Chapter 4. To the Cloud!
The trend toward server-side computing and the exploding popularity of Internet services has created a new class of computing systems that we have named warehouse-scale computers, or WSCs. The name is meant to call attention to the most distinguishing feature of these machines: the massive scale of their software infrastructure, data repositories, and hardware platform. This perspective is a departure from a view of the computing problem that implicitly assumes a model where one program runs in a single machine. In warehouse-scale computing, the program is an Internet service, which may consist of tens or more individual programs that interact to implement complex end-user services such as email, search, or maps.
—Luiz André Barroso and Urs Hölzle, The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines (Morgan and Claypool)
Introduction
In this chapter, we will extend the stack we introduced in Chapter 3 into a scaled-up cloud stack (Figure 4-1 and Figure 4-2). In so doing, we will enable a bridge between local operations on sample data and those in the cloud at scale on big data. We’ll be taking advantage of the cloud’s elasticity along the way. In the following pages, we’ll be employing such services as GitHub, dotCloud, and Amazon Web Services to deploy our application at scale. Doing so will allow us to proceed unencumbered by the limited resources of our own machines, and will enable access to vast resources and data.

Cloud computing has revolutionized the development of new applications—greenfield projects unconstrained by existing infrastructure. For a new project, or a new company, cloud computing offers instant-on infrastructure that can scale with any load or any problem. More than that—once we accept that we must build horizontally scalable systems out of commodity components—cloud computing offers application development at the level of the composition of vast system components.
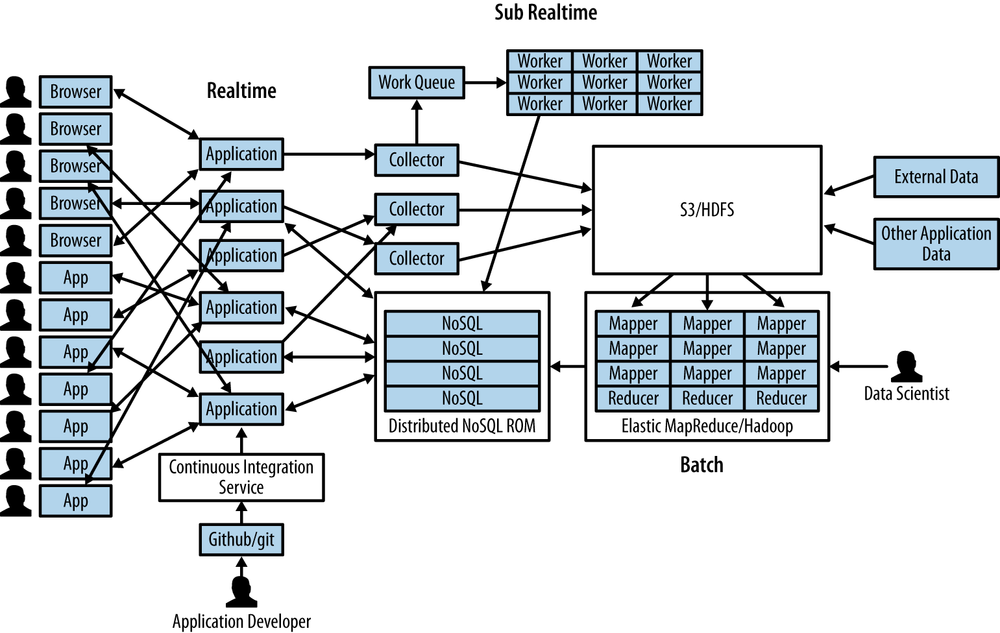
We are able to operate in terms of systems in a datacenter controlled by a small team, composed into architecture on the fly and scaled up and down to match any load. In cloud computing, there is freedom to operate at new degrees of complexity via higher levels of abstraction and automation.
Note
Indeed, the development of cloud computing is as fundamental as electrification, whereby clock cycles replace electrons, and we are only beginning to see the consequences of its potential. As research scientist and author Andrew McAfee writes in his blog post “The Cloudy Future of Corporate IT”: “The real impact of the new technology was not apparent right away. Electrical power didn’t just save costs or make factories a bit more efficient. It allowed radically new designs and approaches.”
Code examples for this chapter are available at https://github.com/rjurney/Agile_Data_Code/tree/master/ch04. Clone the repository and follow along!
git clone https://github.com/rjurney/Agile_Data_Code.git
GitHub
Git is a fast, distributed version control system created by Linus Torvalds for the Linux Kernel. Git addresses the operational problems large projects had with there being a single serial “repository of record.”
In providing a concurrent source code repository, Git enabled the creation of the social network GitHub, which enables collaboration and monitoring of myriad software projects and their authors. GitHub has become a jumping-off point for other web services, and we will use it to deploy our application to the cloud.
