiler can even generate optimized code to minimize costly memory accesses.
[8] The program numTranspositions in the code repository empirically validates this claim for small n up to 12; also see Trivedi (2001).
Get Algorithms in a Nutshell now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