Excellent instructions for getting started with GitHub are available at http://help.github.com/, so we will not repeat them here. Sign up for a GitHub basic account if you do not already have one.
dotCloud
dotCloud, shown in Figure 4-3, is a cloud application platform. Sitting on top of Amazon Web Services, it abstracts away the complexity of building reliable web application and database hosting, while still being accessible to other Amazon Web Services. Higher-level tools and platforms are more powerful, and we will be using dotCloud in place of building our own high-availability web server and MongoDB clusters.
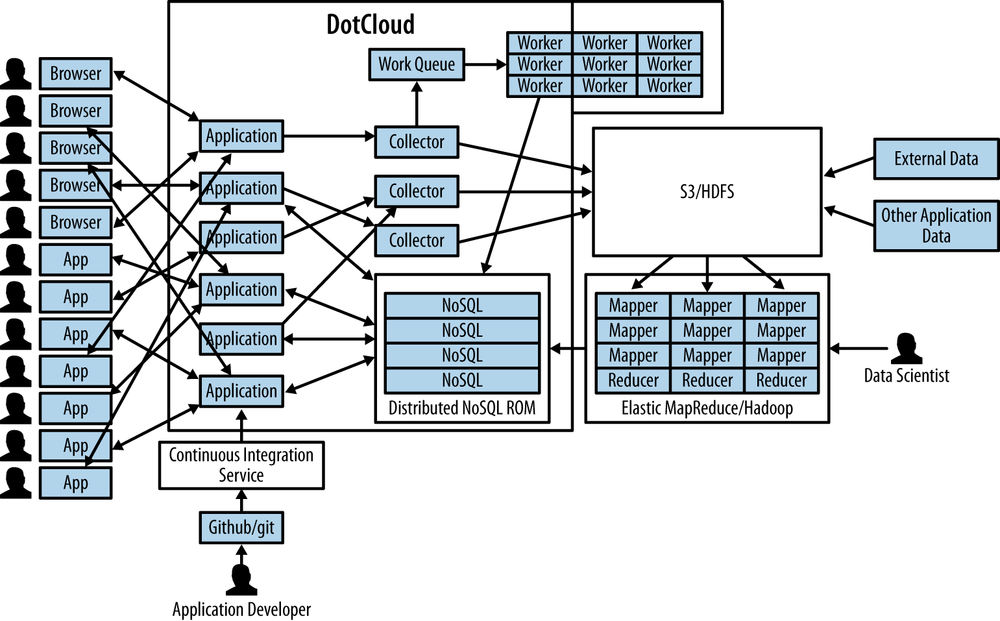
Although there are other “cloud platform as a service” providers, we’ll use dotCloud because it supports many languages, offers Amazon Web Services interoperability, autoscales in response to load, and includes a rich library of services for databases and other features.
Echo on dotCloud
Excellent instructions for getting started with dotCloud and Python are available at http://docs.dotcloud.com/0.9/firststeps/install/ and http://docs.dotcloud.com/0.9/services/python/, so we will not repeat them here. Set up a dotCloud account if you do not already have one, and create a dotCloud project pointing at the GitHub project ch04 you set up in the last section.
The initial application code for our project is simple, as you can see in Example 4-1.
Edit ch04/dotcloud.yml to specify our application’s resources: a Python application with system dependencies (Ubuntu packages), and a MongoDB database instance.
www:
type: python
systempackages:
- libatlas-base-dev
- gfortran
- libsnappy1
- libsnappy-dev
data:
type: mongodbFinally, edit ch04/wsgi.py, which shows dotCloud how to run your web application, as shown in Example 4-2.
Now ensure the dotCloud CLI is installed on your machine: http://docs.dotcloud.com/0.9/firststeps/install/.
That’s it. We can now create a dotCloud
application with dotcloud create
myapp, and update/deploy the application with dotcloud push. For this minor trouble, we get
a highly available application server that can autoscale with the push
of a button.
Use dotcloud setup to configure
your environment:
dotcloud setup <dotCloud username or email: russell.jurney@gmail.com Password: ==> dotCloud authentication is complete! You are recommended to run `dotcloud check` now.
dotcloud create will set up an
application like so:
$ dotcloud create testola ==> Creating a sandbox application named "testola" ==> Application "testola" created. Connect the current directory to "testola"? [Y/n]: y ==> Connecting with the application "testola" ==> Connected with default push options: --rsync
To update code, run dotcloud
push:
...
02:29:15.262548: [www] Build completed successfully. Compiled image size is 38MB
02:29:15.279736: [www] Build successful for service (www)
02:29:15.290683: --> Application (testola) build is done
02:29:15.311308: --> Provisioning services' instances... (This may take a bit)
02:29:15.338441: [www] Using default scaling for service www (1 instance(s)).
02:29:15.401420: [www.0] Provisioning service (www) instance #0
02:29:16.414451: [data] Using default scaling for service data (1 instance(s)).
02:29:16.479846: [data.0] Provisioning service (data) instance #0
02:30:00.606768: --> All service instances have been provisioned. Installing...
02:30:00.685336: [www.0] Installing build revision rsync-136003975113 for service
(www) instance #0
02:30:22.430300: [www.0] Running postinstall script...
02:30:23.745193: [www.0] Launching...
02:30:28.173168: [www.0] Waiting for the instance to become responsive...
02:30:41.201260: [www.0] Re-routing traffic to the new build...
02:30:43.199746: [www.0] Successfully installed build revision rsync-
1360203975113 for service (www) instance #0
02:30:43.208778: [www.0] Installation successful for service (www) instance #0
02:30:43.211030: --> Application (testola) fully installed
==> Application is live at http://testola-rjurney.dotcloud.comTo monitor logs, use dotcloud
logs.
Our server is up at the URL given, in this case http://testola-rjurney.dotcloud.com. Visiting our app with some input, http://testola-rjurney.dotcloud.com/hello world shows us our application is running, as shown in Figure 4-4.
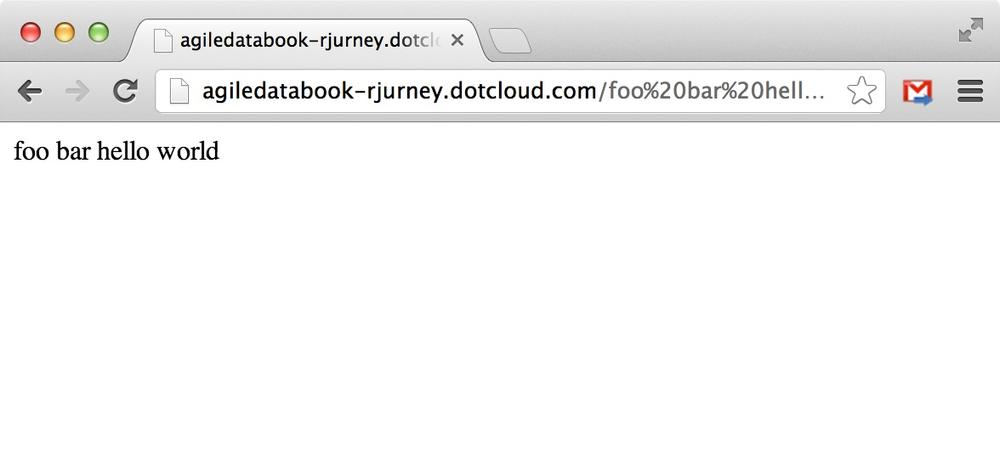
We can now use Git to release our application continuously as we mine and publish new data to display.
Python Workers
dotCloud provides Python workers that can help process events of content that is generated on the fly, and that takes longer than a web request to process, but not so long that we would want to wait for an entire Hadoop job to finish. Instructions on using Python dotCloud workers can be found at http://docs.dotcloud.com/0.9/services/python-worker/.
Amazon Web Services
According to the whitepaper “Building Fault-Tolerant Applications on AWS”:
Amazon Web Services (AWS) provides a platform that is ideally suited for building fault-tolerant software systems. However, this attribute is not unique to our platform. Given enough resources and time, one can build a fault-tolerant software system on almost any platform. The AWS platform is unique because it enables you to build fault-tolerant systems that operate with a minimal amount of human interaction and up-front financial investment.
Amazon is the leading cloud provider, setting the standard against which others are measured. Amazon has managed to continue to innovate, rolling out many new offerings at higher and higher levels each year.
More important, dotCloud and the other platform-as-a-service (PaaS) offerings we are using are built on top of AWS. This allows us to use these platforms directly with AWS offerings like S3 and EC2. This means we can roll custom infrastructure when it is called for, and rely on platforms as a service to save time otherwise.
Simple Storage Service
Amazon’s Simple Storage Service (S3) is a cloud-based replacement for the Hadoop filesystem: vast, distributed, reliable storage that can be read concurrently from many processes. S3 is highly available, and is well connected to other services.
S3 should be the dumping ground for all data associated with your project. All logs, scrapes, and database dumps go here. We will combine datasets on S3 to produce more value, then publish them to MongoDB.
Download the s3cmd utility from http://sourceforge.net/projects/s3tools/files/ and use it to upload your emails to S3.
[bash]$ s3cmd --configure
Your settings should look like this:
New settings: Access Key: <access_key_id> Secret Key: <secret_key> Encryption password: Path to GPG program: None Use HTTPS protocol: True HTTP Proxy server name: HTTP Proxy server port: 0
Now create a bucket for your emails and upload them, as shown in Example 4-3. The bucket name will need to be unique, so personalize it.
[bash]$ s3cmd mb s3://rjurney.email.upload Bucket 's3://rjurney.email.upload/' created [bash]$ s3cmd put --recursive /me/tmp/inbox s3://rjurney.email.upload /me/tmp/inbox/part-0-0.avro -> s3://rjurney.email.upload/inbox/part-0-0.avro [part 1 of 4, 15MB] 15728640 of 15728640 100% in 21s 725.65 kB/s done /me/tmp/inbox/part-0-0.avro -> s3://rjurney.email.upload/inbox/part-0-0.avro [part 2 of 4, 15MB] 2322432 of 15728640 14% in 4s 533.93 kB/s
Elastic MapReduce
Amazon’s Elastic MapReduce, or EMR, allows us to spin up a Hadoop cluster of any size we like, and to rent it hourly to process our data. When we are finished, we throw the cluster away. This gives us the agility to scale our data processing to whatever load we throw at it in a moment’s notice.
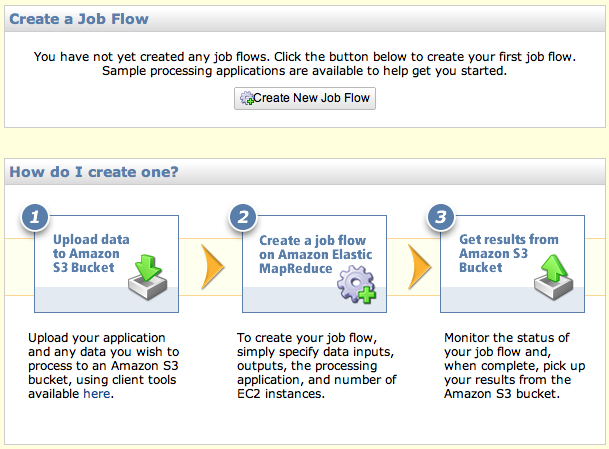
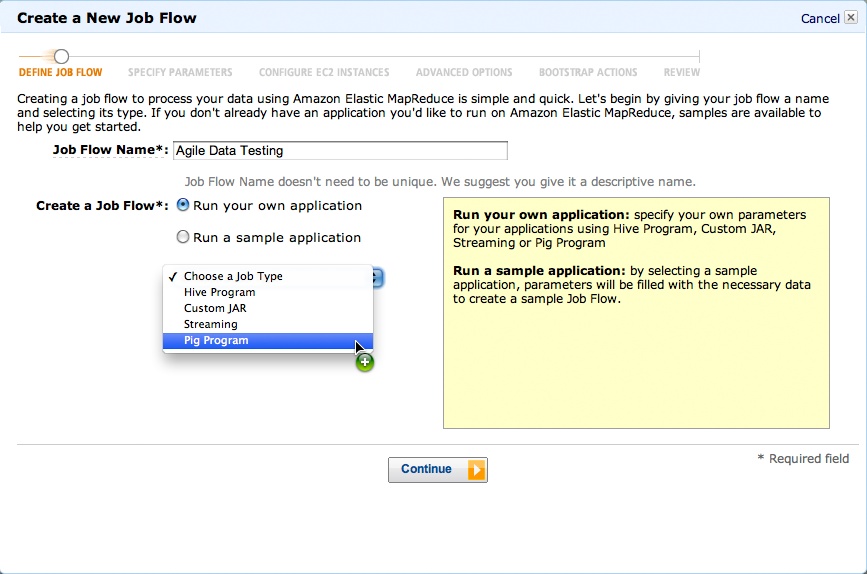
To start, set up a new job flow as shown in Figure 4-5.
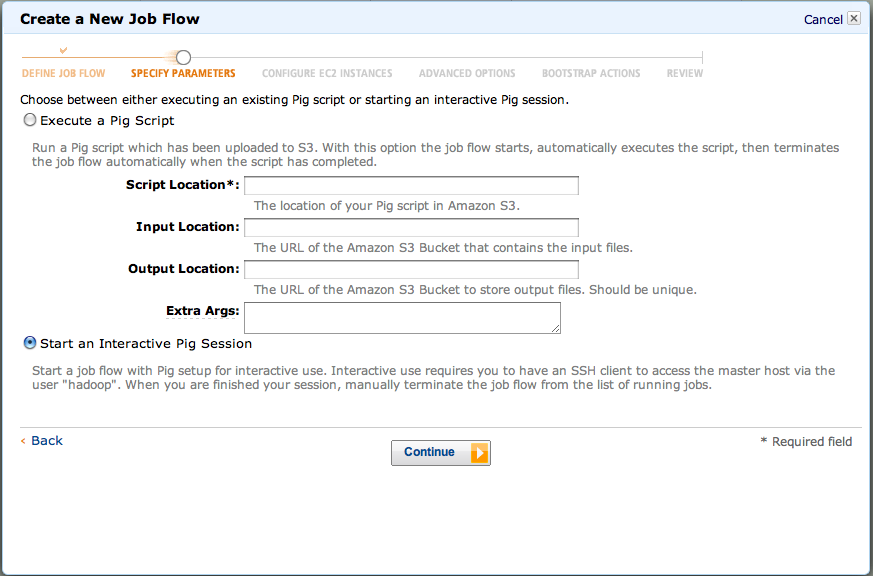
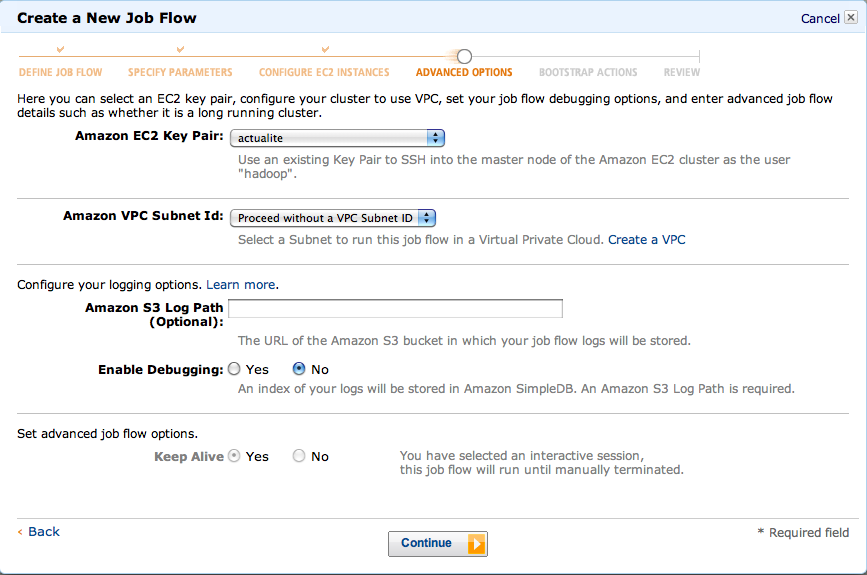
Select ‘Run’ your own application, and choose ‘Pig Program’ as the type (Figure 4-6).Then choose ‘Start an Interactive Pig Session’ (Figure 4-7). Finally, select a keypair for your session (Figure 4-8).
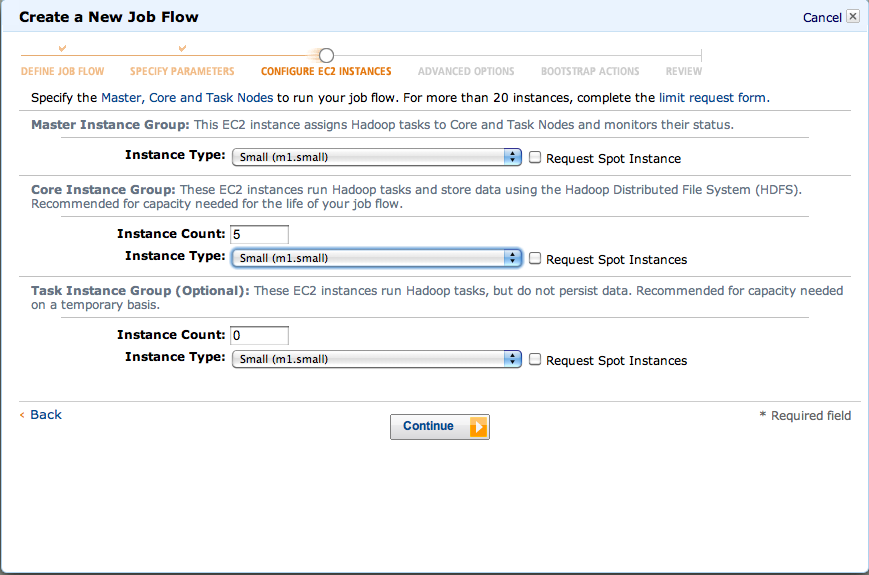
Select one small instance for the Hadoop master node, and five small instances for the core instance group (Figure 4-9). These five nodes will chew our emails in parallel, coordinated by the master node. The more nodes we add, the faster our data will be processed if we tell Pig to increase parallelism.
Launch this cluster, and then check the Elastic MapReduce section of the AWS console (Figure 4-10).
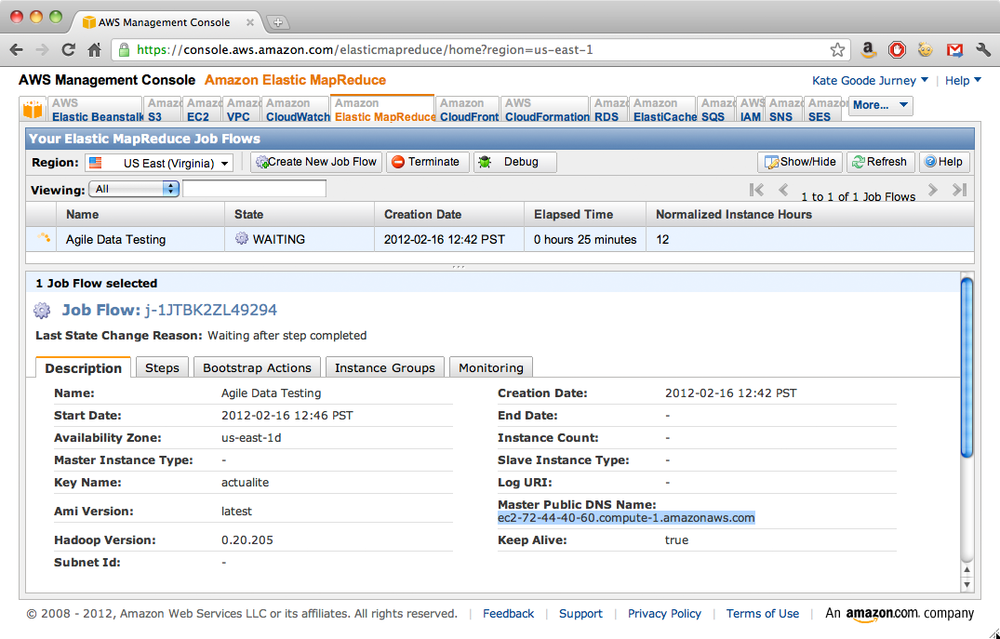
Note the Master Public DNS Name. Once the
cluster state shows the cluster is launched and ready, we can
ssh to the name node and start our Pig session on our new Hadoop cluster. Remember to use the
key with which we configured the cluster earlier.
ssh -i ~/.ssh/actualite.pem hadoop@ec2-given-ip.compute-1.amazonaws.com
You may now run Pig and proceed as you did in
Chapter 3, substituting s3n:// or
s3:// for file://.
Let’s load the emails we uploaded previously and reexecute a Pig script—this time against five nodes.
REGISTER /me/pig/build/ivy/lib/Pig/avro-1.5.3.jar REGISTER /me/pig/build/ivy/lib/Pig/json-simple-1.1.jar REGISTER /me/pig/contrib/piggybank/java/piggybank.jar /* This gives us a shortcut to call our Avro storage function */ DEFINE AvroStorage org.apache.pig.piggybank.storage.avro.AvroStorage(); rmf s3n://agile.data/sent_counts.txt -- Load our emails using Pig's AvroStorage User Defined Function (UDF) messages = LOAD 's3://agile.data/again_inbox' USING AvroStorage(); -- Filter missing from/to addresses to limit our processed data to valid records messages = FILTER messages BY (from IS NOT NULL) AND (to IS NOT NULL); -- Project all unique combinations of from/to in this message, then lowercase emails -- Note: Bug here if dupes with different case in one email. smaller = FOREACH messages GENERATE FLATTEN(from) as from, FLATTEN(to) AS to; pairs = FOREACH smaller GENERATE LOWER(from) AS from, LOWER(to) AS to; -- Not group the data by unique pairs of addresses, take a count, and store as text in /tmp froms = GROUP pairs BY (from, to) PARALLEL 10; sent_counts = FOREACH froms GENERATE FLATTEN(group) AS (from, to), COUNT(pairs) AS total; sent_counts = ORDER sent_counts BY total; STORE sent_counts INTO 's3n://agile.data/sent_counts.txt';
We should see our successful job output, as shown in Figure 4-11.
... Input(s): Successfully read 55358 records (2636 bytes) from: "s3://agile.data/again_inbox" Output(s): Successfully stored 9467 records in: "s3n://agile.data/sent_counts.txt"
Note the parts in boldface. We are now loading
and storing data via s3n URLs. We are also using the PARALLEL decorator to use multiple
mappers and reducers on multiple nodes in parallel. As our data
increases, so does the PARALLEL parameter. You can
find out more about this parameter here: http://pig.apache.org/docs/r0.9.2/cookbook.html#Use+the+PARALLEL+Clause.
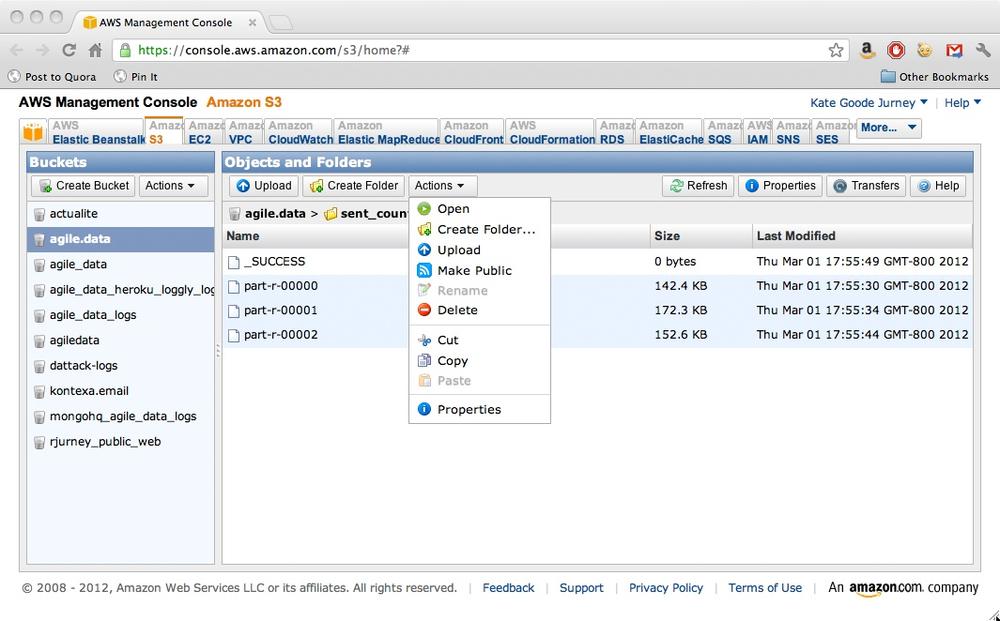
This script generates our
sent_counts on S3, where they are accessible by any
client with the right key. Note that S3 also allows us to publish this
data directly—to one person or to everyone. It also allows us to push
this content to the Cloudfront content distribution network. S3 gives us
options. In Agile Big Data, we love options, as they enable
innovation.
To learn more about Pig, read Programming Pig by Alan Gates (O’Reilly).
Just like before on our local machine, what we really want to do is to easily publish our data to a database. That is where dotCloud’s MongoDB resource comes in.
MongoDB as a Service
Much of the power of dotCloud is its rich library of services. We can use these services to avoid creating system components, outsourcing the complexity of configuring and operating these services without a loss of functionality. The only question, then, is reliability. Can we trust a relatively unknown database provider to keep up its service? What if there is data loss?
In Agile Big Data, we do not trust any database. All data we will be storing in MongoDB is derived and can be rederived and updated at any time. This lowers the bar considerably and allows us to take a chance on a new vendor in production when we might otherwise not.
At the time of writing, two EC2
MongoDB-as-a-service providers are available: MongoHQ and MongoLabs.
Both are good choices, and both work with Elastic MapReduce. That being
said, dotCloud has its own MongoDB service that we’ve provisioned under
the data tag.
You can get info about the MongoDB instance we configured with
the dotcloud info data
command:
dotcloud info data
== data
type: mongodb
instances: 1
reserved memory: N/A
config:
mongodb_nopreallocj: True
mongodb_oplog_size: 256
mongodb_replset: testola.data
mongodb_password: ***************
mongodb_logrotate_maxage: 30
mongodb_noprealloc: True
mongodb_smallfiles: True
URLs: N/A
=== data.0
datacenter: Amazon-us-east-1d
service revision: mongodb/32d488a9ef44 (latest revision)
ports:
mongodb: mongodb://root:***@testola-rjurney-data-0.azva.dotcloud.net:40961We’ll use the MongoDB connection string in our Pig script to push
data there. First we need to set up the agile_data
database and user. To set up authentication, run dotcloud run
data mongo.
use admin
db.auth("root", "*******");Then, to set up our database, run:
use metrics
switched to db metrics
db.getSisterDB("admin").auth("root", "*******");
db.my_collection.save({"object": 1});
db.my_collection.count();To set up a user, run:
use metrics
db.getSisterDB("admin").auth("root", "*******");
mynicedb.data:PRIMARY> db.addUser("jack", "OpenSesame");Now our database is built, so let’s use it to push data to Mongo!
Pushing data from Pig to MongoDB at dotCloud
Pushing data from Pig to dotCloud MongoDB works the same as before, but our connection string changes to the URI provided by dotCloud, with a new username and password plugged in (Example 4-4).
REGISTER /me/mongo-hadoop/mongo-2.7.3.jar
REGISTER /me/mongo-hadoop/core/target/mongo-hadoop-core-1.0.0-rc0.jar
REGISTER /me/mongo-hadoop/pig/target/mongo-hadoop-pig-1.0.0-rc0.jar
sent_counts = LOAD 's3://agile.data/sent_counts.txt' AS (from:chararray,
to:chararray, total:int);
STORE sent_counts INTO
'mongodb://jack:OpenSesama@testola-rjurney-data-0.azva.dotcloud.net:40961/
<agile_data>.sent_dist'
USING com.mongodb.hadoop.pig.MongoStorage;Finally, we verify that our data is present in our new MongODB instance:
dotcloud run data mongo
==> Executing "mongo" on service (data) instance #0 (application testola)
^[[AMongoDB shell version: 2.2.2
connecting to: test
> use agile_data
> db.auth("jack", "OpenSesame")
> show collections
sent_dist
system.indexes
system.users
> db.sent_dist.find()
{ "_id" : ObjectId("4f41b927414e552992bf3911"), "from" : "k@123.org", "to" :
"common-user@hadoop.apache.org", "total" : 3 }
{ "_id" : ObjectId("4f41b927414e552992bf3912"), "from" : "fm@hint.fm", "to" :
"russell.jurney@gmail.com", "total" : 1 }
{ "_id" : ObjectId("4f41b927414e552992bf3913"), "from" : "li@idle.li", "to" :
"user@hbase.apache.org", "total" : 3 }
...Instrumentation
If we aren’t logging data on how our application is used, then we aren’t able to run experiments that teach us about our users and how to meet their needs and give them value.
Google Analytics
Google Analytics (http://www.google.com/analytics/) provides basic
capability to understand the traffic on your website. Sign up if you
haven’t already. Create a new property under the Admin>Accounts tab.
Name it after your dotCloud site, in this case, http://agiledatabook.dotcloud.com. Select, copy, and
paste the tracking code into the
<head>
of your site-layout template like so:
<head>
...
<script type="text/javascript">
var _gaq = _gaq || [];
_gaq.push(['_setAccount', 'XX-XXXXXXX-X']);
_gaq.push(['_trackPageview']);
(function() {
var ga = document.createElement('script'); ga.type = 'text/javascript';
ga.async = true;
ga.src = ('https:' == document.location.protocol ? 'https://ssl' :
'http://www') + '.google-analytics.com/ga.js';
var s = document.getElementsByTagName('script')[0];
s.parentNode.insertBefore(ga, s);
})();
</script>
</head>That’s it. We’ve inserted basic click tracking into our application.
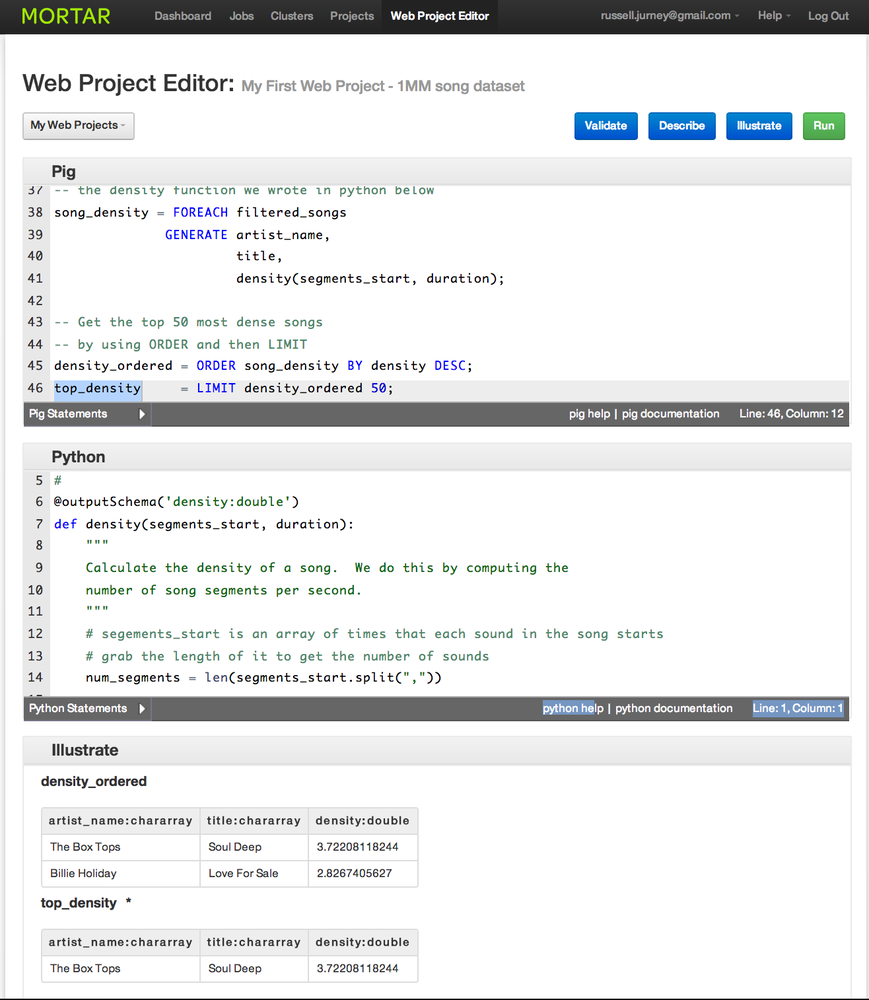
Mortar Data
One way to accelerate Pig development is with the PaaS provider Mortar Data (Figure 4-12). Using Mortar Data, you can refine data in Pig and Python (as first-class user-defined functions [UDFs], including nltk, numpy, and scipy!), and publish to MongoDB—all from a clean, intuitive web interface.
Get Agile Data Science now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

